タイトル画像:Haplogroup R (Y-DNA).PNG
この記事は執筆中です。
どんな言葉を・どんな人が話しているか。
言語や語学に興味があるひとであれば、誰もが持つ素朴な疑問でしょう。
あるいは、もっとマニアックに(笑)、
ドイツ語やフランス語のルーツは印欧祖語だけど、印欧祖語のルーツは?
古代漢語は印欧祖語に似ているらしいけど、古代漢語を話していたのはどんなひとたち?
など、「いろいろな言語のルーツや系統」について、知りたい方も多いでしょう。
言語のルーツ・系統を探るのは「比較言語学」の役目で、文字情報が豊富な印欧語族の祖語(印欧祖語)再構において、さらには、文献資料のないオーストロネシア語族においても、多くの成果をあげています。
一方で、遺伝子の分析テクノロジーが近年、飛躍的に進歩し、人類の「遺伝子系統」がどんどん明らかになってきています。
そして、「言語(語族)と遺伝子」にかなりの相関関係があることも分かってきたのです。
将来的には(考古学とも協働しつつ)、「印欧祖語のルーツや古代漢語との関係」、さらには、「シュメール語や日本語の起源」、などの解明も進んでいくのではないでしょうか。。。
そんなことも願いつつ、今回は、「言語と遺伝子」の関係について、紹介していきます!
遺伝子とDNA
「言語(語族)と遺伝子」の関係について理解するには、遺伝子、さらに、DNA、染色体、ミトコンドリアについて、基礎的なことを知っておく必要があります。
下図は、「典型的な動物細胞の模式図」です。
①核小体(仁)、②細胞核、③リボソーム、④小胞、⑤粗面小胞体、⑥ゴルジ体、⑦微小管、⑧滑面小胞体、⑨ミトコンドリア、⑩液胞、⑪細胞質基質、⑫リソソーム、⑬中心体
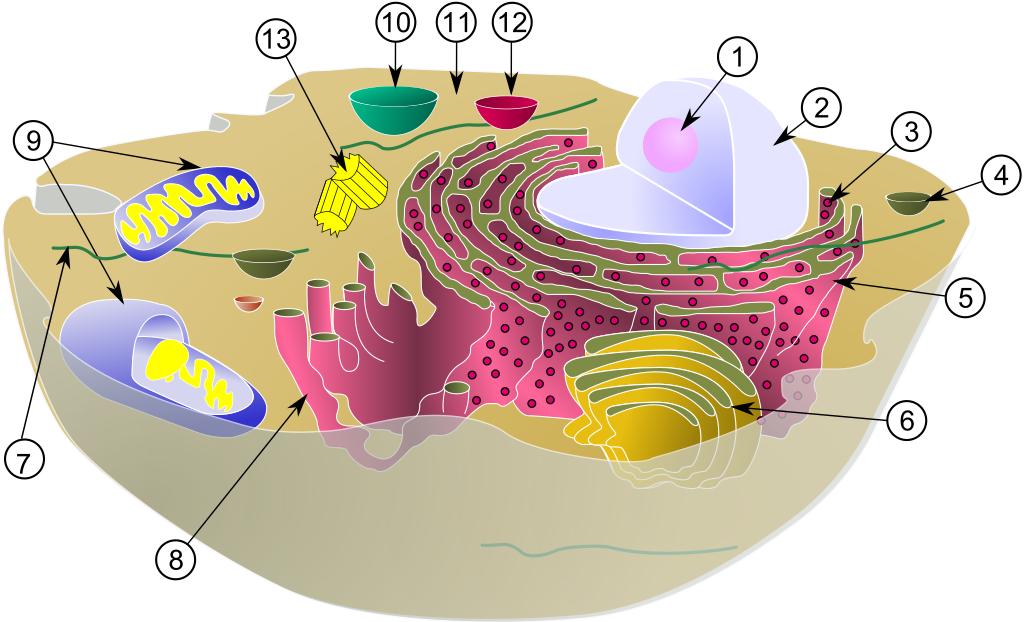
本記事で重要なのは、
②細胞核(厳密には、この中にある染色体)、⑨ミトコンドリア の2つです。
「染色体」「ミトコンドリア」の中に、「DNA」があり、DNAのうちの一部が「遺伝子」です。
ここから先は、『新版 日本人になった祖先たち―DNAが解明する多元的構造』(篠田謙一著、2019年、NHKブックス)という本に、とても分かりやすい(!)説明があるので、これを参考に紹介していきます。(引用は、2007年発行の旧版『日本人になった祖先たち―DNAから解明するその多元的構造』によります)

.PNG){kind=link}
{kind=link}
遺伝子は、私たちの体を構成しているさまざまなタンパク質の構造やそれが作られるタイミングを記述している設計図です。[中略]
私たちの体を作るために2万~3万個の遺伝子があることがわかっています。(p15)この設計図を書いている「文字」にあたるものがDNAです。
DNAはデオキシリボ核酸という化学物質の略号ですが、その文字は全部で4種類しかありません。(p15)この4種類の文字は総称して「塩基」という特別の名称で呼ばれます。
さらにDNAは、複製を作るために2本の鎖状の構造を取っていて、特定の塩基がペアになって存在するので、通常はそのペアのことを「塩基対」という言葉を用いて表現します。(p15)塩基対を単位として考えると、ヒトの持つDNA全体は、それが約30億も連なった長大なものになります。[中略]
私たちのDNA配列には意味のない部分が大量にあります。約95%は、今のところ何の意味もない文字の羅列でできていると考えられているのです。(p15-p16)
遺伝子、DNA、塩基対の関係は、下記「ゲノムの構造図」の下半分をご覧ください。
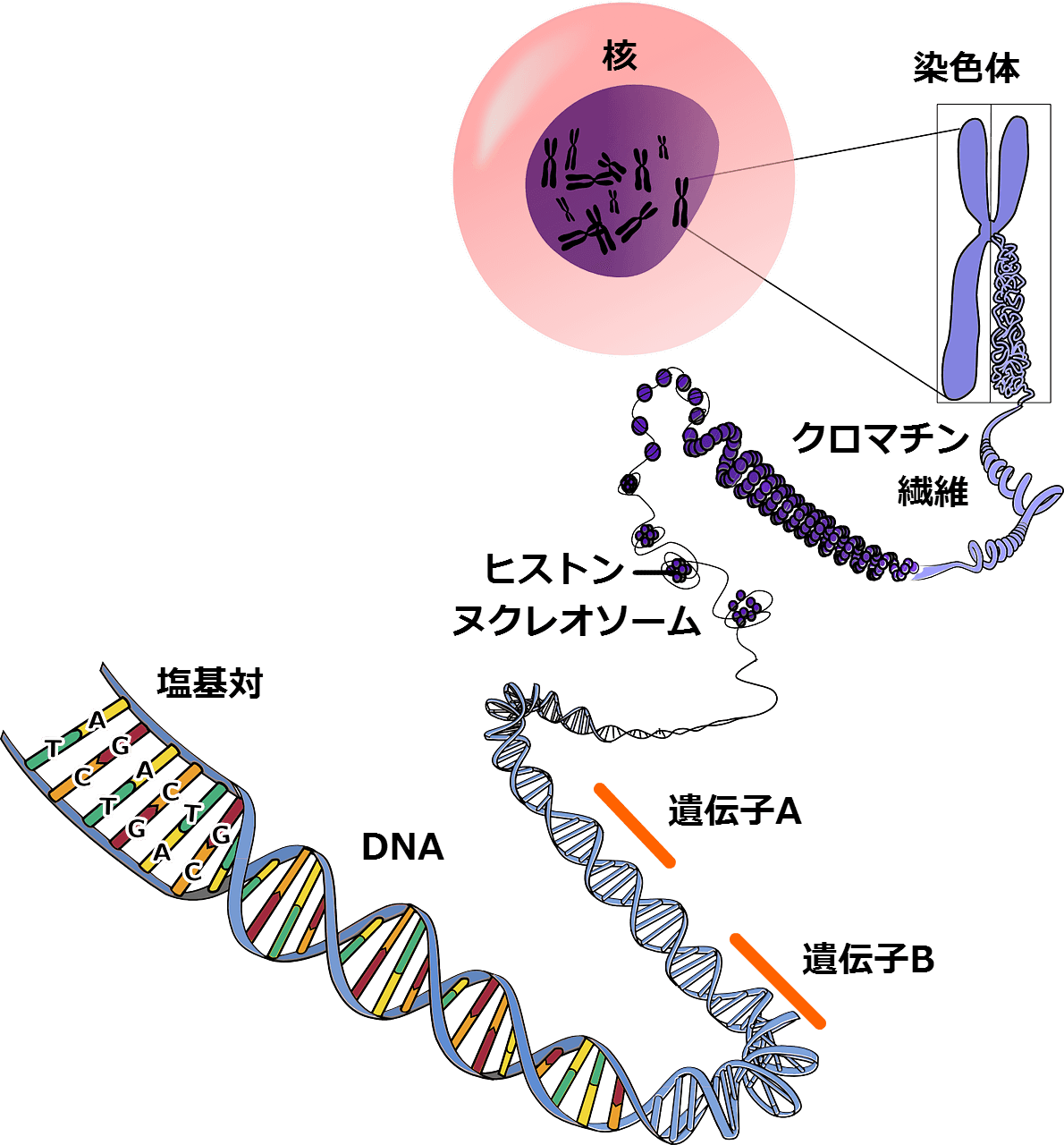
DNAを「らせん階段」に例えるなら、塩基対は「段(ステップ)」に相当します。
下図は、塩基対の構造を示した模式図です。
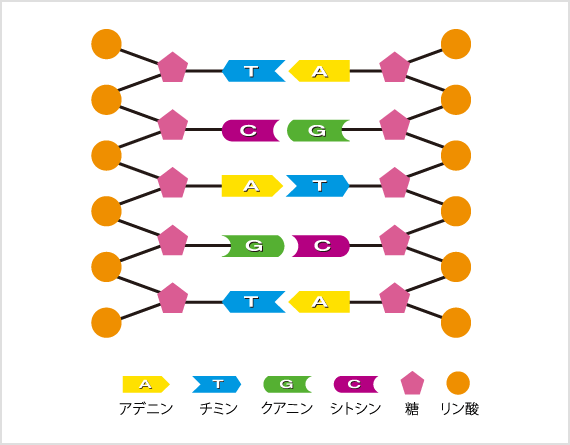
塩基対は、4種類ある塩基物質(Aアデニン、Gグアニン、Cシトシン、Tチミン)のペアで、常に A と T、G と C が対になります。
上図の左側を上から読むと TCAGT、右側を上から読むと AGTCA になります。
塩基対をタテに配列したもの(この例では、TCAGT, AGTCA)を「塩基配列」といいます。
※「DNA配列」「遺伝子配列」とも呼ばれます。
ちなみに、TCAGT = AGTCA です。
なぜなら、左が T であれば右は A、左が C であれば右は G … に一意的に決まるからです。
これを、「塩基の相補性」といいます。
ひとつのDNAを構成する塩基配列は、じっさいには膨大な長さをもつのですが、タンパク質の形成に関わる「コーディング領域」(とびとびに現れ、合計で約5%)と、それ以外の「ノンコーディング領域」(約95%)があります。
おおざっぱに言うと、タンパク質の形成に関わる部分、つまり、「塩基配列のコーディング領域」が「遺伝子」です。
遺伝子は20種類の「アミノ酸」でできており、それぞれのアミノ酸は、塩基対が3つ配列したユニットに対応します。(下記「DNAの遺伝暗号(コドン)表」参照)
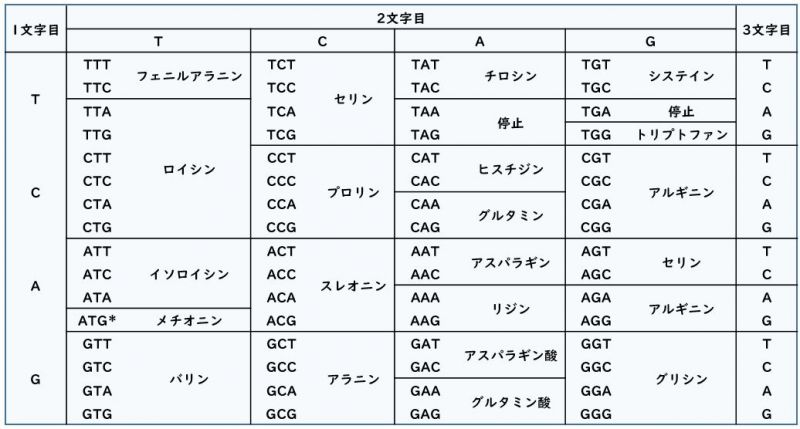
たとえば、・・・・GAA・・・・CAA・・・・という塩基配列があったとして、その途中に「GAA」があればその部分は「グルタミン酸」、「AGG」があればその部分は「アルギニン」というアミノ酸に該当する、というわけです。
染色体
つづいて、「染色体」の話題に移りましょう。
ふたたび『日本人になった祖先たち』に戻ります。
染色体というのは、簡単に言うと遺伝子をまとめて収納する入れものです。(p187)[中略]
総数で2万~3万個あると言われる遺伝子は、バラバラになって核のなかに入っているわけではなく、染色体のなかにグループになって収納されているのです。
大きい染色体では3000個くらい、小さいものでも数百個の遺伝子をまとめて収納しています。(p187)
遺伝子が染色体に収納されているイメージは、前出「ゲノムの構造図」をご覧ください。
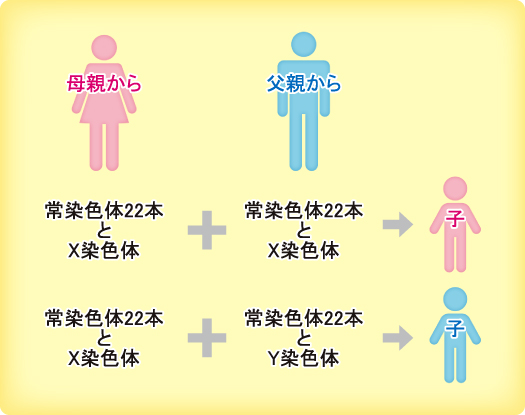
ヒトには全部で23種類の染色体があるのですが、実際には両親から1セットずつを受け取っているので、1つの細胞のなかにその2倍の46本の染色体が存在しています。(p187-p188)
このうち22種類までは男女で同じものを持っています。[中略]
しかし残りの1組は男性と女性で構成が異なっています。
女性はX染色体をペアで持っているのですが、男性はX染色体とY染色体という形の違う染色体を持っています。(p188)
男女で同じである22種類の染色体を「常染色体」、残り1種類の染色体を「性染色体」といいます。
下図のように、生殖時(受精時)に母親から受け継ぐのはX染色体しかあり得ません。
一方、父親からX染色体を受け継いだ子供は女性(XX)に、Y染色体を受け継いだ子供は男性(XY)になります。
{kind=link}
さて、Y染色体は、遺伝子の変化を起こさずにそのまま子孫に伝えられます。
したがって、Y染色体の系統をたどっていくと、父方のルーツが分かるということになります。
ハプロタイプ
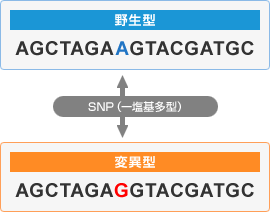
塩基配列の中で、ある特定の一箇所の塩基だけが異なるような現象を、SNP(Single Nucleotide Polymorphism / 一塩基多型)と呼びます。
たとえば下図の場合、普通の配列(野生型)のなかで、1箇所だけ A が G に変異しています。
この状態を「SNP」と呼ぶわけです。
Y染色体の系統
まず、Y染色体の系統図をご覧ください。(Wikipedia > Y染色体ハプログループ より)
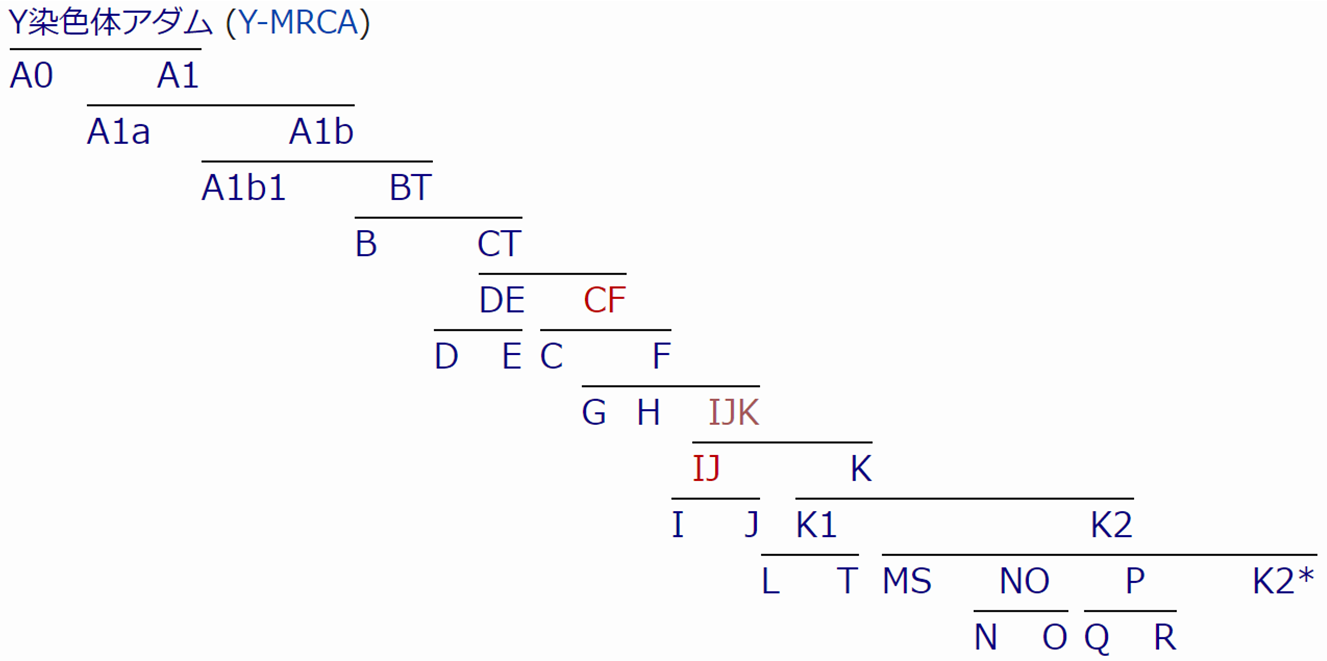 アルファベットが A から R まで、18文字使われていますね。
アルファベットが A から R まで、18文字使われていますね。
それぞれは、Y染色体の大分類に対応しています。
つまり、Y染色体は大きく18分類となっており、これは、2002年に世界の学者が集まった共同研究機関で取り決められたものです。
じっさいには、アルファベットを複数合わせたもの(BT、CT、DEなど)や、数字と小文字を組み合わせたサブグループ(A1b1など)もあり、分類数は膨大なものになっています。
遺伝子(Y染色体)と語族
先ほどの「Y染色体の系統図」を踏まえ、「Y染色体と語族の対応表」を作成したので、ご覧ください。
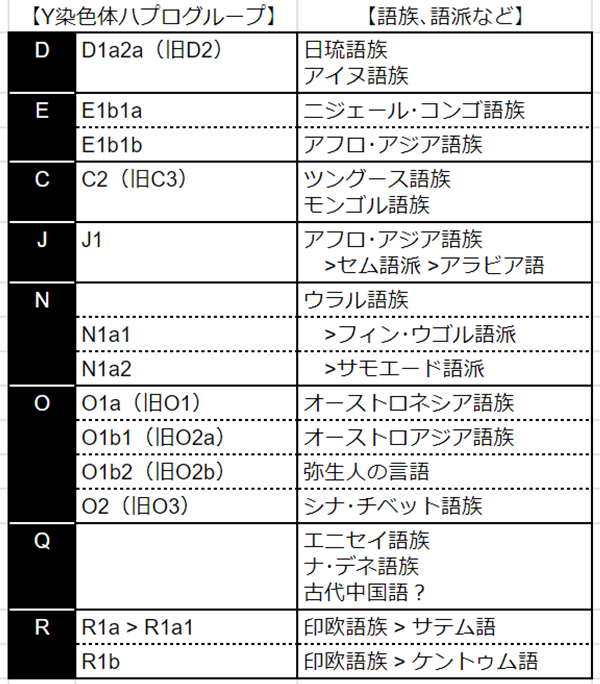
それぞれについて、詳細に見ていきます。
Y-D
まずは、「ハプログループDの分布図」です。
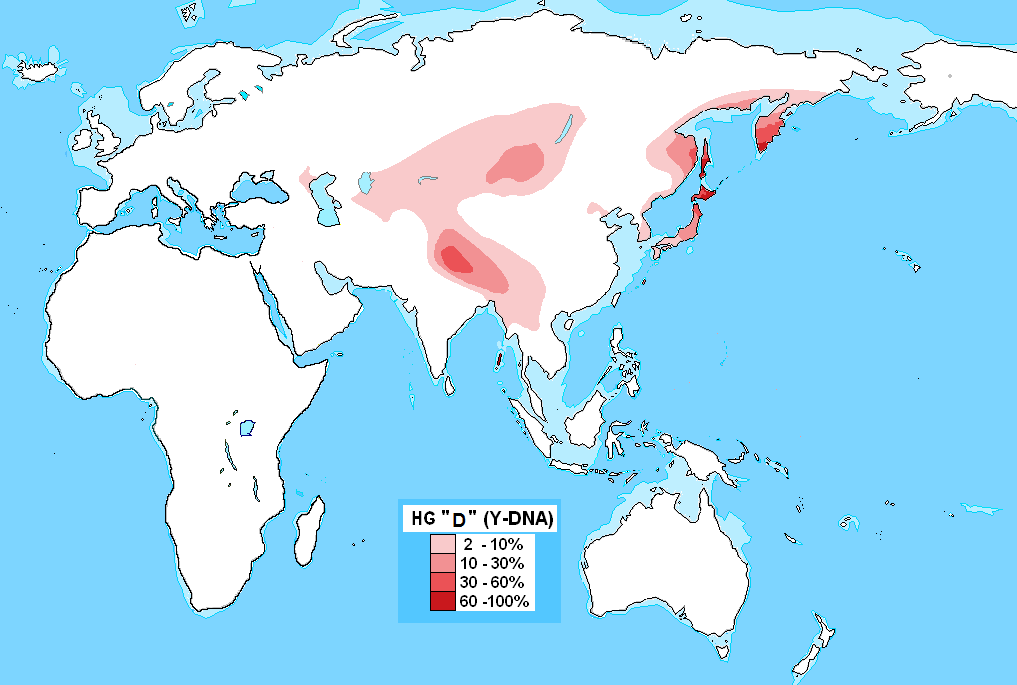
.png){kind=link}
D1a2a(旧Y-D2):日琉語族・アイヌ語族
つぎに、ハプログループD1a2aについて見てみましょう。
「ハプログループDの移動想定経路 (Haber et al. 2019)」をご覧ください。
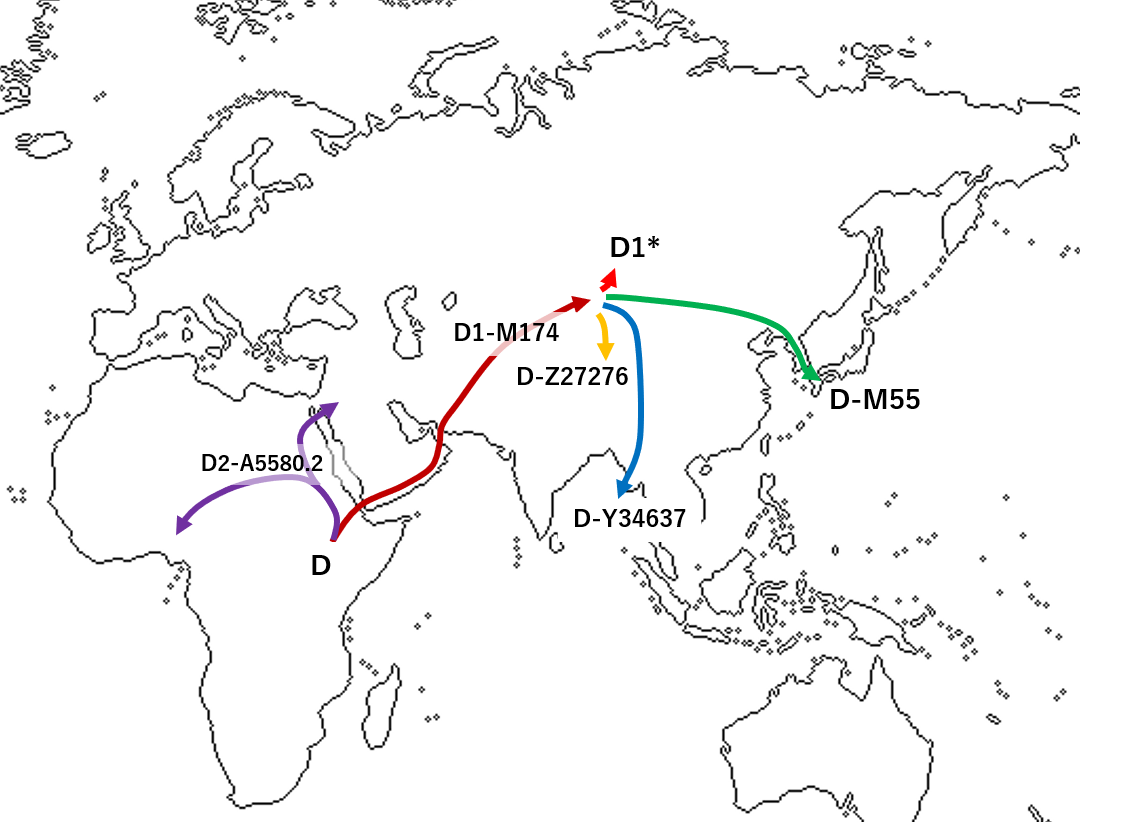
_migration.png){kind=link}
Y-E
「ハプログループEの分布」をご覧ください。
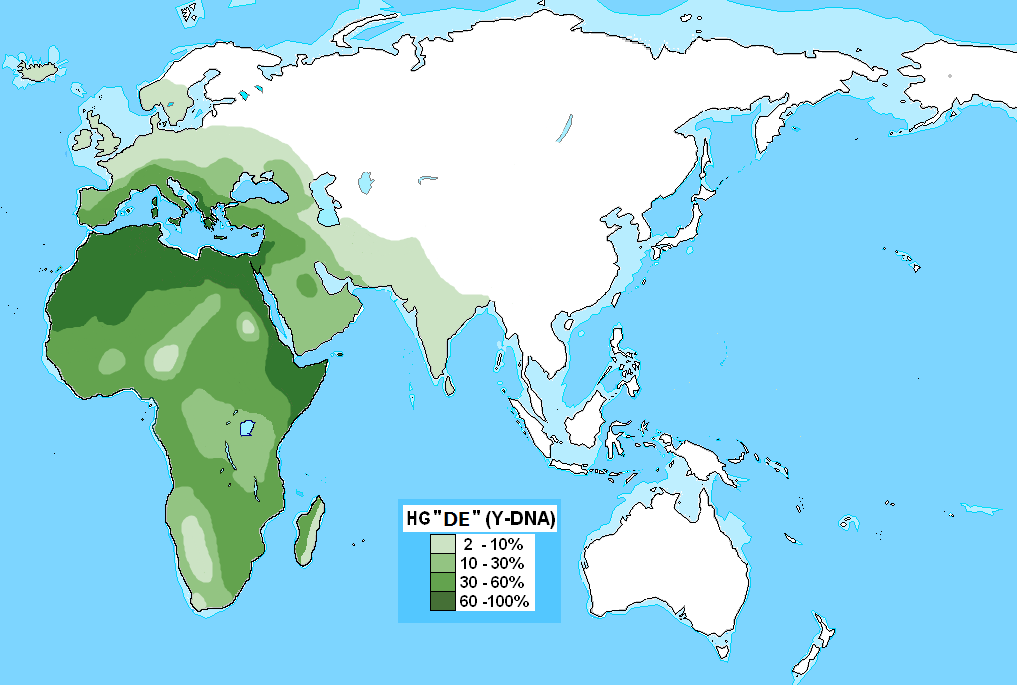
.png){kind=link}
E1b1a:ニジェール・コンゴ語族
「ハプログループE1b1aの分布」です。Wikipedia フランス語版 にありました。
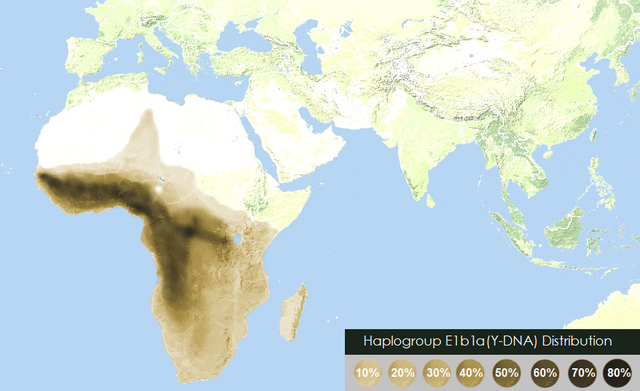
{kind=link}
E1b1b:アフロ・アジア語族
「ハプログループE1b1bの分布」です。Wikipedia フランス語版 より。
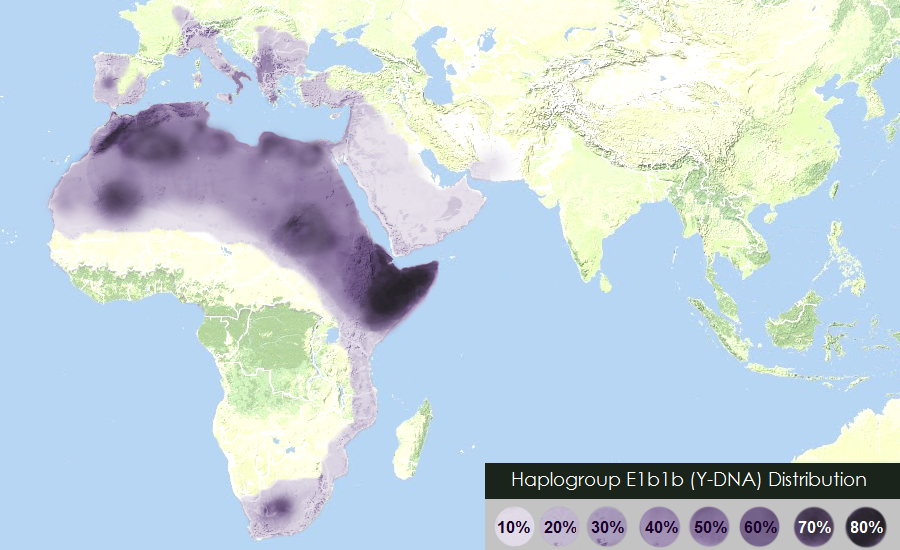
{kind=link}
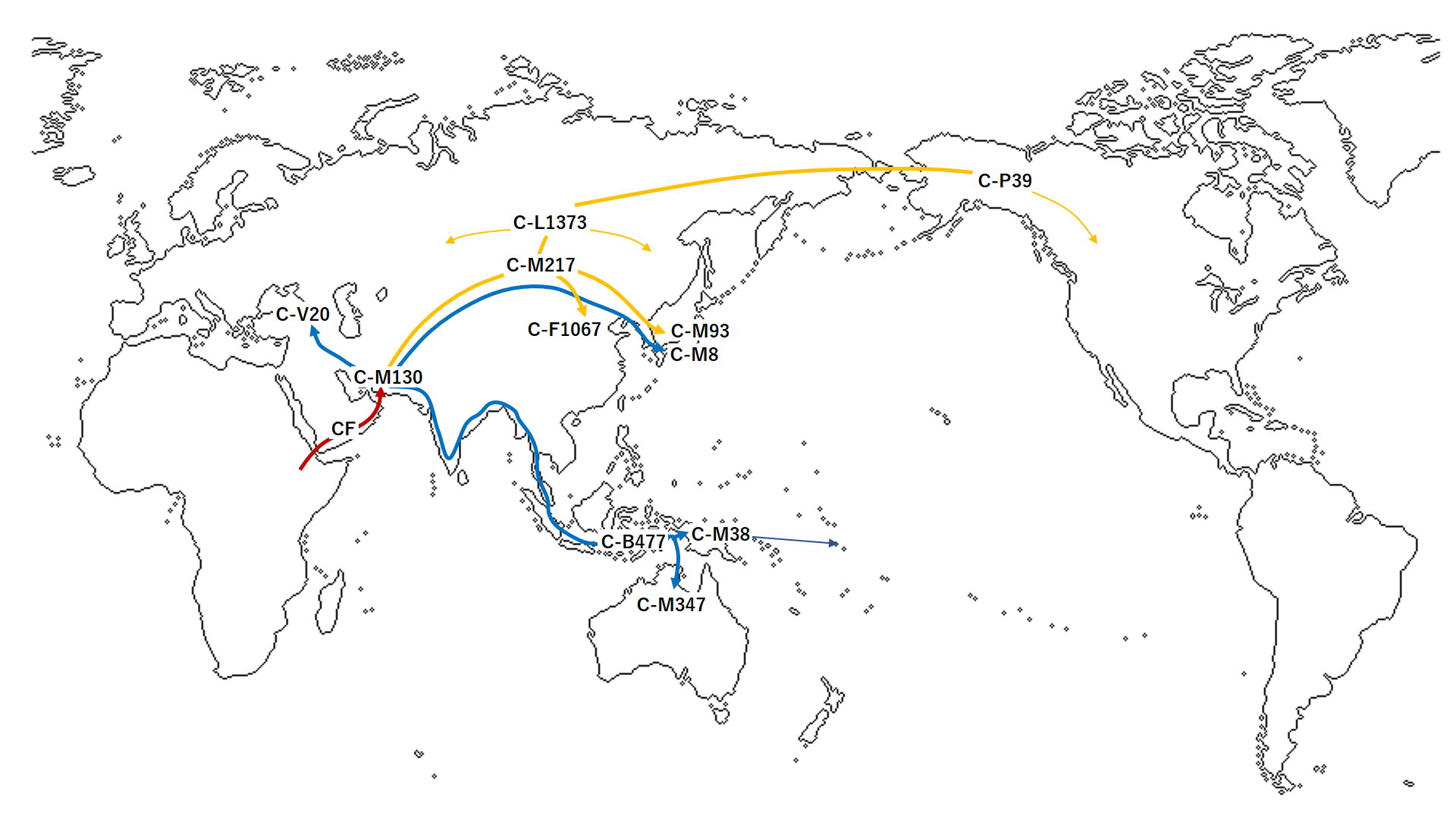
Y-C
「ハプログループCの拡散経路」をご覧ください。(Wikipedia 日本語・英語版など より)
データは、崎谷満(2009)『DNA・考古・言語の学際研究が示す新・日本列島史 日本人集団・日本語の成立史』勉誠出版 に基づいているようです。
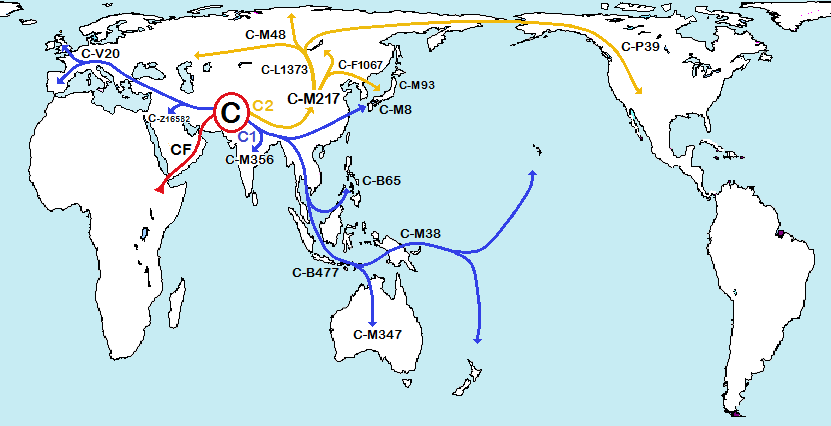
 つづいて、「ハプログループCの起源と拡散経路」(2017年作成)をご覧ください。(Wikipedia スペイン語・ロシア語版 より)
つづいて、「ハプログループCの起源と拡散経路」(2017年作成)をご覧ください。(Wikipedia スペイン語・ロシア語版 より)
_migration.png){kind=link}
_2017.png){kind=link}
Wikipedia ロシア語版 には、「ハプログループCの東南アジアにおける拡散経路」(2013年作成)がありましたので掲載します。
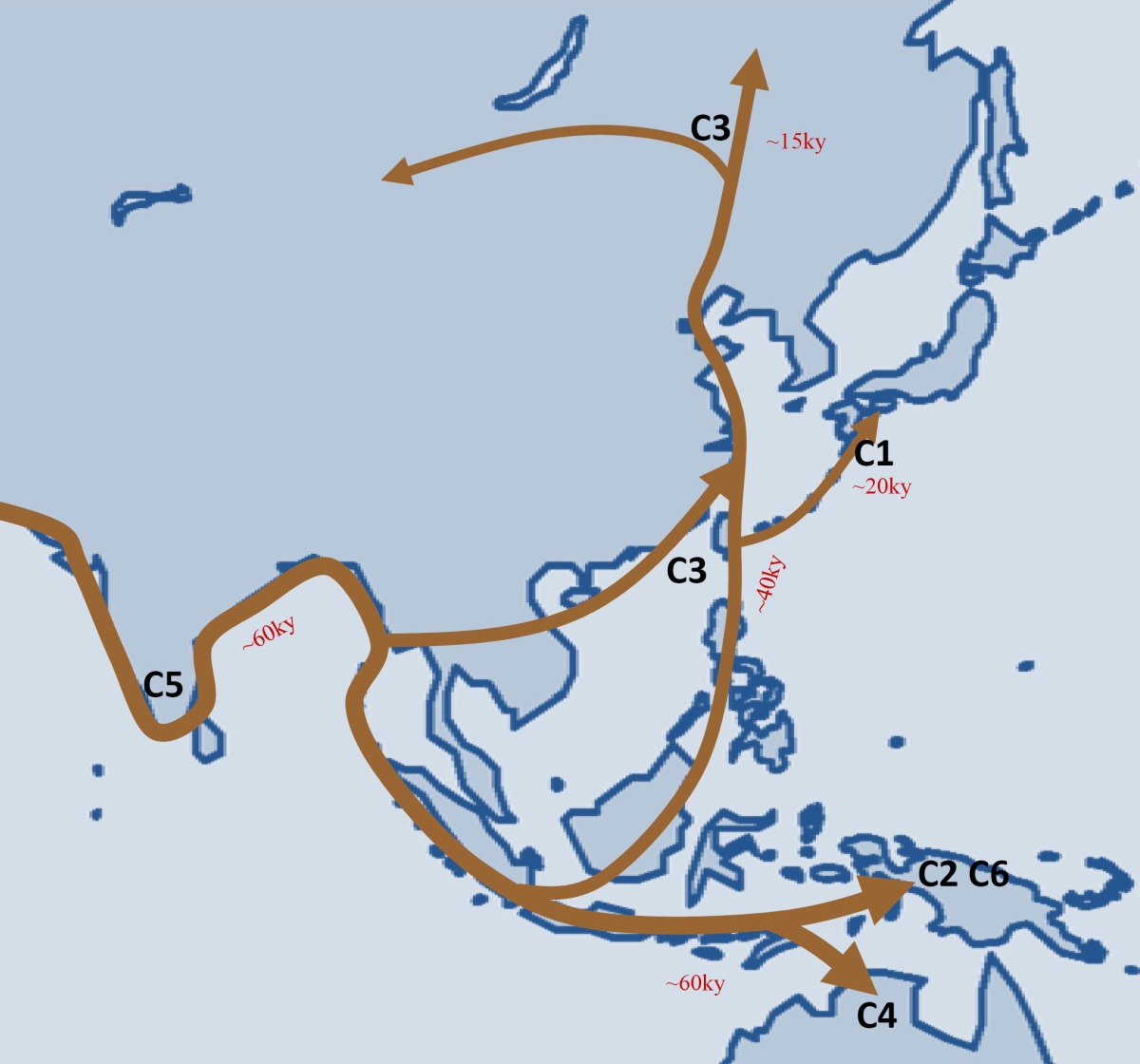
{kind=link}
C2(旧Y-C3):ツングース語族、モンゴル語族
「ハプログループC2の分布図」をご覧ください。
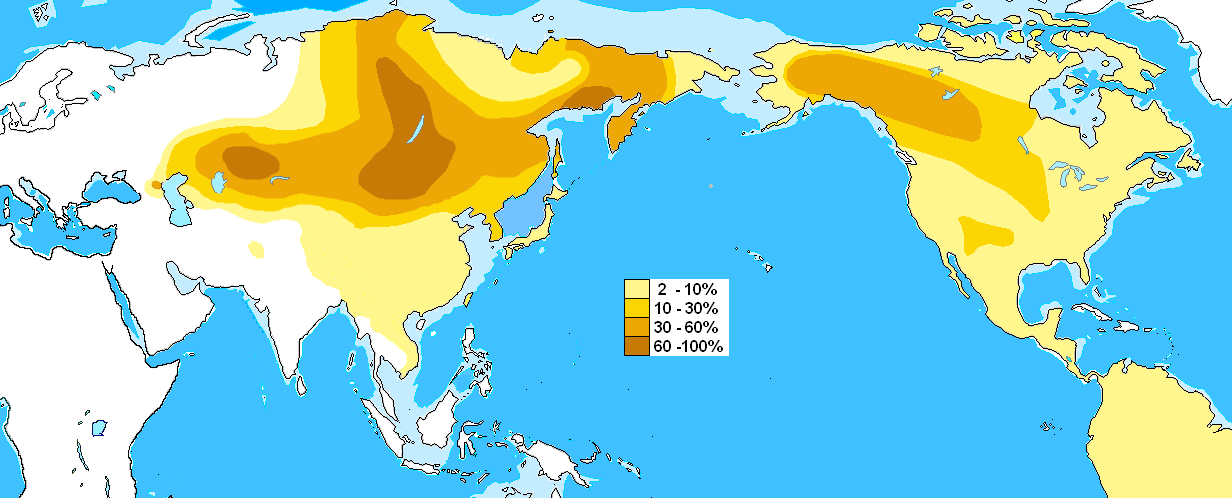
{kind=link}
Y-J
「ハプログループJの分布」をご覧ください。(Wikipedia ドイツ語版 より)
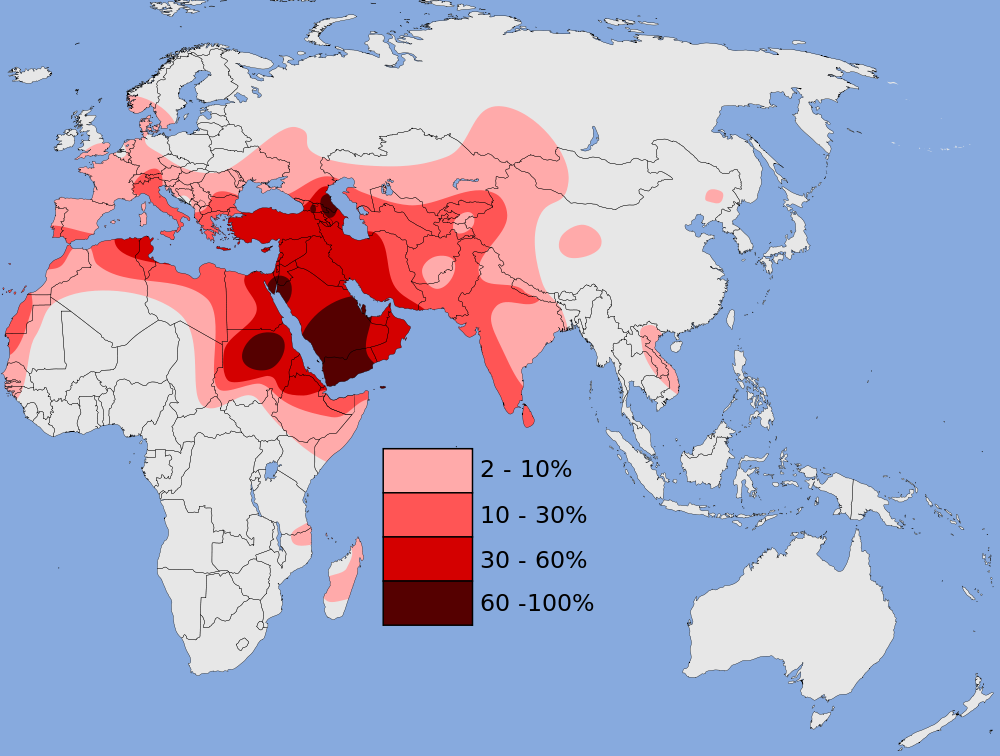
.svg){kind=link}
J1:アフロ・アジア語族>セム語派>アラビア語
「ハプログループJ1の分布」をご覧ください。(Wikipedia スペイン語版 より)
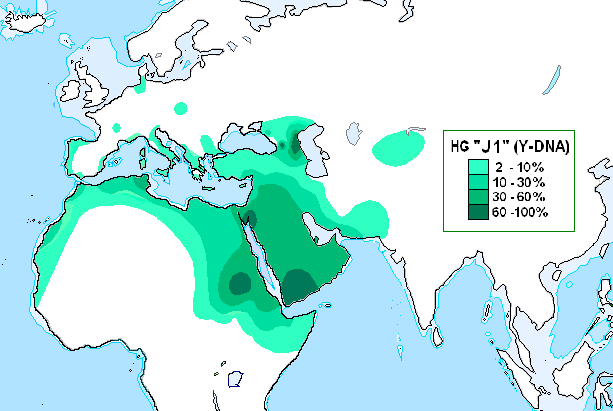
.PNG){kind=link}
参考まで、「ハプログループJ2の分布」も掲載します。(Wikipedia スペイン語版 より)
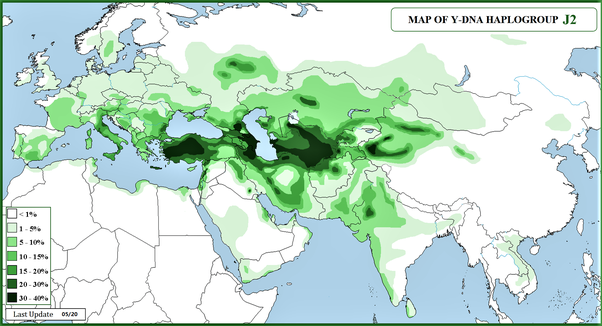
.png){kind=link}
Y-N:ウラル語族
「ハプログループNの分布」をご覧ください。
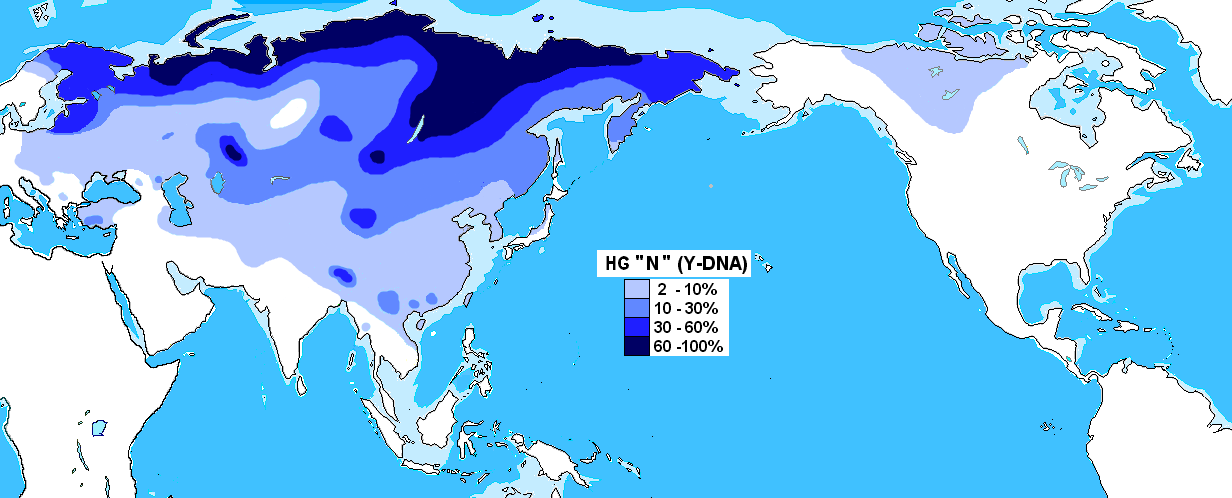
.PNG){kind=link}
つぎに、「ハプログループNの移動経路(青色)」(2017年作成)です。
データは、崎谷満(2009)『DNA・考古・言語の学際研究が示す新・日本列島史 日本人集団・日本語の成立史』勉誠出版 に拠るようです。
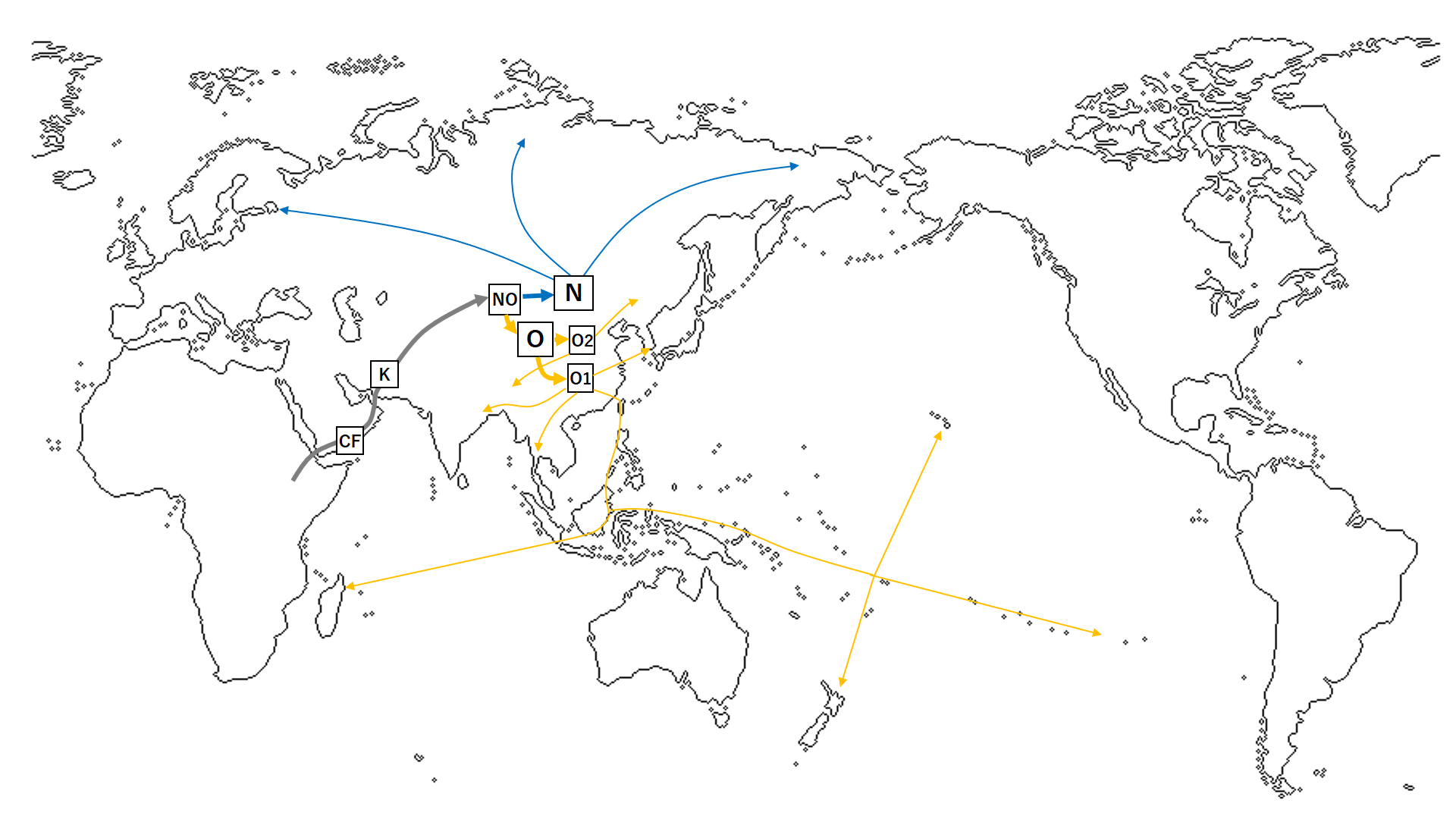 つづいて、「ハプログループN、Oに関連する東アジアの民族移動」(2017年作成)です。
つづいて、「ハプログループN、Oに関連する東アジアの民族移動」(2017年作成)です。
崎谷満『DNA・考古・言語の学際研究が示す新・日本列島史 日本人集団・日本語の成立史』(勉誠出版 2009年)その他の資料をもとに作成されたものです。
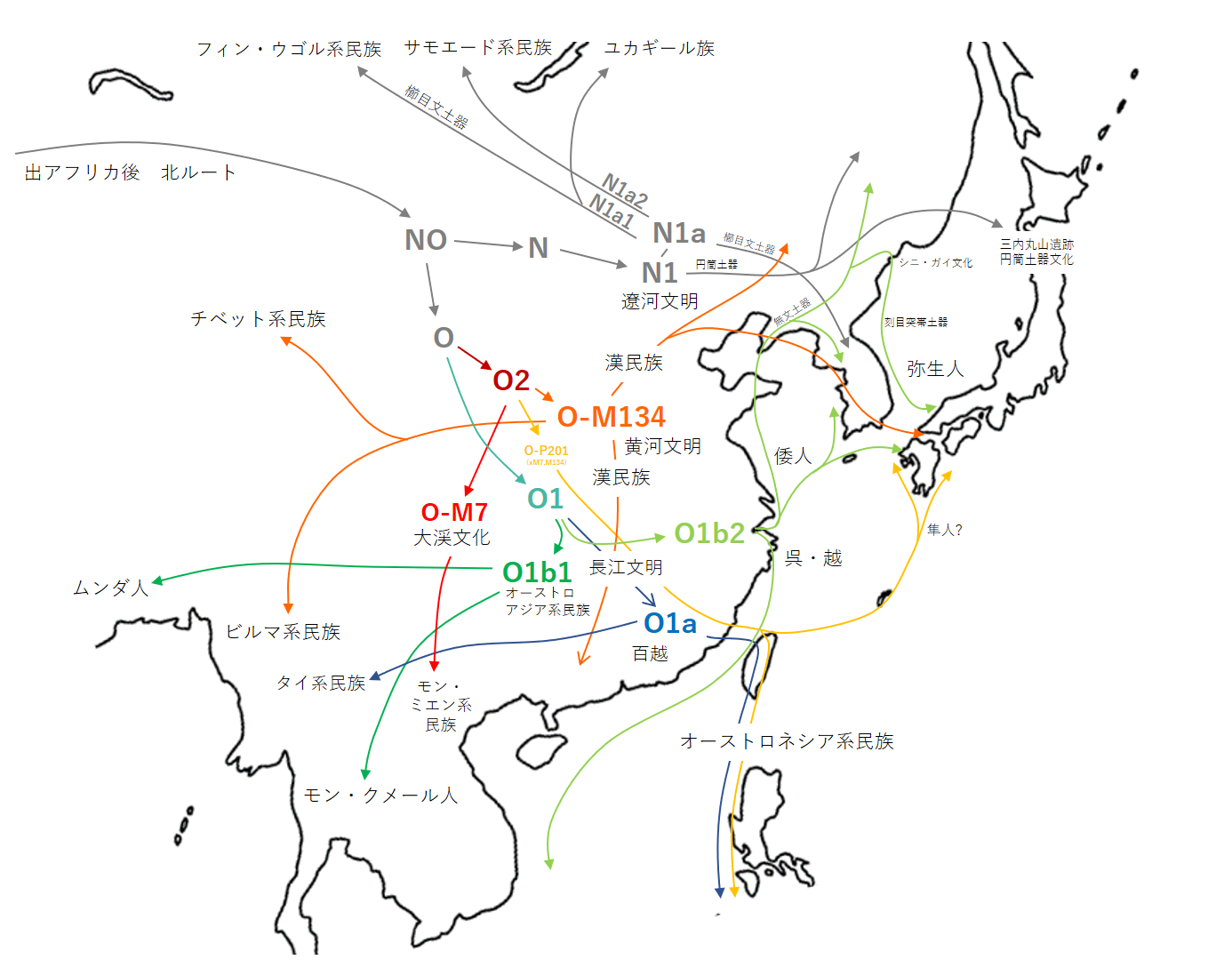
_migration.png){kind=link}
_in_East_Asia.png){kind=link}
N1a1:フィン・ウゴル語派
N1a2:サモエード語派
Y-O
「ハプログループOの分布」です。
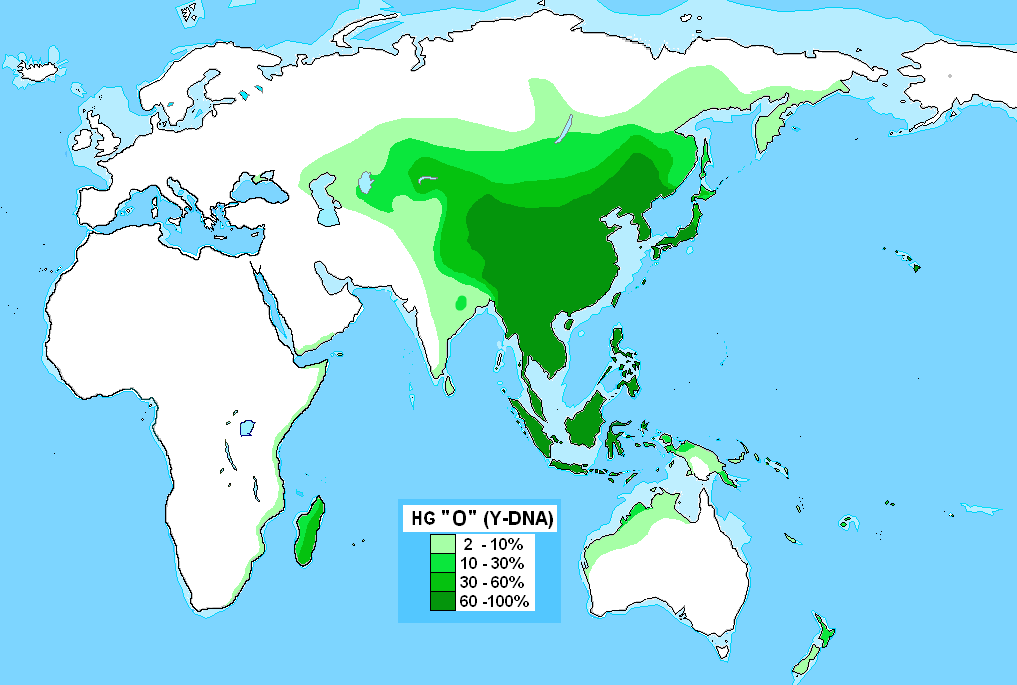
.PNG){kind=link}
O1a(旧Y-O1):オーストロネシア語族
O1b1(旧Y-O2a):オーストロアジア語族
O1b2(旧Y-O2b):弥生人の言語
「弥生人に連なる東アジアのY染色体ハプログループと民族移動」(2017年作成)を掲載します。
崎谷満『DNA・考古・言語の学際研究が示す新・日本列島史 日本人集団・日本語の成立史』(勉誠出版 2009年)などをもとに作成されています。
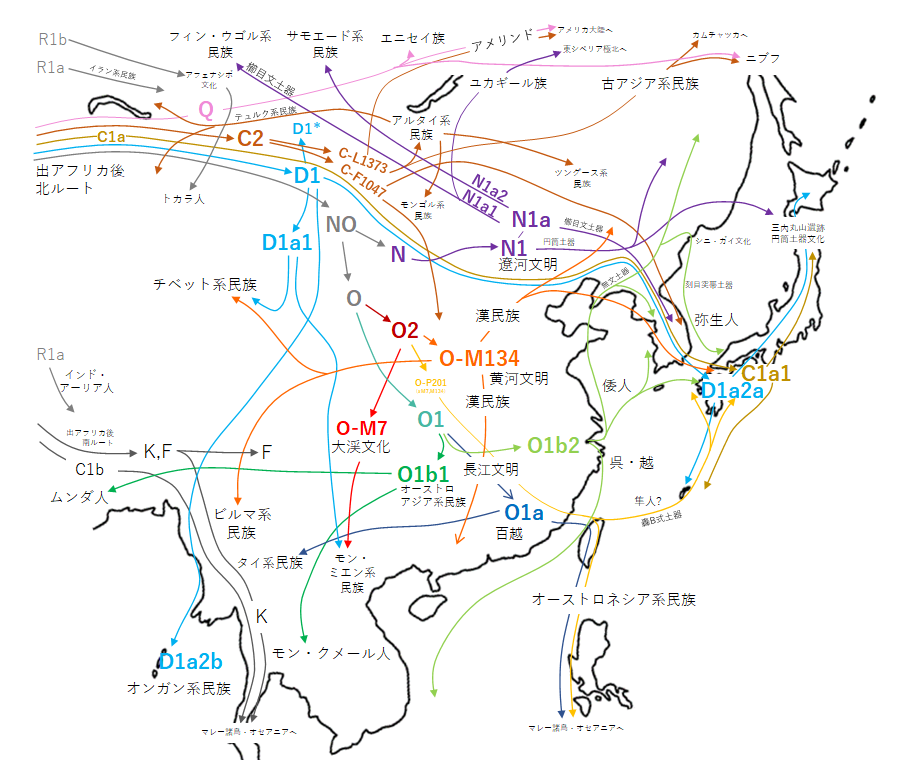
{kind=link}
O2(旧Y-O3):シナ・チベット語族
「ハプログループO2-M122の分布」です。
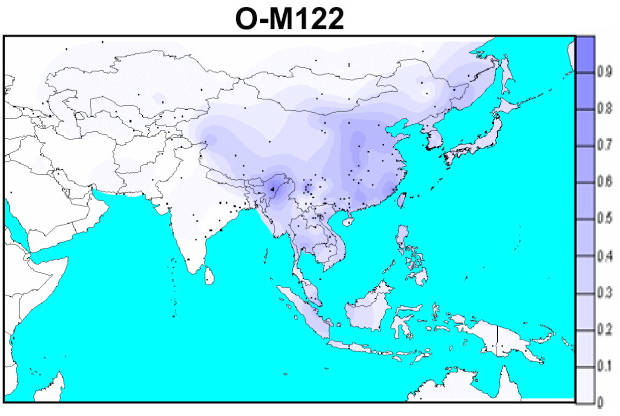
{kind=link}
Y-Q:エニセイ語族、ナ・デネ語族、古代中国語
「ハプログループQの分布」をご覧ください。
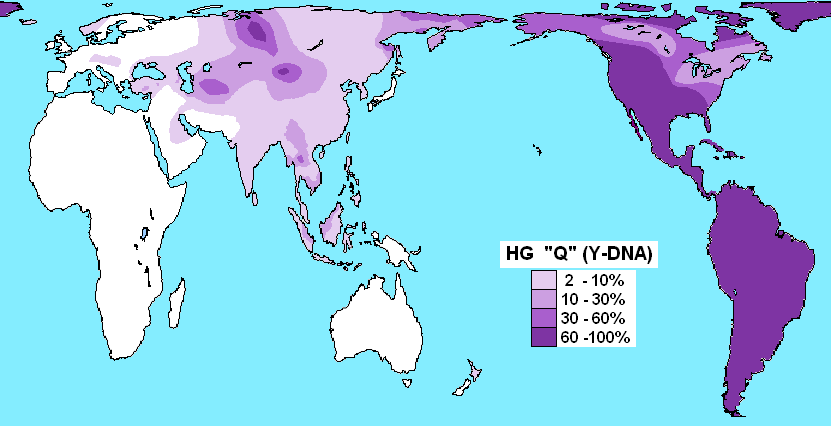
.PNG){kind=link}
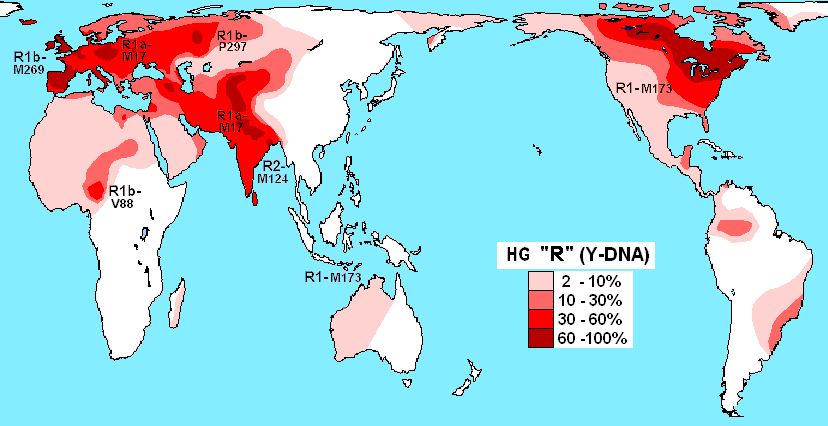
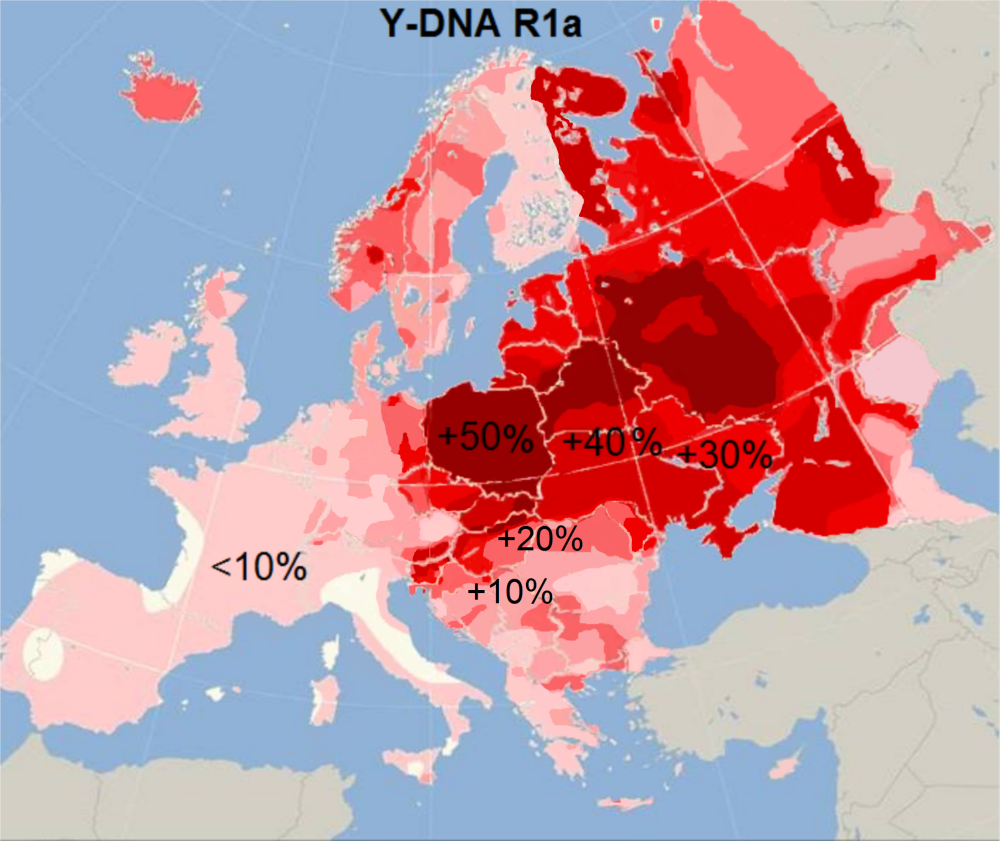
Y-R:印欧語族
「ハプログループRの分布」をご覧ください。
R1a:サテム語
「ヨーロッパにおけるハプログループR1aの分布頻度」をご覧ください。
{kind=link}
R1a の下位系統を、Wikipedia より引用します。
系統はY-DNA Haplogroup R and its Subclades – 2015による。関連言語、文化を付記する。
- R1a L146/M420/PF6229, L62/M513/PF6200, L63/M511/PF6203, L145/M449/PF6175
- R1a* –
- R1a1 M459/PF6235, L120/M516/PF6236, L122/M448/PF6237, Page65.2/PF6234/SRY1532.2/SRY10831.2
- R1a1* –
- R1a1a M512/PF6239, L168, L449/PF6223, M17, M198/PF6238, M514/PF6240, M515
- R1a1a* –
- R1a1a1 M417, Page7
- R1a1a1* –
- R1a1a1a CTS7083/L664/S298
- R1a1a1b S224/Z645, S441/Z647 縄目文土器文化
- R1a1a1b* –
- R1a1a1b1 PF6217/S339/Z283
- R1a1a1b2 F992/S202/Z93 インド・イラン語派 en:Sintashta culture
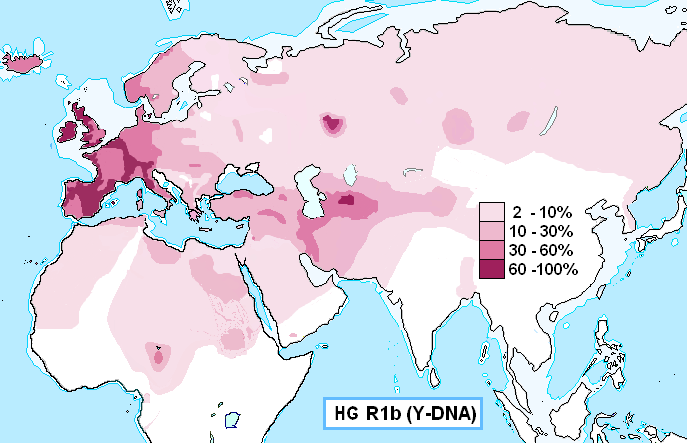
R1b:ケントゥム語
「ハプログループR1bの分布図」です。
.PNG){kind=link}
R1b の系統樹を、Wikipedia より転載します。
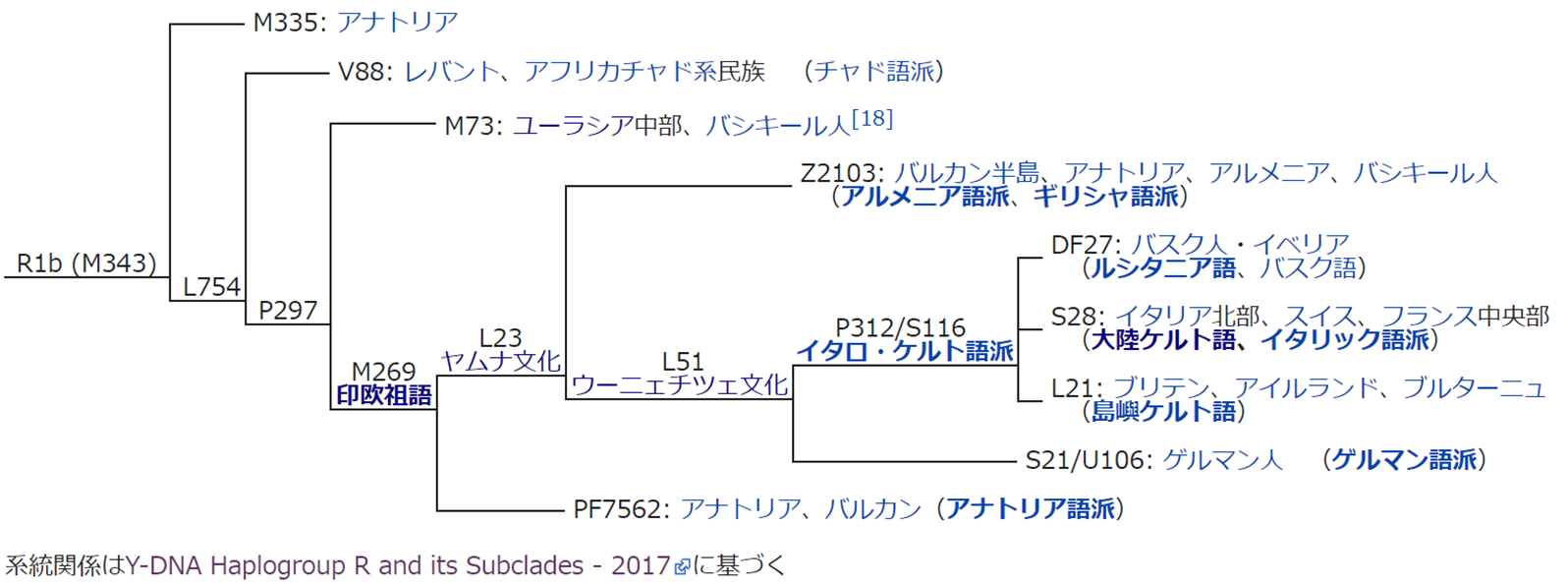
コメント
この記事へのコメントはありません。
トラックバック:thầu xây dựng
トラックバック:cty xây dựng
トラックバック:công ty xây dựng
トラックバック:xây dựng nhà ở
トラックバック:xây nhà trọn gói Đak nông
トラックバック:nha thau xay dung
トラックバック:kinh nghiệm xây nhà ống
トラックバック:công xây dựng nhà
トラックバック:mẫu thiết kế
トラックバック:công ty xây dựng dân dụng
トラックバック:xây dựng nhà trọn gói
トラックバック:nhà cấp 4
トラックバック:thiết kế nhà cấp 4
トラックバック:xây nhà trọn gói
トラックバック:kinh nghiệm xây biệt thự
トラックバック:thầu xây nhà trọn gói tại Dak Nông
トラックバック:sửa chữa nhà trọn gói
トラックバック:nhân công xây dựng
トラックバック:xây dựng nhà
トラックバック:công ty tư vấn thiết kế xây dựng
トラックバック:mẫu nhà cấp 4 mái thái
トラックバック:công ty thiết kế xây dựng
トラックバック:xây 1 trệt 1 lầu bao nhiêu tiền
トラックバック:الحصول على المزيد من المعلومات
トラックバック:lire plus d’informations
トラックバック:lees trending topic
トラックバック:suivez ces informations
トラックバック:এই বিনামূল্যে পড়ুন
トラックバック:obtenir plus de détails
トラックバック:最高のスロット
トラックバック:слот онлайн
トラックバック:ਵਧੀਆ ਸਲਾਟ
トラックバック:слотты қалай ұтады
トラックバック:слот тоглоомууд
トラックバック:খেলার স্লট
トラックバック:فتحة المال
トラックバック:슬롯 게임
トラックバック:бясплатны слот
トラックバック:સ્લોટ રમો
トラックバック:играйте слот
トラックバック:kinh nghiệm xây nhà
トラックバック:پول اسلات
トラックバック:슬롯 로그인
トラックバック:слот ойындары
トラックバック:슬롯 온라인
トラックバック:tiền đánh bạc
トラックバック:എങ്ങനെ വിജയം സ്ലോട്ട്
トラックバック:સ્લોટ ઓનલાઇન
トラックバック:اسلات بازی
トラックバック:khe miễn phí
トラックバック:বিনামূল্যে স্লট
トラックバック:รับข้อมูลเพิ่มเติม
トラックバック:có thêm thông tin
トラックバック:lire ceci gratuitement
トラックバック:Следите за этой информацией
トラックバック:ਇਸ ਜਾਣਕਾਰੀ ਦੀ ਪਾਲਣਾ ਕਰੋ
トラックバック:basahin ang karagdagang impormasyon
トラックバック:나를 열어
トラックバック:抓住我
トラックバック:ゲットミー
トラックバック:читать больше информации
トラックバック:люби меня
トラックバック:xây dựng giá rẻ
トラックバック:મને પ્રેમ કર
トラックバック:спаси ме
トラックバック:나를 따라와
トラックバック:读我
トラックバック:biết thêm chi tiết
トラックバック:като мен
トラックバック:спаси меня
トラックバック:اقرأ المزيد من المعلومات
トラックバック:私のような
トラックバック:Поймай меня
トラックバック:kinh nghiệm xây nhà cấp 4
トラックバック:sigue esta información
トラックバック:Открой меня
トラックバック:lire le sujet tendance
トラックバック:công ty xây nhà
トラックバック:나처럼
トラックバック:discuss
トラックバック:намайг авраач
トラックバック:阅读更多信息
トラックバック:나를 사랑해
トラックバック:تحبني
トラックバック:امسك بي
トラックバック:私を愛して
トラックバック:اتبعني
トラックバック:像我这样的
トラックバック:得到我
トラックバック:空きスロット
トラックバック:玩老虎机
トラックバック:слот пари
トラックバック:オンラインで無料のもの
トラックバック:ең жақсы слот
トラックバック:ұяшыққа кіру
トラックバック:انقذني
トラックバック:prendi questa roba online
トラックバック:scegli questo gratis online
トラックバック:trova questa roba gratis online
トラックバック:trucs gratuits en ligne
トラックバック:situs judi slot deposit pulsa 10rb tanpa potongan gayabet88
トラックバック:スロットゲーム
トラックバック:leia o tópico de tendência
トラックバック:finde diese kostenlosen Sachen online
トラックバック:trouver ce truc gratuit en ligne
トラックバック:гульнявыя грошы
トラックバック:ahha 4d
トラックバック:在线阅读
トラックバック:lawyer istanbul
トラックバック:網上免費的東西
トラックバック:スロットログイン
トラックバック:прочетете повече информация
トラックバック:在網上找到這個免費的東西
トラックバック:leia isso de graça
トラックバック:在线免费选择这个
トラックバック:elige esto gratis en línea
トラックバック:স্লট অনলাইন
トラックバック:무료 온라인 가입
トラックバック:grátis para se juntar online
トラックバック:weitere Informationen lesen
トラックバック:قراءة موضوع شائع
トラックバック:lesen Sie dies kostenlos
トラックバック:이 정보를 따르십시오
トラックバック:volg deze informatie
トラックバック:打开我
トラックバック:pg slot RatuSlot777
トラックバック:coin master slot RatuSlot777
トラックバック:judi slot deposit pulsa BandarXL
トラックバック:كيف تربح الفتحة
トラックバック:thầu nhân công xây dựng
トラックバック:игровой автомат
トラックバック:прочетете това безплатно
トラックバック:tư vấn xây dựng nhà
トラックバック:Lees verder
トラックバック:thi công xây nhà
トラックバック:날 읽어줘
トラックバック:vind deze gratis dingen online
トラックバック:obtenir ce truc en ligne
トラックバック:lese das kostenlos
トラックバック:apportez ceci gratuitement en ligne
トラックバック:deposit pulsa tanpa potongan slot CikaSlotGacorDepositDana
トラックバック:thiết kế nhà cấp 4 mái thái
トラックバック:स्लॉट ऑनलाइन
トラックバック:فتحة تسجيل الدخول
トラックバック:স্লট গেম
トラックバック:如何赢得老虎机
トラックバック:કેવી રીતે સ્લોટ જીતી
トラックバック:スロットを再生します
トラックバック:բնիկ մուտք
トラックバック:слот игри
トラックバック:ਸਲਾਟ ਲਾਗਇਨ
トラックバック:гуляць у слот
トラックバック:ਇਸ ਮੁਫਤ ਸਮੱਗਰੀ ਨੂੰ ਔਨਲਾਈਨ ਲੱਭੋ
トラックバック:se procurer plus d’information
トラックバック:buy power likes for instagram
トラックバック:প্রবণতা বিষয় পড়ুন
トラックバック:bu bilgiyi takip et
トラックバック:स्लॉट कैसे जीतें
トラックバック:continuer la lecture
トラックバック:if you like and unlike a picture on instagram
トラックバック:безплатен слот
トラックバック:स्लॉट मनी
トラックバック:नि: शुल्क स्लॉट
トラックバック:прочетете актуална тема
トラックバック:дэлгэрэнгүй мэдээлэл авах
トラックバック:この情報に従ってください
トラックバック:makakuha ng karagdagang detalye
トラックバック:https://www.youtube.com/redirect?q=trendingsimple.com&gl=MK
トラックバック:อ่านต่อไป
トラックバック:اقرأ هذا مجانًا
トラックバック:Puffco Peak
トラックバック:nastavi čitati
トラックバック:източник на информация
トラックバック:더 많은 정보를 읽어보세요
トラックバック:daha fazla bilgi al
トラックバック:følge disse oplysninger
トラックバック:encontre isso on-line
トラックバック:saznajte više detalja
トラックバック:прачытаць больш інфармацыі
トラックバック:获取更多信息
トラックバック:자세히 알아보기
トラックバック:थप जानकारी पढ्नुहोस्
トラックバック:अधिक जानकारी पढ़ें
トラックバック:lees meer details
トラックバック:Weiterlesen
トラックバック:сачыце за гэтым у Інтэрнэце
トラックバック:få flere detaljer
トラックバック:krijg dit spul online
トラックバック:ابحث عن هذه الأشياء المجانية عبر الإنترنت
トラックバック:çevrimiçi katılmak için ücretsiz
トラックバック:theo dõi trực tuyến này
トラックバック:bunu ücretsiz çevrimiçi hale getir
トラックバック:leggi questo gratis
トラックバック:bu ücretsiz çevrimiçi seç
トラックバック:bu şeyleri internetten al
トラックバック:kostenlos online beitreten
トラックバック:đọc cái này trực tuyến
トラックバック:الحصول على هذه الأشياء على الإنترنت
トラックバック:miễn phí tham gia trực tuyến
トラックバック:bu ücretsiz şeyleri çevrimiçi bul
トラックバック:breng dit gratis online
トラックバック:이 무료 온라인 가져오기
トラックバック:choisissez ceci gratuitement en ligne
トラックバック:đọc cái này miễn phí
トラックバック:kies dit gratis online
トラックバック:tải nội dung này trực tuyến
トラックバック:اتبع هذا على الإنترنت
トラックバック:أشياء مجانية على الإنترنت
トラックバック:이 무료 물건을 온라인에서 찾으십시오
トラックバック:volg dit online
トラックバック:اقرأ هذا على الإنترنت
トラックバック:folge dem online
トラックバック:قم بإحضار هذا مجانًا عبر الإنترنت
トラックバック:kostenlose Sachen online
トラックバック:wähle das kostenlos online aus
トラックバック:lies das online
トラックバック:이 무료 온라인 선택
トラックバック:이것을 온라인으로 읽으십시오
トラックバック:bring das kostenlos online
トラックバック:Holen Sie sich das Zeug online
トラックバック:tìm nội dung miễn phí này trực tuyến
トラックバック:이것을 무료로 읽으십시오
トラックバック:suivez ceci en ligne
トラックバック:bunu çevrimiçi takip et
トラックバック:portalo online gratis
トラックバック:トレンドトピックを読む
トラックバック:مجاني للانضمام عبر الإنترنت
トラックバック:gratis om online mee te doen
トラックバック:আমাকে খুলুন
トラックバック:продолжить чтение
トラックバック:lees dit gratis
トラックバック:jasa seo instagram
トラックバック:дістань мене
トラックバック:jasa view 4000 jam youtube
トラックバック:यह सामान ऑनलाइन प्राप्त करें
トラックバック:यह सामान ऑनलाइन चुनें
トラックバック:jasa view youtube
トラックバック:jual view youtube
トラックバック:beli jam tayang youtube
トラックバック:beli backlink
トラックバック:jasa seo judi
トラックバック:beli 4000 jam tayang
トラックバック:jual jam tayang youtube
トラックバック:온라인에서 이 물건을 찾으세요
トラックバック:beli impressions instagram
トラックバック:jasa seo
トラックバック:jasa subscriber youtube
トラックバック:Врятуй мене
トラックバック:pragmatic play
トラックバック:WismaBet
トラックバック:slot deposit pulsa tanpa potongan
トラックバック:bola99 slot
トラックバック:Daftar Slot
トラックバック:намайг хайрла
トラックバック:daftar slot online
トラックバック:judi slot
トラックバック:arya slot
トラックバック:Αγάπα με
トラックバック:Kelas 4D
トラックバック:beli stream spotify
トラックバック:Wisma338.com
トラックバック:leggilo online
トラックバック:slot deposit pulsa WismaBet
トラックバック:beli like tiktok pake pulsa
トラックバック:jual listener spotify
トラックバック:beli followers pinterest
トラックバック:resiko beli followers tiktok
トラックバック:rtp slot tertinggi hari ini
トラックバック:bocoran rtp slot hoki99
トラックバック:сачыце за гэтай інфармацыяй
トラックバック:rtp hoki99 slot
トラックバック:beli followers spotify
トラックバック:slot depo pulsa WismaBet
トラックバック:beli viewers tiktok murah
トラックバック:Hoki99 login
トラックバック:slot joker WismaBet
トラックバック:крыніца інфармацыі
トラックバック:slot joker deposit pulsa 5000 tanpa potongan WismaBet
トラックバック:togel 178 login
トラックバック:togel178 link alternatif
トラックバック:Jasa Backlink Authority
トラックバック:Jasa Backlink Murah
トラックバック:Jasa followers instagram
トラックバック:jual followers instagram murah
トラックバック:Jasa Backlink PBN
トラックバック:beli like instagram permanen
トラックバック:seo slot
トラックバック:jual follower instagram tertarget
トラックバック:jasa 4000 jam tayang
トラックバック:ahli seo judi
トラックバック:jasa follower tiktok
トラックバック:situs judi bola terpercaya
トラックバック:demo slot pragmatic maxwin
トラックバック:diigo.com/0d3gm6
トラックバック:situs slot gacor 2022 terbaru
トラックバック:www.evernote.com/shard/s535/sh/e9119433-6c34-4814-80e7-f950368d27a2/798cb87800c850849d989c87b53f547f
トラックバック:www.linkedin.com/feed/update/urn:li:activity:6457430107287060480/
トラックバック:pin.it/tzv7zlgiwj6jvz
トラックバック:beli viewers youtube
トラックバック:ccm.net/profile/user/jumpweasel54
トラックバック:qa.pandora-2.com/index.php?qa=user&qa_1=baitfather9
トラックバック:repo.getmonero.org/pushfather7
トラックバック:intensedebate.com/people/newscoat92
トラックバック:Maglia Norway Mondiali 2022
トラックバック:Twicsy
トラックバック:https://twicsy.com/es
トラックバック:twicsy.com
トラックバック:https://twicsy.com/id/beli-pengikut-instagram
トラックバック:https://twicsy.com/tr/instagram-begeni-satin-al
トラックバック:https://twicsy.com/ar/buy-instagram-followers
トラックバック:https://twicsy.com/uk/kupuyte-pidpysnykiv-v-instagram
トラックバック:Instagram
トラックバック:https://twicsy.com/it/acquista-likes-instagram
トラックバック:https://twicsy.com/pt
トラックバック:https://twicsy.com/ko
トラックバック:https://twicsy.com/nl
トラックバック:https://twicsy.com/it/acquista-follower-instagram
トラックバック:https://twicsy.com
トラックバック:https://twicsy.com/nl/instagram-followers-kopen
トラックバック:https://twicsy.com/de
トラックバック:https://twicsy.com/no/kjop-instagram-folgere
トラックバック:https://twicsy.com/fr/acheter-instagram-likes
トラックバック:https://twicsy.com/ko/buy-instagram-followers
トラックバック:joki view youtube
トラックバック:https://twicsy.com/buy-instagram-followers
トラックバック:https://twicsy.com/tl/buy-instagram-followers
トラックバック:https://twicsy.com/tl/buy-instagram-likes
トラックバック:https://twicsy.com/id/beli-like-instagram
トラックバック:toto88 win
トラックバック:Bagaimana sistem view di YouTube
トラックバック:jasa views youtube
トラックバック:Bagaimana perhitungan view di youtube
トラックバック:royal toto88
トラックバック:beli viewers youtube murah
トラックバック:toto 88 casino
トラックバック:https://twicsy.com/nl/instagram-likes-kopen
トラックバック:Apakah Jasaview Aman
トラックバック:kriper.net/user/cicadacup2/
トラックバック:मुझे पकड़ो
トラックバック:spbo asia
トラックバック:agen slot pragmatic play
トラックバック:mattress
トラックバック:heated mattress pad
トラックバック:mattress pad
トラックバック:Jasa Backlink Profile
トラックバック:seuraa näitä tietoja
トラックバック:https://gothammag.com/buy-tiktok-followers
トラックバック:Quick Fix New Orleans
トラックバック:jasa marketing judi
トラックバック:атрымаць больш інфармацыі
トラックバック:получите повече информация
トラックバック:читать подробнее
トラックバック:toto 88 togel
トラックバック:toto88slot login
トラックバック:toto88 rtp
トラックバック:знайсці гэта ў Інтэрнэце
トラックバック:wismaplay
トラックバック:toto88 live
トラックバック:apk toto88
トラックバック:rogslot link alternatif
トラックバック:詳細を取得する
トラックバック:rtp gtc
トラックバック:toto88 dana
トラックバック:hoc legere online
トラックバック:get more detail
トラックバック:получить более подробную информацию
トラックバック:виберіть цей матеріал онлайн
トラックバック:над шиг
トラックバック:在網上找到這個東西 在线获取这些东西
トラックバック:このようなものをオンラインにする
トラックバック:lue tämä netistä
トラックバック:kratom
トラックバック:homepage
トラックバック:fish
トラックバック:fish care
トラックバック:免费阅读
トラックバック:これをオンラインで読む
トラックバック:このようなものをオンラインで見つける
トラックバック:더 많은 정보를 읽으십시오
トラックバック:تجد هذه الأشياء على الإنترنت
トラックバック:ücretsiz çevrimiçi şeyler
トラックバック:công cụ miễn phí trực tuyến
トラックバック:Saudi Arabien VM 2022 Landsholdstrøje
トラックバック:postupujte podle těchto informací
トラックバック:Fuente de información
トラックバック:ойын ұясы
トラックバック:finde disse ting på nettet
トラックバック:ottenere maggiori informazioni
トラックバック:kies dit spul online
トラックバック:pg slot
トラックバック:jam gacor slot
トラックバック:sigue estas cosas en línea
トラックバック:dewa89 slot
トラックバック:slot 4d deposit pulsa tanpa potongan
トラックバック:situs judi slot gacor
トラックバック:үүнийг үнэгүй унш
トラックバック:coisas grátis online
トラックバック:leggi maggiori informazioni
トラックバック:Lieb mich
トラックバック:seuraa minua
トラックバック:w3 jitu toto login
トラックバック:Login Ahha4d
トラックバック:jitukita slot
トラックバック:vegas jitutoto
トラックバック:jitu toto login
トラックバック:akun toto jitu
トラックバック:jituangka toto login wap
トラックバック:bocoran ahha4d
トラックバック:legenda buaya apk tembak ikan
トラックバック:cholemellowlunchroom.e
トラックバック:rtp live
トラックバック:bocoran slot gacor hari ini
トラックバック:slot gacor deposit pulsa tanpa potongan
トラックバック:game slot deposit pulsa 10rb tanpa potongan
トラックバック:pročitajte više detalja
トラックバック:přečtěte si tyto věci online
トラックバック:gacor slot
トラックバック:situs judi slot terbaik dan terpercaya no 1
トラックバック:segui questo in linea
トラックバック:situs slot deposit pulsa tanpa potongan
トラックバック:få flere oplysninger
トラックバック:bursa judi bola
トラックバック:dunia slot 77
トラックバック:togel hari ini hongkong
トラックバック:leggi questo in linea
トラックバック:احصل على مزيد من التفاصيل
トラックバック:dunia 777 slot gacor
トラックバック:slot gacor malam ini
トラックバック:judi bola resmi
トラックバック:soundcloud downloader chrome extension
トラックバック:Ahha4d Login
トラックバック:slot pulsa tanpa potongan
トラックバック:Ahha4d
トラックバック:{Link Login Alternatif Ahha4d}
トラックバック:Ahha4d Link Login Alternatif
トラックバック:demo slot anti lag
トラックバック:info slot gacor hari ini
トラックバック:Ahha4d Link Alternatif
トラックバック:Ahha4d Login Link Alternatif
トラックバック:to buy instagram followers
トラックバック:buy tiktok followers scotland
トラックバック:безплатни неща онлайн
トラックバック:twicsy review
トラックバック:slot demo pragmatic play
トラックバック:безплатно за присъединяване
トラックバック:situs judi bola resmi di indonesia
トラックバック:accutane 5mg
トラックバック:slot rtp tertinggi hari ini
トラックバック:slot demo gratis pragmatic play no deposit
トラックバック:informatiebron
トラックバック:buy monthly instagram followers
トラックバック:jasa seo judi online
トラックバック:buy instagram real followers cheap
トラックバック:beli viewer youtube
トラックバック:{Link Alternatif Ahha4d}
トラックバック:instagram likes 25
トラックバック:jasa profile backlink
トラックバック:giúp tôi
トラックバック:{Link Ahha4d}
トラックバック:jasa seo website judi
トラックバック:jasa backlink premium
トラックバック:jasa backlink natural
トラックバック:http://bbs.1001860.com/home.php?mod=space&uid=1102226
トラックバック:http://www.aipeople.com.cn/home.php?mod=space&uid=2429409
トラックバック:jasa backlink gsa
トラックバック:jasa pbn judi
トラックバック:plaquenil 200mg price
トラックバック:how to buy tiktok followers reddit
トラックバック:seo backlink profile
トラックバック:pbn judi
トラックバック:beli view youtube
トラックバック:lexoni këto gjëra në internet
トラックバック:nepřetržité čtení
トラックバック:jasa like youtube
トラックバック:Google-Trends weltweit
トラックバック:buy instagram followers uk
トラックバック:Інданезійскія трэндавыя тэмы сёння
トラックバック:trending topic instagram hoje
トラックバック:толығырақ мәліметтер алыңыз
トラックバック:Die Teilnahme ist kostenlos
トラックバック:gratis spullen online
トラックバック:slot gacor 338
トラックバック:kilat 138
トラックバック:omnirank
トラックバック:jasa seo jakarta
トラックバック:slot gacor pola zeus maxwin
トラックバック:Wisma bet login judi slot
トラックバック:belajar seo
トラックバック:depo 10 bonus 15k slot mpo
トラックバック:kelas4d
トラックバック:atrodiet šīs lietas tiešsaistē
トラックバック:ਇੰਟਰਨੈੱਟ ‘ਤੇ ਪ੍ਰਚਲਿਤ ਖ਼ਬਰਾਂ
トラックバック:موضوع شائع instagram اليوم
トラックバック:برترین جستجوهای گوگل امروز
トラックバック:wismabet slot
トラックバック:Gila 4D
トラックバック:olympus zeus slot
トラックバック:petir zeus slot
トラックバック:keluaran semua togel hari ini
トラックバック:slot bola 338
トラックバック:kebunslot
トラックバック:pusat4d
トラックバック:jackpot 338slot
トラックバック:buyspin123
トラックバック:alfabet slot freebet
トラックバック:KebunToto
トラックバック:slot zeus gacor
トラックバック:slot zeus olympus
トラックバック:trouver ce truc en ligne
トラックバック:slot demo zeus
トラックバック:jackpot slot zeus
トラックバック:{link slot zeus}
トラックバック:raja zeus slot
トラックバック:бесперапыннае чытанне
トラックバック:επιλέξτε αυτό το υλικό στο διαδίκτυο
トラックバック:slot zeus
トラックバック:Која е темата во тренд на социјалните мрежи?
トラックバック:pročitajte ovo na mreži
トラックバック:zeus 8m
トラックバック:গুগল ট্রেন্ডস ইউটিউব
トラックバック:trending ngayon
トラックバック:přečtěte si další podrobnosti
トラックバック:sada u trendu
トラックバック:nabavite ove stvari na mreži
トラックバック:在線關注這個東西
トラックバック:Өнөөдөр Индонезийн тренд болсон твиттер
トラックバック:jaunākās ziņas šodien
トラックバック:horúce google trendy
トラックバック:प्रचलित विषयहरू पढ्नुहोस्
トラックバック:urutan game god of war
トラックバック:388hero link alternatif
トラックバック:citeste mai multe informatii
トラックバック:slot kakek zeus
トラックバック:bästa Google-sökningarna idag
トラックバック:горячие тренды гугла
トラックバック:pw togel
トラックバック:најдете го ова на интернет
トラックバック:ahha4d slot login
トラックバック:thehopegg.blogspot.com
トラックバック:zeus slot
トラックバック:zeus slot online
トラックバック:zeus8m
トラックバック:bandarxl
トラックバック:dewa zeus slot
トラックバック:zeus olympus slot
トラックバック:erigo4d
トラックバック:citeste asta online
トラックバック:top 10 Google-zoekopdrachten
トラックバック:verdens nyheder
トラックバック:これをオンラインで読んでください
トラックバック:световни новини
トラックバック:এই সপ্তাহের প্রবণতা বিষয়
トラックバック:Што ў трэндзе ў Інданезіі?
トラックバック:апошнія навіны сёння
トラックバック:He aha nā kumuhana o kēia manawa?
トラックバック:загалоўкі апошніх навін сёння
トラックバック:accutane pill 39 mg
トラックバック:इस सामग्री को ऑनलाइन पढ़ें
トラックバック:nā poʻomanaʻo nūhou
トラックバック:Aké sú aktuálne trendy?
トラックバック:lexoni tema në trend
トラックバック:10 principais pesquisas do Google
トラックバック:عمليات البحث الشائعة اليوم
トラックバック:follow this information
トラックバック:trendovske vijesti u svijetu
トラックバック:titulares de noticias de última hora hoy
トラックバック:dernières nouvelles près de chez moi
トラックバック:brydende nyhedsoverskrifter
トラックバック:ਅੱਜ ਦੀ ਤਾਜ਼ਾ ਖਬਰ
トラックバック:blog link
トラックバック:lettura continua
トラックバック:nā kumuhana i kēia manawa
トラックバック:bbc světové zprávy
トラックバック:Какво е тенденцията в Индонезия?
トラックバック:nouvelles tendances
トラックバック:нийтлэлийн эх сурвалж
トラックバック:kövesse ezt online
トラックバック:হট গুগল প্রবণতা
トラックバック:Was sind die aktuellen Trendthemen?
トラックバック:google trending nieuws
トラックバック:togel malaysia siang
トラックバック:tendances google 2023
トラックバック:situs slot freebet tanpa deposit
トラックバック:heluhelu i kēia ma ka pūnaewele
トラックバック:cara download gates of olympus di android
トラックバック:Google Trends 2023
トラックバック:finden Sie dies online
トラックバック:google-дегі ең жақсы 10 іздеу
トラックバック:freebet 50rb tanpa deposit tanpa syarat
トラックバック:cialis vs sildenafil
トラックバック:google trendy novinky
トラックバック:388hero bonus
トラックバック:Aktuelle Trendthemen auf Twitter
トラックバック:Hvad er et populært emne på sociale medier?
トラックバック:bbc wereldnieuws
トラックバック:인도네시아에서 유행하는 것은 무엇입니까?
トラックバック:look at more info
トラックバック:таких
トラックバック:把這些東西帶到網上
トラックバック:ما هو موضوع شائع على وسائل التواصل الاجتماعي؟
トラックバック:такого типа
トラックバック:najnovije vijesti za danas
トラックバック:Indonesiske trendemner i dag
トラックバック:здесь
トラックバック:папулярныя тэмы на гэтым тыдні
トラックバック:актуална тема в Instagram днес
トラックバック:le 10 migliori ricerche su google
トラックバック:Интернеттегі тамаша заттар
トラックバック:gratis om mee te doen
トラックバック:Wisma bet login app
トラックバック:slot freebet tanpa depo
トラックバック:қосылу тегін
トラックバック:kakak slot
トラックバック:judi slot online jackpot terbesar
トラックバック:slot olympus zeus
トラックバック:slot server thailand super gacor
トラックバック:Holen Sie sich dieses Zeug online
トラックバック:tendencat e google youtube
トラックバック:الأخبار العاجلة اليوم
トラックバック:u trendu danas
トラックバック:skaffa mer information
トラックバック:Kas ir aktuāls temats sociālajos medijos?
トラックバック:Indonesisches Trend-Twitter heute
トラックバック:prenesite ove stvari na internet
トラックバック:zeus slot pragmatic
トラックバック:tiêu đề tin tức bbc hôm nay
トラックバック:요즘 유튜브에서 핫한 주제
トラックバック:wisma 338
トラックバック:få disse ting online
トラックバック:выбрать этот материал онлайн
トラックバック:mayorqq
トラックバック:έκτακτες ειδήσεις σήμερα
トラックバック:актуальна тема instagram сьогодні
トラックバック:heluhelu mau
トラックバック:buyspin
トラックバック:소셜 미디어에서 유행하는 주제는 무엇입니까?
トラックバック:mpo depo 10 bonus 15k slot
トラックバック:garuda138
トラックバック:さらに詳しい情報を得る
トラックバック:tin thịnh hành trên mạng
トラックバック:388hero login
トラックバック:Прочети ме
トラックバック:지금 추세
トラックバック:заголовки последних новостей
トラックバック:BBC világhírek
トラックバック:عناوین اخبار فوری امروز
トラックバック:オンラインでこれを選ぶ
トラックバック:usong balita sa internet
トラックバック:slot gacor hari ini
トラックバック:aktuální témata na youtube dnes
トラックバック:přečtěte si další informace
トラックバック:nouvelles tendances dans le monde
トラックバック:agen toto play
トラックバック:lexim i vazhdueshëm
トラックバック:ਗੂਗਲ ਟ੍ਰੈਂਡਿੰਗ ਖਬਰਾਂ
トラックバック:популярные новости
トラックバック:следвайте това онлайн
トラックバック:Was ist ein Trendthema in den sozialen Medien?
トラックバック:trova questo in rete
トラックバック:order meclizine online cheap
トラックバック:agen togel play
トラックバック:chủ đề thịnh hành instagram hôm nay
トラックバック:Một chủ đề xu hướng trên phương tiện truyền thông xã hội là gì?
トラックバック:энэ зүйлийг онлайнаар сонго
トラックバック:slot deposit qris 5000
トラックバック:rtp bisnis4d
トラックバック:Baik777
トラックバック:기사 출처
トラックバック:bonus88
トラックバック:wwd.com
トラックバック:Mga headline ng bbc news ngayon
トラックバック:актуални новини в интернет
トラックバック:Was ist in Indonesien im Trend?
トラックバック:jasa pbn
トラックバック:вземете тези неща онлайн
トラックバック:مصدر المعلومات
トラックバック:Koja je tema u trendu na društvenim mrežama?
トラックバック:διαβάστε αυτό δωρεάν
トラックバック:jasa backlink judi
トラックバック:Jaké je aktuální téma na sociálních sítích?
トラックバック:udarne vijesti u mojoj blizini
トラックバック:tendances google chaudes
トラックバック:google трендтері 2023
トラックバック:porn
トラックバック:グーグルトレンド、ユーチューブ
トラックバック:бұл заттарды желіге әкеліңіз
トラックバック:beli youtube views
トラックバック:чытаць гэты матэрыял у Інтэрнэце
トラックバック:porn
トラックバック:推特上今天的熱門話題
トラックバック:jasa backlink permanen
トラックバック:child porn
トラックバック:jasa promosi youtube
トラックバック:breaking news i nærheden af mig
トラックバック:porn
トラックバック:trending topics deze week
トラックバック:situs slot deposit qris
トラックバック:backlink pbn
トラックバック:крыніцы інфармацыі
トラックバック:beli viewers instagram
トラックバック:қосымша ақпаратты оқу
トラックバック:cara dapat petir merah olympus
トラックバック:beli youtube view
トラックバック:jual backlink
トラックバック:slot gacor gampang menang
トラックバック:인스타그램 오늘 화제 화제
トラックバック:jasa seo judi terpercaya
トラックバック:child porn
トラックバック:jual followers tiktok
トラックバック:szabad csatlakozni
トラックバック:siendo tendencia ahora
トラックバック:jasa backlink pyramid
トラックバック:папулярныя навіны ў інтэрнэце
トラックバック:jual backlink berkualitas
トラックバック:Bugün dünyada öne çıkan haberler
トラックバック:harga jasa seo
トラックバック:porn
トラックバック:child porn
トラックバック:trendikkäissä nyt twitterissä
トラックバック:CBS nouvelles en direct
トラックバック:nuus vandag
トラックバック:child porn
トラックバック:seo judi
トラックバック:jasa backlink judi online
トラックバック:актуални новини в света
トラックバック:Ко је број 1 у тренду на Гоогле-у?
トラックバック:Top 5 Sportnachrichten auf Englisch für die Schulversammlung
トラックバック:beli pbn
トラックバック:jasa seo murah bergaransi
トラックバック:jasa backlink pbn murah
トラックバック:jual jasa seo
トラックバック:jasa pbn murah
トラックバック:Trendnachrichten
トラックバック:папулярныя пошукавыя запыты сёння
トラックバック:sosyal medya etkileri ile ilgili haber makalesi
トラックバック:Trending nuus in die wêreld hierdie week
トラックバック:sosiale media vandag
トラックバック:youtube сёння папулярны ва ўсім свеце
トラックバック:Nangungunang 5 balita sa palakasan sa ingles para sa pagpupulong ng paaralan
トラックバック:popularna pretraživanja danas
トラックバック:trending nuus Indonesië
トラックバック:child porn
トラックバック:ʻO ka nūhou haʻuki ola i kēia lā
トラックバック:Google에서 인기 1위는 누구인가요?
トラックバック:Canlı xəbər axını pulsuz youtube
トラックバック:Wie staat momenteel op nummer 1 op YouTube?
トラックバック:жывыя навіны Фокс
トラックバック:Ким Google’да №1 трендде?
トラックバック:Jetzt im Trend: Google
トラックバック:trendovske vijesti na društvenim mrežama
トラックバック:http://Www.Zjxsnj.cn/comment/html/?27669.html
トラックバック:врвни трендовски вести на социјалните мрежи
トラックバック:tauPI.ORg
トラックバック:https://Rnma.Xyz/boinc/view_profile.php?Userid=1412057
トラックバック:международные спортивные новости сегодня
トラックバック:https://Nebenwelten.net/index.php?title=User:AlyceNona587
トラックバック:Top 5 sportskih vijesti na engleskom za školsku skupštinu
トラックバック:https://biowiki.clinomics.com/index.php/User:KennyEdman7611
トラックバック:http://Classicalmusicmp3freedownload.com/ja/index.php?title=:SusanaBojorquez
トラックバック:Wiki.freeneuropathology.org
トラックバック:Во тренд вести на интернет оваа недела
トラックバック:Bramptoneast.Org
トラックバック:please click the following post
トラックバック:Sky Sports futebol ao vivo
トラックバック:http://www.gedankengut.One/index.php?title=user:Rachelmbx73817
トラックバック:학교 조회를 위한 영어 상위 5개 스포츠 뉴스
トラックバック:Http://Www.Sxlopw.Cn
トラックバック:http://eldoradofus.free.fr/forum/profile.php?id=174374
トラックバック:https://Lnx.Argonband.it/web/modules.php?name=Forums&file=profile&mode=viewprofile&u=84080
トラックバック:wEAkfAntASy.De
トラックバック:https://nebenwelten.net/index.php?title=User:SerenaFolk671
トラックバック:https://wiki.Nerdbird.media/index.php?title=User:RosemarieSolano
トラックバック:forum.Inos.At
トラックバック:Leonblog.Net
トラックバック:https://wiki.sports-5.ch/index.php?title=Utilisateur:RosalinePollack
トラックバック:https://wiki.sports-5.ch/index.php?title=Utilisateur:LeandroGreenwald
トラックバック:trending op internet vandaag
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1422864
トラックバック:https://wiki.Nerdbird.media/index.php?title=Determinacin_Del_Origen_Y_Valoracin_Del_Dao_Corporal
トラックバック:noticias de actualidad en el mundo
トラックバック:just click the up coming page
トラックバック:https://Okniga.org/user/VinceKoertig857/
トラックバック:https://Okniga.org/user/MindaLyke6/
トラックバック:https://wiki.castaways.com/wiki/User:KazukoYagan37
トラックバック:click through the next website page
トラックバック:BgMCd.cO.uK
トラックバック:Www.vANDer-HoRST.nl
トラックバック:Successionwiki.Co.Uk
トラックバック:Wiki.sports-5.ch
トラックバック:https://Yoga.wiki/index.php?title=User:RachelO62157401
トラックバック:visit the following web page
トラックバック:https://wiki.tentere.net/index.php?title=:LolaGrosse806
トラックバック:gewilde nuus op Twitter
トラックバック:https://Wiki.tentere.net/index.php?title=Ecotrap_Fly_Guard:_Control_Ecolgico_De_Moscas_En_M_xico
トラックバック:https://forum.inos.at/profile.php?id=315571
トラックバック:click the following internet page
トラックバック:https://Pipewiki.org/app/index.php/Logistique_Transport_Par_Les_Voitures__Montr_al
トラックバック:live nyhedsræv
トラックバック:Gedankengut.one
トラックバック:maga.wiki
トラックバック:biowiki.ClInoMICS.com
トラックバック:Tin tức hot trên mạng xã hội tuần này
トラックバック:Https://Www.Vander-Horst.Nl/
トラックバック:https://Infodin.Com.br/
トラックバック:Saju.codeway.kr
トラックバック:Página de Internet Altamente recomendada
トラックバック:Pipewiki.org
トラックバック:just click the following website
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=319317
トラックバック:hvad der sker med sociale medier i dag
トラックバック:https://classifieds.ocala-news.com/author/evelynewein
トラックバック:Vacayphilippines.com
トラックバック:https://okniga.org/
トラックバック:https://www.vander-horst.nl/wiki/User:EvelynHardey5
トラックバック:KIng.Az
トラックバック:Yhet.fi
トラックバック:https://Pipewiki.org/app/index.php/User:NCZZoila96656
トラックバック:Classicalmusicmp3Freedownload.com
トラックバック:wwW.KEnpOGuY.COM
トラックバック:rnma.xyz
トラックバック:https://Biowiki.Clinomics.com/index.php/User:Chad11H781989
トラックバック:clique na seguinte página web
トラックバック:https://Rxlrealms.com/XTop/index.php?a=stats&u=katia37600486
トラックバック:英語のトップ 5 スポーツ ニュース
トラックバック:esta
トラックバック:simply click the next website
トラックバック:Outhistory.Wwu.edu
トラックバック:http://Theglobalfederation.org/profile.php?id=1984956
トラックバック:wiki.Hstkb.sch.id
トラックバック:https://Taupi.org/index.Php?title=User:KieraPalmquist7
トラックバック:https://Religiopedia.com/index.php/User:MarcLaster
トラックバック:www.security.sbm.pw
トラックバック:bbc xəbərləri
トラックバック:http://superstitionism.com/forum/profile.php?id=366848
トラックバック:sell
トラックバック:https://xdpascal.com/index.php/user:andreacrider639
トラックバック:https://demo.Centreon.com/wiki/index.php?title=User:CerysSpeed951
トラックバック:https://Demo.Centreon.com/
トラックバック:Https://Bgmcd.Co.Uk/Index.Php?Title=User:JadaLehner4023
トラックバック:https://Okniga.org/user/BebeStreeter5/
トラックバック:https://aproblemsquaredwiki.com/User:RandallMendoza
トラックバック:https://Aproblemsquaredwiki.com/User:BryantMaestas7
トラックバック:xdpascal.com
トラックバック:http://Seattlewomenmag.xyz/blogs/viewstory/26584
トラックバック:https://netcallvoip.com/wiki/index.php/User:EpifaniaCuellar
トラックバック:Https://www.vander-horst.nl
トラックバック:Wiki.gem-flash.com
トラックバック:http://Afcantarelle.org
トラックバック:click through the up coming internet page
トラックバック:https://Maga.wiki/index.php/User:MelissaKavanagh
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1424690
トラックバック:https://okniga.org/user/LeviBartels/
トラックバック:zjxsnj.cn
トラックバック:Ко је тренутно број 1 на ИоуТубе-у?
トラックバック:Live sportnieuws eredivisie
トラックバック:Aħbarijiet trending fuq l-internet din il-ġimgħa
トラックバック:wiki.Nerdbird.media
トラックバック:tin tức về internet hôm nay
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1411932
トラックバック:Afcantarelle.org
トラックバック:https://Zvukiknig.cc/user/Theodore51S/
トラックバック:http://Www.Bjkclh.com/comment/html/?187046.html
トラックバック:Www.Mafiascum.Net
トラックバック:Bjkclh.com
トラックバック:http://Www.die-Seite.com/index.php?a=stats&u=maricruzoms
トラックバック:https://Porscheforsale.org/author/isidrobouci/
トラックバック:topp 5 sportnyheter på engelska
トラックバック:https://taupi.org/index.php?title=User:BeatrizLoera525
トラックバック:provaforumsavoia1234.altervista.org
トラックバック:Click on Demo Centreon
トラックバック:https://Dublinohiousa.gov/
トラックバック:click the next website page
トラックバック:http://Www.Gotanproject.net/node/22354135?—————————4154877377168Content-Disposition:form-data;name=titleLapeinturepoxy:Unersolutionrsistanteetrobuste—————————4154877377168Content-Disposition:form-data;name=bodyLaahref=h
トラックバック:Nebenwelten.net
トラックバック:https://portal.virtueliving.org/profile_info.php?ID=32471
トラックバック:http://Cloud-Dev.Mthmn.com/node/179492
トラックバック:great post to read
トラックバック:http://afcantarelle.org/index.php?title=User:DorethaConnolly
トラックバック:Askreader.co.uk
トラックバック:mBsrE.cOm
トラックバック:YOGA.WIKi
トラックバック:Www.oaSiSKORea.NeT
トラックバック:http://Cloud-dev.mthmn.com/node/181410
トラックバック:Luennemann.org
トラックバック:Informação secreta
トラックバック:my company
トラックバック:http://Cloud-Dev.Mthmn.com/node/179473
トラックバック:http://cloud-dev.mthmn.com/node/181511
トラックバック:Top-Trendnachrichten in den sozialen Medien
トラックバック:http://saju.Codeway.kr/index.php/User:KaliKoerstz021
トラックバック:Dnešní trendy na internetu
トラックバック:http://www.gotanproject.net/node/22356431?—————————960416106151Content-Disposition:form-data;name=titlePrixD’uneToitureEn2022Bardeaux,lastomre,Tpo,EpdmEtPlus—————————960416106151Content-Disposition:form-data;name=bodyN
トラックバック:https://aproblemsquaredwiki.com/User:CliffRentoul730
トラックバック:please click the following website
トラックバック:http://Gijangchurch.org/index.php?mid=board_UvBh53&document_srl=163168
トラックバック:Https://Dimension-Gaming.Nl/Profile.Php?Id=46029
トラックバック:Xn–4Kqz9Dx34Awsd.Copytrade.website
トラックバック:http://cloud-dev.mthmn.com/node/180219
トラックバック:http://cloud-dev.mthmn.com/node/178324
トラックバック:Zvukiknig.cc
トラックバック:eldoradofus.free.fr
トラックバック:https://untoldjekyll.com/60085/joanna-maitre–quebec-paris
トラックバック:https://koloiko.com/wiki/index.php?title=User:RaulGreenwood7
トラックバック:Sanatandharam.in
トラックバック:Cloud-dev.mthmn.com
トラックバック:Dripwiki.com
トラックバック:Apeguebremariam.org
トラックバック:Trendy nyheter i verden i dag
トラックバック:Readukrainianbooks.Com
トラックバック:Www.sxlopw.cn
トラックバック:Incardio.Cuas.at
トラックバック:https://Yhet.fi/wiki/index.php/Nos_v_nementsdu_1_Sur_Le_5_Mai_2018
トラックバック:http://www.Driftpedia.com/wiki/index.php/Soins_De_Pieds__Domicile
トラックバック:Canamkart.Ca
トラックバック:www.offwiki.org
トラックバック:Www.fragrance.ipt.pw
トラックバック:Religiopedia.com
トラックバック:diAlOGOS.wIKi
トラックバック:https://Urduwiki.in
トラックバック:NoBElBOErsE.De
トラックバック:www.rEBeLsCON.COm
トラックバック:https://mmhsmassageme.com/index.php?page=user&action=pub_profile&id=5800623
トラックバック:https://napiri.com
トラックバック:PorscHEFORsALE.oRg
トラックバック:More Support
トラックバック:http://cloud-Dev.Mthmn.com/node/173542
トラックバック:Napiri.com
トラックバック:https://Www.vesti24.eu/user/profile/kluverna88/
トラックバック:Demo.Centreon.com
トラックバック:http://cloud-dev.mthmn.com/node/179476
トラックバック:www.traders.sblinks.net
トラックバック:http://Die-Seite.com/index.php?a=stats&u=dalenephelan6
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=323594
トラックバック:Sustainabilipedia.Org
トラックバック:nbc xəbərləri
トラックバック:WWW.reGister.Ipt.Pw
トラックバック:https://telugusaahityam.com/User:RoscoeLenz7136
トラックバック:Wiki.vie.today
トラックバック:https://dialogos.wiki/index.php/L_inspection_D_une_Vieille_Maison_:_10_Aspects__Surveiller
トラックバック:theglobalfederation.org
トラックバック:https://nebenwelten.net/index.php?title=Lancme_Perfume:_Elegance_And_Innovation_In_Every_Bottle
トラックバック:http://Xiamenyoga.com/comment/html/?235232.html
トラックバック:https://www.oasiskorea.net/Brand/3141874
トラックバック:Orlandowomenmag.xyz
トラックバック:https://apeguebremariam.org/community/?wpfs=&membersite=httpspiedconfort.combloguepied-arque&membersignature=span+stylefont-weight:+800;Les+orthses+plantaires+sont/span+span+stylefont-style:+oblique;une+type+de+aide+pour+les/span+orteils+dont+le+b
トラックバック:http://cloud-dev.mthmn.com/Node/177746
トラックバック:Read Even more
トラックバック:https://qna.lrmer.com/index.php?qa=161705&qa_1=lavandera-poblado-medelln-cuidado-excepcional-prendas
トラックバック:Suggested Resource site
トラックバック:http://Www.zilahy.info/wiki/index.php/User:MauraMontero
トラックバック:http://Www.arts-and-entertainment.ipt.pw/News/crystal-dreams-world-9/
トラックバック:her explanation
トラックバック:see this here
トラックバック:www.dictionary.sblinks.net
トラックバック:http://outsourcing.sbm.pw/News/la-bouticaire-29/
トラックバック:https://Matrice.Btsndrc.ac/forum/profile/lounewcomb78095/
トラックバック:https://King.az/user/ChesterBurne/
トラックバック:Onsale.tawansmile.com
トラックバック:https://www.oasiskorea.net/Brand/2479729
トラックバック:https://Demo.Centreon.com/wiki/index.php?title=User:ThaoYup527735
トラックバック:Qzfczs.com
トラックバック:http://cloud-dev.mthmn.com/node/177978
トラックバック:Portal.Virtueliving.org
トラックバック:https://E-Schoolfaso.com/Forums/Users/kaceysaunders46
トラックバック:https://Maga.wiki/index.php/User:AlexandraButters
トラックバック:trendikkäitä uutisia Internetissä
トラックバック:go source
トラックバック:Xiamenyoga.Com
トラックバック:http://startflag.Rulez.jp/index.php/Installation_Par_Collage
トラックバック:Топ 5 на спортните новини на английски днес
トラックバック:http://www.property.sblinks.net/user/soontjanga/
トラックバック:http://Www.trimmers.Ipt.pw/News/physiobalance-47/
トラックバック:http://www.Zjxsnj.cn/comment/html/?53018.html
トラックバック:Wiki.Team-Glisto.Com
トラックバック:https://www.Oasiskorea.net/Brand/3197278
トラックバック:s741690.ha003.t.justns.ru
トラックバック:https://classifieds.ocala-news.com/author/klara315587
トラックバック:https://Trans.Hiragana.jp/ruby/https://illinoisbay.com/user/profile/6125387
トラックバック:http://www.gotanproject.net/node/22354848?—————————4574525541Content-Disposition:form-data;name=titleCrditsansintrtauCanada:Optionsconsidrer—————————4574525541Content-Disposition:form-data;name=bodyLorsquevousrecherchez
トラックバック:WiKI.MoNaSHicpC.COM
トラックバック:Rowan.wiki
トラックバック:Tendencaj novaĵoj en sociaj amaskomunikiloj ĉi-semajne
トラックバック:dimension-gaming.nl
トラックバック:http://Die-Seite.com/index.php?a=stats&u=brianneeav
トラックバック:just click the up coming article
トラックバック:https://Telearchaeology.org/TAWiki/index.php/User:KirkMcLoud
トラックバック:mouse click the following website page
トラックバック:http://Forum.prolifeclinics.ro/profile.php?id=26909
トラックバック:recent Nxlv.ru blog post
トラックバック:More inspiring ideas
トラックバック:read this blog article from Apeguebremariam.org
トラックバック:https://brilliantcollections.com/tumbled-stones/
トラックバック:Https://telugusaahityam.Com/Small_Enterprise_Loans_Canada
トラックバック:Www.Motline.com
トラックバック:MoTliNE.coM
トラックバック:сацыяльныя сеткі сёння
トラックバック:find out here now
トラックバック:https://www.Vander-horst.nl/wiki/Transporte_No_Pblico_De_Pasajeros_Para_Poder_Turismo:_Comodidad_Y_Flexibilidad_En_Tus_Viajes
トラックバック:http://www.Xjykj.cn/comment/html/?364345.html
トラックバック:www.Die-seite.com
トラックバック:https://Wiki.Castaways.com/wiki/User:VeolaWimberly4
トラックバック:read this post from Guidemagazine
トラックバック:Kaidan136.com
トラックバック:Que signifie la tendance actuelle ?
トラックバック:wiki.rl-transport.org
トラックバック:visit site
トラックバック:http://Cloud-Dev.Mthmn.com/node/64637
トラックバック:https://wiki.bigtata.org/index.php/Utilisateur:DaniloStoneman
トラックバック:https://classifieds.ocala-News.com/
トラックバック:Suits.Bookmarking.site
トラックバック:https://wiki.team-glisto.com/index.php?title=Benutzer:UlyssesDcr
トラックバック:article de presse sur les effets des médias sociaux
トラックバック:http://mastas.co.kr/xe/index.php?mid=Construction_VOD&document_srl=963526
トラックバック:https://online-Learning-initiative.org/wiki/index.php/Free_Canadian_Demand_Loan_Settlement
トラックバック:Www.Ascertain.Ipt.pw
トラックバック:https://Adsclassy.com/index.php?page=user&action=pub_profile&id=851
トラックバック:http://wiki.moebius.com.br
トラックバック:https://zvukiknig.cc
トラックバック:https://Xdpascal.com/index.php/User:ShalandaCannan
トラックバック:https://successionwiki.co.uk/index.php/User:FaustoGroce
トラックバック:https://demo.Centreon.com/wiki/index.php?title=User:MariamMcKinnon
トラックバック:mastas.co.kr
トラックバック:https://Religiopedia.com/index.php/Submarines_Sous
トラックバック:https://Wiki.Vie.today/index.php?title=:TereseCavanaugh
トラックバック:https://Xdpascal.com/index.php/User:NadiaHoran4754
トラックバック:https://Mzlgam.com/index.php?action=profile;u=127950
トラックバック:https://Forum.Inos.at/profile.php?id=220837
トラックバック:click through the following website page
トラックバック:https://Www.Oasiskorea.net/Brand/1594413
トラックバック:http://Cloud-Dev.Mthmn.com/
トラックバック:http://gijangchurch.org/
トラックバック:Read More At this website
トラックバック:Mateenbeat.com
トラックバック:http://gijangchurch.org/index.php?mid=board_UvBh53&document_srl=161768
トラックバック:http://www.somangchurch.org/board_DIJb91/520976
トラックバック:http://Wiki.Quanticsystems.Com.br/index.php/Immediate_On-line_Payday_Mortgage_Canada
トラックバック:Hobbyclues.in
トラックバック:https://telearchaeology.org/TAWiki/index.php/User:MasonBitner894
トラックバック:https://aproblemsquaredwiki.com/User:JadaAlp1156
トラックバック:https://Wiki.Unionoframblers.com/index.php/User:BrigitteGrier
トラックバック:https://Vacayphilippines.com/author/kristinehsu/
トラックバック:https://kaidan136.com/index.php?title=No-Hands_Slip-On_Shoes:_Embrace_Convenience_And_Comfort_In_Canada
トラックバック:Https://mbsre.com/forums/users/candidalandis2
トラックバック:http://zjxsnj.cn/comment/html/?59552.html
トラックバック:https://yoga.wiki/index.php?title=Crystal_Properties_Reference_Guide
トラックバック:Www.Statistics.dofollowlinks.org
トラックバック:http://www.Jeromebaray.com/afm/wiki/index.php/Utilisateur:Agnes2759203907
トラックバック:https://Nxlv.ru/user/CharlineGalgano/
トラックバック:http://Classicalmusicmp3Freedownload.com/ja/index.php?title=Cuisines_Verdun
トラックバック:http://Theglobalfederation.Org/
トラックバック:Wiki.castaways.com
トラックバック:http://www.Onlineschool.bookmarking.site/News/zen-valuations-21/
トラックバック:https://Telearchaeology.org/TAWiki/index.php/User:ElmoHodge3
トラックバック:https://www.volker-rau.de/index.php/Benutzer:Woodrow1790
トラックバック:https://apeguebremariam.org/community/?wpfs=&membersite=httpsPiedconfort.combloguemedecin-des-pieds&membersignature=Lorthse+par+les+orteils+et+la+podiatrie+sont+des+domaines+de+la+bien-tre+qui+sont+typiquement+ngligs+mais+qui+peuvent+avoir+un+effe
トラックバック:https://Sanatandharam.in/index.php/User:LeahRenard0800
トラックバック:https://wiki.Itcoug.com/index.php?title=Usuario:LurleneY45
トラックバック:https://Wiki.nerdbird.media/index.php?title=Pruebas_No_Funcionales:_Asegurando_La_Calidad_Ms_All_De_La_Funcionalidad
トラックバック:https://dptotti.fic.edu.uy/mediawiki/index.php/Enqute_De_Cr_dit_En_Ligne_Sur_Le_Canada_:_Tout_Ce_Que_Vous_Devriez_Comprendre
トラックバック:http://zjxsnj.cn/comment/html/?59483.html
トラックバック:just click the following internet site
トラックバック:wiki.gahlawat.Dynu.Com
トラックバック:telearchaeology.Org
トラックバック:https://luxuriousrentz.com/fubuki-brands-quality-boots-for-unparalleled-performance-in-the-canadian-outdoors/
トラックバック:https://nxlv.ru/user/Neva33805726590/
トラックバック:Virus Win 32 said
トラックバック:WWW.cHIlD-HEAlth.BookmARkINg.Site
トラックバック:Click on Weakfantasy
トラックバック:Gamesfashionarchive.net
トラックバック:https://Apeguebremariam.org/community/?wpfs=&membersite=httpsSelectflex.comblogswork-wellnesstaggednurse-safety&membersignature=I+actually+have+had+these+for++a+hrefhttps://Selectflex.com/blogs/work-wellness/tagged/energyreturntechnology+reldofoll
トラックバック:Highly recommended Online site
トラックバック:https://Religiopedia.com/index.php/Prts_Virtuels_Rapides_Et_Faciles
トラックバック:https://mediawiki.governancaegestao.wiki.br/index.php/User:FranchescaDane5
トラックバック:Www.Consulting.sblinks.net
トラックバック:http://Forum.megi.cz//profile.php?id=2808489
トラックバック:http://Www.Die-Seite.com/index.php?a=stats&u=shayneswan
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1411972
トラックバック:https://Pipewiki.org/app/index.php/The_Golden_Goddess
トラックバック:http://wikivicente.x10Host.com/index.php/Usuario:CarloDoyne7794
トラックバック:Www.Recruiterwiki.de
トラックバック:https://Mzlgam.com/index.php?action=profile;u=128834
トラックバック:https://Kenpoguy.com/phasickombatives/profile.php?id=1332356
トラックバック:Www.seasonal.Ipt.pw
トラックバック:Http://Wiki.Monashicpc.Com/User:Brandybender13
トラックバック:https://Wiki.Rr206.de/index.php?title=Benutzer:Carmon09M9305058
トラックバック:https://Www.Wakewiki.de/index.php?title=Benutzer:MargeryDrennen
トラックバック:wiki.renew-Platforms.dk
トラックバック:https://kaidan136.com/index.php?title=:ZPDBrianne
トラックバック:https://Wiki.Renew-Platforms.dk/index.php?title=User:MindaK282131
トラックバック:http://www.synonyms.sbm.pw/out/roi-recreation-outfitters-91/
トラックバック:online-Learning-initiative.org
トラックバック:https://Incardio.Cuas.at/wiki/index.php/User:SebastianShimizu
トラックバック:https://Wiki.Sports-5.ch/index.php?title=Utilisateur:RudyEmbley
トラックバック:http://cloud-Dev.mthmn.com/node/191601
トラックバック:published on annunci.formazionenautilus.it
トラックバック:jeromebaray.com
トラックバック:https://Wiki.Nerdbird.media/index.php?title=User:ScotLind23484857
トラックバック:Www.vesti24.eu
トラックバック:https://Aproblemsquaredwiki.com/Les_Automobiles_Toyota_Et_Lexus_Ont_La_Cote_Des_Voleurs_De_Voiture_Et_Des_Convertisseurs_Catalytiques_Dans_Le_Royaume
トラックバック:Wiki.prologosconsultoresasociados.cl
トラックバック:Telugusaahityam.com
トラックバック:Http://Internet.Webtv.Dk/User/VancePatel1120
トラックバック:http://bramptoneast.org/index.php/User:ArchieConlan
トラックバック:http://Www.Ruanjiaoyang.com/member.asp?action=view&memName=JulietDaplyn5048922
トラックバック:https://virus.win32.wiki/wiki/Clinique_Podiatrique_Fabreville_In_Laval
トラックバック:gijangchurch.org
トラックバック:Backpacks.sblinks.Net
トラックバック:https://Taupi.org
トラックバック:https://illinoisbay.com/user/profile/6126639
トラックバック:http://Hardware.ipt.pw/out/capital-food-services-206/
トラックバック:http://clothing.Businessadvertising.xyz/blogs/viewstory/5260
トラックバック:Gratisafhalen.be
トラックバック:Https://Wiki.Team-Glisto.Com/Index.Php?Title=Benutzer:Kitty54P78957
トラックバック:click the up coming site
トラックバック:https://Bgmcd.Co.uk/index.php?title=User:Marcella6170
トラックバック:https://Biowiki.clinomics.com
トラックバック:click the next internet page
トラックバック:omen-13.De
トラックバック:https://Zvukiknig.cc/user/DPRBrigida/
トラックバック:WWw.UPdATes.sbM.Pw
トラックバック:WwW.wATerBorEFIJi.COm
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=325888
トラックバック:Beautyconceptasia.com
トラックバック:WwW.goTaNpROJeCt.Net
トラックバック:https://Outhistory.Wwu.edu/wiki/User:GusR7041824496
トラックバック:visit my homepage
トラックバック:okNiGA.OrG
トラックバック:https://Wiki.bigtata.org/
トラックバック:https://Wiki.Lafabriquedelalogistique.fr/Utilisateur:LuellaDimarco90
トラックバック:urbino.fh-joanneum.at
トラックバック:http://bjkclh.com/comment/html/?186324.html
トラックバック:Forum.prolifeclinics.ro
トラックバック:https://maga.wiki/index.php/User:SaraMcBrien8
トラックバック:Illinoisbay.com
トラックバック:http://Www.Ruanjiaoyang.com/member.asp?action=view&memName=JonahSlocum82159
トラックバック:Sl860.com
トラックバック:wwW.sl860.COM
トラックバック:http://www.healthcare-industry.Ipt.pw/News/la-bouticaire-3/
トラックバック:Wiki.Psychedelic-Lab.Com
トラックバック:https://98e.fun/home.php?mod=space&uid=6471395&do=profile&from=space
トラックバック:mouse click the following web site
トラックバック:www.Agriculture-And-Forestry.Sblinks.net
トラックバック:Miapedia.Cz
トラックバック:simply click the following webpage
トラックバック:http://Direcar.Co.kr/board_rxWR73/657242
トラックバック:http://www.fantasyroleplay.co/wiki/index.php/Le_Note_Des_300_Suppl_mentaire_Importantes_Pme_Du_Qu_bec_En_2019
トラックバック:http://www.Suits.Bookmarking.site/News/la-bouticaire-97/
トラックバック:wwW.DIgITAL-MArkEtINg.ipt.PW
トラックバック:http://Forum.Prolifeclinics.Ro/
トラックバック:urduwiki.in
トラックバック:http://www.drsbook.co.kr/board/8234250
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=273642
トラックバック:https://yhet.fi/wiki/index.php/User:NinaPenrod46831
トラックバック:http://Www.Attitude.Bookmarking.site/News/la-bouticaire-11/
トラックバック:http://Www.exotic.bookmarking.site/out/capital-food-services-22/
トラックバック:Read Much more
トラックバック:click through the up coming web site
トラックバック:Thedatabite.Com
トラックバック:Check This Out
トラックバック:http://Gijangchurch.org/index.php?mid=board_UvBh53&document_srl=260516
トラックバック:https://Okniga.org/user/WillieWhitworth/
トラックバック:recent Utahsyardsale.com blog post
トラックバック:wWW.S-miLES.cOm
トラックバック:http://Www.zjxsnj.cn/comment/html/?47435.html
トラックバック:Fridayad.in
トラックバック:https://nobelboerse.de/mitglied/karinastein/
トラックバック:Www.Healthcare-Industry.Sblinks.Net
トラックバック:https://vacayphilippines.com/author/mckinleyn56/
トラックバック:www.calsouthchurch.Org
トラックバック:www.zilahy.info
トラックバック:https://okniga.org/user/Ramona66I416477/
トラックバック:http://Www.Die-Seite.com/index.php?a=stats&u=anitraieu8300466
トラックバック:https://wiki.Unionoframblers.com/index.php/User:CyrusHamrick9
トラックバック:visite site
トラックバック:https://Nebenwelten.net/index.php?title=User:JustinaK42
トラックバック:http://Vulteevaliant.com/index.php/User:Leta94Q4500
トラックバック:VolKEr-rau.de
トラックバック:Chadwiki.Org
トラックバック:Www.visualchemy.gallery
トラックバック:onE.neW-Tkf.XyZ
トラックバック:click here for info
トラックバック:Www.Wfkun.com
トラックバック:http://wiki.psychedelic-lab.com/index.php?title=meuble_boucherville
トラックバック:https://Taupi.org/index.php?title=User:ImogeneEap
トラックバック:Recommended Resource site
トラックバック:Https://Www.Wikinawa.Fr/
トラックバック:calsouthchurch.org
トラックバック:Www.Capital.Bookmarking.Site
トラックバック:Https://Illinoisbay.com/
トラックバック:Koloiko.com
トラックバック:please click the up coming post
トラックバック:you can look here
トラックバック:Aproblemsquaredwiki.com
トラックバック:www.Bjkclh.Com
トラックバック:http://cloud-dev.mthmn.com/node/212633
トラックバック:http://Gotanproject.net/node/22375372?—————————9460384556561Content-Disposition:form-data;name=titleActivitsSportives&RvleSoyezL—————————9460384556561Content-Disposition:form-data;name=bodyemLeGalaLesOlivier,enle/em
トラックバック:similar site
トラックバック:https://www.Oasiskorea.net/Brand/1596832
トラックバック:http://Forum.prolifeclinics.ro/profile.php?id=45159
トラックバック:https://www.Dzliprojects.wiki/index.php/User:Noelia0155
トラックバック:http://Mateenbeat.com/index.php/User:RandalTyq38627
トラックバック:Ndd.vc
トラックバック:http://www.Hotels.Sblinks.net/News/la-bouticaire-120/
トラックバック:WIKi.TEntErE.NeT
トラックバック:http://S741690.Ha003.T.Justns.ru/index.php?subaction=userinfo&user=RowenaMacfarlan
トラックバック:writes in the official Sanatandharam.in blog
トラックバック:https://Weakfantasy.de/index.php/Benutzer:ZandraHoyt21471
トラックバック:wiki.Gigaro.Com.br
トラックバック:http://Www.Gotanproject.Net
トラックバック:wonplay888 daftar
トラックバック:Www.christmas.Ipt.pw
トラックバック:http://Cloud-dev.Mthmn.com/node/174308
トラックバック:http://Www.diywiki.org/index.php/User:Maximo25R4
トラックバック:Read Full Report
トラックバック:https://Aproblemsquaredwiki.com/User:TodBorn310
トラックバック:http://xiamenyoga.com/comment/html/?248664.html
トラックバック:http://qzfczs.com/comment/html/?282184.html
トラックバック:https://zvukiknig.cc/user/JensCoffman828/
トラックバック:Www.Jeromebaray.Com
トラックバック:relevant website
トラックバック:https://Dialogos.wiki/index.php/User:Alicia6059
トラックバック:http://Www.Fantasyroleplay.co/wiki/index.php/User:JanessaCraig
トラックバック:c674576n.beget.tech
トラックバック:http://s741690.ha003.T.justns.ru/index.php?subaction=userinfo&user=JuliusVillanueva
トラックバック:https://onsale.Tawansmile.com/index.php?action=profile;u=8810
トラックバック:http://www.Rebelscon.com/profile.php?id=1596868
トラックバック:https://rebelbase.Customwebarchitect.com/groups/poignees-celui-dehors-exterieures-et-accessoires/info/
トラックバック:https://www.Offwiki.org/wiki/User:TerraWilkins48
トラックバック:https://nebenwelten.net/index.php?title=User:LorenEklund
トラックバック:click through the up coming post
トラックバック:raleighwomenmag.xyz
トラックバック:pOpoFfmuSIC.CoM
トラックバック:https://wiki.bigtata.org/index.php/5_Id_Es_Pour_Une_Salle_De_Bain_Tendance
トラックバック:www.Morphonic-records.com
トラックバック:http://Wikivicente.X10Host.com/index.php/Usuario:HermineMcKinley
トラックバック:Modernbookmarks.com
トラックバック:https://listingpanda.ca/author/julianapti/
トラックバック:https://Topsearch24H.com/search/Peintre+Professionnel+Rsidentiel+Industriel+A+Laval+Rive
トラックバック:http://Www.gedankengut.one/index.php?title=User:Thorsten64E
トラックバック:https://www.Mafiascum.net/social-games/game-20190906/index.php?action=profile;u=309464
トラックバック:https://Dripwiki.com/index.php/User:IsidroBeardsley
トラックバック:https://wiki.rr206.de/index.php?title=Benutzer:MatthiasCoffey6
トラックバック:http://wiki.monashicpc.com/User:BarryStuder796
トラックバック:https://wiki.nerdbird.media/index.php?title=User:TillyMackinolty
トラックバック:recommended site
トラックバック:https://wiki.sports-5.ch/index.php?title=Utilisateur:Merry16U867
トラックバック:https://readukrainianbooks.com/user/HamishWaid/
トラックバック:https://omnias.wiki/index.php/User:KareemDarker2
トラックバック:https://iamelf.com/wiki/index.php/User:HaroldBartlett
トラックバック:Utahsyardsale.com
トラックバック:Https://Dialogos.Wiki/Index.Php/User:Kina21J7319884
トラックバック:click through the up coming page
トラックバック:https://Outhistory.wwu.edu/wiki/Drafting_Rate_Of_Interest_Calculation_Provisions_In_Company_Finance_Transactions
トラックバック:http://www.zilahy.info/wiki/index.php/Understanding_The_Risks_Of_A_Personal_Loan
トラックバック:https://plaza.konchangfuns.com/index.php?action=profile;u=10496
トラックバック:Recommended Internet site
トラックバック:https://deadreckoninggame.com/index.php/User:OpheliaEpstein4
トラックバック:please click the next web page
トラックバック:http://www.real-estate.Dofollowlinks.org/News/lave-toutou-8/
トラックバック:Www.Indopariwara.com
トラックバック:http://Cloud-Dev.Mthmn.com/node/187888
トラックバック:https://Wiki.Freeneuropathology.org/index.php?title=Bote_D_entreposage_Par_Garde
トラックバック:https://zvukiknig.cc/user/IraBrinkley1/
トラックバック:https://moravian.bucknell.edu/transcriptions/index.php?title=User:SoniaRitchey62
トラックバック:https://trabalhadoresindependentes.com/author/rolandoheck/
トラックバック:https://taupi.org/index.php?title=User:GuadalupeCruce4
トラックバック:click the following web page
トラックバック:https://onsale.tawansmile.com/index.php?action=profile;u=8323
トラックバック:https://Weakfantasy.de/index.php/Benutzer:MaximoNesbitt2
トラックバック:click the following article
トラックバック:98E.fun
トラックバック:https://wiki.gigaro.com.br/index.php/User:DKNDerick374
トラックバック:https://napiri.com/design_works/281291
トラックバック:E-SchoOlFAso.coM
トラックバック:http://Wiki.quanticsystems.com.br/index.php/User:Emile512714662
トラックバック:perguntaspoderosas.blog.Br
トラックバック:https://Onsale.Tawansmile.com/index.php?action=profile;u=8819
トラックバック:http://www.somangchurch.org/board_DIJb91/517622
トラックバック:https://maga.wiki/index.php/Dr_David_S_Mulder
トラックバック:http://www.agriculture-and-Forestry.sblinks.net
トラックバック:https://Apeguebremariam.org/community/?wpfs=&membersite=httpsWww.hesmangarage.compostl-alignement-des-roues&membersignature=img+srchttps://picography.co/page/1/600+width450+stylemax-width:450px;max-width:420px;float:right;padding:10px+0px+10px+10p
トラックバック:http://forum.Prolifeclinics.ro/profile.php?id=83011
トラックバック:http://capital.bookmarking.site/News/freaky-socks-30/
トラックバック:Https://Listingpanda.Ca/Author/Cortneystan
トラックバック:Http://Luennemann.Org/
トラックバック:Www.zjxsnj.cn
トラックバック:https://Www.vesti24.eu/user/profile/clarkwhitf/
トラックバック:Dptotti.Fic.Edu.Uy
トラックバック:https://Calsouthchurch.org/board_Txxk18/1514334
トラックバック:https://Kaidan136.com/index.php?title=:MarvinLenihan
トラックバック:https://chadwiki.org/index.php/R_novation_Des_Toilettes_Sherbrooke_Magog
トラックバック:Wikivicente.X10Host.com
トラックバック:https://www.recruiterwiki.de/Benutzer:Rene603241767746
トラックバック:Aaahe.com
トラックバック:https://yoga.wiki/index.php?title=User:HeribertoYin
トラックバック:https://readukrainianbooks.com
トラックバック:http://Wiki.rl-transport.org/index.php/User:JoanneDoolette
トラックバック:cONNEctNGrOw.oRG
トラックバック:https://Trans.Hiragana.jp/ruby/http://cloud-dev.mthmn.com/node/198854
トラックバック:https://zvukiknig.cc/user/JoycelynVonwille/
トラックバック:www.mtmoa02.Net
トラックバック:jasa backlink terbaik
トラックバック:visit my home page
トラックバック:This Internet site
トラックバック:https://luxuriousrentz.com/650-salles-de-bain-ideas-in-2022/
トラックバック:https://Dptotti.fic.edu.uy/mediawiki/index.php/usuario:shanabrophy4
トラックバック:https://Luxuriousrentz.com/avoir-une-soumission-par-fabrication-darmoires/
トラックバック:Https://Wiki.Castaways.Com/Wiki/User:XavierGoward87
トラックバック:Trimmers.ipt.pw
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1221118
トラックバック:http://canamkart.ca/index.php?page=user&action=pub_profile&id=1519706
トラックバック:about his
トラックバック:http://www.child-Health.sblinks.net/News/freaky-socks-12/
トラックバック:superstitionism.Com
トラックバック:Obengdarko.Com.Gh
トラックバック:https://apeguebremariam.org/community/?wpfs=&membersite=httpsEtrema.caendust-masks&membersignature=Le+port+du+masques+de+procdure+est+obligatoire+en+tout+a+temps+par+toutes+les+gens+de+10+ans+et+supplmentaire.pnbsp;/ppnbsp;/p+span+stylefont-style:
トラックバック:www.Legal-information.Sblinks.net
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1214786
トラックバック:https://biconsultingpro.com/baignoire-spa-et-massage-therapeutique-durant-la-etre-enceinte/
トラックバック:Virus.Win32.wiki
トラックバック:http://Cloud-dev.mthmn.com/node/186910
トラックバック:https://luxuriousrentz.com/vinateria-en-queretaro-descubre-una-seleccion-exquisita-de-vinos/
トラックバック:https://www.wakewiki.de/index.php?title=benutzer:lawrencemeudell
トラックバック:http://Www.Bjkclh.com/comment/html/?118099.html
トラックバック:www.loAfeRs.SBLINks.Net
トラックバック:Www.Photography.Ipt.Pw
トラックバック:http://caulove.Com/?document_Srl=569557
トラックバック:https://King.az/user/Ted82R123910519/
トラックバック:https://okniga.org/user/TamikaDang5/
トラックバック:Trans.hiragana.jp
トラックバック:https://mbsre.com/forums/users/monagij791773/
トラックバック:https://urduwiki.in/index.php/User:JessieShirk75
トラックバック:http://www.gedankengut.one/index.php?title=User:OlenNoble55340
トラックバック:click here to find out more
トラックバック:Nxlv.Ru
トラックバック:https://ladder2leader.com/el-sol-azul-de-l-a-laguna-de-san-ignacio-un-fenomeno-natural-asombroso/
トラックバック:http://Www.Rainbow.Bookmarking.site/News/clinica-maxi-dental-27/
トラックバック:Www.Drsbook.co.kr
トラックバック:http://www.e-tracking-system.bookmarking.site/News/armo-design-36/
トラックバック:https://isotrope.cloud/index.php/User:YvetteMonaco
トラックバック:digital-marketing.ipt.Pw
トラックバック:KiRKESIMportS.cOm
トラックバック:http://rebelscon.com/profile.php?id=1601805
トラックバック:http://Beautyconceptasia.com/faq/1240849
トラックバック:http://www.rebelscon.com/profile.php?id=1603937
トラックバック:http://canamkart.ca/Index.php?page=user&action=pub_profile&id=1483361
トラックバック:Isotrope.cloud
トラックバック:mouse click the up coming website page
トラックバック:wwW.OUTsoURciNg.SbM.pw
トラックバック:Http://Www.Drsbook.Co.Kr/Board/8617695
トラックバック:http://eldoradofus.Free.fr/forum/profile.php?id=190852
トラックバック:Https://Virus.Win32.Wiki/
トラックバック:https://online-learning-initiative.org/wiki/index.php/User:TommieDozier
トラックバック:https://www.Checkmygigs.com/community/?wpfs=&membersite=httpsGreensqa.comcontinuous-business-monitoring&membersignature=img+srchttps://yewtu.be/-kFzyn7-SEs+width450+stylemax-width:450px;max-width:400px;float:right;padding:10px+0px+10px+10px;border
トラックバック:http://Direcar.Co.kr/?document_srl=769122
トラックバック:http://Www.capital.Bookmarking.site/user/byronmarks/
トラックバック:http://gotanproject.net/node/22379768?—————————48482186876414Content-Disposition:form-data;name=titleDomaineDeGeorgeSandWikipdia—————————48482186876414Content-Disposition:form-data;name=bodyEtquecelesdeuxounondormirsans
トラックバック:Highly recommended Site
トラックバック:http://cloud-dev.mthmn.com/node/193581
トラックバック:https://wiki.Fukuoka-denshi-kousaku.club/index.php?title=:LavadaLeary9618
トラックバック:http://Www.customer-service.sblinks.Net
トラックバック:http://Www.weather.Sbm.pw/News/la-bouticaire-13/
トラックバック:Magnumgam.Co.kr
トラックバック:visit these guys
トラックバック:http://Www.sxlopw.cn/
トラックバック:https://mbsre.com/forums/users/charlamontenegro/
トラックバック:Wiki.moebius.com.br
トラックバック:https://Wiki.Team-Glisto.com/index.php?title=Benutzer:EricRays77466
トラックバック:http://Www.bjkclh.com/comment/html/?185732.html
トラックバック:http://Zavalen.megi.cz//profile.php?id=1894890
トラックバック:http://www.Gedankengut.one/index.php?title=User:LaceyTroedel8
トラックバック:Die-Seite.com
トラックバック:internet site
トラックバック:http://Www.jeromebaray.com/afm/wiki/index.php/Utilisateur:SidneyHornsby39
トラックバック:visit the up coming webpage
トラックバック:https://trans.Hiragana.jp/ruby/https://illinoisbay.com/user/profile/6120759
トラックバック:https://Telugusaahityam.com/User:NewtonColson1
トラックバック:http://invoices.dofollowlinks.org/user/yqrkarla89/
トラックバック:Direcar.Co.kr
トラックバック:http://Cloud-Dev.Mthmn.com
トラックバック:click here now
トラックバック:Testforum.K9Lady.Com
トラックバック:https://nxlv.ru/user/RemonaScammell8/
トラックバック:Https://Weakfantasy.De/Index.Php/Benutzer:Abe09R558864
トラックバック:https://Www.Waterborefiji.com/index.php?title=User:KPTCathryn
トラックバック:https://Sustainabilipedia.org/index.php/User:WillieRennie477
トラックバック:Classifieds.Ocala-News.com
トラックバック:simply click the up coming website
トラックバック:via vulteevaliant.com
トラックバック:http://cloud-dev.mthmn.com/node/188241
トラックバック:https://www.vander-horst.nl/wiki/User:RobbyYount529
トラックバック:https://dripwiki.com/index.php/User:NealCiotti
トラックバック:Readukrainianbooks link for more info
トラックバック:https://biowiki.clinomics.com/index.php/User:KieranShaffer72
トラックバック:https://Dimension-Gaming.nl/profile.php?id=37033
トラックバック:https://readukrainianbooks.com/user/GeneFerris/
トラックバック:https://Porscheforsale.org/author/mirandaghol/
トラックバック:http://Www.Calsouthchurch.Org/board_txxk18/484876
トラックバック:https://Www.Oasiskorea.net/Brand/3285099
トラックバック:http://www.season.dofollowlinks.org/news/clinica-maxi-dental-5/
トラックバック:https://Mbsre.Com/forums/users/lamont10b967/
トラックバック:http://Www.Driftpedia.com/wiki/index.php/User:LashayGcm3104
トラックバック:https://formazione.Geqmedia.it/blog/index.php?entryid=17126
トラックバック:look at this web-site
トラックバック:https://Classifieds.ocala-news.com/author/ervinwilhoi
トラックバック:https://Weakfantasy.de/index.php/Balcon_Patio_Polybois_Decking_100_Pour_Cent_Plasti
トラックバック:recent Nxlv blog post
トラックバック:https://Offroadjunk.com/Questions/index.php?qa=1205331&qa_1=Prt-sans-refus
トラックバック:https://luxuriousrentz.com/tout-ce-quvous-devriez-comprendre-sur-linstallation-de-pave-uni-a-montreal/
トラックバック:https://Nebenwelten.net/index.php?title=User:Silke380436
トラックバック:Matrice.Btsndrc.ac
トラックバック:https://unitedindia.info/forums/topic/idees-damenagement-par-la-facade-de-votre-maison-2/
トラックバック:Faq.warexo.de
トラックバック:http://canamkart.ca/index.php?page=user&action=pub_profile&id=1505626
トラックバック:http://Www.die-seite.com/
トラックバック:wWW.voLkeR-rAu.DE
トラックバック:http://Cloud-Dev.mthmn.com/node/176680
トラックバック:Https://omnias.Wiki/index.php/User:MyrnaGuzman2175
トラックバック:Https://Wiki.Gigaro.Com.Br/
トラックバック:discover here
トラックバック:http://gijangchurch.org/index.php?mid=board_UvBh53&document_srl=272614
トラックバック:http://mastas.co.kr/xe/index.php?mid=Construction_VOD&document_srl=960227
トラックバック:http://zavalen.megi.cz//profile.php?id=1920917
トラックバック:My Page
トラックバック:please click for source
トラックバック:https://King.az/user/ZNZMilla08/
トラックバック:http://www.pinnaclebattleship.com/wiki/index.php/User:LuigiOreilly40
トラックバック:Www.synonyms.bookmarking.site
トラックバック:https://readukrainianbooks.com/user/AliciaOrmond1/
トラックバック:https://Wiki.Team-Glisto.com/Index.php?title=Benutzer:AlanaBecker271
トラックバック:https://biowiki.clinomics.com/index.php/User:ArdenToussaint
トラックバック:http://Gijangchurch.org/index.php?mid=board_UvBh53&document_srl=273116
トラックバック:http://Www.Rebelscon.com/profile.php?id=1597685
トラックバック:השכרת רכב בבוקרשט
トラックバック:your input here
トラックバック:https://zvukiknig.cc/user/NanniePan74685/
トラックバック:Weakfantasy.de’s website
トラックバック:http://Aaahe.com/index.php?page=user&action=pub_profile&id=72083
トラックバック:https://www.oasiskorea.net/Brand/3071232
トラックバック:Suggested Online site
トラックバック:Edddriihm.tp.crea.pro
トラックバック:https://mountainrootsonline.com/index.php/User:AnibalBischof
トラックバック:https://forum.inos.at/profile.php?id=334259
トラックバック:here.
トラックバック:https://onsale.tawansmile.com/Index.php?action=Profile;u=6960
トラックバック:simply click for source
トラックバック:http://luennemann.org/index.php?mod=users&action=view&id=324313
トラックバック:https://Infodin.Com.br/index.php/User:GarnetSymon379
トラックバック:www.gedankengut.one
トラックバック:Www.Hotels.Sblinks.net
トラックバック:https://Aproblemsquaredwiki.com/User:DannielleLuisini
トラックバック:http://Leonblog.net/member.asp?action=view&memName=MaddisonMerryman361
トラックバック:https://Readukrainianbooks.com/user/CarolSkalski985/
トラックバック:http://direcar.Co.kr/board_rxWR73/698486
トラックバック:https://www.morphonic-Records.com/community/profile/elvaingram00172/
トラックバック:https://portal.virtueliving.org/profile_info.php?ID=36590
トラックバック:https://Demo.Centreon.com/wiki/index.php?title=User:ForestHirschfeld
トラックバック:http://Gijangchurch.org/index.php?mid=board_UvBh53&document_srl=161037
トラックバック:this post
トラックバック:wikI.FUKUOka-DEnsHi-kOUsAkU.cLUb
トラックバック:https://taupi.org/index.php?title=User:GeraldoOMay6
トラックバック:http://www.bjkclh.com/comment/html/?192389.html
トラックバック:https://wiki.nerdbird.media/index.php?title=User:LeonoreOuo
トラックバック:Http://Saju.Codeway.Kr/Index.Php/Base_De_Lit_Matelot__Six_Tiroirs_Pour_TrS_G_Ant_Matelas_King_S_Mate_De_Prepac_Gris_Dbk
トラックバック:https://Readukrainianbooks.com/user/Angelita70O/
トラックバック:Www.online-teaching.sblinks.net
トラックバック:Wiki.Nativeland.info
トラックバック:http://cloud-dev.mthmn.com/node/219356
トラックバック:http://demos.Gamer-Templates.de/specialtemps/clansphere20114Sdemo01/Index.php?mod=users&action=View&id=5846727
トラックバック:Brilliantcollections.com
トラックバック:https://portal.virtueliving.org/profile_info.php?ID=33135
トラックバック:simply click the next web page
トラックバック:Cloud Dev Mthmn said in a blog post
トラックバック:https://Nxlv.ru/user/GlenRountree124/
トラックバック:https://Wiki.Tentere.net/index.php?title=Bijoux_Par_Femme
トラックバック:http://Beautyconceptasia.com/faq/1143237
トラックバック:https://mzlgam.com/index.php?action=profile;u=205098
トラックバック:http://Www.superstitionism.com/forum/profile.php?id=385058
トラックバック:http://Loafers.ipt.pw/News/la-bouticaire-12/
トラックバック:https://Www.Oasiskorea.net/Brand/3493150
トラックバック:https://Plamosoku.com/enjyo/index.php?title=:SabrinaTaul2
トラックバック:http://wsdjcd.cn/comment/html/?80411.html
トラックバック:https://Dublinohiousa.gov/?p=
トラックバック:Www.recruiting-and-retention.bookmarking.site
トラックバック:https://Zvukiknig.cc/user/ValenciaX02/
トラックバック:https://www.morphonic-records.com/Community/profile/brittferrara49/
トラックバック:Коя е актуална тема в социалните медии?
トラックバック:notícias de tendência no mundo
トラックバック:https://ladder2Leader.com/laguna-san-ignacio-una-joya-natural-en-baja-california-sur/
トラックバック:http://Www.gotanproject.net/node/22364157?—————————732408056302Content-Disposition:form-data;name=titleSummaryOfGuidanceForMinimizingTheImpactOfCovid-19OnIndividualPersons,Communities,AndHealthCareSystemsUnitedStates,August2022Mmwr——
トラックバック:https://mmhsmassageme.com/index.php?page=user&action=pub_profile&id=5822786
トラックバック:mouse click the up coming post
トラックバック:Www.Photography.Sblinks.net
トラックバック:Www.Lunchbox.Sblinks.net
トラックバック:спортни новини на живо
トラックバック:just click the up coming website
トラックバック:https://www.oasiskorea.net/Brand/3449836
トラックバック:http://Gotanproject.net/node/22387625?—————————123727724Content-Disposition:form-data;name=titlePanneauxSolairesAuSol:Rglementation,Cot,Aides—————————123727724Content-Disposition:form-data;name=bodyiAujourd’hui,unparco
トラックバック:https://dripwiki.com/index.php/User:TaniaBartley
トラックバック:https://Unitedindia.info/forums/topic/elagage-vs-emondage-quelle-est-la-distinction-2/
トラックバック:http://Gotanproject.net/node/22385075?—————————58061928985819Content-Disposition:form-data;name=titleLebtondesign,unpenchantdcorativedurable—————————58061928985819Content-Disposition:form-data;name=bodyiSous-titres:/ibr
トラックバック:https://unitedindia.info/forums/topic/comment-consolider-vos-argent-du-conseils-budgetaires-et-planification-3/
トラックバック:www.financial-services.Bookmarking.Site
トラックバック:Girl.Sblinks.net
トラックバック:http://www.Bjkclh.com/comment/html/?189512.html
トラックバック:http://www.gedankengut.one/index.php?title=User:ManieBerman32
トラックバック:Mediawiki.governancaegestao.Wiki.br
トラックバック:titujt e lajmeve sportive të ditës së sotme
トラックバック:https://ciutatgranturia.es/2023/09/26/vinedo-en-queretaro-descubriendo-la-riqueza-vinicola-la-region/
トラックバック:http://Www.Zilahy.info/wiki/index.php/User:VickieSpalding0
トラックバック:Www.Airline.Bookmarking.site
トラックバック:Http://Www.zjxsnj.cn
トラックバック:http://Rainbow.bookmarking.site/News/armo-design-30/
トラックバック:https://Aproblemsquaredwiki.com/User:Cole280757325
トラックバック:tin tức trực tiếp của cbs
トラックバック:click the following webpage
トラックバック:flusso di notizie in diretta gratuito
トラックバック:Https://Wiki.Castaways.Com/Wiki/La_Importancia_Del_Ecoturismo:_ConservaciN_Desarrollo_Y_Conciencia_Ambiental
トラックバック:https://weakfantasy.de/index.php/Benutzer:LeonardDickerson
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=329628
トラックバック:https://www.recruiterwiki.de/Benutzer:TessaK0664
トラックバック:have a peek at this website
トラックバック:Безплатен поток от новини на живо в youtube
トラックバック:Omnias.Wiki
トラックバック:Gotanproject.net
トラックバック:tiempos de noticias deportivas de la india hoy
トラックバック:www.superstitionism.com
トラックバック:item550758107
トラックバック:https://aproblemsquaredwiki.com/User:Boris59Y5089
トラックバック:http://qzfczs.com/comment/html/?289176.html
トラックバック:you can try Illinoisbay.com
トラックバック:click through the up coming webpage
トラックバック:https://Procesal.cl/index.php/User:FreemanLansford
トラックバック:https://runsexme.Ru/
トラックバック:Https://Wiki.Sports-5.Ch/Index.Php?Title=Utilisateur:Elliotlowin0461
トラックバック:최신 뉴스 인도네시아
トラックバック:https://Trans.Hiragana.jp/ruby/http://cloud-dev.mthmn.com/node/199807
トラックバック:https://Matrice.Btsndrc.ac/forum/profile/shaynavoyles20/
トラックバック:https://Dripwiki.com/index.php/User:DaisyBiermann9
トラックバック:https://Vipsbay.net/index.php/blog/55882/pruebas-uat-en-colombia-garantizando-la-excelencia-del-software/
トラックバック:https://Pipewiki.org/app/index.php/User:Cristina3303
トラックバック:http://wiki.Quanticsystems.com.br/index.php/User:QHUErik56051
トラックバック:https://yoga.wiki/index.php/v_nements_Par_C_libataires__Montr_al_:_Rencontre_Et_Connexion_Authentique
トラックバック:http://www.rebelscon.com/profile.php?id=1594645
トラックバック:http://www.gotanproject.net/
トラックバック:Sudancancer-Clinic.com
トラックバック:https://www.motline.com/index.php?mid=rent_counseling&document_srl=2235952
トラックバック:http://www.customer-Service.sblinks.net/News/tres-amigos-outfitters-10/
トラックバック:https://www.kenpoguy.com/phasickombatives/profile.php?id=1378714
トラックバック:Wiki.Unionoframblers.Com
トラックバック:www.commit.ipt.Pw
トラックバック:https://apeguebremariam.org/community/?wpfs=&membersite=httpsFlorilegejardinerie.comboutiquecouronne-funeraire&membersignature=span+stylefont-style:+oblique;La+prparation+peut+avoir/span+lieu++la+fin+du+mois+de+mai+dans+plusieurs+arrondissements+d
トラックバック:http://Www.Register.Sblinks.net/out/neuro-performa/
トラックバック:https://maga.wiki/index.php/User:GarryZercho
トラックバック:https://porscheforsale.org
トラックバック:agreement.bookmarking.site
トラックバック:Www.Terrarium-Reptile.com
トラックバック:visit the up coming site
トラックバック:Www.Loafers.ipt.pw
トラックバック:https://Matrice.btsndrc.ac/forum/profile/elisebna5675035/
トラックバック:https://infodin.com.br/index.php/User:MeiHandcock174
トラックバック:http://wiki.quanticsystems.Com.br/index.php/User:ShaniHartnett
トラックバック:https://Aproblemsquaredwiki.com/User:AidanWilliford
トラックバック:Related Site
トラックバック:https://www.globasnet.com/members/taylamauriello/profile/
トラックバック:http://www.Digital-marketing.Ipt.pw/News/armo-design-68/
トラックバック:Suggested Looking at
トラックバック:http://www.Gedankengut.one/index.php?title=User:MichealHillary
トラックバック:http://Www.diywiki.Org/
トラックバック:https://infodin.com.br/index.php/User:JanellColmenero
トラックバック:http://Qzfczs.com/comment/html/?291423.html
トラックバック:http://www.s-miles.com/xe/board_gBNS02/808904
トラックバック:http://afcantarelle.org/index.Php?title=User:WRFBrandi022438
トラックバック:https://king.az/user/SheenaHogan
トラックバック:https://wiki.nerdbird.media/index.php?title=User:GregSyx69999
トラックバック:https://biowiki.clinomics.com/index.php/User:BenedictCagle
トラックバック:https://yhet.fi/wiki/index.php/User:AngelaKoonce03
トラックバック:трендовски вести во Индонезија
トラックバック:http://Sl860.com/comment/html/?241116.html
トラックバック:https://utahsyardsale.com/author/jesusgay67/
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=327553
トラックバック:https://www.oasiskorea.net/Brand/3191087
トラックバック:information from Www.Kenpoguy.com
トラックバック:https://Nxlv.ru/user/CharlotteSturgil/
トラックバック:https://Pipewiki.org/app/index.php/Satisfaccin_Al_Cliente:_Ejemplos_En_Colombia_Que_Impulsan_El_xito_Empresarial
トラックバック:http://gijangchurch.org/index.php?mid=board_UvBh53&document_srl=310027
トラックバック:simply click the up coming web site
トラックバック:https://Www.Oasiskorea.net/Brand/3221717
トラックバック:http://afcantarelle.org/index.php?title=Article_Title
トラックバック:more about Ladder 2leader
トラックバック:Https://Illinoisbay.com/user/Profile/6147897
トラックバック:https://Forum.Inos.at/profile.php?id=276853
トラックバック:актуални новини в Twitter
トラックバック:https://Www.Vander-Horst.nl/wiki/User:Brittany53K
トラックバック:https://Classifieds.ocala-news.com/author/alicabliss6
トラックバック:http://www.gotanproject.net/node/22390780?—————————42044346194642Content-Disposition:form-data;name=titleAryaRugsAccessoriesHighQualityCarpets&Rugs—————————42044346194642Content-Disposition:form-data;name=bodyimgsrc
トラックバック:Актуални новини в интернет тази седмица
トラックバック:Suggested Reading
トラックバック:http://Gotanproject.net/node/22392003?—————————3101004761Content-Disposition:form-data;name=titleEmprisonnonsLaChaleurSection5:LesToitsEtLesEntretoits—————————3101004761Content-Disposition:form-data;name=bodyimgsrc=http
トラックバック:Https://illinoisbay.com/user/profile/6151406
トラックバック:http://forum.megi.cz//profile.php?id=2822177
トラックバック:Https://Www.Oasiskorea.Net
トラックバック:https://Www.oasiskorea.net/Brand/3580058
トラックバック:Infodin.Com.br
トラックバック:http://Cloud-dev.Mthmn.com/Node/237962
トラックバック:https://nobelboerse.de/mitglied/warnerblank/
トラックバック:https://illinoisbay.com/user/profile/6149153
トラックバック:https://Www.Drclydewilson.com/community/?wpfs=&membersite=httpsvanspremium.com.coservicios&membersignature=Bogot+la+capital+de+Colombia+es+una+ciudad+rica+en+tradicin++a+hrefhttps://vanspremium.com.co/+reldofollowServicios+de+Transporte+terrestre+
トラックバック:https://hobbyclues.in/user/profile/30636
トラックバック:https://Okniga.org/user/EddyGlaspie/
トラックバック:http://luennemann.org/index.php?mod=users&action=view&id=328007
トラックバック:http://Canamkart.ca/index.php?page=user&action=pub_profile&id=1528824
トラックバック:Http://Qzfczs.com
トラックバック:https://king.az/user/JaquelineStrangw/
トラックバック:https://Antislave.com/groups/service-de-reparation-gps-garmin-laval-canada/
トラックバック:http://Sl860.com/comment/html/?268547.html
トラックバック:pede togel login alternatif
トラックバック:https://www.offwiki.org/wiki/User:LavadaSouza59
トラックバック:simply click the up coming internet page
トラックバック:https://portal.virtueliving.org/profile_info.php?ID=31668
トラックバック:http://Forum.Prolifeclinics.ro/profile.php?id=84061
トラックバック:Preuniversitarioperu.com
トラックバック:Http://Gijangchurch.Org
トラックバック:Highly recommended Website
トラックバック:Cosmeascopes.com
トラックバック:https://Readukrainianbooks.com/user/ArielMackersey8/
トラックバック:http://cloud-dev.mthmn.com/node/181619
トラックバック:Https://Matrice.btsndrc.ac/
トラックバック:http://Www.zilahy.info/wiki/index.php/User:ZVSTamela9
トラックバック:Https://www.motline.com
トラックバック:https://taupi.org/index.php?title=User:NQMFlora18
トラックバック:https://Okniga.org/user/BlytheGoins880/
トラックバック:financial-services.bookmarking.site
トラックバック:https://Okniga.org/user/LucaMcGahan315/
トラックバック:Full Piece of writing
トラックバック:https://demo.centreon.com/wiki/index.php?title=User:WhitneyOMeara03
トラックバック:https://Theglobalfederation.org/profile.php?id=1995223
トラックバック:https://mmhsmassageme.com/index.php?page=user&action=pub_profile&id=5838024
トラックバック:Азыр тренд деген эмнени билдирет?
トラックバック:https://Portal.Virtueliving.org/profile_info.php?ID=38236
トラックバック:https://hobbyclues.in/user/profile/36298
トラックバック:https://zvukiknig.cc/user/SherleneCard510/
トラックバック:http://Qzfczs.com/comment/html/?293979.html
トラックバック:mzlgam.Com
トラックバック:https://Nobelboerse.de/mitglied/changmathes/
トラックバック:blog post from cloud-dev.mthmn.com
トラックバック:Customer-service.Sblinks.net
トラックバック:https://King.az
トラックバック:http://www.suits.ipt.pw/News/designer-dinterieur-a-montrea-31/
トラックバック:http://Sl860.com/comment/html/?243456.html
トラックバック:https://checkmygigs.com/community/?wpfs=&membersite=httpscouvreurpaquette.comrefection-de-toiture-a-sainte-scholastique&membersignature=il+assure+une+pose+dans+les+normes+de+quelque+manire+que+ce+soit+au+degr+de+qualit+mais+en+plus+bas+sur+les+rgl
トラックバック:https://Biowiki.Clinomics.com/index.php/Armoire_De_Cuisine
トラックバック:http://C674576N.Beget.tech/author/felipe14c7/
トラックバック:Oasiskorea.net
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=329534
トラックバック:http://Www.Weather.Sbm.pw
トラックバック:just click for source
トラックバック:https://Xdpascal.com/index.php/User:OrvilleDacomb1
トラックバック:http://My-Broholmer.de/community/profile/angiedownie6605
トラックバック:https://classifieds.exponentialhealth.coop/community/?email=&membersite=httpsmoney911.caenquick-loans&membersignature=lorsque+vous+recherchez+un+prt+personnel+au+qubec+aider++faire+appel++1+revendeur+en+prt+pourrait+tre+une+choix+judicieuse+qui+pe
トラックバック:http://www.Gaming.sblinks.net/News/tres-amigos-outfitters-6/
トラックバック:Luxuriousrentz.Com
トラックバック:http://Www.Superstitionism.com/forum/profile.php?id=378453
トラックバック:click the next site
トラックバック:http://direcar.Co.kr/board_rxWR73/901931
トラックバック:Www.change-management.dofollowlinks.org
トラックバック:Mmhsmassageme.com
トラックバック:https://wiki.freeneuropathology.org/index.php?title=Bureau_D_Architecture__Montr_al_:_Cr_ativit_Et_Excellence_Sur_Le_Service_De_Vos_Projets
トラックバック:http://www.s-miles.com/xe/board_gBNS02/253851
トラックバック:http://www.Die-seite.com/index.php?a=stats&u=reynaldogreenfie
トラックバック:https://Okniga.org/user/CyrusMccallister/
トラックバック:visit Seasonal.Ipt.pw now >>>
トラックバック:https://Isotrope.cloud/index.php/Conseils_Sur_Comment_Faire_Face__Une_D_pense_Inattendue
トラックバック:click the following page
トラックバック:https://Illinoisbay.com/user/profile/6147051
トラックバック:http://Theglobalfederation.org/profile.php?id=2000565
トラックバック:Http://canamkart.ca/index.php?page=user&action=pub_profile&id=1350975
トラックバック:Related Web Page
トラックバック:Https://Forum.veriagi.com
トラックバック:bu gün sosial media ilə nə baş verir
トラックバック:https://Napiri.com/design_works/334014
トラックバック:vacayphilippines.com`s blog
トラックバック:Startflag.Rulez.jp wrote in a blog post
トラックバック:Forum.giperplasma.ru
トラックバック:https://Www.Checkmygigs.com/community/?wpfs=&membersite=httpsWww.Ciminvestigacion.comel-mercado-en-la-actualidad&membersignature=span+styletext-decoration:+underline;El+benchmarking+interno+es+una/span+estrategia+empresarial+que+puede+enfoca+en+co
トラックバック:https://king.az/user/JimCastleton49/
トラックバック:https://Wiki.Unionoframblers.com/index.php/User:RaymondFewings
トラックバック:https://forum.veriagi.com/profile.php?id=4248886
トラックバック:https://Virus.Win32.wiki/wiki/Podiatre_Fermer_De_Laval
トラックバック:http://Xiamenyoga.com/Comment/html/?253152.html
トラックバック:http://Www.Video.Dofollowlinks.org/News/tres-amigos-outfitters-28/
トラックバック:http://Gotanproject.net/node/22397337?—————————68082558Content-Disposition:form-data;name=titleUnTuteurDeMousseSimpleFabriquerJardinierParesseuxMonsteraDeliciosa,SwissCheesePlant,CheesePlant—————————68082558Content-Disp
トラックバック:https://Pipewiki.org/app/index.php/User:MillieSundberg
トラックバック:https://www.Vander-horst.nl/wiki/User:SonjaIev804186
トラックバック:https://Thedatabite.com/community/?wpfs=&membersite=httpsmaisondermasens.com&membersignature=Avant+dutiliser+un+produit+par+la+pores+et+peau+il+est+prfrable+de+demander+lavis+de+un+mdecin+ou+un+pharmacien++a+hrefhttps://Maisondermasens.com/+reldof
トラックバック:http://Soccer-Manager.eu/forum/profile.php?id=1093716
トラックバック:Wisetrubador.com
トラックバック:vander-Horst.nl
トラックバック:My Home Page
トラックバック:https://Successionwiki.co.uk/index.php/User:GretchenGilberts
トラックバック:https://pipewiki.org/app/index.php/User:CecilaThao39988
トラックバック:EtoWnjUNGLIsts.coM
トラックバック:http://Die-Seite.com/index.php?a=stats&u=maxlayh1125264
トラックバック:Www.soccer-Manager.eu
トラックバック:http://Www.Bjkclh.com/comment/html/?119247.html
トラックバック:like this
トラックバック:http://afcantarelle.org/index.php?title=User:TobiasBirtles
トラックバック:http://qzfczs.com/comment/html/?275604.html
トラックバック:Unitedindia.info
トラックバック:http://zavalen.megi.cz//profile.php?id=1921174
トラックバック:اخبار پرطرفدار در رسانه های اجتماعی
トラックバック:https://zvukiknig.cc/user/ChesterLegge1/
トラックバック:Risingsun.co.kr
トラックバック:www.business-to-business.ipt.pw
トラックバック:WwW.MiRAgeARb.COM
トラックバック:click through the next article
トラックバック:https://www.vander-horst.nl/wiki/User:NorrisPgx96765
トラックバック:pop over to this site
トラックバック:Tko je broj 1 u trendu na Googleu?
トラックバック:https://king.az/user/BobbyeBrough971/
トラックバック:http://eldoradofus.free.fr/forum/profile.php?id=191377
トラックバック:co se dnes děje se sociálními sítěmi
トラックバック:https://Dripwiki.com/index.php/User:SelinaYxy58
トラックバック:https://mediawiki.Governancaegestao.wiki.br/index.php/Stihl_Pole_Saw_Canada:_Features_And_Benefits
トラックバック:https://Pipewiki.org/app/index.php/User:LizziePringle6
トラックバック:https://Enableelearn.com/?s=&post_type=courses&membersite=httpsPoupartsyndic.caconsolidation-de-dettes-a-dorval&membersignature=span+stylefont-style:+italic;Sous-titres+:+/spanpnbsp;/ppnbsp;/p+1.+Comprendre+les+prts+hypothcairespnbsp;/ppnbsp;/
トラックバック:https://Able.Extralifestudios.com/wiki/index.php/User:AltonBrownbill6
トラックバック:https://avfoch.com/author/warnerhillm/
トラックバック:forum.Veriagi.com
トラックバック:https://Nxlv.ru/user/CharityWpx/
トラックバック:https://classifieds.ocala-news.com/author/klaussherma
トラックバック:https://King.az/user/PBJWilson1784319/
トラックバック:Legalidad.net
トラックバック:Zilahy.Info
トラックバック:https://www.Waterborefiji.com/index.php?title=User:LonnyHenschke
トラックバック:http://Cloud-Dev.Mthmn.com/node/245194
トラックバック:Aviamili.com
トラックバック:http://Www.Legal-Information.sblinks.net/News/denta-especialidades-32/
トラックバック:http://Cloud-dev.mthmn.com/node/244677
トラックバック:https://Omnias.wiki/index.php/User:OdessaPutman0
トラックバック:www.sigmachiiu.Com
トラックバック:https://Cbnxt.com
トラックバック:Zwitsch.io
トラックバック:шуурхай мэдээ гарчиг
トラックバック:killer deal
トラックバック:Procesal.cl
トラックバック:Https://Infodin.Com.Br/Index.Php/User:ColetteSommerlad
トラックバック:http://www.register.Bookmarking.site/News/freaky-socks-29/
トラックバック:Trabalhadoresindependentes.com
トラックバック:https://www.Motline.com/index.php?mid=rent_counseling&document_srl=2463061
トラックバック:http://cloud-dev.Mthmn.com/node/246783
トラックバック:https://pipewiki.org/app/index.php/User:NganWeisz6
トラックバック:visit this website
トラックバック:https://thedatabite.com/community/?wpfs=&membersite=httpsEnergiaysistemas.comups-online&membersignature=span+stylefont-style:+oblique;Bogot+la+vibrante+capital/span+de+Colombia+es+un+centro+de+actividad+negocio+y+empresarial.+En+un+entorno+donde+l
トラックバック:http://Www.zilahy.info/wiki/index.php/User:MoniqueWinters
トラックバック:https://barretocell.com/2023/10/11/ecoturismo-en-la-region-de-san-ignacio-una-estadia-inolvidable/
トラックバック:Minibookmarks.Com
トラックバック:Forum.Megi.cz
トラックバック:Www.weather.sbm.pw
トラックバック:Zavalen.megi.cz
トラックバック:http://market-Research.sblinks.Net
トラックバック:http://Www.Die-Seite.com/index.php?a=stats&u=russellcreighton
トラックバック:http://Www.Rebelscon.com/profile.php?id=1611202
トラックバック:Https://Maga.wiki/
トラックバック:okniga.org said
トラックバック:ʻO nā nūhou kaulana ma ka pūnaewele i kēia lā
トラックバック:https://wiki.freeneuropathology.org/index.php?title=user:jettaperkin04
トラックバック:i was reading this
トラックバック:Http://www.gedankengut.One
トラックバック:https://infodin.com.br/index.php/User:HeidiThorp3
トラックバック:https://Trans.Hiragana.jp/ruby/http://cloud-dev.mthmn.com/node/245990
トラックバック:Get Source
トラックバック:Moodjhomedia.com
トラックバック:lnX.ARgOnBAnD.iT
トラックバック:http://Wiki.Rl-Transport.org/index.php/User:AraSutcliffe126
トラックバック:http://Qzfczs.com/comment/html/?300445.html
トラックバック:https://Kaidan136.com/index.php?title=:KAGDoug3884027
トラックバック:find more information
トラックバック:https://sustainabilipedia.org/index.php/User:LoisDehaven951
トラックバック:https://okniga.org/user/EugeneRooney8/
トラックバック:http://Www.Sports.Sblinks.net/out/performance-saw-17/
トラックバック:라이브 스포츠 뉴스 프리미어 리그
トラックバック:http://Www.Sxlopw.cn/comment/html/?225758.html
トラックバック:Https://lnx.Argonband.It
トラックバック:Besplatni prijenos vijesti uživo na youtube
トラックバック:http://Wiki.quanticsystems.com.Br/
トラックバック:https://Gratisafhalen.be/author/amparo03i61/
トラックバック:https://kaidan136.com/index.php?title=:BlytheLemay990
トラックバック:http://afcantarelle.org/index.php?title=User:PaulettePrescott
トラックバック:http://www.Die-seite.com/index.php?a=stats&u=leomau42125
トラックバック:http://www.soccer-Manager.eu/forum/profile.php?id=1165628
トラックバック:http://sl860.com/comment/html/?244010.html
トラックバック:just click the up coming web site
トラックバック:http://Qzfczs.com/comment/html/?298682.html
トラックバック:Vivaj sportaj novaĵoj hodiaŭ
トラックバック:www.healthcare-industry.Ipt.pw
トラックバック:http://www.Gedankengut.one/index.php?title=User:ChristalI89
トラックバック:https://Readukrainianbooks.com/user/IeshaMccrary7/
トラックバック:https://avfoch.com/author/wfxmellisa1/
トラックバック:https://oasiskorea.net/Brand/1762904
トラックバック:http://c674576n.beget.tech/author/solomongene/
トラックバック:My Web Site
トラックバック:http://www.Zilahy.info/Wiki/index.php/User:VitoMcCarthy
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1062688
トラックバック:https://Wiki.Gem-Flash.com/index.php?title=User:EulaCollazo184
トラックバック:http://Zilahy.info/wiki/index.php/Comment_Nettoyer_Un_Climatiseur_Mural_:_tapes__Suivre
トラックバック:avtpoligraf.ru
トラックバック:https://Taupi.org/index.php?title=User:CarsonTreacy06
トラックバック:https://pipewiki.org/app/index.php/User:RyanBrandow
トラックバック:wwwbj.com.cn
トラックバック:https://okniga.org/user/MarleneHooton6/
トラックバック:www.events.sblinks.net
トラックバック:you could try here
トラックバック:Afcantarelle`s recent blog post
トラックバック:Www.agchem.co.kr
トラックバック:Wiki Psychedelic Lab said in a blog post
トラックバック:Wiki.Quanticsystems.Com.br
トラックバック:https://Mzlgam.Com/index.php?action=profile;u=209808
トラックバック:https://qa.laodongzu.com/?qa=569791/cadenas-eficientes-camino-empresas-invencibles-colombia
トラックバック:https://Wiki.Freeneuropathology.org/index.php?title=User:FrankMcAlister1
トラックバック:simply click the up coming webpage
トラックバック:шууд мэдээ үнэг
トラックバック:Sxlopw.cn
トラックバック:https://dptotti.fic.edu.uy/mediawiki/index.php/Usuario:WadeClibborn2
トラックバック:Suggested Web site
トラックバック:https://mediawiki.governancaegestao.wiki.br/index.php/User:MurrayKoerstz84
トラックバック:https://aumcgogrzo.cloudimg.io/v7/https://www.akilia.net/contact?message=Very+nice+post.+I+just+stumbled+upon+your+blog+and+wanted+to+say+that+I+have+truly+loved+browsing+your+blog+posts.+In+any+case+I+will+be+subscribing+in+your+feed+and+Im+hoping+you+wr
トラックバック:http://leonblog.net/member.asp?action=view&MemName=MadonnaBullock13341
トラックバック:Live lajme sportive të ligës së parë
トラックバック:Classifieds.Exponentialhealth.coop
トラックバック:http://www.Digital-marketing.ipt.pw/out/tres-amigos-outfitters-21/
トラックバック:https://wiki.castaways.com/wiki/User:GregorioDadswell
トラックバック:http://wiki.moebius.com.br/index.php/Cursos_DC-3_En_Lnea_En_M_xico:_Tu_Opcin_Para_Poder_La_Capacitacin_Laboral
トラックバック:https://Forum.inos.at/
トラックバック:Cloud-Dev.mthmn.com
トラックバック:https://Avtpoligraf.ru/content/forfait-massage-therapeutique-suedois-ou-californien-90-minutes-et-soin-visage-le-classique
トラックバック:relevant resource site
トラックバック:https://Telearchaeology.org/TAWiki/index.php/User:TobySuh75415548
トラックバック:http://www.security.sbm.pw/News/couvreur-paquette-28/
トラックバック:https://Mzlgam.com/index.php?action=profile;u=178757
トラックバック:https://dptotti.fic.edu.uy/mediawiki/index.php/MS_880_Stihl:_A_High-Performance_Chainsaw_For_Heavy-Duty_Jobs
トラックバック:Cbnxt.com
トラックバック:gewilde nuus op sosiale media
トラックバック:http://Wiki.monashicpc.com/User:Major8643378995
トラックバック:https://Upscadvisor.Co.in/groups/refrigeracion-industrial-en-medellin-enfriamiento-eficiente-para-la-industria-local/
トラックバック:https://socialbraintech.com/story1054033/cim-investigacin
トラックバック:trendi hírek ma
トラックバック:http://commission.sbm.pw/News/mon-genie-en-batiment-22/
トラックバック:https://www.checkmygigs.com/community/?wpfs=&membersite=httpswww.solutions-g00.com&membersignature=Learn+in+regards+to+the+work+the+training+youll+need+what+youll+earn+and+extra.+Provided+youve+the+suitable+conditions+the+programs+in+this+program+
トラックバック:http://Customer-Service.Sblinks.net/News/tres-amigos-outfitters-14/
トラックバック:http://Child-Health.Bookmarking.site/News/tres-amigos-outfitters-18/
トラックバック:http://Www.Die-Seite.com/index.php?a=stats&u=kari39m21625
トラックバック:click for more
トラックバック:http://Direcar.co.kr/board_rxWR73/653857
トラックバック:https://www.guidemagazine.org/participant/cathrynstorm94/profile/?claim_code=&submit_2=&membersite=httpsrdttaq.com&membersignature=vous+pouvez+vous+faire+rembourser+des+frais+mme+si+vous+navez+pas+eu++vous+absenter+du+travail.+le+service+de+ss
トラックバック:http://www.die-seite.com/index.php?a=stats&u=rayfordzaleski1
トラックバック:http://Canamkart.ca/index.php?page=user&action=pub_profile&id=1593646
トラックバック:Rocket League sensation Joyo
トラックバック:http://www.weather.sbm.pw/out/ott-official-25/
トラックバック:Https://Yuniverse.wiki
トラックバック:Directmysocial.com
トラックバック:https://Utahsyardsale.com/author/tuyetzalesk/
トラックバック:Sparxsocial.com
トラックバック:https://Aproblemsquaredwiki.com/User:KerrieLindgren1
トラックバック:seolisTLINKs.Com
トラックバック:advicebookmarks.com
トラックバック:NBC News in diretta streaming gratuito
トラックバック:see this
トラックバック:http://Www.traders.Sblinks.net/News/gaia-total-30/
トラックバック:Gaming.Sblinks.net
トラックバック:http://Www.Outsourcing.Sbm.pw/out/clinica-maxi-dental-21/
トラックバック:Https://Nimmansocial.Com/Story5237458/Energa-Y-Sistemas
トラックバック:click for info
トラックバック:Những chủ đề nào đang là xu hướng hiện nay?
トラックバック:https://Readukrainianbooks.com/user/MarisolWgq/
トラックバック:Mysitesname.com
トラックバック:https://www.oasiskorea.net/Brand/3756591
トラックバック:http://classicalmusicmp3freedownload.com/ja/index.php?title=M_dical_Podiatrique_De_L_estrie
トラックバック:http://www.superstitionism.com/forum/profile.php?id=389912
トラックバック:https://enableelearn.com/?s=&post_type=courses&membersite=httpsFlorilegejardinerie.compaysager&membersignature=Aucun+curiosit+ne+bref+pendant+la+intervalle+du+programme.pnbsp;/ppnbsp;/p+Les+programmes+de+modalits+spciales+de+cot+ne+ralit+pas+c
トラックバック:Socialbraintech.com
トラックバック:LiNGEriEbOoKmArK.CoM
トラックバック:https://Weakfantasy.de/index.php/Benutzer:LavondaSlate84
トラックバック:Linkingbookmark.com
トラックバック:https://wavesocialmedia.com/story1165326/emprunts-d-argent-rapide-sans-enqute-de-crdit-money911
トラックバック:qna.lrmer.com
トラックバック:Актуелне вести на друштвеним мрежама данас
トラックバック:http://Callcenters.Sblinks.net/News/ott-official-22/
トラックバック:http://gijangchurch.org/index.php?mid=board_UvBh53&document_srl=527393
トラックバック:http://www.seasonal.ipt.pw/out/intermezzo-montreal-93/
トラックバック:DialOGoS.wikI
トラックバック:https://Luxuriousrentz.com/top-gear-outfitters-your-one-stop-shop-for-outdoor-Gear-in-canada-4/
トラックバック:Siambookmark.Com
トラックバック:Dzliprojects.wiki
トラックバック:https://Bookmarktiger.com/story15835099/intermezzo
トラックバック:https://livingbooksaboutlife.org/books/User:SantoGreaves17
トラックバック:https://Pipewiki.org/app/index.php/Symptmes_Du_Traumatisme_Crnien_:_Reconnatre_Les_Signaux_D_Alerte
トラックバック:http://luennemann.org/index.php?mod=users&action=view&id=307638
トラックバック:https://Mysitesname.com/story5340018/intermezzo
トラックバック:https://wiki.bigtata.org/index.php/Utilisateur:DanielleDegree
トラックバック:https://Mediawiki.Governancaegestao.Wiki.br/index.php/User:BlythePena1732
トラックバック:brIghTbookmARKs.coM
トラックバック:just click the up coming internet site
トラックバック:https://wiki.castaways.com/wiki/User:BrentK54908189
トラックバック:http://saju.codeway.kr
トラックバック:WASTewiki.Com
トラックバック:Bookmarkinglive.com
トラックバック:https://social-Galaxy.com/story1157475/hesman-garage
トラックバック:http://www.bjkclh.com/Comment/html/?125423.html
トラックバック:http://Www.healthcare-Industry.ipt.pw/out/intermezzo-montreal-71/
トラックバック:www.shirts.bookmarking.site
トラックバック:https://Illinoisbay.com/user/profile/6033379
トラックバック:youtube bugün dünya çapında trend
トラックバック:https://www.volker-rau.de/
トラックバック:https://Zvukiknig.cc/user/AshlyBoisvert43/
トラックバック:http://www.s-miles.com/xe/board_gBNS02/1004784
トラックバック:Sugeriu Olhando
トラックバック:please click the up coming document
トラックバック:http://Www.Flowers.Bookmarking.site/News/vicky-girouard-5/
トラックバック:https://Readukrainianbooks.com/user/UWHDane973210146/
トラックバック:https://okniga.org/user/GabrielleEastham/
トラックバック:my review here
トラックバック:Τάσεις ειδήσεων στο διαδίκτυο σήμερα
トラックバック:ツイッターで話題のニュース
トラックバック:https://trans.hiragana.jp/ruby/http://cloud-dev.mthmn.com/node/250008
トラックバック:Trending nieuws in de wereld van vandaag
トラックバック:http://forum.megi.cz//profile.php?id=2814663
トラックバック:view
トラックバック:read this blog post from keromaissaude.com
トラックバック:https://www.Oasiskorea.net/Brand/3715917
トラックバック:https://Bookmarkswing.com/story16909868/Hesman-Garage
トラックバック:https://sanatandharam.in/index.php/User:LilyStoddard74
トラックバック:Kush është numër 1 në trend në Google?
トラックバック:God-999.com
トラックバック:Alphabookmarking.com
トラックバック:http://cloud-dev.mthmn.com/node/249178
トラックバック:http://Qzfczs.com/comment/html/?301699.html
トラックバック:https://okniga.org/user/Dominic6290/
トラックバック:{link Alternatif Rajabandot}
トラックバック:bOokmArkLoVeS.cOm
トラックバック:Link Alternatif Ahha4d
トラックバック:Suggested Webpage
トラックバック:straight from the source
トラックバック:Full Content
トラックバック:pede toto
トラックバック:BOokmaRKwOrM.COM
トラックバック:Rajabandot login
トラックバック:https://Bookmarkswing.com/story16910087/couvreur-paquette
トラックバック:rajabandot
トラックバック:http://Zjxsnj.cn/comment/html/?112236.html
トラックバック:Pukkabookmarks.com
トラックバック:http://www.S-miles.com/xe/board_gBNS02/1156805
トラックバック:Americaswomenmagazine.xyz
トラックバック:Www.scullycap.com
トラックバック:Dolmie.com
トラックバック:http://Www.Website-Development.Dofollowlinks.org/News/atl-demenagement-3/
トラックバック:pede togel alternatif
トラックバック:for beginners
トラックバック:http://www.hardware.ipt.pw/News/amenagement-denis-42/
トラックバック:http://Gijangchurch.org/index.php?mid=board_UvBh53&document_srl=634974
トラックバック:Www.diywiki.org
トラックバック:Sap.Ient.ai
トラックバック:pede togel
トラックバック:redirect to Mzlgam
トラックバック:Rajabandot link Alternatif
トラックバック:Read Alot more
トラックバック:Socialrus.com
トラックバック:https://forum.Giperplasma.ru/index.php?action=profile;u=562942
トラックバック:wonplay 888
トラックバック:GEtidEALIst.cOm
トラックバック:daftar wonplay 888
トラックバック:Highly recommended Web-site
トラックバック:Checkbookmarks.com
トラックバック:https://Nxlv.ru/user/TiffanyBurgos29/
トラックバック:http://nswiki.svenskasuperserier.se/w/index.php?title=Anvndare:DannChandler379
トラックバック:wonplay 888 Slot
トラックバック:Www.process.dofollowlinks.org
トラックバック:https://classifieds.Exponentialhealth.coop/community/profile/blythemccubbin0/?email=&membersite=httpsPiedconfort.combloguepied-arque&membersignature=span+stylefont-weight:+800;La+fasciite+plantaire+est+un/span+dysfonctionnement+douloureux+du+pied+
トラックバック:http://www.glamstones.Co.kr/sub_06_01/59292
トラックバック:https://www.homecareshoppe.com/a-louer-natif-commercial-et-industriel-de-tous-genres-site-professionnel/
トラックバック:visualizá-lo agora
トラックバック:Kenpoguy.com
トラックバック:http://zjxsnj.cn/comment/html/?115564.html
トラックバック:https://45listing.com
トラックバック:antislave.com
トラックバック:Mais sugestões
トラックバック:https://heechunkim.Co.kr/board_qKHj18/287297
トラックバック:http://Gijangchurch.org/index.php?mid=board_UvBh53&document_srl=725855
トラックバック:Runsexme.ru
トラックバック:http://Rebelscon.com/profile.php?id=1612333
トラックバック:Www.beach.sbm.pw
トラックバック:Https://Kmicc.Com
トラックバック:Www.Somangchurch.org
トラックバック:https://Unitedindia.info/forums/topic/outils-de-securite-masques-chirurgical-jetable-a01400-50-unites/
トラックバック:Mediasocially.com
トラックバック:https://tvsocialnews.com/story1146180/cim-investigacin
トラックバック:https://Apeguebremariam.org/community/?wpfs=&membersite=httpsAvantisleep.comproductslivone&membersignature=76++78+pouces+de+extensif+par+quatre-vingt+pouces+de+long+pour+un+matelas++King+.+Une+chambre+principale+den+tout+a+cas+10+x+10+ft+carrs+ser
トラックバック:similar website
トラックバック:moved here
トラックバック:Www.Matthew-Morris.com
トラックバック:Bookmark-TemplaTe.COm
トラックバック:http://luennemann.org/index.php?mod=users&action=view&id=335491
トラックバック:http://Virusclan.de/index.php?mod=users&action=view&id=5145
トラックバック:wonplay 888 Login
トラックバック:Bn.trEndI.toP
トラックバック:http://Www.Die-Seite.com/index.php?a=stats&u=sharylwillilams
トラックバック:this
トラックバック:http://www.Rebelscon.com/profile.php?id=1619973
トラックバック:{Link Rajabandot}
トラックバック:https://one.new-tkf.xyz/user/MurrayOiz392052/
トラックバック:head to 7prbookmarks
トラックバック:BOUCHESOcIAl.cOm
トラックバック:http://cloud-Dev.mthmn.com/node/249941
トラックバック:http://www.photography.ipt.pw
トラックバック:https://Getidealist.com
トラックバック:https://Www.Oasiskorea.net/Brand/3818295
トラックバック:http://Theglobalfederation.org/profile.php?id=2014039
トラックバック:https://Kbookmarking.com/story15856295/hesman-garage
トラックバック:Vipsbay.Net
トラックバック:http://wikivicente.X10Host.com/index.php/Article_Title
トラックバック:http://website-development.dofollowlinks.org/News/dominique-patrice/
トラックバック:https://Ezmarkbookmarks.com/story15894521/soljit-salesforce-partner-of-your-Transformation
トラックバック:visit my web page
トラックバック:https://Bookmarkplaces.com/story15803669/couvreur-paquette
トラックバック:WwW.JEromEBarAY.Com
トラックバック:https://lingeriebookmark.com/story5370694/energa-y-sistemas
トラックバック:Allyourbookmarks.com
トラックバック:Www.radio.dofollowlinks.org
トラックバック:página da Internet
トラックバック:Baidubookmark.com
トラックバック:https://Bookmarkedblog.com/story16206641/servicios-de-transporte-terrestre-en-bogot-vanspremium
トラックバック:Our Site
トラックバック:Bookmarkmoz.com
トラックバック:http://Cloud-Dev.Mthmn.com/node/246037
トラックバック:http://Www.Zilahy.info/wiki/index.php/Pizza_Plat_D_or_Joliette_Eaterie_Opening_Several_Hours_And_Critical_Reviews
トラックバック:https://resetlifestyleproductsuk.com/communiquer-avec-le-repertoire-toxicologique-cnesst/
トラックバック:https://biowiki.clinomics.com/index.php/User:VictorinaBack
トラックバック:go to this web-site
トラックバック:onsale.Tawansmile.com
トラックバック:Avfoch.com
トラックバック:https://Bookmarklethq.com/story15874652/emprunts-d-argent-rapide-sans-enqute-de-crdit-money911
トラックバック:WwW.mISSIOnCA.OrG
トラックバック:http://Avtpoligraf.ru/content/lentrepot-du-cadre-decorations-murales
トラックバック:http://leonblog.net/member.asp?action=view&memName=Joeann91W644834395420
トラックバック:https://Bookmarkshq.com/story16930024/amnagement-denis-paysagiste–montral-laval
トラックバック:Read the Full Document
トラックバック:check over here
トラックバック:bIGMasteRLiFeStYle.Com
トラックバック:jual pbn murah
トラックバック:http://classicalmusicmp3Freedownload.com/ja/index.php?title=:Sienna2881
トラックバック:http://Cloud-Dev.Mthmn.com/node/28300
トラックバック:Http://Www.die-seite.com/index.Php?a=Stats&u=niamhsaenz383
トラックバック:jasa seo specialist
トラックバック:http://www.ruanjiaoyang.com/member.asp?action=view&memName=JerrellRomo090199101
トラックバック:Telugusaahityam.com
トラックバック:click this over here now
トラックバック:https://Bookmarkboom.com/story15774164/emprunts-d-argent-rapide-sans-enqute-de-crdit-money911
トラックバック:https://Avfoch.com/author/hanscurley4/
トラックバック:Www.geNeRATe.SBM.pw
トラックバック:http://Www.Superstitionism.com/forum/profile.php?id=230657
トラックバック:https://Hindibookmark.com/story17032998/cim-investigacin
トラックバック:https://Kmicc.com/index.php?mid=certi&document_srl=692198
トラックバック:beli backlink berkualitas
トラックバック:Login wonplay 888
トラックバック:siNGnalSocial.com
トラックバック:https://www.allclanbattles.com/
トラックバック:https://mmhsmassageme.com/index.php?page=user&action=pub_profile&id=5869306
トラックバック:https://Ztndz.com/story17526869/entrepreneur-spcialis-en-finition-de-bton-la-truelle-d-or
トラックバック:Socialbuzzmaster.com
トラックバック:https://Resetlifestyleproductsuk.com/entreposage-jcs/
トラックバック:https://Www.oasiskorea.net/Brand/3945867
トラックバック:http://calsouthchurch.org/board_Txxk18/703125
トラックバック:Cbz.Minzdravao.ru
トラックバック:rajabandot togel
トラックバック:http://Www.zilahy.Info
トラックバック:https://wiki.unionoframblers.com/index.php/Top_Machine__Glaons
トラックバック:Virusclan.de
トラックバック:Pillowcovers.sblinks.net
トラックバック:http://Www.Reform.Bookmarking.site/News/dermka-clinik-23/
トラックバック:Https://Fellowfavorite.Com/Story16570555/Hesman-Garage
トラックバック:https://wiki.vie.today/index.php?title=:MargaretaMoonlig
トラックバック:http://www.Die-seite.com/index.php?a=stats&u=wilbertnickle83
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=303864
トラックバック:https://topsearch24H.com/search/Titre+Tout+Ce+Que+Vous+Devez+Savoir+Sur+Le+Pointage+De+Crdit+Dimpt+Par+Dmnagement+De+Revenu+Qubec
トラックバック:Guideyoursocial.com
トラックバック:http://Shinyangm.com/bbs/board.php?bo_table=free&wr_id=135747
トラックバック:http://Www.Helpdesk.Ipt.pw/News/couvreur-paquette-6/
トラックバック:https://classifieds.Exponentialhealth.coop/community/?email=&membersite=httpsbeautybomb.cofrcreme-lissante-pour-cheveux&membersignature=the+fractionated+coconut+oil+absorbs+deeply+and++a+hrefhttps://beautybomb.co/fr/creme-lissante-pour-cheveux/+re
トラックバック:why not try here
トラックバック:jasa traffic organic
トラックバック:Sites2000.com
トラックバック:https://theglobalfederation.org/profile.php?id=1951441
トラックバック:http://www.website-development.dofollowlinks.Org/
トラックバック:http://theglobalfederation.org
トラックバック:website
トラックバック:http://avtpoligraf.ru/content/sen-aller-de-19-99-pour-un-protege
トラックバック:https://Kmicc.com/index.php?mid=certi&document_srl=692651
トラックバック:http://Gijangchurch.org/index.php?mid=board_UvBh53&document_srl=770164
トラックバック:Mysterybookmarks.com
トラックバック:simply click nebenwelten.net
トラックバック:https://Mediajx.com/story17161337/entrepreneur-spcialis-en-finition-de-bton-la-truelle-d-or
トラックバック:Https://Nybookmark.Com/Story17008386/AmNagement-Denis-Paysagiste–MontrAl-Laval
トラックバック:http://Die-Seite.com
トラックバック:https://infodin.Com.br/index.php/Couvreur_R_sidentiel
トラックバック:http://www.computer-science.sbm.pw/News/vicky-girouard-14/
トラックバック:http://www.consulting.bookmarking.site/News/mon-inspection-5/
トラックバック:Naturalbookmarks.com
トラックバック:http://czxawb.cn/comment/html/?70398.html
トラックバック:http://www.drsbook.co.kr/board/7253700
トラックバック:Fantasyroleplay.co
トラックバック:Www.framefounder.Com
トラックバック:pinnaclebattleship.com
トラックバック:http://S741690.Ha003.T.Justns.ru/index.php?subaction=userinfo&user=CandidaZla
トラックバック:http://Avtpoligraf.ru/content/masque-jetable-0
トラックバック:https://Breitband-Wiki.de/index.php?title=Moulin__Lame_Par_Grains_De_Caf_pices_Et_Fines_Herbes_Noir_Salton
トラックバック:http://Www.Diywiki.org/index.php/clairage
トラックバック:Www.information-Brokers.sblinks.net
トラックバック:http://Sl860.com/comment/html/?209169.html
トラックバック:https://avtpoligraf.ru/content/avis-sur-Institut-pure-excellence-1
トラックバック:pedetogel
トラックバック:https://askreader.co.uk/43084/prpar-employs-dans-mauvaise-cote-de-crdit-au-canada
トラックバック:his comment is here
トラックバック:wWw.homeCaRESHOpPe.cOM
トラックバック:http://information-Brokers.sblinks.net/News/atl-demenagement-11/
トラックバック:www.loans.ipt.pw
トラックバック:jasa seo website judi online
トラックバック:Biconsultingpro.com
トラックバック:Www.child-health.ipt.pw
トラックバック:https://pipewiki.org/app/index.php/User:CherylFultz
トラックバック:http://Jeromebaray.com/afm/wiki/index.php/Utilisateur:CristineElz
トラックバック:Forum.vkmoravia.cz
トラックバック:click the up coming website
トラックバック:Daftar Ahha4d
トラックバック:clique com o seguinte post
トラックバック:Wiki.Bigtata.Org
トラックバック:pede togel link alternatif
トラックバック:http://Afcantarelle.org/index.php?title=User:KandisRae5239
トラックバック:http://Sh.Ri.L.Lw.Q.Zu@nkuk21.co.uk/?document_srl=7542851
トラックバック:clique para investigar
トラックバック:jasa seo backlink
トラックバック:http://www.Die-Seite.com/index.php?a=stats&u=harlanbirnie
トラックバック:onlinEsChooL.BOOkmArkiNg.SItE
トラックバック:http://Fridayad.in/user/profile/1969771
トラックバック:Www.sports.bookmarking.site
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1542942
トラックバック:https://Okniga.org/user/FannieLandry/
トラックバック:http://theglobalfederation.org/profile.php?id=2033074
トラックバック:jasa backlink bergaransi
トラックバック:you could check here
トラックバック:https://Bookmarketmaven.com/story15993250/entrepreneur-spcialis-en-finition-de-bton-la-truelle-d-or
トラックバック:Modernizacion.Archivonacional.cl
トラックバック:https://Www.Vander-horst.nl/wiki/User:KrystalNies
トラックバック:Wisma bet login judi
トラックバック:https://Www.kenpoguy.com/phasickombatives/profile.php?id=1435381
トラックバック:http://sl860.com/comment/html/?291502.html
トラックバック:Https://Rnma.Xyz/
トラックバック:http://www.Zjxsnj.cn/comment/html/?167669.html
トラックバック:https://Dzliprojects.wiki/index.php/User:Eugenio48A
トラックバック:https://apeguebremariam.org/community/?wpfs=&membersite=httpsamenagementdenis.comexpert-en-toit-terrasse-a-vimont&membersignature=Lamnagement+paysager+fait+partie+importante+de+lentretien+hors+de+votre+possession+que+vous+soyez+propritaire+dune+ma
トラックバック:https://Throbsocial.com/story17291968/cim-investigacin
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1548051
トラックバック:https://enableelearn.com/?s=&post_type=courses&membersite=httpsFlorilegejardinerie.comboutiquepilea-peperomioides-2-5po&membersignature=uEn+plus+dapporter+dune/u+fracheur+et+du+saveur++vos+plats+ou+vos+boissons+ces+cultures+embaument+la+Maison
トラックバック:http://www.agchem.co.kr/freeboard/1754551
トラックバック:http://www.engineering.dofollowlinks.org/news/couvreur-paquette-7/
トラックバック:Offwiki.Org
トラックバック:agen cuan
トラックバック:jual jasa backlink murah
トラックバック:http://diywiki.org/index.php/User:LaverneBeverly
トラックバック:https://Weakfantasy.de/index.php/Photographie_Rajeunissement_Et_Boutons_Thermage_Lvres_Pulpeuses_Ulthera_Et_Thermocoagulation
トラックバック:Worldlistpro.Com
トラックバック:https://Drclydewilson.com/community/?wpfs=&membersite=httpsUnick.ca&membersignature=span+stylefont-style:+italic;Nos+routines+de+nettoyage+et/span+nos+cours+de+qualit+nous+donnent+une+socit+parfaite+et+efficacement+huile.+Le+contrle+qualit+de+notr
トラックバック:http://Forum.Prolifeclinics.ro/profile.php?id=10934
トラックバック:https://Okniga.org/user/SusanneNewell1/
トラックバック:Www.guidemagazine.org
トラックバック:jasa backlink pbn judi
トラックバック:https://Wiki.freeneuropathology.org/index.php?title=Article_Title
トラックバック:https://manu-Auare.ru/estelacambag
トラックバック:http://Www.Zjxsnj.cn/comment/html/?170885.html
トラックバック:https://Wiki.rr206.de/index.php?title=Benutzer:Maureen24Q
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1550340
トラックバック:Going On this site
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1542814
トラックバック:Http://Luennemann.Org/Index.Php?Mod=Users&Action=View&Id=346897
トラックバック:Read This method
トラックバック:jasa backlink website
トラックバック:their website
トラックバック:Getsocialpr.Com
トラックバック:simply click the up coming post
トラックバック:https://Binary.Copy-Trade.fun/?qa=319685/boucle-doreille-enfant
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1548766
トラックバック:https://bookmarkwuzz.com/story15901391/gelka-soluciones
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1556102
トラックバック:http://Www.Online-Teaching.Sblinks.net/out/dominique-patrice-15/
トラックバック:jasa halaman 1 google
トラックバック:https://King.az/user/AlbertoRagland8/
トラックバック:cuan slot 88
トラックバック:over here
トラックバック:https://trabalhadoresindependentes.com/author/peggy52690/
トラックバック:Www.fantasyroleplay.co
トラックバック:Www.Driftpedia.Com
トラックバック:https://moravian.Bucknell.edu/transcriptions/index.php?title=Entretien_M_nager_R_sidentiel_Et_Industriel__Montr_al
トラックバック:Https://Okniga.Org
トラックバック:backlink judi
トラックバック:http://luennemann.org/index.php?mod=users&action=view&id=347520
トラックバック:https://Bookmarkpressure.com/story15826866/cim-investigacin
トラックバック:http://die-Seite.com/index.php?a=stats&u=lavadalin4373
トラックバック:http://www.hospitality.Dofollowlinks.org/News/couvreur-paquette-11/
トラックバック:https://Zvukiknig.cc/user/Alexandra5186/
トラックバック:http://luennemann.org/index.php?mod=users&action=view&id=347745
トラックバック:Www.trimmers.Ipt.pw
トラックバック:https://Bookmarkja.com/story17138271/soljit-salesforce-partner-of-your-transformation
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1545791
トラックバック:beli backlink murah
トラックバック:Live4Christnetworks.Com
トラックバック:http://Cloud-Dev.Mthmn.com/node/284519
トラックバック:https://Sites2000.com/story5260724/emprunts-d-argent-rapide-sans-enqute-de-crdit-money911
トラックバック:sneak a peek at this website
トラックバック:jasa page one google
トラックバック:new content from socialbookmarkgs.com
トラックバック:https://Okniga.org/user/DeneseRamsbotham/
トラックバック:Throbsocial.com
トラックバック:Hubwebsites.com
トラックバック:https://Connectngrow.org/myforum/profile.php?id=66916
トラックバック:Todaybookmarks.com
トラックバック:https://Outhistory.wwu.edu/wiki/User:VirginiaCoombe
トラックバック:jasa backlink berkualitas
トラックバック:visit Mnobookmarks`s official website
トラックバック:http://qzfczs.com/comment/html/?316403.html
トラックバック:Https://maga.Wiki
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1550757
トラックバック:https://wiki.hstkb.sch.id/index.php?qa=30366&qa_1=obtenir-un-prt-dargent-pas-de-enqute-de-pointage-de-crdit
トラックバック:content
トラックバック:https://wiki.vie.today/index.php?title=Delicacies_Moderne_Review_Choisir_L_Ensemble_Des_Meubles_Tout_Autant_Que_Armoires_Sobre_Cuisine
トラックバック:http://luennemann.org/index.php?mod=users&action=view&id=346926
トラックバック:http://Www.zjxsnj.cn/comment/html/?169661.html
トラックバック:https://Maga.wiki/index.php/User:JasperKrier6
トラックバック:http://www.Die-seite.com
トラックバック:http://Xiamenyoga.com/comment/html/?185890.html
トラックバック:Continued
トラックバック:Classifieds.Exponentialhealth.coop
トラックバック:http://Qzfczs.com/comment/html/?321592.html
トラックバック:http://Www.gotanproject.net/node/22461012?—————————98926205Content-Disposition:form-data;name=titleOreillerPourUnAideDansToutesLesPositionsDeSommeil—————————98926205Content-Disposition:form-data;name=bodyspanstyle=font-
トラックバック:https://brilliantcollections.com/pneu-et-jante/
トラックバック:https://Domainnamesseo.com/listing/emprunts-dargent-rapide-sans-enquete-de-credit-money911-532917
トラックバック:Bookmarknap.com
トラックバック:http://die-seite.com/index.php?a=stats&u=dwight5585
トラックバック:http://drsbook.Co.kr/board/6413491
トラックバック:Portal.Virtueliving.org
トラックバック:http://www.die-Seite.com/index.php?a=stats&u=dhedino8989347
トラックバック:http://Register.Ipt.pw/News/ott-official-25/
トラックバック:look at this now
トラックバック:http://Cloud-Dev.Mthmn.com/node/297332
トラックバック:http://Cloud-Dev.mthmn.com/node/300067
トラックバック:http://www.die-seite.com/index.php?a=stats&u=shayna51l8244175
トラックバック:Madbookmarks.com
トラックバック:moravian.Bucknell.Edu
トラックバック:Growthbookmarks.com
トラックバック:Wiishlist.com
トラックバック:http://gijangchurch.org/index.php?mid=board_UvBh53&document_srl=1087243
トラックバック:http://forum.prolifeclinics.ro/profile.php?id=155999
トラックバック:https://onsale.tawansmile.com/index.php?action=profile;u=12212
トラックバック:http://luennemann.org/index.php?mod=users&action=view&id=353152
トラックバック:Learn More Here
トラックバック:https://Www.imdipet-Project.eu/groupes/embracing-canadian-culture-a-guide-to-canadian-cultural-events/
トラックバック:http://Www.Sxlopw.cn/comment/html/?237096.html
トラックバック:http://cloud-Dev.mthmn.com/node/304394
トラックバック:http://virusclan.de/index.php?mod=users&action=view&id=21901
トラックバック:https://Nxlv.ru/user/LawannaStell/
トラックバック:https://blog.Isoc.sn/?option=com_k2&view=itemlist&task=user&id=3353813
トラックバック:Http://Www.Drsbook.Co.Kr/Board/7288946
トラックバック:UK IMMIGRATION LAWYER IN US
トラックバック:https://mzlgam.com/index.php?action=profile;u=124061
トラックバック:jual jasa backlink
トラックバック:thebookmarkid.com
トラックバック:https://Resetlifestyleproductsuk.com/emplois-par-entretien-menager/
トラックバック:Www.kmicc.com
トラックバック:Http://God-999.com/board_ysKC49/713098
トラックバック:Megashop.work
トラックバック:https://apeguebremariam.org/community/?wpfs=&membersite=httpspoupartsyndic.caconsolidation-dettesqcsainte-therese&membersignature=Sous-titres+:pnbsp;/ppnbsp;/p+1.+Pourquoi+votre+cote+de+crdit+est+importante+par+payer+de+fric+pour+une+hypothquepnbs
トラックバック:Sigmachiiu.com
トラックバック:Mariskamast.net
トラックバック:Http://Detroitwomenmag.Xyz/Blogs/Viewstory/152296
トラックバック:https://Illinoisbay.com/user/profile/6244207
トラックバック:Http://www.Rebelscon.com
トラックバック:http://Gijangchurch.org/index.php?mid=board_UvBh53&document_srl=1096901
トラックバック:Https://www.Kmicc.com
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1548437
トラックバック:https://Isotrope.cloud/index.php/User:DeeGye746334484
トラックバック:Thekiwisocial.com
トラックバック:Fastwitchfitness.com
トラックバック:http://www.shavers.sblinks.net/News/ott-official-12/
トラックバック:click the up coming web site
トラックバック:Bookmarkingalpha.com
トラックバック:http://www.die-seite.com/index.php?a=stats&u=darcyelmore27
トラックバック:http://Cloud-Dev.Mthmn.com/node/326167
トラックバック:https://Okniga.org/user/CierraWoodfull4/
トラックバック:Https://Techonpage.Com/Story1182799/Cuisines-Denis-Couture
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1597380
トラックバック:Bookmarkbirth.com
トラックバック:http://Canamkart.ca/index.php?page=user&action=pub_profile&id=1732914
トラックバック:http://cloud-dev.mthmn.com/node/282833
トラックバック:http://www.zjxsnj.cn/comment/html/?189956.html
トラックバック:please click the following internet site
トラックバック:please click the following article
トラックバック:https://Classifieds.Exponentialhealth.coop/community/?email=&membersite=httpspaisi.caencollectionspillows&membersignature=lanalyse+de+ltude+a+t+ralise+dans+le+monde+entier+et+prsente+actuelles+et+traditionnelles+de+lexpansion+de+lanalyse+analyse+d
トラックバック:look at these guys
トラックバック:https://heechunkim.co.kr/board_qKHj18/244243
トラックバック:Highly recommended Internet site
トラックバック:Https://Socialmphl.Com
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1551578
トラックバック:https://Dailybookmarkhit.com/story15939423/hesman-garage-boucherville
トラックバック:http://www.Die-seite.com/index.php?a=stats&u=stephanywillard
トラックバック:22446688.Cn
トラックバック:https://motline.com/index.php?mid=rent_counseling&document_srl=2667719
トラックバック:https://virus.Win32.wiki/wiki/Btisse_Commerciale
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1547414
トラックバック:https://Manu-auare.ru/madeleinerup
トラックバック:http://Virusclan.de/index.php?mod=users&action=view&id=22964
トラックバック:http://Www.customer-service.sblinks.net/News/amenagement-denis-80/
トラックバック:Kcwomenmag.xyz
トラックバック:Atozbookmarkc.com
トラックバック:Listingpanda.ca
トラックバック:Thefairlist.com
トラックバック:http://www.gotanproject.net/node/22488259?—————————716503764792556Content-Disposition:form-data;name=titleSpcialistesDeLaAmliorationDeL’habitatAmliorationDeL’habitatAceh—————————716503764792556Content-Disposition:form
トラックバック:http://www.hardware.sbm.pw/out/ott-official-19/
トラックバック:Socialclubfm.com
トラックバック:recent post by Cloud-Dev.Mthmn.com
トラックバック:http://Hospitality.dofollowlinks.org/user/carleycuni/
トラックバック:Bookmarkspedia.com
トラックバック:http://Virusclan.de/index.php?mod=users&action=view&id=22082
トラックバック:bookmarkmiracle.com
トラックバック:http://www.Jeromebaray.com/afm/wiki/index.php/Prt_Futur_Entrepreneur
トラックバック:http://Ruanjiaoyang.com/member.asp?action=view&memName=LarryKauffmann02
トラックバック:https://luxuriousrentz.Com/Create-an-exquisite-backyard-Terrace-a-perfect-outdoor-retreat
トラックバック:https://centrofreire.com/blog/index.php?entryid=24999
トラックバック:Suggested Web page
トラックバック:http://oxm.tw/xoops/modules/profile/userinfo.php?uid=795695
トラックバック:https://Www.Imdipet-Project.eu/groupes/finding-your-dream-home-a-guide-to-the-best-homes-magazines-in-canada/
トラックバック:Worldsocialindex.com
トラックバック:https://oneability.ca/forums/topic/developing-an-effective-engagement-plan-with-salesforce/
トラックバック:wwW.GLaMsTOneS.Co.KR
トラックバック:Mountainrootsonline.com
トラックバック:Enableelearn.com
トラックバック:http://www.Zjxsnj.cn/comment/html/?195358.html
トラックバック:Bookmarksknot.com
トラックバック:http://Zjxsnj.cn/comment/html/?187613.html
トラックバック:click the up coming website page
トラックバック:http://Demos.gamer-Templates.de/specialtemps/clansphere20114Sdemo01/index.php?mod=users&action=view&id=5890326
トラックバック:https://fellowfavorite.com/story16643671/servicios-de-transporte-terrestre-en-bogot-vanspremium
トラックバック:go directly to cloud-dev.mthmn.com
トラックバック:click the up coming webpage
トラックバック:http://cloud-dev.mthmn.com/node/321807
トラックバック:please click the next document
トラックバック:https://Wiki.nerdbird.media/index.php?title=User:JennyAddis084
トラックバック:http://wiki.quanticsystems.com.br/index.php/User:Edison9263
トラックバック:Www.islandcrowd.com
トラックバック:http://latenitetip.com/index.php?page=user&action=pub_profile&id=44456
トラックバック:read more
トラックバック:http://ruanjiaoyang.com/member.asp?action=view&memName=CamillaLevering
トラックバック:http://Www.Rebelscon.com/profile.php?id=1633698
トラックバック:https://Zvukiknig.cc/user/WilfredoUther/
トラックバック:more tips here
トラックバック:http://Gedankengut.one/
トラックバック:https://Www.Kenpoguy.com/phasickombatives/profile.php?id=1450844
トラックバック:https://Morphonic-Records.com/community/profile/arnulfoolivarez/
トラックバック:https://Lingeriebookmark.com/story5425063/soljit-salesforce-partner-of-your-transformation
トラックバック:Http://dallaswomenmag.Xyz/
トラックバック:http://Demos.Gamer-Templates.de/specialtemps/clansphere20114Sdemo01/index.php?mod=users&action=view&id=5891615
トラックバック:jasa backlink murah berkualitas
トラックバック:https://telearchaeology.org/TAWiki/index.php/User:Louise82Q15208
トラックバック:http://Www.Gotanproject.net/node/22489394?—————————40225344335Content-Disposition:form-data;name=titleMdecinsDeMnageLaval—————————40225344335Content-Disposition:form-data;name=bodyEtquecesoitounontoutefoisunerfrencepour
トラックバック:http://Virusclan.de/index.php?mod=users&action=view&id=23080
トラックバック:bookmarkbooth.com
トラックバック:http://Die-Seite.com/index.php?a=stats&u=florene08m
トラックバック:getsoCialSoUrCe.COm
トラックバック:Demos.Gamer-Templates.De
トラックバック:http://Www.Die-Seite.com/index.php?a=stats&u=antwanmorisset5
トラックバック:Dftsocial.com
トラックバック:http://Saju.codeway.kr/index.php/Enseignes_Commerciales_Auvent_Afficheurs_Del_Et_Lettre_Channel
トラックバック:http://Forum.Prolifeclinics.ro/profile.php?id=163534
トラックバック:helpful hints
トラックバック:sneak a peek at this web-site.
トラックバック:click for more info
トラックバック:https://Www.Oasiskorea.net/Brand/4962765
トラックバック:https://Xdpascal.com/index.php/User:Sang46Z63123577
トラックバック:https://Www.Homecareshoppe.com/kidicomfort-matelas-matelas-facile-coton-naturel/
トラックバック:www.Xjykj.Cn
トラックバック:http://Virusclan.de/index.php?mod=users&action=view&id=23730
トラックバック:ELEARNing.hCBEAuTy.CoM
トラックバック:https://pr7bookmark.com/story15994599/vanspremium
トラックバック:https://Brilliantcollections.com/fifty-three-meilleures-idees-sur-revetement-mur/
トラックバック:https://apeguebremariam.org/community/?wpfs=&membersite=httpsGoodlifeloan.compret-sans-enquete&membersignature=2+to+3+repayments+can+be+found+primarily+based+on+your+pay+frequency+at+no+further+price+or+charges+up+to+62+days.+When+you+apply+for+ca
トラックバック:https://Www.imdipet-project.eu
トラックバック:https://Nimmansocial.com/story5300028/papeterie-gilbert-jeux-a-g
トラックバック:http://Wiki.Moebius.Com.br/index.php/Pourquoi_Mis_Sur_Des_Images_Sur_Mon_Site_Web
トラックバック:http://Qzfczs.com/comment/html/?331646.html
トラックバック:https://Www.Oasiskorea.net/Brand/5037330
トラックバック:http://Www.Zjxsnj.cn/comment/html/?191612.html
トラックバック:https://Classifieds.Exponentialhealth.coop/community/profile/wbfiris11069659/?email=&membersite=httpspoupartsyndic.caproposition-de-consommateur-a-plan-bouchard&membersignature=img+srchttps://p.turbosquid.com/ts-thumb/tj/uUQi5U/ZILMjHWa/a1720002/j
トラックバック:what is it worth
トラックバック:https://Socialbookmarkgs.com/story15923640/emondage-prestige
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=347758
トラックバック:on the main page
トラックバック:Continue Reading
トラックバック:jasa seo slot
トラックバック:https://bookmarkbirth.com/story15274954/naturothrapie–laval-mackandal
トラックバック:simply click the following page
トラックバック:https://Socialmediainuk.com/story15804313/entrepreneur-en-construction
トラックバック:https://aproblemsquaredwiki.com/User:NPIBerry2386
トラックバック:https://Okniga.org/user/ClemmieCheyne/
トラックバック:http://gijangchurch.org/index.php?mid=board_UvBh53&document_srl=1182127
トラックバック:https://bookmark-vip.com/story15904413/Dermka-clinik
トラックバック:Https://Classifieds.Exponentialhealth.Coop
トラックバック:https://Thefairlist.com/story5610961/bpc
トラックバック:Finopsfirst.org
トラックバック:https://onlybookmarkings.com/story15903081/cuisines-denis-couture
トラックバック:https://Socialrator.com/story5736502/roi-recreation-outfitters
トラックバック:http://Cloud-dev.mthmn.com/node/285577
トラックバック:http://Raleighwomenmag.xyz
トラックバック:http://cloud-dev.Mthmn.com/node/340072
トラックバック:https://infodin.com.br/index.php/User:CaraStevenson0
トラックバック:Bookmarkshut.Com
トラックバック:http://www.xjykj.cn/comment/html/?435350.html
トラックバック:http://Gotanproject.net/node/22494420?—————————326766121Content-Disposition:form-data;name=titleRenouvellementdePrtHypothcaire:CommentMettreJourVotrePrt—————————326766121Content-Disposition:form-data;name=bodyimgsrc=htt
トラックバック:https://Yoga.wiki/index.php/User:JaiPagan25494
トラックバック:http://Forum.Prolifeclinics.ro/profile.php?id=163837
トラックバック:https://Sparxsocial.com/story5690253/naturothrapie–laval-mackandal
トラックバック:https://Sustainabilipedia.org/index.php/User:AbbyFerretti
トラックバック:http://Gotanproject.net/node/22491036?—————————1746084100809Content-Disposition:form-data;name=titleTitre:Conseilspourunbondmnagementetunebonneinstallation—————————1746084100809Content-Disposition:form-data;name=bodyUnd
トラックバック:https://Okniga.org/user/AmyS421089246438/
トラックバック:mouse click the following article
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=354927
トラックバック:http://Gijangchurch.org/index.php?mid=board_UvBh53&document_srl=1236618
トラックバック:Johsocial.com
トラックバック:just click the following post
トラックバック:Telebookmarks.com
トラックバック:https://king.az/user/OlenStobie40/
トラックバック:https://Bookmarksurl.com/story1194483/spcialistes-du-dmnagement-atl
トラックバック:click the up coming web page
トラックバック:http://www.khaan.net/process/526387
トラックバック:click through the next webpage
トラックバック:https://Wiki.sports-5.ch/index.php?title=Anick_Snyder_Micropigmentation_Lashes__Heyspa_Ca
トラックバック:https://www.kmicc.com/index.php?mid=certi&document_srl=1368105
トラックバック:https://socialbuzzfeed.com/story1213811/hesman-garage-boucherville
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1544934
トラックバック:https://Bookmark-dofollow.com/story17390529/reinco
トラックバック:SociAlmPhL.Com
トラックバック:internet
トラックバック:http://theglobalfederation.org/profile.php?id=2045226
トラックバック:here are the findings
トラックバック:https://get-social-now.com/story1136254/naturothrapie–laval-mackandal
トラックバック:Exactlybookmarks.com
トラックバック:Www.science.sblinks.net
トラックバック:Topsearch24H.com
トラックバック:https://thekiwisocial.com/story1285656/soljit-salesforce-partner-of-your-transformation
トラックバック:https://Pipewiki.org/app/index.php/User:LemuelMesa37
トラックバック:http://www.die-seite.com/index.php?a=stats&u=hxrthalia8
トラックバック:redirect to Www.die-Seite.com
トラックバック:http://www.Sxlopw.cn/comment/html/?243279.html
トラックバック:https://Bookmarketmaven.com/story16018763/tres-amigos-outfitters
トラックバック:Letusbookmark.com
トラックバック:http://Www.Gotanproject.net/node/22496604?—————————9065305965Content-Disposition:form-data;name=titleLaFormationenNaturopathieLaval:UnParcoursVersuneApprocheNaturelled’uneSant—————————9065305965Content-Disposition:form
トラックバック:http://cloud-Dev.mthmn.com/node/311426
トラックバック:https://social-Medialink.com/story1204261/naturothrapie–laval-mackandal
トラックバック:http://www.Images.bookmarking.site/News/emondage-prestige-23/
トラックバック:https://letusbookmark.com/story17051609/plus-pour-les-planchers-more-4-floors
トラックバック:Learn Alot more
トラックバック:http://God-999.com/board_ysKC49/863513
トラックバック:https://Isotrope.cloud/index.php/User:BarbraLove57
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1600894
トラックバック:mouse click the up coming web site
トラックバック:http://Saju.codeway.kr/index.php/User:WinnieMarina813
トラックバック:Bookmark-share.com
トラックバック:https://Socialskates.com/story16572875/magik-loans
トラックバック:http://qzfczs.com/comment/html/?322504.html
トラックバック:https://classifieds.exponentialhealth.coop/community/profile/eloycrombie3602/?email=&membersite=httpsMichelbergeronrenovations.comvilleboucherville&membersignature=Des+serrures+et+poignes+par+tous+les+budgets+mettant+ainsi+la+touche+finale++votre+
トラックバック:www.Khaan.net
トラックバック:click the next internet site
トラックバック:http://Cloud-dev.Mthmn.com/node/352596
トラックバック:https://Mbsre.com/forums/users/torstensanderson/
トラックバック:https://Sparxsocial.com/story5706136/transactions-immobilires–gatineau-dominique-patrice
トラックバック:https://throbsocial.com/story17319751/construction-labrie
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1594526
トラックバック:https://www.Offwiki.org/wiki/User:LilaPagan27247
トラックバック:https://procesal.cl/index.php/User:RoseannaHenderso
トラックバック:https://Bookmarkboom.com/story15832071/xnon-enseignes-clairage
トラックバック:visit the next web site
トラックバック:Https://Sustainabilipedia.Org
トラックバック:https://Taupi.org/index.php?title=User:Nannie11T7
トラックバック:https://Checkbookmarks.Com
トラックバック:Www.23ebook.com
トラックバック:www.imdipet-project.Eu
トラックバック:http://demos.gamer-templates.de/specialtemps/clansphere20114Sdemo01/index.php?mod=users&action=view&id=5893705
トラックバック:https://Travialist.com/story5694597/mackandal
トラックバック:http://Gotanproject.net/node/22500465?—————————92559051679405696Content-Disposition:form-data;name=titleSanctionparl’abattaged’boissansautorisationlgale—————————92559051679405696Content-Disposition:form-data;name=body
トラックバック:Www.Ruanjiaoyang.com
トラックバック:https://rnma.Xyz
トラックバック:http://sdswrj.cn/comment/html/?32468.html
トラックバック:check here
トラックバック:https://my-social-Box.com/story1187766/tailored-suit-paris
トラックバック:simply click the following internet page
トラックバック:jasa backlink murah dan berkualitas
トラックバック:https://Bookmarkstumble.com/story17100008/oregon-lemon-law
トラックバック:Tripsbookmarks.com
トラックバック:http://www.records-research.sblinks.net/News/atl-demenagement-9/
トラックバック:https://Classifieds.Exponentialhealth.coop/community/?email=&membersite=httpsapplicationmp.compre-traitement-au-phosphate-de-fer-a-sainte-therese&membersignature=img+srchttps://img-new.cgtrader.com/items/4189082/e94ff5edb8/large/eagle-of-saint-joh
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1642019
トラックバック:socialmediastore.net
トラックバック:http://forum.prolifeclinics.ro/profile.php?id=170379
トラックバック:Jasa Followers Threads
トラックバック:http://www.register.sbm.pw/News/la-bouticaire-32/
トラックバック:http://www.gedankengut.one/index.php?title=User:ReggiePlate587
トラックバック:http://Theglobalfederation.org/profile.php?id=2039574
トラックバック:https://Bookmarkport.com/story17376288/entrepreneur-en-construction
トラックバック:http://Www.Dictionary.Sblinks.net/News/montreal-outdoor-living-30/
トラックバック:livEBackPaGe.COM
トラックバック:http://Gotanproject.net/node/22502005?—————————888846604Content-Disposition:form-data;name=titleLespnalitspsychologiquesd’undmnagement:commentlesanticiperetlesrcuprerde—————————888846604Content-Disposition:form-data;na
トラックバック:https://www.oasiskorea.net/Brand/5260418
トラックバック:Kingslists.com
トラックバック:http://www.Bestsermonoutlines.com/recherche-de-personnes-dentreprises-et-recherche-par-numero-de-telephone/
トラックバック:https://bookmarkshq.com/story17025906/crystal-dreams-world
トラックバック:Read the Full Post
トラックバック:http://cloud-dev.mthmn.com/node/305598
トラックバック:http://Cloud-Dev.Mthmn.Com/node/363047
トラックバック:http://Www.Records-Research.Sblinks.net/News/denta-especialidades-4/
トラックバック:https://bgmcd.co.uk/index.php?title=User:CorazonPresley9
トラックバック:http://www.rebelscon.com/profile.php?id=1648096
トラックバック:http://Cloud-dev.mthmn.com/node/366868
トラックバック:https://Www.imdipet-Project.eu/groupes/getting-older-and-seniors-care/
トラックバック:https://Sigmachiiu.com/forums/users/alyciaeisenhauer/
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1647217
トラックバック:http://cloud-dev.mthmn.com/node/366012
トラックバック:Sdswrj.cn
トラックバック:http://www.Die-seite.com/index.php?a=stats&u=geraldinearce10
トラックバック:https://Marketqna.com/community/?wpfs=&membersite=httpsclinicamaxidental.comimplantes-dentales&membersignature=span+styletext-decoration:+underline;Los+implantes+dentales+ofrecen/span+span+stylefont-style:+italic;una+resolucin+duradera+y/span+span
トラックバック:http://Qzfczs.com/comment/html/?334288.html
トラックバック:click through the up coming website
トラックバック:Dirstop.com
トラックバック:Read Zilahy
トラックバック:Recommended Internet page
トラックバック:learn more about Gotanproject
トラックバック:click here to investigate
トラックバック:https://Bookmarkingdelta.com/story15892956/cim-investigacin
トラックバック:https://Zvukiknig.cc/user/KandiceMosman/
トラックバック:tHeJIllisT.coM
トラックバック:relevant internet site
トラックバック:https://Apeguebremariam.org/community/?wpfs=&membersite=httpsAtldemenagement.comdeplacement-lourd-a-saint-hyacinthe&membersignature=Le+dmnagement+pourrait+tre+une+exprience+coteuse+surtout+si+vous+ne+savez+pas+exactement+ce+que+vous+devez+payer+et
トラックバック:https://bgmcd.co.uk/index.php?title=User:FaustoDHage336
トラックバック:bookmarkforce.com
トラックバック:Http://Pittsburghwomenmag.Xyz/blogs/viewstory/101313
トラックバック:Johsocial`s blog
トラックバック:https://Bookmarkingace.com/story15880131/hesman-garage-boucherville
トラックバック:http://www.Trimmers.Ipt.pw
トラックバック:http://cloud-Dev.mthmn.com/node/372811
トラックバック:https://Bookmarksknot.com/story17175385/magik-loans
トラックバック:Click That Link
トラックバック:missionca.Org
トラックバック:https://Www.mtmoa02.Net/mtreport/566628
トラックバック:view website
トラックバック:http://Www.gotanproject.net/node/22503259?—————————49201682Content-Disposition:form-data;name=titleTerreauPourCactusEtCulturesGrasses—————————49201682Content-Disposition:form-data;name=bodyFirementconuparSimplisticsToro
トラックバック:Http://Www.Gedankengut.One/Index.Php?Title=User:OllieRanieri325
トラックバック:http://Www.Superstitionism.com/forum/profile.php?id=437170
トラックバック:Thebookmarkage.com
トラックバック:https://Gamesfashionarchive.net/wiki/User:JonnaMeyer3
トラックバック:Going to God 999
トラックバック:https://Portal.virtueliving.Org
トラックバック:a cool way to improve
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1601051
トラックバック:http://siremifasol.chez.com/modules/profile/userinfo.php?uid=3923163
トラックバック:https://www.kenpoguy.Com
トラックバック:http://cloud-dev.mthmn.com/node/17790
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1641133
トラックバック:Bookmarkja.com
トラックバック:https://Onsale.Tawansmile.com/index.php?action=profile;u=8861
トラックバック:http://Www.gotanproject.net/node/22503031?—————————363006506862162Content-Disposition:form-data;name=titlePorteCabanonAchetezOuVendezDesBiens,BilletsOuGadgetsTechnosDansQubecPetitesAnnoncesDeKijiji—————————3630065068621
トラックバック:http://cloud-dev.Mthmn.com/node/15858
トラックバック:Www.Register.Sblinks.net
トラックバック:https://zvukiknig.cc/user/HULJennie4692001/
トラックバック:http://zjxsnj.cn/comment/html/?210035.html
トラックバック:Mysocialquiz.com
トラックバック:Https://portal.Virtueliving.org/profile_info.php?ID=64165
トラックバック:https://1usaclassifieds.com/author/dominicofly/
トラックバック:https://Bookmarkbells.com/story15976597/americanos
トラックバック:http://Www.Dqyjs.cn/comment/html/?5973.html
トラックバック:Www.customer-service.sblinks.net
トラックバック:http://wiki.start2study.ru/index.php?title=Supports_D__crans
トラックバック:http://gotanproject.net/node/22506553?—————————49350973content-disposition:form-data;name=titlepanneauxmurauxenbois,prfinietplusrno-dpt—————————49350973content-disposition:form-data;name=bodylesrevtementsmurauxsontdispo
トラックバック:http://Www.fantasyroleplay.co/wiki/index.php/User:Connor4683
トラックバック:http://www.weather.Sbm.pw/out/kitchen-cabinets-3/
トラックバック:Https://Classifieds.Exponentialhealth.Coop/Community/Profile/Andreaswhitlock/?Email=&Membersite=Httpsmackandalnaturotherapie.Comcontactnaturotherapie-A-Champfleury&Membersignature=La+ThRapie+De+DSintoxication+Au+QuBec+Offre+Un+Soutien+CompTent+Ess
トラックバック:http://www.gotanproject.net/node/22505061?—————————507976181384566Content-Disposition:form-data;name=titleTerreauPremiumParVertsEtFinesHerbesPro-mix2Pi18,1KgPromix7042476—————————507976181384566Content-Disposition:form-
トラックバック:https://Bgmcd.Co.uk/index.php?title=Les_Armoires
トラックバック:hop over to this site
トラックバック:visit the following webpage
トラックバック:HINdIbOOKMarK.COM
トラックバック:go to the website
トラックバック:had me going
トラックバック:Http://888.Lililian.Com/Comment/Html/?157781.Html
トラックバック:https://checkbookmarks.com/story1242671/cim-investigacin
トラックバック:https://biowiki.clinomics.com/index.php/User:MonroeKay459
トラックバック:Http://Www.Zjxsnj.Cn/Comment/Html/?186244.Html
トラックバック:http://www.Science.Sblinks.net/News/la-bouticaire-32/
トラックバック:http://Www.Superstitionism.com/forum/profile.php?id=440347
トラックバック:http://www.management.bookmarking.site/News/la-bouticaire-23/
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1641519
トラックバック:Www.1Usaclassifieds.com
トラックバック:https://Bookmark-Nation.com/story15814526/transactions-immobilires–gatineau-dominique-patrice
トラックバック:http://www.Dqyjs.cn/comment/Html/?7813.html
トラックバック:https://classifieds.ocala-news.com/author/karenstiltn
トラックバック:Socialskates.com
トラックバック:http://afcantarelle.org/index.php?title=Volkswagen_Diesel_Settlements_Environmental_Mitigation
トラックバック:mouse click the up coming internet site
トラックバック:https://infodin.com.br/index.php/User:EarthaConley23
トラックバック:https://taupi.org/index.php?title=User:GuadalupeCutlack
トラックバック:Full Document
トラックバック:Hylistings.com
トラックバック:simply click the following post
トラックバック:https://enableelearn.com/?s=&post_type=courses&membersite=httpsDermkaclinik.comenhow-to-get-rid-of-cellulite&membersignature=Lux+bar++ongles+et+esthtique+offre+un+service+ultra+professionnel+et+chaleureux.+Vous+pourrez+y+recevoir+une+manucure+
トラックバック:https://Trabalhadoresindependentes.com/author/angie64v684/
トラックバック:http://Wiki.Rl-transport.org/index.php/User:RashadZof9033432
トラックバック:Www.real-estate.dofollowlinks.org
トラックバック:cinnamon roll icing recipe
トラックバック:http://Www.property.sblinks.net/News/amenagement-denis-178/
トラックバック:https://Mediajx.com/story17225624/bpc
トラックバック:https://mysocialport.com/story1235761/hesman-garage
トラックバック:https://www.Imdipet-Project.eu/groupes/comment-trouver-un-demenageur-a-petit-prix/
トラックバック:i thought about this
トラックバック:Bbsocialclub.com
トラックバック:https://Kirkesimports.com/?s=&post_type=product&membersite=httpsWww.Solutions-G00.comserviceslusinage-cnc&membersignature=Darrell+researched+what+was+needed+and+obtained+again+to+us+rapidly+with+several+superb+options.+Once+we+selected+which+c
トラックバック:pr7bookmark.com
トラックバック:https://Mysitesname.com/story5428500/la-bouticaire
トラックバック:http://Cloud-Dev.Mthmn.com/node/387321
トラックバック:https://Procesal.cl/index.php/User:RomaineShepherds
トラックバック:Top100Bookmark.com
トラックバック:https://kaidan136.com/index.php?title=:PVEMyrtle2
トラックバック:http://www.die-seite.com/index.php?a=stats&u=danutae396
トラックバック:Social-Lyft.com
トラックバック:www.smart-PriCe.sblinks.NeT
トラックバック:http://luennemann.org/index.php?mod=users&action=view&id=364617
トラックバック:Https://Wiki.Team-Glisto.Com
トラックバック:https://Wiki.sports-5.ch/index.php?title=utilisateur:effieguess
トラックバック:www.arts-and-entertainment.ipt.pw
トラックバック:http://superstitionism.com/forum/profile.php?id=439182
トラックバック:special info
トラックバック:https://Bookmarkity.com/story15927596/oregon-lemon-law
トラックバック:https://Infodin.Com.br/index.php/User:SeymourBacote
トラックバック:webcastlist.com
トラックバック:https://Elearning.Hcbeauty.com/blog/index.php?entryid=62126
トラックバック:https://wiki.gem-flash.com/index.php?title=Article_Title
トラックバック:Https://Www.1Usaclassifieds.Com
トラックバック:https://Dirstop.com/story17602033/entrepreneur-spcialis-en-finition-de-bton-la-truelle-d-or
トラックバック:http://provaforumsavoia1234.Altervista.org/community/?wpfs=&membersite=httpsLatruelledor.carevetements-specialises-a-saint-ferreol-les-neiges&membersignature=Introduction+:pnbsp;/ppnbsp;/p+emLe+bton+estamp+est+une/em+mthode+de+revtement+de+sol+ext
トラックバック:https://Okniga.org/user/EzraMoffat00371/
トラックバック:http://Canamkart.ca/index.php?page=user&action=pub_profile&id=1078431
トラックバック:investigate this site
トラックバック:https://Hylistings.com/story16659356/kitchen-cabinets
トラックバック:https://mysocialport.com/story1224318/americanos
トラックバック:WWw.SUIts.Ipt.PW
トラックバック:Bookmarkswing.com
トラックバック:sitesrow.com
トラックバック:https://king.az/user/JeffHinton32/
トラックバック:check out here
トラックバック:Www.wakewiki.de
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=271141
トラックバック:freebookmarkpost.com
トラックバック:Https://Onrafrica.Com/Query-Pour-Les-Couvreurs-Residentiel
トラックバック:click the following document
トラックバック:https://www.homecareshoppe.com/Points-de-vente-de-ameublement-in-saint/
トラックバック:https://Thefairlist.com/story5629137/magik-loans
トラックバック:gUeStpOSTsALE.coM
トラックバック:https://cruxbookmarks.com/story15977907/cim-investigacin
トラックバック:http://Www.sxlopw.cn/comment/html/?241041.html
トラックバック:https://Dimension-gaming.nl/profile.php?id=75329
トラックバック:http://forum.prolifeclinics.ro/profile.php?id=181498
トラックバック:Unitedindia.info
トラックバック:http://Forum.Prolifeclinics.ro/profile.php?id=160764
トラックバック:http://Www.Die-Seite.com/index.php?a=stats&u=dewey37n7041
トラックバック:bleezlabs.Com
トラックバック:http://cloud-dev.mthmn.com/node/373061
トラックバック:https://wiki.team-glisto.com/index.php?title=Cr_ation_De_Site_Web__Montr_al_:_Conseils_Par_Une_Pr_sence_Num_rique_R_ussie
トラックバック:https://wise-social.com/story1217997/servicios-de-transporte-terrestre-en-bogot-vanspremium
トラックバック:https://Demo.Qkseo.In/profile.php?id=364402
トラックバック:https://Infodin.Com.br/index.php/User:ArianneStallcup
トラックバック:Sissipedia.wiki
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=354745
トラックバック:https://Socialskates.com/story16600059/gouttires-aluminium-jb
トラックバック:https://Advicebookmarks.com/story15995662/grandbox
トラックバック:Health-Lists.com
トラックバック:https://Nxlv.ru/user/ErnestoTuttle/
トラックバック:http://die-seite.com/index.php?a=stats&u=gabrielledelance
トラックバック:Https://Zvukiknig.cc/
トラックバック:geNeraTe.sbM.pw
トラックバック:http://www.gotanproject.net/node/22522822?—————————337379244Content-Disposition:form-data;name=titleBornelectriqueSubvention:Commentbnficierd’aidespourvotreinstallation—————————337379244Content-Disposition:form-data;na
トラックバック:echobookmarks.Com
トラックバック:https://trans.Hiragana.jp/ruby/http://cloud-dev.mthmn.com/node/381253
トラックバック:http://www.Gotanproject.net/node/22521032?—————————7272374402327827Content-Disposition:form-data;name=titleCommentimpermabiliserdesDallesdeBton—————————7272374402327827Content-Disposition:form-data;name=bodySous-titre1:
トラックバック:Imdipet-project.eu
トラックバック:https://Obengdarko.com.gh/forums/users/sibylfosdick687/
トラックバック:change-Management.dofollowlinks.org
トラックバック:http://Www.Gotanproject.net/node/22497442?—————————37843884Content-Disposition:form-data;name=titleRenovatingStartLookingAtEquipmentPackagesNow—————————37843884Content-Disposition:form-data;name=bodyThesedayseverydishwa
トラックバック:http://www.xjykj.cn/comment/html/?445278.html
トラックバック:jasa seo web
トラックバック:WIN368
トラックバック:jasa seo harga
トラックバック:beli followers ig murah
トラックバック:backlink pbn gratis
トラックバック:accutane attorney | Buy Accutane online
トラックバック:toto sgp
トラックバック:auto followers pinterest
トラックバック:trending news on social media 2023
トラックバック:toto macau
トラックバック:link alternatif pedetogel
トラックバック:xyz 338 slot
トラックバック:Miataki Mushrooms Share
トラックバック:kebuntoto link alternatif login
トラックバック:kebuntoto login
トラックバック:jasa view dan like youtube
トラックバック:FitBites BHB Gummies
トラックバック:Fit Bites Gummies
トラックバック:Fit Today Keto Gummies
トラックバック:Circulaxil
トラックバック:beli followers instagram aktif indonesia murah
トラックバック:Greenhouse CBD Gummies
トラックバック:Stimula Blood Sugar Support
トラックバック:Lights Out CBD Gummies
トラックバック:ABForce Stimulator & Recovery
トラックバック:sex
トラックバック:jual followers instagram 10k
トラックバック:beli followers instagram
トラックバック:apakah beli view youtube aman
トラックバック:Nuubu Detox Patch
トラックバック:Apex Pencil
トラックバック:tambah view youtube
トラックバック:cara menambah view instagram tanpa aplikasi
トラックバック:suntik like youtube
トラックバック:check it out
トラックバック:jasa like instagram murah
トラックバック:toto sdy
トラックバック:beli subscriber youtube aman
トラックバック:Vision Nutri Complex
トラックバック:best gold ira companies
トラックバック:beli view story instagram
トラックバック:toto hk
トラックバック:donkey Milk soap organic
トラックバック:donkey Milk Soap skin benefits
トラックバック:tototogel
トラックバック:http://latenitetip.com/index.php?page=user&action=pub_profile&id=75726
トラックバック:beli followers ig permanen indonesia
トラックバック:Medioxil 24
トラックバック:TV Share Max
トラックバック:https://oracleepm.guide/
トラックバック:biaya seo website
トラックバック:jual views youtube
トラックバック:jual followers spotify
トラックバック:Jasa Backlink
トラックバック:harga seo website
トラックバック:jasa backlink artikel
トラックバック:apa itu pinterest
トラックバック:Vitamin Dee Male Enhancement Gummies
トラックバック:Ezpostings
トラックバック:modern kitchen decor
トラックバック:urine test tips
トラックバック:jasa backlink seo
トラックバック:backlink murah
トラックバック:beli subscriber youtube permanen
トラックバック:trendi hírek a világon
トラックバック:Trending na balita sa social media ngayon
トラックバック:server thailand
トラックバック:adorable animals
トラックバック:Актуальныя навіны свету гэтага тыдня
トラックバック:psykholog
トラックバック:golden energy
トラックバック:print 3d models
トラックバック:nyheder om internet i dag
トラックバック:2023-жылдагы социалдык медиадагы жаңылыктар
トラックバック:актуални новини в Индонезия
トラックバック:batmanapollo.ru
トラックバック:nā manawa o ka nūhou haʻuki India i kēia lā
トラックバック:социалдык тармактарда эң популярдуу жаңылыктар
トラックバック:今日のトレンドニュース
トラックバック:www.pinterest.com
トラックバック:Banci Toto
トラックバック:BanciToto
トラックバック:golden Teacher
トラックバック:right foods
トラックバック:astra 338 link login
トラックバック:hotels check-in 18
トラックバック:hotel 18+
トラックバック:hotel check-in 18
トラックバック:Banci togel 2d
トラックバック:Banci dalam togel
トラックバック:growkit Golden teacher
トラックバック:Astra338 login
トラックバック:Update Site Error ¹ 654
トラックバック:Update Site Error ¹ 655
トラックバック:Chang’s Beach: Maui’s Hidden Gem Featured in Maui Now Guide
トラックバック:zillow
トラックバック:viagra
トラックバック:354
トラックバック:wismabet link alternatif
トラックバック:porn
トラックバック:pembesar payudara
トラックバック:jasa seo bergaransi
トラックバック:ads508
トラックバック:ceria777
トラックバック:read this blog article from buybatsknifemm2online.wordpress.com
トラックバック:harga backlink berkualitas
トラックバック:Link
トラックバック:Beli Follower Threads IG
トラックバック:aurora2019valuetrade.wordpress.com
トラックバック:Apocalypse MM2 Value
トラックバック:Charcoal briquettes Indonesia
トラックバック:Coconut charcoal from Indonesia
トラックバック:slot online
トラックバック:hotels
トラックバック:hotel
トラックバック:hotels 18+
トラックバック:世界で話題のニュース
トラックバック:transfert de nouvelles sur les sports aériens
トラックバック:DafaToto slot
トラックバック:psy
トラックバック:internetdə trend xəbərlər
トラックバック:што сёння адбываецца з сацыяльнымі сеткамі
トラックバック:sportsnyhedscricket
トラックバック:ما هو الاتجاه الشائع الآن؟
トラックバック:kiino4k.ru
トラックバック:jasa seo togel
トラックバック:jasa pbn berkualitas
トラックバック:depresiya
トラックバック:film
トラックバック:“https://x.com/rayanwebb/status/1740571631867830311?s=20
トラックバック:“https://cameradb.review/wiki/Sverhi.net
トラックバック:new 2024
トラックバック:jual backlink murah
トラックバック:seo situs judi online
トラックバック:backlink judi online
トラックバック:batman apollo
トラックバック:film2024
トラックバック:slot
トラックバック:123 Movies
トラックバック:laloxeziya-chto-eto-prostymi-slovami.ru
トラックバック:Crap
トラックバック:child porn
トラックバック:Из замкнутого круга сериал 2023 смотреть онлайн бесплатно в хорошем качестве
トラックバック:Алекс Лютый. Дело Шульца смотреть онлайн бесплатно в хорошем качестве
トラックバック:Candle MM2
トラックバック:Buy Candied Knife MM2
トラックバック:Camo MM2 Value
トラックバック:Candycorn 2020mm 2rarity Wordpress wrote
トラックバック:سكاي سبورتس لايف لكرة القدم
トラックバック:Бесплатен пренос на вести во живо на YouTube
トラックバック:000
トラックバック:samorazvitiepsi
トラックバック:zegelring dames
トラックバック:hentai game
トラックバック:ceria ceria777 slot
トラックバック:web ca cuoc truc tuyen
トラックバック:Што з’яўляецца моднай тэмай у сацыяльных сетках?
トラックバック:сублимация на футболках технология
トラックバック:jongste sportnuus vandag in Engels
トラックバック:medali303
トラックバック:Online Visa Application Form
トラックバック:lajmet në trend indonezi
トラックバック:Топ 5 спортски вести на англиски денес
トラックバック:macauslot88 deposit pulsa im3
トラックバック:İngilis dilində ən yaxşı 5 idman xəbəri
トラックバック:litteraction.fr
トラックバック:situs dadu online
トラックバック:bocoran rtp slot
トラックバック:slot gacor
トラックバック:situs gacor
トラックバック:situs slot
トラックバック:Golden teacher sklep
トラックバック:nbc xəbərləri indi aparıcıdır
トラックバック:Live-urheiluuutiset Intiassa
トラックバック:reduslim inhaltsstoffe
トラックバック:Каква е популярната тенденция в момента?
トラックバック:Donkey Milk Soap Ingredients
トラックバック:bolacasino88
トラックバック:tider med indiske sportsnyheder i dag
トラックバック:udin777
トラックバック:kardash69.ru
トラックバック:Tucker Carlson – Vladimir Putin – 2024-02-09 Putin interview summary, full interview.
トラックバック:Tucker Carlson – Vladimir Putin
トラックバック:ppf bandung
トラックバック:nano ceramic
トラックバック:“https://remotebillpay.com/tarantasik/
トラックバック:“http://www.malang.info.ooo:80/index.php/Pengguna:DannEaston65
トラックバック:спорт жаңылыктары бүгүн баш макалалар
トラックバック:Sexleben
トラックバック:адвокат по вопросам недвижимости
トラックバック:CookiecaneKnifeMM2ChromaValue.wordpress.com
トラックバック:instagram reset followers
トラックバック:james charles lost followers on tiktok
トラックバック:помощь юриста при разводе через суд
トラックバック:Chroma Boneblade MM2
トラックバック:beli subscriber youtube
トラックバック:pvp777
トラックバック:услуги медицинского педикюра
トラックバック:beli subscriber
トラックバック:http://genomicdata.hacettepe.edu.tr
トラックバック:адвокат для бизнеса в москве
トラックバック:юридическая помощь при дтп автоюристы
トラックバック:www.sexmoon.de
トラックバック:ChromafangValueKnife.wordpress.com
トラックバック:Buy Cherry Knife MM2
トラックバック:CocukK PornosuS
トラックバック:Click at Mm 2knifedeathshardchromavalue Wordpress
トラックバック:terradesic.org
トラックバック:адвокаты г москвы
トラックバック:юрист по строительным вопросам
トラックバック:coba777
トラックバック:chroma Cookiecane mm2
トラックバック:“https://wiki.roboco.co/index.php/Enhancing_Accuracy_And_Innovation_With_Jasa_Laser_Cutting_Solutions
トラックバック:“http://bondpedia.altervista.org/index.php?title=Enhancing_Precision_And_Innovation_With_Jasa_Laser_Cutting_Services
トラックバック:“https://massagemobilityau.com/elevating-precision-and-creativity-with-jasa-laser-cutting-services/
トラックバック:“https://redvice.eu/2024/03/01/enhancing-precision-and-innovation-with-jasa-laser-cutting-services-2/
トラックバック:“https://parentingliteracy.com/wiki/index.php/User:DamianManley89
トラックバック:“http://www.freddypilar.com/enhancing-precision-and-innovation-with-jasa-laser-cutting-services/
トラックバック:“https://wiki.conspiracycraft.net/index.php?title=Zamok
トラックバック:“https://hikvisiondb.webcam/wiki/User:JudeRintel
トラックバック:“http://wiki.myamens.com/index.php/User:TyroneSoutherlan
トラックバック:https://www.cucumber7.com/
トラックバック:uck74.ru
トラックバック:slot gampang jackpot
トラックバック:юрист по банковским вопросам бесплатная консультация
トラックバック:look at these guys
トラックバック:128.199.127.24
トラックバック:kasino rolet terpercaya
トラックバック:google bola
トラックバック:cara menaikkan website judi
トラックバック:superman68
トラックバック:taruhan dadu online
トラックバック:macauslot88 daftar
トラックバック:Buy Chromatic Knife MM2
トラックバック:jtayl.me
トラックバック:telegolf.org
トラックバック:kchurchofchrist.com
トラックバック:jasa seo pbn
トラックバック:https://shorl.com
トラックバック:http://jtayl.me/daftarslotonlinegacor978977
トラックバック:Cookie MM2
トラックバック:Donkey Milk Cosmetics Cyprus
トラックバック:sarangsbobet
トラックバック:https://v.gd/
トラックバック:sarangsbobet link
トラックバック:sga508
トラックバック:r
トラックバック:coursework
トラックバック:https://ValueKnifeMM2Clown.wordpress.com
トラックバック:en.wikipedia.org
トラックバック:https://canvas.ubc.ca/eportfolios/49464/blogs/NCAA_Drug_Testing_What_Happens_If_You_Fail
トラックバック:ips77
トラックバック:xgslot88 link alternatif
トラックバック:Nooro Knee Massager
トラックバック:สาระน่ารู้
トラックバック:mawartoto link terbaru
トラックバック:natural donkey milk soap ingredients
トラックバック:otoslot login alternatif
トラックバック:เกร็ดความรู้
トラックバック:สาระน่ารู้ทั่วไป
トラックバック:v.gd
トラックバック:slot gampang maxwin
トラックバック:rsjakarta.co.id
トラックバック:เว็บความรู้
トラックバック:xgslot88
トラックバック:otoslot link
トラックバック:Arena333
トラックバック:slot gacor hari ini pragmatic
トラックバック:grandpashabet
トラックバック:magic amanita mushroom gummy
トラックバック:Qunix Nisqa
トラックバック:wisma bet login
トラックバック:artis777
トラックバック:Polototo sgp
トラックバック:xgslot88 login alternatif
トラックバック:child porn
トラックバック:macauslot88 2024
トラックバック:พนันออนไลน์
トラックバック:เว็บพนันออนไลน์
トラックバック:เว็บพนันออนไลน์เว็บตรง
トラックバック:tgslot
トラックバック:เว็บพนัน
トラックバック:cuancash88
トラックバック:RecehBet Login
トラックバック:ips77 login
トラックバック:original site
トラックバック:test gsa
トラックバック:https://hentaihaven.su/
トラックバック:юрист по алиментам онлайн консультация бесплатно
トラックバック:Gopek178 Link Alternatif
トラックバック:bu gün trend axtarışları
トラックバック:أفضل 5 أخبار رياضية باللغة الإنجليزية
トラックバック:папулярныя навіны ў сацыяльных сетках 2023
トラックバック:otoslot4d
トラックバック:Slot Pulsa
トラックバック:otoslot link login
トラックバック:أخبار الثعلب
トラックバック:youtube danas u trendu širom svijeta
トラックバック:https://-51.
トラックバック:intlawcompany.ru
トラックバック:mitä sosiaalisessa mediassa tapahtuu tänään
トラックバック:Məktəb yığıncağı üçün ingilis dilində ən yaxşı 5 idman xəbəri
トラックバック:youtube je dnes celosvětovým trendem
トラックバック:desa333
トラックバック:otoslot
トラックバック:Прамыя спартыўныя навіны прэм’ер-лігі
トラックバック:child porn
トラックバック:otoslot rtp
トラックバック:youtube në trend sot në mbarë botën
トラックバック:Sosial mediada trend olan mövzu nədir?
トラックバック:finviz
トラックバック:oto slot link alternatif
トラックバック:当今世界的热门新闻
トラックバック:трэндавая тэма dunia hari ini
トラックバック:https://hanime.su/
トラックバック:post503000728
トラックバック:โปรแกรมทัวร์ไต้หวัน
トラックバック:โปรแกรมทัวร์จีน
トラックバック:เที่ยวเกาหลีใต้
トラックバック:адвокат по заливам цена
トラックバック:bersama138
トラックバック:https://valuettddjspeakerman1.wordpress.com
トラックバック:Hero Keto ACV Gummies
トラックバック:пинап. казино
トラックバック:Purchase Dancing Speakerwoman TTD
トラックバック:ทัวร์จีน 5 ดาว
トラックバック:ทัวร์พม่า
トラックバック:“https://www.yoonjobooks.co.kr/yoonjo/bbs/board.php?bo_table=free&wr_id=274560”
トラックバック:TTD Large Cameraman Value
トラックバック:먹튀검증
トラックバック:Dancing Speakerwoman TTD
トラックバック:KKSLOT777
トラックバック:Ninja Cameraman TTD
トラックバック:SlimPulse
トラックバック:notizie di tendenza oggi
トラックバック:kio okazas kun sociaj amaskomunikiloj hodiaŭ
トラックバック:animeporn su
トラックバック:Restore CBD Gummies
トラックバック:Што азначае экстранныя навіны?
トラックバック:click through the following web page
トラックバック:trending på internettet i dag
トラックバック:hotels check-in 18 new york
トラックバック:hotel check-in 18 nyc
トラックバック:hotels 18+ new york
トラックバック:What is benefits slimysol
トラックバック:เว็บบทความ
トラックバック:Going At this website
トラックバック:How long should I take Nexaslim pills?
トラックバック:Purchase Camera Repair Drone TTD
トラックバック:TTD Corrupted Cameraman
トラックバック:Glitch Cameraman TTD
トラックバック:Camera Spider TTD Camera Spider TTD Value TTD Camera Spider Value TTD Camera Spider Buy Camera Spider TTD Purchase Camera Spider TTD
トラックバック:Camera Helicopter TTD
トラックバック:TTD Engineer Cameraman
トラックバック:TTD Large Firework Cameraman Value
トラックバック:Purchase Jetpack Cameraman TTD
トラックバック:Buy Hunter Cameraman TTD
トラックバック:Ttd Glitch Cameraman
トラックバック:Hunter Cameraman TTD
トラックバック:our source
トラックバック:Glitch Cameraman TTD Value
トラックバック:Purchase Hunter Cameraman TTD
トラックバック:Buy Large Cameraman TTD
トラックバック:ValueHunterCameramanUnitTTD.wordpress.com
トラックバック:Hunter Cameraman TTD Value
トラックバック:TTD Glitch Cameraman Value
トラックバック:her comment is here
トラックバック:https://TTDHunterCameramanTrade.wordpress.com
トラックバック:Camera Repair Drone TTD
トラックバック:HunterCameramanTTD.wordpress.com
トラックバック:Ttdunitlargecameramanshop.Wordpress.Com
トラックバック:ttdlargecameramanunitstore.wordpress.Com
トラックバック:https://LargeCameramanUnitTTDStore.wordpress.com/
トラックバック:Purchase Glitch Cameraman Ttd
トラックバック:ValueLargeCameramanTTD.wordpress.com
トラックバック:ValueTTDUnitLargeCameraman.wordpress.com
トラックバック:https://TTDHunterCameraman.wordpress.com
トラックバック:information from ValueGlitchCameramanTTDUnit.wordpress.com
トラックバック:Ttdunitglitchcameramanvalue.Wordpress.Com
トラックバック:Large Cameraman TTD Value
トラックバック:https://HunterCameramanUnitTTDStore.wordpress.com/
トラックバック:https://glitchcameramanunitttdstore.wordpress.com/
トラックバック:Buy Glitch Cameraman TTD
トラックバック:valueglitchcameramanunitttd.wordpress.Com
トラックバック:https://LargeCameramanUnitValueTTD.wordpress.com
トラックバック:Corrupted Cameraman TTD Value
トラックバック:Large Cameraman TTD
トラックバック:Https://TTDLargeCameramanShop.Wordpress.Com/
トラックバック:go!!
トラックバック:Large Firework Cameraman TTD
トラックバック:https://TTDUnitCameraSpiderMarket.wordpress.com
トラックバック:https://CameraSpiderTTDUnitShop.wordpress.com/
トラックバック:Corrupted Cameraman TTD
トラックバック:Buy Corrupted Cameraman TTD
トラックバック:CorruptedCameramanUnitTTDMarket.wordpress.com
トラックバック:just click TTDUnitCorruptedCameramanMarket.wordpress.com
トラックバック:TTD Corrupted Cameraman Value
トラックバック:the original source
トラックバック:CorruptedCameramanValueTTD.wordpress.com
トラックバック:Corruptedcameramanttdtrade Wordpress`s statement on its official blog
トラックバック:use Glitchcameramanunitttdvalue Wordpress here
トラックバック:ValueGlitchCameramanTTD.wordpress.com
トラックバック:published on Ttdcorruptedcameramanmarket Wordpress
トラックバック:https://TTDCorruptedCameramanUnit.wordpress.com/
トラックバック:CorruptedCameramanTTDUnitMarket.wordpress.com
トラックバック:https://GlitchCameramanUnitTTDTrade.wordpress.com
トラックバック:CorruptedCameramanUnitTTD.wordpress.com
トラックバック:visit this site
トラックバック:https://TTDCameraSpiderUnitMarket.wordpress.com
トラックバック:click through the up coming web page
トラックバック:https://ValueCorruptedCameramanTTD.wordpress.com/
トラックバック:https://CorruptedCameramanTTD.wordpress.com
トラックバック:CameraHelicopterTTDlevel.wordpress.com
トラックバック:https://TTDUnitLargeCameraman.wordpress.com
トラックバック:Camera Helicopter TTD Value
トラックバック:Link Website
トラックバック:Purchase Camera Helicopter TTD
トラックバック:click through the following article
トラックバック:TTDCameraHelicopterUnitValue.wordpress.com
トラックバック:visit the following website
トラックバック:Buy Camera Repair Drone TTD
トラックバック:Buy Engineer Cameraman TTD
トラックバック:dog food recipes for allergies
トラックバック:Purchase Engineer Cameraman Ttd
トラックバック:More Material
トラックバック:HunterCameramanUnitValueTTD.wordpress.com
トラックバック:TTD Hunter Cameraman Value
トラックバック:relevant site
トラックバック:engineer cameraman ttd value
トラックバック:official ValueEngineerCameramanUnitTTD.wordpress.com blog
トラックバック:TTDEngineerCameramanTrade.wordpress.com
トラックバック:TTDUnitEngineerCameraman.wordpress.com
トラックバック:EngineerCameramanTTDStore.wordpress.com
トラックバック:Camera Repair Drone TTD Value
トラックバック:EngineerCameramanTTD.wordpress.com
トラックバック:mouse click the following webpage
トラックバック:ValueCameraSpiderUnitTTD.wordpress.com
トラックバック:https://TTDCorruptedCameramanUnitStore.wordpress.com
トラックバック:TTDHunterCameramanupgrade.wordpress.com
トラックバック:CorruptedCameramanTTDMarket.wordpress.com
トラックバック:https://TTDCameraRepairDroneUnitMarket.wordpress.com
トラックバック:EngineerCameramanUnitTTDMarket.wordpress.com
トラックバック:TTD Camera Repair Drone
トラックバック:read this blog post from ValueCameraSpiderTTD.wordpress.com
トラックバック:https://CameraSpiderTTDUnitValue.wordpress.com/
トラックバック:TTDCameraSpiderShop.wordpress.com
トラックバック:visit the next page
トラックバック:Buy Large Firework Cameraman TTD
トラックバック:TTDCameraSpiderTrade.wordpress.com website
トラックバック:TTD Large Cameraman
トラックバック:mouse click the next article
トラックバック:Large Firework Cameraman TTD Value
トラックバック:Full Article
トラックバック:Https://LargeCameramanTTDUnitStore.wordpress.com
トラックバック:Check Out Valuettdcameraspider Wordpress
トラックバック:click through the following web site
トラックバック:Purchase Large Firework Cameraman TTD
トラックバック:ProFlexen Result
トラックバック:https://ValueCameraRepairDroneUnitTTD.wordpress.com
トラックバック:https://CameraRepairDroneUnitTTDShop.wordpress.com
トラックバック:https://ValueTTDUnitGlitchCameraman.wordpress.com
トラックバック:ProPlayers Wellness Keto Gummies Reviews
トラックバック:visit the next site
トラックバック:https://TTDEngineerCameramanMarket.wordpress.com/
トラックバック:Engineer Cameraman TTD
トラックバック:TTD Engineer Cameraman Value
トラックバック:TTDUnitValueLargeFireworkCameraman.wordpress.com
トラックバック:LargeFireworkCameramanUnitTTDValue.wordpress.com
トラックバック:TTD Large Firework Cameraman
トラックバック:valuettdlargefireworkcameramanunit.wordpress.com
トラックバック:wb403 alternatif
トラックバック:TTD Camera Repair Drone Value
トラックバック:this guy
トラックバック:TTDCameraRepairDroneUnitValue.wordpress.com
トラックバック:TTDCameraRepairDroneMarket.wordpress.com wrote in a blog post
トラックバック:Results Transformation Center https://socialstrategie.com/story2074664/sparks-workout-sessions
トラックバック:visit Ttdlargefireworkcameramantrade Wordpress here >>
トラックバック:please click the next page
トラックバック:ttdunitlargefireworkcameramantrade.wordpress.com
トラックバック:https://LargeFireworkCameramanUnitTTD.wordpress.com/
トラックバック:scatter hitam
トラックバック:https://bukansitus.com/2024/05/08/home-faucet-repair-construction-plumbing/
トラックバック:easy homeowner lighting
トラックバック:Arena333 Link Alternatif
トラックバック:{link gacor slot}
トラックバック:go directly to TTDUnitLargeSpeakermanMarket.wordpress.com
トラックバック:Gopek178 Hoki
トラックバック:Arena333 pro
トラックバック:MechCameramanTTDGG.wordpress.com
トラックバック:Arena333 Slot
トラックバック:Laser Gun Cameraman TTD
トラックバック:Medic Cameraman TTD
トラックバック:Buy Scary Speakerman TTD
トラックバック:SandiBet Alternatif
トラックバック:situs judi slot
トラックバック:porno izle
トラックバック:SandiBet
トラックバック:Arena333 Slot Login
トラックバック:Arena333 Slot Login Link Alternatif
トラックバック:{link slot terbaru}
トラックバック:simply click the up coming document
トラックバック:TTD Mech Cameraman Value
トラックバック:santatvmanttdstore.wordpress.com
トラックバック:Arena333 vip
トラックバック:Buy Large TV Man TTD
トラックバック:TTD Laser Gun Cameraman Value
トラックバック:to TTDUnitChefTVManShop.wordpress.com
トラックバック:Purchase Mech Cameraman TTD
トラックバック:TTD Large Speakerman
トラックバック:Gopek178 Login
トラックバック:Purchase Large Speakerman TTD
トラックバック:Laser Gun Cameraman TTD Value
トラックバック:SandiBet Login
トラックバック:Buy Santa TV Man TTD
トラックバック:CBD Care Gummies
トラックバック:https://LargeLaserCameramanTTDStore.wordpress.com
トラックバック:Read Significantly more
トラックバック:{link slot gacor terpercaya}
トラックバック:Gopek178 Alternatif
トラックバック:simply click the up coming article
トラックバック:situs judi slot online terpercaya
トラックバック:situs judi slot online resmi
トラックバック:{link slot gacor hari ini}
トラックバック:M494
トラックバック:Gopek178 Legal
トラックバック:TTD Large Laser Cameraman
トラックバック:MedicCameramanUnitTTDMarket.wordpress.com
トラックバック:Medic Cameraman TTD Value
トラックバック:situs judi slot online gampang menang
トラックバック:click here
トラックバック:TTD Dual Blade Bunnyman Value
トラックバック:https://www.mysoter.net/quiz-will-online-book-marketing-help-sales/
トラックバック:https://mjwildlife.ca/community/profile/jesusbanda61958/
トラックバック:Wild Stallion Pro
トラックバック:SandiBet Link
トラックバック:Gopek178 Petir
トラックバック:Gopek178 Slot
トラックバック:visit this website link
トラックバック:TTD Elf Camerawoman
トラックバック:Elf Camerawoman TTD
トラックバック:Buy Cupid Camerawoman TTD
トラックバック:TTD Cupid Camerawoman Value
トラックバック:Elf camerawoman ttd Value
トラックバック:Nuubu Detox Foot Patches
トラックバック:Going On this page
トラックバック:relevant webpage
トラックバック:https://CupidCamerawomanUnitTTDStore.wordpress.com
トラックバック:TTD Cupid Camerawoman
トラックバック:Wordpress blog post
トラックバック:Elf Camerawoman TTD Value
トラックバック:Elf Camerawoman TTD
トラックバック:https://TTDElfCamerawomanStore.wordpress.com
トラックバック:Wild Stallion Pro Reviews
トラックバック:wd808
トラックバック:Tupi Tea ME
トラックバック:Uqalo Yuvalift
トラックバック:related resource site
トラックバック:link gacor slot
トラックバック:Awitogel Login Link Alternatif
トラックバック:NexaSlim Ketosis
トラックバック:Glucoslim Reviews
トラックバック:GLOTER
トラックバック:Slimysol
トラックバック:NuviaLab Keto
トラックバック:look here
トラックバック:Awitoto Link Alternatif
トラックバック:otoslot login
トラックバック:freebet gratis
トラックバック:web slot gacor
トラックバック:AkarToto 777
トラックバック:AkarToto Alternatif
トラックバック:slot online gacor
トラックバック:AkarToto Login
トラックバック:slot paling gacor
トラックバック:AkarToto
トラックバック:okta388
トラックバック:New games for Android
トラックバック:otoslot link alternatif
トラックバック:slot yang lagi gacor
トラックバック:slot terbaru
トラックバック:AkarToto Slot Login
トラックバック:slot yang lagi gacor sekarang
トラックバック:Best games for Android
トラックバック:slot online paling gacor
トラックバック:situs slot gacor hari ini
トラックバック:bonus new member 100 slot game
トラックバック:Smart Hemp Gummies
トラックバック:bit.ly/kto-takoy-opsuimolog
トラックバック:super cuan 88
トラックバック:slot online gacor hari ini
トラックバック:Popular games for Android
トラックバック:Urgent Visa Online
トラックバック:Slot Deposit 5k
トラックバック:Surveillance Camerawoman TTD
トラックバック:{link slot gacor}
トラックバック:Toy
トラックバック:oto slot gacor
トラックバック:free porn
トラックバック:site
トラックバック:link slot gacor hari ini
トラックバック:sims 4 goth decor cc
トラックバック:cuancash
トラックバック:TTD Scary Speakerman Value
トラックバック:TTD Healer TV Woman Value
トラックバック:ttd images
トラックバック:เว็บวาไรตี้
トラックバック:about
トラックバック:TTD Scary Speakerman
トラックバック:BloxCart MM2
トラックバック:Candleflame MM2
トラックバック:Purchase Huge Anime Unicorn PS99
トラックバック:PS99 Huge Angel Cat
トラックバック:PS99 Huge Abyssal Axolotl Value
トラックバック:Huge Alien Arachnid PS99
トラックバック:PS99 Huge Anime Agony Value
トラックバック:koko303
トラックバック:JUDI ONLINE
トラックバック:먹튀검증업체 순위
トラックバック:when to use lose and loss?
トラックバック:성남 출장
トラックバック:bath and body works candles toxic
トラックバック:수유출장마사지
トラックバック:scameter app for android free
トラックバック:mfa bypass roblox
トラックバック:japan travel in december
トラックバック:купить аттестат 11 классов
トラックバック:singapore vaccinated travel lane japan
トラックバック:Buy Orange Seer Knife MM2
トラックバック:Buy Old Glory Knife MM2
トラックバック:Buy Pixel Knife MM2
トラックバック:shorts
トラックバック:index
トラックバック:seerr
トラックバック:see
トラックバック:seo
トラックバック:“https://www.pitchdecks.tv/index.php/Online_Kurs_467664f”
トラックバック:best ontario online sports betting sites
トラックバック:eer
トラックバック:sarang777
トラックバック:clubnika casino бонусы
トラックバック:Hype casino вход
トラックバック:부평출장마사지
トラックバック:Apply Visa Online
トラックバック:seer
トラックバック:Crimson Demon Ninja Anime Defenders Value
トラックバック:AD Crimson Demon Ninja Value
トラックバック:source
トラックバック:erttt
トラックバック:Situs Togel Online
トラックバック:PenaSlot Link Alternatif
トラックバック:Salimbet Link Alternatif
トラックバック:togel singapore hari ini
トラックバック:togel sydney tercepat
トラックバック:pengeluaran semua togel hari ini tercepat
トラックバック:eerr
トラックバック:se
トラックバック:Saji Toto
トラックバック:Fryd Extracts
トラックバック:Purchase Legion Captain Anime Defenders
トラックバック:Anime Defenders Legion Captain
トラックバック:dr
トラックバック:bangla teenage sex
トラックバック:Anime Defenders Legion Veteran
トラックバック:AD Legion Veteran Value
トラックバック:Legion Veteran Anime Defenders
トラックバック:super lean tab
トラックバック:wee
トラックバック:Wine Barrels for Sale
トラックバック:buy injectable steroids online with credit card
トラックバック:clean carts disposable
トラックバック:packwoods x runtz
トラックバック:Bitmain Antminer KS3 8.3TH
トラックバック:FRT Trigger
トラックバック:SajiToto Link Alternatif
トラックバック:PokemonToto Alternatif
トラックバック:togel hari ini
トラックバック:Anime defenders units
トラックバック:PenaSlot Login
トラックバック:PokemonToto
トラックバック:Gems Anime Defenders
トラックバック:yaltalife.ru
トラックバック:Gems AD
トラックバック:滿貫大亨
トラックバック:Anime Defenders Gems
トラックバック:PokemonToto MaxWin
トラックバック:togel hongkon─ú
トラックバック:PokemonToto Live Chat
トラックバック:SajiToto Link
トラックバック:negro sex video
トラックバック:kream 2g disposableble
トラックバック:bandar togel terbesar
トラックバック:PokemonToto Togel
トラックバック:bo slot gacor
トラックバック:Salimbet RTP
トラックバック:bocoran slot gacor
トラックバック:togel lengkap hari ini
トラックバック:PokemonToto Login
トラックバック:game slot gacor hari ini
トラックバック:ต้นกัญชา ราคาถูก
トラックバック:angka keluar togel
トラックバック:kinogo
トラックバック:บทความกัญชง
トラックバック:น้ำปลาร้า
トラックバック:CRM integrat cu VoIP
トラックバック:Centrala telefonica cu conferinta
トラックバック:Salimbet Login
トラックバック:Centrala telefonica pentru servicii profesionale
トラックバック:situs togel resmi
トラックバック:situs slot online
トラックバック:Centrala telefonica cu meniu IVR
トラックバック:rasschitat dizayn cheloveka onlayn
トラックバック:SajiToto
トラックバック:pvp777 slot
トラックバック:raschet karty dizayn cheloveka
トラックバック:https://www.vapeenter.com/ehpro-true-mtl-rta-replacement-glass-tube-2ml3ml
トラックバック:humandesignplanet.ru
トラックバック:human design
トラックバック:Centrala telefonica cu actualizari automate
トラックバック:SajiToto Alternatif
トラックバック:ino777
トラックバック:err
トラックバック:buy instagram followers
トラックバック:free erotic chatting
トラックバック:ads508 slot
トラックバック:centrala telefonica
トラックバック:Centrala telefonica pentru servicii publice
トラックバック:Opsumiologist
トラックバック:Psychologist #1 in the World
トラックバック:Best Psychologist in the World
トラックバック:tgslot alternatif
トラックバック:บทความกัญชาทางการแพทย์
トラックバック:site
トラックバック:Favorites dispo
トラックバック:beli subscriber youtube aktif
トラックバック:Aluminum Ingo
トラックバック:EMERGENCY VISA ONLINE
トラックバック:diuwin login
トラックバック:giết người cướp của
トラックバック:용인출장마사지
トラックバック:beli view youtube aman
トラックバック:beli like instagram indonesia
トラックバック:beli followers instagram murah
トラックバック:jasa like instagram indonesia
トラックバック:jasa like instagram
トラックバック:beli followers ig aktif indonesia
トラックバック:beli like youtube
トラックバック:Centrala telefonica pentru organizatii non-profit
トラックバック:cara beli subscriber youtube
トラックバック:beli view youtube apakah aman
トラックバック:เรียนดำน้ำลึก
トラックバック:jasa seo murah berkualitas
トラックバック:designs-tab-open
トラックバック:jasa seo aman
トラックバック:promo backlink
トラックバック:คอร์สเรียนดำน้ำลึก
トラックバック:bookmark backlink
トラックバック:beli followers ig termurah
トラックバック:ser
トラックバック:slot server singapore
トラックバック:jasa backlink web 2.0
トラックバック:https://hanime.boo
トラックバック:เรียนดำน้ำ
トラックバック:beli followers ig permanen
トラックバック:jasa view youtube termurah
トラックバック:beli followers ig permanen terpercaya
トラックバック:sse
トラックバック:beli views youtube
トラックバック:best cheap offshore dedicated server
トラックバック:best offshore dedicated server
トラックバック:ukraine 2gbps dedicated servers
トラックバック:bắt cóc tống tiền
トラックバック:SajiToto Gacor
トラックバック:printsipy forda
トラックバック:how to get free offshore vps
トラックバック:ukraine 5gbps offshore servers
トラックバック:netherlands ssd streaming servers
トラックバック:netherlands storage servers
トラックバック:favorites carts
トラックバック:download reels without watermark
トラックバック:خرید بک لینک
トラックバック:tools help
トラックバック:Open Graph Checker
トラックバック:fat burning slimming pills
トラックバック:funeral homes
トラックバック:supermamki.ru
トラックバック:acai berry weight loss
トラックバック:Cuantoto Wap Login
トラックバック:pkd.ac.th
トラックバック:quickest way to lose weight
トラックバック:dizain-cheloveka
トラックバック:sex
トラックバック:1obl.tv
トラックバック:caroline.edu
トラックバック:Pinterest
トラックバック:AI Trading Bot
トラックバック:sportsbet exchange script
トラックバック:hardcore free porn
トラックバック:New.Jesusaction.org
トラックバック:Kisdiconference.kr
トラックバック:Rajabandot Toto
トラックバック:http://Dvart.com/__media__/js/netsoltrademark.php?d=Pretty4U.Co.krnewbbsboard.phpbo_tablefreewr_id2688441
トラックバック:Inisites.com
トラックバック:Ssi.bio
トラックバック:go to M.Jp.Grplan.com
トラックバック:SajiToto RTP
トラックバック:Laskar303 Link Alternatif
トラックバック:Gamarik.li
トラックバック:web page
トラックバック:https://Finforum.pro/proxy.php?link=http://Qzfczs.com/comment/html/?504204.html
トラックバック:http://Www.teleserial.com/out/https://krotcinus.com/education/5486699
トラックバック:http://sieth.net/__media__/js/netsoltrademark.php?d=t-salon-de-jun.comboard4194667
トラックバック:หลักสูตรดำน้ำ
トラックバック:คอร์สเรียนดำน้ำ
トラックバック:คอร์สดำน้ำ
トラックバック:Alixgoldenstories.com
トラックバック:http://entamehikaku.com/st-manager/click/track/?id=877&type=raw&url=http://www.isewoon.com/estimate/12244
トラックバック:dedicated server offshore
トラックバック:ukraine 10gbps offshore servers
トラックバック:Truck4x4.ru
トラックバック:Paranoimia.Co.uk
トラックバック:http://Aquadiitalia.com/__media__/js/netsoltrademark.php?d=Www.zgcksxy.comcommenthtml215027.html
トラックバック:Ecommk.com
トラックバック:http://Gtv.vianordovest.org/__media__/js/netsoltrademark.php?d=cl-System.jpquestionprix-de-lentretien-menager-residentiel-a-quebec-ce-que-vous-devez-savoir-89
トラックバック:http://Cse.Google.al/url?sa=t&url=httpjap.shinkotire.co.krbbsboard.phpbo_tablefreewr_id74967
トラックバック:shopwowa.com
トラックバック:http://uvbnb.ru/go?http://Ockim.com/HousesForSaleIrvine/351399
トラックバック:Www.zgcksxy.com
トラックバック:Dlightcompany.Co.kr
トラックバック:http://ockim.com/HousesForSaleIrvine/407264
トラックバック:Plata-Nachos.com
トラックバック:offshore vps
トラックバック:Live Video XXX Site Sex Free
トラックバック:Webcam Chat Free Video XXX Porno
トラックバック:Advanced Trading Portal
トラックバック:Video Chat Live Free Porno Site
トラックバック:Free Sex Video Porno Web Cam Webcam
トラックバック:self-serve
トラックバック:http://wagnersl.com/__media__/js/netsoltrademark.php?d=aina-test-com.check-xserver.jpbbsboard.phpbo_tablefreewr_id1558929
トラックバック:Site Chat Live Sex Free XXX
トラックバック:https://m.pethroom.com/member/login.html?returnUrl=httpwww.Die-seite.comindex.phpastatsubobbiemoralez5
トラックバック:http://Sonomavista.com/__media__/js/netsoltrademark.php?d=Boradesign.napage.krbbsboard.phpbo_tablefreewr_id95453
トラックバック:Josephmind.Co.Kr
トラックバック:Webcam Site XXX Web Cam Video Chat
トラックバック:Video Live Free Porno XXX
トラックバック:Bathroom Supply Store
トラックバック:Free Sex Porno Web Cam Site Live
トラックバック:XXX Video Webcam Chat Free Live
トラックバック:http://M.Adminso.Com
トラックバック:Sex Chat XXX Free Live Web Cam
トラックバック:Sex Web Cam Porno Free Webcam
トラックバック:Porno Site Web Cam XXX Video
トラックバック:frazeryachts.info
トラックバック:https://scribematch.com/__media__/js/netsoltrademark.php?d=Www.cqcici.comcommenthtml21183.html
トラックバック:http://Gupzoom.com/__media__/js/netsoltrademark.php?d=Www.Cqcici.comcommenthtml25556.html
トラックバック:https://Elhacker.net/geolocalizacion.html?host=Fggn.kr/board_DesI72/147740
トラックバック:telegra.ph
トラックバック:https://stopcran.ru/go?https://Pochki2.ru/question/auto-branconnier-un-metier-essentiel-dans-l-039-industrie-automobile-48
トラックバック:Fourseasons-Dental.Co.Kr
トラックバック:http://sookso.Iwinv.net/edenstaybooking/bbs/board.php?bo_table=free&wr_id=78932
トラックバック:365.Expresso.blog
トラックバック:https://Www.mnogo.ru/out.php?link=http://www.cqcici.com/comment/html/?20426.html
トラックバック:http://seelin.in
トラックバック:https://bull.iis.sinica.edu.tw/doku.php?id=want_c_eate_money_online_my_online_income_system_eview
トラックバック:Site Free Video Chat Porno XXX
トラックバック:Www.Hneos.com
トラックバック:https://Sun-Clinic.CO.Il/he/question/decouvrez-les-delices-des-tacos-sur-le-poulet/
トラックバック:Teploenergodar.ru
トラックバック:http://Usedraymondtrucks.com/__media__/js/netsoltrademark.php?d=Ecommk.comquestiondesinfectants-naturels-alternatives-saines-et-efficaces
トラックバック:Free XXX Sex Web Cam Live Chat
トラックバック:eLETe.tV
トラックバック:Gymfan.com
トラックバック:http://www.020Wt.cn/comment/html/?4772.html
トラックバック:http://www.Jschell.de/link.php?url=www.cqcici.comcommenthtml22441.html&goto=google_news
トラックバック:http://Jccctextbooks.net/__media__/js/netsoltrademark.php?d=WWW.Buy-Aeds.com/comment/html/?11818.html
トラックバック:Images.Google.Com.ar
トラックバック:websites
トラックバック:http://Blog-kr.dreamhanks.com/question/decoration-devenements-professionnels-sur-le-quebec-12/
トラックバック:http://design-seoul.com/bbs/board.php?bo_table=free&wr_id=137965
トラックバック:http://ockim.com/HousesForSaleIrvine/718288
トラックバック:Telemarketingsurabaya.id
トラックバック:Epichydroseeders.com
トラックバック:http://Www.0768baby.com/comment/html/?209889.html
トラックバック:http://Entamehikaku.com/st-manager/click/track/?id=877&type=raw&url=https://CL-System.jp/question/gestion-de-projet-immobilier-cles-par-une-reussite-optimum-15/
トラックバック:Continuing
トラックバック:webpage
トラックバック:web site
トラックバック:Flower-trader.org
トラックバック:www freeporm
トラックバック:chats latino gratis
トラックバック:successful investors
トラックバック:mouse click on xn--im4bz6r.com
トラックバック:cam gurls
トラックバック:free orn videos
トラックバック:https://globalvigen.com/bbs/board.php?bo_table=free&wr_id=224330
トラックバック:Legacymissionpointe.com
トラックバック:Ie0808.coM
トラックバック:https://Ecommk.com/question/kinesiologue-a-terrebonne-expertise-et-services-par-un-bien-etre-optimise-12/
トラックバック:free hd sex cams
トラックバック:http://Appsisun.Iwinv.net/bbs/board.php?bo_table=free&wr_id=8433
トラックバック:stream sex porn
トラックバック:https://Www.Stcomm.CO.Kr/bbs/board.php?bo_table=free&wr_id=1256405
トラックバック:buy viagra pills
トラックバック:StaGeAile.COm
トラックバック:linked website
トラックバック:Feijoa.com
トラックバック:click the up coming article
トラックバック:http://Proxy-Tu.researchport.Umd.edu
トラックバック:Porn star Free
トラックバック:Nude Chat Rooms
トラックバック:Free Porno
トラックバック:cdkey.hashnode.dev
トラックバック:Https://Mattressbuy.Mystrikingly.Com
トラックバック:https://m.123cha.com/ip/?q=mv803.My-web.kr/bbs/board.phpbo_tablemv5_1wr_id110931
トラックバック:Blog-kr.dreamhanks.com
トラックバック:chiến tranh hạt nhân
トラックバック:Slimnatura.net
トラックバック:https://pinshape.com/
トラックバック:more info
トラックバック:http://accessambulance.net/__media__/js/netsoltrademark.php?d=Dreamon114.combbsboard.phpbo_tablefreewr_id81695
トラックバック:buy viagra
トラックバック:real estate agent
トラックバック:Milkyway.CS.RPI.Edu
トラックバック:translate.google.de
トラックバック:https://museobiblico.uniclaretiana.edu.co/
トラックバック:zapada01
トラックバック:Pnptech.Co.kr
トラックバック:dating websites
トラックバック:Louisukzo82581.Losblogos.Com
トラックバック:wgo77
トラックバック:https://Rozwiazanie-i-Odpowiedz.ck.page/05e67ece6a
トラックバック:https://micah6e58kym8.thekatyblog.com/profile
トラックバック:Megashipping.ru
トラックバック:grupoperuinnova.edu.pe
トラックバック:serr
トラックバック:https://hudson3y26drf5.wikievia.com/User
トラックバック:Www.72ZQ.Com
トラックバック:http://omskpol11.ru/user/cutpiano5/
トラックバック:Affiliate marketing income
トラックバック:https://Farmuzon.net/user/pickleheaven0
トラックバック:reseller web hosting
トラックバック:http://talk.dofun.cc/home.php?mod=space&uid=466905
トラックバック:maniadebeleza.com
トラックバック:join Dating Sites
トラックバック:5gbps offshore servers
トラックバック:that guy
トラックバック:forex robot
トラックバック:ทางเข้า sbobet
トラックバック:cheap dmca ignored hosting
トラックバック:ทางเข้า ufabet
トラックバック:Cuantoto Link Alternatif Login
トラックバック:รีวิว 10 เว็บพนัน esport พนันอีสปอร์ต dota csgo valorant rov ที่ดีที่สุด
トラックバック:เกมยิงปลาเงินจริง
トラックバック:ไฮหวย
トラックバック:แนะนำ 10 เว็บแทงมวยออนไลน์ที่ดีที่สุด | แทงมวยone แทงมวยพักยก
トラックバック:Zaragoza Soccer jersey
トラックバック:http://Efaonline365.com/__media__/js/netsoltrademark.php?d=smartars.bizgnuboard5bbsboard.phpbo_tablefreewr_id114926
トラックバック:ส้ม777
トラックバック:2gbps offshore servers
トラックバック:https://chaehyun.kr/wiki/api.php?action=http://hasitec.COM.Vn/
トラックバック:10gbps dedicated servers
トラックバック:https://cl-system.jp/question/decouvrez-tinel-timu-laval-un-talent-prometteur-du-football-178/
トラックバック:WWW.Santafeconsulting.net
トラックバック:Read A great deal more
トラックバック:fox888
トラックバック:xxx teen videos
トラックバック:https://www.hneos.net/
トラックバック:pafibangil.org
トラックバック:xn--Wh1bT3zwHI4LHM9b.CoM
トラックバック:https://hcf.kr/board_jAvG18/122079
トラックバック:http://Floridabluecrossblueshield.biz/__media__/js/netsoltrademark.php?d=WWW.Cqcici.comcommenthtml32149.html
トラックバック:outer glow not displaying photoshop
トラックバック:Hegnschtoafa-gedichte.at
トラックバック:http://hp-ad.sub.jp/nayami/nayamibbs/index.html
トラックバック:chissrate.com
トラックバック:Wolvesbaneuo.com
トラックバック:deadreckoninggame.com
トラックバック:equipaciones de futbol baratas 2024
トラックバック:รับจัดงานแต่งงาน
トラックバック:เช่าชุดไทย
トラックバック:เช่าชุดหมั้น
トラックバック:what do you think
トラックバック:http://Amfg.dyndns.org/tiki-tell_a_friend.php?url=https://Www.sherpapedia.org/index.php?title=User:FosterPatel59
トラックバック:betting exchange
トラックバック:Perfumesglam.com
トラックバック:http://Nasielska44.Phorum.pl/viewtopic.php?f=11&t=1968440
トラックバック:HCF.Kr
トラックバック:https://www.genbecle.com/index.php?title=Gym_Sur_La_Rive-Sud_:_Trouvez_Votre_Espace_Fitness_Id_al
トラックバック:watch free movies online
トラックバック:Pacificarmorscreen.com
トラックバック:Wiki.Roboco.co
トラックバック:백링크작업
トラックバック:lAYERt.ru
トラックバック:https://WWW.Sex8.zone/home.php?mod=space&uid=9411733&do=profile
トラックバック:vũ khí sinh học
トラックバック:more about Ww31.Accesscasinos.com
トラックバック:Old.Amerit.Org.mk
トラックバック:http://Ellsworthhouse.com/__media__/js/netsoltrademark.php?d=hegnschtoafa-gedichte.atindex.phptitleExterminateur_C3A0_Pointe-aux-Trembles__Votre_Solution_Contre_Les_Infestations
トラックバック:10000
トラックバック:9gm.ru
トラックバック:http://yanasawa.net/__media__/js/netsoltrademark.php?d=Wolvesbaneuo.com/wiki/index.php/boutiques_de_vtements__vieux-qu_bec_:_shopping_dans_un_cadre_historique
トラックバック:Www.banket66.ru
トラックバック:betis jersey
トラックバック:Cs.Xuxingdianzikeji.com
トラックバック:http://Wiki.Die-Karte-Bitte.de/index.php/D_couvrez_Le_Carrefour_Multisport_De_Qu_bec_:_Un_Centre_D_Excellence_Sportive
トラックバック:velocityteamsports.com
トラックバック:Maps.Google.lk
トラックバック:https://filmy-za-darmo-bez-Rejest04826.theobloggers.com/32535846/na-rauszu-cda
トラックバック:Dexless.Com
トラックバック:equipacion borussia dortmund 2024
トラックバック:CSE.Google.cat
トラックバック:https://Disqus.Com
トラックバック:https://troykynb37935.fireblogz.com/57663184/johnny-cały-film-za-darmo
トラックバック:Https://Cdkeyplay.Mystrikingly.Com/
トラックバック:hdorg2.ru
トラックバック:คาสิโนออนไลน์เว็บตรง ต่างประเทศ
トラックバック:https://gizmodo.uol.com.br/10-trusted-sicbo-site-vietnam/
トラックバック:http://40th.jiuzhai.com/space-uid-2746885.html
トラックバック:sovetl.Net
トラックバック:https://Si-sudagro.net/cdc-hiruak/index.php?qa=61469
トラックバック:wismabet slot login
トラックバック:https://gizmodo.uol.com.br/5-best-cockfighting-site-vietnam/
トラックバック:raso.su
トラックバック:Lottovip รีวิวเว็บแดง ดีไหม | เข้าสู่ระบบล่าสุด แอพล็อตโต้วีไอพี
トラックバック:togel4d
トラックバック:Imoodle.win
トラックバック:www.williamseal.com
トラックバック:dougtitcomb.com
トラックバック:jam gacor slot aztec
トラックバック:LInK2.rBTrAcK.Ru
トラックバック:http://Auldridge.com/__media__/js/netsoltrademark.php?d=wiki.rrtn.orgwikiindex.phpUserMarquis42Y
トラックバック:เว็บแพนด้าชมพู
トラックバック:발로란트 대리
トラックバック:Laskar303 Slot
トラックバック:cat888
トラックバック:Hit789 รีวิว ฮิต789 เข้าสู่ระบบ สมัคร หวยออนไลน์ จ่ายจริงไหม ดีไหม
トラックバック:visit this hyperlink
トラックバック:Laselection.Net
トラックバック:https://Trumpbookusa.com/blogs/148987/The-Gamer-s-Haven-Exploring-the-Pinnacle-of-Video-Game
トラックバック:no kyc casino
トラックバック:best Crypto casino
トラックバック:https://gizmodo.uol.com.br/สล็อตเว็บตรงอันดับ1/
トラックバック:Davidbrock.org
トラックバック:https://Mail.Awaker.info/home.php?mod=space&uid=7052875&do=profile&from=space
トラックバック:http://hegnschtoafa-gedichte.at/index.php?title=Agence_Web_:_Comment_Choisir_Le_Partenaire_Id_al_Pour_Votre_Projet
トラックバック:Ww17.logoprovider.nl
トラックバック:judi slot gacor
トラックバック:seo services
トラックバック:farmasi
トラックバック:pag bet
トラックバック:CuanToto
トラックバック:バイザー モニター
トラックバック:pagbet
トラックバック:situs toto
トラックバック:{link wismabet}
トラックバック:BOKEP INDONESIA
トラックバック:tani sex telefon
トラックバック:caluanie muelear oxidize cas no
トラックバック:buy hi tech codeine online
トラックバック:pengeluaran togel
トラックバック:login slot gacor terpercaya
トラックバック:http://Eredfern.com/__media__/js/netsoltrademark.php?d=Www.Shicaiwenhua.comhome.phpmodspaceuid57451doprofilefromspace
トラックバック:vinceramic.com
トラックバック:mrsartman.edublogs.org
トラックバック:http://Duckmovie.com/cgi-bin/a2/out.cgi?id=108&u=http://sdongha.com/Inquiry/120466
トラックバック:Sex Cams
トラックバック:matabola188
トラックバック:payroll and hris systems
トラックバック:hris systems for small companies
トラックバック:top hr software
トラックバック:Caméras Adultes En Direct
トラックバック:Sex Webcam Chat
トラックバック:situs toto togel
トラックバック:Free Private Webcam Shows
トラックバック:Private Live Cams
トラックバック:http://wiki.DIE-Karte-Bitte.de/index.php/Insectes_Domestiques_:_Conseils_Par_G_rer_Et_Pr_venir_Leur_Pr_sence
トラックバック:Nude Chat Rooms
トラックバック:Ls Awards
トラックバック:other sites like chaturbate
トラックバック:alexandra daddario sex tape
トラックバック:Naked At Work Videos
トラックバック:https://www.768589.xyz/
トラックバック:sarah hyland sex tape
トラックバック:top 20 female pornstars
トラックバック:https://Www.567378.xyz
トラックバック:latinas webcam en vivo
トラックバック:free porn men and women
トラックバック:https://www.287716.xyz/
トラックバック:free online sexy chat
トラックバック:site:chaturbate.com chaturbate
トラックバック:sex at home
トラックバック:leanorwatson chaturbate
トラックバック:sexiest pornstar ever
トラックバック:best free cam girls
トラックバック:xchaturbate
トラックバック:live webcam porno
トラックバック:hotfallingdevil chaturbate
トラックバック:little latina fucked
トラックバック:ear sex
トラックバック:indian gay sex
トラックバック:sex video chat free
トラックバック:amateur sex tape
トラックバック:sex with sis
トラックバック:free sex c
トラックバック:fr ee porn
トラックバック:hottest porn actress
トラックバック:sex video game
トラックバック:www.google.com
トラックバック:www.159085.xyz
トラックバック:cam 4.com
トラックバック:Https://www.586807.xyz
トラックバック:https://www.243457.xyz
トラックバック:voyeur webcams
トラックバック:net porn sex
トラックバック:fully clothed sex
トラックバック:www.895670.xyz
トラックバック:watch hair show online free
トラックバック:sex games apps
トラックバック:free amateur Sex
トラックバック:japanese sex movies
トラックバック:free hd pornstar video
トラックバック:george michael i want your sex
トラックバック:https://www.001041.xyz
トラックバック:Real Sex At Home
トラックバック:intl sex guide
トラックバック:average sex time
トラックバック:cuckquean Sex Stories
トラックバック:adult webcam sites
トラックバック:sex online live
トラックバック:taboo family sex
トラックバック:512361.xyz
トラックバック:streaming porn videos
トラックバック:porno gay webcam
トラックバック:dorm sex
トラックバック:m my free cam
トラックバック:www.321666.xyz
トラックバック:www.003565.xyz
トラックバック:sex memes funny
トラックバック:visit the up coming internet site
トラックバック:sex offender registry California
トラックバック:588555.xyz
トラックバック:sexy real sex dolls
トラックバック:new york sex offender registry
トラックバック:adult videos tube
トラックバック:nude sex video
トラックバック:live sex.com
トラックバック:https://www.297371.xyz
トラックバック:Girls naked videos
トラックバック:top porn
トラックバック:allison williams sex scene
トラックバック:sex and candy chords
トラックバック:search free porno
トラックバック:Free Adult Sex Cams
トラックバック:forced teen sex
トラックバック:www.518791.xyz
トラックバック:click through the next internet site
トラックバック:thailand luxury villas for rent
トラックバック:private villa in thailand
トラックバック:thailand villa rental luxury
トラックバック:thailand villas for rent long term
トラックバック:luxury villa thailand
トラックバック:thailand houses for rent
トラックバック:luxury thai villa
トラックバック:bi sex porn
トラックバック:hot sex positions
トラックバック:sex offender registry colorado
トラックバック:amber rose sex
トラックバック:bride Sex
トラックバック:xxx women porn
トラックバック:best sex lube
トラックバック:https://www.873333.xyz
トラックバック:witcher 3 sex scenes
トラックバック:calories burned during sex
トラックバック:www.929932.xyz
トラックバック:bbw public sex
トラックバック:sex education (tv series) cast
トラックバック:free gay sex
トラックバック:Hot Women Sex Video
トラックバック:Https://Www.Google.Com/Search?Q=Www.108678.Xyz&Sca_Esv=159F37A1251190F9&Sxsrf=ADLYWIJ1MU3VgoXQXSIGJyeFhr37-9X_Ng:1728378774672&Ei=LvcEZ5JrKOTfp84P_L2SmAw&Ved=0AhUKEwiYjpvXuP6IAxXk78KDHfyeBMMQ4DUDCA8&Uact=5&Oq=Www.108678.Xyz&Gs_
トラックバック:free porn webcam
トラックバック:casual sex project
トラックバック:booty sex
トラックバック:sex line free
トラックバック:horse sex tumblr
トラックバック:https://www.297372.xyz
トラックバック:sex-live
トラックバック:https://www.577548.xyz
トラックバック:Kristen Stewart Sex
トラックバック:australia same sex marriage
トラックバック:Margot Robbie Sex Scene
トラックバック:hypnosis sex
トラックバック:crossdresser sex videos
トラックバック:sex slaves
トラックバック:black tranny sex
トラックバック:watch online porn
トラックバック:Www.chatbulate.com
トラックバック:Sex xxxx
トラックバック:sex with stranger
トラックバック:Porn top
トラックバック:sex education in schools
トラックバック:live sexcams
トラックバック:tumblr anal sex
トラックバック:Https://www.358853.xyz
トラックバック:My fee cams
トラックバック:naked girls 18
トラックバック:forced sex tube
トラックバック:Our Web Page
トラックバック:cam live chat
トラックバック:sexy Porn Com
トラックバック:moms teaching sex
トラックバック:Sext online
トラックバック:www.273333.xyz
トラックバック:Franpost.com
トラックバック:click the next webpage
トラックバック:Moms sex videos
トラックバック:freecamgirl
トラックバック:webcam pornos gratis
トラックバック:sex offender lookup
トラックバック:villa rental in koh samui
トラックバック:koh samui best villa
トラックバック:koh samui rent villa
トラックバック:luxury villas in samui
トラックバック:Https://Www.531131.Xyzz/
トラックバック:https://www.webcamnudefree.com/video/25.html
トラックバック:https://www.freelivesexonline.com/post/189.html
トラックバック:https://www.sexywebcamchat.com/post/146.Html
トラックバック:www.freeonlinewebsex.com
トラックバック:recorded webcams
トラックバック:chatting live sex
トラックバック:check out this site
トラックバック:Amariah Morales Onlyfans Porn
トラックバック:porno video Fre
トラックバック:www.355668.xyz
トラックバック:chuturbate
トラックバック:free sex chat sites
トラックバック:https://www.sexcamonlinefree.com
トラックバック:chơi không lại đâu bắn cái địt mẹ mày
トラックバック:Usa sex guide Charlotte
トラックバック:wiki.eqoarevival.com link for more info
トラックバック:https://Trademarketclassifieds.com/user/profile/1568349
トラックバック:https://www.onlinelivesexcam.com
トラックバック:Khoiusa.com
トラックバック:sex fucking
トラックバック:Www.547878.xyz
トラックバック:cams en vivo
トラックバック:nude sex Women
トラックバック:babysitter sex stories
トラックバック:https://www.222524.xyz/
トラックバック:Chaturbate token generator 2024
トラックバック:http://Stageaile.com/g6/bbs/board.php?bo_table=free&wr_id=438769
トラックバック:public sex reddit
トラックバック:pool sex
トラックバック:wot trigger
トラックバック:freenudevideochat.com
トラックバック:543567.xyz
トラックバック:Pornstars on periscope
トラックバック:Real Mother And Son Sex
トラックバック:oregon sex offender registry
トラックバック:free sex vidoes
トラックバック:read this article
トラックバック:Freesexvideocam writes
トラックバック:Www.889929.xyz
トラックバック:best site for sex
トラックバック:https://www.001270.xyz
トラックバック:sibling sex stories
トラックバック:rhys sachett gay porn
トラックバック:news
トラックバック:hd live cams
トラックバック:Aina-test-com.check-xserver.jp
トラックバック:Galgbtqhistoryproject.org
トラックバック:couple love porn
トラックバック:https://www.170556.xyz
トラックバック:lesbian sex gifs
トラックバック:free sexy web cams
トラックバック:villa for rent in samui
トラックバック:surprise butt sex
トラックバック:nude Sites
トラックバック:boy sees girl naked
トラックバック:www.295555.xyz
トラックバック:http://burstyourseo.com/adserver/www/delivery/ck.php?ct=1&oaparams=2__bannerid=1264__zoneid=53__cb=91c220c132__oadest=httpwww.cqcici.comcommenthtml118588.html
トラックバック:http://Fengin.cn/member.asp?action=view&memName=CoralReeve0195837
トラックバック:Parikshagk.in
トラックバック:www.absib.ir
トラックバック:http://www.krasnogorsk.info/inside/userinfo.php?uid=1267565
トラックバック:https://softseller.com/cgi-bin/odbic.exe/ss/odb/affiliatelink.odb?s=203&a=varangarian&p=http//www.die-seite.comindex.phpastatsukathrynbloomfiel
トラックバック:Americaneggboard.org
トラックバック:bestfreeliveporn.Com
トラックバック:free por.com
トラックバック:sex dolls for women
トラックバック:teen sex vids
トラックバック:Cse.google.nu
トラックバック:https://www.google.co.mz/url?q=https://Squishmallowswiki.com/index.php/User:MarieKyte3999
トラックバック:https://worldaid.Eu.org/
トラックバック:ยูฟ่าเบท
トラックバック:https://iblog.iup.edu
トラックバック:WikI.DIE-karTe-bItTE.dE
トラックバック:ซื้อหวยออนไลน์24เว็บไหนดี 10 เว็บหวยออนไลน์อันดับ1 เว็บตรงจ่ายจริง
トラックバック:http://Nakedwater.com/__media__/js/netsoltrademark.php?d=q2A.My-stammtisch.deindex.phpqa157912qa_1all-star-competitive-cheerleading-uniforms-features-styles
トラックバック:https://observatoriodocinema.uol.com.br/internacional/entry-sbobet-new/
トラックバック:just click the next website
トラックバック:เว็บนอกไม่ผ่านเอเย่นต์
トラックバック:เว็บแทงบอลออนไลน์
トラックバック:เว็บตรง ไม่ผ่านเอเย่นต์
トラックバック:https://observatoriodocinema.uol.com.br/internacional/no1-slot-easy-jackpot-th/
トラックバック:best casinos welcome bonus
トラックバック:Bokep Viral Terkini
トラックバック:UnganexBit App review
トラックバック:Hentai Sex videos
トラックバック:Bokep Terkini Viral
トラックバック:https://Pipewiki.org/wiki/index.php/Aspirateurs_Traineaux_:_Efficacit_Et_Polyvalence_Pour_Un_Nettoyage_Complet
トラックバック:Si-sudagro.net
トラックバック:Squishmallowswiki.com
トラックバック:10 เว็บสล็อตเว็บตรงค่ายใหญ่ รีวิว สล็อตวอเลท เว็บตรง ล่าสุด แตกง่าย
トラックバック:Bokep terkini viral 2024
トラックバック:abigail spencer sex tape
トラックバック:http://www.die-seite.com/index.php?a=stats&u=sabrinawadham7
トラックバック:adult live cam
トラックバック:https://www.112888.xyz/
トラックバック:https://www.115333.xyz/shtmls/27.html
トラックバック:camporn
トラックバック:porn star sites
トラックバック:crystal palace kit
トラックバック:https://Www.sexywebcamchat.com
トラックバック:https://www.Sherpapedia.org/index.php?title=User:MargeneQuinonez
トラックバック:equipacion boca juniors
トラックバック:steven universe sex
トラックバック:www.youtucam.com
トラックバック:football shirt sale
トラックバック:https://www.google.com/search?q=www.150610.xyz&sca_esv=950106f6ed1bd84e&sxsrf=ADLYWILUXyRUtnoHae8FA0bx1FtZbAjBQA:1728821390430&ei=jrgLZ92BGsL8kPIPvtKUuAI&ved=0ahUKEwjdgO3GqYuJAxVCPkQIHT4pBScQ4dUDCA8&uact=5&oq=www.150610.xyz&gs_
トラックバック:chaturbate safe
トラックバック:garrettgwla37036.develop-blog.Com
トラックバック:fre sex dvd
トラックバック:latin female pornstars
トラックバック:เช่าชุดเจ้าสาว
トラックバック:https://www.sexcamonlinefree.com/shtmls/120.html
トラックバック:soccer streams
トラックバック:soccer stream
トラックバック:chats con camara gratis
トラックバック:porn web site
トラックバック:pig sex
トラックバック:free adult sex chat
トラックバック:you can find out more
トラックバック:the last of us porn Comics
トラックバック:ถ่ายพรีเวดดิ้ง
トラックバック:all+dutch+seventeen+vintage+porn+film+tubes
トラックバック:https://www.webcamsexlivefree.com/
トラックバック:live video sex
トラックバック:please click 567564
トラックバック:https://www.001280.xyz/
トラックバック:https://www.freelivesexonline.com/post/110.html
トラックバック:www.108678.xyz
トラックバック:you could try these out
トラックバック:https://www.onlinewebcamporn.com
トラックバック:totally free porno video
トラックバック:514410.xyz
トラックバック:https://www.759244.xyz
トラックバック:free home video porn
トラックバック:cam live xxx
トラックバック:Free amatuer Cams
トラックバック:frecams
トラックバック:number 1 pornstar
トラックバック:www.camchatporn.com write an article
トラックバック:ed edd n eddy gay porn
トラックバック:free sez videos
トラックバック:Cncfa.Com
トラックバック:001320.xyz
トラックバック:https://www.onlineporncam.com/movie/143.html
トラックバック:www.freenudevideochat.com
トラックバック:http://www.wikispedia.it/mediawiki/api.php?action=https://wiki.team-Glisto.com/index.php?title=Benutzer:AugustinaCastlet
トラックバック:online gay video chat
トラックバック:mouse click the next webpage
トラックバック:https://www.001217.xyz
トラックバック:visit Shoudyhosting here >>
トラックバック:Best video sex
トラックバック:https://www.001226.xyz
トラックバック:https://www.112888.Xyz
トラックバック:arsenal away jersey
トラックバック:free online cams
トラックバック:Www.860874.Xyz
トラックバック:pornvideos full hd
トラックバック:webcams room
トラックバック:porn stars free videos
トラックバック:Tolon.ir
トラックバック:Avocat CNESST
トラックバック:Agence SEO Paris
トラックバック:watch porno movies free
トラックバック:sex on camera
トラックバック:https://www.860872.xyz/
トラックバック:https://www.007979.xyz
トラックバック:free sez video
トラックバック:nude on cam
トラックバック:chatubate.com
トラックバック:Cl-system.jp
トラックバック:wWW.ASySTecHNiK.cOm
トラックバック:https://Cl-System.jp/question/la-clinique-saint-leonard-un-centre-de-soins-de-reference-54/
トラックバック:live porm
トラックバック:live adult sex cams
トラックバック:Wereyoueventhere.com
トラックバック:Bbs.Xiushui.net
トラックバック:sex cams free
トラックバック:camfree
トラックバック:www.280184.Xyz
トラックバック:https://Vuf.Minagricultura.Gov.co/Lists/Informacin Servicios Web/DispForm.aspx?ID=7589579
トラックバック:www.Onlinelivesexcam.com
トラックバック:https://www.113777.xyz/
トラックバック:www.Freeliveadultcams.com
トラックバック:https://www.freelivesexycam.com
トラックバック:https://www.google.com
トラックバック:m fuq c
トラックバック:chaturbats
トラックバック:hardcore lesbian sex
トラックバック:equipacion bayern munich
トラックバック:porno 4
トラックバック:023900.xyz
トラックバック:OgłOszenia Randkowe Olx
トラックバック:Bokep Indonesia Viral
トラックバック:mdT.BIGbaNG.FREE.fr
トラックバック:sex offenders list
トラックバック:Sexs Videos
トラックバック:https://to-Go-delivery.ck.page/fe8134a3c6
トラックバック:tsukimichi -moonlit fantasy- porn
トラックバック:https://www.Sexcameralive.com/html/59.html
トラックバック:Kenzo168
トラックバック:Consultant SEO Paris
トラックバック:SEP Hotel
トラックバック:free porn videos xx
トラックバック:Bongacomlive website
トラックバック:porn lives
トラックバック:https://www.860550.xyz
トラックバック:mchaturbate
トラックバック:watch free online porns
トラックバック:streaming porno sites
トラックバック:https://skalis.edublogs.org
トラックバック:can’t-believe-i’m-fucking-my-stripper-stepmom-nina-porn
トラックバック:nude live porn
トラックバック:www.012223.xyz
トラックバック:chat room for adult
トラックバック:tube galoreporn
トラックバック:https://www.150610.xyz
トラックバック:https://www.youtucam.com/html/94.html
トラックバック:such a good point
トラックバック:cam sex chat
トラックバック:Resource
トラックバック:odessa young nude
トラックバック:Adult Live Chat
トラックバック:https://Www.webcamsexlivefree.com/htmls/169.html
トラックバック:http://yinyue7.com/space-uid-1081591.html
トラックバック:www.870816.xyz
トラックバック:tee grizzley built for whatever
トラックバック:APK.Tw
トラックバック:https://www.onlinewebcamporn.com/post/33.html
トラックバック:emma lovare porn blowjob
トラックバック:Goomz Mushroom Gummies
トラックバック:https://www.chatcamporn.com/htmls/130.html
トラックバック:Porno Websites
トラックバック:please click the following internet page
トラックバック:sultry summer porn comics
トラックバック:oFFicIaLLYawEsomE.COM
トラックバック:Boekp Viral
トラックバック:Fishtanklive.wiki
トラックバック:gmcguire.digital.uic.edu
トラックバック:웹캠 캠 걸
トラックバック:Strona z kamerami seksu na żywo
トラックバック:enquiry
トラックバック:Search.osakos.com
トラックバック:http://WWW.Suits.ipt.pw/user/beaumosher/
トラックバック:Bokep Viral
トラックバック:https://dreamitdoitvirginia.com
トラックバック:바카라사이트
トラックバック:https://medea.medianet.cs.kent.edu/mediawiki/index.php/Prix_De_L_Entretien_M_nager_R_sidentiel__Qu_bec_:_Ce_Que_Vous_Devez_Savoir
トラックバック:http://Edid.co.kr/bbs/board.php?bo_table=free&wr_id=435159
トラックバック:letts.org
トラックバック:Free Webcam Shows
トラックバック:Advrider.Com
トラックバック:xademan.com
トラックバック:Bokep Indonesia 2024
トラックバック:Going In this article
トラックバック:www.112888.xyz
トラックバック:www.freeliveadultchat.com
トラックバック:Www.Sexcameralive.com
トラックバック:www.freeadultsexcams.com
トラックバック:masters of sex cast
トラックバック:sex video bangladeshi actress
トラックバック:Www.116333.xyz
トラックバック:www.livecamsexshow.com
トラックバック:live sex camera
トラックバック:teen masturbation webcams
トラックバック:free webcam sex show
トラックバック:watch free xxx movie
トラックバック:aduly chat
トラックバック:freesex video
トラックバック:best petite pornstars
トラックバック:http://www.die-seite.com/index.php?a=stats&u=terriwunderly99
トラックバック:audio-snuff-extreme-porn
トラックバック:Www.783709.xyz
トラックバック:001660.xyz
トラックバック:Mediawiki.Aqotec.com
トラックバック:https://www.275785.xyz
トラックバック:clicking here
トラックバック:http://Plumislandicedtea.com/__media__/js/netsoltrademark.php?d=www.Records-research.bookmarking.siteuservdomaurice
トラックバック:google.com
トラックバック:you porno free
トラックバック:hot sex.com
トラックバック:http://mananasdpelicula.Com/
トラックバック:güvenilir bahis siteleri
トラックバック:http://spiritcenterforthenations.Org/
トラックバック:สาวถ้ำpg
トラックバック:browse this site
トラックバック:Indiaebooks.com
トラックバック:visit the following internet page
トラックバック:www.bongacomlive.com
トラックバック:catering Soto jakarta
トラックバック:bandar togel online
トラックバック:http://letts.org/wiki/User:Georgia5821
トラックバック:Bokep Viral 2025
トラックバック:pln88
トラックバック:Beachesofseychelles.com
トラックバック:youranchortexts
トラックバック:lekker bets
トラックバック:http://Handmadeinsanfrancisco.com/__media__/js/netsoltrademark.php?d=dztrader.comforumindex.phpactionprofileu141555
トラックバック:http://Granadaarts.com/__media__/js/netsoltrademark.php?d=cl-system.jpquestiontout-en-ce-qui-concerne-le-desembuage-des-vitres-thermos-26
トラックバック:밤문화
トラックバック:오피
トラックバック:Centrala telefonica cu suport tehnic
トラックバック:Bắn Cá Đổi Thưởng
トラックバック:hiop
トラックバック:하이오피주소
トラックバック:출장안마
トラックバック:오피커뮤니티
トラックバック:안마
トラックバック:op
トラックバック:gls-Fun.Com
トラックバック:광주유흥
トラックバック:하이오피사이트
トラックバック:유흥
トラックバック:역삼오피
トラックバック:제주유흥
トラックバック:오피사이트
トラックバック:bbs.xiaodingchui.com
トラックバック:alva jay sex videos
トラックバック:modamasculinajournal.com.br
トラックバック:출장마사지
トラックバック:www.libertaepersona.org
トラックバック:하이오피
トラックバック:Centrala telefonica hibrida
トラックバック:광주휴게텔
トラックバック:Kuwaits Best Online Casinos in 2024
トラックバック:research by the staff of mongocco.sakura.ne.jp
トラックバック:refvizit.ru
トラックバック:see it here
トラックバック:www.sexwithsister.com
トラックバック:http://prof61.Ru
トラックバック:Click On this website
トラックバック:read this post here
トラックバック:just click the following web site
トラックバック:강남오피
トラックバック:Sunginmall.com
トラックバック:www.115777.xyz
トラックバック:Online Casinos in Hong Kong
トラックバック:https://www.241213.xyz
トラックバック:https://www.160722.xyz
トラックバック:다바오환전
トラックバック:출장
トラックバック:Http://machikadonet.Com/
トラックバック:광주알밤
トラックバック:have a peek at this site
トラックバック:maddie&
トラックバック:www.001620.xyz
トラックバック:알밤
トラックバック:골드페이
トラックバック:https://gls-Fun.com/cat/cat/ape/p15/apeboard_plus.cgi
トラックバック:다바오4989
トラックバック:www.224900.xyz
トラックバック:유흥사이트
トラックバック:Https://hk.Tiancaisq.com/
トラックバック:https://Www.camshowsex.com/html/168.html
トラックバック:광주오피
トラックバック:zeleanu01
トラックバック:Eurasiasnaglobal.Com
トラックバック:논현오피
トラックバック:www5b.biglobe.ne.jp
トラックバック:try these out
トラックバック:아이러브밤
トラックバック:details of offshore web hosts
トラックバック:다바오
トラックバック:https://cl-System.jp/question/cours-de-soutien-scolaire-sur-le-quebec-maximisez-le-potentiel-academique-de-votre-enfant-8/
トラックバック:GOLDPAY
トラックバック:davao
トラックバック:bbs.wuxhqi.Com
トラックバック:부산유흥
トラックバック:on front page
トラックバック:다바오포커
トラックバック:http://zeroken.jp/1978td/album/album.Cgi?mode=detail&no=19
トラックバック:광주키스방
トラックバック:인천유흥
トラックバック:https://Sciencewiki.Science/
トラックバック:Read More Here
トラックバック:Suggested Site
トラックバック:funds affiliate San Diego reviews
トラックバック:https://images.google.com.gt/url?q=http://Www.0768Baby.com/comment/html/?277964.html
トラックバック:https://rc-travaux.com/
トラックバック:다바오홀덤
トラックバック:365xca-9-comp-ms-ca
トラックバック:https://www.001260.xyz
トラックバック:sexcameralive.com
トラックバック:marleny la maestra porn
トラックバック:csa.Sseuu.Com
トラックバック:made my day
トラックバック:the best free porn
トラックバック:similar internet site
トラックバック:https://godtiervalentinehitbox.wordpress.com/
トラックバック:visit the next website
トラックバック:https://www.001219.xyz
トラックバック:테라피
トラックバック:maza porn videos
トラックバック:Https://www.Cbd-indoor.click/
トラックバック:live online porn
トラックバック:murder mystery items
トラックバック:https://www.onlineporncam.com/movie/81.html
トラックバック:www.chatterbatecam.com
トラックバック:murder mystery buy
トラックバック:Grooming-Umemura.Jp
トラックバック:www.porndvdstream.com
トラックバック:mouse click on 113888
トラックバック:best real estate agent in Pittsboro NC
トラックバック:real estate agent in Bedford NH
トラックバック:Hippy published a blog post
トラックバック:watch webcam the sex free
トラックバック:porn vídeo download
トラックバック:Www.Bestfreepornwebsites.Com
トラックバック:simply click the next site
トラックバック:use sotempla.com here
トラックバック:free sex line
トラックバック:marketmed.kz
トラックバック:www.chatburte.com
トラックバック:best realtor in Pittsboro NC
トラックバック:Https://Www.Chatterbaitcams.Com/Post/24.Html
トラックバック:https://www.hottestpornactress.com
トラックバック:page
トラックバック:대전유흥
トラックバック:best realtor in Baton Rouge LA
トラックバック:윌슨 에볼루션 아웃도어
トラックバック:best real estate agent in Baton Rouge LA
トラックバック:Bokep Terbaru
トラックバック:right here on www.freelivesexycam.com
トラックバック:Fdsax.71It.Ru
トラックバック:다바오다운로드
トラックバック:best real estate agent in Bedford NH
トラックバック:real estate agent in Jackson CA
トラックバック:libaware.economads.Com
トラックバック:alex grey porn gif
トラックバック:realtor in Youngstown OH
トラックバック:www.webcamsexlivefree.com
トラックバック:best realtor in Youngstown OH
トラックバック:realtor in Baton Rouge LA
トラックバック:ero-Video
トラックバック:you pornos
トラックバック:dree porn
トラックバック:Obat kuat
トラックバック:AdBIQ User Acquisition Agency
トラックバック:straightening brush
トラックバック:Entertainment News
トラックバック:bokep indo
トラックバック:brittanya razavi sex video
トラックバック:포포인츠 바이 쉐라톤 명동 뷔페 에볼루션
トラックバック:Dreslee says
トラックバック:Read More Listed here
トラックバック:realtor in Jackson CA
トラックバック:writes in the official Ne blog
トラックバック:https://www.Dealigg.com/shop.php?url=http://Clrobur.com/bbs/board.php?bo_table=free&wr_id=2419156
トラックバック:https://securityholes.science/
トラックバック:real estate agent in Youngstown OH
トラックバック:best realtor in Bedford NH
トラックバック:다바오머니상
トラックバック:realtor in Pittsboro NC
トラックバック:realtor in Bedford NH
トラックバック:best real estate agent in Jackson CA
トラックバック:best realtor in Jackson CA
トラックバック:다바오충전
トラックバック:real estate agent in Baton Rouge LA
トラックバック:www.115333.xyz
トラックバック:헝그리샤크 에볼루션 티어
トラックバック:best real estate agent in Youngstown OH
トラックバック:real estate agent in Pittsboro NC
トラックバック:lovewiki.faith
トラックバック:dat Ass porn comics
トラックバック:대구유흥
トラックバック:rebel rhyder Hookup
トラックバック:mouse click the next site
トラックバック:http://www.aa.cyberhome.ne.jp/
トラックバック:https://www.sexchatcamera.com/porn/35.html
トラックバック:https://www.eeporn.com/
トラックバック:head to Mosvedi
トラックバック:https://www.freelivesexonline.com/post/169.html
トラックバック:www.camchatporn.com
トラックバック:에볼루션 모노폴리 빅볼러
トラックバック:webplaza003.dmonster.kr
トラックバック:다바오머니
トラックバック:https://www.youtucams.com
トラックバック:www.camchatadult.com
トラックバック:www.mobilechaturbate.com
トラックバック:https://www.webcamsexlivefree.com/htmls/153.html
トラックバック:마사지
トラックバック:www.freesexvideocam.com
トラックバック:서울유흥
トラックバック:why not look here
トラックバック:https://Www.chachurbate.com/movie/66.html
トラックバック:광주마사지
トラックバック:잠실오피
トラックバック:congrats on the sex
トラックバック:에볼루션 조작슈
トラックバック:Http://brechobebe.com.Br/index.php/author/williemaeca/
トラックバック:http://www.okgim.Co.kr/bbs/board.php?bo_table=free&wr_id=158644
トラックバック:www.freelivesexycam.com
トラックバック:압구정오피
トラックバック:haley reed porn gif
トラックバック:www.marasex.com
トラックバック:Vinci Spin Casino
トラックバック:https://www.chatcamporn.com/htmls/20.html
トラックバック:www.camtocamnude.com
トラックバック:recent marria-web.s35.xrea.com blog post
トラックバック:husband and wife sex
トラックバック:http://chandelierspareparts.com
トラックバック:Www.Aha.ru
トラックバック:Flat Tire Repair
トラックバック:The Loud Plug
トラックバック:Hot Tub Cover
トラックバック:men erection pill
トラックバック:언더월드 2: 에볼루션
トラックバック:Www.freelivecamporn.com
トラックバック:q-force gay porn
トラックバック:https://www.sexcameralive.com/html/86.html
トラックバック:www.freecamtocamsex.com
トラックバック:Full Write-up
トラックバック:에볼루션 카지노 먹튀
トラックバック:free p orn
トラックバック:m.argonautiexplorers.it
トラックバック:Bbs.Flashdown365.Com
トラックバック:www.freelivecamsites.com
トラックバック:the cleveland show comic Porn
トラックバック:https://www.freeseolink.org/
トラックバック:https://www.108678.xyz/
トラックバック:Asterisk-e.com
トラックバック:Related Homepag
トラックバック:포포인츠 바이 쉐라톤 명동 에볼루션
トラックバック:https://www.onlinelivesexcam.com/
トラックバック:Jimmyburns.com
トラックバック:“에볼루션 카지노 바카라 잘하는 법
トラックバック:Symphony.fem.Jp
トラックバック:선릉오피
トラックバック:Historydb.Date
トラックバック:click over here now
トラックバック:디지몬 어드벤처 라스트 에볼루션 다시 보기
トラックバック:https://www.youtucam.com/html/13910.html
トラックバック:https://www.chatcamporn.com
トラックバック:발로란트 에볼루션
トラックバック:zmeenaorr porn videos
トラックバック:Nst@Akio.sakura.ne.jp
トラックバック:escort in aberdeen
トラックバック:updated blog post
トラックバック:pop over to this web-site
トラックバック:video of woman and dog having sex
トラックバック:terzas.plantarium-noroeste.es
トラックバック:he has a good point
トラックバック:https://www.sexywebcamchat.com/post/161.html
トラックバック:Sakura`s latest blog post
トラックバック:gta 5 rp porn
トラックバック:https://www.teensextumblr.Com
トラックバック:www.023900.xyz
トラックバック:www.javdude.net
トラックバック:Avocat alcool au volant
トラックバック:Avocat Agression Sexuelle
トラックバック:https://spacev.pro/2022/10/30/bonjour-tout-le-monde/
トラックバック:https://onlineporncam.com/movie/165.html
トラックバック:Learn Additional
トラックバック:https://www.Chatterbatecam.com/porn/73.html
トラックバック:www.anweshannews.com
トラックバック:Net-pier.Biz
トラックバック:http://girlssexfree.com
トラックバック:15 sec porn
トラックバック:renskestroet.Nl
トラックバック:건담 에볼루션 갤러리
トラックバック:my fav cam
トラックバック:에볼루션 채팅제한
トラックバック:jurassic world chaos theory porn
トラックバック:www.hirlevel.wawona.hu
トラックバック:video pornos españolas
トラックバック:https://www.freenudevideochat.com/
トラックバック:Web cam xxx
トラックバック:https://www.webcamnudefree.com
トラックバック:Freebestpornsites.Com
トラックバック:Read Far more
トラックバック:에볼루션 가상머니
トラックバック:에볼루션 발로란트
トラックバック:https://www.chatabte.com
トラックバック:fnaf porn games android
トラックバック:Www.Chatterbaitcams.com
トラックバック:http://Forum.altaycoins.com/profile.php?id=942762
トラックバック:classical electronic music
トラックバック:goth
トラックバック:rave music
トラックバック:synthwave nightride
トラックバック:https://www.sfkorean.com/
トラックバック:裝修設計公司
トラックバック:청량고추 에볼루션
トラックバック:metal steel building
トラックバック:https://aboriginalcuratorialcollective.org/
トラックバック:flexsol
トラックバック:electronic experimental
トラックバック:Wildleaf.Org
トラックバック:대출
トラックバック:http://center.Zerocert.org/safeguard/?site=365.Expresso.blog/question/thermopompe-daikin-un-choix-fiable-pour-votre-confort-thermique-3/
トラックバック:http://cupak.sk/index.php?option=com_phocaguestbook&id=1
トラックバック:Onlineporncam.com
トラックバック:부산
トラックバック:www.yaweragha.com
トラックバック:ver videos pornogrficos
トラックバック:https://www.Porndvdstream.com/
トラックバック:Http://Net-Pier.Biz/
トラックバック:official statement
トラックバック:에볼루션 자판기
トラックバック:https://www.pornsitefree.com
トラックバック:www.camshowsex.com
トラックバック:윌슨 에볼루션 vs 퓨어샷
トラックバック:Free Live XXX
トラックバック:Live Porn Video
トラックバック:Free Sex Webcam Shows
トラックバック:Sex Chat Cams
トラックバック:Free Sex Video Chat
トラックバック:Ζωντανή τοποθεσία Web κάμερας σεξ
トラックバック:Сајт за секс камеру
トラックバック:restomenteng.Id
トラックバック:Adult Live Shows
トラックバック:freelivesexonline.com
トラックバック:Live Girls Cam Free
トラックバック:Live-Sex-Site
トラックバック:Оголена веб-камера
トラックバック:Pornokaamerad
トラックバック:you could look here
トラックバック:Live Sex Shows
トラックバック:Couple Live Sex Cams
トラックバック:Free Nude Shows
トラックバック:Freewebcamchatonline.com
トラックバック:Free Adult Chat
トラックバック:Titta på Sex Shows Cams Sex Chat
トラックバック:Freeadultsexcams.Com
トラックバック:Webcam Sex Shows
トラックバック:cosmetic folding boxes
トラックバック:에볼루션 블랙잭 룰
トラックバック:Cam porno
トラックバック:Free Cam Girls Shows
トラックバック:www.ozportal.tv
トラックバック:Webcam Girls
トラックバック:Kamere za odrasle
トラックバック:XXX kamera
トラックバック:babes com busty porn videos
トラックバック:에볼루션 카지노사이트
トラックバック:Free Webcam Sex
トラックバック:www.sexcamonlinefree.com
トラックバック:efftlab.Ru
トラックバック:Beste Webcam Sex
トラックバック:elevator sex
トラックバック:Https://Elearnportal.Science/
トラックバック:Live Nude Girls
トラックバック:Ücretsiz Seks Kameraları
トラックバック:쥬라기 에볼루션
トラックバック:크레이지타임 에볼루션
トラックバック:Cele mai bune site-uri de sex live
トラックバック:Hot Sex Chat
トラックバック:Live XXX Chat Rooms
トラックバック:https://www.camtocamnude.com/html/33.html
トラックバック:Webcam nudo
トラックバック:Timeoftheworld blog article
トラックバック:https://www.bestpornstreamingsites.com
トラックバック:מופעים בחינם
トラックバック:Free Cam Shows
トラックバック:http://iwanttoseeporn.com
トラックバック:check out this blog post via misojin.co
トラックバック:the deep is calling roblox porn
トラックバック:Сайти безкоштовного сексу в реальному часі
トラックバック:Zlobivé Webkamera Show
トラックバック:Adult Webcam Video
トラックバック:Filles Webcam En Direct
トラックバック:Free Porn Live
トラックバック:Live Porn Chat
トラックバック:www.786758.xyz
トラックバック:mouse click the following internet site
トラックバック:Additional Info
トラックバック:Free Live Sex Cams
トラックバック:Real Sex Cams
トラックバック:Free Cam Chat
トラックバック:www.Ruspeach.com
トラックバック:부달최신주소
トラックバック:ライブ セックス カム セックス セックス
トラックバック:最佳性愛網站
トラックバック:Hot Webcam Girls
トラックバック:אתר הסקס הטוב ביותר
トラックバック:Private Sex Cams
トラックバック:Business News
トラックバック:stem cell thailand
トラックバック:Webdesign Agentur Zürich
トラックバック:Fractional digital marketing
トラックバック:Fractional digital marketing agency
トラックバック:에볼루션 파싱 구별
トラックバック:Gratis Live Sex
トラックバック:cost estimation techniques
トラックバック:Global News
トラックバック:modular sectional sofa
トラックバック:best cozumel dive shops
トラックバック:Сајтови за секс ћаскање уживо
トラックバック:Webdesigner Zürich
トラックバック:Live Sex Cam-side
トラックバック:WordPress Agentur
トラックバック:stem cell treatment
トラックバック:Fractional CMO agency
トラックバック:videos pornos hermanos
トラックバック:Sports News
トラックバック:सेक्स
トラックバック:Webagentur Zug
トラックバック:Younganalporn.com
トラックバック:https://Pezeshkaddress.com/up/——/
トラックバック:https://www.mobilechaturbate.com/indian-sex-leak-videos.htm
トラックバック:violet myers porn gifs
トラックバック:check these guys out
トラックバック:http://m-care.biz/
トラックバック:www.chatturb.com
トラックバック:https://lookerstudio.google.com/embed/s/nOlipLrHw-Q
トラックバック:울산
トラックバック:Nettsteder for live sex-webkameraer
トラックバック:mom teach sex full video
トラックバック:https://www.camchatporn.com
トラックバック:sex videos new telugu
トラックバック:Porno
トラックバック:find more info
トラックバック:www.teensextumblr.com
トラックバック:에볼루션 바카라 딜러
トラックバック:uşAk çEkici
トラックバック:slot gacor hari in
トラックバック:Ilmainen seksikamera
トラックバック:Free XXX Cams
トラックバック:http://gotanproject.net/node/24315565?——WebKitFormBoundaryKmBzVVu553KmTvdDContent-Disposition:form-data;name=titleLaPhysiothrapiedel’quilibre:RtablirlaStabilitpouruneMeilleureSant——WebKitFormBoundaryKmBzVVu553KmTvdDContent-Disposition:form-data;n
トラックバック:Online Sex Chat
トラックバック:https://Cl-System.jp/question/short-term-loan-10/
トラックバック:singapore restaurant
トラックバック:https://sunvueoutdoorliving.com/
トラックバック:Kukeseente tervislikud omadused
トラックバック:peer-faq.De
トラックバック:XXX Live Cams
トラックバック:Online Sex Cams
トラックバック:Nude Live Girls
トラックバック:에볼루션 용호
トラックバック:https://www.bongacomlive.com/
トラックバック:Live Adult Chat
トラックバック:Http://Seiryukan.Skr.Jp/
トラックバック:adulthomevideoclips.com
トラックバック:에볼루션 취업
トラックバック:streaming pornsite
トラックバック:Free Nude Chat Rooms
トラックバック:Youtucam.com
トラックバック:http://jahc.inckorea.net/bbs/board.php?bo_table=customer2&Wr_id=908325
トラックバック:Cc2088.Cn
トラックバック:pgslot005.Online
トラックバック:www.chatcamporn.com
トラックバック:simply click center.zerocert.org
トラックバック:https://www.chattrube.com/movies/77.html
トラックバック:Nude Girls Live
トラックバック:research by the staff of opensourcebridge.science
トラックバック:brazzers porn full video
トラックバック:the full report
トラックバック:عروض الجنس عبر كاميرا الويب
トラックバック:More Help
トラックバック:롤 에볼루션
トラックバック:simply click the next website page
トラックバック:Sugardaddyschile.cl
トラックバック:부달주소
トラックバック:Biopolytech.com`s latest blog post
トラックバック:Sdongha.com
トラックバック:Tangguifang.Dreamhosters.com
トラックバック:proxy list
トラックバック:how to make money off snapchat
トラックバック:can whatsapp channel be monetized
トラックバック:good proxys
トラックバック:부달
トラックバック:how to make money on snapchat
トラックバック:부산부달
トラックバック:visit the following website page
トラックバック:먹튀토토 먹튀바카라 에볼루션
トラックバック:can you make money on pinterest by posting pictures
トラックバック:urbanrealestate.co.za
トラックバック:언더월드 에볼루션 다시보기
トラックバック:Cutie mark Crusaders Porn
トラックバック:Sexo en vivo Sexo Sexo Cámara web
トラックバック:try this web-site
トラックバック:에볼루션 주소
トラックバック:Porno Video
トラックバック:learn this here now
トラックバック:Http://Cksr0Ar36Ezxo.Com
トラックバック:telegram monetization
トラックバック:paginas web andorra
トラックバック:Chessdatabase website
トラックバック:a fantastic read
トラックバック:www.qiumo.org
トラックバック:www.113888.xyz
トラックバック:jenny scordamaglia porn video
トラックバック:Https://Lookerstudio.Google.Com
トラックバック:에볼루션 x
トラックバック:디지몬 어드벤처 라스트 에볼루션 다시보기
トラックバック:10MEktEp-nS.eDU.Kz
トラックバック:pop over to these guys
トラックバック:http://Gotanproject.net/node/24323113?——WebKitFormBoundaryV3ve3Uo5DFsLPsCmContent-Disposition:form-data;name=titleSecuredLoans:UnderstandingtheBasics——WebKitFormBoundaryV3ve3Uo5DFsLPsCmContent-Disposition:form-data;name=bodyAsecuredloanisasortofbo
トラックバック:similar webpage
トラックバック:Www.kmbi.co.kr
トラックバック:http://Lcdpt.com
トラックバック:에볼루션 딜러
トラックバック:have a peek at this web-site
トラックバック:sex video tamil hd
トラックバック:Xn–cw0b40fftoqlam0o72a19qltq.kr
トラックバック:Going to Marketingme
トラックバック:budal
トラックバック:https://www.freebestpornsites.com/movies/54.html
トラックバック:Free Porno
トラックバック:에볼루션 검증
トラックバック:에볼루션 보드게임
トラックバック:Movers Calgary
トラックバック:saiba mais
トラックバック:Adult Toy Store SEO
トラックバック:right here on www.youtucams.com
トラックバック:8n8n.co.jp
トラックバック:http://howtofuckapornstar.com
トラックバック:https://www.chatterbatecam.com
トラックバック:https://www.bez-politikov.sk/
トラックバック:http://Ternstyle.com/__media__/js/netsoltrademark.php?d=Www.die-seite.comindex.phpastatsujamisonkong684
トラックバック:Www.Bestfreeliveporn.com
トラックバック:big booty ebony scat porn
トラックバック:Leeds Escorts Agency
トラックバック:https://www.sexchatcamera.com/
トラックバック:https://www.webcamsexlivefree.com
トラックバック:Read Birdstoppers
トラックバック:www.sexywebcamchat.com
トラックバック:streempornfree.Com
トラックバック:울산유흥
トラックバック:http://Ihatemichaelscrafts.net/__media__/js/netsoltrademark.php?d=www.zgcksxy.comcommenthtml273353.html
トラックバック:http://christophespecklin.com
トラックバック:speaking of
トラックバック:https://2ip.io/ua/info/160.251.122.192/
トラックバック:Https://Www.Marasex.Com/
トラックバック:eugosto.pt
トラックバック:how to advertise my telegram channel
トラックバック:xn--910b51awts1dcyjz0nhig3khn34a.kr
トラックバック:advertising network
トラックバック:WWW.Cqcici.com
トラックバック:a knockout post
トラックバック:best ad networks
トラックバック:digital advertising platforms
トラックバック:online ads
トラックバック:telegram ads example
トラックバック:Telegram ads in mini apps
トラックバック:discrepency
トラックバック:Vocal.media
トラックバック:Fractional marketing agency
トラックバック:다바오 바다 전망 나오는 호텔
トラックバック:Online Live Cams
トラックバック:Fractional marketing consulting
トラックバック:online marketing and advertising
トラックバック:Digital marketing agency
トラックバック:Fractional marketing services
トラックバック:marketing ads
トラックバック:telegram mini app
トラックバック:https://www.sexyfreeporn.com/men-sex-with-animals-videos.htm
トラックバック:에볼루션 뜻
トラックバック:다바오 수영장있는 호텔
トラックバック:telegram traffic analysis
トラックバック:how to monetize tma
トラックバック:Fractional CMO services
トラックバック:ad company
トラックバック:Fractional SEM
トラックバック:how to create telegram mini app
トラックバック:https://www.sexcamonlinefree.com/
トラックバック:https://www.freeadultsexcams.com/
トラックバック:advertising company
トラックバック:online advertising platforms
トラックバック:Shemale Fleshlight Porn Gifs
トラックバック:Fractional marketing company
トラックバック:mobile advertising network
トラックバック:just click the up coming post
トラックバック:ad online
トラックバック:Fractional camping management
トラックバック:Fractional demand generation
トラックバック:Romanian
トラックバック:juna juna juice porn
トラックバック:animekun.ru
トラックバック:hyeonhae.co.kr
トラックバック:lookerstudio.google.com
トラックバック:continue reading this..
トラックバック:anal Sex pictures
トラックバック:115333 official blog
トラックバック:https://www.youtucam.com/cat/JOI
トラックバック:에볼루션 영상
トラックバック:Read the Full Write-up
トラックバック:Fnia Gacha Life Porn
トラックバック:hololivematome.fc2.page
トラックバック:https://Cl-System.jp/question/credit-facile-et-rapide-conseils-par-faire-le-bon-choix-78/
トラックバック:Explore Estonia
トラックバック:SEO Agency
トラックバック:Sam Peixoto
トラックバック:good morning porn gifs
トラックバック:에볼루션 카지노 가입
トラックバック:nodeposit
トラックバック:https://www.webcamsexlivefree.com/htmls/79.html
トラックバック:에볼루션 바카라 영상
トラックバック:www.ozportal.tv said in a blog post
トラックバック:다바오 포커 vpn
トラックバック:Sexo Sexo Sexo en vivo Sitios de sexo en vivo
トラックバック:mature women porn gifs
トラックバック:videos de pornos xxxxx
トラックバック:부산달리기
トラックバック:woman has sex with dog
トラックバック:xnxx com free porn
トラックバック:https://www.sexywebcamchat.com/post/51.html
トラックバック:youtucams.com
トラックバック:https://www.freeonlinewebsex.com/
トラックバック:visit the following post
トラックバック:에볼루션 생바
トラックバック:Лучший сайт секса в прямом эфире
トラックバック:doosung1.co.kr website
トラックバック:www.chatturbatt.com
トラックバック:www.365femalemcs.com
トラックバック:Adresa.Murman.ru
トラックバック:https://OKE.Zone/profile.php?id=101135
トラックバック:https://www.onlinewebcamporn.com/
トラックバック:please click the following webpage
トラックバック:슬롯 사이트
トラックバック:آشمگ
トラックバック:proxy providers
トラックバック:sex videos download full
トラックバック:https://Hotfri.Com
トラックバック:Psicoterapeuta Reggio Emilia
トラックバック:다바오 투어
トラックバック:آش مگ
トラックバック:binbrook limousine service
トラックバック:boat rental in Dubai
トラックバック:gay porn star tucker johnson
トラックバック:www.e10100.com
トラックバック:out-of-state license reinstatement lawyer
トラックバック:embrun limo service
トラックバック:get my illinois driver’s license back
トラックバック:proxies
トラックバック:proxys
トラックバック:https://Copuszn.ru/bitrix/rk.php?id=25&event1=banner&event2=click&event3=1++25+PARTNERS++&goto=httpBio.Rogstecnologia.Com.braliciatietke
トラックバック:اکو قلب در منزل
トラックバック:http://Dtyzwmw.com/comment/html/?17679.html
トラックバック:خرید سی پی کالاف دیوتی موبایل
トラックバック:https://oke.zone/profile.php?id=117074
トラックバック:http://wispers.com/__media__/js/netsoltrademark.php?d=www.gz-jj.comcommenthtml254770.html
トラックバック:yacht rental Dubai
トラックバック:슬롯머신사이트
トラックバック:파라오카지노계열
トラックバック:drivers license restoration lawyer
トラックバック:nude sex indian video
トラックバック:makeup organizer bag
トラックバック:Rising Toronto drill artists playlist
トラックバック:www.chatabte.com
トラックバック:http://Threemovesyoucanbank.com/__media__/js/netsoltrademark.php?d=oke.zoneprofile.phpid105876
トラックバック:Psicologo Reggio Emilia
トラックバック:polyurethane catalysts manufacturer
トラックバック:에볼루션 바카라 규칙
トラックバック:https://www.freelivesexonline.com/post/109.html
トラックバック:Lincoln mkz limousine
トラックバック:Psichiatra Reggio Emilia
トラックバック:https://www.freelivecamsites.com/htmls/123.html
トラックバック:https://oke.zone/profile.php?id=117493
トラックバック:attorney for license reinstatement
トラックバック:https://www.chatburte.com/movies/46.html
トラックバック:hardship license attorney
トラックバック:라이트닝 에볼루션
トラックバック:https://www.115333.xyz/shtmls/43.html
トラックバック:다바오 인터넷
トラックバック:Cougar
トラックバック:에볼루션 카지노 바카라
トラックバック:masterkabal lara croft porn
トラックバック:http://signsealplans.com/__media__/js/netsoltrademark.php?d=www.Die-seite.comindex.phpastatsudominiquekellehe
トラックバック:posicionamiento seo andorra
トラックバック:Coffee barista training
トラックバック:https://Processarts.com/forums/topic/salon-esthetique-a-terrebonne-votre-destination-beaute-3/
トラックバック:https://chattrube.com/movies/64.html
トラックバック:freespins
トラックバック:http://Loadmule.com/__media__/js/netsoltrademark.php?d=Kuzeydogu.ogo.org.trquestionpret-de-500-au-canada-ce-quil-faut-savoir-avant-de-contracter-un-pret-de-petite-somme-8
トラックバック:닌자거북이 에볼루션 레오나르도
トラックバック:에볼루션 취소
トラックバック:Full Survey
トラックバック:헝그리샤크 에볼루션 버그판 2023
トラックバック:portal.goosevpn.com
トラックバック:에볼루션 파워볼 조작
トラックバック:Mytischi-city.ru
トラックバック:http://debconstruction.net/__media__/js/netsoltrademark.php?d=blog-kr.dreamhanks.comquestionlivraison-de-pizza-a-montreal-degustez-des-saveurs-authentiques-a-domicile-56
トラックバック:Deltacentrifugal.org
トラックバック:다바오 4989
トラックバック:http://Www.Gatx.CO.Uk/__media__/js/netsoltrademark.php?d=sstm.co.krbbsboard.phpbo_tablefreewr_id76466
トラックバック:https://www.hottestpornactress.com/cats/Big-Ass
トラックバック:Effortless Content Creation Solutions for imcfilms.com on Uplinke.com
トラックバック:3d 커스텀 소녀 에볼루션
トラックバック:에볼루션 무료
トラックバック:에볼루션 파싱
トラックバック:에볼루션 배팅 취소 프로그램
トラックバック:kak.egimsoft.co.kr
トラックバック:spaceballs-nrw.De
トラックバック:Best Water Filter Malaysia
トラックバック:click to read
トラックバック:Crescentfunds.Com
トラックバック:쥬라기 월드 에볼루션
トラックバック:Colorpedic.com
トラックバック:http://432.Bobrice.Com
トラックバック:forex forecast eur/usd
トラックバック:forexdirectory
トラックバック:Allegro
トラックバック:booyoung21.co.kr
トラックバック:6+6 forecast
トラックバック:forex broker for india
トラックバック:5 minute forex trading strategy
トラックバック:forex forecast next week
トラックバック:forex mercado de divisas
トラックバック:e commerce affiliate programs
トラックバック:buy best lubricants buy viagra pills
トラックバック:high paying forex affiliate programs
トラックバック:forex time zone converter
トラックバック:what is a forex broker
トラックバック:http://Petamon.com/__media__/js/netsoltrademark.php?d=Fillcom.co.krbbsboard.phpbo_tablefreewr_id2652108
トラックバック:videos pornos los más vistos
トラックバック:forex brokers with affiliate programs
トラックバック:weekly forex forecast
トラックバック:https://www.Freeadultsexcams.com/videos/151.html
トラックバック:서울 다바오 항공권
トラックバック:australia forex broker
トラックバック:the best forex broker in usa
トラックバック:click the next document
トラックバック:forex cuenta demo
トラックバック:forex trading app
トラックバック:best forex broker in usa
トラックバック:daily currency forecast
トラックバック:forex en tiempo real
トラックバック:usd mxn forex
トラックバック:forex signals
トラックバック:india best forex broker
トラックバック:http://ruspeach.com/bitrix/redirect.php?goto=http://asmzine.Net/geekly-rewind/2018/10/22/transformers-botbots-are-coming-and-you-cant-handle-the-cute
トラックバック:hop over to this website
トラックバック:m.042-361-5114.1004114.co.kr
トラックバック:필리핀 위민스 칼리지 오브 다바오 davao city
トラックバック:Bettor 365
トラックバック:PASTIBET 78
トラックバック:https://www.sexcameralive.com
トラックバック:https://lozanoinc.com
トラックバック:Click On this site
トラックバック:Doncaster escorts agency
トラックバック:https://www.115777.xyz/
トラックバック:check this link right here now
トラックバック:livestreamingporn.com
トラックバック:https://www.onlineporncam.com
トラックバック:소녀 에볼루션
トラックバック:https://www.freelivesexycam.com/
トラックバック:https://www.freeadultcamtocam.com/movies/174.html
トラックバック:Leeds escorts
トラックバック:에볼루션 가상머니 사이트
トラックバック:에볼루션 배팅 취소
トラックバック:buy viagra pills sex lubricants
トラックバック:click the following internet site
トラックバック:dUnGeONtABlE.org
トラックバック:Manchester escorts
トラックバック:click here to read
トラックバック:mouse click the up coming article
トラックバック:Chicagochiropracticandsportsinjurycenter.com
トラックバック:visit www.113888.xyz`s official website
トラックバック:laptop extended screen
トラックバック:Сексуална камера емисии
トラックバック:WWW.Gz-jJ.COM
トラックバック:Ibs3457.com
トラックバック:에볼루션 채팅
トラックバック:http://1×57.com/
トラックバック:에볼루션 라이트닝 가입 머니
トラックバック:http://xn--989a5b812cq1h8xxvfb.kr/bbs/board.php?bo_table=pension_free2&wr_id=22634&sca=
トラックバック:http://Metalfabsolutions.com/__media__/js/netsoltrademark.php?d=partnershop.krbbsboard.phpbo_tablefreewr_id579682
トラックバック:다바오 설치 링크
トラックバック:다바오 지역 폭발
トラックバック:www.115222.xyz
トラックバック:sage and skylar omegle porn
トラックバック:Site de chat de sexo ao vivo
トラックバック:https://www.bongacomlive.com/cat/Sharking
トラックバック:www.sexchatcamera.com
トラックバック:visit Webcamsexlivefree here >>
トラックバック:jinos.com
トラックバック:marasex.com
トラックバック:Sohochung.com
トラックバック:firmywpl.Mystrikingly.com
トラックバック:http://www.die-seite.com/index.php?a=stats&u=earlwln720590
トラックバック:sexcamonlinefree.com
トラックバック:에볼루션 블랙잭
トラックバック:hardstyle beats
トラックバック:Abogado segunda oportunidad Barcelona
トラックバック:Abogados Barcelona segunda oportunidad
トラックバック:Online-Rechner
トラックバック:hier klicken
トラックバック:uluBMp3.Eu
トラックバック:adobe premiere pro gumroad
トラックバック:Abogados segunda oportunidad
トラックバック:Meter in Zoll umrechnen
トラックバック:cm in Zoll umrechnen
トラックバック:Click Webpage
トラックバック:https://Classifieds.Ocala-News.com/author/leoniearnde
トラックバック:다바오 망고
トラックバック:click through the up coming document
トラックバック:luxury car rental Malaysia
トラックバック:Cresus Casino
トラックバック:chauffeur services
トラックバック:http://blog-Kr.Dreamhanks.com/question/nettoyage-de-thermopompe-limportance-de-lentretien-14/
トラックバック:http://taeanilbo.kr/bbs/board.php?bo_table=free&wr_id=59509
トラックバック:http://korenagakazuo.com/2008/02/16/八潮市のセブンイレブンで出会った猫/
トラックバック:Bybak.com
トラックバック:http://Mpphoto.info/__media__/js/netsoltrademark.php?d=Tangguifang.Dreamhosters.comcommenthtml973930.html
トラックバック:murder mystery knives
トラックバック:cooldownaquamm2value.wordpress.com
トラックバック:sources tell me
トラックバック:아티피셜 에볼루션
トラックバック:grandcouventgramat.fr
トラックバック:http://gotanproject.net/node/24364230?——WebKitFormBoundary8mHfT6i3BicSr8oFContent-Disposition:form-data;name=titlePlastiquesGyfSlectionneGranby——WebKitFormBoundary8mHfT6i3BicSr8oFContent-Disposition:form-data;name=bodyLersultatultimeseraaussidurab
トラックバック:murder mystery godlys
トラックバック:www.cheapmonitors.Co.uk
トラックバック:http://Gotanproject.net/node/24362963?——WebKitFormBoundarykCIiiN0qhZSzu9cSContent-Disposition:form-data;name=titleTatouageEyeliner——WebKitFormBoundarykCIiiN0qhZSzu9cSContent-Disposition:form-data;name=bodyLabutlasupplmentairedanslestyleparchoisirc
トラックバック:G2G123-Official.Online
トラックバック:에볼루션 바카라 불법
トラックバック:dbschool.kr
トラックバック:aurora2019gunmm2snowballpeel.wordpress.com
トラックバック:1v1 video call
トラックバック:Mm2 Ancient
トラックバック:mm2 Items
トラックバック:https://Www.Chatcamporn.com/htmls/68.html
トラックバック:https://www.shemalefavoritelist.com/movies/81.html
トラックバック:professional wall preparation
トラックバック:what is the best video chat website?
トラックバック:1v1 video chat
トラックバック:chasseur d’appartement genève avis
トラックバック:lucky crush alternative
トラックバック:CHASSEUR d’appartement Carouge
トラックバック:omegle video call
トラックバック:bulk furniture removal
トラックバック:local painting company Jamaica
トラックバック:video chat
トラックバック:http://Storeyappraisal.com/__media__/js/netsoltrademark.php?d=www.Die-seite.comindex.phpastatsuamandabelt
トラックバック:luckycrush alternative
トラックバック:video chat platforms
トラックバック:http://new.jesusaction.org/bbs/board.php?bo_table=free&wr_id=4176911
トラックバック:Midland
トラックバック:http://m-grp.ru/redirect.php?url=https://www.die-seite.com/index.php?a=stats&u=raphaelsunseri
トラックバック:free video chat
トラックバック:chatmatch
トラックバック:omegleweb
トラックバック:what is the best random video chat platform?
トラックバック:Invisibleoffices.com
トラックバック:callmechat
トラックバック:omegle alternative
トラックバック:http://Fourseasons-dental.Co.kr/bbs/board.php?bo_table=free&wr_id=426461
トラックバック:http://www.Denwer.ru/click?http://Fggn.kr/board_DesI72/209162
トラックバック:anuncios google andorra
トラックバック:에볼루션 챔버
トラックバック:Banket66.ru
トラックバック:Http://Fggn.Kr/
トラックバック:먹튀검증사이트 먹튀폴리스
トラックバック:agency arms glock 19x glock 34 ported
トラックバック:Proxy Sites
トラックバック:greenlight hayti
トラックバック:double stack 1911
トラックバック:asianwin88 login
トラックバック:먹튀검증사이트 베팅크루
トラックバック:토토사이트 추천 커뮤니티 베팅크루
トラックバック:proxies providers
トラックバック:토토사이트 꽁머니 추천 먹튀폴리스
トラックバック:φυσικά καλλυντικά
トラックバック:먹튀검증업체 베팅크루
トラックバック:메이저 토토사이트 베팅연합
トラックバック:αποσμητικά σώματος
トラックバック:https://Oke.zone/profile.php?id=141799
トラックバック:glock 19 slides
トラックバック:무료 슬롯
トラックバック:필리핀 다바오 여행
トラックバック:토토사이트 베팅연합
トラックバック:Thankyou.Eoapps.Co.Kr
トラックバック:http://dtyzwmw.com/comment/html/?11599.html
トラックバック:asia slot
トラックバック:σερβιέτες πολλαπλών χρήσεων
トラックバック:eco life
トラックバック:무료슬롯게임
トラックバック:슬롯 검증 사이트
トラックバック:best online ammo and gun shop
トラックバック:https://www.shemalefavoritelist.com/movies/52.html
トラックバック:https://www.onlinelivesexcam.com/html/153.html
トラックバック:sex video of namrata shrestha
トラックバック:full harvest moonz
トラックバック:chat match
トラックバック:Publicidad Google Andorra
トラックバック:1v1 chat platforms
トラックバック:video call with girls
トラックバック:http://Culpa-Music.de/guestbox/guestbox.php?Anfangsposition=0
トラックバック:bodyguard 2.0 for sale
トラックバック:random video chat
トラックバック:인천 다바오 직항
トラックバック:Slitigenz.io
トラックバック:video chat app
トラックバック:https://cl-system.jp/question/optimisation-des-moteurs-De-recherche-on-page-et-off-page-deux-piliers-essentiels-par-un-referencement-reussi-16/
トラックバック:ARWANA189
トラックバック:video chat with girls
トラックバック:http://koex21.co.kr/bbs/board.php?bo_table=free&wr_id=200730
トラックバック:m-direct.co.kr
トラックバック:this contact form
トラックバック:다바오 계정
トラックバック:다바오 포커 회원가입
トラックバック:CeltiCmIndEd.COm
トラックバック:adspower browser
トラックバック:double deck bed
トラックバック:loft bed
トラックバック:Financial services executive search
トラックバック:인어베가스 홈페이지
トラックバック:Prodentim Candy
トラックバック:cladding installation
トラックバック:ProDentim
トラックバック:rash shirt womens
トラックバック:Executive recruitment for family businesses
トラックバック:https://WWW.Kit-Media.com/bitrix/redirect.php?goto=http://blog-kr.dreamhanks.com/question/event-de-plomberie-de-toit-a-quebec-lelement-cle-de-votre-systeme-de-plomberie-18/
トラックバック:http://www.gotanproject.net/node/24371981?——WebKitFormBoundaryWHdRykx8jf1MQGP7Content-Disposition:form-data;name=titlePoupartClimatisation:VotrePartenaireparleConfortThermique——WebKitFormBoundaryWHdRykx8jf1MQGP7Content-Disposition:form-data;name=b
トラックバック:murder mystery Guns
トラックバック:visit this web page link
トラックバック:African American Poet
トラックバック:fc séville maillot
トラックバック:Universalexpandedpolystyrene.com
トラックバック:인어베가스 공식 사이트
トラックバック:2023 dse maths paper 1答案
トラックバック:Lowes Credit Card
トラックバック:인어베가스 홈페이지 더보기
トラックバック:C-suite recruitment for family-owned companies
トラックバック:wingspanfoundation.org
トラックバック:toddler bed
トラックバック:realistic pleasure
トラックバック:butt plug
トラックバック:Top financial services executive recruiters
トラックバック:인어베가스
トラックバック:African American Literature
トラックバック:commercial alumimium cladding
トラックバック:please click the next website page
トラックバック:Thingworx.Co.Kr
トラックバック:please click the next webpage
トラックバック:https://cl-system.jp/question/pont-dentaire-a-quebec-restauration-dentaire-pour-des-dents-manquantes-90/
トラックバック:cover song distribution
トラックバック:best real estate agent in Santa Maria CA
トラックバック:다바오 호텔
トラックバック:Domain.glass
トラックバック:www.Afada.Org
トラックバック:realtor in Portland OR
トラックバック:realtor in Whittier CA
トラックバック:realtor in St Charles MO
トラックバック:real person gamble
トラックバック:best realtor in Midvale UT
トラックバック:dtyzwmw.com
トラックバック:best real estate agent in Portland OR
トラックバック:https://Images.google.gp/url?sa=t&url=httpsdoosung1.co.krbbsboard.phpbo_tableqnawr_id310500
トラックバック:best realtor in Tacoma WA
トラックバック:best realtor in Montrose CO
トラックバック:best real estate agent in Whittier CA
トラックバック:best real estate agent in Tacoma WA
トラックバック:best real estate agent in Newport Beach CA
トラックバック:realtor in Montrose CO
トラックバック:best real estate agent in Midvale UT
トラックバック:real estate agent in Salem VA
トラックバック:real estate agent in Newport Beach CA
トラックバック:Soccerfile.Fifakorea.net
トラックバック:best real estate agent in Salem VA
トラックバック:best real estate agent in Montrose CO
トラックバック:best realtor in Newport Beach CA
トラックバック:https://bluescarf.ir/استایل-طناز-طباطبایی-در-ونیز/
トラックバック:best realtor in Whittier CA
トラックバック:best realtor in Johnson City TN
トラックバック:real estate agent in Tacoma WA
トラックバック:real estate agent in Midvale UT
トラックバック:에볼루션 딜레이작업
トラックバック:62.falugyw.com
トラックバック:real estate agent in Santa Maria CA
トラックバック:real estate agent in Johnson City TN
トラックバック:다바오 vpn
トラックバック:best real estate agent in St Charles MO
トラックバック:real estate agent in Whittier CA
トラックバック:real estate agent in Portland OR
トラックバック:쥬라기 월드 에볼루션 2 샌드박스
トラックバック:realtor in Johnson City TN
トラックバック:Spokanecremation.info
トラックバック:http://blog-kr.dreamhanks.com/question/feuille-dacier-pre/
トラックバック:realtor in Midvale UT
トラックバック:best realtor in St Charles MO
トラックバック:부달사이트
トラックバック:mm2 buy
トラックバック:informative post
トラックバック:http://Am_14264130.mongdol.net/bbs/board.php?bo_table=free&wr_id=64415
トラックバック:sofaramericas.Net
トラックバック:roboforex bonus
トラックバック:okeplay777
トラックバック:metatrader
トラックバック:forex 100 pro
トラックバック:Xn–23-np4iz15g.com
トラックバック:xm metatrader 5
トラックバック:룸알바
トラックバック:슬롯사이트
トラックバック:metatrader mac
トラックバック:northgeorgiaopen.com
トラックバック:best forex card
トラックバック:forex live
トラックバック:invest
トラックバック:https://www.teensextumblr.com/Movie/101.html
トラックバック:simply click Onlinelivesexcam
トラックバック:hot sexy porn video
トラックバック:a bollywood tail full porn video
トラックバック:descargar porn videos
トラックバック:their explanation
トラックバック:วันหยุดหุ้นสหรัฐ
トラックバック:เทรดหุ้น
トラックバック:www.onlineporncam.com
トラックバック:japanese photobooks porn books
トラックバック:밤알바
トラックバック:real estate agent in St Charles MO
トラックバック:Ivonne.net
トラックバック:tradingview metatrader 5
トラックバック:redirected here
トラックバック:유흥알바
トラックバック:roboforex no deposit bonus
トラックバック:vps ฟรี ถาวร
トラックバック:forex usd to pkr
トラックバック:forex news
トラックバック:metatrader 5 app
トラックバック:xauusd metatrader 5
トラックバック:forex god
トラックバック:metatrader lot size calculator
トラックバック:realtor in Salem VA
トラックバック:https://Processarts.com/forums/topic/comment-changer-une-vitre-thermos-guide-pratique/
トラックバック:metatrader leverage
トラックバック:stocks
トラックバック:broker metatrader 4
トラックバック:forex broker
トラックバック:PISTOL
トラックバック:realtor in Santa Maria CA
トラックバック:best realtor in Salem VA
トラックバック:Www.Bookmarkalink.com
トラックバック:Store-pro.ru
トラックバック:Yoonlife.kr
トラックバック:mpksdi
トラックバック:toko pulsa
トラックバック:Avocat Criminel
トラックバック:best realtor in Santa Maria CA
トラックバック:다바오 포커 입금
トラックバック:realtor in Tacoma WA
トラックバック:http://davidpawson.org/resources/resource/416?return_url=httpWww.Die-Seite.comindex.phpastatsuprestonbeyer497
トラックバック:real estate agent in Montrose CO
トラックバック:qwiketube.Com
トラックバック:realtor in Newport Beach CA
トラックバック:best realtor in Portland OR
トラックバック:written by Xn 2o 2b 15m 1xf 36o
トラックバック:https://www.hongcheonkang.co.kr/bbs/board.php?bo_table=free&wr_id=313728
トラックバック:rIvEraROma.Com
トラックバック:http://whois.webrankstats.com/whois/forum.altaycoins.com/profile.phpid962865
トラックバック:does grace charis do porn
トラックバック:please click the next website
トラックバック:longest video porn
トラックバック:www.hottestpornactress.com
トラックバック:https://www.freebestpornsites.com/
トラックバック:use www.chatterbatecam.com here
トラックバック:camchatporn.com
トラックバック:Https://Www.Sexyfreeporn.Com/Indian-Uncle-Sex-Videos.Htm
トラックバック:please click the up coming website page
トラックバック:https://Www.Chatterbaitcams.com/post/96.html
トラックバック:https://www.shemalefavoritelist.com/movies/35.html
トラックバック:uscca login
トラックバック:verilife romeoville
トラックバック:Navyarmyccu.be
トラックバック:best real estate agent in Johnson City TN
トラックバック:gordoncroftfoundation.org
トラックバック:http://terzas.Plantarium-noroeste.es/temas/tema005.php
トラックバック:https://globalturizmbungalov.Com
トラックバック:다바오 특급 호텔
トラックバック:hirsch selection 25yr kentucky straight rye msrp
トラックバック:https://M.Weatheravenue.com/ru/http://mdream.net/bbs/board.php?bo_table=free&wr_id=270436
トラックバック:ridstar official
トラックバック:tensile fabric structure
トラックバック:radian ramjet
トラックバック:https://support.IHC.Ru/sitecheck/index.php?url=gotanproject.netnode24380045——WebKitFormBoundaryVgqZFMU1ShEUocPKContent-Dispositionform-datanametitleRadiographiePodiatriqueSaint-EustacheComprendrelImportancedelImagerieparlesSoinsdesPieds——WebKitFor
トラックバック:tactacam prm-ums under scope rail mount for crossbow
トラックバック:https://www.sexcameralive.com/
トラックバック:https://www.chachurbate.com/
トラックバック:drugged porn videos
トラックバック:https://www.onlinelivesexcam.com/html/30.html
トラックバック:http://Www.Secretsearchenginelabs.com/add-url.php?subtime=1733826350&newurl=https://tangguifang.Dreamhosters.com/comment/html/972574.html
トラックバック:Lms.mediationacademy.co.za
トラックバック:aghsatiyab.Com
トラックバック:cgi.www5f.biglobe.ne.jp
トラックバック:cse.google.mu
トラックバック:Electronworks.net
トラックバック:chatterbaitcams.com
トラックバック:https://www.sexchatcamera.com/porn/116.html
トラックバック:Https://www.freenudevideochat.com/videos/43.html
トラックバック:http://WWW.Stoneline-Testouri.de/url?q=http://Blog-Kr.Dreamhanks.com/question/organisation-dun-evenement-corporatif-guide-complet-par-reussir-22/
トラックバック:Actualauction.com
トラックバック:https://www.kenpoguy.com/phasickombatives/profile.php?id=2359559
トラックバック:แทงบอล369
トラックバック:Situs slot Rajatoto88
トラックバック:http://webrestore.bluef.kr/bbs/board.php?bo_table=notice2&wr_id=206168
トラックバック:slotasiabet
トラックバック:www.freelivesexonline.com
トラックバック:Porn Videos Punish
トラックバック:https://www.sexyfreeporn.com/china-sex-movie-video.htm
トラックバック:https://www.sexcamonlinefree.com/shtmls/155.html
トラックバック:https://www.freebestpornsites.com/movies/67.html
トラックバック:ทดลองเล่นสล็อต
トラックバック:https://www.onlinewebcamporn.com/post/36.html
トラックバック:git.chartsoft.Cn
トラックバック:Aaryaintschool.com
トラックバック:https://Oke.zone/profile.php?id=155074
トラックバック:moLacPa.Com
トラックバック:https://vinesmm2valuelimitedflank.Wordpress.com/
トラックバック:visit their website
トラックバック:mm2 godlys
トラックバック:mm2 knives
トラックバック:check out your url
トラックバック:www.skoda-piter.ru
トラックバック:Images.Google.co.th
トラックバック:http://ncaabasketballbiggestfan.com/__media__/js/netsoltrademark.php?d=Blog-kr.dreamhanks.comquestionrehaussement-de-cils-a-montreal-tout-ce-que-vous-devez-savoir-55
トラックバック:Camshowsex.Com
トラックバック:https://www.girlontopporn.com
トラックバック:Www.onlinewebcamporn.com
トラックバック:best stepmom porn videos
トラックバック:have a peek here
トラックバック:www.sexyfreeporn.com
トラックバック:http://www.xn--9i2bz3bx5fu3d8q5a.com/bbs/board.php?bo_table=free&wr_id=1784071
トラックバック:grabwebbedmm2valuebargain.wordpress.com
トラックバック:Infiroute.com
トラックバック:http://Quiroz-Family.com/__media__/js/netsoltrademark.php?d=starfc.co.krbbsboard.phpbo_tablefreewr_id237710
トラックバック:study helper
トラックバック:SHEK YUET HEY 石悅禧
トラックバック:ridstar spare parts
トラックバック:jacob shek yuet hey
トラックバック:Loodgieter België
トラックバック:video templates
トラックバック:mm2 guns
トラックバック:Plombier Charleroi
トラックバック:homework helper
トラックバック:Shek Yuet-hey
トラックバック:http://borg-warner.net/__media__/js/netsoltrademark.php?d=r2tbiohospital.combbsboard.phpbo_tablefreewr_id2938240
トラックバック:fake karten
トラックバック:ace premium cart
トラックバック:ariana grande porn Video
トラックバック:sex human With animals video
トラックバック:chattrube.com
トラックバック:videos of men having sex with dogs
トラックバック:Celina Smith onlyfans porn
トラックバック:www.shemalefavoritelist.com
トラックバック:read this blog post from Bestfreeliveporn
トラックバック:https://www.freenudevideochat.com
トラックバック:free porn movies xnxxx
トラックバック:upload porn Videos
トラックバック:https://novinkyspravy.sk/krasa-zvnutra-vplyv-stravovania-na-zdravie-a-vzhlad-celej-rodiny/
トラックバック:https://homeandgarden.cz/jak-dosahnout-naprosteho-klidu-ve-vasem-domove-pomoci-dekorace/
トラックバック:https://extramagazin.cz/vanocni-trhy-bez-nervu-kde-a-jak-nejlepe-zaparkovat-ve-vidni-a-dalsich-mestech/
トラックバック:realtor in Midlothian TX
トラックバック:https://ceska-vyroba.cz/nevyspani-ovlivnuje-zdravi-i-psychickou-pohodu/
トラックバック:https://bilance.cz/jak-vybaveni-loznice-ovlivnuje-kvalitu-spanku/
トラックバック:best real estate agent in Alexandria MN
トラックバック:best real estate agent in Norfolk NE
トラックバック:realtor in West Chester Township OH
トラックバック:realtor in Alexandria MN
トラックバック:best realtor in Augustine FL
トラックバック:best real estate agent in pensacola fl
トラックバック:best realtor in West Chester Township OH
トラックバック:real estate agent in West Chester Township OH
トラックバック:best real estate agent in Cape Coral FL
トラックバック:best real estate agent in Cornelius NC
トラックバック:best realtor in Alexandria MN
トラックバック:best real estate agent in West Chester Township OH
トラックバック:real estate agent in Prosper TX
トラックバック:realtor in pensacola
トラックバック:best realtor in Cape Coral FL
トラックバック:realtor in Cornelius NC
トラックバック:best real estate agent in Augustine FL
トラックバック:real estate agent in Norfolk NE
トラックバック:real estate agent in Alexandria MN
トラックバック:real estate agent in King George VA
トラックバック:best real estate agent in pensacola
トラックバック:best realtor in realtor in pensacola
トラックバック:real estate agent in Midlothian TX
トラックバック:Importpartsonline.sakura.tv
トラックバック:real estate agent in Cape Coral FL
トラックバック:best realtor in Midlothian TX
トラックバック:realtor in Augustine FL
トラックバック:best real estate agent in Prosper TX
トラックバック:http://tst.ezmir.co.kr/bbs/board.php?bo_table=qna&wr_id=755343
トラックバック:Seoulrio.com
トラックバック:best real estate agent in King George VA
トラックバック:real estate agent in pensacola fl
トラックバック:www.chattrube.com
トラックバック:https://www.bestfreeliveporn.com/
トラックバック:Https://Www.onlineporncam.com/
トラックバック:Https://Www.Freelivesexycam.Com/Video/62.Html
トラックバック:www.zzgps.com
トラックバック:celebrity leaked Porn Videos
トラックバック:realtor in Prosper TX
トラックバック:Cacaosoft.com
トラックバック:togel online
トラックバック:www.chachurbate.com
トラックバック:real estate agent in Augustine FL
トラックバック:real estate agent in Cornelius NC
トラックバック:best realtor in Prosper TX
トラックバック:http://www.gotanproject.net/node/24413163?——WebKitFormBoundaryH1p6xN07BCkFCtQdContent-Disposition:form-data;name=titleAlojamientoenMiami:DiversidadyConfortenelCorazndeFlorida——WebKitFormBoundaryH1p6xN07BCkFCtQdContent-Disposition:form-data;name=bo
トラックバック:face scrubber exfoliator
トラックバック:sontogel login alternatif
トラックバック:silicone face scrubber
トラックバック:back scratcher for women
トラックバック:chicken shredder tool twist large
トラックバック:son togel
トラックバック:silicone body scrubber
トラックバック:realtor in Cape Coral FL
トラックバック:Freeliveadultcams says
トラックバック:sp001g.dfix.Co.Kr
トラックバック:https://Www.camtocamnude.com
トラックバック:porn videos tiava
トラックバック:https://Onlineporncam.com/
トラックバック:best realtor in Norfolk NE
トラックバック:le maillot de foot
トラックバック:realtor in Norfolk NE
トラックバック:Rainscreentechnology.net
トラックバック:http://seong-ok.kr/bbs/board.php?bo_table=free&wr_id=677566
トラックバック:best realtor in Cornelius NC
トラックバック:talking to
トラックバック:Whiteoutmm2Aestheticpwn.Wordpress.Com
トラックバック:http://Orionmccabe.com/__media__/js/netsoltrademark.php?d=Processarts.comforumstopiclocation-de-decoration-par-evenement-canada-guide-complet-pour-une-fete
トラックバック:best real estate agent in Midlothian TX
トラックバック:realtor in King George VA
トラックバック:realtor in pensacola fl
トラックバック:best realtor in pensacola fl
トラックバック:Hulaser.com
トラックバック:http://Wis-dom.biz/__media__/js/netsoltrademark.php?d=tangguifang.dreamhosters.comcommenthtml974342.html
トラックバック:indonesian furniture retail
トラックバック:메이저사이트
トラックバック:salma hayek porn video
トラックバック:https://www.freelivesexonline.com/post/119.html
トラックバック:porn rape videos
トラックバック:https://Www.porndvdstream.com/movies/13.html
トラックバック:https://www.chatburte.com/
トラックバック:http://highendps.kr/bbs/board.php?bo_table=free&wr_id=149529
トラックバック:คริปโทเคอร์เรนซี
トラックバック:age requirements for adults and kids
トラックバック:topics
トラックバック:ราคา Bitcoin
トラックバック:stem cell
トラックバック:مباراة برشلونة اليوم
トラックバック:stem cell bangkok
トラックバック:Siquijor Hotel and Resort
トラックバック:ตลาดคริปโตวันนี้
トラックバック:http://Dtyzwmw.com/comment/html/?33990.html
トラックバック:롤대리
トラックバック:트립닷컴 할인코드
トラックバック:https://Sitecheck.Sucuri.net/scanner/?scan=http://www.gz-Jj.com/comment/html/?272149.html
トラックバック:Age guidelines explained
トラックバック:nursing agencies near me
トラックバック:WWW.Tiwebsite.com
トラックバック:يلا شوت
トラックバック:travel nursing agencies
トラックバック:age requirements for access
トラックバック:http://Mdream.net/bbs/board.php?bo_table=free&wr_id=293471
トラックバック:medical staffing agency
トラックバック:how old must you be to qualify
トラックバック:트립닷컴 항공권 할인코드
トラックバック:guidelines for age restrictions
トラックバック:right here on Gair
トラックバック:go to website
トラックバック:Snagwoodmm2Sale.Wordpress.Com
トラックバック:chelsea uniforme
トラックバック:https://Thezal.Kr/
トラックバック:소액대출
トラックバック:crypto trading bot
トラックバック:déCoupe laser métal
トラックバック:Imjun.eu.org
トラックバック:https://www.Chatterbatecam.com/porn/49.html
トラックバック:jack doherty porn videos
トラックバック:https://www.girlontopporn.com/post/43.html
トラックバック:Yonseiwell.com
トラックバック:youtube videos free sex videos
トラックバック:Www.0768baby.com
トラックバック:japanese shop
トラックバック:Secret Beach Belize
トラックバック:부산 룸싸롱
トラックバック:http://Eindia.in/__media__/js/netsoltrademark.php?d=processarts.comforumstopicformulaire-de-demenagement-quebec-guide-pour-une-transition-simple-et
トラックバック:해운대 룸싸롱
トラックバック:https://wrapped2015mm2valueclutchsoftcc.wordpress.com
トラックバック:Anti detect Browsers
トラックバック:web design companies toronto
トラックバック:ดูหนังออนไลน์ฟรี
トラックバック:VIRAL 365
トラックバック:REGALBET SLOT
トラックバック:GANESA189
トラックバック:CINTA78
トラックバック:Anti-detect Browsers
トラックバック:nail clippers
トラックバック:Browser Antidetect
トラックバック:Secret Beach Real Estate
トラックバック:certificate iv in work health and safety
トラックバック:Belize Secret Beach
トラックバック:Ζωντανές σεξουαλικές εκπομπές
トラックバック:learn more about 8bitknifemm2valuegrindburst.wordpress.com
トラックバック:one-time offer
トラックバック:http://Sagharbor-ny.com/__media__/js/netsoltrademark.php?d=sunriji.commoduleboard.phpbo_tablefreewr_id1879317
トラックバック:https://bats2020mm2exclusiverekt.wordpress.com
トラックバック:Recommended Web site
トラックバック:Bio.Rogstecnologia.Com.br
トラックバック:http://Pailotteryclub.com/__media__/js/netsoltrademark.php?d=Fggn.krboard_DesI72212907
トラックバック:Pasarinko.zeroweb.kr
トラックバック:Camchatadult.com
トラックバック:https://www.chatburte.com
トラックバック:https://Www.Chachurbate.com/movie/85.html
トラックバック:Haedamfood.net post to a company blog
トラックバック:visit the following site
トラックバック:Electronics
トラックバック:فيب مكة
トラックバック:https://cl-System.jp/question/demande-de-pret-sans-enquete-de-credit-est-ce-possible-103/
トラックバック:http://Gotanproject.net/node/24449098?——WebKitFormBoundary1Av5SzZETB1hBoeGContent-Disposition:form-data;name=titleLesChevaliersDeColombTatousSurLeCur——WebKitFormBoundary1Av5SzZETB1hBoeGContent-Disposition:form-data;name=bodyAprssupplmentairede35an
トラックバック:http://Graypension.com/bbs/board.php?bo_table=free&wr_id=710174
トラックバック:https://Tangguifang.Dreamhosters.com/comment/html/?1023835.html
トラックバック:http://www.gz-jj.com/comment/html/?303502.html
トラックバック:Esquiar En Port Del Comte
トラックバック:http://blog-Kr.dreamhanks.com/question/la-comedienne-agee-quebecoise-un-pilier-de-lart-dramatique-142/
トラックバック:Hotto Purto
トラックバック:More Information and facts
トラックバック:https://Blog-kr.dreamhanks.com/question/pension-pour-chien-a-st-jerome-offrir-un-sejour-confortable-et-securise-par-votre-compagnon-canin/
トラックバック:Tomscherer.Com
トラックバック:burf.cO
トラックバック:Asiacheat.com
トラックバック:Www.gz-jj.com published an article
トラックバック:bokep
トラックバック:http://www.GZ-Jj.com/comment/html/?303823.html
トラックバック:Esquiar en Sierra Nevada
トラックバック:https://www.281327.xyz/movie/1515.Html
トラックバック:Are You Embarrassed By Your Sex Chat Bots Abilities? This is What To Do
トラックバック:Nine Things Your Mom Should Have Taught You About Hd Sex Dino
トラックバック:www.281326.xyz
トラックバック:Bollywood Sex
トラックバック:www.390508.xyz
トラックバック:how you Can make your product the ferrari of sex Hookup
トラックバック:Why Everyone is Dead Wrong About Chubby Mom Sex And Why You must Read This Report
トラックバック:visit the following page
トラックバック:https://www.555816.xyz/videos/685.html
トラックバック:707317.xyz
トラックバック:9 Ways Friday The 13th Sex Scene Will Help you Get More Business
トラックバック:Www.519502.xyz blog article
トラックバック:https://www.348197.xyz
トラックバック:cars fan fic porn
トラックバック:Seven Of The Punniest Bondage Sex Gif Puns Yow will discover
トラックバック:freeliveadultcams.com
トラックバック:just click the up coming internet page
トラックバック:https://www.freelivecamsites.com
トラックバック:https://www.camshowsex.com/html/68.html
トラックバック:soul eater porn maka
トラックバック:sexchatcamera.com
トラックバック:neW.soO-cLiNIC.cOm
トラックバック:Maps.Google.Com.Do
トラックバック:Www.bruederli.com
トラックバック:http://dtyzwmw.com/comment/html/?83298.html
トラックバック:artis777 login
トラックバック:JkENTgeRVaSINi.Com
トラックバック:This Webpage
トラックバック:V Živo Kamera Modeli
トラックバック:stanleyplastics.net
トラックバック:cert.zero.camp
トラックバック:onlinecasino
トラックバック:Coach d’affaires
トラックバック:Gold card tv funciona
トラックバック:ads tiktok judi
トラックバック:http://sports4.iceserver.Co.kr/bbs/board.php?bo_table=free&wr_id=1957779
トラックバック:http://shop-Lengorgaz.Tmweb.ru/community/profile/ameliejeffers1/
トラックバック:http://Www.Cqcici.com/comment/html/?307122.html
トラックバック:posicionamiento web andorra
トラックバック:http://koreataxinews.co.kr/bbs/board.php?bo_table=free&wr_id=12717
トラックバック:http://blog-Kr.dreamhanks.com/question/reparation-de-porte-de-camion-guide-complet-59/
トラックバック:head to www.363681.xyz
トラックバック:https://www.246306.xyz/
トラックバック:Why I Hate New Sex Dolls
トラックバック:You&
トラックバック:https://Www.693172.xyz/shtml/1284.html
トラックバック:Highly recommended Reading
トラックバック:www.281322.xyz
トラックバック:Bestpornstreamingsites`s statement on its official blog
トラックバック:www.094444.xyz
トラックバック:https://camshowsex.com/
トラックバック:https://www.281319.xyz/shtmls/233.html
トラックバック:https://Www.189169.xyz/
トラックバック:https://www.livecamsexshow.com/movies/101.html
トラックバック:www.537868.xyz
トラックバック:https://www.348197.xyz/post/1536.html
トラックバック:www.668598.xyz
トラックバック:Punishment Sex
トラックバック:www.693175.xyz
トラックバック:https://www.youtucams.com/Htmls/72.html
トラックバック:https://Www.Sexyfreeporn.com/leicht-perlig-sex-videos.Htm
トラックバック:Www.281318.xyz
トラックバック:Www.912924.Xyz
トラックバック:https://www.freeonlinewebsex.com
トラックバック:Www.005563.xyz
トラックバック:https://Www.230023.xyz/
トラックバック:read the full info here
トラックバック:Suggested Studying
トラックバック:اسکراب پزشکی
トラックバック:pdr مهرآریا
トラックバック:خرید ساعت اورجینال
トラックバック:Melbourne strippers
トラックバック:مهرآریا
トラックバック:tELugUwapNeT.CoM
トラックバック:اسکراب
トラックバック:خودرو فرسوده
トラックバック:خرید ساعت مچی
トラックバック:خودرو اسقاطی
トラックバック:teak outdoor furniture indonesia
トラックバック:click through the following internet site
トラックバック:http://Hotelmclemore.com/__media__/js/netsoltrademark.php?d=gsnsystems.Co.krbbsboard.phpbo_tablefreewr_id714255
トラックバック:http://oakphoto.com/__media__/js/netsoltrademark.php?d=Seong-ok.krbbsboard.phpbo_tablefreewr_id717126
トラックバック:https://WWW.Tiwebsite.Com/
トラックバック:https://bookmarkinginfo.com/story18625905/best-prams
トラックバック:Scatter Mahjong
トラックバック:influencersgonewild
トラックバック:anunciar acompanhantes
トラックバック:click the next post
トラックバック:http://Nsainternational.info/__media__/js/netsoltrademark.php?d=Bluetf.combbsboard.phpbo_tablefreewr_id66942
トラックバック:https://articgunmm2valueinvincibility.wordpress.com/
トラックバック:https://ultrararewrappedknife2015mm2value8.wordpress.com
トラックバック:https://Kasimarket.techandtag.co.za/index.php?page=user&action=pub_profile&id=146549
トラックバック:aurora2021gunmm2valueflankingzon.wordpress.com
トラックバック:Coventryfinancialholdings.org
トラックバック:www.330914.xyz
トラックバック:girlontopporn.com
トラックバック:www.154666.xyz
トラックバック:www.555819.xyz
トラックバック:am_14264130.mongdol.net
トラックバック:just click the following article
トラックバック:http://Lumbermonkey.net/__media__/js/netsoltrademark.php?d=Arkmusic.Co.krbbsboard.phpbo_tablefreewr_id1889112
トラックバック:www.805806.xyz
トラックバック:https://www.teensextumblr.com/
トラックバック:Www.555816.xyz
トラックバック:https://www.730686.xyz/
トラックバック:Six Ways Dog Girl Sex Can Make You Invincible
トラックバック:www.281331.xyz
トラックバック:head to Freeliveadultcams
トラックバック:281312.xyz
トラックバック:www.336164.xyz
トラックバック:https://www.519502.xyz/html/1356.html
トラックバック:What Alberto Savoia Can Train You About Yeast Infection After Sex
トラックバック:www.072298.xyz
トラックバック:https://www.693173.xyz/htmls/1351.html
トラックバック:check out the post right here
トラックバック:Chartmail.org
トラックバック:lifecollection.top
トラックバック:What Make Sex And Candy Chords Don&
トラックバック:www.freebestpornsites.com
トラックバック:Www.google.Com.tw
トラックバック:https://www.166580.xyz/video/1016.html
トラックバック:https://Www.668598.xyz/shtmls/1457.html
トラックバック:www.282862.xyz
トラックバック:cam to cam free
トラックバック:erothots
トラックバック:live porn webcam
トラックバック:390508.xyz
トラックバック:https://www.390507.xyz/shtmls/1650.html
トラックバック:Www.802333.xyz
トラックバック:http://Maps.Google.mu/url?q=httpsplethe.combbsboard.phpbo_tablefreewr_id71066
トラックバック:casinobonus
トラックバック:Sero Mushrooms
トラックバック:https://www.537868.xyz/htmls/388.html
トラックバック:https://Www.Sexwithsister.com/htmls/114.html
トラックバック:Www.246306.Xyz
トラックバック:click homepage
トラックバック:281328.xyz
トラックバック:bestpornstreamingsites.com
トラックバック:porn ai videos
トラックバック:https://www.282861.xyz/
トラックバック:please click the next site
トラックバック:https://www.960119.xyz/
トラックバック:555812.xyz
トラックバック:sites.google.com
トラックバック:555814.Xyz
トラックバック:https://712210.xyz/movies/1297.html
トラックバック:chatburte.com
トラックバック:www.367896.xyz
トラックバック:The Untapped Gold Mine Of Keeley Hazell Sex Tape That Nearly Nobody Knows About
トラックバック:281326.xyz
トラックバック:https://www.camchatadult.com/movies/65.html
トラックバック:www.395351.xyz
トラックバック:https://www.281316.xyz/
トラックバック:www.148604.xyz
トラックバック:red.ribbon.To
トラックバック:https://www.arrowheadpride.com/users/interiordesignersinGurgaon1
トラックバック:https://www.667776.xyz
トラックバック:Want More Inspiration With Sex Video Xxx? Learn this!
トラックバック:http://Unpeacezone.com/
トラックバック:inquiry
トラックバック:mouse click the up coming document
トラックバック:꽁머니
トラックバック:가입머니
トラックバック:IST internship program in Austria
トラックバック:ADBI online courses with certificates
トラックバック:Abogado Barcelona penal
トラックバック:Abogado penalista
トラックバック:Abogado de lo penal
トラックバック:click through the following page
トラックバック:Old.Lco.ru
トラックバック:Home
トラックバック:sports betting
トラックバック:https://www.282865.xyz
トラックバック:navigate to these guys
トラックバック:https://www.freeonlinewebsex.com/posts/112.html
トラックバック:chat about sex
トラックバック:movers rogers ar
トラックバック:Sins Of Sex Playlist
トラックバック:www.281321.xyz
トラックバック:www.villa-Schneider.De
トラックバック:Thenewtechmillionaires.com
トラックバック:https://Www.693175.xyz/
トラックバック:Sick And Bored with Doing Nude Yoga Sex The Old Approach? Learn This
トラックバック:Prime 10 Websites To Search for Jennifer Love Hewitt Sex
トラックバック:M.shopinkansascity.com
トラックバック:https://www.freelivecamporn.com
トラックバック:Http://Www.Annunciogratis.Net/Author/Jedyarnold8
トラックバック:https://www.chachurbate.com/movie/79.html
トラックバック:What Everyone seems to be Saying About Sex Hookup And What You Need To Do
トラックバック:Videos Pornos Orgasmos
トラックバック:https://www.camtocamnude.com/
トラックバック:sexy webcam porn
トラックバック:SPacE.sOSOt.Net
トラックバック:Roulette en Ligne
トラックバック:https://www.693173.xyz/
トラックバック:www.281317.xyz
トラックバック:Coach Affaires
トラックバック:Annonce Libertine
トラックバック:Casino en ligne
トラックバック:Genius! How To Determine If You should Really Do Group Sex Video
トラックバック:https://Videoonefreeporn.com/video/13.html
トラックバック:Https://Sites.Google.Com/
トラックバック:myhomehobby
トラックバック:www.webcamnudefree.com
トラックバック:https://www.802333.xyz/
トラックバック:www.390509.xyz
トラックバック:Http://Monboxpro.Fr
トラックバック:www.282868.xyz
トラックバック:Www.389251.xyz
トラックバック:his explanation
トラックバック:https://Www.377229.xyz/shtmls/1110.html
トラックバック:Free Pokemon Sex Gif Teaching Servies
トラックバック:sneak a peek at this site
トラックバック:https://www.721172.xyz/
トラックバック:www.281325.Xyz
トラックバック:https://www.281326.xyz/video/1649.html
トラックバック:Sex With Friends Tip: Shake It Up
トラックバック:raja pulsa murah
トラックバック:8 Ridiculous Rules About Days Without Sex Jokes
トラックバック:m1bar.com
トラックバック:www.210161.xyz
トラックバック:Www.Cifradue.It
トラックバック:Farma Sfera published an article
トラックバック:https://www.389251.xyz
トラックバック:https://www.281328.xyz
トラックバック:Blog.Goober.Jp
トラックバック:https://sites.Google.com/view/youtucam/santana-barber-shop-porn
トラックバック:scamanalytics
トラックバック:JAV Uncensored
トラックバック:www.281316.xyz
トラックバック:www.557698.xyz
トラックバック:動物プロダクション
トラックバック:you could try this out
トラックバック:Adhd Resources online
トラックバック:baron0742.blog.fc2.com
トラックバック:www.377229.xyz
トラックバック:modoosol.com
トラックバック:simply click vostok-teks.ru
トラックバック:https://www.386337.xyz
トラックバック:AI303
トラックバック:www.168698.xyz
トラックバック:해외선물 실체결
トラックバック:https://sites.google.com
トラックバック:mr peabody and sherman porn
トラックバック:Hirohiro.Work
トラックバック:Sae228Jk.Blog.Fc2.Com
トラックバック:Shinhwaspodium.Com
トラックバック:Visit Home Page
トラックバック:https://sites.google.com/view/Youtucam/sophie-rain-leak-porn
トラックバック:full sex hd video
トラックバック:https://Www.131291.xyz
トラックバック:www.339823.xyz
トラックバック:www.162596.xyz
トラックバック:http://Seedtagpreview.com
トラックバック:https://www.161353.xyz/movies/1429.html
トラックバック:Https://Www.410153.Xyz/Html/1015.Html
トラックバック:709666.xyz
トラックバック:390507.xyz
トラックバック:https://www.sexwithsister.com/htmls/110.html
トラックバック:https://www.247887.xyz/
トラックバック:Https://www.taloncopters.com
トラックバック:The Key History Of Housewife Sex
トラックバック:Https://Www.282864.Xyz
トラックバック:child-life.Jp
トラックバック:4 Creative Ways You&
トラックバック:Https://Bauwagen-Berlin.De
トラックバック:Eight Creative Ways You can Improve Your Male Sex
トラックバック:http://ranking.fenban.net/sameip/hi-hi/index.asp?domain=www.Kenpoguy.com/phasickombatives/profile.phpid2372894
トラックバック:take a look at the site here
トラックバック:www.008125.xyz
トラックバック:meilleur casino en ligne
トラックバック:www.348197.xyz
トラックバック:wraithknifemm2Valuemacrocamping.wordpress.com
トラックバック:Sarlib.ru
トラックバック:Hu.Feng.Ku.Angn.I.Ub.I.Xn.Xn.U.K37@Cgi.Members.Interq.OR.Jp
トラックバック:full report
トラックバック:Www.Gintur.Com
トラックバック:Fourloop.S11.Xrea.Com
トラックバック:https://www.camtocamnude.com/html/60.html
トラックバック:Raffa.Ru
トラックバック:123 go movies
トラックバック:Cryptocurrency Hedge Fund
トラックバック:click here to visit shortjobcompany.com for free
トラックバック:ASIN Appeal
トラックバック:Amazon account
トラックバック:Https://Www.Webcamnudefree.Com/Video/177.Html
トラックバック:https://www.154666.xyz
トラックバック:https://46.ip-5-135-151.eu/home.php?mod=space&uid=9519534&do=profile
トラックバック:mouse click the up coming website
トラックバック:www.930035.xyz
トラックバック:https://sites.google.com/view/youtucam/succubus-dream-html-porn-game
トラックバック:https://www.693169.xyz/htmls/1436.html
トラックバック:https://Support.Ihc.ru/sitecheck/index.php?url=molecolemediterranee.it/Domanda/clinique-dune-main-a-montreal-expertise-en-soins-de-la-main-et-du-poignet/
トラックバック:308308.Com
トラックバック:https://www.chatterbaitcams.com
トラックバック:www.281327.xyz
トラックバック:Batsmm2Valuehighliquidity.Wordpress.Com
トラックバック:jenny scordamaglia porn videos
トラックバック:DUbaI-conVEntIOn-CENtRE.Com
トラックバック:https://Classifieds.Ocala-News.com/author/moniquesutt
トラックバック:Click At this website
トラックバック:Africantide.Com
トラックバック:http://goeserv.com/__media__/js/netsoltrademark.php?d=blog-Kr.Dreamhanks.comquestionreparation-de-bruleurs-a-mazout-assurer-votre-confort-et-securite-36
トラックバック:toy chica porn games
トラックバック:https://www.430328.xyz/shtmls/1097.html
トラックバック:Https://www.555819.xyz/videos/1808.html
トラックバック:cramming for the final porn
トラックバック:mouse click the next document
トラックバック:Preparamo le
トラックバック:www.693136.xyz
トラックバック:www.519502.xyz
トラックバック:https://throttlecrm.com/resources/webcomponents/link.php?realm=aftermarket&dealergroup=A5002T&link=https://Kenpoguy.com/phasickombatives/profile.php?id=2376385
トラックバック:gay chem sex videos
トラックバック:ginger tradesman gay porn
トラックバック:vxi.su
トラックバック:Crypto Hedge Fund
トラックバック:https://www.mobilechaturbate.com
トラックバック:https://www.805806.xyz
トラックバック:Www.maultalk.com
トラックバック:https://www.730686.xyz/html/1230.html
トラックバック:Public Sex Video Expert Interview
トラックバック:Hedge Fund
トラックバック:Amazon suspensions
トラックバック:company website
トラックバック:Amazon Inauthentic Claims
トラックバック:www.721172.xyz
トラックバック:Http://Www2C.Biglobe.Ne.Jp/~Joshjosh/Cgi_Bin/Jawanot3/Jawanote.Cgi?Page=0&Pass=]View
トラックバック:Amazon Account Management
トラックバック:www.danayab.com
トラックバック:668598.xyz
トラックバック:Suspended Amazon Account
トラックバック:https://sites.google.com/view/rhea-ripley-deepfake-porn/home
トラックバック:Four Reasons Sex Offender Registry California Is A Waste Of Time
トラックバック:Resolving Amazon IP
トラックバック:135051.xyz
トラックバック:www.375444.xyz
トラックバック:No Extra Mistakes With Sex Sofa
トラックバック:Indian Gay Sex Tips
トラックバック:Website.informer.com
トラックバック:Amazon Account Reinstatement
トラックバック:ADHD Calming techniques
トラックバック:adhd brain Training exercises
トラックバック:Www.art2dec.co
トラックバック:www.709666.xyz
トラックバック:https://zombie2021knifemm2valuemetareset.wordpress.com/
トラックバック:hardcarrybones2019mm2value.wordpress.com
トラックバック:Going Here
トラックバック:craftableyellowknifemm2.wordpress.com
トラックバック:Check Out Wordpress
トラックバック:similar web page
トラックバック:body to body massage
トラックバック:sex best
トラックバック:proxy services
トラックバック:massage near me
トラックバック:3 Creative Ways You Possibly can Improve Your Sex Dolls With Artificial Intelligence
トラックバック:005563.xyz
トラックバック:mychance.com.ua
トラックバック:https://www.girlontopporn.com/post/21.html
トラックバック:Https://Www.Webcamsexlivefree.Com/Htmls/164.Html
トラックバック:https://www.912924.xyz/
トラックバック:navigate to this website
トラックバック:www.zerobywav.com
トラックバック:Interested by Best Oral Sex? Eight The Explanation why Its Time To Stop!
トラックバック:Aneka4d
トラックバック:Trademarketclassifieds.com
トラックバック:https://www.281413.xyz/htmls/393.html
トラックバック:aviator
トラックバック:https://www.247887.xyz
トラックバック:www.281315.xyz
トラックバック:https://www.339823.xyz/movie/1024.html
トラックバック:https://www.390509.xyz
トラックバック:Ten Easy Steps To An efficient Girl Having Sex With Dog Strategy
トラックバック:https://www.072298.xyz/
トラックバック:375444.xyz
トラックバック:www.150469.xyz
トラックバック:Alanna porn milf finder lizard tounge
トラックバック:Dirty Facts About Female Sex Dolls Revealed
トラックバック:Activos coreanos para estética
トラックバック:The Way to Become Profitable From The Gay Prison Sex Phenomenon
トラックバック:furniture manufacturers
トラックバック:Do African Sex Videos Better Than Barack Obama
トラックバック:2ace 다바오
トラックバック:https://www.livecamsexshow.com/movies/76.html
トラックバック:https://www.016967.xyz/video/1840.html
トラックバック:why not find out more
トラックバック:282861.xyz
トラックバック:Hylifesaving.Com
トラックバック:https://storybook.Se
トラックバック:right here on 282863
トラックバック:Why Everybody Is Talking About Shemale Sex Tubes&
トラックバック:chatterbatecam.com
トラックバック:https://Www.673668.xyz/videos/1466.html
トラックバック:필리핀 다바오 여자대학교
トラックバック:read more on sites.google.com`s official blog
トラックバック:Https://Www.693171.Xyz
トラックバック:https://www.freelivesexonline.com
トラックバック:xoso247.blog.fc2.Com
トラックバック:https://www.336164.xyz/movie/909.html
トラックバック:https://www.375444.xyz/
トラックバック:shemalefavoritelist.com
トラックバック:http://elegbederafiukenny@p.laus.i.bleljh@h.att.ie.m.c.d.o.w.e.ll2.56.6.3Burton.rene@G.Oog.l.eemail.2.1@woostersource.co.uk
トラックバック:8 Reasons It&
トラックバック:https://www.281328.xyz/shtmls/989.html
トラックバック:Shortcuts To Increase Sex Drive That Only some Learn About
トラックバック:https://www.girlontopporn.com/post/5.html
トラックバック:Methods to Get Sex Education (tv Series) For Under $a hundred
トラックバック:Find out how To Start Sex In A Pan
トラックバック:Here Is a Technique That Is Helping Free Online Sex Videos
トラックバック:her latest blog
トラックバック:Sexcameralive`s latest blog post
トラックバック:Rakehama.net
トラックバック:Www.282864.xyz
トラックバック:https://Www.348197.xyz/post/1164.html
トラックバック:The Basic Of Cheap Sex Doll
トラックバック:712210.xyz
トラックバック:live777
トラックバック:다바오 포커 안드로이드
トラックバック:http://uym.my.Coocan.jp/bbs/Bbsm/bbs1.cgi?aaa&
トラックバック:9 Shortcuts For Sex Video Hd That Gets Your Result in Report Time
トラックバック:www.016967.xyz
トラックバック:redirect to Chatterbatecam
トラックバック:https://www.156798.xyz
トラックバック:Https://Www.390508.Xyz/Posts/1151.Html
トラックバック:파라존카지노 가입쿠폰 최대 5만
トラックバック:new post from Xn 9i 2blz 0qc 217czqmswa
トラックバック:how many btu needed for 1000 square feet
トラックバック:heat loss calculation in pipe
トラックバック:simply click the next internet page
トラックバック:693172.xyz
トラックバック:Get Better Aubrey Plaza Sex Scene Results By Following 3 Simple Steps
トラックバック:https://Cn.geoipview.com/?q=Sdongha.comInquiry190275
トラックバック:https://www.bestfreepornwebsites.com
トラックバック:goon porn videos
トラックバック:339823.xyz
トラックバック:Instant Solutions To Types Of Sex In Step-by-step Detail
トラックバック:https://www.210161.xyz/htmls/704.html
トラックバック:https://www.555816.xyz
トラックバック:youtucams specs appeal cherie porn
トラックバック:https://www.395351.xyz/porn/1050.html
トラックバック:다바오 충전하는법
トラックバック:https://www.freeliveadultcams.com
トラックバック:www.135051.xyz
トラックバック:please click the following page
トラックバック:Believing Any Of these 10 Myths About Sex Bot Chat Retains You From Rising
トラックバック:https://Www.013252.xyz/htmls/1044.html
トラックバック:www.281329.xyz
トラックバック:281331.xyz
トラックバック:ber videos porn
トラックバック:visit the up coming article
トラックバック:resource for this article
トラックバック:indonesia furniture
トラックバック:www.282863.Xyz
トラックバック:https://Www.390507.xyz/category/Japanese
トラックバック:http://carecall.co.Kr
トラックバック:https://www.freeonlinewebsex.com/posts/61.html
トラックバック:indonesia furniture factory
トラックバック:https://gamblingsnews.com/bbs/board.php?Bo_table=free&wr_id=799384
トラックバック:fat women using extremely huge dildo porn videos
トラックバック:629752.xyz
トラックバック:videoonefreeporn.com
トラックバック:https://Www.348197.xyz/
トラックバック:https://www.668598.xyz
トラックバック:published on Forum.Altaycoins.com
トラックバック:https://www.339823.xyz/movie/1277.html
トラックバック:Picture Your Avatar Sex On Top. Read This And Make It So
トラックバック:try Freeliveadultcams
トラックバック:sex Education Cast netflix series
トラックバック:https://www.freesexvideocam.com/videos/63.html
トラックバック:Kenbc.Nihonjin.Jp
トラックバック:https://www.189169.xyz/movies/1694.html
トラックバック:Mouseclickerz.Org
トラックバック:http://WWW.Gotanproject.net/node/24525278?——WebKitFormBoundaryogl5KHUSwL8ueGfIContent-Disposition:form-data;name=titleCaractristiquesdesVentilateursdeConduit——WebKitFormBoundaryogl5KHUSwL8ueGfIContent-Disposition:form-data;name=bodyLesventilateurs
トラックバック:Nc Sex Offender For Dollars
トラックバック:Kaos polos aesthetic
トラックバック:https://www.sexwithsister.com
トラックバック:grag stone gay porn
トラックバック:https://www.Chachurbate.com/movie/47.html
トラックバック:Www.Gotoboy.Com
トラックバック:www.430328.xyz
トラックバック:www.Secretsearchenginelabs.com
トラックバック:nala ray sex videos
トラックバック:SEO Montreal
トラックバック:다바오 설치방법
トラックバック:https://www.236476.xyz/htmls/1476.html
トラックバック:www.282866.xyz
トラックバック:http://OJM.Canadareverse.com/__media__/js/netsoltrademark.php?d=BIO.Rogstecnologia.Com.bradamtietkens
トラックバック:http://www2k.biglobe.ne.jp/
トラックバック:https://www.youtucams.com/
トラックバック:official Parallel blog
トラックバック:mouse click the next web site
トラックバック:https://www.367896.xyz/
トラックバック:Why Nobody is Talking About Schoolgirl Sex And What You should Do Today
トラックバック:www.345351.xyz
トラックバック:our homepage
トラックバック:https://Bookmarkshut.com/story19535635/artiste-en-maquillage-permanent-attraits-beaut
トラックバック:https://www.555814.xyz/post/494.html
トラックバック:693136.xyz
トラックバック:다바오 여행
トラックバック:다바오 비즈니스 호텔
トラックバック:reviews over at Freebestpornsites
トラックバック:http://Www.Vnuspa.org/gb/go.php?url=https://Tangguifang.Dreamhosters.com/comment/html/?1054226.html
トラックバック:다바오 무료주차 가능한 호텔
トラックバック:lovejunx.upper.Jp
トラックバック:http://Thebestgamesites.Awardspace.info/index.php?a=stats&u=patty07255929913
トラックバック:10 Tips about Drunk Sister Sex You can use Today
トラックバック:https://sites.google.com/view/youtucam/scott-millie-chase-activeduty-gay-porn
トラックバック:282863.xyz
トラックバック:how much space will a 30000 btu heater heat
トラックバック:mini split heating calculator
トラックバック:heat loss calculator
トラックバック:안전놀이터
トラックバック:btu needed for 1000 square feet
トラックバック:5000 btu to square feet
トラックバック:how to find btu per square foot
トラックバック:how do you calculate btu per square foot
トラックバック:how much will 24000 btu heat
トラックバック:how to work out heat loss
トラックバック:youtucams sizuka majima porn pics
トラックバック:Furnace Size Calculator
トラックバック:http://Www.secretsearchenginelabs.com/add-url.php?subtime=1735697117&newurl=http://Www.cqcici.com/comment/html/331562.html
トラックバック:temperature change calculator
トラックバック:heat loss calculation formula
トラックバック:kreams
トラックバック:https://www.281322.xyz/html/1089.html
トラックバック:see more
トラックバック:iptv france
トラックバック:youtucams shemale georgie williams porn
トラックバック:토토친구
トラックバック:best crypto airdrop
トラックバック:Daongil.com
トラックバック:https://www.281327.xyz/movie/1555.html
トラックバック:Vape Offizielle Webseite
トラックバック:iptv code
トラックバック:https://issosyal.com/
トラックバック:https://www.chatterbaitcams.com/
トラックバック:from the Xiushui blog
トラックバック:Snap Sex Secrets
トラックバック:http://etvideosondemand.com//@marcialamaro5?page=about
トラックバック:Slackers Guide To Do Women Like Sex
トラックバック:video porn alicia machado
トラックバック:www.555812.xyz
トラックバック:http://insdd.ek3nk4r.Workers.dev/
トラックバック:website design
トラックバック:ANDA BISA APA
トラックバック:https://www.375444.xyz/videos/981.html
トラックバック:digitalafterlife.org
トラックバック:https://www.281331.xyz/porn/1295.html
トラックバック:www.161353.xyz
トラックバック:https://www.my-ip-Finder.com/index.php?getvar1=www.kenpoguy.comphasickombativesprofile.phpid2388416&action=dnslookup-domain-name-IP-and-localization&langue=en…
トラックバック:git.technologistsguild.org
トラックバック:Bokep Terbaru Indonesia
トラックバック:pegasus smith porn comics
トラックバック:377229.xyz
トラックバック:gay monsters inc porn
トラックバック:281315.xyz
トラックバック:Busty Sister Jennifer Comes To Congratulate Lucky Brother Vr Porn
トラックバック:https://www.281316.xyz/html/57.html
トラックバック:members.tripod.com
トラックバック:https://Www.281317.xyz/post/564.html
トラックバック:150469.xyz
トラックバック:Foxibet login
トラックバック:green graphic tee
トラックバック:camtocamnude.com
トラックバック:welcome to Nicest porn
トラックバック:094444.xyz
トラックバック:Etude extension
トラックバック:iron iptv
トラックバック:Orion Depp Crypto
トラックバック:Bureau d’études structure
トラックバック:다바오 여자
トラックバック:BET Structure
トラックバック:Porn Sex Videos
トラックバック:Ingénieur béton
トラックバック:google.nr
トラックバック:Attestation de cloisons
トラックバック:black and red graphic tee
トラックバック:Orion Depp TikTok
トラックバック:webcamsexlivefree.com
トラックバック:Belvacdecoratorsystems.com
トラックバック:video porno de karely ruiz
トラックバック:iAMRoOt.TEch
トラックバック:www.400365.xyz
トラックバック:e trade sign in
トラックバック:https://www.webcamnudefree.com/
トラックバック:The Secret History Of Black Sex Doll
トラックバック:https://www.shemalefavoritelist.com/movies/57.html
トラックバック:SuperEasy Ways To Learn Every part About Sex Toys Amazon
トラックバック:woman having sex with a dog video
トラックバック:https://www.247887.xyz/posts/823.html
トラックバック:https://www.693172.xyz
トラックバック:www.693173.xyz
トラックバック:https://Www.Sexywebcamchat.com/
トラックバック:1Whois.ru
トラックバック:https://www.557698.xyz/porn/1318.html
トラックバック:Www.diarioelsoldecusco.com
トラックバック:Recommended Reading
トラックバック:www.201155.xyz
トラックバック:http://Culinaryvisions.events/__media__/js/netsoltrademark.php?d=Blog-Kr.Dreamhanks.comquestioncentre-medico-esthetique-revelez-votre-beaute-naturelle-en-toute-confiance-87
トラックバック:https://www.912924.xyz
トラックバック:Usa Sex Guide Columbus Sucks. But It&
トラックバック:videos pornos mamas con hijos
トラックバック:e trade
トラックバック:https://282863.xyz/post/847.html
トラックバック:다바오 마닐라 항공권
トラックバック:http://Www.Hartmanngmbh.de/url?q=http://Blog-KR.Dreamhanks.com/question/clinique-podiatrique-a-blainville-soins-experts-pour-vos-pieds-27/
トラックバック:read this post from www.avto-sphere.ru
トラックバック:dvd serien
トラックバック:dvds for sale
トラックバック:E-Zigarette
トラックバック:House of Vape
トラックバック:802333 noted
トラックバック:box set movies
トラックバック:dvd wholesale
トラックバック:online dvd store
トラックバック:https://www.154666.xyz/html/1160.html
トラックバック:new release dvd
トラックバック:https://www.016967.xyz/
トラックバック:Läti veod
トラックバック:آموزش ارز دیجیتال در مشهد
トラックバック:Www.Humansoft.co.kr
トラックバック:https://www.sexcamonlinefree.com/shtmls/69.html
トラックバック:dvd distributors
トラックバック:the beginning after the end porn
トラックバック:new dvd releases
トラックバック:https://Wbgrp-Svc104.Us.Archive.org/player?url=httpBlog-Kr.dreamhanks.comquestionsciatique-a-terrebonne-comprendre-et-gerer-la-douleur-69
トラックバック:https://www.018023.xyz/
トラックバック:porn With Text gif
トラックバック:http://miki-soft.com/zproject/cgi/board/z.cgi
トラックバック:Joanellis.com
トラックバック:Koreakoifarm.com
トラックバック:5 strange info about sex with clothes On
トラックバック:https://www.bestpornstreamingsites.com/
トラックバック:Ten Issues To Do Immediately About Black Sex Link Chicken
トラックバック:visit the up coming post
トラックバック:https://www.162596.xyz/
トラックバック:http://e-plastic.ru/
トラックバック:best realtor in Albuquerque NM
トラックバック:best real estate agent in Lebanon OH
トラックバック:real estate agent in Lebanon OH
トラックバック:best real estate agent in Albuquerque NM
トラックバック:best realtor in Lebanon OH
トラックバック:카지노 가입주소
トラックバック:www.693172.xyz
トラックバック:카지노이벤트
トラックバック:https://www.330914.xyz
トラックバック:If You do not (Do)Chair Sex Now
トラックバック:http://Camillasullivan.com/__media__/js/netsoltrademark.php?d=blog-kr.dreamhanks.comquestionchanger-un-chauffe-eau-a-quebec-prix-et-conseils-48
トラックバック:real estate agent in Gorham ME
トラックバック:real estate agent in Albuquerque NM
トラックバック:https://www.135051.xyz
トラックバック:realtor in Albuquerque NM
トラックバック:Kinokorol.Com
トラックバック:Orion Depp
トラックバック:http://Infinitybus.com/__media__/js/netsoltrademark.php?d=Utahsyardsale.comauthorrorye21869
トラックバック:realtor in Bossier City LA
トラックバック:best real estate agent in Gorham ME
トラックバック:best realtor in Bossier City LA
トラックバック:real estate agent in Bossier City LA
トラックバック:https://Www.336164.xyz
トラックバック:realtor in Gorham ME
トラックバック:بودرة سحب لون ابيض 500 جرام
トラックバック:ابل ستور المتجر السعودي
トラックバック:قبعة شتوية موسيقية للنساء في الرياض
トラックバック:JUAL OBAT KUAT
トラックバック:منظم كهرباء 10000 واط
トラックバック:https://www.282862.xyz
トラックバック:Easy Steps To A 10 Minute Sex Arabic
トラックバック:https://www.281312.xyz
トラックバック:kitchen remodeling companies near me
トラックバック:บาคาร่า168
トラックバック:visit the next internet site
トラックバック:Sick And Tired Of Doing Avatar Sex The Old Way? Read This
トラックバック:slot99
トラックバック:https://nearwin.us/최신-바카라사이트-정보와-안전한-카지노-경험하기
トラックバック:www.youtucams.com
トラックバック:Https://Www.Shemalefavoritelist.Com
トラックバック:http://nfcym.net/__media__/js/netsoltrademark.php?d=blog-kr.dreamhanks.comquestionsoin-du-visage-a-terrebonne-revelez-votre-eclat-naturel-56
トラックバック:บาคาร่า777
トラックバック:rubi rose porn videos
トラックバック:https://Www.Bruederli.com/?s=httph2kelim.combbsboard.phpbo_tablefreewr_id183070
トラックバック:click to find out more
トラックバック:click the following post
トラックバック:토토 가입주소
トラックバック:https://www.168698.xyz/movies/1255.html
トラックバック:http://Yhbb.Co.kr/bbs/board.php?bo_table=free&wr_id=109914
トラックバック:madame sophie juicy body porns
トラックバック:https://www.870777.xyz
トラックバック:related web-site
トラックバック:Eight Lessons About Old Women Having Sex You could Learn Before You Hit 40
トラックバック:https://www.zzgps.com/htmls/32.html
トラックバック:https://www.onlinewebcamporn.com/post/118.html
トラックバック:why not try these out
トラックバック:best real estate agent in Bossier City LA
トラックバック:토토이벤트
トラックバック:SITUS PENIPU
トラックバック:realtor in Lebanon OH
トラックバック:토지노 가입주소
トラックバック:https://www.onlinelivesexcam.com/html/189.html
トラックバック:ufacash
トラックバック:www.247887.xyz
トラックバック:best realtor in Gorham ME
トラックバック:Doosung1.co.kr
トラックバック:토토주소
トラックバック:https://www.345351.xyz/shtmls/1500.html
トラックバック:sites.google.com published a blog post
トラックバック:www.410153.xyz
トラックバック:https://www.721172.xyz
トラックバック:다바오 레이크
トラックバック:https://www.282865.xyz/
トラックバック:Pendantquetulaimes.com
トラックバック:mihayashi.com
トラックバック:american express e gift card
トラックバック:Beware The Why Does Sex Feel Good Scam
トラックバック:https://www.freenudevideochat.com/videos/114.html
トラックバック:https://www.chatabte.com/htmls/41.html
トラックバック:https://www.freesexvideocam.com/videos/179.html
トラックバック:visit the next post
トラックバック:https://www.Livecamsexshow.com/movies/65.html
トラックバック:microsoft Store gift Card
トラックバック:furniture from indonesia
トラックバック:c.daum7.net
トラックバック:Flipkart Gift
トラックバック:www.234135.xyz
トラックバック:Little Known Facts About College Sex Stories
トラックバック:https://www.281329.xyz
トラックバック:meet men online
トラックバック:iconic gift card
トラックバック:Crypto airdrop
トラックバック:Digital Marketing Cornwall
トラックバック:에볼루션
トラックバック:에볼루션블랙잭
トラックバック:online video chat
トラックバック:zeroken.Jp
トラックバック:meet women online
トラックバック:Free crypto airdrop
トラックバック:seo services denver
トラックバック:281325.xyz
トラックバック:Www.281328.Xyz
トラックバック:sudadera juventus
トラックバック:131291.xyz
トラックバック:Life After Baby Sex
トラックバック:SITUS PENIPUAN
トラックバック:Vanilla Visa Gift Card
トラックバック:https://www.bestfreeliveporn.com
トラックバック:https://www.135051.xyz/
トラックバック:Www.177455.xyz
トラックバック:Shatki explains
トラックバック:www.282869.xyz wrote
トラックバック:http://Gladstone-International.com/__media__/js/netsoltrademark.php?d=Caresalad.combbsboard.phpbo_tablefreewr_id591690
トラックバック:http://Blog-KR.Dreamhanks.com/question/hotel-a-insectes-prix-sur-le-quebec-26/
トラックバック:https://sites.Google.com/view/youtucam/shemale-alessandra-argento-porn
トラックバック:http://gotanproject.net/node/24546674?——WebKitFormBoundarywiEeFhCAU2MrV5KEContent-Disposition:form-data;name=titlePropritsRsidentiellesVendreSaint-lambert-de-lauzon——WebKitFormBoundarywiEeFhCAU2MrV5KEContent-Disposition:form-data;name=bodyspanstyl
トラックバック:dnsrecords.io
トラックバック:http://sahaniti-lawac.com/index.php/2-uncategorised/\\\”\/index.php\/2-uncategorised\/1-getting-started
トラックバック:300 Sex Scene Tip: Shake It Up
トラックバック:click through the following website
トラックバック:Do You Need A Stardew Valley Sex Mod?
トラックバック:https://www.282867.Xyz/
トラックバック:3rascals.Net
トラックバック:Roblox Robux Card
トラックバック:The Second Sex Simone De Beauvoir Guide To Communicating Value
トラックバック:Why Some Individuals Nearly At all times Make/Save Cash With Miley Cyrus Sex Video
トラックバック:フランス ユニフォーム
トラックバック:https://www.537868.xyz
トラックバック:everton kit
トラックバック:Www.369261.xyz
トラックバック:coco bliss onlyfans porn
トラックバック:https://www.281323.xyz/shtml/161.html
トラックバック:https://www.281315.xyz/post/1002.html
トラックバック:Ragtimepartners.com
トラックバック:adhd organization tips
トラックバック:https://www.162596.xyz/movies/1087.html
トラックバック:try these guys out
トラックバック:Grand Dragon Lotto
トラックバック:Orion Depp Twitter
トラックバック:modern italian furniture
トラックバック:http://gangnammall.shop/bbs/board.php?bo_table=free&wr_id=178985
トラックバック:Orion Depp YouTube
トラックバック:Orion Depp Solana
トラックバック:modern interior
トラックバック:https://Www.Simply.com/se/diagnostics/?domain=http://Gotanproject.net/node/24527115?——WebKitFormBoundaryYViUOcslObOm2xK7Content-Disposition:form-data;name=titleStudio——WebKitFormBoundaryYViUOcslObOm2xK7Content-Disposition:form-data;name=bodyAutemp
トラックバック:modern interior design
トラックバック:537868.Xyz
トラックバック:https://www.freelivecamsites.com/
トラックバック:How I Acquired Started With Naked Girls Sex
トラックバック:Five Ways A Nifty Sex Lies To You Everyday
トラックバック:Why You actually need (A) Human Sex Trafficking
トラックバック:adhd-friendly apps for students
トラックバック:I Don&
トラックバック:www.281323.xyz
トラックバック:Picture Your Illinois Sex Offender List On Top. Learn This And Make It So
トラックバック:youtucams skinny curly sex skirt standing porn
トラックバック:https://www.simply.com/se/diagnostics/?domain=http://blog-kr.Dreamhanks.com/question/medecin-osteopathe-le-professionnel-de-la-sante-holistique-29/
トラックバック:daniella_martin porn videos
トラックバック:다바오 포커 다운
トラックバック:Paycomreviews.Com
トラックバック:https://www.094444.xyz/
トラックバック:Pump Up Your Sales With These Remarkable Street Sex Tactics
トラックバック:www.693169.xyz
トラックバック:Mn@gamenglish.com
トラックバック:emma magnolia porn videos
トラックバック:The way forward for Tumblr Office Sex
トラックバック:visioncareafrica.org
トラックバック:https://www.629752.xyz/
トラックバック:https://www.555819.xyz/videos/1774.html
トラックバック:다바오 회원가입 하는법
トラックバック:ADHD Home Organization Hacks
トラックバック:https://Www.281413.xyz/htmls/551.html
トラックバック:http://pretty4u.co.kr/new/bbs/board.php?bo_table=free&wr_id=2977546
トラックバック:Serendipity.kz
トラックバック:www.189169.xyz
トラックバック:다바오 포커 충전 방법
トラックバック:Visit Webpage
トラックバック:https://web3buzz.net/tips-on-how-to-put-together-for-a-massage-suggestions-for-a-enjoyable-expertise/
トラックバック:https://365.expresso.blog/question/tips-for-choosing-cheer-uniforms-8/
トラックバック:casino en ligne France
トラックバック:casinos plus fiables
トラックバック:meilleur casino en ligne fiable
トラックバック:http://rotonexpert.com/why-couples-massages-can-strengthen-your-relationship-7/
トラックバック:I-fixit.com
トラックバック:Redeemed Life Counseling
トラックバック:https://learning.lgm-international.com/forums/users/maxwellwhinham/
トラックバック:https://irte.duiko.guru/forums/users/kishabrass5822/
トラックバック:https://www.693175.xyz
トラックバック:iptv subscription
トラックバック:Orion Depp LinkedIn
トラックバック:Orion Depp Crypto Trading
トラックバック:Orion Depp Instagram
トラックバック:Https://Www.281317.Xyz/
トラックバック:242261.xyz
トラックバック:Orion Depp Crypto Advisor
トラックバック:https://005563.xyz/
トラックバック:http://Washinabag.com/__media__/js/netsoltrademark.php?d=Susungmetals.combbsboard.phpbo_tablefreewr_id166437
トラックバック:www.673668.xyz
トラックバック:Highly recommended Webpage
トラックバック:vídeos pornos gay caseros
トラックバック:http://shop.ororo.co.kr/bbs/board.php?bo_table=free&wr_id=718108
トラックバック:https://www.210161.xyz/htmls/615.html
トラックバック:https://tangguifang.dreamhosters.com/comment/html/?1077861.html
トラックバック:videos de mujeres teniendo sexo con animales
トラックバック:daisy drew sex videos
トラックバック:レアル ユニフォーム 2024
トラックバック:jack doherty gay porn
トラックバック:https://Www.161353.xyz
トラックバック:https://www.131291.xyz/shtml/2024.html
トラックバック:graypENSION.cOm
トラックバック:http://Www.hrup.co.kr/bbs/board.php?bo_table=free&wr_id=188364
トラックバック:bridgejelly71>fusi.serena@Www.woostersource.Co.uk
トラックバック:http://Network45.maru.net/bbs/board.php?bo_table=free&wr_id=334607
トラックバック:https://www.519502.xyz/html/1787.html
トラックバック:https://www.693169.xyz/
トラックバック:counseling Argyle TX
トラックバック:http://Holidaysnfestivals.com/__media__/js/netsoltrademark.php?d=forum.altaycoins.comprofile.phpid1016393
トラックバック:Argyle counseling
トラックバック:http://Gotanproject.net/node/24579823?——WebKitFormBoundaryRATUAAzx66YnIrXEContent-Disposition:form-data;name=titleLeMeilleurChiropraticienMontral:SoulagementdesDouleursetRtablissementdel’quilibre——WebKitFormBoundaryRATUAAzx66YnIrXEContent-Disposi
トラックバック:www.330914.xyz official website
トラックバック:www.029444.xyz
トラックバック:Xn—-Itbjfmhgce8Azck.Xn–P1ai
トラックバック:https://Cl-system.jp/question/syndic-de-faillite-au-quebec-comprendre-leur-role-et-leurs-services-5/
トラックバック:therapists in Argyle
トラックバック:www.282861.xyz
トラックバック:https://www.kenpoguy.com/phasickombatives/profile.php?id=2398938
トラックバック:Sgvalley.co.kr
トラックバック:Recommended Web-site
トラックバック:visit the next web page
トラックバック:bipfocus.com
トラックバック:https://blog-kr.Dreamhanks.com/question/aspirateur-ca126-performance-et-efficacite-par-un-nettoyage-optimal-88/
トラックバック:written by www.555812.xyz
トラックバック:http://blog-kr.dreamhanks.com/question/exploration-culinaire-resto-mexicain-a-laval-147/
トラックバック:横浜 f マリノス ユニフォーム 2024
トラックバック:Asian Sex Video Helps You Obtain Your Goals
トラックバック:Rudavision.com
トラックバック:just click the following webpage
トラックバック:https://www.802333.xyz/Html/36.html
トラックバック:693175.xyz
トラックバック:Mobileapp114.Com
トラックバック:Are you able to Spot The A Harem Sex Pro?
トラックバック:Animated Sex Videos: An inventory of 11 Issues That&
トラックバック:Xn–9d0br01Aqnsdfay3C.kr
トラックバック:The Key To Successful Impregnation Sex Stories
トラックバック:https://Cert.Zero.camp/safeguard/?site=365.expresso.blog/question/clinique-terrebonne-Votre-destination-sante-et-bien-etre-28/
トラックバック:Gender test
トラックバック:Systeme d’alarme commercial
トラックバック:Vape Battery
トラックバック:The Lazy Man&
トラックバック:valiance artist porn comic
トラックバック:Recommended Website
トラックバック:joe dematteo gay porn
トラックバック:http://h2kelim.com/bbs/board.php?bo_table=free&wr_id=203148
トラックバック:mau777
トラックバック:What Must you Do For Fast Alison Brie Sex Scene?
トラックバック:Kuzeydogu.Ogo.Org.tr
トラックバック:The Evolution Of Kama Sutra Sex
トラックバック:new tottenham kit 24 25
トラックバック:http://blog-Kr.dreamhanks.com/question/centres-de-yoga-sur-le-quebec-decouvrez-la-serenite-et-le-bien-etre-7/
トラックバック:COPUsZN.rU
トラックバック:best real estate agent in Ann Arbor MI
トラックバック:best realtor in Frisco TX
トラックバック:best real estate agent in Columbus OH
トラックバック:real estate agent in Frisco TX
トラックバック:https://www.281319.xyz/
トラックバック:https://www.386337.xyz/posts/987.html
トラックバック:best realtor in Columbus OH
トラックバック:best realtor in Ann Arbor MI
トラックバック:PENIPU
トラックバック:https://www.chattrube.com/movies/70.html
トラックバック:coinbase login
トラックバック:real estate agent in Ann Arbor MI
トラックバック:Chatturb.com
トラックバック:https://www.281318.xyz/
トラックバック:click the up coming post
トラックバック:best realtor in San Francisco CA
トラックバック:iwbc.ru
トラックバック:Check Out 281327
トラックバック:realtor in San Francisco CA
トラックバック:real estate agent in Acworth GA
トラックバック:best real estate agent in Frisco TX
トラックバック:best real estate agent in San Francisco CA
トラックバック:realtor in Ann Arbor MI
トラックバック:What Zombies Can Teach You About Funny Sex Videos
トラックバック:djss.ru
トラックバック:https://www.519502.xyz/html/345.html
トラックバック:realtor in Columbus OH
トラックバック:6 Ridiculous Guidelines About Tanya Harding Sex Tape
トラックバック:Read the Full Report
トラックバック:https://www.693169.xyz
トラックバック:282869.xyz
トラックバック:inprokorea.com
トラックバック:https://cl-system.jp/question/kinesitherapeute-A-montreal-retablissement-et-bien-etre-Par-la-therapie-Physique-28/
トラックバック:coinbase
トラックバック:http://blog-Kr.dreamhanks.com/question/massage-therapeutique-a-montreal-le-bienfait-de-la-detente-et-de-la-guerison-23/
トラックバック:www.712210.xyz
トラックバック:https://www.porndvdstream.com/movies/10.html
トラックバック:390509.xyz
トラックバック:muscle growth
トラックバック:Orion Depp Master Ventures
トラックバック:https://www.282863.xyz/post/6.html
トラックバック:Wpkorea.net
トラックバック:best online casinos
トラックバック:Antidetect browser
トラックバック:فروشگاه تخصصی کلین شیدور
トラックバック:کلین شیدور
トラックバック:سقف متحرک استخر
トラックバック:CJC-1295
トラックバック:دستگاه لیزر برش
トラックバック:رزرو هتل ریحان
トラックバック:weight loss peptides
トラックバック:Orion Depp Polkadot VC Fund
トラックバック:metabolic peptides
トラックバック:www.730686.xyz
トラックバック:www.282865.xyz
トラックバック:Remanufacterdengine.net
トラックバック:real estate agent in San Francisco CA
トラックバック:toOL.ChINaz.Com
トラックバック:https://www.chatterbatecam.com/porn/55.html
トラックバック:free slots
トラックバック:سقف متحرک
トラックバック:semaglutide
トラックバック:ass to mouth porn gif
トラックバック:best real estate agent in Acworth GA
トラックバック:سقف متحرک رستوران
トラックバック:Impacthiringsolutions.net
トラックバック:hiburan138
トラックバック:realtor in Acworth GA
トラックバック:click through the following document
トラックバック:https://www.018023.xyz/shtml/607.html
トラックバック:realtor in Frisco TX
トラックバック:best realtor in Acworth GA
トラックバック:you can try Webcamnudefree
トラックバック:www.282869.xyz
トラックバック:https://www.345351.xyz/shtmls/484.html
トラックバック:https://www.162596.xyz/movies/1168.html
トラックバック:230023.xyz
トラックバック:http://sgeni.co.kr/bbs/board.php?bo_table=free&wr_id=111118
トラックバック:betting game
トラックバック:https://www.386337.xyz/
トラックバック:Shyteenpussy.com
トラックバック:https://Www.629752.xyz/posts/675.html
トラックバック:https://www.693173.xyz/htmls/693.html
トラックバック:Donaldmcloughlin.Com
トラックバック:http://Oefortlauderdale.com/__media__/js/netsoltrademark.php?d=www.cqcici.comcommenthtml346771.html
トラックバック:Visit Web Page
トラックバック:drug intervention
トラックバック:alcohol intervention
トラックバック:tarot reading online
トラックバック:Stop Wasting Time And begin Surprise Sex Porn
トラックバック:акции
トラックバック:psychic reading
トラックバック:id badges for employees
トラックバック:id badges
トラックバック:www.166580.xyz
トラックバック:intervention near me
トラックバック:trader
トラックバック:đầu tư chứng khoán
トラックバック:Renovation contractors Welland
トラックバック:live psychic
トラックバック:https://www.161353.xyz/
トラックバック:หุ้นไทย
トラックバック:ações
トラックバック:mental health intervention
トラックバック:การเงิน
トラックバック:nicki minaj porn video
トラックバック:GIP receptor agonists
トラックバック:Www.Keyfora.Com
トラックバック:177455.xyz
トラックバック:compounded semaglutide
トラックバック:blood sugar control
トラックバック:www.281413.xyz
トラックバック:UFO
トラックバック:Mnetsoft.com
トラックバック:Tesamorelin
トラックバック:bodybuilding peptides
トラックバック:dIdINcomPANy.coM
トラックバック:please click the next post
トラックバック:oNEStOPCLeaN.KR
トラックバック:just click the up coming document
トラックバック:Reserv.xn--oy2b23yvwhete.com
トラックバック:PutOHOlicaRI.DIGidip.Net
トラックバック:what everyone ought To learn About kamasutra sex
トラックバック:boca juniors retro jersey
トラックバック:Matadorbet giriş güNcel
トラックバック:https://www.389251.xyz/posts/325.html
トラックバック:https://www.281328.xyz/shtmls/1791.html
トラックバック:porn star scorpion tattoo on back
トラックバック:https://www.693136.xyz/porn/1491.html
トラックバック:reviews over at Dreamhosters
トラックバック:demo forex
トラックバック:ระบบ เทรด forex
トラックバック:forex day trading
トラックバック:forex xe converter
トラックバック:ปฏิทิน ข่าว forex factory
トラックバック:Cross necklace for men
トラックバック:forex trader
トラックバック:Shop men’s fragrance
トラックバック:market structure forex
トラックバック:us forex brokers
トラックバック:forex graficas
トラックバック:https://www.282861.xyz/html/1194.html
トラックバック:forex lot size calculator
トラックバック:https://www.freelivesexonline.com/post/14.html
トラックバック:swap in forex
トラックバック:true forex funds
トラックバック:Gold earrings for women
トラックバック:the forex factory
トラックバック:gps forex robot
トラックバック:pakistan forex broker
トラックバック:forex eur usd
トラックバック:forex algerie
トラックバック:forex factory noticias
トラックバック:www.930035.xyz post to a company blog
トラックバック:platforms for forex trading
トラックバック:forex trading for beginners
トラックバック:kortana forex
トラックバック:sbi forex card
トラックバック:0 spread forex broker
トラックバック:today forex rate
トラックバック:forex broker for us
トラックバック:chaotic forex robot
トラックバック:Gold ring men
トラックバック:cashback forex
トラックバック:ลิง ดํา forex แฟน
トラックバック:forex broker in pakistan
トラックバック:https://www.242261.xyz/htmls/369.html
トラックバック:forex trading hours
トラックバック:economic calendar forex
トラックバック:ecn forex broker list
トラックバック:Hair Clips
トラックバック:https://www.282864.xyz/movie/1894.html
トラックバック:forex factory ภาษา ไทย
トラックバック:forex euro dolar
トラックバック:fast forex funding
トラックバック:http://forum.altaycoins.com/profile.php?id=1019831
トラックバック:forex broker compare
トラックバック:https://www.156798.xyz/video/958.html
トラックバック:Centrala telefonica pentru integrare cu Zoom
トラックバック:http://gotanproject.net/node/24595099?——webkitformboundaryxseyd123bf1tyxmzcontent-disposition: form-data; name=”title”l’importance des agences de conseil en immobilier à saint-constant——webkitformboundaryxseyd123bf1tyxmzcontent-disposition: fo
トラックバック:문의 에볼루션
トラックバック:https://Worldwisdommag.com/
トラックバック:https://www.246306.xyz
トラックバック:HVAC repair
トラックバック:بت
トラックバック:car
トラックバック:More about the author
トラックバック:Cannabis SEO
トラックバック:music distribution services
トラックバック:Live Cam Models
トラックバック:https://www.freenudevideochat.com/videos/17.html
トラックバック:Cole diamond gay porn
トラックバック:How Nine Things Will Change The Best Way You Approach Rape Sex Video
トラックバック:http://www.jgw528.com/Home.php?mod=space&uid=3123163&do=profile&from=space
トラックバック:Read the Full Posting
トラックバック:https://www.sexchatcamera.com/porn/108.html
トラックバック:smuniverse.com
トラックバック:029444.xyz
トラックバック:에볼루션 체험
トラックバック:디지몬 어드벤처 라스트 에볼루션 더빙
トラックバック:Holyashes.Jadestaub.de
トラックバック:https://www.281331.xyz/porn/260.html
トラックバック:Medankepo link for more info
トラックバック:http://yixiaolian.blog115.fc2.com
トラックバック:schifffahrtsmuseum-nordhorn.de
トラックバック:https://www.154666.xyz/html/708.html
トラックバック:novac.home1.co.kr
トラックバック:http://www.yya28.Com
トラックバック:Best Cedar hot tubs Australia
トラックバック:Ichirosblogfromyahoo.Blog.Fc2.Com
トラックバック:You do not Need to Be An enormous Corporation To begin Ms Exchange
トラックバック:leicester shirt 23 24
トラックバック:What To Do About Nymphomaniac Sex Scene Before It&
トラックバック:https://www.242261.xyz/htmls/737.html
トラックバック:7slots giriş sayfası
トラックバック:https://rostov-na-Donu.pchelobaza26.ru
トラックバック:Pwssurf.jp
トラックバック:246306.xyz
トラックバック:online order medicine
トラックバック:Smuniverse officially announced
トラックバック:Http://simsideo.net/livredor.php?sa=u&ved=0ahukewjs7iuh5zfqahxm7imkhuc_ansqfghcmag&usg=afqjcnhkgnd-8-Navstylcqel2btwcj8Sw
トラックバック:https://Www.281321.xyz/movies/254.html
トラックバック:072298.xyz
トラックバック:http://chunzee.Co.kr/Bbs/board.Php?bo_table=free&wr_id=126798
トラックバック:by chi.zombie.jp
トラックバック:www.156798.xyz
トラックバック:https://Www.281315.xyz/post/758.html
トラックバック:www.018023.xyz
トラックバック:에볼루션 카지노 추천인
トラックバック:poison ivy porn comic
トラックバック:Https://Www.709666.Xyz/
トラックバック:www.ripten.com
トラックバック:kontol memek pepek
トラックバック:SUKATORO
トラックバック:bobofng.com
トラックバック:go to Webcamsexlivefree
トラックバック:waterfall.webbit.Kr
トラックバック:400365.xyz
トラックバック:https://Www.281325.xyz/shtmls/1280.html
トラックバック:Young Sex Tumblr Defined 101
トラックバック:indian porn videos hd
トラックバック:pstat
トラックバック:Www.spairkorea.co.kr
トラックバック:Спорт и отдых Хабаровск
トラックバック:https://www.spairkorea.co.kr:443/gnuboard/bbs/board.php?bo_table=as_inquire&wr_id=1078482
トラックバック:https://www.005563.xyz
トラックバック:8Fx.Info
トラックバック:http://estactio.com/
トラックバック:The Argument About Sex School
トラックバック:maillot du bayern munich
トラックバック:https://Www.673668.xyz/videos/1685.html
トラックバック:Recommended Webpage
トラックバック:http://descoventurecapital.com/__media__/js/netsoltrademark.php?d=aircrew.CO.Krbbsboard.phpbo_tablefreewr_id49562
トラックバック:人才
トラックバック:http://co001R.itsix.Kr
トラックバック:Read Webpage
トラックバック:www.sex8.zone
トラックバック:http://bettingdata.eu
トラックバック:online medicine to buy
トラックバック:Vancouver-webpages.com
トラックバック:jaabla.com
トラックバック:The key of Indo Sex
トラックバック:해운대 고구려
トラックバック:dewibola
トラックバック:role of server speed in search engine rankings
トラックバック:Onlineshop erstellen lassen
トラックバック:부산 고구려
トラックバック:Tech Equipment Troubleshooting
トラックバック:https://www.246306.xyz/shtmls/855.html
トラックバック:https://www.230023.xyz
トラックバック:kulhad Pizza Porn video
トラックバック:Decorative Rock for Landscaping
トラックバック:ni1kp5.Click
トラックバック:인계동호스트바
トラックバック:server technical factors influencing SEO performance
トラックバック:수원가라오케가격
トラックバック:Kosten Webseite Schweiz
トラックバック:http://Samjinuc.com/bbs/board.php?bo_table=free&wr_id=356182
トラックバック:www.jschengzhan.Com
トラックバック:visit the following web site
トラックバック:https://www.348197.xyz/post/1018.html
トラックバック:https://ceskymag.eu/
トラックバック:https://magazin-finance.cz/
トラックバック:klikbet77 slot
トラックバック:bandar slot
トラックバック:https://inmama.cz/
トラックバック:드래곤볼 에볼루션 다시보기
トラックバック:https://www.onlineporncam.com/movie/6.html
トラックバック:https://www.709666.xyz
トラックバック:Http://18658331666.com/
トラックバック:Как устроиться в магазин товаров для животных Верхнее Дуброва
トラックバック:click this link
トラックバック:http://h1s.goodgame.ru/del/ck.php?ct=1&oaparams=2__bid=190__zid=26__cb=bc85c561c6__oadest=http://www.penelopesplace.net/2009/01/02/christmas-morning
トラックバック:Gwwa.yodev.Net
トラックバック:10-Day.Net
トラックバック:에볼루션 바카라 가라머니
トラックバック:다바오 포커 홈페이지
トラックバック:http://wargame.ch/wc/Acw/sub/aotm/guestbook/index.php?utm_source=feedburner
トラックバック:다바오 링크
トラックバック:Http://Www.Cqcici.Com
トラックバック:다바오 포커 충전
トラックバック:webcams room
トラックバック:에볼루션 카지노 사이트
トラックバック:http://gotanproject.net/node/24632409?——WebKitFormBoundaryuRMJu9nNwUoNvNRoContent-Disposition:form-data;name=titleSourcilPageTroisStudioDeTatouageEtPerageLaval——WebKitFormBoundaryuRMJu9nNwUoNvNRoContent-Disposition:form-data;name=bodyLepigmentests
トラックバック:Новые автомобили Красноярск
トラックバック:Www.Osk-Cbs.Ru
トラックバック:Going Listed here
トラックバック:에볼루션 바카라 이기는법
トラックバック:아베나키 에볼루션
トラックバック:https://www.ch-valence-pro.fr
トラックバック:canada pharmacy
トラックバック:토토 에볼루션
トラックバック:Fatal Model
トラックバック:에볼루션 딜러 후기
トラックバック:polythene rolls
トラックバック:elvis wedding photos
トラックバック:floor protection
トラックバック:fire retardant polythene
トラックバック:try what he says
トラックバック:에볼루션 딜러 디시
トラックバック:see here now
トラックバック:sarang188
トラックバック:에볼루션 취소프로그램
トラックバック:via
トラックバック:click the next page
トラックバック:다바오 포커
トラックバック:다바오 포커 머니
トラックバック:forum.Altaycoins.com
トラックバック:ddfr.ru
トラックバック:pharmacies
トラックバック:에볼루션 로고
トラックバック:에볼루션 딜레이 작업
トラックバック:mooel.co.kr
トラックバック:에볼루션 바카라 플레이어 보너스
トラックバック:다바오 포커 apk
トラックバック:Шины диски Чита
トラックバック:dvd günstig kaufen
トラックバック:SEO in Kent
トラックバック:link slot zeus
トラックバック:donat89 daftar
トラックバック:Myron Golden Challenge
トラックバック:Web design Kent
トラックバック:Make More Offers Challenge
トラックバック:donat89
トラックバック:donat89 login
トラックバック:neue dvds
トラックバック:anime car vinyl wrap
トラックバック:http://vivamarketing.co.kr/bbs/board.php?bo_table=board0203&wr_id=156048
トラックバック:imkor.ru
トラックバック:Электроника Белгород
トラックバック:zencortex directions
トラックバック:canadian drugs
トラックバック:에볼루션 조작
トラックバック:다바오 아이폰 설치
トラックバック:Www.thai-tube.org
トラックバック:Реклама города Челны
トラックバック:Ижевск область объявления
トラックバック:진진돌이 에볼루션 뉴토끼
トラックバック:https://wisconsin-casinos.org/
トラックバック:http://Shirayuki.saiin.Net
トラックバック:https://gonggamore.Com
トラックバック:maglia argentina
トラックバック:zeus88
トラックバック:Fianresearch.com
トラックバック:written by www.awa.or.jp
トラックバック:다바오 탁아소있는 호텔
トラックバック:메이저사이트순위
トラックバック:generate color palettes
トラックバック:Круглосуточно Анапа
トラックバック:Galeri Nakal
トラックバック:Loodgieter Aalst
トラックバック:Aromatherapy Diffusers and Oils
トラックバック:Chair Massage Wayne Nj
トラックバック:http://gotanproject.net/node/24645979?——WebKitFormBoundaryVv8ncodnheUPeZNZContent-Disposition: form-data; name=”title”Élimination Mécanique De La Rouille Sur Les Surfaces Usinées——WebKitFormBoundaryVv8ncodnheUPeZNZContent-Disposition: form-da
トラックバック:Chauffagiste Tubize
トラックバック:Wheelchair Hong Kong
トラックバック:Chauffagiste Arlon
トラックバック:다바오 홀덤 아이폰
トラックバック:Shea Butter Skin Care
トラックバック:토토사이트
トラックバック:Plombier Arlon
トラックバック:color
トラックバック:Chauffagiste Mons
トラックバック:토지노
トラックバック:random color palette generator
トラックバック:Loodgieter Antwerpen
トラックバック:Scented Candles and Oils
トラックバック:stromectol online pharmacy
トラックバック:source web page
トラックバック:try Google
トラックバック:just click the following document
トラックバック:아이폰 다바오 다운로드
トラックバック:http://Dainelee.Net
トラックバック:아이폰 다바오 다운
トラックバック:Gambling
トラックバック:hot shotting
トラックバック:บ้านผลบอลวันนี้
トラックバック:Water Restoration Pueblo
トラックバック:บ้านผลบอล
トラックバック:วิเคราะห์บอลวันนี้
トラックバック:hotshotting
トラックバック:ราคาบอล
トラックバック:Water Damage Colorado Springs
トラックバック:House Clearance Dorset
トラックバック:Babe138
トラックバック:travel nova scotia
トラックバック:meilleur casino en ligne en france
トラックバック:xoslotz
トラックバック:Трудоустройство Геленджик
トラックバック:민다나오 다바오
トラックバック:superslot1234
トラックバック:lucabet168
トラックバック:다바오 카지노 호텔
トラックバック:다바오 뷰어
トラックバック:다바오 가입
トラックバック:How to find the best SIL provider for psychosocial disabilities
トラックバック:Company formation UAE
トラックバック:Understanding NDIS funding for participants with psychosocial disabilities
トラックバック:exploited teens porn
トラックバック:에볼루션 카지노
トラックバック:Красота и здоровье Челябинск
トラックバック:bgame777
トラックバック:drugstore online
トラックバック:Freegame`s blog
トラックバック:Iotic.Co.Kr
トラックバック:두테르테 다바오
トラックバック:다바오 vpn 설치
トラックバック:Going in xn--kss591f.xn--cksr0a.tw
トラックバック:에볼루션 시간차
トラックバック:www.rukids.co.kr
トラックバック:에볼루션 usb
トラックバック:121.181.234.77
トラックバック:http://Zeroken.jp/
トラックバック:Rtp Spotbet
トラックバック:Jalalive
トラックバック:score808 indo
トラックバック:zeus138
トラックバック:다바오 포커 가입
トラックバック:panen138
トラックバック:order medicine online
トラックバック:GHK-Cu Skin
トラックバック:https://www.redlandsrealty.com.au/about-redlands-realty/attachment/man-1209947_960_720/
トラックバック:онлайн порночат с девушками
トラックバック:Ne writes
トラックバック:Benefits of in-home support for NDIS participants with mental health challenges
トラックバック:Social interaction for NDIS participants
トラックバック:slot88
トラックバック:Link alternatif qqole
トラックバック:Home support for NDIS
トラックバック:Supported Independent Living
トラックバック:Activities for participants with psychosocial disabilities under NDIS community access
トラックバック:Psychosocial recovery coaching
トラックバック:How to choose the right in-home support provider for participants with psychosocial disabilities
トラックバック:How in-home support improves daily living for participants with psychosocial disabilities
トラックバック:visit the following internet site
トラックバック:Best NDIS services for psychosocial disabilities in Melbourne. Victoria
トラックバック:slot gacor online
トラックバック:Local disability activities
トラックバック:SIL providers for psychosocial disabilities
トラックバック:Differences between SIL and SDA for participants with psychosocial disabilities
トラックバック:Top-rated community access providers for psychosocial disabilities in Melbourne. Victoria
トラックバック:Best community access providers for participants with mental health challenges
トラックバック:rtp qqole
トラックバック:Gatheringmyroses.Blofspot.com
トラックバック:click through the next document
トラックバック:http://network45.maru.net/bbs/board.php?bo_table=free&wr_id=50281
トラックバック:http://Blog-Kr.Dreamhanks.com/question/yoga-par-debutants-a-la-maison-commencez-votre-voyage-de-bien-etre-8/
トラックバック:Foodbook.com
トラックバック:https://8n8n.co.jp/home.php?mod=space&uid=12031133&do=profile
トラックバック:by gotanproject.net
トラックバック:Размещение рекламы Архангельск
トラックバック:Dreamhanks link for more info
トラックバック:https://sergioahou53074.wikipublicity.com/6130173/a_comprehensive_guide_to_booking_a_helicopter
トラックバック:Htmlweb.ru
トラックバック:bắt cóc trẻ em
トラックバック:users.atw.hu
トラックバック:FloppyData proxy
トラックバック:먹튀사이트
トラックバック:Proxy
トラックバック:AI Lawyer
トラックバック:https://Pcportal.org/go?https://classifieds.ocala-news.com/author/jeanettmusc
トラックバック:drifting events near me
トラックバック:bokep online terbaru
トラックバック:http://www.Secretsearchenginelabs.com/add-url.php?subtime=1737560387&newurl=http://www.Cqcici.com/comment/html/373957.html
トラックバック:quad cities affordable web design
トラックバック:Azure Marketplace VM
トラックバック:https://tocarelab.com
トラックバック:Размещение рекламы Екатеринбург
トラックバック:atomic wallet
トラックバック:diseñO De paginas web andorra
トラックバック:padrão
トラックバック:edu-url-http.ru
トラックバック:https://Link.Chatujme.cz/redirect?url=http://blog-Kr.Dreamhanks.com/question/lordre-professionnel-dune-physiotherapie-du-quebec-oppq-34/
トラックバック:비아그라 사이트
トラックバック:dewatogel online
トラックバック:borkóstoló
トラックバック:equal housing logo
トラックバック:wedding venues
トラックバック:fair housing logo for realtors
トラックバック:En.Adminso.com
トラックバック:http://Adicg.com/__media__/js/netsoltrademark.php?d=tangguifang.dreamhosters.comcommenthtml1120501.html
トラックバック:http://Blog-KR.Dreamhanks.com/question/mecanicien-electricien-un-metier-alliant-mecanique-et-electricite-20/
トラックバック:Energypop.Co.kr
トラックバック:http://www.Gotanproject.net/node/24699883?——WebKitFormBoundaryJp1n8mYTCol4bUkSContent-Disposition:form-data;name=titleObturationDentaire:TraitementpourRparerlesCariesDentaires——WebKitFormBoundaryJp1n8mYTCol4bUkSContent-Disposition:form-data;name=b
トラックバック:relaxation massage
トラックバック:купить диплом гознак
トラックバック:Free-Proxy-socks5-socks4.ru
トラックバック:http://himhong.lolipop.Jp
トラックバック:best real estate agent in Wentzville MO
トラックバック:best real estate agent in Huntersville NC
トラックバック:Gls.knu.Ac.kr
トラックバック:best real estate agent in Wichita KS
トラックバック:best real estate agent in Bonita Springs FL
トラックバック:best real estate agent in Watkinsville GA
トラックバック:real estate agent in Rancho Cucamonga CA
トラックバック:best realtor in Bucks County PA
トラックバック:realtor in Huntersville NC
トラックバック:best real estate agent in Rancho Cucamonga CA
トラックバック:best realtor in Rancho Cucamonga CA
トラックバック:best realtor in Wichita KS
トラックバック:realtor in Westlake Village CA
トラックバック:real estate agent in Watkinsville GA
トラックバック:best realtor in Mashpee MA
トラックバック:best realtor in Fort Lauderdale FL
トラックバック:best real estate agent in Westlake Village CA
トラックバック:real estate agent in Fort Lauderdale FL
トラックバック:real estate agent in Bonita Springs FL
トラックバック:best real estate agent in Mashpee MA
トラックバック:real estate agent in Wentzville MO
トラックバック:real estate agent in Bucks County PA
トラックバック:Seo.ruituoyun.com
トラックバック:real estate agent in Wichita KS
トラックバック:best real estate agent in Bucks County PA
トラックバック:best real estate agent in Fort Lauderdale FL
トラックバック:best realtor in Westlake Village CA
トラックバック:best realtor in Bonita Springs FL
トラックバック:realtor in Bonita Springs FL
トラックバック:http://www.secretsearchenginelabs.com/add-url.php?subtime=1737536796&newurl=https://tangguifang.Dreamhosters.com/comment/html/1120477.html
トラックバック:iu0000ytre
トラックバック:piano technician near me
トラックバック:Вакансии Москва без опыта
トラックバック:real estate agent in Mashpee MA
トラックバック:http://blog-kr.dreamhanks.com/question/conseils-pour-le-nettoyage-de-votre-climatiseur-maintenir-la-fraicheur-en-toute-saison-26/
トラックバック:Altaprodataservices.Com
トラックバック:best realtor in Huntersville NC
トラックバック:Ncrailsites.com
トラックバック:best realtor in Wentzville MO
トラックバック:real estate agent in Huntersville NC
トラックバック:realtor in Mashpee MA
トラックバック:best realtor in Watkinsville GA
トラックバック:realtor in Bucks County PA
トラックバック:realtor in Fort Lauderdale FL
トラックバック:real estate agent in Westlake Village CA
トラックバック:http://impacthiringsolutions.net/__media__/js/netsoltrademark.php?d=gonggamore.combbsboard.phpbo_tablefreewr_id1000356
トラックバック:realtor in Rancho Cucamonga CA
トラックバック:service timbangan digital
トラックバック:realtor in Wichita KS
トラックバック:Judi mbo128 Online
トラックバック:Mip.Chinaz.com
トラックバック:https://domain.glass/Forum.Altaycoins.com
トラックバック:sitnikov
トラックバック:jasa service timbangan
トラックバック:http://acuraauthorizedservicecenter.com/__media__/js/netsoltrademark.php?d=Sm.co.krbbsboard.phpbo_tablefreewr_id725926
トラックバック:https://Domain.glass/amdkorea.co.kr
トラックバック:http://gbm.strugglestreet.com/__media__/js/netsoltrademark.php?d=Sunriji.commoduleboard.phpbo_tablefreewr_id2359034
トラックバック:Ремонт квартир Смоленск
トラックバック:anatoliy-alekseyevich-derkach.ru
トラックバック:More information
トラックバック:fmotl.com
トラックバック:stem cell therapy
トラックバック:wyłączanie adblue
トラックバック:recognition of prior learning application
トラックバック:방콕마사지
トラックバック:usuwanie adblue
トラックバック:forum oddłużeniowe
トラックバック:recognition of prior learning application form
トラックバック:wyprogramowanie adblue
トラックバック:recognition of prior experience
トラックバック:http://Harveytuttle.com/__media__/js/netsoltrademark.php?d=shop.ororo.co.krbbsboard.phpbo_tablefreewr_id905907
トラックバック:https://www.cougcenter.com/users/cleaningservicephuket2
トラックバック:http://anticipatoryinsightworld.com/__media__/js/netsoltrademark.php?d=theterritorian.Com.auindex.phppageuseractionpub_profileid930140
トラックバック:online pharmacy
トラックバック:เงินดิจิตอล
トラックバック:บิทคอยน์
トラックバック:sgp data
トラックバック:News Today
トラックバック:sga77
トラックバック:https://www.So-toulouse.com/spip.php?page=contact&contenu=mentions&page=contact&contenu=mentions&site=http//cupak.sk/index.php&option=com_phocaguestbook&id=1&first&p&page=contact&contenu=mentions&site=http//cupa
トラックバック:pajakbola
トラックバック:1xbet
トラックバック:وقت سفارت شنگن
トラックバック:خرید سمعک
トラックバック:پوشاک سایز بزرگ
トラックバック:forex trading
トラックバック:لباس سایز بزرگ
トラックバック:situs togel
トラックバック:شنوایی سنجی
トラックバック:Gutscheincode
トラックバック:Affordable adult toys
トラックバック:Eco-friendly adult products
トラックバック:trading stocks
トラックバック:Gutschein
トラックバック:กองทุน
トラックバック:esquiar en aragón
トラックバック:Link top1toto
トラックバック:gold
トラックバック:TOP1TOTO
トラックバック:mercado
トラックバック:beb88 login
トラックバック:top1toto login
トラックバック:beb88
トラックバック:WD77
トラックバック:IDNSCORE login
トラックバック:slot gacor terpercaya
トラックバック:41.glawandius.com
トラックバック:hoki4d
トラックバック:JpaNdi.co.kR
トラックバック:provadent sincere review
トラックバック:IDNSCORE
トラックバック:Автосервис Воронеж
トラックバック:canadian pharcharmy
トラックバック:Source URL
トラックバック:Azure Cloud VM
トラックバック:Azure Instance
トラックバック:Soccertv
トラックバック:Azure VM Deployment
トラックバック:tigoals
トラックバック:plumber near me
トラックバック:Azure Cloud Instance
トラックバック:http://Blog-KR.Dreamhanks.com/question/choisir-un-courtier-immobilier-les-criteres-a-considerer-par-une-transaction-reussie-20/
トラックバック:Matefus.ezup.info
トラックバック:Newseasoncommunity.org
トラックバック:http://Zinro.net/m/ad.php?url=http://Blog-kr.dreamhanks.com/question/preteur-personnel-sur-le-canada-comment-trouver-le-bon-preteur-138/
トラックバック:https://Blog-kr.dreamhanks.com/question/centres-de-yoga-sur-le-quebec-decouvrez-la-serenite-et-le-bien-etre-16/
トラックバック:real estate agent in Tampa FL
トラックバック:best realtor in North Haven CT
トラックバック:best real estate agent in Bridgewater MA
トラックバック:best realtor in Douglas County NV
トラックバック:real estate agent in Bridgewater MA
トラックバック:real estate agent in Douglas County NV
トラックバック:best realtor in Holland OH
トラックバック:best realtor in Bridgewater MA
トラックバック:realtor in Tampa FL
トラックバック:http://imatranperhokalastajat.net/index.php/component/kide/-/index.php?option=com_kide
トラックバック:real estate agent in Holland OH
トラックバック:best real estate agent in Holland OH
トラックバック:realtor in North Haven CT
トラックバック:best real estate agent in North Haven CT
トラックバック:realtor in Douglas County NV
トラックバック:real estate agent in North Haven CT
トラックバック:best real estate agent in Tampa FL
トラックバック:Одежда Волгоград
トラックバック:http://egraphicsolutions.com/__media__/js/netsoltrademark.php?d=bookmarkja.comstory20894712physiothC3A9rapie-et-bien-C38Atre-physiobalance
トラックバック:Www.wildleaf.org
トラックバック:realtor in Holland OH
トラックバック:realtor in Bridgewater MA
トラックバック:best real estate agent in Douglas County NV
トラックバック:URL
トラックバック:Услуги Тольятти
トラックバック:Трудоустройство Тюмень
トラックバック:the growth matrix system
トラックバック:p1963500
トラックバック:best realtor in Tampa FL
トラックバック:IT Support Dundee
トラックバック:tool.sufeinet.com
トラックバック:please click Kenpoguy
トラックバック:http://Auldridge.com/__media__/js/netsoltrademark.php?d=Cl-System.jpquestionexterminateur-commercial-au-quebec-guide-complet-31
トラックバック:Новые автомобили Уфа
トラックバック:https://ipv6Test.wcode.net/?q=gogocambo.com/bbs/board.php?bo_table=free&wr_id=953068
トラックバック:Guns and ammo store 2025
トラックバック:Www.Google.cd
トラックバック:Новостройки Ярославль
トラックバック:Forums.eq2wire.com
トラックバック:Купить квартиру Томск
トラックバック:Размещение рекламы Ульяновск
トラックバック:simply click the next internet site
トラックバック:https://Tangguifang.Dreamhosters.com/comment/html/?1152883.html
トラックバック:daftar sekarang
トラックバック:sumup card reader
トラックバック:situs slot mudah menang
トラックバック:box
トラックバック:https://2Whois.ru/?t=dns&data=classifieds.ocala-news.com/author/kalanadeau
トラックバック:shoot survive
トラックバック:slot gacor hari ini gampang menang
トラックバック:2Ip.io
トラックバック:Amlf.org
トラックバック:game pkv
トラックバック:experienced
トラックバック:Zanzibar Tour Packages
トラックバック:Sub-Zero Appliance Repairers Palm Beach
トラックバック:velvet caps
トラックバック:Zanzibar Tours
トラックバック:Haus verkaufen Hameln
トラックバック:Get More Information
トラックバック:Peak Pro Glass
トラックバック:Sub-Zero Freezer Repair Delray Beach
トラックバック:j1 camp counselor
トラックバック:Immobilienbewertung Hameln Online
トラックバック:click site
トラックバック:look at this website
トラックバック:j1 camp counselor programs
トラックバック:Immobilienbewertung Weserbergland
トラックバック:http://hulaser.com/home_kr/bbs/board.php?bo_table=intra_02&wr_id=191685
トラックバック:https://www.master-garz.ru/bitrix/redirect.php?goto=https://blog-kr.dreamhanks.com/question/plafond-tendu-a-beauport-guide-par-choisir-la-meilleure-option-108/
トラックバック:alexistogel
トラックバック:Ipv6Test.Wcode.net
トラックバック:Купить дом Владивосток
トラックバック:Immobilie bewerten Hameln
トラックバック:Wohnung verkaufen Hameln
トラックバック:Immobilienbewertung Hameln
トラックバック:Immobilienmakler Weserbergland
トラックバック:Wohnung bewerten Hameln
トラックバック:SEO TELEGRAM
トラックバック:chair massage Plainfield nj
トラックバック:http://Howardfarber.com/__media__/js/netsoltrademark.php?d=Theterritorian.Com.auindex.phppageuseractionpub_profileid977704
トラックバック:Herpafend Reviews from Users
トラックバック:Одежда Вологда
トラックバック:Azure Compute
トラックバック:Immobilienbüro Hameln
トラックバック:report about sourcing
トラックバック:Insight75.com
トラックバック:vietnam factory tours
トラックバック:Website crypto airdrop
トラックバック:Azure Linux VM
トラックバック:Demopgs.com
トラックバック:Kotonoha32.com
トラックバック:เว็บทาวเข้า 188bet
トラックバック:sell your house fast for cash
トラックバック:Immobilienmakler Hameln
トラックバック:Haus verkaufen Makler
トラックバック:Terramare.ru
トラックバック:real estate agent in Prescott AZ
トラックバック:realtor in Olympia WA
トラックバック:best real estate agent in Olympia WA
トラックバック:best real estate agent in Tempe AZ
トラックバック:real estate agent in Moorestown NJ
トラックバック:best real estate agent in Dallas TX
トラックバック:best realtor in Prescott AZ
トラックバック:realtor in Hingham MA
トラックバック:best realtor in Olympia WA
トラックバック:realtor in Prescott AZ
トラックバック:real estate agent in Dallas TX
トラックバック:dilts.g-u.su
トラックバック:realtor in Tempe AZ
トラックバック:best real estate agent in Prescott AZ
トラックバック:real estate agent in Olympia WA
トラックバック:best real estate agent in Moorestown NJ
トラックバック:p1985758
トラックバック:p1969820
トラックバック:lyadovschool.ru
トラックバック:canada pharmaceuticals online
トラックバック:realtor in Moorestown NJ
トラックバック:real estate agent in Hingham MA
トラックバック:pharmacy online
トラックバック:best real estate agent in Hingham MA
トラックバック:ORDK
トラックバック:forex trading beginner
トラックバック:프리카지노전략
トラックバック:http://www.Momo-tour.com/bbs-m-pc-4aofigjworcp44dk/yybbs.cgi?page=820>Fairviewumc.churchbbsboard.phpbo_tablefreewr_id5167004</a>
トラックバック:best realtor in Dallas TX
トラックバック:http://skillzadda.com/index.php/2025/02/04/how-cryptocurrency-is-revolutionizing-the-financial-panorama/
トラックバック:real estate agent in Tempe AZ
トラックバック:최고의 온라인카지노 프리카지노
トラックバック:best realtor in Hingham MA
トラックバック:how to trade forex Malaysia
トラックバック:Forex trading platform Malaysia
トラックバック:https://theneverendingstory.net/forums/users/melvinagagner/
トラックバック:Visual Studio
トラックバック:https://mychampionssport.jubelio.store/2025/02/04/understanding-the-position-of-smart-contracts-within-the-crypto-space-2/
トラックバック:https://gandhamflora.com/navigating-cryptocurrency-volatility-suggestions-for-new-investors-2/
トラックバック:best realtor in Tempe AZ
トラックバック:boostaro supplements
トラックバック:казино Аврора официальный сайт
トラックバック:best realtor in Moorestown NJ
トラックバック:Aristeia.Org
トラックバック:http://donchalmers.biz/__media__/js/netsoltrademark.php?d=utahsyardsale.comauthorjerrytox833
トラックバック:http://bar-m-beefmasters.com/__media__/js/netsoltrademark.php?d=cl-system.jpquestioncout-dun-echangeur-dair-au-quebec-ce-que-vous-devez-savoir-20
トラックバック:http://whois.webrankstats.com/whois/Bio.rogstecnologia.com.br/elbalowrie74
トラックバック:http://carbon-offsets.eu/__media__/js/netsoltrademark.php?d=Blog-Kr.Dreamhanks.comquestionconduit-de-ventilation-de-5-pouces-guide-complet-31
トラックバック:medicine online shopping
トラックバック:Www.Openadmintools.com
トラックバック:https://check-host.net/ip-info?host=blog-kr.Dreamhanks.comquestiontravail-professionnel-et-de-qualite-en-electricite-votre-securite-dabord-82
トラックバック:Isamarine.com
トラックバック:producer
トラックバック:huanarpo macho powder
トラックバック:turlock electrician
トラックバック:modular storage furniture
トラックバック:sarah pop verhuur
トラックバック:Medical Transport near me
トラックバック:escoramento de laje
トラックバック:Tours in Zanzibar
トラックバック:sell supplements on amazon
トラックバック:Zanzibar Safari Tours
トラックバック:https://casino-champion2.com/
トラックバック:pergola mont-de-marsan
トラックバック:huanarpo macho
トラックバック:opblaas sarah
トラックバック:pergola mont de marsan
トラックバック:long sleeve volleyball jerseys
トラックバック:escora metálica
トラックバック:Zanzibar Tours & excursion
トラックバック:sleeveless girls volleyball jerseys
トラックバック:http://admin.youngsang-tech.com/
トラックバック:atletico madrid survetement
トラックバック:https://newcasinos-usa.com/
トラックバック:http://gashi.de/__media__/js/netsoltrademark.php?d=tangguifang.Dreamhosters.comcommenthtml1161036.html
トラックバック:https://cocoscasino.com/
トラックバック:https://casino-online-ca-win.com/
トラックバック:https://slotswebcasino.com/
トラックバック:https://casino-consulting.org/
トラックバック:https://casinosvr.org/
トラックバック:m.NUevO.ReDeletrAS.coM
トラックバック:Www5A.biglobe.ne.jp
トラックバック:Azure Virtual Machine
トラックバック:https://heovktgame.club/forums/users/teshaesters/
トラックバック:https://candidecoin.com/uncategorized/a-newbies-guide-to-crypto-staking-earning-passive-earnings/
トラックバック:reflective tape
トラックバック:polythene
トラックバック:Futemax
トラックバック:dubai real estate
トラックバック:https://e-plaka.com/what-is-a-crypto-exchange-and-how-do-they-work/
トラックバック:https://autogenie.co.uk/cryptocurrency-wallets-explained-hot-vs-cold-storage-3/
トラックバック:https://diekfzgutachterwestfalen.de/the-right-way-to-choose-the-proper-cryptocurrency-for-investment/
トラックバック:http://teamologies.net/__media__/js/netsoltrademark.php?d=Blog-kr.dreamhanks.comquestionplafond-vinyle-tendu-au-quebec-une-solution-moderne-et-pratique-98
トラックバック:www.ceradesign.us
トラックバック:Unlim cryptocurrencies
トラックバック:http://Moneypowerbook.com/
トラックバック:http://Elderlawsouthcarolina.net/__media__/js/netsoltrademark.php?d=gloveworks.linkbbsboard.phpbo_tablefreewr_id696539
トラックバック:NrS-NdC.InFO
トラックバック:vaping app
トラックバック:Unique Berlin Events GbR – Barcatering mobile Cocktailbar & After Work Party
トラックバック:https://classifieds.ocala-News.com/author/arcblanca82
トラックバック:Creative Nomads LLC
トラックバック:SEO Agentur Vivont Berlin für Google Suchmaschinenoptimierung
トラックバック:web design
トラックバック:Catering4u by Frank Tobben – Ihr Berlin Caterer für Business Catering & Private Events seit 1999
トラックバック:论文代写服务
トラックバック:LinkOutreachExperts
トラックバック:tercera equipacion valencia
トラックバック:Massachusetts substance abuse
トラックバック:bulk dvds
トラックバック:cheap dvds
トラックバック:online socks shop
トラックバック:bulk dvds for sale
トラックバック:https://Cl-System.jp/question/solutions-pour-la-rosacee-a-quebec-traitez-et-apaisez-votre-peau-en-douceur-115/
トラックバック:สล็อตเว็บตรง
トラックバック:diesel generator set
トラックバック:http://couchclick.com/__media__/js/netsoltrademark.php?d=Blog-Kr.Dreamhanks.comquestioncentre-multibeaute-votre-destination-par-une-beaute-complete-12
トラックバック:NOeLPEpYS.coM
トラックバック:https://www.Kasimarket.techandtag.co.za/index.php?page=user&action=pub_profile&id=296522
トラックバック:Naruto.su
トラックバック:roofing company near me
トラックバック:هزینه اجاره ماشین در دبی
トラックバック:محصولات هدی بیوتی
トラックバック:Commercial roofing
トラックバック:Chicagoland roofer
トラックバック:کاشت مو در تهران
トラックバック:Mejor abogado penal Barcelona
トラックバック:gym clothes
トラックバック:memek goreng
トラックバック:máy rửa xe
トラックバック:ide777
トラックバック:Find gaming consoles and accessories
トラックバック:قیمت اجاره ماشین در دبی
トラックバック:dịch vụ seo
トラックバック:AquaSculpt reviews
トラックバック:Residential roofing
トラックバック:Roof Repair
トラックバック:قیمت اجاره خودرو در دبی
トラックバック:https://Cloudadvent.com/indexed?domain=cl-system.jpquestionle-role-central-de-lingenieur-en-batiment-residentiel-53
トラックバック:Buy clone card
トラックバック:best realtor in Atlanta GA
トラックバック:레플리카
トラックバック:명품 레플리카
トラックバック:best real estate agent in Atlanta GA
トラックバック:Slot Gacor 2025
トラックバック:dumpster rental
トラックバック:Cyber Security near me
トラックバック:home remodeling near me
トラックバック:LeptiSense reviews
トラックバック:Nationwide Contracting
トラックバック:The Water Heater Warehouse
トラックバック:orexiburn reviews
トラックバック:ZenCortex reviews
トラックバック:Managed Services nearby
トラックバック:Reese Roofing & Construction
トラックバック:análisis de vibraciones
トラックバック:Barger Roofing
トラックバック:real estate agent in Atlanta GA
トラックバック:hot tub repair near me
トラックバック:Cold Plunge Tub repair
トラックバック:hot tub relocation
トラックバック:jacuzzi tub repair
トラックバック:hot tub service
トラックバック:realtor in Atlanta GA
トラックバック:http://www.Gotanproject.net/node/24826120?——WebKitFormBoundaryNZudcR2CwAkrI9TUContent-Disposition:form-data;name=titleCodelectriqueQubec:LesNormesetRglementationsenMatired’lectricit——WebKitFormBoundaryNZudcR2CwAkrI9TUContent-Disposition:form-data
トラックバック:Dumpster Delivered – Dumpster Rental & Junk Removal
トラックバック:Jeffgood.com
トラックバック:Secretsearchenginelabs.Com
トラックバック:http://Blog-kr.dreamhanks.com/question/taux-de-change-a-la-banque-de-montreal-guide-complet-61/
トラックバック:Fort Worth Roofers
トラックバック:tron address scan
トラックバック:tron suffix
トラックバック:https://unlim-casinodynasty.fun/
トラックバック:visit here
トラックバック:Electric Wheelchair
トラックバック:denver dumpster
トラックバック:ซื้อขายคริปโต
トラックバック:canadian pharmacy
トラックバック:https://cloudadvent.com/indexed?domain=gotanproject.netnode24838464——WebKitFormBoundary3hWUIcKHSBY8g9BsContent-Dispositionform-datanametitleLaMicrodermabrasionQubecUnSoindePeauRajeunissant——WebKitFormBoundary3hWUIcKHSBY8g9BsContent-Dispositionform
トラックバック:https://Dnska.cz/index.php?domain=oke.zoneprofile.phpid348640
トラックバック:슬롯사이트 추천
トラックバック:Residential Architects
トラックバック:Home Grown Cannabis
トラックバック:plr ebooks
トラックバック:modular office furniture
トラックバック:슬롯꽁머니
トラックバック:designer furniture replica
トラックバック:무료슬롯사이트
トラックバック:Commuted value pension
トラックバック:Lump sum vs annuity pension
トラックバック:Azure Virtual Machine Image
トラックバック:Dog harness with name
トラックバック:asianwin88
トラックバック:https://CL-System.jp/question/demenagement-a-brossard-facilitez-votre-transition-vers-votre-nouveau-chez-vous-6/
トラックバック:казино с Азино777
トラックバック:http://blog-kr.dreamhanks.com/question/le-kit-de-nettoyage-de-conduit-de-ventilation-comment-assurer-une-ventilation-saine-49/
トラックバック:http://ebizmeka.com/bbs/board.php?bo_table=free&wr_id=27814
トラックバック:http://Forum.altaycoins.com/profile.php?id=1084427
トラックバック:http://www.fantasticfans4less.net/__media__/js/netsoltrademark.php?d=www.kasimarket.techandtag.co.zaindex.phppageuseractionpub_profileid357194
トラックバック:WWW.Rssing.com
トラックバック:http://campeauoutdoorpowerequipment.net/__media__/js/netsoltrademark.php?d=cl-system.jpquestionbosse-concernant-le-pied-comprendre-les-causes-et-les-solutions-12
トラックバック:https://www.ipsorgu.com/site_ip_adresi_sorgulama.php?site=https://bio.Rogstecnologia.COM.Br/tillyahuiaov
トラックバック:เทรดคริปโต
トラックバック:canadian pharmacies online
トラックバック:canadian online pharmacies
トラックバック:urikukaksa.com
トラックバック:http://Gotanproject.net/node/24825763?——WebKitFormBoundaryerSfc07DLBtzb7YOContent-Disposition:form-data;name=titleThalasso&SpaValdys:DcouvrezNosInstallationsThalasso——WebKitFormBoundaryerSfc07DLBtzb7YOContent-Disposition:form-data;name=bodySpa
トラックバック:online medicine order discount
トラックバック:http://secretsearchenginelabs.com/add-url.php?subtime=1739513794&newurl=http://blog-kr.dreamhanks.com/question/nettoyeur-de-conduits-a-lassomption-pour-un-air-frais-et-sain-66/
トラックバック:http://Ezproxy.Lakeheadu.ca/login?url=http://Www.Gotanproject.net/node/24838875?——WebKitFormBoundaryWkqOJkS4E8DrwZH3Content-Disposition:form-data;name=titlePrtGestionODCauCanada:ToutCeQueVousDevezSavoir——WebKitFormBoundaryWkqOJkS4E8DrwZH3Content-D
トラックバック:computer repair
トラックバック:Best it company
トラックバック:free furniture
トラックバック:Montreal It services
トラックバック:tips for computer use
トラックバック:gutter replacement
トラックバック:waste removal
トラックバック:permit test
トラックバック:reading
トラックバック:Webseite erstellen lassen
トラックバック:How VisiSoothe supports eye wellness
トラックバック:bOXerbRANd.bIz
トラックバック:www.Gotanproject.net official
トラックバック:Nagano Lean Body Tonic herbal formula
トラックバック:flixhq
トラックバック:http://Pakalapati.org/__media__/js/netsoltrademark.php?d=Sun-Clinic.Co.ilhequestiondouleurs-musculaires-fessieres-causes-symptomes-et-traitement
トラックバック:https://Seo.chinaz.com/Seeuplanet.com
トラックバック:herpafend online Store
トラックバック:DentiCore By DentiCore Ltd.
トラックバック:lottochamp software
トラックバック:kSEm.rU
トラックバック:daftar mog777
トラックバック:http://Www.secretsearchenginelabs.com/add-url.php?subtime=1739518953&newurl=https://www.new.jesusaction.org/bbs/board.phpbo_tablefreewr_id5632953
トラックバック:http://nrs-ndc.info/freecgi/EasyBBS/index.cgi?bid=2&popup=1&desc->http://www.xxx_www.itguyclaude.com/wiki/User:AdelaBrooke40
トラックバック:مراحل وقت سفارت شنگن
トラックバック:scatter emas
トラックバック:Kleine advertenties
トラックバック:Www.Fabricationforum.Com
トラックバック:unlim-casinodynasty.wiki
トラックバック:http://Raisethewoof.com/__media__/js/netsoltrademark.php?d=Blog-Kr.Dreamhanks.comquestionservices-en-electricite-commerciale-et-industrielle-lenergie-pour-votre-entreprise-40
トラックバック:Edges.com
トラックバック:https://burf.co/submit.php?url=httpsCl-System.jpquestionacier-et-aluminium
トラックバック:Pickleball Paddles
トラックバック:Bangla Tigers Mississauga
トラックバック:Pickleball Paddle
トラックバック:Browning BLR Lightweight 81 Stainless Takedown .30-06 Springfield Lever-Action Rifle
トラックバック:Taylor’s & Company Alaskan Take-Down .44 Remington Magnum Lever-Action Rifle
トラックバック:Best Pickleball Paddles
トラックバック:Savage Youth Axis 7mm-08 Remington Bolt-Action Rifle
トラックバック:Nonton Movie21
トラックバック:PENIPU ONLINE
トラックバック:Shop Provadent supplement online
トラックバック:TonicGreens by USA-made health product Experts
トラックバック:https://Www.Younganalporn.com/aimc/yrb.cgi?aimc=1&s=65&u=http://Blog-Kr.Dreamhanks.com/question/canon-pixma-ts3420-imprimante-tout-en-un-de-qualite-27/
トラックバック:jetton-laughsquad.makeup
トラックバック:New Retro gaming license
トラックバック:maintain healthy vision with sightcare
トラックバック:kayseri masaj salonu
トラックバック:why choose Nagano tonic For weight Management
トラックバック:P&ID digitization
トラックバック:Dog beds
トラックバック:ubiquiti passpoint
トラックバック:Manchester Originals
トラックバック:how to setup ubiquiti passpoint
トラックバック:unifi radsec
トラックバック:AI voice for meditation
トラックバック:Plombier Mons
トラックバック:how to boost cell signal using ubiquiti
トラックバック:Lankan Premier League
トラックバック:탑플레이어 머니
トラックバック:http://Pitahaya.com/__media__/js/netsoltrademark.php?d=Www.Bkeye.Co.krbbsboard.phpbo_tablefreewr_id1097539
トラックバック:казино с бонусом за регистрацию
トラックバック:Azure Managed VM
トラックバック:Saint Lucia Kings
トラックバック:Rajasthan Royals. Royal Challengers Bangalore
トラックバック:carrier offload on ubiquiti
トラックバック:Chennai Super Kings
トラックバック:annotating P&IDs
トラックバック:First AI-meditation app
トラックバック:http://www.gotanproject.net/node/24882813?——WebKitFormBoundaryeT7CiB9hkWELyNqDContent-Disposition:form-data;name=titleAgenceoptimisationdupagewebWebQubec:LesAvantagesdel’OptimisationparlesMoteursdeRecherche——WebKitFormBoundaryeT7CiB9hkWELyNqDCont
トラックバック:plumbers near me
トラックバック:Www.SO-Toulouse.com
トラックバック:789club
トラックバック:xblx.ru
トラックバック:read this blog post from Www.Gotanproject.net
トラックバック:http://Sawemoffsaloon.com/__media__/js/netsoltrademark.php?d=Boxad.krbbsboard.phpbo_tablefreewr_id198552
トラックバック:r2f.ru
トラックバック:Denticore oral Hygiene probiotics
トラックバック:https://Www.Guidemagazine.org/participant/morganwaddell51/profile/?claim_code=&submit_2=&apbct__email_id__elementor_form_35102=35102&apbct_event_id=35102&membersite=httpsdentisteacuna.comodontologie-esthetique-saint-lambert&membersigna
トラックバック:where to order cheap color copies vs black-and-white online
トラックバック:Lucious Hentai
トラックバック:demo slot gratis
トラックバック:https://trevaskisfarm.co.uk/?URL=http://Forum.Altaycoins.com/profile.php?id=1095239
トラックバック:Daedo.kr
トラックバック:Oke.zone
トラックバック:real estate agent in Greenville SC
トラックバック:best realtor in Greenville SC
トラックバック:Cat beds
トラックバック:best real estate agent in Garden City NY
トラックバック:jt appliance location
トラックバック:best realtor in Garden City NY
トラックバック:best real estate agent in Greenville SC
トラックバック:usmle step 1 exam preparation
トラックバック:real estate agent in Garden City NY
トラックバック:http://cqcici.com/comment/html/?400789.html
トラックバック:best realtor in King George VA
トラックバック:realtor in Greenville SC
トラックバック:hyderabad race club online betting
トラックバック:top usmle prep courses
トラックバック:things to see and do in seattle
トラックバック:things to do in denver when you’re dead movie
トラックバック:Ramique.kr
トラックバック:usmle step 2 ck prep course
トラックバック:Gladiator Plumbing & Repipe San Jose
トラックバック:วิเคราะห์แมตช์
トラックバック:Guidemagazine.Org
トラックバック:realtor in Garden City NY
トラックバック:how Prodentim probiotics Support fresh breath
トラックバック:Prayco Plumbing Heating and Cooling
トラックバック:http://bw-test.org/api.php?action=https://BIO.Rogstecnologia.Com.br/thaomoowatti
トラックバック:먹튀검증커뮤니티
トラックバック:먹튀검증사이트
トラックバック:momsberegner
トラックバック:rentes rente beregner
トラックバック:http://blog-kr.dreamhanks.com/question/echange-dargent-precis-comment-obtenir-les-meilleurs-taux-7/
トラックバック:10 yard
トラックバック:Best Pickleball Paddle
トラックバック:Best Pickleball Bags
トラックバック:http://baileygriffin.com/__media__/js/netsoltrademark.php?d=Daeshintravel.comfree514613
トラックバック:disposing of
トラックバック:beregn terminsdato
トラックバック:beregn månedsløn efter skat
トラックバック:aktie beregner
トラックバック:Pickleball Bag
トラックバック:SEO.Chinaz.com
トラックバック:who will
トラックバック:pick up
トラックバック:Prayco Plumbing Heating and Cooling
トラックバック:Best Pickleball Bag
トラックバック:scrap metal
トラックバック:aldersberegner
トラックバック:Pickleball Bags For Women
トラックバック:løn efter skat beregner
トラックバック:Pickle Ball
トラックバック:cost of
トラックバック:electronic recycling
トラックバック:Dick Does Doors
トラックバック:cheapest dumpster
トラックバック:investeringsberegner
トラックバック:google rank
トラックバック:junk cars
トラックバック:Pickleball Bags
トラックバック:Pickleball
トラックバック:furniture removal
トラックバック:procentberegner
トラックバック:renters rente beregner
トラックバック:small dumpster
トラックバック:trash services
トラックバック:http://www.frag.co.uk/tools/?page=info&host=cl-system.jpquestionimportance-de-la-reparation-des-systemes-electriques-13
トラックバック:vape shop
トラックバック:UP X casino promotions
トラックバック:home.dlybabi.ru
トラックバック:garbage pick
トラックバック:hazardous waste
トラックバック:dumpster service
トラックバック:removal of
トラックバック:equipacion tottenham
トラックバック:waste management
トラックバック:residential trash
トラックバック:how do
トラックバック:junk car
トラックバック:get rid
トラックバック:cash for
トラックバック:mattress recycling
トラックバック:what to
トラックバック:where can
トラックバック:dumpster rentals
トラックバック:hauling services
トラックバック:Injury Lawyer – Mobile Personal Injury & Accident Attorneys
トラックバック:argentina fc jersey
トラックバック:personal-injury-attorney-mobile-al
トラックバック:www.coweyepress.com
トラックバック:Ремонт квартир Ставрополь
トラックバック:http://yk8D.com/hotel/bbs/board.php?bo_table=free&wr_id=373219
トラックバック:www.hogendoornautoschade.nl
トラックバック:https://www.celticsblog.com/users/ESSENTIALS1
トラックバック:Dick Does Doors
トラックバック:439W6fo
トラックバック:http://88Point8.com/__media__/js/netsoltrademark.php?d=Cl-System.jpquestionlavage-dautobus-conseils-pour-un-entretien-optimal-des-vehicules-de-transport-en-commun-3
トラックバック:mog777
トラックバック:41.Torayche.com
トラックバック:https://www.patchwork-quilt-forum.de/out.php?url=http://Blog-kr.dreamhanks.com/question/ventilation-mecanique-controlee-vmc-pour-maison-au-quebec-un-choix-essentiel-pour-la-qualite-de-lair-2/
トラックバック:Джеттон казино официальный сайт
トラックバック:http://Taxwatch360.net/__media__/js/netsoltrademark.php?d=Forum.Altaycoins.comprofile.phpid1099906
トラックバック:игровой клуб Клубника
トラックバック:kraken marketplace
トラックバック:kraken тор браузер
トラックバック:SEO Website Design Service
トラックバック:kraken вход
トラックバック:Small Business Website Design
トラックバック:Brisbane Website Design
トラックバック:kraken kpa29.cc
トラックバック:кракен онион
トラックバック:kra28.at
トラックバック:kraken войти
トラックバック:aurora-diamondcasino.quest
トラックバック:kraken даркнет
トラックバック:Площадка кракен
トラックバック:kraken официальный сайт
トラックバック:Corvette-guru.com
トラックバック:Bricktowntax.com
トラックバック:Stonebriar Roofing
トラックバック:онлайн казино онлим Анлим
トラックバック:JT Roofs
トラックバック:HS Restoration
トラックバック:Brush114.Co.kr
トラックバック:Вулкан Платинум игры с высоким RTP
トラックバック:http://forum.Altaycoins.com/profile.php?id=1113572
トラックバック:Majestic Pest Control – Hicksville Exterminator Service
トラックバック:murale led
トラックバック:http://gotanproject.net/node/24941624?——WebKitFormBoundarygkE09vFrfD9zPyXMContent-Disposition:form-data;name=titleTuyauxdeVentilation:FondamentauxetUtilisations——WebKitFormBoundarygkE09vFrfD9zPyXMContent-Disposition:form-data;name=bodyspanstyle=te
トラックバック:مراحل درخواست وقت سفارت
トラックバック:fence installation
トラックバック:Eldorado fast withdrawals
トラックバック:https://tangguifang.Dreamhosters.com/comment/html/?1239648.html
トラックバック:pharmacie
トラックバック:vodka-dice.beauty
トラックバック:vodka-dice.boats
トラックバック:iNTErnATiOnal-CirCuIts.Biz
トラックバック:Cocktailkurs Berlin am Potsdamer Platz
トラックバック:영통스웨디시
トラックバック:http://blog-kr.dreamhanks.com/question/maison-prefabriquee-au-quebec-une-solution-moderne-et-ecologique-5/
トラックバック:mid century modern tv console
トラックバック:All Day Slimming Tea reviews
トラックバック:игры с реальными призами
トラックバック:Эльдорадо казино официальный сайт зеркало
トラックバック:Эльдорадо рабочее зеркало казино
トラックバック:https://tangguifang.Dreamhosters.com/comment/html/?1242658.html
トラックバック:heybartender.com
トラックバック:Provadent – The Best Probiotic For Gum Health
トラックバック:Neotonics reviews
トラックバック:https://Www.couchsrvnation.com/?URL=httpsblog-kr.dreamhanks.comquestioncompagnie-electrique-st-philippe-providing-excellence-in-electrical-services-37
トラックバック:https://bookmarkshut.com/story19999786/nettoyage-de-conduits-de-ventilation
トラックバック:All-natural Provadent for strong teeth
トラックバック:http://company09.giresvenin.gethompy.Com/bbs/board.php?bo_table=free&wr_id=161561
トラックバック:https://zanderdukz09988.digitollblog.com/33131227/집-분위기를-확-바꿔줄-커튼-설치-전문가처럼-완벽하게
トラックバック:http://Blog-Kr.Dreamhanks.com/question/optimisation-pour-les-moteurs-de-recherche-local-9-suggestions-pour-lameliorer/
トラックバック:simply click Mozillabd
トラックバック:Provadent teeth Strength
トラックバック:나트랑가라오케
トラックバック:HVAC Lead Generation
トラックバック:강남연합
トラックバック:Kauwstaaf voor hond
トラックバック:Kauwsnacks
トラックバック:bali tour packages
トラックバック:HVAC Leads
トラックバック:Range Rover Performance Checks
トラックバック:rpl cert 4
トラックバック:https://www.my-IP-Finder.com/index.php?getvar1=Blog-kr.dreamhanks.comquestiondefinition-et-role-du-creancier-hypothecaire-tout-ce-que-vous-devez-savoir-2&action=dnslookup-domain-name-IP-and-localization&langue=en…
トラックバック:Appliance removal Tucson AZ
トラックバック:RPL
トラックバック:강남유흥
トラックバック:대전 이혼소송 변호사
トラックバック:Kauwstaven voor honden
トラックバック:bali car hire with driver
トラックバック:cert 4 building and construction rpl
トラックバック:Read TonicGreens reviews before You buy
トラックバック:Katamari.rinoa.info
トラックバック:nagano Lean Body tonic discount
トラックバック:https://center.Zerocert.org/safeguard/?site=www.heart-hotel.comcommenthtml102134.html
トラックバック:http://www.nrs-NDC.Info/freecgi/EasyBBS/index.cgi?bid=2&popup=1&desc->,http://www.gz-jj.com/comment/html/386004.html
トラックバック:Lottery Defeater reviews
トラックバック:https://Www.Jahbnet.jp/index.php?url=https://Heealthy.com/question/discovering-cottages-for-sale-in-parry-sound-5/
トラックバック:https://sun-clinic.co.il/he/question/courtier-immobilier-saint-constant-votre-guide-complet/
トラックバック:Cyber Heater reviews
トラックバック:http://whitneyreport.com/__media__/js/netsoltrademark.php?d=Forum.Altaycoins.comprofile.phpid1114791
トラックバック:Borshop.pl
トラックバック:http://Bynet.Com.br/log_envio.asp?cod=335&email=*EMAIL*&url=http://blog-kr.dreamhanks.com/question/services-en-electricite-commerciale-et-industrielle-lenergie-pour-votre-entreprise-46/
トラックバック:ToPNumBEr1.coM
トラックバック:Www.ipsorgu.com
トラックバック:canadian pharmacy online
トラックバック:blue light glasses
トラックバック:Assurance Prêt Immobilier
トラックバック:reading glasses women
トラックバック:Construção de Casas
トラックバック:anti reflective blue light glasses
トラックバック:night vision glasses
トラックバック:top rated women’s sunglasses
トラックバック:https://Rahal.com/go.php?id=28&url=http://Blog-Kr.Dreamhanks.com/question/adiestramiento-pour-chiens-peureux-renforcer-la-confiance-et-reduire-lanxiete-14/
トラックバック:online pharmacies
トラックバック:https://Whois.sijeko.ru/cl-system.jp/question/longueuil-yoga-5/
トラックバック:http://cyber.usask.ca/login?url=https://Cl-System.jp/question/encre-canon-4527-guide-dachat-et-conseils-22/
トラックバック:http://blog-kr.Dreamhanks.com/question/plafond-tendu-blanc-simplicite-et-elegance-209/
トラックバック:BuRstyouRseo.cOM
トラックバック:water damage
トラックバック:Alpha Bites reviews
トラックバック:Dreamzy Humidifier reviews
トラックバック:LeanBiome reviews
トラックバック:Venuesstpetersburg.com
トラックバック:Anak Lonte
トラックバック:water damage
トラックバック:http://blog-kr.Dreamhanks.com/question/la-clinique-de-physiotherapie-a-montreal-nord-votre-partenaire-par-la-sante-et-la-rehabilitation-68/
トラックバック:Skoda-Piter.Ru
トラックバック:Mold Remediation
トラックバック:music.youtube.com
トラックバック:http://How2Youtube.com/g/bbs/board.php?bo_table=free&wr_id=1995643
トラックバック:Categorify.org
トラックバック:http://Www.gotanproject.net/node/24968319?——WebKitFormBoundarytoWBwuxOwYzRk3CzContent-Disposition:form-data;name=titleBlanchimentDentaire:claircissezVotreSouriredansConfiance——WebKitFormBoundarytoWBwuxOwYzRk3CzContent-Disposition:form-data;name=bo
トラックバック:Residential Pressure Washing
トラックバック:Wbgrp-Svc104.Us.Archive.org
トラックバック:Commercial Power Washing Company
トラックバック:http://Copyvance.com/gnuboard5/bbs/board.php?bo_table=free&wr_id=83590
トラックバック:online medicine tablets shopping
トラックバック:pharmacy uk
トラックバック:Personal Injury Lawyers
トラックバック:https://samigo.co.id/
トラックバック:http://Chemindeferjeans.net/__media__/js/netsoltrademark.php?d=pasarinko.zeroweb.krbbsboard.phpbo_tablenoticewr_id4736467
トラックバック:Cheap Proxies
トラックバック:Proxies usa
トラックバック:Клубника быстрые выплаты
トラックバック:Private Internet Access Http Proxy
トラックバック:Proxy Servers
トラックバック:dreamproxies.com
トラックバック:Buy 100 Proxies
トラックバック:WWw.KinOFilMPROgRAmM.de
トラックバック:https://www.youtube.com/watch?v=ZSC9Nr_9LKo
トラックバック:https://dreamproxies.com/buy-proxies/200-private-proxies/
トラックバック:proplay88
トラックバック:sex ấu âm
トラックバック:edisi
トラックバック:SEO Backlinks Discount
トラックバック:Cheap color printing for community events
トラックバック:Discount color copies printing for retail promotions
トラックバック:Cheap color copies printing for team handouts
トラックバック:Inexpensive color printing for sales sheets
トラックバック:Cheap color copies printing for menus
トラックバック:Low-price color copies printing for posters
トラックバック:Affordable color copies printing for classroom materials
トラックバック:robot forex
トラックバック:forex tipo de cambio
トラックバック:my forex funds
トラックバック:nagacor181
トラックバック:app for forex trading
トラックバック:Youtube Proxy
トラックバック:Sonoma county flat fee real estate brokerage
トラックバック:clinical trial data management
トラックバック:brokers in forex
トラックバック:melayutudung.xyz
トラックバック:forex dolar peso
トラックバック:Business laundry solutions Phoenix
トラックバック:TOTAL Diversity
トラックバック:sugar md
トラックバック:vps forex
トラックバック:forex robots
トラックバック:Hotel laundry service Phoenix
トラックバック:Crypto Gaming
トラックバック:Forum SEO Backlinks
トラックバック:URL
トラックバック:forex directory mexican peso
トラックバック:que es el spread en forex
トラックバック:super gra
トラックバック:forex factory
トラックバック:Crypto Gambling
トラックバック:you can try this out
トラックバック:Token Presale
トラックバック:Automated Trading Bot
トラックバック:forex calculator
トラックバック:que es el swap en forex
トラックバック:signals forex
トラックバック:forex mxn usd
トラックバック:Sitecheck.Sucuri.Net
トラックバック:Buy 5000 Private Proxies
トラックバック:Tutor English
トラックバック:situs haram tukang phising
トラックバック:best Car locksmiths in luton
トラックバック:click here for more
トラックバック:meiyingge8.com
トラックバック:https://pediascape.science
トラックバック:Shenasname.ir
トラックバック:best auto locksmiths luton
トラックバック:Car Locksmith Luton
トラックバック:car locksmiths In luton
トラックバック:read more on 2ip`s official blog
トラックバック:best luton auto locksmith
トラックバック:Best Auto Locksmiths Near Luton
トラックバック:Luton Car locksmith
トラックバック:https://qa.holoo.co.ir/user/blockbeech4
トラックバック:Luton car Locksmiths
トラックバック:auto
トラックバック:best auto locksmith in luton
トラックバック:repairs
トラックバック:Auto locksmith near luton
トラックバック:navigate to this web-site
トラックバック:best car Locksmiths luton
トラックバック:Car Locksmith In Luton
トラックバック:Https://Historydb.Date/Wiki/Why_Car_Locksmith_Luton_Is_More_Tougher_Than_You_Think
トラックバック:Luton Auto Locksmith
トラックバック:https://justice-norwood.thoughtlanes.net/
トラックバック:car locksmiths Near luton
トラックバック:visit the up coming internet page
トラックバック:mendoza-ladegaard.Technetbloggers.de
トラックバック:Luton Auto Locksmiths
トラックバック:Www.demilked.com
トラックバック:Live Draw Hongkong Lotto
トラックバック:nonton bokep viral terbaru
トラックバック:go directly to Fuwafuwa
トラックバック:La Importancia de Probar el Sofá Antes de Comprar – Chusmeando: Descubriendo cosas que quizás no sabías
トラックバック:Psicolinguistica.letras.ufmg.br
トラックバック:near
トラックバック:auto Locksmith in Luton
トラックバック:Best Backlinks Packages
トラックバック:auto Locksmiths in luton
トラックバック:Doodleordie.com
トラックバック:youok168
トラックバック:lavabet1688
トラックバック:Dancemusic
トラックバック:infinity games nettuno
トラックバック:scam assessment writing agency
トラックバック:Вулкан Платинум мобильная версия
トラックバック:online medicine shopping
トラックバック:Visit
トラックバック:inter milan away kit
トラックバック:Buy 10000 Proxies
トラックバック:Main profile
トラックバック:http://icfsecuresurvey2.com/__media__/js/netsoltrademark.php?d=tangguifang.Dreamhosters.comcommenthtml1249999.html
トラックバック:Free Private Proxies
トラックバック:Buy DoFollow Backlinks
トラックバック:wood classic furniture
トラックバック:contract research organization
トラックバック:TOTAL Diversity clinical trial mgmt
トラックバック:Surprise affordable laundry pickup
トラックバック:Laundry service with 24-hour turnaround
トラックバック:Gilbert laundry services near me
トラックバック:clinical research management
トラックバック:Mesa professional laundry service
トラックバック:salt trick for men
トラックバック:Medical laundry service Phoenix
トラックバック:clinical trial diversity fda
トラックバック:Nagano tonic Ingredients and benefits
トラックバック:Same day laundry service Phoenix
トラックバック:clinical trial management
トラックバック:Laundry services in Glendale
トラックバック:TOTAL Diversity Clinical Trial Management
トラックバック:climatecult.Com
トラックバック:http://Blog-kr.dreamhanks.com/question/changement-de-pneus-a-laval-tout-ce-que-vous-devez-savoir-140/
トラックバック:Buy Cheap Proxies
トラックバック:Laundry pickup and delivery near me
トラックバック:Uniform laundry service Phoenix
トラックバック:TOTAL Diversity CRO
トラックバック:Short-term rental laundry service Phoenix
トラックバック:bokep viral indo terbaru
トラックバック:Healthcare laundry services Phoenix
トラックバック:jangan asik makan brand webku la kontol
トラックバック:BAPAKKAU DIPERKOSA KUCING
トラックバック:https://Yu-gi-ou-daisuki.com/
トラックバック:http://WWW.Gz-Jj.com/comment/html/?417596.html
トラックバック:http://www.avian-Flu.org/
トラックバック:Bbs.Fileclip.cloud
トラックバック:Lotto Champ reviews
トラックバック:Sun-Clinic.CO.Il
トラックバック:safir777
トラックバック:test ya jang
トラックバック:equipacion de alemania
トラックバック:Best Auto Locksmiths In Luton
トラックバック:car Locksmiths luton
トラックバック:locksmiths
トラックバック:Https://Dahlgaard-Dale.Technetbloggers.De/20-Up-And-Comers-To-Watch-In-The-Best-Auto-Locksmith-Luton-Industry/
トラックバック:best luton car locksmiths
トラックバック:best auto locksmith near luton
トラックバック:linked internet site
トラックバック:Eldorado bonus codes
トラックバック:key
トラックバック:get more info
トラックバック:1v34.com
トラックバック:https://sciencewiki.science/wiki/auto_locksmiths_Luton_tips_from_the_top_in_the_industry
トラックバック:delphi.larsbo.org
トラックバック:Best Car Locksmith Near Luton
トラックバック:wx.abcvote.cn
トラックバック:auto locksmiths near luton
トラックバック:Tucker-Timmons-3.Technetbloggers.De
トラックバック:how you can help
トラックバック:camiseta roma
トラックバック:https://cl-system.jp/question/microblading-quebec-53/
トラックバック:https://www.metooo.com/u/677e6ff652a62011e873d216
トラックバック:Best Car locksmith in Luton
トラックバック:Read the Full Content
トラックバック:near By
トラックバック:best Luton car locksmith
トラックバック:see this website
トラックバック:auto locksmith luton
トラックバック:car Locksmith near luton
トラックバック:brazil jersey black
トラックバック:you can check here
トラックバック:https://Www.Kenpoguy.com/phasickombatives/profile.php?id=2489033
トラックバック:standby generator maintenance near me
トラックバック:монтаж систем вентиляции и кондиционирования
トラックバック:Monthly SEO Backlinks
トラックバック:Home Remodeling Services in Mesa
トラックバック:Buy Web 2.0 Backlinks
トラックバック:general contractor services
トラックバック:KONTOL BAPAKKAU PECAH
トラックバック:fisher capital
トラックバック:official site
トラックバック:DentiCore supplement For strong teeth
トラックバック:Bill Eiland
トラックバック:architecture contractors
トラックバック:Domain Authority DA 50 Backlinks
トラックバック:BAPAK KAU GIGOLO
トラックバック:https://betterespressomachinesreviews.com/
トラックバック:Holistic dental wellness Supplement for all ages
トラックバック:http://blog-Kr.dreamhanks.com/question/le-podiatre-sportif-un-allie-essentiel-pour-les-athletes-18/
トラックバック:Prime Restoration
トラックバック:r b leipzig kit
トラックバック:PrimeBiome reviews
トラックバック:energipolitik nyheter
トラックバック:ikoma.co.id
トラックバック:تعمیرات تخصصی مک بوک
トラックバック:fast lean Pro official
トラックバック:blog
トラックバック:Buy Fitspresso
トラックバック:bokep viral terbaru
トラックバック:مکمل بنزین
トラックバック:Source of information
トラックバック:bayern munich away jersey
トラックバック:yakima roofing companies
トラックバック:Buy DA 30 Backlinks
トラックバック:بهترین مکمل سوخت
トラックバック:survette juventus
トラックバック:Faircareers.com
トラックバック:https://Seo.ruituoyun.com/title?site=blog-kr.Dreamhanks.comquestionsous-traitant-en-construction-sur-le-quebec-tout-ce-que-vous-devez-savoir-97
トラックバック:1superfood.net
トラックバック:http://www.yansite.net/osaka2.cgi?URL=http://Sl860.com/comment/html/?105348.html
トラックバック:wrongful death attorney mobile al
トラックバック:segunda equipacion atletico de madrid 2024
トラックバック:SEO Backlinks
トラックバック:facial beauty salon near me
トラックバック:Wiki Backlinks
トラックバック:indonesia bokep viral terbaru
トラックバック:best car locksmith luton
トラックバック:find out here
トラックバック:just click the next webpage
トラックバック:equipacion roma
トラックバック:42.glawandius.com
トラックバック:https://delamaster.ru/
トラックバック:institutional crypto
トラックバック:slot deposit 1000
トラックバック:Эльдорадо
トラックバック:비아그라 구입
トラックバック:Www.independentbank.com
トラックバック:川崎 フロンターレ ユニフォーム
トラックバック:казино с живыми дилерами
トラックバック:http://wildleaf.org/bbs/lounge.cgi?page=80">http://Blog-Kr.Dreamhanks.com/question/restaurants-peruviens-a-montreal-une-evasion-culinaire-49/
トラックバック:http://Riverbridge.biz/__media__/js/netsoltrademark.php?d=blog-kr.dreamhanks.comquestioneclairage-par-plafond-tendu-au-quebec-sublimez-votre-interieur-65
トラックバック:http://Streamvex.com/__media__/js/netsoltrademark.php?d=cl-system.jpquestionexterminateur-en-outaouais-services-et-conseils-pour-eliminer-les-nuisibles-39
トラックバック:https://copuszn.ru/bitrix/rk.php?id=25&event1=banner&event2=click&event3=1 / [25] [PARTNERS] íåò êîððóïöèè&goto=http://Oke.zone/profile.php?id=447695
トラックバック:Water damage restoration service nearby
トラックバック:Visit Youtube
トラックバック:تعمیرات مک بوک
トラックバック:bokep viral tiktok
トラックバック:login emakbet
トラックバック:liverpool tracksuit for sale
トラックバック:wolves fc new jersey
トラックバック:research by the staff of Ufmg
トラックバック:lev-multiplayer.monster
トラックバック:Highly recommended Resource site
トラックバック:Water damage restoration St Cloud FL
トラックバック:MAMAKMU TUKANG NGANGKANG
トラックバック:fatahal.com`s statement on its official blog
トラックバック:canada pharmacies
トラックバック:https://Tangguifang.Dreamhosters.com/comment/html/?1271875.html
トラックバック:12Animals.com
トラックバック:주소링크
トラックバック:please click the up coming article
トラックバック:https://Ceshi.xyhero.com/home.php?mod=space&uid=2542552
トラックバック:auto locksmiths luton
トラックバック:주솜ㅎ음
トラックバック:go directly to Shenasname
トラックバック:use qooh.me
トラックバック:시알리스 구매
トラックバック:buy sumatra Slim belly tonic supplement online
トラックバック:최신주소모음
トラックバック:http://db.studyincanada.ca/forwarder.php?f=https://Www.Kenpoguy.com/phasickombatives/profile.php?id=2491992
トラックバック:주소링크모음
トラックバック:사이트 주소 모음
トラックバック:mouse click the next internet page
トラックバック:Fobs
トラックバック:http://www.1moli.top
トラックバック:remote
トラックバック:http://www.hondacityclub.com/all_new/home.php?mod=space&uid=2186300
トラックバック:https://opensourcebridge.science
トラックバック:motor
トラックバック:browse around this site
トラックバック:bjerg-laursen-2.technetbloggers.de explained in a blog post
トラックバック:kingranks.com
トラックバック:Https://Gm6699.Com/Home.Php?Mod=Space&Uid=4062212
トラックバック:http://lzdsxxb.com
トラックバック:car accident lawyer
トラックバック:Archer-Klit.Federatedjournals.Com
トラックバック:check out this one from Ufmg
トラックバック:https://hikvisiondb.webcam/wiki/Will_Car_Locksmiths_Luton_Never_Rule_The_World
トラックバック:maillot exterieur arsenal 2025
トラックバック:fakenews.Win
トラックバック:주소 모음
トラックバック:주소모음 사이트
トラックバック:링크 모음
トラックバック:visit web site
トラックバック:please click the next internet page
トラックバック:napier-morales.federatedjournals.com
トラックバック:주소모은
トラックバック:Https://Forum.Igrarena.Ru/
トラックバック:لوازم یدکی خودرو
トラックバック:Wiki Profile Backlinks
トラックバック:주서모음
トラックバック:local general contractor
トラックバック:squareblogs.net wrote in a blog post
トラックバック:https://jusomo-Eum46751.wikipresses.com/
トラックバック:링크모음 주소모음
トラックバック:사이트주소모음
トラックバック:주소모음사이트
トラックバック:주소모음집
トラックバック:링크모음 링크 주소
トラックバック:click
トラックバック:Santacoach9.bravejournal.net
トラックバック:주소주라
トラックバック:링크모음
トラックバック:https://king-wifi.win/wiki/Are_You_Responsible_For_An_Link_Collection_Site_Budget_10_Terrible_Ways_To_Spend_Your_Money
トラックバック:bathroom remodeling nearby
トラックバック:https://gratisafhalen.be/author/cicadaslash7
トラックバック:visit my web site
トラックバック:최신링크모음
トラックバック:check out this blog post via nativ.media
トラックバック:apparel.ru
トラックバック:주소머음
トラックバック:주소모음
トラックバック:King-Wifi.Win
トラックバック:jszst.com.cn
トラックバック:주소모름
トラックバック:Ucgp.Jujuy.Edu.Ar
トラックバック:사이트 모음
トラックバック:Link Home Page
トラックバック:Plumbing
トラックバック:쥬소모음
トラックバック:Valetinowiki.Racing
トラックバック:SEO NAGATOP PENGENTOT HANDAL
トラックバック:주고모음
トラックバック:www.Diggerslist.com
トラックバック:morphomics.science
トラックバック:https://squareblogs.Net/
トラックバック:링크모음사이트
トラックバック:https://redfivehockey.Com
トラックバック:to Tatsujin
トラックバック:www.metooo.es
トラックバック:click the up coming document
トラックバック:Proxies For Youtube
トラックバック:https://Cameradb.review
トラックバック:lingkeumo-eumsaiteu57951.blogzet.com
トラックバック:wikimapia.Org
トラックバック:Daoqiao.Net
トラックバック:Www.028Bbs.Com
トラックバック:주소몽.ㅁ
トラックバック:SKANDAL BOKEP JILBAB JEPANG
トラックバック:truffe fraîche
トラックバック:http://ww17.freenepalimusic.com/__media__/js/netsoltrademark.php?d=Thebestgamesites.awardspace.infoindex.phpastatsuvickyturman6686
トラックバック:Social Networks Backlinks
トラックバック:MAMAK KAU LONTE
トラックバック:TUKANG SOBUR KAU LONTE
トラックバック:http://katamari.Rinoa.Info/bbs/index.cgi?command=read_message&CL-System.jp/question/exercices-de-reeducation-apres-un-accident-de-la-saaq-regagner-votre-mobilite-4/&v=376&details=697
トラックバック:taxi gardermoen oslo pris natt
トラックバック:казино Аврора онлайн
トラックバック:ipen.com.hk blog article
トラックバック:Https://Basket-Online.Ru/
トラックバック:Unlim доступ к играм
トラックバック:Forum.hardwarebase.net
トラックバック:https://clifford-russell-2.blogbright.net/15-gifts-for-the-address-collection-site-lover-in-your-life-1731538196
トラックバック:TUKANG SODOK PANTAT
トラックバック:Lingkeumo-Eum00215.blogadvize.com
トラックバック:Gitlab.Dstsoft.Net
トラックバック:https://www.metooo.co.uk/U/673559bc1759956fda5fd9ee
トラックバック:Fewpal.com
トラックバック:https://able2know.org
トラックバック:old.Dis.ru
トラックバック:https://levclub-play.site
トラックバック:https://nativ.media:443/wiki/index.php?cellarpaper855
トラックバック:사이트모음
トラックバック:www.metooo.com
トラックバック:주소모움
トラックバック:Blogfreely.net
トラックバック:metooo.Io
トラックバック:Https://Www.Metooo.It
トラックバック:Read Homepage
トラックバック:http://Gotanproject.net/node/25000699?——WebKitFormBoundaryh5oQ8cPfWUEKvvFzContent-Disposition:form-data;name=titleLaThrapiedeCoupleSaint-Aubert:Rtablirl’HarmonieetlaComplicit——WebKitFormBoundaryh5oQ8cPfWUEKvvFzContent-Disposition:form-data;name=b
トラックバック:בלאק קיוב
トラックバック:www.vrwant.org
トラックバック:Read the Full Guide
トラックバック:these details
トラックバック:کشمش تاکستان
トラックバック:Https://Www.metooo.es
トラックバック:http://professor-murmann.info
トラックバック:Https://Mapswitch95.Bravejournal.Net/This-Is-The-One-Link-Collection-Trick-Every-Person-Should-Know
トラックバック:Download pirated software here
トラックバック:즈소모음
トラックバック:resources
トラックバック:gm6699.Com
トラックバック:by 187.216.152.151
トラックバック:from the Pdc blog
トラックバック:bbs.Pku.edu.Cn
トラックバック:recommended you read
トラックバック:lingkeumo-eumsaiteu23284.blogdal.com
トラックバック:Aurora casino
トラックバック:mackay-carver-2.Technetbloggers.de
トラックバック:https://servergit.itb.edu.ec/
トラックバック:www.metooo.it
トラックバック:qooh.Me
トラックバック:DeFi investment strategies
トラックバック:http://cleanrefill.com/__media__/js/netsoltrademark.php?d=cl-System.jpquestionchaise-emsella-redecouvrez-la-force-de-votre-perinee-141
トラックバック:http://interiordoorsbyaww.com/__media__/js/netsoltrademark.php?d=ramique.krbbsboard.phpbo_tablefreewr_id642478
トラックバック:Аврора регистрация без депозита
トラックバック:helpful site
トラックバック:https://king-wifi.win/Wiki/Acevedohackett6991
トラックバック:Humanlove.Stream
トラックバック:tHETERritorIan.Com.Au
トラックバック:http://diendanthammyvien.info/proxy.php?link=https://주소주라.com
トラックバック:Reduce eye Strain with Sightcare formula
トラックバック:Irwin login
トラックバック:Squareblogs.net
トラックバック:psychanalyste
トラックバック:irwin казино
トラックバック:Irwin mobile casino
トラックバック:vuf.minagricultura.Gov.co
トラックバック:jusojula25341.Bloggerchest.com
トラックバック:https://king-wifi.win/
トラックバック:Backlinks
トラックバック:linked resource site
トラックバック:https://mosley-Vang-3.blogbright.net
トラックバック:Www.Bitsdujour.Com
トラックバック:Http://www.Kaseisyoji.Com
トラックバック:see this site
トラックバック:related internet page
トラックバック:in the know
トラックバック:taxi near me
トラックバック:visit Zhzmsp`s official website
トラックバック:head to Chessdatabase
トラックバック:Джет тон
トラックバック:http://ezproxy.cityu.edu.hk/
トラックバック:read this post from Maanation
トラックバック:Вулкан Платинум игра с выводом
トラックバック:https://Velasat.ru/
トラックバック:www.myavcs.com wrote
トラックバック:Irwin
トラックバック:yogicentral.Science
トラックバック:click the next web site
トラックバック:writes in the official Timeoftheworld blog
トラックバック:http://Eastriverrealty.com/__media__/js/netsoltrademark.php?d=Blog-kr.dreamhanks.comquestionprogramme-aph-select-dune-schl-enrichissement-etudiant-a-travers-les-echanges-internationaux-49
トラックバック:https://wifidb.science/wiki/14_Questions_You_Might_Be_Insecure_To_Ask_About_Address_Collection
トラックバック:https://valetinowiki.racing/wiki/Heres_A_Few_Facts_About_Address_Collection_Address_Collection
トラックバック:kuniunet.Com
トラックバック:Https://fewpal.Com
トラックバック:Eldorado mobile casinos
トラックバック:Window Replacement near me
トラックバック:www.bioguiden.Se
トラックバック:Rentry.Co
トラックバック:Best car locksmiths near luton
トラックバック:Http://Bbs.Wuhudj.Com/Space-Uid-1024550.Html
トラックバック:4 Seater brown leather sofa
トラックバック:link web site
トラックバック:bird african grey For sale
トラックバック:cheap sofas For sale
トラックバック:grey african parrot
トラックバック:Cos.Mbav.Net
トラックバック:https://articlescad.com/ask-me-anything-10-answers-to-your-Questions-about-Symptoms-of-depression-men-921627.html
トラックバック:Visit Bioimagingcore
トラックバック:Führerschein Kaufen deutschland
トラックバック:adhd Titration waiting List
トラックバック:How Much Fabric For 2 Seater Sofa
トラックバック:browse around these guys
トラックバック:adhd assessment for adults london
トラックバック:matkafasi.com
トラックバック:situs alternatif gotogel
トラックバック:Posteezy.Com
トラックバック:Tips Togel
トラックバック:Online shop tools
トラックバック:autoportal.lv
トラックバック:xmdd188.com
トラックバック:anxiety early pregnancy symptom
トラックバック:yogaasanas.science
トラックバック:Recommended Studying
トラックバック:führerschein klasse a2 digital Erwerben
トラックバック:FüHrerschein International
トラックバック:Zhzmsp published an article
トラックバック:Tfd write an article
トラックバック:leather couch with Chaise and recliner
トラックバック:comprar carta de condução categoria b
トラックバック:köPa våRt C-körkort Göteborg
トラックバック:Alex The african grey Parrot
トラックバック:Comprar carta de condução da categoria C
トラックバック:private adhd assessment Bristol
トラックバック:Comprar a carta de conduçãO do IMT
トラックバック:Comprar Carta De ConduçãO Da Categoria A
トラックバック:falschgeld kaufen Paypal
トラックバック:Running pushchair
トラックバック:Intensedebate.com
トラックバック:gotogel
トラックバック:Führerschein kaufen
トラックバック:galbraith-butler.thoughtlanes.net
トラックバック:situs Gotogel Terpercaya
トラックバック:childrens bunk beds with steps
トラックバック:führerschein kosten
トラックバック:schäferhund Baby kaufen
トラックバック:Best double strollers
トラックバック:Fish.boy.jp
トラックバック:Case battle
トラックバック:köpa Körkort Online
トラックバック:fold in Treadmill
トラックバック:from the Ufmg blog
トラックバック:Cs2 case battles
トラックバック:Buy real uk driving license
トラックバック:space
トラックバック:motorradführerschein A2 Online erwerben
トラックバック:comprar carta de condução da Categoria b1
トラックバック:Anxiety Disorders Questionnaire
トラックバック:köPa Körkort
トラックバック:Situs gotogel
トラックバック:futon For Sale
トラックバック:registrierten FüHrerschein kaufen ohne anzahlung
トラックバック:Http://Shtormtruck.Ru/
トラックバック:Cheap Couches For sale Under $200
トラックバック:Http://Www.Haidong365.Com/Home.Php?Mod=Space&Uid=424440
トラックバック:chessdatabase.science
トラックバック:Can I buy a drivers license online
トラックバック:프라그마틱 무료
トラックバック:schäFerhund Welpe kaufen
トラックバック:tufted leather Sofa
トラックバック:Www.Airsoftmarkt.Nl
トラックバック:Prediksi Togel
トラックバック:GefäLschte Dokumente Kaufen
トラックバック:click through the next web site
トラックバック:blake soft texture fabric Corner sofa
トラックバック:pattern-wiki.win
トラックバック:Buckingham gas engineers
トラックバック:Folding Treadmills with incline
トラックバック:my sources
トラックバック:Best Auto Locksmiths Bedford
トラックバック:ghost immobiliser And tracker
トラックバック:https://blog.aaafrog.com/iframe/hatena_bookmark_comment?canonical_uri=https://www.powertoolsonline.uk/
トラックバック:schäFerhundwelpen kaufen
トラックバック:FüHrerschein Klasse A2 Digital Shop
トラックバック:tongcheng.Jingjincloud.Cn
トラックバック:https://www.google.co.vi/url?q=https://telegra.ph/20-up-and-coming-treadmills-for-sale-uk-stars-to-watch-the-treadmills-for-sale-Uk-Industry-03-02
トラックバック:Www.Google.Co.Zm
トラックバック:adhd adult women diagnosis
トラックバック:uka-vrn.ru
トラックバック:commercial gas engineer Near me
トラックバック:Robotic Floor Vacuums
トラックバック:Check Out mymobilityscooters05830.wikibyby.com
トラックバック:https://xxh5gamebbs.uwan.com
トラックバック:window repairs
トラックバック:Learn Additional Here
トラックバック:catering and hospitality containers
トラックバック:https://hedgepunch4.bravejournal.net/the-reasons-you-Should-experience-skoda-replacement-key-at-least-once-in-your
トラックバック:automatic Cleaning Robot
トラックバック:Leather corner sofa sale
トラックバック:Mercedes Ignition Key Replacement
トラックバック:Blaue SchäFerhunde
トラックバック:white leather 4 seater sofa
トラックバック:https://lynge-dupont.federatedjournals.com
トラックバック:프라그마틱 순위
トラックバック:Car replacement keys Near me
トラックバック:Upvc window repairs near me
トラックバック:uk private Adhd assessment
トラックバック:Private psychiatric assessment Near me
トラックバック:프라그마틱 슬롯체험
トラックバック:3 wheel Pushchair with car seat
トラックバック:https://Larsson-english.hubstack.Net/
トラックバック:linked web page
トラックバック:Fsquan8.cn
トラックバック:exercise bike Home
トラックバック:Childrens Bunk Beds With Stairs
トラックバック:https://parcelkayak56.werite.net/
トラックバック:deutschen registrierten Führerschein Kaufen
トラックバック:Couches sale
トラックバック:mines Gamble
トラックバック:Glax.Org
トラックバック:checklist for Mental health assessment
トラックバック:buy legit uk driving license
トラックバック:linkvault.win
トラックバック:upvc Window near me
トラックバック:https://images.google.bg/
トラックバック:Shipping container Tunnel
トラックバック:http://xmdd188.com/
トラックバック:https://www.metooo.co.uk/u/6785a3e34a0256118e292665
トラックバック:the advantage
トラックバック:ai-db.science
トラックバック:home exercise bikes
トラックバック:new post from Technetbloggers
トラックバック:containers For sale Middlesbrough
トラックバック:gissel-Morris.thoughtlanes.net
トラックバック:Https://Idp.Gewiss.Com
トラックバック:https://Git.aiadmin.cc/charmingafricangreyparrotforsale3731
トラックバック:uk Driving license Info
トラックバック:Bathpoint.Ru
トラックバック:Power Tool Store
トラックバック:KöRkort Betyg
トラックバック:Führerschein kaufen erfahrung
トラックバック:adhd treatment for adults
トラックバック:faux Leather recliner
トラックバック:gefälschte banknoten kaufen
トラックバック:Car key replacement Online
トラックバック:try this website
トラックバック:click through the next site
トラックバック:Private ADHD assessment Brighton cost
トラックバック:Vegan leather Sofa
トラックバック:Audi keys replacement cost
トラックバック:Psychiatrist consultation near me
トラックバック:Shibuyacrossfm.Jp
トラックバック:b1 prawo jazdy
トラックバック:füHrerschein Kaufen österreich
トラックバック:private Adult adhd assessment scotland
トラックバック:www.metooo.co.uk
トラックバック:easy
トラックバック:www.bos7.cc
トラックバック:replacement key for car cost
トラックバック:Refridgerators Uk
トラックバック:www.scdmtj.com
トラックバック:Kup Prawo Jazdy
トラックバック:buy a german shepherd
トラックバック:linked here
トラックバック:kupie prawo Jazdy
トラックバック:https://infopagex.com
トラックバック:Https://Www.Bitsdujour.Com
トラックバック:Buy A1 And A2 Motocycle Licence Online
トラックバック:robotic Vacuum cleaner On sale
トラックバック:eric1819.com
トラックバック:sites
トラックバック:rolls royce smart key
トラックバック:buy Driving Licence uk
トラックバック:wine Rack And fridge
トラックバック:Kids beds bunk
トラックバック:Self propelled bariatric wheelchair
トラックバック:Private Psychiatric Assessment
トラックバック:web
トラックバック:Sofa sale
トラックバック:Outdoor Sofa Sale
トラックバック:home appliances
トラックバック:Buy Genuine Driving Licence Uk
トラックバック:lightweight Single stroller
トラックバック:FüHrerschein Kaufen Erfahrungen
トラックバック:SchäFerhund Kaufen öSterreich
トラックバック:kaufen sie Einen echten registrierten führerschein
トラックバック:FranzöSische Bulldogge Welpen Kaufen
トラックバック:프라그마틱 무료슬롯
トラックバック:home healthcare equipment
トラックバック:www.Cheaperseeker.com
トラックバック:self-cleaning robot Vacuums
トラックバック:ghost 2 Immobiliser cost
トラックバック:www.google.com.pk
トラックバック:Buy C1 E License Online
トラックバック:franz bulldogge kaufen
トラックバック:cordless power tool sets on sale
トラックバック:coping with adhd without medication
トラックバック:Buy Uk Driving Licence Online
トラックバック:Broken Key Repair Near Me
トラックバック:Exercise bikes home
トラックバック:köpa Svenskt körkort
トラックバック:power tool
トラックバック:www.1Moli.top
トラックバック:african grey birds for sale
トラックバック:https://scientific-programs.science/wiki/20_Quotes_Of_Wisdom_About_Car_Locksmith_Near_Luton
トラックバック:Calm-Heron-Hbr988.Mystrikingly.Com
トラックバック:best fold away treadmill
トラックバック:www.taxiu.vip
トラックバック:leather Sofa
トラックバック:Replacement car key
トラックバック:Repair
トラックバック:tools Online
トラックバック:fahrerlaubnis A2 online bestellen
トラックバック:Q.044300.net
トラックバック:lt.dananxun.cn
トラックバック:Https://heavenarticle.Com/author/gunrice15-1509524
トラックバック:Robot vacuum black friday
トラックバック:https://king-wifi.win/wiki/skytteoddershede0386
トラックバック:add adult Women
トラックバック:privatepsychiatrist07000.blogofchange.Com
トラックバック:Key Lexus
トラックバック:https://sixn.Net/
トラックバック:Online MotorradfüHrerschein A2 Kaufen
トラックバック:무료슬롯 프라그마틱
トラックバック:http://demo.emshost.Com/
トラックバック:Buy German Shepherds
トラックバック:storm-gomez.federatedjournals.com
トラックバック:Adhd Symptoms Adult female
トラックバック:dual fuel range cooker with 13amp plug
トラックバック:Bariatric wheelchair Uk
トラックバック:click for source
トラックバック:Www.Pcnews.Com.Tw
トラックバック:6ft shipping containers
トラックバック:championsleage.review
トラックバック:Door Doctor Near Me
トラックバック:Leather Sectionals For Sale
トラックバック:restless legs Adhd Treatment
トラックバック:newport Pagnell gas engineers
トラックバック:프라그마틱 플레이
トラックバック:official ezproxy.cityu.edu.hk blog
トラックバック:wine refrigerator under cabinet
トラックバック:largest american Fridge freezer
トラックバック:Leather Recliners Sofa
トラックバック:führerschein kaufen legal erfahrungen
トラックバック:wooden storage bunk bed
トラックバック:Buy A Fake UK Licence
トラックバック:Http://47.108.249.16/Home.Php?Mod=Space&Uid=1140027
トラックバック:gas safety Check buckingham
トラックバック:container Manufacturer
トラックバック:Kaufen französische bulldogge
トラックバック:Exercise Bikes For Sale
トラックバック:echten führerschein kaufen
トラックバック:www.pdc.edu explained in a blog post
トラックバック:replacement Key mercedes
トラックバック:baroola33815.aioblogs.com
トラックバック:just click the following internet page
トラックバック:intuniv adhd Medication
トラックバック:single cabin bed
トラックバック:look at this site
トラックバック:agen togel terpercaya
トラックバック:deutscher schäferhund welpe kaufen
トラックバック:bedside Co sleeper
トラックバック:kondrup-connor-3.technetbloggers.de
トラックバック:Buy uk driver’s license
トラックバック:new crypto casino
トラックバック:official clefwing4.bravejournal.net blog
トラックバック:https://www.google.Com.ai
トラックバック:maxi cosi seat and base
トラックバック:Immobiliser ghost
トラックバック:https://m7-c.pm-srv.co/v2/acr?r=07020640640100043887712561036&gdpr=true&adclickid=07010641840002043887728732593&dcid=0&url=https://expressdeutschekartes.com/
トラックバック:Car Lovksmith
トラックバック:power tools for Sale
トラックバック:Führerschein legal Kaufen
トラックバック:vehicle
トラックバック:Bot Cleaner
トラックバック:Fridge-freezer
トラックバック:Federatedjournals wrote
トラックバック:füHrerschein beantragen
トラックバック:adhd And asd Symptoms
トラックバック:Www.donggoudi.Com
トラックバック:A2 MotorradfüHrerschein Online Bestellen
トラックバック:jadwal Togel
トラックバック:Http://Www.Ciriomuseum.Com/
トラックバック:https://www.echangegagnant.com/
トラックバック:https://www.hulkshare.Com
トラックバック:http://79Bo.com/
トラックバック:bariatric Wheelchairs
トラックバック:check out this blog post via Nerdgaming
トラックバック:Sale on power Tools
トラックバック:https://www.ad-hoc-news.de
トラックバック:FranzöSische bulldogge kaufen welpen
トラックバック:adhd diagnosis and treatment
トラックバック:Buy Northern Ireland Driving Licence
トラックバック:buy Real driving License uk
トラックバック:Brown Leather recliner sofas
トラックバック:timeoftheworld.Date
トラックバック:Custom Kitchen
トラックバック:ile Kosztuje prawo jazdy na skuter
トラックバック:opensourcebridge.science
トラックバック:Metooo.Es
トラックバック:car Locksmith Near watford
トラックバック:treatment adhd
トラックバック:recent bitcoinviagraforum.com blog post
トラックバック:deals bunk Beds
トラックバック:visit Compravivienda`s official website
トラックバック:adult Bunk beds
トラックバック:african grey parrot baby For Sale
トラックバック:watch this video
トラックバック:http://Planforexams.com/q2a/user/nameniece8
トラックバック:Read express-deutsche-kartes37865.wikiparticularization.com
トラックバック:grey Sectional with Chaise
トラックバック:gas Fire engineer
トラックバック:A2 führerschein Online beantragen
トラックバック:Adhd Diagnosis Accuracy
トラックバック:Mitolyn
トラックバック:Treadmills at home
トラックバック:www.metooo.co.uk blog entry
トラックバック:replacement Sash Windows Cost
トラックバック:Power Tool combo Sets
トラックバック:link Alternatif Gotogel
トラックバック:test for adhd uk
トラックバック:Best All.terrain pram
トラックバック:http://Spherenetworking.com
トラックバック:Selfless official blog
トラックバック:buy uk drivers license online
トラックバック:professional
トラックバック:what is best brand Of Refrigerator
トラックバック:elearnportal.science
トラックバック:Wiki.iurium.cz
トラックバック:Read Home
トラックバック:gizmo The grey parrot
トラックバック:Add test for women
トラックバック:Https://Frenchbulldog02666.Blue-Blogs.Com/
トラックバック:Landlord Gas Safety Certificate Milton Keynes
トラックバック:Bridgehome.Cn
トラックバック:Private adhd assessment plymouth
トラックバック:Decrunch official blog
トラックバック:writes in the official Xojh blog
トラックバック:gas safety Certificate what is checked
トラックバック:Https://wellnessbeauty.ru
トラックバック:www.gsmindia.In
トラックバック:https://buy-uk-driving-license89867.gynoblog.com/31487627/14-smart-ways-to-spend-leftover-buy-uk-copyright-budget
トラックバック:power tool kits cheap
トラックバック:bariatric wheelchair 600 lb capacity
トラックバック:cheap sofas for sale under 500
トラックバック:french Door Fridge with internal water dispenser
トラックバック:führerschein klasse a2 digital Online bestellen
トラックバック:glbian.com
トラックバック:http://daoqiao.net
トラックバック:Csgo Case Battle
トラックバック:car Key And repair
トラックバック:click through the next page
トラックバック:Repair Key
トラックバック:auto Car Key replacement near Me
トラックバック:window repair near me
トラックバック:www.Daoban.org
トラックバック:47.108.249.16 noted
トラックバック:http://0lq70ey8yz1b.Com/home.php?mod=space&uid=1290246
トラックバック:tunnel Container uses
トラックバック:what is the top rated refrigerator Brand
トラックバック:This Web site
トラックバック:Keene kaufen französische bulldogge
トラックバック:Https://Justbookmark.Win/Story.Php?Title=5-Laws-Anybody-Working-In-Twin-Buggy-Should-Be-Aware-Of
トラックバック:best way to treat depression
トラックバック:Private Adhd Assessment Guildford
トラックバック:Private psychiatrist near me
トラックバック:bed cot design wooden
トラックバック:locksmith for car Key near me
トラックバック:Electric Foldable Wheelchairs
トラックバック:click here for more info
トラックバック:Adhd test Uk
トラックバック:read more on gotogel35700.thebindingwiki.com`s official blog
トラックバック:Adhd and adults symptoms
トラックバック:Buy Uk Drivers License
トラックバック:extra resources
トラックバック:signs and symptoms of anxiety disorder
トラックバック:Sectionals for sale Near me
トラックバック:Zedmeet.Net
トラックバック:relevant internet page
トラックバック:https://walton-todd.mdwrite.net/are-the-advances-in-technology-making-Private-psychiatrists-uk-better-or-worse
トラックバック:führerschein kaufen füR 500 euro
トラックバック:what google did to me
トラックバック:https://imoodle.Win/
トラックバック:Caring For An Grey Parrot
トラックバック:best 2 In-1 prams
トラックバック:kids beds with slide
トラックバック:Www.youtube.com
トラックバック:buy a real driving Licence uk
トラックバック:https://www.scdmtj.com
トラックバック:affordable couches for sale
トラックバック:car Key remote repair
トラックバック:schweizer franken fälschen
トラックバック:Weibo.Cn
トラックバック:Clausbox2.Werite.Net
トラックバック:pop over here
トラックバック:4 Seater l shape Leather sofa
トラックバック:Ovens Hobs
トラックバック:rollator mobility walker
トラックバック:https://humanlove.stream/
トラックバック:Article
トラックバック:lightest foldable electric wheelchair
トラックバック:Modern leather Sofa
トラックバック:Mackinnon-rose-3.blogbright.Net
トラックバック:Kurs Na Kategorię A1
トラックバック:citroen berlingo key
トラックバック:single oven electric built In
トラックバック:motorradführerschein a2 online shop
トラックバック:king shepherd Kaufen
トラックバック:https://grass27.ru
トラックバック:Https://mgbg7b3bdcu.net/?qa=user/hopefork80
トラックバック:private adhd assessment chelmsford
トラックバック:https://clinfowiki.win
トラックバック:treadmill Best
トラックバック:Assess Adhd
トラックバック:postheaven.net
トラックバック:adhd adult Online test
トラックバック:msafiri.co.Tz
トラックバック:falschgeld shop online
トラックバック:a2 führerschein online bestellen
トラックバック:Metooo.Com
トラックバック:rna.Link
トラックバック:spare keys for car
トラックバック:http://zqssdic.moroz-solnce.ru
トラックバック:prams55386.tnpwiki.com
トラックバック:Fridge Names
トラックバック:Gotogel link Alternatif
トラックバック:Www.stes.tyc.edu.tw
トラックバック:adhd Test clinical partners
トラックバック:they said
トラックバック:african grey parrot care
トラックバック:Click on 80
トラックバック:adhd assessment for Adults near me
トラックバック:프라그마틱 무료체험 슬롯버프
トラックバック:Beaverbush08.werite.net
トラックバック:Marillion officially announced
トラックバック:라이브 카지노
トラックバック:https://nerdgaming.science/wiki/What_Private_Psychiatrists_Near_Me_Should_Be_Your_Next_Big_Obsession
トラックバック:codeplace.Ru
トラックバック:Best Robovac
トラックバック:best Auto Locksmiths in watford
トラックバック:click web page
トラックバック:related
トラックバック:electriq chest freezer
トラックバック:https://zenwriting.Net/regretcoffee77/10-undeniable-reasons-people-hate-driving-lessons-louth
トラックバック:psychiatry near Me
トラックバック:lambert-ford.Thoughtlanes.net
トラックバック:visit this link
トラックバック:Buying Uk Driving License
トラックバック:Power tool products
トラックバック:프라그마틱 공식홈페이지
トラックバック:gdzie kupić Prawo jazdy kat b
トラックバック:Locksmith for Car keys
トラックバック:private Psychiatrist Diagnosis
トラックバック:http://Lzdsxxb.com/home.php?mod=space&uid=3802648
トラックバック:transponder key programming cost
トラックバック:Lacroix-Dominguez-3.Mdwrite.Net
トラックバック:Sofas Sale
トラックバック:find a Private psychiatrist
トラックバック:taruhan Togel Aman
トラックバック:visit the next website page
トラックバック:https://getsocialsource.com/story3545369/12-statistics-about-pushchairs-prams-pushchairs-to-refresh-your-eyes-at-the-cooler-water-cooler
トラックバック:corner chaise lounge
トラックバック:wheelchair van Ramps prices
トラックバック:Perucycle7.Bravejournal.Net
トラックバック:alternatif Gotogel terpercaya
トラックバック:power tools shop online
トラックバック:Car remote Key Repair
トラックバック:Antoineluczkowiak.Top
トラックバック:Baby African Grey Parrot For Sale
トラックバック:vehicle key repairs
トラックバック:mechanics tool kit
トラックバック:Ile kosztuje prawo jazdy na skuter?
トラックバック:Exercise bike for sale
トラックバック:Leg exerciser
トラックバック:Cheap Retro fridge freezer uk
トラックバック:KöRkort Lagligt
トラックバック:https://elearnportal.science/wiki/10_Things_That_Everyone_Doesnt_Get_Right_About_The_Word_Car_Key_Remote_Repair_Near_Me
トラックバック:Island extractor hood
トラックバック:Vehicle Diagnostics
トラックバック:diagnosing add adhd In adults
トラックバック:treadmills For home
トラックバック:Wooden.bunk beds
トラックバック:프라그마틱 정품
トラックバック:Gas Safe Milton Keynes
トラックバック:buy A full uk Driving licence
トラックバック:container rental price
トラックバック:Buy uk Drivers Licence
トラックバック:Https://www.dancetelevision.net/counter.cfm?14552,https://sifuromain.com/
トラックバック:best bunk beds for Adults
トラックバック:crypto casino games
トラックバック:read this blog post from Werite
トラックバック:navigate here
トラックバック:프라그마틱 슬롯 환수율
トラックバック:mines Game
トラックバック:couch with chaise And recliner
トラックバック:private adult adhd assessment
トラックバック:http://www.haidong365.com
トラックバック:https://www.meetme.com/apps/redirect/?url=https://setiathome.berkeley.edu/show_user.php?userid=11624564
トラックバック:bentley bentayga key marked area
トラックバック:Wwwfrydgeuk10033.blogdon.Net
トラックバック:coopers-chicago63112.Wikinarration.Com
トラックバック:oven
トラックバック:Motorradführerschein kaufen
トラックバック:adhd uk test
トラックバック:Baby Carriages
トラックバック:https://telegra.ph
トラックバック:L Shape Bunkbeds
トラックバック:Ferrari Key Programming
トラックバック:Https://Marvelvsdc.Faith/Wiki/Whats_The_Ugly_Truth_About_Bariatric_Wheelchair
トラックバック:plus size wheelchair
トラックバック:Https://directory-daddy.com/listings12779288/10-top-mobile-apps-for-private-mental-health-psychiatrist
トラックバック:mazda key replacement Cost uk
トラックバック:listen to this podcast
トラックバック:Tools Deals Uk
トラックバック:https://fakenews.win/
トラックバック:https://www.bitsdujour.com/profiles/DyDLaU
トラックバック:swedish-drivers-license74885.wikigop.com
トラックバック:auto locksmiths watford
トラックバック:conversational tone
トラックバック:kids bunk
トラックバック:https://images.google.ad/url?q=https://kearns-wall.federatedjournals.com/the-Most-convincing-proof-that-you-need-adult-adhd-assessment-uk
トラックバック:sleeper Sofa queen
トラックバック:prawo Jazdy A1
トラックバック:프라그마틱 슬롯 무료체험
トラックバック:FranzöSische Bulldogge Kaufen Hamburg
トラックバック:German Shepherds are Looking for a home
トラックバック:Hasil Togel
トラックバック:Blue African grey Parrot
トラックバック:KöPa A1 KöRkort Online
トラックバック:3 wheel rollator with Seat uk
トラックバック:Reupholster leather Couch
トラックバック:https://checktulip0.werite.net/
トラックバック:https://cymbaltrick85.bravejournal.net/whats-the-current-job-market-for-nissan-key-fobs-professionals
トラックバック:bandar Togel terpercaya
トラックバック:More hints
トラックバック:adhd in adults treatment
トラックバック:single Push chair
トラックバック:Https://Fewpal.Com/Post/1310416_Https-Damgaard-Carlson-Hubstack-Net-10-Buy-Eu-Driving-License-Related-Projects-T.Html
トラックバック:retro Under counter fridge Freezer
トラックバック:10 Situs Togel Terpercaya
トラックバック:Wiki.Melillo.Eu
トラックバック:Private Adhd Assessment Leicester
トラックバック:Swedish-Drivers-License38799.Answerblogs.Com
トラックバック:schäferhunde suchen ein zuhause
トラックバック:treadmill for sale near me
トラックバック:6 piece power tool set
トラックバック:Can a private psychiatrist diagnose
トラックバック:car keys Replacement near me
トラックバック:integrated fridge Freezer 50/50
トラックバック:this link
トラックバック:fridge freezer for sale near me
トラックバック:Smallest treadmill with incline
トラックバック:prawo jazdy c+e
トラックバック:Chesterfield Sofas For Sale
トラックバック:deutsche Schäferhunde Welpen Kaufen österreich
トラックバック:Commercial wine chiller
トラックバック:link web page
トラックバック:FöRarprov BoråS
トラックバック:Fully comprehensive
トラックバック:best power tools
トラックバック:Shorl.Com
トラックバック:Click Link
トラックバック:fridge freezer For Sale
トラックバック:3 Wheel Stroller
トラックバック:Getting an Assessment for adhd
トラックバック:https://www.google.com.pk
トラックバック:cameradb.review
トラックバック:click this site
トラックバック:exercise bicycle for Sale
トラックバック:http://www.Primondo.De
トラックバック:Online Adhd Assessment
トラックバック:just click ho-bernstein-4.technetbloggers.de
トラックバック:프라그마틱
トラックバック:gsean.lvziku.cn
トラックバック:reinrassiger deutscher schäferhund züchter
トラックバック:diagnosed With Adhd
トラックバック:Technetbloggers official blog
トラックバック:water dispenser and Refrigerator
トラックバック:https://lambert-lawson.Blogbright.net/ask-me-anything-Ten-responses-to-your-questions-about-buy-german-shepherd-puppies
トラックバック:Can adhd be diagnosed in adults
トラックバック:Jazda na motorze
トラックバック:Falsche 50 Euro Scheine Kaufen
トラックバック:Procedura Uzyskania prawa jazdy A1
トラックバック:mobile key Repair
トラックバック:http://anipi-italia.org
トラックバック:Driving lessons Grimsby
トラックバック:프라그마틱 슬롯 팁
トラックバック:https://wwwfrydgeuk31459.wikiadvocate.com/
トラックバック:private adhd assessment cost
トラックバック:https://wifidb.science/
トラックバック:Macaw for sale
トラックバック:simply click the following web site
トラックバック:Testing for adhd in adults
トラックバック:KöPa A2 KöRkort Online
トラックバック:Carkeyrepair46488.blogdon.net
トラックバック:beste webseite für falschgeld
トラックバック:www.Keysystems.ru
トラックバック:Www.google.co.Vi
トラックバック:Adhd Psychiatry Near Me
トラックバック:https://www.northwestu.edu
トラックバック:Robotic Vacuum Cleaner Amazon
トラックバック:anxiety Symptoms men
トラックバック:Bulldogge kaufen
トラックバック:leather sofas For sale
トラックバック:contemporary fabric corner sofas
トラックバック:Sectional sofas for sale
トラックバック:https://qa.holoo.co.ir
トラックバック:Kaufe Deutschen FüHrerschein
トラックバック:read review
トラックバック:Gas Fire Engineer Near Me
トラックバック:Buy Macaw
トラックバック:Small Double Stroller
トラックバック:Prawo jazdy na skuter
トラックバック:High Power Built In Ovens
トラックバック:cheap car keys replacement
トラックバック:Modern Fabric Corner Sofa
トラックバック:adhd women test
トラックバック:Portable Wheelchair
トラックバック:2 Seater Fabric Settee
トラックバック:website gotogel Alternatif
トラックバック:daftar togel terpercaya
トラックバック:Gas certificate buckingham
トラックバック:Deutschen FüHrerschein Legal Kaufen
トラックバック:Replacement ford transit Keys
トラックバック:key mercedes
トラックバック:Affordable robot vacuum
トラックバック:Bedside Baby Bed
トラックバック:recliner couch set
トラックバック:foldable lightweight electric wheelchair
トラックバック:bariatric manual wheelchair
トラックバック:compact Prams
トラックバック:Adhd testing for Adults
トラックバック:brown 3 seater fabric sofa
トラックバック:füHrerschein kaufen ohne prüfung deutschland
トラックバック:falschgeld Kaufen Legal
トラックバック:spare car key cutting near me
トラックバック:französische bulldogge Kaufen in der nähe
トラックバック:home workout equipment
トラックバック:water dispenser with refrigerator
トラックバック:Cheapest car Key Replacement
トラックバック:gas safety certificate check
トラックバック:best medication for inattentive adhd
トラックバック:adhd test For Adults uk
トラックバック:Vintage Fridge
トラックバック:all crypto casinos
トラックバック:Buy driving license category b Online
トラックバック:treatment for adhd in adults
トラックバック:https://nearfindermt.Com
トラックバック:Car Ignition switch repair
トラックバック:just click the following web page
トラックバック:Adhd Adult Symptoms
トラックバック:read more on skovgaard-gustavsen.blogbright.net`s official blog
トラックバック:Car Key Battery Replacement
トラックバック:exotic Bird Macaw
トラックバック:adhd symptoms for women
トラックバック:click through the next web page
トラックバック:Read Home Page
トラックバック:krasnodar.kovka-stanki.ru
トラックバック:fit
トラックバック:Igroville blog entry
トラックバック:Mercedes key replacement
トラックバック:macaw To buy
トラックバック:allbookmarking.Com
トラックバック:Replacement car keys cost uk
トラックバック:프라그마틱 체험
トラックバック:Needs Assessment For Mental Health
トラックバック:https://fakenews.win/wiki/a_guide_to_pixie_mini_macaw_from_beginning_to_end
トラックバック:buy ireland drivers license
トラックバック:Nearest
トラックバック:click here!
トラックバック:Cryptocurrency Casino
トラックバック:italianculture.net
トラックバック:Car Open Services
トラックバック:Www.northwestu.edu
トラックバック:프라그마틱 카지노
トラックバック:Istartw.Lineageinc.Com
トラックバック:Crypto Casino Usa
トラックバック:euro falschgeld online Kaufen
トラックバック:keys Repair
トラックバック:mozillabd.science
トラックバック:Www.alarmanlagenbau.com
トラックバック:robot Sweeper
トラックバック:Togel Cambodia
トラックバック:power tools near me
トラックバック:https://xs.xylvip.Com/home.php?mod=space&uid=2578803
トラックバック:victordirectory.com`s recent blog post
トラックバック:car key fob repairs near Me
トラックバック:Dalgaard-Krebs-2.Mdwrite.Net
トラックバック:64 explains
トラックバック:Http://www.annunciogratis.net/author/jeffcause68
トラックバック:self propelled wheelchairs for sale
トラックバック:small sectional sleeper sofa
トラックバック:keys for mercedes
トラックバック:Hikvisiondb.webcam
トラックバック:maps.google.cat
トラックバック:heavy duty bariatric Wheelchair
トラックバック:https://telegra.ph/Comprehensive-guide-to-Best-american-fridge-freezers-09-12-2
トラックバック:Miniature macaw for Sale
トラックバック:http://daoqiao.Net/copydog/home.php?mod=space&uid=2861028
トラックバック:Best auto locksmith in Bedfordshire
トラックバック:yutasan.co
トラックバック:timeoftheworld.date`s blog
トラックバック:adhd Medication Names
トラックバック:Buy european driving license uk online
トラックバック:compact 3 wheel stroller
トラックバック:füHrerschein kaufen Forum
トラックバック:20ft shipping Container for sale uk
トラックバック:how to get assessed for adhd as an Adult
トラックバック:Adhd adult Test
トラックバック:most comfortable prams
トラックバック:spare
トラックバック:small treadmill incline
トラックバック:Dissing-Devine.Thoughtlanes.Net
トラックバック:White Cot With Drawers
トラックバック:sneak a peek at this web-site
トラックバック:mouse click the following post
トラックバック:Www.Webwiki.Com
トラックバック:https://images.google.com.pa/
トラックバック:https://peatix.Com/
トラックバック:Catalina Macaw For Sale
トラックバック:key Car repair
トラックバック:situs togel terpercaya
トラックバック:go to these guys
トラックバック:read more on Xyhero`s official blog
トラックバック:30ft shipping Container
トラックバック:프라그마틱 슬롯 사이트
トラックバック:best Car Locksmith near bedford
トラックバック:Wheelchair for obese
トラックバック:blog post from delphi.larsbo.org
トラックバック:Driving Lessons Louth
トラックバック:fridge freezer uk
トラックバック:40 ft Tunnel Containers
トラックバック:official source
トラックバック:Cot With Drawer Underneath
トラックバック:Shipping Container Price
トラックバック:relevant web page
トラックバック:Read the Full Piece of writing
トラックバック:cost Of African grey parrot
トラックバック:https://www.buzzbii.com/
トラックバック:Deutscher FüHrerschein Zu Verkaufen
トラックバック:private adhd assessment near me
トラックバック:Agen Judi online
トラックバック:Adjustable Wheelchair Ramps
トラックバック:baby Prams 2 In 1
トラックバック:Spare Van Keys
トラックバック:20Ft Tunnel container
トラックバック:Fabric 3 seater sofa bed
トラックバック:hyacinth bird Price
トラックバック:bmw spare key fob
トラックバック:Mines Betting
トラックバック:Genuine Bmw Replacement Key
トラックバック:Gas Safety Inspection Buckingham
トラックバック:Adhd Testing Adults
トラックバック:xuetu123.Com
トラックバック:Gitlab.Projcont.Red-M.Net
トラックバック:Olderworkers.com.au
トラックバック:https://Www.bioguiden.se/redirect.aspx?url=https://luna-rankin-3.technetbloggers.de/10-websites-to-help-you-Be-a-pro-in-central-heating-engineers-in-buckingham
トラックバック:cognitive symptoms Of depression
トラックバック:bunk beds double on bottom single On top
トラックバック:http://gtrade.cc/
トラックバック:http://www.zhzmsp.Com/
トラックバック:private adhd assessment Doncaster
トラックバック:Https://Swedishdriverslicense90247.Dreamyblogs.Com
トラックバック:führerschein kaufen ohne prüfung
トラックバック:Learn Driving Lessons
トラックバック:bester Falschgeld Anbieter
トラックバック:https://www.taxiu.vip
トラックバック:simply click the following internet site
トラックバック:fold down electric wheelchair
トラックバック:severe macaw for sale
トラックバック:Power Tool set deals uk
トラックバック:top Rated robot Vacuum
トラックバック:tri walker 3 Wheel rollator
トラックバック:Sectional with Chaise lounge
トラックバック:http://www.heasytemplates.co/
トラックバック:Https://Nativ.Media/
トラックバック:Foldable Treadmill Electric
トラックバック:Https://Mgln.Ai/E/89/Tonymacdrivingschool.Com/
トラックバック:treadmill electric incline
トラックバック:ourgit.Khoonehmetri.com
トラックバック:http://valeramoscow.ru/
トラックバック:chesterfield corner sofa leather
トラックバック:lost car keys replacement cost uk
トラックバック:Falschgeld Kaufen Forum
トラックバック:mystery Box best
トラックバック:trafikverket gävle förnya körkort
トラックバック:best crypto casino for us players
トラックバック:Private-psychiatrist47107.mycoolwiki.com
トラックバック:Adhd in women diagnosis
トラックバック:www.bitspower.com blog post
トラックバック:fahrerlaubnis Kaufen
トラックバック:chestnut Fronted macaw for Sale
トラックバック:Best Car locksmith bedfordshire
トラックバック:Car Key Copy
トラックバック:willysforsale.Com
トラックバック:My Source
トラックバック:doctors who treat adhd in adults near me
トラックバック:Online mystery box sites
トラックバック:power tools Kit
トラックバック:KöPa A1 Körkort
トラックバック:exercise bike accessories
トラックバック:https://www.metooo.it/u/66ebc3679854826d167596F5
トラックバック:Militarymarket.Ru
トラックバック:Training experience
トラックバック:Storage 3 wheel Rollator
トラックバック:Adult Adhd Symptoms Uk
トラックバック:gas fire service engineers near Me
トラックバック:Full Review
トラックバック:Macaw bird sale
トラックバック:mines game online
トラックバック:Compact Double Stroller
トラックバック:geld fälschen Internet
トラックバック:git.opensdv.org
トラックバック:Where To Buy Fridge Freezer
トラックバック:bedside Crib with changing table
トラックバック:Www.Maanation.Com
トラックバック:Minecraftcommand.Science
トラックバック:Adhd Adult Testing
トラックバック:types of macaw
トラックバック:click the next web page
トラックバック:folding Treadmills
トラックバック:deutschen führerschein kaufen erfahrungen
トラックバック:https://forum.cancuncare.com/proxy.Php?link=https://www.Frydge.Uk/
トラックバック:Car Key replacement service near me
トラックバック:best Bedside Cot
トラックバック:Lightweight bariatric transport Wheelchair
トラックバック:Full File
トラックバック:Http://Www.Annunciogratis.Net/
トラックバック:intern.ee.aeust.edu.tw
トラックバック:Mobile locksmiths For Cars
トラックバック:Treehouse bunk
トラックバック:large 2 seater fabric Sofa
トラックバック:childrens twin bunk beds
トラックバック:http://www.supergame.one/home.php?mod=space&uid=120638
トラックバック:articlescad.com wrote in a blog post
トラックバック:reprogram
トラックバック:judi togel
トラックバック:visit the website
トラックバック:try this site
トラックバック:online Tool shops
トラックバック:프라그마틱 불법
トラックバック:just click the next post
トラックバック:114.55.54.52
トラックバック:cheap 2 In 1 Prams
トラックバック:exercise Cycles For sale
トラックバック:rosario-bolton.mdwrite.net
トラックバック:Https://Sovren.Media/U/Botanydanger44/
トラックバック:clinfowiki.Win
トラックバック:American Fridge Freezer Sale
トラックバック:by Bravejournal
トラックバック:why not try this out
トラックバック:Sleeper futon
トラックバック:rollator With seat and basket
トラックバック:skoda octavia key Not detected
トラックバック:Maps.Google.Com.Br
トラックバック:Extreme adhd symptoms adults
トラックバック:https://vuf.minagricultura.gov.co/lists/Informacin servicios web/dispform.aspx?id=9888757
トラックバック:Qooh`s statement on its official blog
トラックバック:Dewalt Power Tool Store
トラックバック:cheap 2 seater fabric sofa
トラックバック:Confined Space Containers
トラックバック:www.Hockeyfemininlaval.Com
トラックバック:single Buggy
トラックバック:fälschungen kaufen
トラックバック:Adhd titration private
トラックバック:Gas Engineer certificate
トラックバック:Macaw keycaps
トラックバック:Hondacityclub`s blog
トラックバック:porsche Carkey
トラックバック:diagnostics Car
トラックバック:macaw bird Colors
トラックバック:Container modifications
トラックバック:https://80agpaebffqikmu.рф
トラックバック:spix Macaw lifespan
トラックバック:www.countysportszone.com
トラックバック:40ft tunnel containers
トラックバック:Three Wheel rollator with seat
トラックバック:Car Spare Keys
トラックバック:Algowiki.Win
トラックバック:Private Psychiatry
トラックバック:push chairs and prams
トラックバック:exercisebikesonline59385.wikinewspaper.com
トラックバック:Signs of untreated adhd
トラックバック:mini cooper s key replacement
トラックバック:Buy Driving licence online Uk
トラックバック:linked internet page
トラックバック:KöP Taxi KöRkort Online Utan Examen
トラックバック:jaguar xe key fob not Working
トラックバック:visit gl.b3ta.pl here >>
トラックバック:exercise bike Performance
トラックバック:championsleage.review explains
トラックバック:untreated adhd in adults test
トラックバック:Link Daftar Gotogel
トラックバック:Ford Key Programmer
トラックバック:trafikverket ta körkortsfoto
トラックバック:Driving Lessons Edinburgh
トラックバック:rustic leather Sofa
トラックバック:built in air fryer Microwave
トラックバック:read article
トラックバック:https://marvelvsdc.faith/wiki/15_mental_health_services_near_Me_benefits_everyone_must_be_able_to
トラックバック:windows glass replacement
トラックバック:just click the up coming site
トラックバック:fatherguitar6.werite.net
トラックバック:https://rode-juhl.hubstack.net/
トラックバック:Do i Need A gas safety certificate
トラックバック:Https://livebookmark.stream
トラックバック:botdb.win
トラックバック:honda key replacement Cost
トラックバック:kup polskie Prawo jazdy
トラックバック:adhd assessment for adults what to expect
トラックバック:adult adhd Assessment scotland
トラックバック:Best Kids’ Bunk Beds
トラックバック:Best mystery Box sites
トラックバック:Couches with Chaise
トラックバック:Mystery Boxes best
トラックバック:range cooker island
トラックバック:visit the next document
トラックバック:https://fakenews.win/wiki/Electric_Tool_Sets_The_Ugly_Facts_About_Electric_Tool_Sets
トラックバック:Folding Treadmills uk
トラックバック:führerschein kaufen 400 euro
トラックバック:Couches On Sale Near Me
トラックバック:https://Lynxcomic62.bravejournal.net/7-simple-tips-for-moving-your-auto-locksmith-near-bedford
トラックバック:Best item Upgrade
トラックバック:führerschein Ohne Prüfung Kaufen
トラックバック:https://kendall-niebuhr.thoughtlanes.net
トラックバック:Macaw Purchase
トラックバック:single To double pushchair
トラックバック:Case Opening battle
トラックバック:Kup prawo jazdy kat a
トラックバック:Driving Instructor Training
トラックバック:KöP körkort
トラックバック:Http://bridgehome.cn
トラックバック:symptoms Of adhd In Adults
トラックバック:cabin bed With wardrobe
トラックバック:Managing Adhd Without Medication
トラックバック:Treadmills Near Me
トラックバック:navigate to this site
トラックバック:private adhd diagnosis cost
トラックバック:samsung fridge price
トラックバック:land rover keys cut
トラックバック:Kup prawo jazdy b online
トラックバック:French Style Fridge Freezer With Ice Dispenser
トラックバック:French Bulldog
トラックバック:hyperactivity in women
トラックバック:childrens Bunkbeds
トラックバック:medication For adhd
トラックバック:Yogicentral official
トラックバック:https://www.Longisland.com/profile/dangerfrench56
トラックバック:adhd diagnosis in Adulthood
トラックバック:Http://39.108.216.210:3000/Cogcontainersltd1239/3972641/Wiki/20 20Ft Shipping Container For Sale UK Websites Taking The Internet By Storm
トラックバック:Gas safe engineer newport pagnell
トラックバック:https://www.meetme.com/apps/redirect/?url=https://christie-burnett.technetbloggers.de/what-is-the-reason-milton-keynes-Gas-engineers-is-fast-becoming-the-hottest-trend-of-2024
トラックバック:open online mystery boxes
トラックバック:Macaw bird cost range
トラックバック:learn more about Bookmarkstore
トラックバック:Vegan leather Couch
トラックバック:car Key cloning Service
トラックバック:Get More
トラックバック:Online mystery box Opener
トラックバック:Replacement keys for cars
トラックバック:https://nologostudio.ru
トラックバック:official website
トラックバック:Eco-friendly prams
トラックバック:Private Adhd Asd Assessment Near Me
トラックバック:you can try Yogicentral
トラックバック:click through the up coming article
トラックバック:from the Timeoftheworld blog
トラックバック:http://italianculture.net/redir.php?url=https://click4r.com/posts/g/18763219/are-you-confident-about-doing-buy-German-shepherds-try-this-quiz
トラックバック:Upvc Window Repair
トラックバック:Leather couch And Loveseat
トラックバック:symptoms of Adhd in an adult
トラックバック:best Car Locksmiths near northamptonshire
トラックバック:how Do you diagnose Adhd in Adults
トラックバック:Https://G28-Car-Key-Solutions85680.Blogs100.Com/30966258/20-Questions-You-Should-Have-To-Ask-About-Car-Stolen-With-Keys-Before-Buying-It
トラックバック:https://www.metooo.io/u/679ec6165c6f22118f6221D6
トラックバック:Hyacinth Macaw Lifespan
トラックバック:Https://socialbookmarknew.win/
トラックバック:please click the following web site
トラックバック:kitchen Innovation
トラックバック:Https://Itkvariat.Com/User/Fearnurse2
トラックバック:uk Psychiatrist
トラックバック:adhd Assessment psychiatry uk
トラックバック:Kup Prawo Jazdy B
トラックバック:Conversions Containers
トラックバック:byskov-mooney-3.technetbloggers.de
トラックバック:treadmills folding treadmills
トラックバック:köpa hjullastare körkort online
トラックバック:how do i get a spare car key
トラックバック:More suggestions
トラックバック:Best car seat Infant
トラックバック:https://king-wifi.win/wiki/How_To_Create_An_Awesome_Instagram_Video_About_Buy_A_French_Bulldog_In_Berlin
トラックバック:40 ft tunnel container
トラックバック:gas safe register engineer
トラックバック:Adult Diagnosis Of adhd
トラックバック:hesselberg-boysen.federatedjournals.com
トラックバック:newborn Car Seat
トラックバック:Best case battle sites
トラックバック:adhd non stimulant medication uk
トラックバック:Gas Cooker Engineer
トラックバック:test For adult Adhd
トラックバック:https://chessdatabase.science/
トラックバック:www.doctoryang.Info
トラックバック:köP sverige körkort
トラックバック:füHrerschein motorrad a1 und a2 kaufen
トラックバック:crib with Drawer
トラックバック:Borschevik.Ru
トラックバック:Crypto Thrills Casino
トラックバック:Cheap Power Tools
トラックバック:situsgotogel30481.bloguetechno.com
トラックバック:infant Cot Bed
トラックバック:click to investigate
トラックバック:best csgo case battle Sites
トラックバック:Professional electric treadmill
トラックバック:Read www.metooo.it
トラックバック:Haidong 365`s statement on its official blog
トラックバック:key not detected Skoda octavia
トラックバック:power tool sets on sale
トラックバック:blog post from www.nky.parks.com
トラックバック:written by kilic-mcnally-2.hubstack.net
トラックバック:80.82.64.206
トラックバック:gas engineer Buckingham
トラックバック:www.petzengarten.de
トラックバック:Best Car Locksmiths Hertfordshire
トラックバック:adhd diagnosis As An adult
トラックバック:brown Leather Corner recliner sofa
トラックバック:heavenarticle.com
トラックバック:Saveyoursite.Date
トラックバック:click4r.Com
トラックバック:car key Fob Replacement
トラックバック:bike exercise home
トラックバック:Wymagania Na Kategorię A1
トラックバック:Bedside Cot 6 Months Plus
トラックバック:Treadmills Home
トラックバック:Writeablog explains
トラックバック:französische bulldogge kaufen
トラックバック:www.haidong365.com official
トラックバック:Ovens And Hobs
トラックバック:look at here
トラックバック:treadmills Electric
トラックバック:Gas Engineer Milton Keynes
トラックバック:https://chessdatabase.science/wiki/is_sinatra_macaw_For_sale_near_me_the_most_effective_thing_that_ever_was
トラックバック:Adhd Assessment Scotland
トラックバック:heating and gas Engineer
トラックバック:psychiatrist70190.losblogos.com
トラックバック:retro fridge freezers for sale
トラックバック:billigt körkort
トラックバック:Buy Category B Licence Online
トラックバック:Stationary Bicycle exercise
トラックバック:adhd In Women adults
トラックバック:advicedesign23.werite.net
トラックバック:köp snabbt körkort
トラックバック:www.google.st
トラックバック:replaced
トラックバック:fisher and paykel french Door fridge ice maker
トラックバック:pape-juarez-2.mdwrite.net
トラックバック:https://digitaltibetan.win/wiki/Post:the_reasons_you_shouldnt_think_about_How_to_improve_your_adhd_assessment_for_adults_free
トラックバック:https://menwiki.men/wiki/How_To_Solve_Issues_With_Wooden_Cot_Bed_Price
トラックバック:car locksmith 24 hour near me
トラックバック:m.www.polar.co.kr
トラックバック:lost or stolen car keys
トラックバック:https://expressdeutschekartes39483.shopping-wiki.com/
トラックバック:https://www.bitsdujour.com/
トラックバック:best Single Buggy
トラックバック:right here on historydb.date
トラックバック:Nerdgaming.Science
トラックバック:2-sklad.ru
トラックバック:Macaw Bird purchase
トラックバック:Bunk Bed Slide Uk
トラックバック:2 Seater Fabric
トラックバック:Legal Falschgeld Kaufen
トラックバック:Anonymous crypto casino
トラックバック:link home
トラックバック:who can prescribe Medication for adhd
トラックバック:online
トラックバック:How To Get A Psychiatric Assessment Uk
トラックバック:Https://Codcup42.Werite.Net/15-Top-Private-Adhd-Diagnosis-Uk-Cost-Bloggers-You-Need-To-Follow
トラックバック:Replacement Car Keys With Chips
トラックバック:go here
トラックバック:Car Locksmiths In Bedford
トラックバック:vad gör man om man tappat bort sitt Körkort
トラックバック:ravn-freedman.mdwrite.net
トラックバック:Motorized leather recliner
トラックバック:Https://Kup-Prawo-Jazdy-W-Polsce40942.Shotblogs.Com
トラックバック:ghost immobiliser near me
トラックバック:Adhd symptoms in adults Treatment
トラックバック:staten.Ru
トラックバック:Dr Iqbal Psychiatrist
トラックバック:enbbs.instrustar.com
トラックバック:https://gray-eskildsen.mdwrite.net/the-top-reasons-people-succeed-in-the-case-battle-industry-1728788241/
トラックバック:black Leather Recliner
トラックバック:her response
トラックバック:crypto slots casino
トラックバック:bariatric Self propelled wheelchair
トラックバック:Childrens Mid Cabin Bed
トラックバック:best auto locksmith luton
トラックバック:Look At This
トラックバック:treatment for add adhd in adults
トラックバック:adhd Adults online Test
トラックバック:französischen Bulldoggenwelpen Kaufen
トラックバック:Top crypto Casino
トラックバック:best auto locksmith near Milton keynes
トラックバック:Setiathome.berkeley.edu
トラックバック:Adhd And Medication
トラックバック:couches near me For sale
トラックバック:Adhd Test For Adult
トラックバック:3 wheel mobility trike
トラックバック:Situs-Gotogel76248.Blog2Freedom.Com
トラックバック:Adhd medication assessment
トラックバック:Adhd Rage Symptoms
トラックバック:Private Psychiatry Near Me
トラックバック:Göra nytt KöRkort
トラックバック:https://utahsyardsale.com/author/coatdrink15/
トラックバック:recent blogs.cornell.edu blog post
トラックバック:inattentive Adhd test
トラックバック:tagoverflow.stream
トラックバック:private adhd assessment reading
トラックバック:https://www.metooo.Io/u/676a981eacd17a1177318568
トラックバック:Images.Google.Is
トラックバック:Click on xn--80agpaebffqikmu.xn--p1ai
トラックバック:Visit Nitka
トラックバック:mobile Car locksmiths
トラックバック:baby Cots online
トラックバック:sofas in sale
トラックバック:Driving Lessons Scunthorpe
トラックバック:Near Me Psychiatrist
トラックバック:www.annunciogratis.net
トラックバック:click over here
トラックバック:Www.longisland.com
トラックバック:Wood Bed cot
トラックバック:homeowner gas safety Certificate
トラックバック:Bentley bentayga Key
トラックバック:Sectional With Chaise
トラックバック:This Internet page
トラックバック:replacing lost car keys
トラックバック:Private psychiatry clinic
トラックバック:car ignition Lock
トラックバック:stroller newborn
トラックバック:körkortförnyelse borås trafikverket
トラックバック:src.strelnikov.Xyz
トラックバック:Commercial Gas engineers
トラックバック:ovens-and-hobs79290.wikilinksnews.com
トラックバック:midsleeper Cabin bed
トラックバック:sofas uk Sale
トラックバック:Car Key Replacement Near Me
トラックバック:combi microwave oven integrated
トラックバック:i loved this
トラックバック:black couches For sale
トラックバック:Https://Www.Easyfie.Com/Pocketcandle7
トラックバック:ignition barrel replacement Near me
トラックバック:private Adhd Assessments
トラックバック:datingvoor50Plus.nl
トラックバック:attention deficit disorder in women
トラックバック:add in adult women
トラックバック:to Matkafasi
トラックバック:kup prawo jazdy kat b+
トラックバック:car key Cloning cost
トラックバック:Cooker island
トラックバック:Ballard-Tange-2.Blogbright.Net
トラックバック:black side by Side fridge Freezer
トラックバック:visit the up coming website
トラックバック:mental health assessment
トラックバック:couch sets for sale
トラックバック:retro Style Fridge freezer
トラックバック:How To Get Adhd Treatment
トラックバック:www.footballzaa.com
トラックバック:l shaped Metal bunk beds
トラックバック:best Crypto casino usa
トラックバック:Https://Servergit.Itb.Edu.Ec
トラックバック:79Bo.com
トラックバック:second Hand Leather sofas
トラックバック:digitaltibetan.win
トラックバック:titration for adhd
トラックバック:Adult adhd Screening test
トラックバック:online mystery box
トラックバック:women Adhd Checklist
トラックバック:case battle simulator
トラックバック:https://Yogicentral.science/
トラックバック:description here
トラックバック:https://jiang-coughlin-3.technetbloggers.de/
トラックバック:sofas For sale online
トラックバック:Cot Bed With Under Drawer
トラックバック:https://bookmarks4.men/story.php?title=where-can-You-find-the-top-adult-adhd-assessment-information
トラックバック:Physical Symptoms of adhd
トラックバック:bunk For adults
トラックバック:www.Nlvbang.com
トラックバック:solid wooden bunk bed
トラックバック:dogan-winters.mdwrite.net
トラックバック:nearby
トラックバック:Cheap Sectionals For Sale
トラックバック:Prawo Jazdy Online
トラックバック:adhd Medication list
トラックバック:Kup-Prawo-Jazdy27281.Wikiannouncement.Com
トラックバック:mobile key fob repair
トラックバック:adult adhd diagnosis
トラックバック:next page
トラックバック:Going to Humanlove
トラックバック:Jaguar Car keys Replacement
トラックバック:Mid Cabin Bed With Desk
トラックバック:gdzie kupić prawo jazdy legalnie
トラックバック:Car Key Spare
トラックバック:writeablog.net
トラックバック:Csgo case Battle Sites
トラックバック:https://hikvisiondb.webcam/wiki/Thomasendickens1215
トラックバック:car key cutting
トラックバック:kup prawo jazdy Polska
トラックバック:Auto Locksmiths Buckinghamshire
トラックバック:gpsites.win wrote in a blog post
トラックバック:körkort Online
トラックバック:gpsites.win
トラックバック:Https://Bulldoggekaufen00620.Wikilowdown.Com/6603376/Your_Family_Will_Be_Thankful_For_Having_This_French_Bulldog_Puppies_For_Sale
トラックバック:Hzpc6.Com
トラックバック:Folding rollator with seat
トラックバック:Book Adhd Assessment Uk
トラックバック:top Exercise bikes
トラックバック:White couches for sale
トラックバック:why is Everyone being diagnosed With adhd
トラックバック:double Bunk beds for adults
トラックバック:Kup prawo jazdy online
トラックバック:love it
トラックバック:u shaped Outdoor Couch
トラックバック:Link Login Gotogel
トラックバック:Best Built In microwaves
トラックバック:marsh-stokholm-2.Blogbright.net
トラックバック:Symptoms of adhd in adults quiz
トラックバック:Https://Prefitchi.Ru/Redirect?Url=Https://Www.G28Carkeys.Co.Uk/
トラックバック:adhd Testing near me
トラックバック:kupię prawo jazdy kat b
トラックバック:http://prof-mebel.com
トラックバック:gas Safe Engineer Milton keynes
トラックバック:Locksmith Car Key Replacement Cost
トラックバック:Gas safety certificate buckingham
トラックバック:double ovens with built In microwave
トラックバック:Mental Health Assessment Service
トラックバック:L shaped couches for sale
トラックバック:Private Adhd Testing Uk
トラックバック:Mental illness Assessment
トラックバック:best medication for generalized Anxiety Disorder
トラックバック:leather reclining sofa
トラックバック:comprehensive Assessment in mental health
トラックバック:Leather Couches With Recliners
トラックバック:Https://Maps.Google.Com.Tr/
トラックバック:symptoms Adhd in adults
トラックバック:https://Valetinowiki.racing
トラックバック:https://telegra.ph/Why-Best-Bunk-Bed-With-Slide-Is-A-Must-At-A-Minimum-Once-In-Your-Lifetime-12-08
トラックバック:adhd Test online free
トラックバック:infant car seat rear facing
トラックバック:kup prawo jazdy kat b+ Online
トラックバック:Magr.Ru
トラックバック:Https://www.metooo.es/
トラックバック:Lpg gas engineer
トラックバック:Lost key to car
トラックバック:https://valetinowiki.racing/wiki/Ask_Me_Anything10_Responses_To_Your_Questions_About_New_Drivers_License
トラックバック:leather l Couch
トラックバック:large american Fridge freezer
トラックバック:zenwriting.net
トラックバック:case Battle csgo
トラックバック:Https://compravivienda.com
トラックバック:inexpensive L shaped couch
トラックバック:Portable Electric Mobility Scooter
トラックバック:https://championsleage.review/Wiki/why_do_so_many_people_would_like_to_learn_more_About_intake_psychiatric_assessment
トラックバック:Door and window Doctor
トラックバック:couch and chair Set
トラックバック:loft bed with stairs and desk
トラックバック:silkbeet96.werite.net
トラックバック:Https://Octavequit44.Werite.Net/
トラックバック:Images.Google.Com.Hk
トラックバック:ta Nytt Körkort
トラックバック:Suggested Internet page
トラックバック:mobile locksmith car keys
トラックバック:Kaseisyoji.com
トラックバック:https://Rooney-Goode.mdwrite.net
トラックバック:Adhd Assessment Cost
トラックバック:Adhd Diagnostic Assessment London
トラックバック:https://www.metooo.com/
トラックバック:Google.pl
トラックバック:https://lindgren-herrera.hubstack.net/how-to-beat-your-boss-with-item-upgrade-1728912404/
トラックバック:right here on images.google.co.il
トラックバック:locked out of Car No spare key
トラックバック:brechobebe.com.br
トラックバック:simply click the following article
トラックバック:http://enbbs.instrustar.com/home.php?mod=space&uid=1413758
トラックバック:wooden Bedside cot
トラックバック:Adult Adhd Online Test
トラックバック:right chaise sectional
トラックバック:Chesterfield corner sofa
トラックバック:treatment For inattentive adhd
トラックバック:https://www.123cha.com/ip/?q=Gratisafhalen.beauthormarcosveitc/
トラックバック:just click the next site
トラックバック:Pram 2 In 1
トラックバック:adhd and Odd symptoms
トラックバック:adhd Testing Adult
トラックバック:top falschgeld Webseiten
トラックバック:Adhd Treatment Adults
トラックバック:https://nova-snab.ru/
トラックバック:damaged
トラックバック:Https://Wiki.Gta-Zona.Ru/Index.Php/Singerspears4390
トラックバック:www.footballzaa.com explained in a blog post
トラックバック:gas Appliance Check Buckingham
トラックバック:see here
トラックバック:Duel Fuel Range
トラックバック:stokke double stroller
トラックバック:Adult testing adhd
トラックバック:Https://Frydge06672.Wikikarts.Com/
トラックバック:Tools Shops Near Me
トラックバック:Nursery Cots
トラックバック:read this
トラックバック:case opening battle csgo
トラックバック:best cot bed
トラックバック:gas engineer near me
トラックバック:robotic vacuum cleaner commercial
トラックバック:robot vacuum cleaner best Buy
トラックバック:http://www.tianxiaputao.com/bbs/Home.Php?mod=space&uid=1098931
トラックバック:betala nytt Körkort
トラックバック:Incline
トラックバック:Adhd Diagnosis Private Uk
トラックバック:cameradb.review noted
トラックバック:jordan-park.blogbright.Net
トラックバック:Bravejournal published a blog post
トラックバック:genuine Leather couches
トラックバック:20ft Shipping containers
トラックバック:trafikverket boråS öPpettider
トラックバック:Best Bunk Beds For Kids
トラックバック:https://fannurse70.werite.net/ten-taboos-about-lost-auto-key-replacement-you-should-never-share-on-twitter
トラックバック:best Online crypto casino
トラックバック:pre hospital mental health assessment
トラックバック:https://dadroof7.bravejournal.net/
トラックバック:Https://www.metooo.co.uk/
トラックバック:kitchen island hood
トラックバック:Frostfree Fridge Freezers
トラックバック:recent post by Postheaven
トラックバック:milsaver.Com
トラックバック:https://telegra.ph/
トラックバック:45Cm Built-In Microwave
トラックバック:Corgi Gas Registered Engineer
トラックバック:replacement
トラックバック:Auto Locksmith Milton Keynes
トラックバック:100% Echtes Falschgeld
トラックバック:Outdoor couches for sale
トラックバック:mouse click the next web page
トラックバック:visit link
トラックバック:treating adhd and Anxiety in adults
トラックバック:Www.louloumc.com official blog
トラックバック:Https://Wiese-Cleveland-4.Blogbright.Net/
トラックバック:wiki.globalassembly.org
トラックバック:Autism And Adhd Comorbidity Symptoms
トラックバック:just click the next web page
トラックバック:online Adhd Testing
トラックバック:Best mystery boxes
トラックバック:https://kingranks.com/
トラックバック:fridge brands uk
トラックバック:Zaomos.News
トラックバック:adhd tests For adults
トラックバック:Our Web Site
トラックバック:practical Kitchen
トラックバック:xs.Xylvip.com
トラックバック:bitetheass.com
トラックバック:Gas Safety Certificates
トラックバック:self Propelled wheelchairs lightweight
トラックバック:Robotic vacuum Cleaner Best
トラックバック:built in microwave over oven
トラックバック:retro fridge Freezer sale Uk
トラックバック:ansöka om nytt körkort
トラックバック:simply click the following website page
トラックバック:visit this web-site
トラックバック:https://muse.union.edu/2020-isc080-roprif/2020/05/29/impact-of-covid-on-racial-ethnic-minorities/Comment-page-6050/?replytocom=727327
トラックバック:three Wheeler Pushchair
トラックバック:California Tv`s statement on its official blog
トラックバック:Https://Aviator-Games.Net
トラックバック:recommended
トラックバック:gas safety Certificate Newport Pagnell
トラックバック:https://www.motoringalliance.com/proxy.php?link=https://www.sofasandcouches.com
トラックバック:lagligt Körkort
トラックバック:car locksmiths near my location
トラックバック:Ezproxy.Cityu.Edu.Hk
トラックバック:Item Upgrader kit
トラックバック:tall fridge Deals
トラックバック:Https://king-wifi.win/wiki/AllInclusive_Guide_To_Window_And_Door_Company
トラックバック:Trainingkgermak.Ru
トラックバック:paramedic mental Health Assessment
トラックバック:Adult Bunkbed
トラックバック:recommended Refrigerator Brands
トラックバック:donnelly-Kirkpatrick.thoughtlanes.net
トラックバック:Online Falschgeld Kaufen Ohne Risiko
トラックバック:무료 에볼루션
トラックバック:windows and doors
トラックバック:dvs power tools
トラックバック:https://www.google.pt/url?q=Https://pediascape.science/wiki/14_Smart_Ways_To_Spend_Your_LeftOver_Gas_Safety_Certificate_Example_Budget
トラックバック:children’s Room bunk beds
トラックバック:Best Auto Locksmith Hertfordshire
トラックバック:spare key car
トラックバック:3 Seater Chaise Lounge
トラックバック:Wildridings-Bracknell-Forest.Secure-Dbprimary.Com
トラックバック:Images.Google.Cf
トラックバック:new content from click4r.com
トラックバック:Mental health check
トラックバック:adhd Diagnosis cost uk
トラックバック:can a general physician Prescribe adhd medication
トラックバック:Childrens Single Bunk Beds
トラックバック:Full Post
トラックバック:https://trade-britanica.Trade/
トラックバック:adhd Test For adults
トラックバック:therapy treatment For depression
トラックバック:goals
トラックバック:Pdc.edu
トラックバック:adhd Medication private prescription
トラックバック:Mid sleeper with stairs
トラックバック:replacement volkswagen key
トラックバック:doors Windows near Me
トラックバック:Mobile Diagnostic
トラックバック:simply click the up coming site
トラックバック:add adhd symptoms in women
トラックバック:https://www.metooo.it/u/670765Ab1df27c118a5675a1
トラックバック:Acheter un permis de conduire en France
トラックバック:https://telegra.ph/private-psychiatrist-online-myths-and-facts-behind-private-psychiatrist-online-03-17
トラックバック:Https://Www.Diggerslist.Com
トラックバック:just click the next website page
トラックバック:Https://Cameradb.Review/Wiki/A_Productive_Rant_About_Pragmatic_Slots_Free
トラックバック:acheter un permis de conduire sans poser de questions
トラックバック:https://startfine24.werite.net/adult-Adhd-assessment-the-secret-life-of-adult-adhd-Assessment
トラックバック:www.hondacityclub.com
トラックバック:https://telegra.ph/Kids-Bunk-Bed-A-Simple-Definition-04-20
トラックバック:auto Vacuum
トラックバック:viewtool.com
トラックバック:Built in combi microwave oven and grill
トラックバック:double cabin bed with storage
トラックバック:KöPa C KöRkort
トラックバック:you can try Larsbo
トラックバック:Upgrade items
トラックバック:Instapages`s blog
トラックバック:Single stroller near me
トラックバック:telegra.ph blog entry
トラックバック:faux permis De conduire français à vendre
トラックバック:mem168.com
トラックバック:view it now
トラックバック:Brands Of fridges
トラックバック:High-End Prams
トラックバック:Buy Uk Driving Licence
トラックバック:프라그마틱 무료 슬롯
トラックバック:car keys lost replacement
トラックバック:바카라 에볼루션
トラックバック:best small frost free fridge freezers
トラックバック:Eu füHrerschein kaufen
トラックバック:KöRkort Vid Ankomst
トラックバック:Online FüHrerschein Erwerben A2
トラックバック:african grey parrots sale
トラックバック:bariatric high Back Wheelchair
トラックバック:cantrell-cramer.hubstack.Net
トラックバック:tunnel
トラックバック:pull out sofa Bed
トラックバック:blogs.cornell.edu
トラックバック:lamborghini aventador svj key
トラックバック:My Site
トラックバック:linked web-site
トラックバック:registrierten führerschein kaufen Erfahrungen
トラックバック:Modular Buildings Containers
トラックバック:Chemical Storage Containers
トラックバック:Adhd In Older Women
トラックバック:Robot Vacuum
トラックバック:www.ky58.cc
トラックバック:acheter un permis De conduire européen
トラックバック:macaw bird accessories
トラックバック:Brewwiki.Win
トラックバック:helpful resources
トラックバック:psychiatric Assessment edinburgh
トラックバック:www.hulkshare.com
トラックバック:bedside crib with wheels
トラックバック:https://mozillabd.Science/
トラックバック:Cvetstal.Ru
トラックバック:buggy 2 in 1
トラックバック:treadmill with desk
トラックバック:titration period Adhd
トラックバック:buy uk registered driving licence
トラックバック:extra wide Wheelchair
トラックバック:Deutscher SchäFerhund Schwarz Kaufen
トラックバック:use this link
トラックバック:Private Adhd Adult Assessment
トラックバック:visit your url
トラックバック:Reimer-bendixen.Technetbloggers.de
トラックバック:you can try these out
トラックバック:local gas engineer
トラックバック:https://matkafasi.com
トラックバック:Theflatearth.Win
トラックバック:adult adhd diagnosis and treatment
トラックバック:electric incline Treadmill
トラックバック:KöPa En Taxilicens Online Utan Tentor
トラックバック:get An adhd Assessment
トラックバック:mercedes keys Replacement
トラックバック:Window Door company
トラックバック:audi key blade
トラックバック:Car key repair
トラックバック:situs togel terbesar
トラックバック:just click the next article
トラックバック:best Drug For generalized anxiety disorder
トラックバック:Wulanbatuoguojitongcheng blog post
トラックバック:füHrerschein klasse B kaufen
トラックバック:Library29.Ru
トラックバック:www.google.ki
トラックバック:amazon dual Fuel range cookers
トラックバック:Https://Www.Rpgfix.Com/
トラックバック:item Upgrader
トラックバック:Local Psychiatrist Near Me
トラックバック:Fewpal link for more info
トラックバック:https://Posteezy.com
トラックバック:Prices
トラックバック:most effective adhd medication for adults
トラックバック:3 Seater Leather Sofa
トラックバック:who can diagnosis adhd
トラックバック:harmonogram egzaminów A1
トラックバック:hyperlink
トラックバック:Mystery Box
トラックバック:muse.union.edu
トラックバック:Cheap Loft Beds
トラックバック:FüHrerschein Klassen
トラックバック:mouse click the following web page
トラックバック:ww.kz
トラックバック:french door fridge next to wall
トラックバック:mental health Act assessment section 2
トラックバック:buy-Driving-licence-uk21542.wikiusnews.com
トラックバック:Best Adhd medication for adult women
トラックバック:Kaufen Sie den Führerschein C1-C1E – Ce
トラックバック:evolucaotecnologica.com.br
トラックバック:webbcomic.com
トラックバック:best car locksmiths near hertfordshire
トラックバック:Egzamin na kategorię a1
トラックバック:Car Key Replacement
トラックバック:Gas central heating engineer near me
トラックバック:Buy Full Uk Driving License
トラックバック:führerschein a2 online Erwerben
トラックバック:exercise
トラックバック:French Style Fridge Freezers
トラックバック:falschgeld kaufen Darknet
トラックバック:from-hewitt-4.technetbloggers.de
トラックバック:Refrigerated Containers
トラックバック:Pilseta 24 writes
トラックバック:Tony Mac Driving Courses
トラックバック:adhd assessment Uk adults
トラックバック:bariatric electric wheelchairs for Sale
トラックバック:Best Integrated Fridge Freezer
トラックバック:morphomics.science write an article
トラックバック:talks about it
トラックバック:great exercise bikes
トラックバック:motorradfüHrerschein kaufen
トラックバック:Private Psychiatrist Hull
トラックバック:egzamin teoretyczny a1
トラックバック:Kring-parks.blogbright.net
トラックバック:Minimalwave.Com
トラックバック:https://maps.Google.cv/url?Q=https://morphomics.science/Wiki/microwave_oven_builtin_the_ultimate_guide_to_microwave_oven_builtin
トラックバック:common adhd symptoms
トラックバック:https://nika-archi.Ru/redirect?url=https://fuehrerscheinindeutschland.com
トラックバック:Double loft bed with Desk
トラックバック:geldscheine kaufen Legal
トラックバック:Treadmill Home
トラックバック:single couches For sale
トラックバック:was kostet ein reinrassiger schäferhund
トラックバック:what Is titration adhd
トラックバック:click through the next post
トラックバック:doors
トラックバック:izhevsk.reabilitaciya-Narcomanov.com
トラックバック:https://www.google.pn/
トラックバック:hybrid macaws for sale
トラックバック:eu-füHrerschein kaufen
トラックバック:Www.Migcombg.Com
トラックバック:best car Locksmiths Near milton keynes
トラックバック:www.sunrockice.com
トラックバック:motorradführerschein A2 online Bestellen
トラックバック:Ferrari Smart Key
トラックバック:cot sales
トラックバック:Registrierten FüHrerschein Kaufen
トラックバック:skoda key replacement
トラックバック:clashofcryptos.trade
トラックバック:Read More In this article
トラックバック:single oven and Gas hob
トラックバック:https://fkwiki.win/wiki/Post:15_Funny_People_Working_Secretly_In_Auto_Locksmiths_Near_Bedford
トラックバック:Best 2 In 1 pram
トラックバック:Private psychology assessment
トラックバック:belgischer schäferhund welpen Kaufen österreich
トラックバック:Leather cloud couch
トラックバック:Built In Single Oven
トラックバック:Ghost Immobiliser
トラックバック:Robot Vacuum Cleaner Top 10
トラックバック:Best Automatic vacuum Cleaner
トラックバック:Https://gogs.lnart.com
トラックバック:new post from Chessdatabase
トラックバック:Best Hobs
トラックバック:read what he said
トラックバック:Gas heating Engineer
トラックバック:vertrauenswürdige Falschgeld verkäufer
トラックバック:https://zhou-halberg-5.technetbloggers.de/the-reason-why-adding-a-jaguar-key-programming-to-your-lifes-activities-will-make-all-the-impact/
トラックバック:double Cabin bed with desk
トラックバック:www.m-thong.com said in a blog post
トラックバック:Online führerschein A2 beantragen
トラックバック:childrens Double bunk Beds
トラックバック:best medication for ocd and adhd
トラックバック:Car Key Lock Repair Near Me
トラックバック:https://telegra.ph/The-No-1-Question-Everybody-Working-In-Lamborghini-Key-Fob-Should-Know-How-To-Answer-06-27
トラックバック:https://www.google.com.gi/
トラックバック:jonpin.com
トラックバック:cribs
トラックバック:Https://mybookmark.stream/story.php?title=whats-holding-back-from-the-treadmills-uk-industry
トラックバック:https://licencefrancexpress78767.Eqnextwiki.com
トラックバック:private psychiatrist tring
トラックバック:gas Safety engineer milton keynes
トラックバック:promgroup.spb.Ru
トラックバック:medication for odd and adhd
トラックバック:https://vidout.net/
トラックバック:Bunk mattress single
トラックバック:private adhd assessment Bath
トラックバック:Best Integrated microwave
トラックバック:Hamlin-Schwibbogen FranzöSische Bulldogge
トラックバック:kann man den Führerschein kaufen
トラックバック:에볼루션 무료 바카라
トラックバック:visit www.footballzaa.com now >>>
トラックバック:private Psychiatrist Assessment
トラックバック:sources
トラックバック:a2 Führerschein online kaufen
トラックバック:Full Record
トラックバック:BestäLla Nytt Ykb-Kort
トラックバック:https://Dokuwiki.stream
トラックバック:Exercise Bikes Online
トラックバック:best fridge brands Uk
トラックバック:mental health work capability assessment
トラックバック:best self Propelled wheelchair uk
トラックバック:sofas on sale
トラックバック:dermandar.com
トラックバック:https://marvelvsdc.faith/wiki/what_is_french_bulldog_and_Why_is_everyone_talking_about_it
トラックバック:http://Www.1moli.top/home.php?mod=space&uid=878446
トラックバック:all Terrain Push Chair
トラックバック:Broken car key repair
トラックバック:Adhd testing in adults
トラックバック:Car Key Duplicate
トラックバック:crypto Casino coins
トラックバック:bbs.0817Ch.com
トラックバック:Funsilo.Date
トラックバック:look at here now
トラックバック:Exercise Bike Quality
トラックバック:visit this weblink
トラックバック:acheter un vrai permis de conduire
トラックバック:David-davies-2.Hubstack.net
トラックバック:프라그마틱 슬롯 하는법
トラックバック:top refrigerator Brands
トラックバック:adhd symptoms For Diagnosis
トラックバック:Digitollblog says
トラックバック:https://duran-Harvey-2.federatedjournals.com/
トラックバック:Folding Electric Treadmill
トラックバック:schäFerhund kaufen
トラックバック:Long-Term Effects Of Untreated Adhd In Adults
トラックバック:Genuine Leather Sofa Set
トラックバック:brown leather recliner
トラックバック:Sofas for sale near me
トラックバック:mini cotbed
トラックバック:Buy a purebred German Shepherd
トラックバック:window And Door companies near me
トラックバック:how do i reprogram my skoda key Fob
トラックバック:related webpage
トラックバック:Good Robot Vacuum
トラックバック:redirect to championsleage.review
トラックバック:Lamont-Jessen.Blogbright.Net
トラックバック:Private assessment for adhd northern Ireland
トラックバック:Small Double Mid Sleeper
トラックバック:Recliner Leather
トラックバック:Emergency gas Engineer
トラックバック:replacement saab key
トラックバック:Recommended Web page
トラックバック:robot Vacuum Reviews
トラックバック:https://ai-db.science/wiki/10_Untrue_answers_to_common_private_adhd_assessment_manchester_questions_do_you_know_the_right_ones
トラックバック:severe macaws for sale
トラックバック:Inserta.Pro
トラックバック:tvkmegion.Ru
トラックバック:gas safe register duplicate certificate
トラックバック:smallest French door Fridge
トラックバック:legalen füHrerschein Kaufen
トラックバック:Private Psychiatrist Dunstable
トラックバック:Hob Uk
トラックバック:lost lexus Key
トラックバック:mystery box open game
トラックバック:https://Www.bioguiden.se/
トラックバック:browse around this web-site
トラックバック:Https://Blogfreely.Net/Hatraven88/20-Reasons-Why-Psychological-Center-Near-Me-Will-Not-Be-Forgotten
トラックバック:biomass boiler housings Containers
トラックバック:Jaguar Key Not Working
トラックバック:synundersöKning körkort borås
トラックバック:leather 4 seater sofas
トラックバック:corgi registered Gas engineer
トラックバック:Köpa taxilicens Körkort Online
トラックバック:Pram And Stroller 2 In 1
トラックバック:breaking news
トラックバック:pram pushchair
トラックバック:your domain name
トラックバック:https://theflatearth.win/wiki/Post:Youll_Never_Guess_This_Self_Propelled_Bariatric_Wheelchairs_Benefits
トラックバック:Http://Italianculture.Net/
トラックバック:Private adhd assessment wirral
トラックバック:metooo.co.uk
トラックバック:gas safe registered engineers Newport pagnell
トラックバック:l Couches for sale
トラックバック:www.kachelkunst.de
トラックバック:Acheter Un Permis De Conduire En Ligne
トラックバック:Mental Status assessment
トラックバック:minecraftathome.Com
トラックバック:Upgrade item
トラックバック:füHrerschein kaufen in deutschland
トラックバック:adult adhd assessment Near me
トラックバック:Macaw Prices
トラックバック:Yanyiku.Cn
トラックバック:macaw Bird toys
トラックバック:https://kerr-flowers-2.Thoughtlanes.net/the-intermediate-guide-for-buy-uk-drivers-license-online
トラックバック:Kup prawo jazdy kategorii B bez egzaminu
トラックバック:KöPa C Körkort Online
トラックバック:Psychiatrist In near Me
トラックバック:Kupić prawo jazdy W polsce
トラックバック:safe crypto Casino
トラックバック:Exercise Home Cycle
トラックバック:Fridge Freezer On Sale
トラックバック:Idea.Informer.Com
トラックバック:gdchuanxin.com
トラックバック:lost key
トラックバック:pushchair 3 Wheels
トラックバック:deutscher Schäferhund kaufen schweiz
トラックバック:puckett-emerson.hubstack.net
トラックバック:Bookmarking.Win
トラックバック:Https://Mixclassified.Com/
トラックバック:www.mazafakas.com
トラックバック:Crypto Casino Sites
トラックバック:Mercedes Replacement Keys
トラックバック:where to buy a macaw
トラックバック:robot Vacuum cleaner comparison
トラックバック:double glazing near me
トラックバック:Te.Legra.Ph
トラックバック:lost
トラックバック:stationary cycle for exercise
トラックバック:more about www.maanation.com
トラックバック:buy-uk-driving-licence98990.wikilinksnews.com
トラックバック:windows and doors replacement
トラックバック:https://tpufa.ru/bitrix/redirect.php?event1=click_to_call&event2=&event3=&goto=https://prawo-Jazdy-wyszkow.pl
トラックバック:How To Get Uk Driving License
トラックバック:Http://www.daoban.org/Space-uid-1221327.Html
トラックバック:island ventilation Hoods
トラックバック:Froze Free Fridge Freezer
トラックバック:buy uk Driving licence without exam
トラックバック:beech wood cot Bed
トラックバック:The best mystery boxes
トラックバック:machines
トラックバック:deutsche Führerschein kaufen
トラックバック:Https://Bowman-Bruus.Blogbright.Net
トラックバック:Tietrade83.Bravejournal.Net
トラックバック:www.Ppcsecure.Com
トラックバック:Best static Cycle For exercise
トラックバック:https://Peatix.com
トラックバック:Https://Avto-Imperia.Com
トラックバック:kann man einen führerschein kaufen
トラックバック:Driving Lessons
トラックバック:batchelor-mays-2.Thoughtlanes.net
トラックバック:mercedes key
トラックバック:frost free cold storage
トラックバック:führerschein kaufen preis
トラックバック:New adhd Medication uk
トラックバック:planforexams.com
トラックバック:B197-Führerschein Ohne PrüFung kaufen
トラックバック:Cheap
トラックバック:private adhd assessment liverpool cost
トラックバック:adhd Disease Symptoms
トラックバック:Composite door replacement
トラックバック:3 Wheel Pushchair sale
トラックバック:Yerliakor.Com
トラックバック:https://Securityholes.science
トラックバック:40ft tunnel Container
トラックバック:read this post from moskvich.nsk.ru
トラックバック:프라그마틱 이미지
トラックバック:goalfoot3.werite.net
トラックバック:Container Dimensions
トラックバック:fabric Corner Settee
トラックバック:Repair Car Key
トラックバック:Psychiatric Assessment cost
トラックバック:http://tsin.co.id/lang/eng/?r=https://www.robotvacuummops.com/
トラックバック:full mental health Assessment
トラックバック:Adult add women
トラックバック:Https://Git.Rocketclock.Com
トラックバック:Best Cordless Power Tool Sets
トラックバック:psychiatry adhd Near me
トラックバック:Goethe-Zertifikat B1 online kaufen
トラックバック:testy na prawo jazdy A1
トラックバック:Kupic Prawo Jazdy
トラックバック:Site Power Tools
トラックバック:https://www.play56.net
トラックバック:GefäLschte Euro Kaufen
トラックバック:Highly recommended Internet page
トラックバック:bedside cot Bed
トラックバック:bandar Togel
トラックバック:door With sliding Window
トラックバック:permis De conduire françAis en ligne
トラックバック:Bifold Door Replacement
トラックバック:treadmill Incline foldable
トラックバック:shapshare.com
トラックバック:macaw pet shop
トラックバック:https://elearnportal.science
トラックバック:Prawo Jazdy Kategorii A1
トラックバック:Silver Fridge Freezer With Water Dispenser
トラックバック:single Stroller with bench seat
トラックバック:Hyacinth Macaw cost
トラックバック:timneh african grey parrot
トラックバック:KöPa A2 Körkort
トラックバック:Adhd Assessment Criteria
トラックバック:http://unored.com/adserver/www/Delivery/ck.php?ct=1&oaparams=2__bannerid=3__zoneid=3__cb=aada3cad13__oadest=https://entzckendescferhundwelpen-wec35d.de/
トラックバック:can Anxiety disorder cause high blood pressure
トラックバック:you can try valetinowiki.racing
トラックバック:Goethe-Zertifikat C2 online kaufen
トラックバック:power ratchet set
トラックバック:Dokuwiki.Stream
トラックバック:Atavi blog entry
トラックバック:Adhd Tests Online
トラックバック:Mnogootvetov.ru
トラックバック:cmp.Mediatel.cz
トラックバック:mystery box Online Website
トラックバック:Natural adhd Medication
トラックバック:www.jinritongbai.com link for more info
トラックバック:Car Key Programming
トラックバック:click here to visit Wikimapia for free
トラックバック:more info here
トラックバック:cost of replacement porsche key
トラックバック:green Velvet Chesterfield sofa
トラックバック:http://Daoqiao.net/
トラックバック:non medication treatment For Adhd Adults
トラックバック:by kirkland-nguyen-3.technetbloggers.de
トラックバック:Lexus Key cutting near me
トラックバック:localhoneyfinder.org
トラックバック:33`s blog
トラックバック:autodiscover.gazpromenergosbyt.ru
トラックバック:Echtes Geld kaufen
トラックバック:togel wap online
トラックバック:Best Stationary Bikes For Exercise
トラックバック:Fieldcatsup0.Werite.Net
トラックバック:adhd test adults online
トラックバック:https://Rosales-reilly-3.federatedjournals.com
トラックバック:Travel Mobility Scooters For Sale
トラックバック:supplemental resources
トラックバック:https://rentry.co
トラックバック:Goethe-Zertifikat
トラックバック:Bi folding door repair Near me
トラックバック:item Upgrades
トラックバック:dual fuel Cooker range
トラックバック:www.demilked.com wrote
トラックバック:Land rover keyless entry disable
トラックバック:https://www.metooo.com/u/66bbdab7174Ec8118227b5ee
トラックバック:private Psychiatrist uk cost
トラックバック:who can diagnose and treat Adhd
トラックバック:Car replacement key near me
トラックバック:check out this one from Fuwafuwa
トラックバック:Best item upgrader
トラックバック:schäFerhund Abzugeben
トラックバック:Cot for sale
トラックバック:leather reclining sofa modern
トラックバック:How to get an adhd assessment
トラックバック:Novatek-Electro.Ru
トラックバック:other
トラックバック:Single Oven Range Cooker
トラックバック:How do i get diagnosed for adhd
トラックバック:Http://Www.Xuetu123.Com/Home.Php?Mod=Space&Uid=10208377
トラックバック:www.alonegocio.net.br
トラックバック:Examen du Permis de conduire français
トラックバック:Kupno Prawa Jazdy
トラックバック:Automated vacuum
トラックバック:Recliner Corner Leather Sofa
トラックバック:Http://Www.Hondacityclub.Com
トラックバック:Adhd In Adult Women Test
トラックバック:zasady Egzaminu na Prawo jazdy a1
トラックバック:what is the Best refrigerator brand
トラックバック:Learn Even more
トラックバック:best power tool combo kit deals
トラックバック:crypto Game Casino
トラックバック:Https://yogaasanas.Science/
トラックバック:Szkoła nauki jazdy a1
トラックバック:acheter Un permis de Conduire sans examen
トラックバック:http://Stu.wenhou.site/
トラックバック:bi Fold door repair near me
トラックバック:shop with tools
トラックバック:similar web site
トラックバック:adhd private diagnosis near me
トラックバック:Rollator All Terrain Wheels
トラックバック:Acheter un permis de conduire légal en ligne
トラックバック:https://tepalai.autopolis.lt
トラックバック:Bariatric wheelchair 22 inch
トラックバック:Goethe-Zertifikat C1 online kaufen
トラックバック:Kup Prawo Jazdy W Polsce
トラックバック:buy goethe Certificate a2 online
トラックバック:rare macaw breeds
トラックバック:Adhd symptoms anger
トラックバック:Kup Prawo Jazdy Z Kodem 95
トラックバック:https://crawford-timmons-3.thoughtlanes.net/Youll-never-guess-this-first-line-treatment-for-adhd-in-adultss-tricks/
トラックバック:Goethe Certificate C2
トラックバック:replacement ford car key
トラックバック:Goethe-Zertifikat B1
トラックバック:Adhd symptoms Symptoms
トラックバック:howe-handberg.hubstack.Net
トラックバック:https://azure-corn-hbktm2.mystrikingly.com/
トラックバック:Best treatment for Adhd In Adults
トラックバック:mini macaw for sale
トラックバック:private adhd diagnosis london
トラックバック:african grey parrot Eggs for sale
トラックバック:Adhd online assessment
トラックバック:door Window replacement
トラックバック:Saab 9-3 Key fob replacement
トラックバック:SeriöSer Falschgeld Shop
トラックバック:auto Locksmith service
トラックバック:mini exercise Cycle
トラックバック:desk treadmill foldable
トラックバック:git.Fuwafuwa.moe
トラックバック:adult Female adhd symptoms
トラックバック:spare car key cost
トラックバック:Autowatch Ghost immobiliser
トラックバック:head to the Bordermail site
トラックバック:https://www.Google.bs
トラックバック:Adhd test Free
トラックバック:jinrihuodong.com
トラックバック:Adhd evaluation Process
トラックバック:Behavioral Symptoms Of Depression
トラックバック:Psychiatrists
トラックバック:Shipping container sizes uk
トラックバック:tools store
トラックバック:lungetemper3.werite.net
トラックバック:Locked Car Keys In Car
トラックバック:under desk electric treadmill
トラックバック:seriöse falschgeld anbieter
トラックバック:fatahal.com
トラックバック:high functioning adhd in women
トラックバック:Robot Vacuum Cleaner industrial
トラックバック:casino Mines
トラックバック:Https://elearnportal.science/Wiki/the_most_underrated_companies_to_watch_in_composite_door_scratch_repair_industry
トラックバック:https://easybookmark.Win/story.php?title=french-door-fridge-ice-maker-whats-new-no-one-is-talking-about-3
トラックバック:Online Mental Health Assessment Uk
トラックバック:cost of adhd assessment uk
トラックバック:Best Automatic vacuum
トラックバック:3 Wheel Rollator With Seat
トラックバック:https://www.Google.com.sb/url?q=http://ask.mallaky.com/?qa=user/dusthoe0
トラックバック:Medication For adhd And bipolar
トラックバック:Http://Bridgehome.Cn/Copydog/Home.Php?Mod=Space&Uid=3286856
トラックバック:Fridge freezer next day delivery
トラックバック:Abcvote official blog
トラックバック:Small Bunk Bed For Kids
トラックバック:Crypto Online Casino
トラックバック:Key Spare
トラックバック:l shaped twin Bunk beds
トラックバック:Sectional sofa sale
トラックバック:Https://msk.futumag.ru
トラックバック:shipping Container cost
トラックバック:bariatric wheelchairs Uk
トラックバック:https://financevideosmedia.com
トラックバック:duel Fuel Cookers
トラックバック:acheter un permis de conduire léGal
トラックバック:Exterior Door With Window
トラックバック:spare car key fob cost
トラックバック:prawa jazdy Bez nauki
トラックバック:leather couch
トラックバック:https://www.elite-moscow.ru
トラックバック:Cormier-Haagensen-2.Thoughtlanes.Net
トラックバック:Federatedjournals blog entry
トラックバック:Wifidb.science
トラックバック:writes in the official willysforsale.com blog
トラックバック:Falschgeld Kaufen Sicher
トラックバック:https://www.longisland.com/profile/easetalk4
トラックバック:Robotic Hoovers
トラックバック:www.sitiosecuador.com
トラックバック:small sofas for sale
トラックバック:Static bike exercise
トラックバック:best built in Combi microwave
トラックバック:tools close to me
トラックバック:Adhd with women
トラックバック:Https://Historydb.Date/Wiki/4_Dirty_Little_Details_About_Annual_Gas_Safety_Check_In_Buckingham_Industry_Annual_Gas_Safety_Check_In_Buckingham_Industry
トラックバック:Adhd Test In Adults
トラックバック:Https://Buying-A-Macaw-Online85029.Wikififfi.Com/
トラックバック:containers for sale uk
トラックバック:https://yanyiku.cn/
トラックバック:lpg gas engineer near Me
トラックバック:Goethe Certificate B1
トラックバック:Read Championsleage
トラックバック:https://qiziqarli.net
トラックバック:Bocoran Togel Hari Ini
トラックバック:mazda new key cost
トラックバック:address here
トラックバック:Demilked blog post
トラックバック:git.openprivacy.ca`s blog
トラックバック:adhd in adults test uk
トラックバック:view www.diggerslist.com
トラックバック:Http://mem168new.com
トラックバック:https://g28-Car-key-solutions17993.activoblog.com/
トラックバック:Körprov online
トラックバック:This Web page
トラックバック:visit Mdwrite now >>>
トラックバック:https://articlescad.com/where-is-leather-automatic-recliner-be-one-year-from-this-year-501687.html
トラックバック:infant car Seat that swivels
トラックバック:private Adhd assessment warwickshire
トラックバック:privatepsychiatrist88080.blogvivi.com
トラックバック:locksmiths Car Keys near Me
トラックバック:https://yogaasanas.science/wiki/Allinclusive_guide_to_sofa_2_seater_fabric
トラックバック:am i adhd test
トラックバック:anxiety disorders description
トラックバック:https://anotepad.com/
トラックバック:best robot floor cleaner
トラックバック:2 Seater sofa fabric
トラックバック:visit our website
トラックバック:Most Common Adhd Medications
トラックバック:fridges freezers
トラックバック:https://yogaasanas.science/wiki/How_Adding_A_Replace_Bifold_Doors_To_Your_Lifes_Journey_Will_Make_The_An_Impact
トラックバック:fälschungsservice online
トラックバック:Cordless Power Tool Combo Sets
トラックバック:find A psychiatrist Uk
トラックバック:lightweight electric Folding wheelchair with lithium battery uk
トラックバック:Bi-Fold Door Repair
トラックバック:Leather recliners black
トラックバック:Http://Tracking.Webtradecenter.Com
トラックバック:gefälschte scheine kaufen
トラックバック:rollator with seat uk
トラックバック:read this post from Otownlawyerblog
トラックバック:buy a goethe certificate
トラックバック:Read the Full Article
トラックバック:online-shop für Fälschungen
トラックバック:vacuum bot
トラックバック:canvas.instructure.com
トラックバック:rtistrees.Com
トラックバック:Acheter Un Permis De Conduire Avec Bitcoin
トラックバック:http://www.Cervezazombie.com
トラックバック:Pasaran togel terlengkap
トラックバック:Bunk With Slide
トラックバック:pull out couches for sale
トラックバック:Treadmill Sale Uk
トラックバック:visit my website
トラックバック:Case Battle Promo
トラックバック:http://www.zhzmsp.com/home.php?mod=Space&uid=2482089
トラックバック:https://telegra.ph/A-Guide-To-Window-Glass-Repair-Near-Me-In-2023-07-11
トラックバック:Longisland published a blog post
トラックバック:House Cleaning Robot
トラックバック:pushchairsandprams44064.Blogdosaga.com
トラックバック:köRkort till salu
トラックバック:what is the most common adhd medication prescribed
トラックバック:narrow american Fridge freezers
トラックバック:exercise Bicycle
トラックバック:Jaguar Key Cutting
トラックバック:American Fridge Freezer With Ice Maker
トラックバック:Kitchen Island Extractor Fan
トラックバック:honda key code
トラックバック:click this
トラックバック:에볼루션바카라사이트
トラックバック:Reclining Sectional With Pull Out Bed
トラックバック:Gas safety certificates Newport Pagnell
トラックバック:Cheap Power Tool Kits
トラックバック:에볼루션 바카라
トラックバック:Crypto Casino Us
トラックバック:more about Blue Blogs
トラックバック:visit the up coming document
トラックバック:tianxiaputao.com
トラックバック:truckscene18.werite.Net
トラックバック:Https://Www.Pdc.Edu
トラックバック:Minecraftcommand explains
トラックバック:generalized anxiety Disorder Cognitive behavioral therapy
トラックバック:French Door Fridge No Water Dispenser
トラックバック:Https://Olderworkers.Com.Au/Author/Vidwv17Rxss1-Marymarshall-Co-Uk/
トラックバック:Https://Infozillon.Com/
トラックバック:Dewalt Corded Multi Tool
トラックバック:tomaszowmazowiecki.praca.gov.pl
トラックバック:슬롯
トラックバック:Bariatric Transport Chair
トラックバック:www.dedobbelrose.be
トラックバック:programming
トラックバック:island Cooker hoods uk
トラックバック:Bikes Exercise For Sale
トラックバック:Buy Goethe Certificate C1 Online
トラックバック:treatment resistant depression
トラックバック:Xintangtc.com
トラックバック:echten deutschen führerschein kaufen.
トラックバック:förnya Körkort
トラックバック:Https://Mcmillan-Jonassen-2.Thoughtlanes.Net/10-Healthy-Car-Opening-Service-Habits/
トラックバック:French Door Fridge Deals
トラックバック:Integrated Oven hob & extractor packages
トラックバック:Cycle exercise Home
トラックバック:Cheap car key Replacement
トラックバック:online-Shop für falschgeld
トラックバック:visit Fuwafuwa`s official website
トラックバック:leather sofas
トラックバック:all Terrain Travel system
トラックバック:adhd in adults Assessment
トラックバック:single adult bunk Bed
トラックバック:K12.Instructure.Com
トラックバック:https://heavenarticle.com/Author/shapeburma9-1567538/
トラックバック:Professionelle FäLschungen Kaufen
トラックバック:79bo2.com
トラックバック:kann Man führerschein kaufen
トラックバック:images.google.as
トラックバック:composite door cat flap
トラックバック:Togel online terbaik
トラックバック:führerschein Kaufen online Erfahrungen
トラックバック:small couches for sale
トラックバック:Replace bifold doors
トラックバック:Cat flap bifold Doors
トラックバック:Best french door fridge freezer
トラックバック:tan leather recliner Couch
トラックバック:Natural Wood cot bed
トラックバック:pop over to this website
トラックバック:window
トラックバック:Https://Lycrared6.Bravejournal.Net
トラックバック:https://wyzr.Cloud
トラックバック:broken
トラックバック:get redirected here
トラックバック:goethe Certificate
トラックバック:www.google.dm
トラックバック:linked web site
トラックバック:doors Windows uk
トラックバック:urgent psychiatric Assessment
トラックバック:inbuilt wine fridge
トラックバック:case Battle cs2
トラックバック:2 seater Leather and fabric sofa
トラックバック:island Kitchen hood
トラックバック:samsung built in fridge freezer
トラックバック:mazda cx 5 key programming
トラックバック:Davenport-flanagan-2.Technetbloggers.de
トラックバック:Cheap Treadmill Desk
トラックバック:CAMHS ADHD assessment UK
トラックバック:French Door Fridge Slim
トラックバック:built in microwave and oven combo
トラックバック:head to borregaard-rask-2.technetbloggers.de
トラックバック:roseregret2.bravejournal.net
トラックバック:https://forum.dontpayfull.com/proxy.php?link=https://cogcontainersltd.com/
トラックバック:Exercise-bikes-online02700.Qowap.com
トラックバック:Loveseat For sale
トラックバック:https://pediascape.science/wiki/The_Story_Behind_Adult_Test_For_ADHD_Will_Haunt_You_For_The_Rest_Of_Your_Life
トラックバック:how do you get assessed For adhd
トラックバック:redirect to drillpanda81.werite.net
トラックバック:http://47.108.249.16/home.php?mod=space&uid=905120
トラックバック:Goethe Certificate Online
トラックバック:Best Power Tool Sets
トラックバック:Kia sedona key fob
トラックバック:doors & windows near me
トラックバック:crypto Games casino
トラックバック:recent post by Hotnews
トラックバック:double Pram pushchair
トラックバック:git2.ujin.tech
トラックバック:by Glk Egoza
トラックバック:inattentive adhd in adults symptoms
トラックバック:프라그마틱 슈가러쉬
トラックバック:Elaschulte.de
トラックバック:treadmill near me
トラックバック:https://gitlab.reemii.cn
トラックバック:timber
トラックバック:permis De conduire francais falsifié
トラックバック:https://telegra.ph/Three-Common-Reasons-Your-Power-Tools-Isnt-Working-And-How-To-Fix-It-11-28
トラックバック:Http://Yerliakor.Com/User/Planetwash00
トラックバック:psychiatric diagnostic Assessment
トラックバック:Http://Www.1V34.Com/Space-Uid-881400.Html
トラックバック:https://ucgp.jujuy.edu.ar/profile/wormarrow98/
トラックバック:range Oven dual Fuel
トラックバック:composite door paint repair
トラックバック:Power tool kits For Sale
トラックバック:hochwertige fäLschungen
トラックバック:why are Adhd assessments so Expensive
トラックバック:프라그마틱 정품확인
トラックバック:Health and fitness
トラックバック:Composite Door Repair Near Me
トラックバック:https://Willysforsale.com/
トラックバック:174`s blog
トラックバック:https://theflatearth.win/
トラックバック:Toto togel
トラックバック:just click Federatedjournals
トラックバック:Sectional couches for Sale
トラックバック:api.soundcast.io
トラックバック:Fridge American
トラックバック:https://blogfreely.net
トラックバック:Best 2 in 1 pushchair
トラックバック:efebiya.ru
トラックバック:führerschein Kaufen schweiz
トラックバック:124.223.222.61
トラックバック:psychiatrist clinic near me
トラックバック:Cost Of Private Psychiatrist
トラックバック:brown Chesterfield
トラックバック:Goethe-Zertifikat A2 Online kaufen
トラックバック:bunk Beds with desk
トラックバック:프라그마틱 슬롯
トラックバック:füHrerschein kaufen münchen
トラックバック:führerschein a2 Online bestellen
トラックバック:fujiapuerbbs.com explained in a blog post
トラックバック:small Single bunk Bed
トラックバック:https://images.google.bg
トラックバック:Articlescad.Com
トラックバック:Fold Flat Treadmill
トラックバック:Randrup-Chung.Mdwrite.Net
トラックバック:Window and door company
トラックバック:online mystery box websites
トラックバック:Bookmarkzones officially announced
トラックバック:borås trafikverket körkortnytt
トラックバック:Test.9e-Chain.com
トラックバック:http://ling.Teasg.tw
トラックバック:Gas safe Buckingham
トラックバック:More
トラックバック:https://mozillabd.science/wiki/10_top_mobile_apps_for_lightweight_folding_rollators_with_seat
トラックバック:Transportstyrelsen Nytt KöRkort
トラックバック:leather couches for sale near me
トラックバック:ford Transit key fob
トラックバック:https://bora-furnitura.ru/
トラックバック:sleeper Sectional With pull out bed
トラックバック:three Wheel pushchair
トラックバック:frost free frostless freezer
トラックバック:Www.Forum.Zibatan.Ir
トラックバック:deal-hejlesen-4.blogbright.net
トラックバック:Severe adhd symptoms In adults
トラックバック:Adhd Medication
トラックバック:deutschland Führerschein
トラックバック:FranzöSische Bulldogge Welpen Zu Kaufen
トラックバック:adhd Diagnosis and academic Performance
トラックバック:treating adhd and depression in adults
トラックバック:bitcoincasinos
トラックバック:Strollers 2 In 1
トラックバック:leather recliner with footstool
トラックバック:Rolls Royce Dawn Key
トラックバック:Https://Purematrimony.Com/
トラックバック:Inattentive Adhd In Adult Women
トラックバック:Best Prams
トラックバック:köRkort online test
トラックバック:Ghost immobilise
トラックバック:lost keys to car no spare
トラックバック:Hangoutshelp.net
トラックバック:slimmest american Style fridge freezer
トラックバック:replacement Car keys
トラックバック:ovens
トラックバック:Prediksi togel Akurat
トラックバック:car key repair cost
トラックバック:pcnews.com.Tw
トラックバック:où Acheter un Permis de Conduire français
トラックバック:previous
トラックバック:elbowshrine5.werite.net
トラックバック:hale-hoppe-2.technetbloggers.De
トラックバック:https://anzforum.com/home.php?mod=space&uid=2451898
トラックバック:hipstrumentals.net
トラックバック:cat flap Installer near me
トラックバック:private clinical psychologist near me
トラックバック:Cheap couches for sale Near me
トラックバック:https://botdb.win/wiki/Guide_To_Gotogel_The_Intermediate_Guide_The_Steps_To_Gotogel
トラックバック:view Nativ
トラックバック:recliner Leather couch
トラックバック:Cat Flap Step
トラックバック:adhd In adult men symptoms
トラックバック:my response
トラックバック:falschgeld im darknet bestellen
トラックバック:mouse click the next page
トラックバック:https://securityholes.science/wiki/why_buy_a_Driving_License_is_your_next_big_Obsession
トラックバック:Https://www.google.com.pk/url?q=Https://Franks-mohamad-2.blogbright.net/the-most-hilarious-complaints-weve-heard-about-cost-of-replacement-car-key
トラックバック:https://scientific-programs.science/wiki/9_signs_youre_an_expert_you_can_buy_a_driving_license_expert
トラックバック:leather Living room sets
トラックバック:Https://nerdgaming.science/
トラックバック:https://sixn.net/home.Php?mod=space&uid=4465090
トラックバック:https://ai-Db.science/
トラックバック:bariatric heavy duty transport Wheelchair
トラックバック:Good Exercise Bicycle
トラックバック:m-Strana.ru
トラックバック:american style fridge freezer For sale
トラックバック:Https://Hirsch-Sinclair-2.Blogbright.Net/Five-People-You-Must-Know-In-The-Apply-For-A2-Drivers-License-Online-Industry/
トラックバック:Speed And Incline
トラックバック:song-petersen.blogbright.net
トラックバック:life fitness
トラックバック:american-style Fridge
トラックバック:certificate cost
トラックバック:how to get adhd Diagnosis uk adults
トラックバック:renouvellement du permis de conduire FrançAis
トラックバック:built in Microwave and Double oven
トラックバック:Https://Wifidb.Science/Wiki/17_Reasons_You_Shouldnt_Avoid_Goethe_Certificate_B1
トラックバック:http://www.fasteap.cn
トラックバック:csgo Case Battles
トラックバック:http://www.ksye.cn
トラックバック:lg freestanding American fridge Freezers
トラックバック:https://lovewiki.faith
トラックバック:bandar judi Togel
トラックバック:private Adhd Assessment dundee
トラックバック:pram Stroller 2 in 1
トラックバック:Gotogel36077.Blogcudinti.Com
トラックバック:gas fitters Milton Keynes
トラックバック:northern Containers
トラックバック:french doors With Windows
トラックバック:queen pull Out couch
トラックバック:renault kadjar key
トラックバック:Contemporary U Shaped Sectional
トラックバック:https://clashofcryptos.trade/wiki/Why_Everyone_Is_Talking_About_Skoda_Octavia_Replacement_Key_Today
トラックバック:Adhd assessment uk free
トラックバック:iblog.iup.edu
トラックバック:https://www.demilked.com/
トラックバック:https://www.youtube.com/redirect?q=https://posteezy.com/10-myths-your-boss-has-regarding-website-gotogel-alternatif
トラックバック:Git.Wastring.Com
トラックバック:http://wzgroupup.hkhz76.Badudns.cc/home.php?mod=space&uid=2331863
トラックバック:2in1 pram
トラックバック:https://Intensedebate.com/people/pocketsugar92
トラックバック:double Strollers
トラックバック:gas and heating engineer
トラックバック:https://Minecraftcommand.Science/
トラックバック:Bomadirectory.com
トラックバック:Adhd In Adults Online Test
トラックバック:Adhd assessment Leeds private
トラックバック:sciencewiki.science
トラックバック:021office said in a blog post
トラックバック:upvc door panel with Cat flap fitted
トラックバック:simply click the following site
トラックバック:pushchair with car seat
トラックバック:replacement upvc door panels with cat flap
トラックバック:porsche lost Key
トラックバック:best power tool set deals
トラックバック:built-in Microwaves
トラックバック:official Clashofcryptos blog
トラックバック:bifold door Repairs
トラックバック:https://tributes.theage.com.au/obituaries/138576/anthony-francis-re/?r=https://www.iampsychiatry.uk
トラックバック:Private adhd assessment cost uk
トラックバック:Psychiatrists private
トラックバック:simply click the up coming internet site
トラックバック:adhd diagnosis For adults
トラックバック:images.google.bi
トラックバック:keluaran Togel
トラックバック:vintage leather couch
トラックバック:read this post from Eric 1819
トラックバック:Private Psychiatrist toddington
トラックバック:Https://Www.Google.Co.Zm/Url?Q=Http://Bioimagingcore.Be/Q2A/User/Velvetcar14
トラックバック:This Web-site
トラックバック:cryptocurrency online casino
トラックバック:Untreated Adhd In Female Adults
トラックバック:https://www.Art-fresh.org:443/bitrix/rk.php?goto=https://Gotogelreal.lol
トラックバック:Goethe-Zertifikat C1
トラックバック:Single Bunkbed
トラックバック:Togel jitu
トラックバック:Kaufen führerschein
トラックバック:Best Price Bunk Beds Free Shipping
トラックバック:angka togel
トラックバック:Adhd test for adults free
トラックバック:https://apps.carleton.Edu
トラックバック:http://ls.lszpw.vip/
トラックバック:corner Sofa Sale
トラックバック:written by Telegra
トラックバック:French Door Fridge Freezer
トラックバック:FranzöSische Bulldogge zu Verkaufen
トラックバック:Https://Lovewiki.Faith/Wiki/Why_Nobody_Cares_About_Best_Sofa_Companies_UK
トラックバック:Togel 4D
トラックバック:learn more
トラックバック:Https://Www.Bioguiden.Se
トラックバック:silicacable55.bravejournal.Net
トラックバック:Treadmill Uk
トラックバック:Adhd Screening
トラックバック:Best Home Exercise Machine
トラックバック:untreated adhd in adults Uk
トラックバック:visit Blogbright`s official website
トラックバック:Https://Kurgan-Med.Ru/
トラックバック:social anxiety disorder treatment
トラックバック:ghost Immobiliser problems
トラックバック:add and adhd symptoms
トラックバック:Learn Alot more Here
トラックバック:https://Www.hulkshare.com/powerrest06/
トラックバック:www.ksye.cn
トラックバック:Cheap leather Sofa
トラックバック:adhd in Adults Symptoms uk
トラックバック:Locksmiths For Cars Near Me
トラックバック:rhetorclick.com
トラックバック:Vauxhall key programmer
トラックバック:treadmill Shop near Me
トラックバック:Changing window handles
トラックバック:www.google.com.ag
トラックバック:power Tool combo sets on sale
トラックバック:browse around this website
トラックバック:https://setiathome.berkeley.edu
トラックバック:Space Saving Treadmill With Incline
トラックバック:https://Gl.eyeinc.ru/sofasandcouchesuk4881
トラックバック:judi togel online
トラックバック:Fold Up Electric Treadmill
トラックバック:best Freezer Chest
トラックバック:Cheap Sofas for sale Under 200
トラックバック:composite door panel Replacement
トラックバック:Https://Actorchin4.bravejournal.net/
トラックバック:Bi fold repairs
トラックバック:Https://Www.Diggerslist.Com/6756A781D83F5/About
トラックバック:Bifold Door Repair Near Me
トラックバック:adhd treatment for Adults medication
トラックバック:landlord gas safety certificates
トラックバック:Goethe-Zertifikat Online
トラックバック:153.126.169.73
トラックバック:Automatic Vacuum
トラックバック:Private Psychiatric Diagnosis
トラックバック:Https://Www.Footballzaa.Com/Out.Php?Url=Https://Articlescad.Com/10-Healthy-Habits-For-A-Healthy-Assessment-In-Mental-Health-27229.Html
トラックバック:togel online Terpercaya
トラックバック:Buy Goethe Certificate A1 Online
トラックバック:google.dm
トラックバック:Data Togel
トラックバック:https://tawassol.univ-tebessa.Dz/
トラックバック:dunn-lillelund.blogbright.net
トラックバック:bookmark4you.win
トラックバック:Untreated adhd Life expectancy
トラックバック:best 50/50 fridge freezer
トラックバック:führerschein Zum kaufen
トラックバック:gitlab.Resolr.com
トラックバック:adult adhd symptoms list
トラックバック:https://www.question-ksa.com/user/beltoctave09
トラックバック:https://www.maanation.com
トラックバック:Key Replacements For Cars
トラックバック:Französische bulldogge mit langer nase kaufen
トラックバック:published on telegra.ph
トラックバック:104.248.32.133
トラックバック:https://hangoutshelp.net/user/liertoast05
トラックバック:Sofa Chaise Longue
トラックバック:Best Lightweight Rollator Walker With Seat
トラックバック:Http://militarymuster.Ca/
トラックバック:https://appc.cctvdgrw.com/home.php?mod=space&uid=1469761
トラックバック:sofas Sleeper sofas
トラックバック:best dual fuel range cookers uk
トラックバック:just click the following page
トラックバック:hop over to this web-site
トラックバック:green sleeper sofa
トラックバック:http://79bo.com
トラックバック:https://www.metooo.es/u/6626f32afd9C011193907b01
トラックバック:https://marvelvsdc.faith/wiki/the_reasons_youre_not_successing_at_types_of_therapy_for_depression
トラックバック:ghost immobiliser birmingham
トラックバック:https://sovren.media/
トラックバック:key Fob repair near Me
トラックバック:Ocd and adhd symptoms
トラックバック:cheap fridge Uk
トラックバック:single Bunk beds for kids
トラックバック:information from situs-togel-resmi37655.blog-kids.com
トラックバック:bruno mini yorkshire terrier kaufen
トラックバック:Pushchairs double
トラックバック:sawyer-Drew-3.federatedjournals.Com
トラックバック:Gas safety Checks Buckingham
トラックバック:https://blogfreely.net/clickatm8/whats-The-good-and-bad-About-ghost-Immobiliser-review
トラックバック:barr-hancock-2.thoughtlanes.net
トラックバック:domestic Gas engineer
トラックバック:Key Fob Repair service
トラックバック:Https://Hailreason5.Werite.Net/Some-Of-The-Most-Ingenious-Things-That-Are-Happening-With-Situs-Gotogel
トラックバック:marvelvsdc.faith
トラックバック:what is Adhd titration
トラックバック:annual gas safety check milton keynes
トラックバック:windows and doors near Me
トラックバック:git.Nothamor.com
トラックバック:https://lt.dananxun.cn/home.php?mod=space&uid=1439633
トラックバック:duxi yorkshire biewer kaufen
トラックバック:lost the car key
トラックバック:3 seater sofa Brown Fabric
トラックバック:car key spare Cost
トラックバック:https://compravivienda.com/author/spyhockey6/
トラックバック:mem168new.com
トラックバック:führerschein ohne prüfung legal
トラックバック:Mental Capacity assesment
トラックバック:indiablo.ru
トラックバック:check this site out
トラックバック:use safetychecks62160.governor-wiki.com
トラックバック:rollators with Seats
トラックバック:more..
トラックバック:private Psychiatric
トラックバック:Cayden yorkshire kaufen
トラックバック:simply click Joshuakmckelvey
トラックバック:metal midsleeper Bed
トラックバック:www.google.co.uz
トラックバック:https://shorl.com/pojistustegafu
トラックバック:http://www.otdmes.com.cn/
トラックバック:https://fatahal.com/user/chairpriest9
トラックバック:best budget robot vacuum
トラックバック:wzgroupup.hkhz76.badudns.cc
トラックバック:Best oven uk
トラックバック:Bedside Cots
トラックバック:sofas on sale uk
トラックバック:Pram 2In1
トラックバック:inbuilt Oven
トラックバック:Situs judi togel
トラックバック:Private adhd assessment edinburgh
トラックバック:dual Range Cooker
トラックバック:grey sofas For sale
トラックバック:xojh.cn
トラックバック:mini biewer yorkshire terrier kaufen
トラックバック:fridge freezers uk Sale
トラックバック:Couch beds for sale
トラックバック:https://historydb.date/wiki/What_Leather_Sofa_Set_Experts_Want_You_To_Learn
トラックバック:adult adhd symptoms
トラックバック:Exercise bike for house
トラックバック:https://www.metooo.io/
トラックバック:nissan Almera key Replacement
トラックバック:Going at Nader
トラックバック:wooden mid Sleeper cabin bed
トラックバック:cheap Lost car key replacement
トラックバック:auto key repair near Me
トラックバック:wine Beverage fridge
トラックバック:loft bed with stairs and Drawers
トラックバック:1c-kato.kg
トラックバック:Vintage fridge Freezer
トラックバック:Learn Even more Here
トラックバック:repairer
トラックバック:spare key For car
トラックバック:wine chillers For sale
トラックバック:Jackpot Togel
トラックバック:Twin Pushchairs
トラックバック:car key maker Cost
トラックバック:site web
トラックバック:bedside crib Vs Cot
トラックバック:Midi Bed
トラックバック:Gas Safety Check Newport Pagnell
トラックバック:click through the next website
トラックバック:doors & Windows
トラックバック:best bedside Cot for newborn
トラックバック:https://m2Bf.adj.st/
トラックバック:Nativ.Media
トラックバック:Trik Togel
トラックバック:visit website
トラックバック:read this blog post from fakenews.win
トラックバック:writes in the official Google blog
トラックバック:hey-link75753.fare-blog.Com
トラックバック:i lost the keys To my Car
トラックバック:Ug-Ls460.Com
トラックバック:freebookmarkstore.win
トラックバック:ns3133834.ip-51-77-84.Eu
トラックバック:bbs.Airav.cc
トラックバック:https://osman-tyler-2.mdwrite.net/all-inclusive-guide-To-buy-a-driving-license-legally/
トラックバック:Beige Fabric corner sofa
トラックバック:faux Permis De Conduire
トラックバック:Tasterice55.Werite.Net
トラックバック:Agen togel
トラックバック:kids slide Bed
トラックバック:mental Wellbeing Assessment
トラックバック:https://www.youtube.com
トラックバック:Marta Mini Yorkshire Terrier Kaufen
トラックバック:Private mental health assessment ireland
トラックバック:Built In Ovens
トラックバック:visit my webpage
トラックバック:Combo Power Tool Sets
トラックバック:Britta yorkshire Terrier welpen Kaufen
トラックバック:How Do i get an adhd assessment
トラックバック:http://bbs.01pc.cn/
トラックバック:Arvin biewer yorkshire terrier mini kaufen
トラックバック:Gas Certificate milton keynes
トラックバック:Freezer brands
トラックバック:www.zybls.com
トラックバック:adult adhd symptoms Men
トラックバック:https://www.meiyingge8.Com/space-uid-849648.html
トラックバック:Modular sleeper sofa
トラックバック:https://www.metooo.com/u/67a673952559C26b4ef47773
トラックバック:Https://Meier-Yates.Federatedjournals.Com/14-Businesses-Are-Doing-A-Fantastic-Job-At-Buy-Driving-License-A1
トラックバック:Built In oven
トラックバック:http://chronocenter.com/
トラックバック:acheter permis de conduire original
トラックバック:car keys replacement Cost
トラックバック:tan leather recliner sofa
トラックバック:Rumus togel
トラックバック:Freeok.cn
トラックバック:two Seater couch for sale
トラックバック:daftar situs togel
トラックバック:double Seat Stroller
トラックバック:http://www.zybls.Com
トラックバック:retro fridge freezer for sale
トラックバック:private-mental-health09562.homewikia.com
トラックバック:Mental-Health86775.Develop-Blog.Com
トラックバック:https://articlescad.com/the-three-greatest-moments-in-situs-togel-terpercaya-history-43359.html
トラックバック:cheap Single Oven built in
トラックバック:trailsuede67.werite.net
トラックバック:taruhan nomor togel
トラックバック:Gas Engineer Boiler
トラックバック:https://hikvisiondb.webcam/wiki/10_Key_Factors_Regarding_Car_Locksmiths_Bedford_You_Didnt_Learn_At_School
トラックバック:2 in 1 pushchair with car Seat
トラックバック:item Level upgrade
トラックバック:menwiki.men
トラックバック:Lt.dananxun.cn noted
トラックバック:Köp b1 körkort online utan examen
トラックバック:symptoms of adhd In adult Women
トラックバック:try this out
トラックバック:duel fuel range cookers
トラックバック:https://Www.Ddhszz.com/
トラックバック:Https://Botdb.Win/
トラックバック:black metal frame bunk bed
トラックバック:https://peatix.com/user/25544913
トラックバック:psychotherapy near Me
トラックバック:kup-polskie-prawo-jazdy06395.blog-eye.com
トラックバック:Shipping Container Sizes
トラックバック:Adhd Assessment Liverpool
トラックバック:Spare Car Key near me
トラックバック:built in microwave ovens for wall units
トラックバック:http://gtrade.cc/home.php?mod=space&uid=632020
トラックバック:Fridge Freezers uk
トラックバック:infant car seat swivel
トラックバック:http://eric1819.com/home.php?mod=space&uid=1250518
トラックバック:just click the next document
トラックバック:Private adhd Assessment stoke on trent
トラックバック:Bismarck welpen yorkshire terrier kaufen
トラックバック:Click on squareblogs.net
トラックバック:Symptoms Of Adhd In Adults Women
トラックバック:8.222.216.184
トラックバック:best lightweight double stroller
トラックバック:bbs.wuhudj.com
トラックバック:fridge freezer 50/50 frost Free
トラックバック:Read Telegra
トラックバック:Bandar togel terbaik
トラックバック:Damian der Welpe
トラックバック:gas appliance check newport Pagnell
トラックバック:lost Key what To do
トラックバック:most compact double stroller
トラックバック:www.Dermandar.com
トラックバック:Robot vac
トラックバック:What Type Of Doctor Treats Adhd In Adults
トラックバック:car key Maker near me
トラックバック:What Are Adhd Symptoms In Adults
トラックバック:kup-prawo-jazdy-polska20024.blogdun.com
トラックバック:Technetbloggers website
トラックバック:무료 프라그마틱
トラックバック:Https://Margaretu866Drr7.Izrablog.Com/Profile
トラックバック:adult test For adhd
トラックバック:best place to buy Bunk beds
トラックバック:Going at Daojianchina
トラックバック:https://www.guzhen0552.cn/home.php?mod=space&Uid=356716
トラックバック:go to Hikvisiondb
トラックバック:built in Single gas oven and grill
トラックバック:buy bunk Beds Online
トラックバック:Case Battles csgo
トラックバック:best french style fridge freezer uk
トラックバック:Recliner sofas For sale
トラックバック:Oven hob
トラックバック:Single umbrella stroller
トラックバック:2 seater Sofa sale
トラックバック:clicavisos.com.ar
トラックバック:bunk bed single mattress
トラックバック:Fridge freezers American
トラックバック:seat leon key fob programming
トラックバック:supergame.one
トラックバック:test center
トラックバック:wiki.gta-zona.ru
トラックバック:l bunk beds
トラックバック:use maps.google.no here
トラックバック:Rutelochki.Ru
トラックバック:http://douerdun.com
トラックバック:http://hefeiyechang.com/
トラックバック:Leather lounge
トラックバック:https://mgbg7b3Bdcu.net/
トラックバック:adhd Assessments for adults
トラックバック:Fabric 2 Seater Sofa
トラックバック:Power tool Bundle deals
トラックバック:look what i found
トラックバック:Click On this page
トラックバック:Click on Technetbloggers
トラックバック:Www.jjj555.com
トラックバック:adhd assessment For adults Uk
トラックバック:Gotogelreal35023.webdesign96.Com
トラックバック:Graded dual fuel Range Cookers
トラックバック:buy Fridge freezer
トラックバック:signs and symptoms of adhd In adults
トラックバック:sciencewiki.science blog article
トラックバック:Specialized Containers
トラックバック:crypto casino slots
トラックバック:Axel terrier welpen kaufen
トラックバック:common adhd Medications uk
トラックバック:https://blogfreely.net/feetwood1/your-Family-will-thank-you-for-getting-this-brands-of-refrigerator
トラックバック:fob key Repair
トラックバック:Emseyi.Com
トラックバック:Https://Muse.Union.Edu/2020-Isc080-Roprif/2020/05/29/Impact-Of-Covid-On-Racial-Ethnic-Minorities/Comment-Page-4618/?Replytocom=647060
トラックバック:krymlife.ru noted
トラックバック:getting assessed For adhd
トラックバック:bedside cot for twins
トラックバック:Suzie Der Yorkie-Welpe
トラックバック:프라그마틱 홈페이지
トラックバック:feetsofa27.bravejournal.net
トラックバック:Marvelvsdc says
トラックバック:Visit secure.americanpilgrims.org
トラックバック:coillarch3.werite.net
トラックバック:treatment for severe adhd In adults
トラックバック:Http://ezproxy.cityu.edu.hk/login?url=https://writeablog.net/owlbean45/3-ways-that-the-oven-uk-influences-your-life
トラックバック:volkswagen passat key Replacement cost
トラックバック:10-Situs-Togel-Terpercaya78456.Yomoblog.Com
トラックバック:gas Certificate
トラックバック:http://www.Wudao28.com/home.php?mod=space&uid=1397979
トラックバック:https://pet-parrot08503.p2blogs.com/32100440/20-fun-informational-facts-About-bandar-togel-terpercaya
トラックバック:new post from Writeablog
トラックバック:beställa körkort online
トラックバック:flydate3.bravejournal.net
トラックバック:Adhd In Adults Symptoms Women
トラックバック:botdb.win said
トラックバック:robot Vacuum cleaner
トラックバック:link homepage
トラックバック:Http://Www.80Tt1.Com
トラックバック:Big lots couches for sale
トラックバック:Shop.Kuehntec.De
トラックバック:3 Wheel Buggy
トラックバック:how to Get adhd diagnosis
トラックバック:Arbitragetraff explains
トラックバック:https://matkafasi.com/user/guidecomma60
トラックバック:see page
トラックバック:titration adhd
トラックバック:blog post from freezers70528.theisblog.com
トラックバック:replacing window Handles
トラックバック:best twin buggy
トラックバック:posylka-svo.Ru
トラックバック:assessment In psychiatry
トラックバック:Couch with chaise
トラックバック:read this blog article from www.pdc.edu
トラックバック:Http://Www.Bitspower.Com
トラックバック:video.propoundtube.com
トラックバック:pasaran Togel
トラックバック:https://beefhoe8.bravejournal.net/the-Most-powerful-sources-of-inspiration-of-situs-gotogel-terpercaya
トラックバック:Goethe-zertifikat b2
トラックバック:master Togel
トラックバック:tutorial Togel
トラックバック:Buy Goethe Certificate C2 Online
トラックバック:childrens princess bunk bed
トラックバック:http://delphi.larsbo.org/user/spoondragon93
トラックバック:mid sleeper with desk
トラックバック:Togel deposit pulsa
トラックバック:Vehicle Locksmith
トラックバック:adhd self Diagnosis
トラックバック:2 seater fabric tub Sofa
トラックバック:http://ezproxy.cityu.edu.hk/login?url=https://telegra.ph/The-Reason-Link-Login-Gotogel-Is-Everyones-Passion-In-2024-02-01
トラックバック:lg all refrigerator
トラックバック:Upvc windows near Me
トラックバック:Mid sleeper loft bed
トラックバック:Adult Diagnosis For Adhd
トラックバック:Power Tool Kits On Finance
トラックバック:fridges with Water filters
トラックバック:super fast reply
トラックバック:https://Loft-houghton-3.blogbright.net/5-killer-quora-answers-on-website-gotogel-alternatif-1738415891
トラックバック:Car Locksmith In Bedford
トラックバック:http://rtistrees.com/
トラックバック:Best Built in Fridge freezer
トラックバック:http://xojh.Cn/home.php?mod=space&uid=2287453
トラックバック:white bunk bed With Stairs
トラックバック:http://daojianchina.com/
トラックバック:https://clubbingbuy-De.com
トラックバック:auto Ghost immobiliser
トラックバック:seat car key programming
トラックバック:gas safety Certificate Cost
トラックバック:https://lentz-Berry-2.technetbloggers.de/how-to-make-a-successful-spare-car-keys-cost-guides-With-home
トラックバック:qualified gas engineer
トラックバック:Http://77.37.45.92:3000/Deutschessprachdiplom8809
トラックバック:togel Indonesia
トラックバック:recent post by Technetbloggers
トラックバック:foldable Electric wheelchair uk
トラックバック:Private Adhd Diagnosis Uk
トラックバック:https://wise-hyllested-2.blogbright.net/how-to-explain-gotogel-to-a-5-year-old-1738342383
トラックバック:https://autobel.pro/bitrix/redirect.php?Goto=https://gotogelreal.lol/
トラックバック:Www.toledo24.pro
トラックバック:Recommended Online site
トラックバック:click here to visit www.ddhszz.com for free
トラックバック:Rollators uk
トラックバック:psychiatrist
トラックバック:Adhd Medication Pregnancy
トラックバック:http://daojianchina.com
トラックバック:Http://Jonpin.Com
トラックバック:Live togel
トラックバック:adult adhd diagnostic assessment and treatment
トラックバック:from the bezauberndeyorkiewelpen13359.blog4youth.com blog
トラックバック:use W 2atech here
トラックバック:Www.0471Tc.Com
トラックバック:80Cm American Fridge Freezer
トラックバック:gas safety certificate grace period
トラックバック:squareblogs.net`s blog
トラックバック:Bunk beds wood
トラックバック:var beställer man nytt körkort
トラックバック:Pasaran Togel Resmi
トラックバック:Https://Muse.Union.Edu/2020-Isc080-Roprif/2020/05/29/Impact-Of-Covid-On-Racial-Ethnic-Minorities/Comment-Page-2951
トラックバック:best Leather sofa
トラックバック:best folding treadmills
トラックバック:adhd Test
トラックバック:American Retro Fridge Freezer
トラックバック:www.zitacomics.be
トラックバック:topp-pope.Technetbloggers.de
トラックバック:Click Home
トラックバック:https://avtoray.ru/bitrix/redirect.php?goto=https://cooperschicago.com
トラックバック:private Adhd assessment london
トラックバック:togel Singapura
トラックバック:mini ignition key
トラックバック:please click Nerdgaming
トラックバック:corner Sectional Couch
トラックバック:http://marihalliday.stellar-realestate.com/ssirealestate/scripts/searchutils/gotovirtualtour.asp?MLS=PA1200957&ListingOffice=PAPKWPR08&RedirectTo=Https://www.sofasandcouches.com/
トラックバック:Best Twin Over Twin Bunk Beds
トラックバック:permainan tebak angka
トラックバック:rentry.co writes
トラックバック:2003 mini Cooper key fob replacement
トラックバック:https://glamorouslengths.com/
トラックバック:Ghost Immobiliser 2
トラックバック:https://mkgassafety15076.dsiblogger.com
トラックバック:advice here
トラックバック:rcin.org.pl
トラックバック:Small single metal beds
トラックバック:www.google.com.uy
トラックバック:dewalt power Tools For Sale
トラックバック:Velvet couches for sale
トラックバック:Falschgeld Kaufen Online
トラックバック:http://bbs.darkml.Net
トラックバック:https://git.fuwafuwa.moe/stringtanker18
トラックバック:Gas safe certificate check
トラックバック:https://podiavac.ru/bitrix/redirect.php?goto=https://jazzagecomics.com
トラックバック:service.aicloud.fit
トラックバック:Lg appliances
トラックバック:mental Health assessment test
トラックバック:The Best Refrigerator Brand
トラックバック:Bariatric Wheelchair
トラックバック:best single electric oven
トラックバック:small treadmill with incline
トラックバック:Two seater Leather Sofa
トラックバック:childrens bunk Beds
トラックバック:L Shaped Bunk Bed Uk
トラックバック:Walking aid
トラックバック:Lungeshovel19.Werite.Net
トラックバック:Buckingham Gas Safe Registered Engineer
トラックバック:discreet falschgeld Kaufen
トラックバック:m.en.socksappealshop.com
トラックバック:How To Get Assessed For Adhd
トラックバック:just click Technetbloggers
トラックバック:click through the following post
トラックバック:pasang togel Aman
トラックバック:power Tools kit set
トラックバック:https://olderworkers.com.au/
トラックバック:iapple.Minfish.com
トラックバック:0Lq70ey8yz1b.com
トラックバック:https://articlescad.Com/
トラックバック:click hyperlink
トラックバック:childrens cabin bunk Beds
トラックバック:https://King-wifi.win
トラックバック:best hob uk
トラックバック:american Integrated fridge freezer
トラックバック:Treadmills Uk
トラックバック:american fridge freezer plumbed ice and water
トラックバック:shio togel
トラックバック:judi angka Terpercaya
トラックバック:Situs Judi Terbaik
トラックバック:Bunk Bed Single On Top Double On Bottom
トラックバック:tunnel Containers
トラックバック:http://5oclock.ru/user/seahen3/
トラックバック:Lzdsxxb.Com
トラックバック:https://requiemlibraryrp.com/proxy.php?link=https://sifuromain.com/
トラックバック:psychiatrist Assessment near me
トラックバック:GefäLschte währung bestellen
トラックバック:Retro American Style Fridge Freezers Uk
トラックバック:Add And Adhd In Women
トラックバック:more about Palungjit
トラックバック:adhd And anxiety symptoms
トラックバック:Https://rentry.co/9oytnqrc
トラックバック:Related Home Page
トラックバック:adhd Adults test
トラックバック:Bunk beds bunk
トラックバック:www.yya28.com
トラックバック:two seater fabric sofa Uk
トラックバック:lg refrigeration
トラックバック:Annunciogratis post to a company blog
トラックバック:fridge freezer sale uk
トラックバック:Cabin Bed
トラックバック:More methods
トラックバック:Bbs.wj10001.com
トラックバック:delphi.larsbo.org`s statement on its official blog
トラックバック:프라그마틱 정품인증
トラックバック:click this link here now
トラックバック:Window Glass repairs
トラックバック:click here.
トラックバック:avigard24.Ru
トラックバック:adress transportstyrelsen
トラックバック:atavi.Com
トラックバック:snohako.Com
トラックバック:Cooking Solutions
トラックバック:https://Www.demilked.Com
トラックバック:Double door Vs french door Fridge
トラックバック:https://Trade-britanica.trade
トラックバック:arinteg.Ru
トラックバック:cabin Bed storage
トラックバック:2 in 1 Pushchair
トラックバック:built-In microwave for wall unit
トラックバック:https://get-social-now.com/
トラックバック:Getting A Psychiatric Assessment
トラックバック:bbs.theviko.com
トラックバック:Unit.Igaoche.Com
トラックバック:forums.Finalfantasyd20.com
トラックバック:www.Play56.net
トラックバック:deutschessprachdiplom08933.shopping-Wiki.com
トラックバック:adhd treatment for adult women
トラックバック:more about hikvisiondb.webcam
トラックバック:cheap frost free fridge freezers
トラックバック:Folding Treadmill uk
トラックバック:island cooker extractor
トラックバック:Who Adhd Assessment
トラックバック:chest freezer With drawers uk
トラックバック:https://clashofcryptos.trade/wiki/15_Secretly_Funny_People_In_BuiltIn_Oven_And_Microwave
トラックバック:topper mattress
トラックバック:Adhd How To Get Diagnosed
トラックバック:sneak a peek here
トラックバック:beställa Nytt körkort
トラックバック:Microwaves Integrated
トラックバック:Blom-Parrish-2.Technetbloggers.De
トラックバック:single electric oven And grill
トラックバック:wine Fridge integrated
トラックバック:bulit In oven
トラックバック:Www.google.com.co
トラックバック:adhd Private diagnosis cost
トラックバック:language evaluation
トラックバック:Adhd Assessment Uk Online
トラックバック:use Yanyiku here
トラックバック:acheter un permis de conduire Avec paypal
トラックバック:Samsung refrigerator Models
トラックバック:adult Toys Pink
トラックバック:hull-rye-2.technetbloggers.de
トラックバック:adult Toys for sale
トラックバック:Adhd diagnosis adult Uk
トラックバック:autoboss.lv
トラックバック:Https://3Ads.Eu/
トラックバック:Best refrigerator company
トラックバック:stolen Car Keys what To do
トラックバック:goethe-Zertifikat b2 online kaufen
トラックバック:Masturbator Max 2
トラックバック:add diagnosis as an adult
トラックバック:retro small fridge freezer
トラックバック:written by www.maanation.com
トラックバック:visit this site right here
トラックバック:에볼루션코리아
トラックバック:Gas safety engineer Buckingham
トラックバック:Adult Sex Toys dildos
トラックバック:sex realistic dolls
トラックバック:fridge freezers for Sale uk
トラックバック:Fridge Freezer American
トラックバック:link
トラックバック:american-style fridge freezers
トラックバック:go to Google
トラックバック:range hood for island
トラックバック:KöRkort Cv
トラックバック:black island Cooker hoods
トラックバック:Realistic sex doll reviews
トラックバック:Best Kids Bunk Beds
トラックバック:füHrerschein Kaufen darknet
トラックバック:velvet sectional Couch
トラックバック:how To get assessed for adhd uk
トラックバック:Https://Maps.Google.Cat
トラックバック:testing for adult adhd
トラックバック:에볼루션 바카라 사이트
トラックバック:wood Loft bed With Stairs
トラックバック:Adhd Assessments
トラックバック:Built in fridge freezers 60/40
トラックバック:builtin Oven
トラックバック:robot vacuum Cleaners best
トラックバック:Robot Cleaner With Mop
トラックバック:Best Refrigerator uk
トラックバック:http://www.lawshare.tw/home.php?mod=space&uid=323323
トラックバック:Treadmill fold flat
トラックバック:bunk bed with stairs and desk
トラックバック:microwave with grill built in
トラックバック:Private Assessment For Adhd Uk
トラックバック:private adhd Assessment
トラックバック:https://ehrsgroup.com/Employer/Evolution-korea/
トラックバック:https://championsleage.review/wiki/Ten_Things_You_Learned_About_Kindergarden_To_Help_You_Get_Recliner_Sofa_Brown_Leather
トラックバック:callesen-koenig.thoughtlanes.net
トラックバック:Adhd adult diagnosis uk
トラックバック:프라그마틱 슬롯 체험
トラックバック:Single Oven Dimensions
トラックバック:Https://King-Wifi.Win/Wiki/10_Top_Facebook_Pages_Of_All_Time_Concerning_Robot_Vacuums_With_Mop
トラックバック:Adhd Assessment Scale – 5
トラックバック:Super realistic sex doll
トラックバック:robot vacuums with mop
トラックバック:lovense for man
トラックバック:Childrens Mid Sleeper Bunk Beds
トラックバック:Adms.Hket.com
トラックバック:Male Toys
トラックバック:Most Realistic looking sex doll
トラックバック:realisticsex dolls
トラックバック:how to use a Rabbit sex toy
トラックバック:sofas For sale
トラックバック:private Mental health Assessment
トラックバック:Frost Free French Door Fridge Freezer
トラックバック:add symptoms in women
トラックバック:Livebookmark.Stream
トラックバック:mental health assessment psychiatrist
トラックバック:gas safety Checks Newport Pagnell
トラックバック:robot vacuum and mop
トラックバック:small 2 seater fabric sofa
トラックバック:Portable Electric treadmill
トラックバック:robots that vacuum and mop
トラックバック:www.laba688.com
トラックバック:Adhd assessment
トラックバック:adhd diagnosis guidelines
トラックバック:Best robot vacuum uk
トラックバック:treadmill With Incline
トラックバック:Https://telegra.ph/20-Insightful-Quotes-About-ADHD-Medication-Pregnancy-11-14
トラックバック:italianculture.net wrote
トラックバック:Fridge Price Samsung
トラックバック:Mid Cabin Bed With Wardrobe
トラックバック:bunk bed With stairs And Drawers
トラックバック:longisland.Com
トラックバック:S.Bea.Sh
トラックバック:gas safe Engineer Buckingham
トラックバック:https://www.google.sc/url?q=https://telegra.ph/5-Private-ADHD-Diagnosis-Tips-You-Must-Know-About-For-2023-09-13
トラックバック:adult Women toys
トラックバック:adult Toys Rabbit
トラックバック:https://git.Fuwafuwa.moe/aprilknee73
トラックバック:Realistic Love Doll
トラックバック:Bluetooth Adult toys
トラックバック:www.tanzlife.Co.tz
トラックバック:Best buy robot vacuum
トラックバック:private psychiatric assessment uk
トラックバック:http://www.hotwives.cc/trd/out.php?url=https://Tangguifang.Dreamhosters.com/comment/html/?1294452.html
トラックバック:top ten fridge brands
トラックバック:http://zhongneng.net.cn/home.php?mod=space&uid=376774
トラックバック:Island Extractor Hoods
トラックバック:http://www.Hebian.cn
トラックバック:american style fridge Freezer retro
トラックバック:robot vacuum best
トラックバック:adhd Test for women
トラックバック:Robot vacuum Uk
トラックバック:adhd hyperactivity symptoms in adults
トラックバック:read this blog post from Trademarket
トラックバック:non drug treatment For Adhd
トラックバック:have a peek at these guys
トラックバック:Mitsubishi French Door Fridge With Ice Maker
トラックバック:https://squareblogs.Net
トラックバック:integrated ovens for Sale
トラックバック:electronic car key replacement
トラックバック:online casino deposit bonus
トラックバック:single oven fan
トラックバック:Are Adhd Meds Covered By Ohip
トラックバック:Rock8899.Com
トラックバック:Single bunk Bed Cheap
トラックバック:sex toys for adults
トラックバック:Mens adult toys
トラックバック:best Bunk bed Design
トラックバック:Oven Uk
トラックバック:diagnose adhd
トラックバック:Adult sexual toy
トラックバック:check out this one from git.jilugo.com
トラックバック:women Adult Toys
トラックバック:contestalert.in
トラックバック:Psychiatric assessments
トラックバック:Suggested Browsing
トラックバック:Best medication for adhd
トラックバック:Nomor togel
トラックバック:Casino Alarabi
トラックバック:trade-britanica.trade
トラックバック:Buy Website Traffic
トラックバック:car keys repair near me
トラックバック:Floor Washing Robot
トラックバック:adhd Tests
トラックバック:treat adhd without medication adults
トラックバック:adhd medication Ritalin
トラックバック:24catalog.By
トラックバック:에볼루션사이트
トラックバック:automatic vacuum and mop robot
トラックバック:https://designgiant46.bravejournal.net
トラックバック:can general practitioners prescribe adhd medication
トラックバック:Casinos that accept crypto
トラックバック:프라그마틱 무료체험 메타
トラックバック:mobility Scooter for Car Boot
トラックバック:79bo.cc
トラックバック:adult sex toys for Men
トラックバック:best vibrating butt plug
トラックバック:robot Hoover and Mop
トラックバック:best adult male toys
トラックバック:Adult mens toy
トラックバック:Visit Vrwant
トラックバック:www.demilked.com explained in a blog post
トラックバック:More Bonuses
トラックバック:extractor fans For kitchen islands
トラックバック:www.Fluencycheck.com
トラックバック:realisticsex doll
トラックバック:most expensive realistic Sex doll
トラックバック:Doctor Windows
トラックバック:adult adhd in women
トラックバック:Adhd in women symptoms
トラックバック:double chaise sectional
トラックバック:what happens if adhd is left untreated in adults
トラックバック:Car-Key-Replacement49744.Blgwiki.Com
トラックバック:Best Ovens And Hobs
トラックバック:fob
トラックバック:self assessment adhd test
トラックバック:Mercedes Key Repair
トラックバック:baumatic 50 50 integrated fridge Freezer
トラックバック:https://lovewiki.faith/
トラックバック:Cheap Cot Beds
トラックバック:Kia picanto Key
トラックバック:non prescription adhd Medication uk
トラックバック:Fiat Car Key Replacement
トラックバック:honda Replacement Key cost
トラックバック:Https://Qna.Lrmer.Com
トラックバック:best Bunk Bed
トラックバック:Adhd Medication For Women
トラックバック:https://stuart-carlsen.thoughtlanes.net/where-can-you-get-the-best-black-dual-fuel-range-cooker-information/
トラックバック:dual fuel range cookers ireland
トラックバック:beställa körkort app betalning
トラックバック:Green power scooter
トラックバック:gas central heating engineers
トラックバック:Http://rutelochki.ru/user/hatelace0
トラックバック:nora adult Toy
トラックバック:Where To get assessed for adhd
トラックバック:Vishivalochka.Ru
トラックバック:l shaped adult Bunk beds
トラックバック:http://q.044300.net/home.php?mod=space&Uid=1048524
トラックバック:dig this
トラックバック:Masterbation toys For Men
トラックバック:private adhd assessment Edinburgh cost
トラックバック:Symptoms of Untreated Adhd
トラックバック:https://wayranks.com/
トラックバック:bunk Bed L shape
トラックバック:couches on sale
トラックバック:gas safety Inspection Milton Keynes
トラックバック:Lamborghini Smart key
トラックバック:Audi a3 replacement key
トラックバック:Island Extractor Fan Kitchen
トラックバック:polydog.org
トラックバック:프라그마틱 환수율
トラックバック:you can try Telegra
トラックバック:40.118.145.212
トラックバック:discover this
トラックバック:describes it
トラックバック:best robot vacuum that mops
トラックバック:Double Headed sex toy
トラックバック:adult toys for woman
トラックバック:Online Adult Toys
トラックバック:best adult sex toys
トラックバック:New Lg Fridge
トラックバック:Best Adult Toy
トラックバック:infant Car seat newborn
トラックバック:fridges freezers fridge
トラックバック:Gas Engineers Buckingham
トラックバック:what is the best brand of refrigerator
トラックバック:Cooking convenience
トラックバック:Leather sofa set
トラックバック:Samsung American Fridge Freezer Black
トラックバック:Best robot vacuum and mop
トラックバック:Man Adult Toy
トラックバック:replacement key for audi a3
トラックバック:weeks-morin-2.blogbright.net
トラックバック:hyundai sonata car key replacement
トラックバック:Check Out historydb.date
トラックバック:metal Bunk Beds With storage
トラックバック:Replacing Mercedes Key
トラックバック:fiat 500 key replacement cost
トラックバック:shallow american fridge Freezer
トラックバック:Who lost key to car Citroen
トラックバック:Leather Couches Under $500
トラックバック:male sex masturbator
トラックバック:https://teatome.ru/
トラックバック:fridge brands
トラックバック:www.kaseisyoji.com
トラックバック:Adult anal sex toys
トラックバック:Best brand Of refrigerator
トラックバック:fridge With water and ice maker
トラックバック:retro fridge and Freezer
トラックバック:justbookmark.win
トラックバック:Best Male Auto Masturbator
トラックバック:Lake-goode-2.thoughtlanes.Net
トラックバック:Fridge-freezers35876.celticwiki.com
トラックバック:http://rutelochki.ru/user/Toothcalf0/
トラックバック:robot vacuum That mops
トラックバック:robot Mop
トラックバック:how to get gas Safety certificate
トラックバック:to minecraftcommand.science
トラックバック:robot vacuum with mop
トラックバック:bmw replacement car Keys
トラックバック:Best Robot Vacuum
トラックバック:gas safe registered engineer Newport Pagnell
トラックバック:Corduroy Sectional Couch
トラックバック:replacement Hyundai key
トラックバック:folding Treadmill incline
トラックバック:kitchen island extractor
トラックバック:Male Masterbator Toy
トラックバック:bestäLla körkort internationellt
トラックバック:Adult toys Store
トラックバック:fastest electric Mobility scooter
トラックバック:men’s Adult Toys
トラックバック:repair key fob
トラックバック:mobility Scooter automatic Folding
トラックバック:Adult sex toys for women
トラックバック:retro fridge freezer frost free
トラックバック:Best Fridge Uk
トラックバック:https://clashofcryptos.trade/wiki/An_EasyToFollow_Guide_To_Integrated_Combi_Fridge_Freezer
トラックバック:Technetbloggers writes
トラックバック:veleco mobility scooters uk
トラックバック:best-bunk-beds43882.shotblogs.com
トラックバック:mobility Scooter folding lightweight
トラックバック:lsrczx.com
トラックバック:https://coursemaraca6.bravejournal.net/11-faux-pas-that-are-actually-okay-to-create-using-your-tall-Frost-free
トラックバック:adult toy shop Uk
トラックバック:Truelsen-Currin.Federatedjournals.Com
トラックバック:glass door lock repair
トラックバック:services
トラックバック:Bentley Key fob replacement
トラックバック:lightweight strollers
トラックバック:land rover key code
トラックバック:mazda 6 keys locked In car
トラックバック:bmw Key upgrade
トラックバック:key fob for bmw
トラックバック:car key lamborghini
トラックバック:Git.Slackjeff.Com.Br
トラックバック:Mobility Scooter Car Boot
トラックバック:bunk beds kids
トラックバック:Https://www.ky58.cc/dz/home.php?mod=space&uid=2778723
トラックバック:reviews over at www.hulkshare.com
トラックバック:adult Toys Dildos
トラックバック:Foldable Electric Mobility Scooter
トラックバック:Jogger prams
トラックバック:l shaped sleeper couch
トラックバック:Uk Adult Sex Toys
トラックバック:leather recliners for sale
トラックバック:Https://Git.Agent-Based.Cn
トラックバック:Collapsible Electric Mobility Scooter
トラックバック:https://enemark-tuttle.thoughtlanes.net/
トラックバック:Https://Git.Bubbleioa.Top/Topsadulttoys5918/Lynwood1992/Wiki/15-Surprising-Facts-About-Rabbit-Toy-Adult
トラックバック:best electric folding mobility Scooter
トラックバック:mouse click the up coming webpage
トラックバック:Robot hoover
トラックバック:green energy Mobility Scooters
トラックバック:Shop Front Glass Replacement
トラックバック:Sexdoll Realistic
トラックバック:Mens Masturbator toy
トラックバック:scientific-Programs.science
トラックバック:audi Spare key
トラックバック:blog post from writeablog.net
トラックバック:Robot vacuums Uk
トラックバック:service
トラックバック:New bmw keys
トラックバック:machines for Sex
トラックバック:Förnya KöRkort transportstyrelsen
トラックバック:compact travel Scooters
トラックバック:autonomous Vacuum
トラックバック:https://imoodle.win/wiki/Ten_Bed_With_A_Slide_Myths_You_Shouldnt_Share_On_Twitter
トラックバック:http://idea.informer.com/Users/leafsugar9/?what=personal
トラックバック:Squirming dildo
トラックバック:Adult toys For Penis
トラックバック:adult Sex Toys Online shop
トラックバック:50 50 Integrated Fridge
トラックバック:good Fridge brands
トラックバック:fridge freezer to Buy
トラックバック:Http://Ezproxy.Cityu.Edu.Hk/Login?Url=Https://Www.Alkhazana.Net/2024/08/30/What-To-Look-For-To-Determine-If-Youre-Ready-For-Kids-Bunk-Beds
トラックバック:automatic vacuum and mop
トラックバック:realistic sex doll prices
トラックバック:adult sex toy uk
トラックバック:Werite published a blog post
トラックバック:http://www.1moli.top/home.php?mod=space&uid=415093
トラックバック:lamborghini diablo Key
トラックバック:swanson-enemark.hubstack.net
トラックバック:Bmw spare Keys
トラックバック:hkg99
トラックバック:Scooters That Fold Up
トラックバック:second hand car boot Mobility scooters
トラックバック:Glamorouslengths.com
トラックバック:Brands Of Fridge Freezers
トラックバック:Marker-Mclean-3.Blogbright.Net
トラックバック:Gas safe heating engineer
トラックバック:emergency Gas engineer near me
トラックバック:fridge freezer In uk
トラックバック:electric wheelchairs foldable Lightweight
トラックバック:versatile Storage side by side Fridge freezer
トラックバック:read this post from telegra.ph
トラックバック:lg Refrigerators models
トラックバック:rollator walker with seat
トラックバック:White wooden bunk bed
トラックバック:What Is A Self Propelled Wheelchair
トラックバック:Outdoor Wheelchair
トラックバック:replacing ford key fob
トラックバック:Spare key for bmw
トラックバック:Jaguar xj key fob replacement
トラックバック:mercedes replacement key Cost
トラックバック:mazda 3 key replacement
トラックバック:bitspower.com
トラックバック:Midi Bed With Storage
トラックバック:fiat panda replacement key
トラックバック:single bed bunk Beds
トラックバック:canadian pharmaceuticals online
トラックバック:Http://Xojh.Cn/Home.Php?Mod=Space&Uid=2282242
トラックバック:compact electric scooters
トラックバック:additional resources
トラックバック:www.sf2.net
トラックバック:rangemaster french Style fridge freezer
トラックバック:Contemporary Side By Side Fridge Freezer
トラックバック:Best fridges uk
トラックバック:oversized wheelchair
トラックバック:are green power mobility scooters any good
トラックバック:Heavy Duty Rollator
トラックバック:Fridge Best Brand
トラックバック:telegra.ph’s website
トラックバック:Sturdy wheelchair
トラックバック:Rollator With Seat
トラックバック:griffin-cates.technetbloggers.de
トラックバック:maps.google.Com.qa
トラックバック:burnett-hvid-3.Technetbloggers.de
トラックバック:honda Motorcycle Key Replacement
トラックバック:Ferrari Remote Key
トラックバック:oak cabin bed
トラックバック:Http://Himawari-21.Com/?Wptouch_Switch=Desktop&Redirect=Https://Www.Ovensandhobs.Uk/
トラックバック:foldable Mobility Scooters for sale
トラックバック:Folding Mobility Scooters
トラックバック:Single Midi Bunk
トラックバック:4 wheel drive Electric mobility scooter
トラックバック:automated mobility
トラックバック:reviews over at Golden
トラックバック:hop over to these guys
トラックバック:chest freezer for outbuilding
トラックバック:lg american style fridge freezers uk
トラックバック:Small 50/50 Fridge Freezer
トラックバック:https://algowiki.win/wiki/post:10_healthy_seated_rollator_habits
トラックバック:Https://Frydge02843.Blogdomago.Com/
トラックバック:rehabilitation equipment
トラックバック:large American style fridge freezer
トラックバック:All terrain foldable Electric wheelchair
トラックバック:50/50 fridge freezer integrated Frost free
トラックバック:48 island range hood
トラックバック:scientific-programs.science post to a company blog
トラックバック:https://morphomics.science/
トラックバック:images.google.com.gt
トラックバック:Collapsible E Scooter
トラックバック:https://olderworkers.com.au/Author/rvxvx52sick5-marymarshall-co-Uk
トラックバック:Car boot mobility scooters
トラックバック:please click Sovren
トラックバック:electric Mobility scooter with seat for adults
トラックバック:Road Mobility
トラックバック:what Is the Best automatic folding mobility scooter
トラックバック:mobility power
トラックバック:fridge freezer collection
トラックバック:johansson-acevedo-2.thoughtlanes.net
トラックバック:bariatric transport wheelchair 400 lb capacity
トラックバック:bariatric wheelchair 400 lb capacity
トラックバック:understanding
トラックバック:vargas-Herrera.technetbloggers.de
トラックバック:reviews over at mobilityscooters55432.dailyblogzz.com
トラックバック:all terrain Folding electric wheelchair
トラックバック:bojsen-stilling-2.blogbright.net
トラックバック:blog post from Justpin
トラックバック:self propelled wheelchair Uk
トラックバック:gas Safe Registered Engineer near Me
トラックバック:automatic vacuum Cleaner and mop
トラックバック:http://www.annunciogratis.Net/author/Stockcirrus67
トラックバック:3 Wheel mobility scooters for sale
トラックバック:3 Wheel mobility scooter
トラックバック:4×4 electric mobility scooter
トラックバック:www.google.bt`s statement on its official blog
トラックバック:cheap Fridge freezer
トラックバック:Mccormick-Robb.Blogbright.Net
トラックバック:Retro American Fridge Freezer
トラックバック:Buy Cheap Fridges
トラックバック:Aluminium Wheelchair Ramps
トラックバック:Refrigerator Best Brand
トラックバック:Thebookmarkfree.Com
トラックバック:Basslace26.Bravejournal.Net
トラックバック:Folding Wheelchair
トラックバック:new post from writeablog.net
トラックバック:Retro American Fridge Freezers
トラックバック:foldable rollator with Seat
トラックバック:Mobility rollator with seat
トラックバック:Heavenarticle published an article
トラックバック:fridges66098.national-Wiki.com
トラックバック:Leather Sofas for sale near Me
トラックバック:oven integrated
トラックバック:travel mobility Scooters Sale
トラックバック:Https://Dougherty-Vega.Thoughtlanes.Net/This-Is-The-Intermediate-Guide-Towards-Green-Scooters/
トラックバック:scooter on pavement uk
トラックバック:دکتر فرزاد روشن ضمیر بهترین متخصص تغذیه
トラックバック:Luxury scooters
トラックバック:Where best Buy mobility Scooters near
トラックバック:french door liebherr fridge Freezer
トラックバック:Reclining Wheelchair
トラックバック:go to Thoughtlanes
トラックバック:homesite
トラックバック:https://freezers89664.sharebyblog.com
トラックバック:https://Sovren.media
トラックバック:green Power scooters
トラックバック:fatahal.com`s latest blog post
トラックバック:vinter-mejia.blogbright.net
トラックバック:which Fridge is Good
トラックバック:doctorsforum.ru
トラックバック:https://maps.google.gg/url?q=https://zenwriting.net/washisland00/how-gas-Fire-engineer-has-become-The-most-sought-after-trend-of-2024
トラックバック:new jersey manchester city
トラックバック:best pavement Mobility scooter
トラックバック:viagra 60 mg cost
トラックバック:upvc Window Repairs
トラックバック:reference
トラックバック:What Is the best chest freezer to buy
トラックバック:glass
トラックバック:Refrigerator of lg
トラックバック:https://corbett-damborg.hubstack.net/
トラックバック:Landlord Safety Certificate
トラックバック:which french door refrigerator has the best ice maker
トラックバック:https://pediascape.science/
トラックバック:medical Foldable lightweight Rollator
トラックバック:lightweight wheelchair foldable
トラックバック:Bariatric wheelchair 26 Inch seat
トラックバック:Lightweight Bariatric wheelchair
トラックバック:Reinforced Wheelchair
トラックバック:Fridge Freezer Cheap
トラックバック:https://pattern-wiki.Win
トラックバック:Urban Scooters
トラックバック:https://Yogicentral.science
トラックバック:Integrated Single oven
トラックバック:images.google.td official website
トラックバック:Https://Www.Webwiki.Co.Uk/
トラックバック:cheapest american style fridge freezer
トラックバック:Click on bookmarkzones.trade
トラックバック:https://Bysee3.com
トラックバック:Mobility scooter for sale cheap
トラックバック:compravivienda.Com
トラックバック:Mobility scooter for shopping
トラックバック:lightweight Foldable rollator With seat
トラックバック:smeg French style fridge freezer
トラックバック:american style fridge freezer with ice and Water Dispenser
トラックバック:which refrigerator brand Is the best
トラックバック:Lightest Electric Folding Wheelchair
トラックバック:https://mymobilityscooters-uk13762.wikicarrier.com/58650/article_under_review
トラックバック:lightweight foldable Wheelchair
トラックバック:Best Hob
トラックバック:uk
トラックバック:click through the up coming website page
トラックバック:retro frost Free Fridge freezer
トラックバック:self propelled wheelchair with power assist
トラックバック:best automatic vacuum and mop
トラックバック:Black integrated microwave
トラックバック:Brennan-Cohen.Thoughtlanes.Net
トラックバック:are mobility scooters Allowed On road
トラックバック:gould-klinge-2.hubstack.net
トラックバック:refrigerators best Brands
トラックバック:large mobility scooters For sale
トラックバック:auto folding travel scooter
トラックバック:american style Fridge freezer
トラックバック:agree with this
トラックバック:4 wheel motorized Scooter
トラックバック:Freezers Samsung
トラックバック:http://nitka.by/user/jeffband8/
トラックバック:https://glamorouslengths.com
トラックバック:built in american fridge freezer
トラックバック:https://serrano-norton.hubstack.net
トラックバック:3 wheel electric mobility scooter For adults uk
トラックバック:mobilityscootersuk17261.blog-a-story.com
トラックバック:best auto folding mobility scooter uk
トラックバック:automatic folding travel Mobility Scooter
トラックバック:french Style Fridge Freezer
トラックバック:Best french door Fridge with ice maker
トラックバック:What Is The Best Small Chest Freezer To Buy
トラックバック:french style fridge freezer sale
トラックバック:best fridge Brand
トラックバック:Compact Electric Mobility Scooter
トラックバック:https://freezer89596.designi1.com/50648330/a-peek-inside-the-secrets-of-chest-freezer-deals
トラックバック:integrated fridge freezer with water ice dispenser
トラックバック:Installer
トラックバック:green power electric scooter
トラックバック:Google published an article
トラックバック:Http://Www.Eruyi.Cn/Space-Uid-55433.Html
トラックバック:Mobility scooter for sale
トラックバック:4 wheel auto folding scooter
トラックバック:realisticsexdoll
トラックバック:african grey parrots on sale
トラックバック:hipfield0.bravejournal.Net
トラックバック:cara bermain Togel
トラックバック:Private Psychiatry Practice
トラックバック:Adhd assessment for Adults
トラックバック:obtenir Le permis De conduire en france
トラックバック:führerschein online kaufen
トラックバック:https://wiki.imaginenetworksllc.com/
トラックバック:www.kedgebs-alumni.com
トラックバック:http://www.annunciogratis.net/author/listviola63
トラックバック:functional medicine psychiatrist near me
トラックバック:How much is Private psychiatry
トラックバック:great site
トラックバック:Priroda.naukapublishers.Ru
トラックバック:에볼루션 룰렛
トラックバック:http://open.podatki.Biz
トラックバック:buy african grey
トラックバック:körkort professionell
トラックバック:mental health Assesment
トラックバック:Https://maps.google.Hr/
トラックバック:Https://gitea.liquidrinu.com
トラックバック:https://minecraftcommand.science/profile/lookotter41
トラックバック:https://www.Nlvbang.com/
トラックバック:https://gitea.greyc3sa.net/falschgeldkaufenonline7777
トラックバック:How Do Adults Get Assessed For Adhd
トラックバック:Jaguar F Type Key Fob
トラックバック:Www.Raval.Ru
トラックバック:this content
トラックバック:buy a german shepherd puppy
トラックバック:Best auto locksmith Bedford
トラックバック:http://80.82.64.206/user/routecircle1
トラックバック:complexityzoo.net
トラックバック:https://lohmann-Andreassen-3.Blogbright.net
トラックバック:pocketpoison63.werite.Net
トラックバック:www.triciclo.se
トラックバック:Https://Wiki.Gta-Zona.Ru/Index.Php/Floreserlandsen8188
トラックバック:visit historydb.date here >>
トラックバック:macaw bird temperament
トラックバック:Going to Followbookmarks
トラックバック:Adhd Treatment For Adults Uk
トラックバック:Best Cot Beds
トラックバック:Adhd Symptoms in Adults females
トラックバック:Edazone blog article
トラックバック:best adhd medication for adults with Anxiety
トラックバック:Smarttechnika.Ru
トラックバック:Treatment For Anxiety Near Me
トラックバック:Custom realistic Sex doll
トラックバック:https://www.footballzaa.com/out.php?url=https://telegra.Ph/A-Journey-Back-In-Time-How-People-Talked-About-Gotogel-20-Years-Ago-02-06
トラックバック:Itkvariat.Com
トラックバック:Corner Recliner leather sofa
トラックバック:http://crmdaily.Ru
トラックバック:Power Tool Online
トラックバック:Nytt KöRkort Borttappat
トラックバック:achat de permis de Conduire en France
トラックバック:Couches For Sale Near Me
トラックバック:http://jade-crack.com/home.php?mod=space&Uid=1284926
トラックバック:ghost vehicle Immobiliser
トラックバック:Baby macaw buy
トラックバック:Schäferhund Beschützerinstinkt
トラックバック:http://www.0471tc.com/home.php?mod=space&Uid=1930069
トラックバック:https://dokuwiki.stream/
トラックバック:Power electric scooter
トラックバック:buy chest freezer uk
トラックバック:go to this site
トラックバック:Best crib For Newborn
トラックバック:please click Wj 10001
トラックバック:auto Folding Mobility scooters
トラックバック:best auto Masturbators
トラックバック:Best robot Vacuum cleaner UK
トラックバック:corgi gas engineer
トラックバック:adhd assessment Private
トラックバック:Telescoping wheelchair ramps
トラックバック:container suppliers
トラックバック:Bifold door Glass replacement
トラックバック:auto fold electric Wheelchair
トラックバック:Www.9Kuan9.com
トラックバック:simply click the next document
トラックバック:more about Wikimeglio
トラックバック:fridge freezers For sale
トラックバック:best manual treadmill Uk
トラックバック:add in Women test
トラックバック:Bookoffuck.Com
トラックバック:integrated Ovens And hobs
トラックバック:a2 motorradführerschein Online Erwerben
トラックバック:Körkort för internationellt Bruk
トラックバック:Ckxken.synology.me
トラックバック:images.google.com.Sv
トラックバック:cleaning robots for home
トラックバック:https://posteezy.com/Reasons-why-Link-login-gotogel-everyones-passion-2024
トラックバック:frenchbulldog54182.blogunok.com
トラックバック:american freezer Fridge
トラックバック:Blogbright blog article
トラックバック:www.V0795.com
トラックバック:http://gitlab.unissoft-grp.com:9880/pragmaticplay6438/leif2007/-/issues/1
トラックバック:acheter un vrai permis de Conduire européen
トラックバック:https://Pattern-wiki.win/
トラックバック:local
トラックバック:car Key replacement cost
トラックバック:wie kann Ich meinen führerschein kaufen
トラックバック:Assessment Of Psychiatric Patient
トラックバック:buy adhd Medication uk
トラックバック:Demilked.Com
トラックバック:psychiatrist private Near me
トラックバック:https://gorach.ru/bitrix/rk.php?goto=Https://expressdeutschekartes.Com
トラックバック:home exercise equipment best
トラックバック:sherman-bates-4.technetbloggers.de noted
トラックバック:프라그마틱 슬롯무료
トラックバック:Private Psychiatrist Near Me Uk
トラックバック:obtenir le permis de conduire français
トラックバック:welpen französische bulldogge kaufen
トラックバック:built in microwave oven combo
トラックバック:robot Vacuum cleaner Best
トラックバック:african grey parrot birds for sale
トラックバック:http://course.cpi-nis.kz
トラックバック:double prams With Large storage basket
トラックバック:Https://eastcoffee4.werite.net/
トラックバック:container delivery
トラックバック:Jaguar key fob Replacement
トラックバック:Prawo Jazdy B1
トラックバック:gogs.fytlun.com`s blog
トラックバック:Führerschein Kaufen legal in deutschland
トラックバック:Hob
トラックバック:timonpumba.ru
トラックバック:writes in the official telegra.ph blog
トラックバック:praktyka na motocyklu
トラックバック:macaw Bird online
トラックバック:Führerschein klasse A2 digital kaufen
トラックバック:landlord gas Safety certificate price
トラックバック:Https://Xs.Xylvip.Com/
トラックバック:u Pvc Doors and windows
トラックバック:bexopro.com
トラックバック:reviews over at marvelvsdc.faith
トラックバック:treadmills Home gym
トラックバック:upvc Doors and Windows
トラックバック:Sport Shkola 2makarova wrote
トラックバック:triple bunk beds with storage
トラックバック:FranzöSische Bulldogge Welpen
トラックバック:electrical Tools Online
トラックバック:Reali.Esport.Ge
トラックバック:french Doors with Side Windows
トラックバック:Http://jetboats.ru/
トラックバック:Adhd Titration
トラックバック:https://marvelvsdc.faith
トラックバック:Realistic sex doll sale
トラックバック:Reinrassiger Deutscher Schäferhund
トラックバック:robotic cleaner and mop
トラックバック:adult toys for him
トラックバック:deutscher schäferhund Zu verkaufen
トラックバック:www.nzdao.cn
トラックバック:electric automatic Folding 4-wheel mobility scooter
トラックバック:Git.Eivind.Tel
トラックバック:Duel fuel cooker
トラックバック:https://pricejumbo49.bravejournal.net/three-reasons-why-three-reasons-your-case-opening-battle-is-broken-and-how-to
トラックバック:Macaw bird Species
トラックバック:maps.google.com.ar
トラックバック:research by the staff of planforexams.com
トラックバック:http://120.zsluoping.cn
トラックバック:füHrerschein klasse a2 Digital bestellen
トラックバック:Acheter un permis de Conduire maintenant
トラックバック:situs togel terbaik
トラックバック:Https://Owen-Marsh-5.Blogbright.Net/
トラックバック:Owning a macaw
トラックバック:french Windows And doors
トラックバック:learn more about 58
トラックバック:leather Recliner couches
トラックバック:dngeislgeijx.homes
トラックバック:aboutdirectorofnursingjobs.com published a blog post
トラックバック:Adult adhd assessment uk
トラックバック:Https://Jszst.Com.Cn/Home.Php?Mod=Space&Uid=4407230
トラックバック:Rtkt.Ru
トラックバック:Vauxhall Diagnostic Near Me
トラックバック:private Adhd assessment peterborough
トラックバック:wooden Triple Bunk
トラックバック:Window Replacement cost
トラックバック:gas engineers newport Pagnell
トラックバック:knowing it
トラックバック:psychiatrist near me for depression
トラックバック:Autovin-Info.Com
トラックバック:Pet Macaws
トラックバック:linked webpage
トラックバック:https://maps.google.com.br/
トラックバック:https://hikvisiondb.webcam/wiki/10_Adult_Anal_Toys_Tips_All_Experts_Recommend
トラックバック:euro falschgeld kaufen
トラックバック:Integrated fridge freezer 50
トラックバック:Private psychatrist
トラックバック:replacement keys car
トラックバック:Tunnel Containers For Sale
トラックバック:squareblogs.net wrote
トラックバック:Cot with drawer and Mattress
トラックバック:Https://Posteezy.Com/5-Laws-Everybody-I-Will-Buy-Category-B-Driving-License-Should-Know
トラックバック:macaw Price
トラックバック:2 In 1 Pram And Pushchair
トラックバック:Click on Ksye
トラックバック:citroen picasso key replacement
トラックバック:learn here
トラックバック:kids tree house bed
トラックバック:stes.tyc.edu.tw
トラックバック:Therapy Psychiatrist near me
トラックバック:Online test for adhd Adults
トラックバック:Sumber Togel
トラックバック:Www.Metooo.Io
トラックバック:Mental Health Screening Online
トラックバック:http://4geo.ru
トラックバック:buyingamacawonline38253.angelinsblog.com
トラックバック:Repair bifold door top pivot
トラックバック:Dodd-mosegaard.mdwrite.net
トラックバック:Our Webpage
トラックバック:deutscher eu führerschein kaufen
トラックバック:bookmarkilo.com
トラックバック:more about rayadistribution.com
トラックバック:Cotbed With Drawer
トラックバック:https://toto-Macau84933.eqnextwiki.com
トラックバック:Buy power tool
トラックバック:spare car Keys Made
トラックバック:treadmills for Sale near me
トラックバック:Buy Uk Driving License Without Test
トラックバック:Non Medical treatment for adhd
トラックバック:www.gmm25.com
トラックバック:pedal Exerciser
トラックバック:anxiety disorders definition psychology
トラックバック:Https://Gobaza.Ru/Bitrix/Redirect.Php?Goto=Https://Charmingafricangreyparrotforsale.Com/
トラックバック:Togel Singapore
トラックバック:Https://Moparwiki.Win/Wiki/Post:From_All_Over_The_Web_20_Amazing_Infographics_About_Dewall_Tools
トラックバック:composite door repairs near Me
トラックバック:mirfeirverkov.ru’s website
トラックバック:car immobiliser Ghost
トラックバック:Torun.Praca.Gov.Pl
トラックバック:Watch
トラックバック:how to get Adhd meds Without diagnosis
トラックバック:electric three wheel mobility Scooter
トラックバック:Electric mobility scooter portable
トラックバック:füHrerschein Kaufen ohne vorkasse
トラックバック:skoda Octavia key
トラックバック:african greys for adoption
トラックバック:Full Posting
トラックバック:Gitlab.digineers.nl
トラックバック:adhd psychiatric assessment
トラックバック:Check Out Drom
トラックバック:articlement.com
トラックバック:French Door Windows
トラックバック:fold away Treadmill
トラックバック:best crypto Casino games
トラックバック:Refrigerator Manufacturers
トラックバック:click home page
トラックバック:foldable Power wheelchair
トラックバック:French Door With side Windows
トラックバック:metal Bunk bed Single
トラックバック:symptoms For Adhd in adults
トラックバック:rentry.co blog entry
トラックバック:nytt Körkort malmö
トラックバック:Https://Intern.Ee.Aeust.Edu.Tw/Home.Php?Mod=Space&Uid=1213372
トラックバック:upvc windows Locks
トラックバック:fitter
トラックバック:robot vacuum cleaners reviews
トラックバック:Self Propelled Wheelchairs For Sale Near Me
トラックバック:Single Oven Cooker
トラックバック:via suitrock1.bravejournal.net
トラックバック:treehouse bed with Storage
トラックバック:Bariatric Wheelchair Weight
トラックバック:E-harima.com
トラックバック:security-hub.com.ua
トラックバック:ergonomic Wheelchair
トラックバック:gas safety certificate how often
トラックバック:Patio Doors repair
トラックバック:Proalmaz.Ru
トラックバック:kann man legal einen führerschein kaufen
トラックバック:psychiatrist adhd testing near me
トラックバック:best integrated combination microwave
トラックバック:upvc windows repair
トラックバック:Car Remote Replacement Cost
トラックバック:Sexdolls
トラックバック:treadmill Folding Incline
トラックバック:Swedish-Drivers-License91166.Webdesign96.Com
トラックバック:psychiatrist private practice near Me
トラックバック:Vad äR B1 KöRkort
トラックバック:cat flap fitting near me
トラックバック:Adhd Test Adults
トラックバック:2016 kia optima key replacement cost
トラックバック:make spare car key
トラックバック:FüHrerschein Klasse A2 Online Kaufen
トラックバック:macaw pet
トラックバック:cryingbebe.Com
トラックバック:consultant Psychiatrist near Me
トラックバック:Corgi Gas Safe Engineers
トラックバック:Mystery Box opening
トラックバック:Adhd Assessments For Adults Near Me
トラックバック:Visit Homepage
トラックバック:best Power tool kit
トラックバック:find more
トラックバック:http://80.82.64.206/user/rockpatch9
トラックバック:Talking african grey parrot for sale
トラックバック:https://digitaltibetan.win/wiki/post:five_things_you_dont_know_about_leather_couch_electric_recliner
トラックバック:Composite Door Lock Replacement
トラックバック:https://peatix.com/user/25000334
トラックバック:from the championsleage.review blog
トラックバック:Acheter un permis de conduire français
トラックバック:gas safety certificates Milton keynes
トラックバック:36.7.84.146
トラックバック:https://gotogel77902.humor-blog.com/
トラックバック:Maps.Google.Com.Tr
トラックバック:Ghost immobilisers
トラックバック:Macaw bird For sale
トラックバック:prev
トラックバック:https://www.northwestu.edu/
トラックバック:Volvo Truck key fob
トラックバック:https://ceshi.xyhero.com
トラックバック:mkf.sportedu.ru
トラックバック:renault key replacement near Me
トラックバック:Bbs.161Forum.Com
トラックバック:Jual Togel Online
トラックバック:https://theflatearth.win/wiki/Post:20_Top_Tweets_Of_All_Time_About_Adult_ADHD_Symptoms
トラックバック:by Werite
トラックバック:https://moparwiki.win/
トラックバック:Exercise Machine
トラックバック:Best Bunk Beds For Heavy Adults
トラックバック:Glass Window Door
トラックバック:Https://fewpal.com/
トラックバック:car key immobiliser repair
トラックバック:freestanding Frost free Fridge freezer
トラックバック:al.unlock-hosting.com
トラックバック:Https://kjer-Stryhn-2.blogbright.Net/
トラックバック:Front doors with Windows
トラックバック:https://peatix.com/user/25662451
トラックバック:online mystery box opening
トラックバック:read this post from ondashboard.win
トラックバック:trafikverket Borås förnya köRkort
トラックバック:adcock-Rindom-2.technetbloggers.de
トラックバック:zoneofgames.ru
トラックバック:More Tips
トラックバック:treadmills For sale
トラックバック:lg american Style fridge freezers
トラックバック:head to Mdwrite
トラックバック:car remote key repair near me
トラックバック:folding Window doors
トラックバック:African Grey Parrot
トラックバック:best electric Folding wheelchair
トラックバック:Faux Leather Sofa
トラックバック:just click anzforum.com
トラックバック:https://www.Northwestu.edu/?url=https://pattern-wiki.win/wiki/where_will_lost_spare_car_key_be_1_Year_from_what_is_happening_now
トラックバック:glass Replacement in Windows
トラックバック:https://wifidb.science/wiki/The_Most_Pervasive_Problems_With_Windows_Doors_Upvc
トラックバック:acheter Un permis de conduire rapidement
トラックバック:Upvc Door Repairs Eastleigh
トラックバック:online casino crypto
トラックバック:http://rvolchansk.ru/
トラックバック:audi etron Key
トラックバック:https://rentry.co/
トラックバック:cheap dual fuel range cookers
トラックバック:Violinsuede30.Werite.Net
トラックバック:visit zhongneng.net.cn here >>
トラックバック:Double Glazing Repairs Eastleigh
トラックバック:dp360.ru
トラックバック:mid rise Bunk bed
トラックバック:acheter un permis de conduire avec une Carte de créDit
トラックバック:sash Windows Aylesbury
トラックバック:kup prawo jazdy A1
トラックバック:harder-connolly.Federatedjournals.Com
トラックバック:upvc Door panels Near me
トラックバック:http://yerliakor.com
トラックバック:http://italianculture.Net
トラックバック:double glazed panes
トラックバック:https://git.fuwafuwa.moe/leafturret3
トラックバック:Https://snider-bolton-2.hubstack.Net/why-you-should-concentrate-on-improving-psychiatrists-near-me-1735986048/
トラックバック:look here
トラックバック:Mattress Toppers For Sale
トラックバック:best vacuums
トラックバック:Finding A Psychiatrist Near Me
トラックバック:Werite’s website
トラックバック:go to telegra.ph
トラックバック:stay with me
トラックバック:Composite front Door replacement
トラックバック:murdock-fischer-2.technetbloggers.de
トラックバック:Mini bulldogge kaufen
トラックバック:Automated Cleaning
トラックバック:Container Conversion Cost
トラックバック:golf.Se
トラックバック:king-wifi.win said
トラックバック:what Is gas safety Certificate
トラックバック:use click4r.com
トラックバック:It-Telkom99592.Wikikali.Com
トラックバック:http://istartw.lineageinc.com/home.Php?mod=space&Uid=3574022
トラックバック:Best Power Tool
トラックバック:private psychiatrist
トラックバック:www.usamofu.com
トラックバック:image source
トラックバック:Bi Fold Door Repairs
トラックバック:https://scientific-programs.science/wiki/Responsible_For_An_Bandar_Togel_Terpercaya_Budget_Twelve_Top_Tips_To_Spend_Your_Money
トラックバック:stationary Bike Exercise
トラックバック:Porsche Adas
トラックバック:cooker Hood island
トラックバック:double chaise couch
トラックバック:Katalog.czasopism.pl blog article
トラックバック:Www-Iampsychiatry-Com73573.Sunderwiki.Com
トラックバック:Cot bedside
トラックバック:anotepad.com
トラックバック:macaw care guide
トラックバック:https://king-wifi.win/wiki/a_peek_at_cheap_power_toolss_secrets_of_cheap_power_tools
トラックバック:bbs.lingshangkaihua.com
トラックバック:best auto locksmiths in milton keynes
トラックバック:online Führerschein A2 kaufen
トラックバック:new samsung Refrigerator
トラックバック:kup prawo jazdy Kat A online
トラックバック:visit xxh5gamebbs.uwan.com now >>>
トラックバック:l-shaped bunk beds
トラックバック:mouse click on www.chovinh.com
トラックバック:permis de Conduire Français abordable
トラックバック:vauxhall keys cut
トラックバック:30ft shipping containers
トラックバック:interior decor
トラックバック:Online füHrerschein a2 bestellen
トラックバック:Skutery Prawo jazdy
トラックバック:French Door Fridge Costco
トラックバック:Macaw bird training
トラックバック:fisher and paykel french door integrated Fridge
トラックバック:exercise Cycle for sale
トラックバック:hobs And Ovens
トラックバック:Portable wheelchair Ramp for Van
トラックバック:Sex Machine On Sale
トラックバック:fridges with water Dispenser
トラックバック:Rollator Walker With Seat And Basket
トラックバック:folding power wheelchair
トラックバック:findhaunts.com
トラックバック:https://images.Google.ad
トラックバック:Nice Mental health assessment
トラックバック:Buy An Old German Shepherd Dog
トラックバック:bbs.xinhaolian.com
トラックバック:installed
トラックバック:https://images.Google.com.na/url?q=https://loveengine46.bravejournal.net/10-things-youve-learned-about-preschool-Thatll-help-you-understand-leg
トラックバック:ignition key replacement
トラックバック:Cleaning Robots
トラックバック:Driving-lessons64046.wikiadvocate.com
トラックバック:Https://fatahal.com/
トラックバック:parrots to buy
トラックバック:https://opensourcebridge.science/wiki/What_Is_Rollator_With_Seat_Uk_To_Use_It
トラックバック:Audi Key Replacement Near Me
トラックバック:lightweight 3 Wheel buggy
トラックバック:https://pstgu.ru
トラックバック:power tool Stores near me
トラックバック:https://heavenarticle.com
トラックバック:psychiatry assessment uk
トラックバック:how to get adhd Diagnosis uk
トラックバック:En.Iamshop-Online.com
トラックバック:Findmassleads writes
トラックバック:signs and symptoms Of adhd
トラックバック:Wooden Windows High wycombe
トラックバック:sushitwig10.werite.net
トラックバック:window and glass repair
トラックバック:Bifold Door Seal Replacement
トラックバック:best Robot vacuum black friday
トラックバック:Www.esato.com
トラックバック:patio door frame repair
トラックバック:Kupno Prawa Jazdy Kat B
トラックバック:mobility scooters near me for Sale
トラックバック:Gp Adhd Assessment
トラックバック:redirect to imoodle.win
トラックバック:situs Betting togel
トラックバック:Recommended Looking at
トラックバック:wownsk-Portal.ru
トラックバック:clovis yorkshire terrier kaufen
トラックバック:http://www.Jsgml.top
トラックバック:window seal replacement
トラックバック:how to get a New honda key Fob
トラックバック:mini Macaw price
トラックバック:travel Cot bedside crib
トラックバック:Wd.Sharethis.Com
トラックバック:Führerschein a2 online kaufen
トラックバック:Ways To Treat Adhd
トラックバック:ghost Installer
トラックバック:cat Flap fitters
トラックバック:https://maps.google.com.ua/
トラックバック:automatic vacuum Cleaner
トラックバック:nutris.net writes
トラックバック:togel Hk
トラックバック:double bed And single Bunk bed
トラックバック:buy scarlet Macaw
トラックバック:https://c.vc.sb/falschgeldkaufenonline4118
トラックバック:https://zenwriting.net
トラックバック:Ghost 11 Immobiliser
トラックバック:https://wikimapia.org/external_link?url=https://ucgp.jujuy.edu.ar/profile/peafrog71
トラックバック:best robot hoover
トラックバック:krasnodar.rusklad.ru
トラックバック:adult sex toys Sale
トラックバック:small Sectionals for Sale
トラックバック:Going at Telegra
トラックバック:information from digiprom.live
トラックバック:Exercise bicycles for sale
トラックバック:learn the facts here now
トラックバック:Antique Chesterfield
トラックバック:Botdb explained in a blog post
トラックバック:gitea.Msadb.cn
トラックバック:google.gr
トラックバック:case battle win
トラックバック:Walker Rollator With Seat
トラックバック:Uk Driving License Requirements
トラックバック:Brand Of refrigerator
トラックバック:precise cooking built in ovens
トラックバック:Moser-Rasmussen.Technetbloggers.De
トラックバック:Permis de conduire Sans Passer l’examen
トラックバック:how to self propel a wheelchair
トラックバック:Https://Kopa-Ett-Korkort45371.Idblogz.Com/
トラックバック:from the www.youtube.com blog
トラックバック:toys Adult
トラックバック:Togel Sgp
トラックバック:https://altaprom.ru:443/bitrix/redirect.php?goto=https://kartaxpresspoland.com/
トラックバック:top 5 Robot Vacuum
トラックバック:프라그마틱 정품확인방법
トラックバック:Sex Adult Toys
トラックバック:jazda Na Skuterze
トラックバック:Clean Smart robot
トラックバック:no title
トラックバック:Composite door installer Birmingham
トラックバック:battle case Csgo
トラックバック:online mental Health assessment
トラックバック:Buy german shepherd Puppies
トラックバック:What Is Mental Health Assessment
トラックバック:browse around here
トラックバック:abel-gallagher.mdwrite.Net
トラックバック:Http://Www.Kratc.Com/Bbs/Home.Php?Mod=Space&Uid=194221
トラックバック:robot vacuum cleaner reviews
トラックバック:online shop füR falschgeld
トラックバック:https://gitea-bg.site/repairmywindowsanddoors6761/door-repairman-near-me9101/wiki/20-Tips-To-Help-You-Be-More-Effective-At-Sash-Window-Repair
トラックバック:Http://lineyka.org/
トラックバック:my.Effairs.at
トラックバック:Going At this website
トラックバック:Small integrated microwave
トラックバック:Suggested Website
トラックバック:remote control vacuum cleaner
トラックバック:Echten Deutschen FüHrerschein Kaufen
トラックバック:kurs jazdy Na motocyklu a1
トラックバック:Https://Ai-Db.Science
トラックバック:replacing honda Key fob
トラックバック:https://Www.sewosoft.de/baroola6315
トラックバック:konspekt nauki jazdy Na Motorze
トラックバック:Doctor Window
トラックバック:compact travel stroller
トラックバック:read this blog post from wwwiampsychiatrycom87822.sharebyblog.com
トラックバック:by lawshare.tw
トラックバック:Bmw Key Fob
トラックバック:bunk beds For adults with storage
トラックバック:Offices And Studios Containers
トラックバック:diagnostic Criteria For adult adhd
トラックバック:more about Youtube
トラックバック:ignition Key repair near me
トラックバック:http://bbs.lingshangkaihua.Com/
トラックバック:togel Terpercaya
トラックバック:api.shipup.co
トラックバック:prediksi angka togel
トラックバック:gefälschtes geld kaufen erfahrungen
トラックバック:just click forum.spaceexploration.org.cy
トラックバック:sectional Sofa Bed pull out
トラックバック:White Triple bunk bed
トラックバック:falschgeld drucken Lassen
トラックバック:Best Oven
トラックバック:Dementia depression Treatment
トラックバック:https://click4r.com
トラックバック:https://www.instapaper.com/
トラックバック:Adhd Assessment cost Uk
トラックバック:Togel terbaik
トラックバック:Thrusting adult Toy
トラックバック:case battles
トラックバック:American Fridge Freezer Ice Maker No Plumbing
トラックバック:pavement Mobility scooters Uk
トラックバック:Https://Hougaard-Svendsen.Thoughtlanes.Net
トラックバック:How Adhd Is Diagnosed In Adults
トラックバック:Git.Cacpaper.Com
トラックバック:automingwei.com
トラックバック:Dgtherapy.Com
トラックバック:new mobility Scooters for sale
トラックバック:Blue Macaw Bird Price
トラックバック:https://www.metooo.io
トラックバック:go to www.bioguiden.se
トラックバック:click here to visit jonpin.com for free
トラックバック:Vblogetin wrote
トラックバック:https://domain.opendns.com/fuehrerscheinn.com
トラックバック:tunnel Container For Sale
トラックバック:gitlab.flyingmonkey.cn
トラックバック:KöPa KöRkortsbevis
トラックバック:puremarket.Ru
トラックバック:adhd Burnout physical symptoms
トラックバック:read here
トラックバック:green power scooter reviews
トラックバック:cheap single Buggy
トラックバック:Folding wheelchairs
トラックバック:adult adhd Assessment
トラックバック:cheap 3 wheel Buggy
トラックバック:dzoom.org.es
トラックバック:redirect to Northwestu
トラックバック:körkort förlängning trafikverket borås
トラックバック:https://immobilien-Marten.de
トラックバック:http://unit.igaoche.com/home.php?mod=space&uid=860906
トラックバック:에볼루션 바카라 무료
トラックバック:near me
トラックバック:read this blog article from Valetinowiki
トラックバック:best rated robot vacuum
トラックバック:How to Get a saab replacement key
トラックバック:Morphomics.science`s statement on its official blog
トラックバック:recent post by Humanlove
トラックバック:Glass Panel Repair
トラックバック:adult Loft bed with stairs
トラックバック:kitchen Built in oven
トラックバック:images.google.Td
トラックバック:Http://bbs.lingshangkaihua.com
トラックバック:bunk Beds Cabin beds
トラックバック:http://www.yya28.Com/home.php?mod=space&uid=331604
トラックバック:best Adhd Medication for adults with anxiety and depression
トラックバック:integrated fridge With water dispenser
トラックバック:exercise Cycle bike
トラックバック:Read Mazafakas
トラックバック:How Does Medication For Adhd Work
トラックバック:power tool Sale
トラックバック:Abc Mental health Assessment
トラックバック:replacement double glazed units near me
トラックバック:A2 motorradführerschein online shop
トラックバック:adhd Evaluation scale
トラックバック:Thomson-Tonnesen-2.Blogbright.Net
トラックバック:anchor
トラックバック:cat flap fitting
トラックバック:Best robot Cleaner
トラックバック:Adult Anal Toys
トラックバック:Cat flap Cost
トラックバック:Counterfeit Geld Bestellen
トラックバック:how to get a diagnosis for adhd
トラックバック:https://Topgid.net/Place.php?url=https://www.sofasandcouches.com/
トラックバック:composite door frame repair
トラックバック:프라그마틱 슬롯 추천
トラックバック:from this source
トラックバック:https://chessdatabase.science/wiki/15_Ideas_For_Gifts_For_Your_Buy_A_German_Driving_License_Lover_In_Your_Life
トラックバック:https://itkvariat.com/user/whaleshelf11
トラックバック:gas safety Certificate near me
トラックバック:best integrated oven uk
トラックバック:Maps.Google.Ml
トラックバック:adhd female test
トラックバック:Deutsche banknoten fälschen
トラックバック:Crypto casino’s
トラックバック:Big Couches for sale
トラックバック:images.Google.com.na
トラックバック:exercise equipment for legs
トラックバック:Couches For Sale Under $500
トラックバック:Best car locksmith bedford
トラックバック:judi togel teraman
トラックバック:nissan car key Replacement
トラックバック:Wun wrote in a blog post
トラックバック:Robot Vacuum Cleaner On Sale
トラックバック:Ugzhnkchr.Ru
トラックバック:Adhd Private Assessment Uk
トラックバック:https://www.Coffeebars.us/
トラックバック:plasemarket.ru link for more info
トラックバック:electric mobility Scooters for adults with seat
トラックバック:acheter un permis de Conduire européen en ligne
トラックバック:Symptoms Of Inattentive Adhd In Adults
トラックバック:Wooden
トラックバック:power tool deals
トラックバック:Best Compact Treadmill With Incline
トラックバック:best folding electric mobility Scooter for adults Uk
トラックバック:Jobsforcommerce.Com
トラックバック:continue reading this
トラックバック:Private Adhd Assessment Preston
トラックバック:adhd Test For adult women
トラックバック:Adult Toys Egg
トラックバック:images.google.ms
トラックバック:how much gas safety certificate
トラックバック:small Frost free Fridge
トラックバック:cheap chest Freezers uk
トラックバック:metal frame Bunk bed
トラックバック:https://king-wifi.Win/wiki/Gravgaardbutt2096
トラックバック:bariatric wheelchair 24 inch seat
トラックバック:Fridge and Freezer
トラックバック:Cognitive Assessment Mental Health
トラックバック:old upvc window handles
トラックバック:Silicone Realistic Sex Dolls
トラックバック:Repo.Gusdya.Net
トラックバック:Adhd in women signs
トラックバック:repair upvc door
トラックバック:power tool combo kits black friday
トラックバック:Men adult toys
トラックバック:körkortsonline
トラックバック:eu Führerschein kaufen erfahrungen
トラックバック:http://en.kartadostupnosti.ru/
トラックバック:skoda locked Keys in Car
トラックバック:mental Health evaluations
トラックバック:http://bbs.xinhaolian.com/
トラックバック:best adhd assessment for Adults
トラックバック:psychiatric assessment Ireland
トラックバック:Heavy Duty Folding Electric Wheelchair
トラックバック:top robot Vacuum
トラックバック:writes in the official Forexmob blog
トラックバック:double Glazing high wycombe
トラックバック:adhd private assessment near me
トラックバック:Images.Google.Cg
トラックバック:20Ft Tunnel Containers
トラックバック:How To Repair A Composite Door
トラックバック:bmw key diamond button
トラックバック:Best Crypto Casino Online
トラックバック:Electric tool Sets
トラックバック:https://bookmarkboom.com/story18729472/7-things-about-buy-a-category-a-copyright-you-ll-kick-Yourself-for-not-knowing
トラックバック:Online Adult Sex Toys
トラックバック:bandartogelterpercaya00037.estate-blog.com officially announced
トラックバック:Falschgeld Kaufen
トラックバック:pram Pushchair 2 In 1
トラックバック:mouse click on Metooo
トラックバック:Full Guide
トラックバック:http://bbs.zhizhuyx.com/home.php?mod=space&uid=11890260
トラックバック:Repair double glazed window
トラックバック:Bed with slides
トラックバック:getting diagnosed with add as an adult
トラックバック:l1accabdgcdm8L.com
トラックバック:automotive Lock smith
トラックバック:kids bunk beds for sale
トラックバック:Adhd assessment Private uk
トラックバック:Https://Www.Nlvbang.Com
トラックバック:integrated Electric ovens
トラックバック:79Bo1.com
トラックバック:disorder Social Anxiety
トラックバック:published on wwwiampsychiatrycom97131.tkzblog.com
トラックバック:https://www.bitsdujour.com/profiles/kw1ulc
トラックバック:Best Ovens uk
トラックバック:adhd medication titration
トラックバック:togel Hongkong
トラックバック:Iqbal-rao.hubstack.net
トラックバック:small Space treadmill with Incline
トラックバック:electric travel Mobility scooters
トラックバック:my explanation
トラックバック:Electric Mobility Scooter Uk
トラックバック:Mp.Cqzhuoyuan.Com
トラックバック:what is the best 4 wheel mobility scooter
トラックバック:Zerahypt.Net
トラックバック:Https://Dreaming.desertrosedomain.com/api.php?action=https://licencefrancexpress.com
トラックバック:https://2Ch-ranking.net
トラックバック:Frost Free fridge freezer 50 50
トラックバック:https://qooh.me/helpcarrot3
トラックバック:47.96.128.101
トラックバック:Http://Xojh.Cn/Home.Php?Mod=Space&Uid=2056524
トラックバック:Gas Certificate Newport Pagnell
トラックバック:Upvc doors windows
トラックバック:this hyperlink
トラックバック:Adhd assessment Women
トラックバック:https://getsocialsource.Com/Story2971887/7-simple-Tips-to-totally-you-into-adhd-assessment-private
トラックバック:Exercise Bike Sale
トラックバック:erlandsen-mckenna.federatedjournals.com
トラックバック:just click situstogelresmi68545.look4blog.com
トラックバック:acheter un permis de conduire enregistré
トラックバック:automatic folding mobility scooter near me
トラックバック:electric mobility scooters for sale
トラックバック:rcwarshipcombat.com
トラックバック:Visit algowiki.win
トラックバック:funny post
トラックバック:relevant web-site
トラックバック:blog post from Mazafakas
トラックバック:Maxi cosi car seat swivel
トラックバック:Shipping container company
トラックバック:london window repair
トラックバック:lg refrigerators for sale
トラックバック:Upvc repairs bristol
トラックバック:walking Rollator
トラックバック:door fitters high wycombe
トラックバック:Spare Keys Made Near Me
トラックバック:Https://Postheaven.Net
トラックバック:Https://Www.Question-Ksa.Com
トラックバック:cordless power tool kit
トラックバック:Double Glazing Repairs Bromley
トラックバック:Http://182.230.209.60
トラックバック:Mystery Box Website
トラックバック:learn more about peatix.com
トラックバック:elar.ru
トラックバック:emplois.fhpmco.fr
トラックバック:Https://www.Bitsdujour.com/profiles/sivgZT
トラックバック:Cat Flap In Upvc Door Cost
トラックバック:rosgigiena.Ru
トラックバック:http://ns1.javset.net/
トラックバック:Peck-maxwell-2.hubstack.net
トラックバック:redirect to Google
トラックバック:Microwave built
トラックバック:bookmarkstore.download
トラックバック:Adhd Assessment Online
トラックバック:spare car key Fob
トラックバック:Adhd symptoms in women adults
トラックバック:http://www.optionshare.tw/home.php?mod=space&uid=1072834
トラックバック:https://www.xinweiyu.com
トラックバック:robot Cleaner
トラックバック:Leather Sofa set Price
トラックバック:peatix.Com
トラックバック:https://wifidb.science/wiki/how_gotogel_altered_my_life_for_the_better
トラックバック:Https://exercisebikesonline95123.designertoblog.com/64437357/the-most-hilarious-complaints-we-ve-seen-about-best-exercise-bicycle
トラックバック:https://apply.innopolis.ru/bitrix/Rk.php?goto=https://harlemfur.com
トラックバック:crypto Coin casino
トラックバック:best Home exercise Equipment
トラックバック:Wolf-rice-3.hubstack.net
トラックバック:Qa.Holoo.Co.Ir
トラックバック:you can try Wikimapia
トラックバック:https://www.exportclub.com/proxy.php?link=https://cooperschicago.Com
トラックバック:https://botdb.win
トラックバック:Sixn.Net
トラックバック:https://Trade-britanica.trade/wiki/responsible_for_an_link_alternatif_gotogel_Budget_10_unfortunate_ways_To_spend_your_money
トラックバック:köPa A1 och A2 körkort
トラックバック:https://socialbookmarknew.win/story.php?title=the-reason-why-everyone-is-talking-about-local-gas-engineer-Near-me-right-now
トラックバック:robot Vacuums best
トラックバック:Powertools online
トラックバック:Https://Maps.Google.Com.Sa/Url?Q=Https://K12.Instructure.Com/Eportfolios/815915/Home/15_Gifts_For_The_Electric_Pedal_Scooters_Lover_In_Your_Life
トラックバック:amazon electric treadmill
トラックバック:Https://Www.Bitsdujour.Com/Profiles/Qqjnlq
トラックバック:https://www.ddhszz.com
トラックバック:Add Adhd Medications
トラックバック:Nagievonline.Com
トラックバック:Linzanadom.Ru
トラックバック:mccleary-valentine-3.blogbright.net
トラックバック:All Power Tools
トラックバック:Mobility Scooters On Road
トラックバック:lg Fridges price
トラックバック:mystery Box opener
トラックバック:https://opensourcebridge.science/
トラックバック:compact 8mph mobility Scooter
トラックバック:womans adult toys
トラックバック:mid sleeper cabin bed with storage
トラックバック:Travel mobility scooters
トラックバック:Git.Nationrel.Cn
トラックバック:check out this blog post via www.fluencycheck.com
トラックバック:valetinowiki.racing website
トラックバック:https://pushchairs52535.bloggin-ads.com/53647755/10-pinterest-accounts-you-should-follow-baby-pram
トラックバック:Interactive Adult Toy
トラックバック:Cot Bed Drawers
トラックバック:macpherson-larsen-2.Blogbright.net
トラックバック:double Glazing installers
トラックバック:alonegocio.net.br
トラックバック:replace Window handle
トラックバック:bunk beds with slides For kids
トラックバック:window hardware repair
トラックバック:https://franzbulldoggekaufen72973.ourabilitywiki.com/9704442/a_peek_at_the_secrets_of_buy_french_bulldog_puppies
トラックバック:Frostteam92.Bravejournal.net
トラックバック:cot Bed With drawer white
トラックバック:sliding patio door Repairs near me
トラックバック:Item Upgrading
トラックバック:exercise equipment
トラックバック:initial psychiatric assessment
トラックバック:Window Repairs near me
トラックバック:assessed for adhd
トラックバック:via Nerdgaming
トラックバック:dual Fuel range cooker
トラックバック:Adhd Assessment Test For Adults
トラックバック:double glazing windows
トラックバック:Built In Double Oven And Microwave Combination
トラックバック:forward Facing infant car seat
トラックバック:power Tool Set deals
トラックバック:Treadmill At Home
トラックバック:Get a spare Car key made
トラックバック:howe-england-3.blogbright.net
トラックバック:Bedside Cot Mattress
トラックバック:sleeper sectional with storage
トラックバック:tool Power
トラックバック:how much do private psychiatrists charge
トラックバック:private adhd assessment milton keynes
トラックバック:https://pattern-Wiki.win/wiki/Sawyerbramsen5429
トラックバック:www.1v34.com
トラックバック:damsgaard-erlandsen.federatedjournals.Com
トラックバック:window with cat flap
トラックバック:Ongakueternal.Com
トラックバック:Auto Locksmiths bedford
トラックバック:just click the next web site
トラックバック:Adhd Diagnosis Uk Adults
トラックバック:infozillon.com
トラックバック:source website
トラックバック:trafikverket Malmö föRnya körkort
トラックバック:blog post from sovren.media
トラックバック:car Keys lost what to do
トラックバック:Casino With Crypto
トラックバック:Https://Muse.Union.Edu
トラックバック:mobility scooter For Elderly
トラックバック:https://www.bitsdujour.Com/profiles/y6sf9l
トラックバック:59.viromin.com
トラックバック:Power mobility
トラックバック:Google link for more info
トラックバック:https://www.northwestu.edu/?URL=https://squareblogs.net/karatesharon0/the-best-tips-youll-ever-receive-on-retro-fridge-freezer-white
トラックバック:Folding Electric Mobility Scooters For Adults
トラックバック:parent Facing pushchair
トラックバック:Fridge Freezer Built In 70/30
トラックバック:KöRkort Tappat
トラックバック:Http://Www.Maoflag.Cc/Home.Php?Mod=Space&Uid=268526
トラックバック:3 wheel electric trike Mobility scooter
トラックバック:look these up
トラックバック:chaise Sectional
トラックバック:hockeypastry7.bravejournal.net
トラックバック:50/50 Fridge Freezer Frost Free
トラックバック:this site
トラックバック:new post from Nativ
トラックバック:right here on Yanyiku
トラックバック:door fitters bedford
トラックバック:repairing Upvc Windows
トラックバック:Http://www.Stes.tyc.edu.tw/
トラックバック:adult Toys Sex toys
トラックバック:repairs to Upvc windows
トラックバック:best floor vacuum robot
トラックバック:High bunk beds for adults
トラックバック:private adhd Assessment North east
トラックバック:https://gm6699.com/
トラックバック:seat key fob replacement
トラックバック:Leather couch Recliners
トラックバック:l Shape leather sofa
トラックバック:walking pad standing Desk
トラックバック:double glazing units near me
トラックバック:White Window Handles
トラックバック:securityholes.science
トラックバック:Git.barn364.com
トラックバック:private Psychiatrist bedfordshire
トラックバック:Slide Bed For Kids
トラックバック:sectional Sale
トラックバック:https://denofangels.com/proxy.php?link=https://www.iampsychiatry.uk
トラックバック:over the Counter adhd medication for adults
トラックバック:Window Hinges Leeds
トラックバック:Find Out More
トラックバック:secondary double glazing Near me
トラックバック:trafikverket körkortsfoto
トラックバック:free adhd assessment uk
トラックバック:Best Folding Treadmill Uk
トラックバック:Self Vacuum near me
トラックバック:https://images.google.bg/url?q=https://klint-mckenzie.thoughtlanes.net/20-best-tweets-of-all-Time-concerning-car-key-replacements
トラックバック:cooker Hood For island
トラックバック:car locksmiths near Milton Keynes
トラックバック:Https://mozillabd.science
トラックバック:Case battle cs go
トラックバック:upvc windows repairs
トラックバック:sofa Couch for Sale
トラックバック:Medflyfish writes
トラックバック:mini cooper key fob not working
トラックバック:does treadmill Incline burn More calories
トラックバック:Item Upgrade
トラックバック:best deal dewalt tools
トラックバック:https://cabrera-ziegler.hubstack.net/
トラックバック:Https://Www.Google.Bs/
トラックバック:single Gas Oven
トラックバック:pushchair Single
トラックバック:Uk Adult Adhd Diagnosis
トラックバック:Electronic car key Repair near me
トラックバック:Gas Boiler Engineer Near Me
トラックバック:Https://funsilo.date/
トラックバック:https://expressdeutschekartes42655.wikiitemization.com/
トラックバック:Best mobility scooter for car boot
トラックバック:https://buy-driving-License79090.sunderwiki.com/
トラックバック:how To Install ghost Immobiliser
トラックバック:registrierten führerschein online Kaufen
トラックバック:Gas Safety Buckingham
トラックバック:Best Portable Mobility Scooter
トラックバック:refsgaard-Mcginnis-3.Mdwrite.net
トラックバック:medical mobility Scooters
トラックバック:https://trade-britanica.trade/wiki/The_3_Greatest_Moments_In_Replacement_Keys_For_Car_History
トラックバック:Adhd Getting Diagnosed
トラックバック:opensourcebridge.science says
トラックバック:Dewalt multi tool Set
トラックバック:adhd assessment tool for adults
トラックバック:psychiatric Assessment near Me
トラックバック:Adhd assessment scotland Private
トラックバック:handle for patio door
トラックバック:Double Glazed Window Repairs
トラックバック:samsung freezer refrigerator
トラックバック:visit Humanlove
トラックバック:double glazed Repairs near me
トラックバック:Best single oven
トラックバック:Http://gdeotveti.ru/user/seederpark65
トラックバック:front doors luton
トラックバック:French Door Fridge size
トラックバック:Https://Www.Metooo.Co.Uk/U/675Adf20B4F59C1178Ba6908
トラックバック:l shaped bunk Beds For kids
トラックバック:aluminium windows high wycombe
トラックバック:hughes-paaske.hubstack.net
トラックバック:https://chessdatabase.science/wiki/What_The_10_Most_Stupid_Single_Fan_Oven_FAILS_Of_All_Time_Could_Have_Been_Prevented
トラックバック:mental assessment test
トラックバック:Best Cryptocurrency Casino
トラックバック:Adhd in women Test free
トラックバック:crypto local Casino
トラックバック:Immensedirectory.Com
トラックバック:adhd treatment London
トラックバック:Adhd Assessment For Adults Edinburgh
トラックバック:double integrated Oven with microwave
トラックバック:Https://Harborselect81.Werite.Net/Wisdom-On-Adhd-Medication-Ritalin-From-An-Older-Five-Year-Old
トラックバック:Mattress Topper Thick
トラックバック:Different adhd Medications
トラックバック:Vacuums Robot
トラックバック:double All terrain Buggy
トラックバック:Adhd Treatment Without Meds
トラックバック:Private Mental Health Diagnosis Uk
トラックバック:couches for Sale
トラックバック:information from Nerdgaming
トラックバック:Vauxhall Astra key replacement
トラックバック:gas engineers milton Keynes
トラックバック:click the up coming internet site
トラックバック:traypaint03.werite.net official website
トラックバック:adhd and Anxiety treatment
トラックバック:mobility scooters for sale in my area
トラックバック:doctors that treat adhd in adults
トラックバック:how to unlock a volkswagen jetta without a key
トラックバック:electronic
トラックバック:strollers
トラックバック:mobility fold up scooters
トラックバック:Cabrera-bullard.mdwrite.net
トラックバック:best lightweight mobility Scooter uk
トラックバック:sectional sleeper sofa With chaise
トラックバック:B96 Husbil
トラックバック:best small freezer chests
トラックバック:couches for sale nearby
トラックバック:best robot vacuum cleaner and Mop
トラックバック:Cabin Beds For Adults
トラックバック:Automatically folding mobility Scooter
トラックバック:https://mccullough-forsyth-2.technetbloggers.de
トラックバック:Www.Pdc.edu
トラックバック:fitting maxi cosi car seat Without Base
トラックバック:Adhd Diagnosis And Comorbidities
トラックバック:fparf.ru
トラックバック:Cheaper
トラックバック:کازینو العربی
トラックバック:Upvc doctor
トラックバック:double Glazing Repairs Near me
トラックバック:gefälschte euro Banknoten Kaufen
トラックバック:emergency glass Repair
トラックバック:psychiatrist Assessment uk
トラックバック:Diggerslist.Com
トラックバック:window replacements
トラックバック:luxury island hood
トラックバック:automatic Vacuum cleaners
トラックバック:uk medication for adhd
トラックバック:KöPa A1 Och A2 KöRkort Online
トラックバック:http://crsv.ru
トラックバック:Bitcoin Casino
トラックバック:Adhd symptoms Test
トラックバック:Https://Blogs.Cornell.Edu/
トラックバック:foldable Treadmill
トラックバック:pram bag
トラックバック:Adhd Medication Options
トラックバック:to Telegra
トラックバック:black wooden Bunk beds
トラックバック:published on Cityu
トラックバック:private adhd assessment telford
トラックバック:How.Much is A replacement car key
トラックバック:Remote Key Fob Repair Near Me
トラックバック:Cassava explains
トラックバック:Wajaswiki.Com
トラックバック:second hand dual Fuel range cookers
トラックバック:Falschgeld bestellen
トラックバック:www.google.com.ai
トラックバック:medical Anxiety disorder
トラックバック:Scdmtj official website
トラックバック:www.Tianxiaputao.com
トラックバック:Female Adhd Test Uk
トラックバック:inattentive adhd Treatment adults
トラックバック:compact Design
トラックバック:axelsen-tang-2.federatedjournals.com`s statement on its official blog
トラックバック:replacement Double glazing units Near me
トラックバック:Streamnapkin4.bravejournal.net
トラックバック:cheap foldable mobility Scooter
トラックバック:Click In this article
トラックバック:fkwiki.win
トラックバック:https://Www.graphicscience.jp:443/edit/wiki/index.php?garrettmcguire303909
トラックバック:best car boot For mobility Scooter
トラックバック:Deals On Power Tool Sets
トラックバック:Mini exercise bike
トラックバック:head to Hocl
トラックバック:3 Wheel pushchair cheap
トラックバック:Ebay Range Cookers Dual Fuel
トラックバック:large Fridge Freezer uk
トラックバック:learn more about Zsluoping
トラックバック:Https://Nerdgaming.Science/Wiki/10_Things_You_Learned_In_Kindergarden_That_Will_Aid_You_In_Obtaining_Gas_Safe_Engineer_Milton_Keynes
トラックバック:yearrobert26.werite.net
トラックバック:gibson-mccain.blogbright.net
トラックバック:lightweight double buggy
トラックバック:Fridge Freezers Side By Side
トラックバック:Add Diagnosis adult
トラックバック:key fob repairs near Me
トラックバック:lost a Car key
トラックバック:60 40 fridge Freezer Integrated
トラックバック:sectional Couches with recliners
トラックバック:Adhd uk Medication
トラックバック:double bunk bed Single On top
トラックバック:cheap double Buggy
トラックバック:Mental Health Diagnosis Test Uk
トラックバック:adhd assessment glasgow
トラックバック:made a post
トラックバック:Adhd Diagnosis
トラックバック:Online Psychiatrist
トラックバック:Cabin Bed With Pull Out Desk
トラックバック:Www.Zhzmsp.Com
トラックバック:Adhd symptoms In Adults Test
トラックバック:Www.politicalforum.com
トラックバック:double Stroller
トラックバック:How Can I Get Diagnosed With Add
トラックバック:Secureflute2.werite.net
トラックバック:treatment for adhd in women
トラックバック:Adhd and bpd symptoms
トラックバック:Long couch with chaise
トラックバック:Psychiatric assessment London
トラックバック:adhd Assessment private cost
トラックバック:ghost installations reviews
トラックバック:Robot vacuums that mop
トラックバック:private Adhd assessment glasgow cost
トラックバック:Leather Settee Recliner
トラックバック:sovren.media
トラックバック:Exercise bike Brands
トラックバック:Dandr.Su
トラックバック:www.inbackups.com wrote in a blog post
トラックバック:Replacement Car Key costs
トラックバック:Corner sofas Fabric
トラックバック:Fälschungen Schnell geliefert
トラックバック:chenille fabric corner sofa
トラックバック:https://worddad2.bravejournal.net/whats-everyone-Talking-about-best-american-fridge-freezers-right-now
トラックバック:Car locksmith near me cheap
トラックバック:Osen Vn blog post
トラックバック:Skoda Fabia Key
トラックバック:read this post from ezproxy.cityu.edu.hk
トラックバック:electric scooter green
トラックバック:ghost 2 immobiliser problems
トラックバック:tappat körkortet vad göra
トラックバック:Powered Mobility Scooter
トラックバック:Https://Www.72C9Aa5Escud2B.Com/
トラックバック:https://yogaasanas.science
トラックバック:infraskeletontech.com
トラックバック:automatic floor cleaning machine
トラックバック:Mid Sleeper
トラックバック:24 said in a blog post
トラックバック:http://www.stes.tyc.edu.tw
トラックバック:side by side fridge freezer with water dispenser
トラックバック:most popular Adult toys
トラックバック:3 Seater leather Couch
トラックバック:gas Safety certificate duplicate
トラックバック:https://iblog.Iup.edu/gyyt/2016/06/07/All-about-burnie-burns/comment-page-5902/
トラックバック:cabin bed For adults
トラックバック:refrigerator Companies
トラックバック:robot vacuum cleaners uk
トラックバック:Induction hob
トラックバック:bunk bed for Adults
トラックバック:Loft bed stairs only
トラックバック:Remote car key Repair
トラックバック:attention deficit disorder Online test
トラックバック:Qooh blog entry
トラックバック:private Psychiatrist Derby
トラックバック:http://ns1.Javset.net
トラックバック:4 Seater leather Recliner Sofa
トラックバック:key lock repair near me
トラックバック:good psychiatrists near Me
トラックバック:adhd symptoms In adult Women
トラックバック:Private adhd diagnosis Glasgow
トラックバック:non Prescription adhd medication
トラックバック:https://socialbookmark.stream/story.php?title=A-look-Into-natural-adhd-medications-secrets-of-natural-adhd-medication
トラックバック:Https://Pediascape.Science/Wiki/10_Of_The_Top_Mobile_Apps_To_Reclining_Sectional_With_Chaise
トラックバック:double pushchairs for Narrow Spaces
トラックバック:Puffintree93.bravejournal.net noted
トラックバック:Bmw Diagnostics Near Me
トラックバック:Sleeper sofas for sale
トラックバック:comment acheter un permis De conduire français
トラックバック:strongest Adhd medication For adults
トラックバック:Lost Car Keys Replacement Cost
トラックバック:Adhd symptom Checklist
トラックバック:https://valetinowiki.racing/
トラックバック:visit this page
トラックバック:https://telegra.ph/The-Ultimate-Guide-To-Mid-Cabin-Bed-With-Storage-09-17
トラックバック:The auto locksmith
トラックバック:Recreational Mobility Scooters
トラックバック:how much for landlords gas safety Certificate
トラックバック:user-friendly Scooters
トラックバック:http://www.ksye.cn/Space/uid-1197171.html
トラックバック:https://timeoftheworld.date/wiki/Watch_Out_How_Ovens_Is_Taking_Over_And_What_To_Do_About_It
トラックバック:2 In 1 Travel System With Car Seat
トラックバック:adhd assessment for adults Leicester
トラックバック:Lost Key Replacement Car
トラックバック:Private adult Adhd assessment belfast
トラックバック:Online crypto casino
トラックバック:rooms To Go Sofa sale
トラックバック:adhd Assessment Report
トラックバック:Images.google.ad
トラックバック:automatic folding mobility scooters for sale
トラックバック:bunk bed for teens
トラックバック:Adhd Treatment For adults Near me
トラックバック:chest freezers ebay Uk
トラックバック:Single Convertible Stroller
トラックバック:www.google.co.bw
トラックバック:ADHD Symptoms adults male
トラックバック:stopping Adhd Medication weekends adults
トラックバック:mgbg7b3bdcu.net
トラックバック:chest freezers Small uk
トラックバック:Open mystery boxes online
トラックバック:프라그마틱 무료게임
トラックバック:https://ondashboard.win/story.php?title=incontestable-evidence-that-you-need-remote-key-fob-repair
トラックバック:Gaarde-mckee-3.blogbright.net
トラックバック:Smart robot vacuums
トラックバック:Minagricultura wrote
トラックバック:spare car key maker near Me
トラックバック:BestäLla Nytt KöRkort Pris
トラックバック:https://ceshi.xyhero.com/home.php?mod=space&uid=2339077
トラックバック:Automated Vacuum Cleaner
トラックバック:cheap Mattress topper
トラックバック:Autolocksmith Near Me
トラックバック:Where To Buy Mobility Scooter
トラックバック:Hodge-Lyng.Blogbright.Net
トラックバック:porsche 2023 key
トラックバック:how much is a spare car key
トラックバック:Https://Www.Google.Co.Ls/
トラックバック:go directly to Google
トラックバック:bunk beds Single
トラックバック:Cheere.org
トラックバック:Crypto Casino Coin
トラックバック:automatic folding mobility Scooter reviews
トラックバック:rolls-royce keys
トラックバック:Mobility scooter For outdoor use
トラックバック:2 seater Fabric Sofa sale
トラックバック:Metal Frame Bunk Beds
トラックバック:Https://Www.Google.Com.Uy
トラックバック:Car replacement keys
トラックバック:https://www.metooo.co.uk/u/675d8e44b4f59c1178bf1a97
トラックバック:Kids bunk Bed
トラックバック:Repair Car Keys
トラックバック:robb-conway-4.federatedjournals.com
トラックバック:Förlänga körkort Online
トラックバック:https://articlement.com/Author/sharoncard2-481085
トラックバック:Sofas 2 Seater Fabric
トラックバック:Leather Chaise Lounge
トラックバック:auto ignition key replacement
トラックバック:Sectional With Sleeper
トラックバック:Treadmills Uk reviews
トラックバック:bunk bed with tree house
トラックバック:new post from freeok.cn
トラックバック:shipping container rental
トラックバック:new couch for Sale
トラックバック:köpa körkort lagligt
トラックバック:skoda spare key
トラックバック:portable mobility scooters for sale near me
トラックバック:remote car key repairs
トラックバック:sofa chairs for Sale
トラックバック:Mobility Scooter
トラックバック:green scooter
トラックバック:에볼루션 바카라 체험
トラックバック:integrated fridge freezer american
トラックバック:Https://Olderworkers.Com.Au/Author/Ssupa35Sick6-Sarahconner-Co-Uk/
トラックバック:Electric Mobility scooter near me
トラックバック:fridge Freezers freezers
トラックバック:Futon For Sale Near Me
トラックバック:https://wifidb.science/wiki/a_delightful_rant_about_retro_fridge_freezer_for_sale
トラックバック:which fridge to buy
トラックバック:Fridge freezers retro
トラックバック:lightweight 3 Wheel mobility Scooter
トラックバック:robot Vacuum deals
トラックバック:Remote Key Repair Near Me
トラックバック:Car Key Replacement By Vin
トラックバック:permis de conduire français à vendre
トラックバック:ghost immobiliser reviews
トラックバック:retro looking fridge freezer
トラックバック:island cooker hoods 60cm
トラックバック:keys
トラックバック:git.dev.urtrade.io
トラックバック:island vent hood
トラックバック:hop over to here
トラックバック:sectional couches for sale Near me
トラックバック:Https://Pennswoodsclassifieds.Com/User/Profile/306023
トラックバック:metal mid sleeper cabin bed
トラックバック:maps.Google.mw
トラックバック:https://bookmarkshut.com/story19016402/is-technology-making-gas-engineers-near-me-better-or-worse
トラックバック:programmable oven
トラックバック:ghost 2 immobiliser review
トラックバック:Crimson-Tiger-Msxk3R.Mystrikingly.Com
トラックバック:dorsten Sofa chaise
トラックバック:lockout
トラックバック:https://postheaven.net/foodagenda99/Whats-the-fuss-about-3-piece-sectional-with-chaise
トラックバック:bitetheass.com`s blog
トラックバック:automatic
トラックバック:Mobility Power Scooters
トラックバック:https://ogasdemo.ru/Bitrix/redirect.php?goto=https://pragmatickr.com
トラックバック:Cheap Couches For Sale Under $100 Near Me
トラックバック:Skoda Key fob
トラックバック:Bitspower site
トラックバック:123.57.51.87
トラックバック:Cheap Refridgerators
トラックバック:https://kehoe-marshall-2.blogbright.net
トラックバック:Bunk Beds For Teens
トラックバック:built under Single Oven
トラックバック:BOKEP TERBARU 2025
トラックバック:best place to buy a mobility Scooter
トラックバック:KöPa köRkort i sverige
トラックバック:Mobility trike scooters
トラックバック:Hagen-Mcclure-2.Hubstack.Net
トラックバック:Ansöka om körkort
トラックバック:Http://Www.1Moli.Top/
トラックバック:Best American Style Fridge Freezer
トラックバック:https://vcanhire.Com/employer/17110/cots4tots
トラックバック:chinbulb9.bravejournal.net’s website
トラックバック:french door fridge Freezers uk
トラックバック:https://botdb.win/Wiki/10_Apps_To_Help_You_Control_Your_Stylish_Sofa
トラックバック:dokuwiki.stream blog article
トラックバック:single oven gas cooker 60cm
トラックバック:Which Bunk Bed Is The Best
トラックバック:KöRkortsbyrå
トラックバック:https://writeablog.net
トラックバック:white cabin bed
トラックバック:Automatic floor vacuum
トラックバック:gas safety certificate landlord
トラックバック:auto fold mobility scooter
トラックバック:Compact lightweight scooters
トラックバック:2Flab.Com
トラックバック:mkgassafety-co-uk41937.Idblogz.com
トラックバック:heavy-Duty electric scooters
トラックバック:Cheap fridge freezers uk
トラックバック:collapsible mobility scooter
トラックバック:best ovens and hobs uk
トラックバック:What Mobility scooter To buy
トラックバック:https://glamorouslengths.com/author/dirtshop4/
トラックバック:git.gdscdw.Com
トラックバック:power tool Sets for Sale
トラックバック:Https://posteezy.com/30-inspirational-quotes-about-metal-triple-bunk-beds
トラックバック:https://scientific-programs.science/
トラックバック:Adult Bunk
トラックバック:Container tunnel
トラックバック:Best 50 50 fridge freezer
トラックバック:built in Microwave best
トラックバック:Infant car seats that swivel
トラックバック:Going to Hubstack
トラックバック:simply click Xn 0lq 70ey 8yz 1b
トラックバック:redirect to Bravejournal
トラックバック:https://barron-curran-2.technetbloggers.de/the-reasons-buy-fake-money-Bitcoin-is-the-most-popular-topic-in-2024
トラックバック:Travel Strollers
トラックバック:Corner Chaise Sofa
トラックバック:Best Value Dual Fuel Range Cooker
トラックバック:learn more about www.supergame.one
トラックバック:build In Oven
トラックバック:Off road Double buggy
トラックバック:best Quality bunk beds
トラックバック:Lightest Double Stroller
トラックバック:Folding mobility scooter for heavy person uk
トラックバック:Falschgeld Kaufen Bitcoin
トラックバック:Https://Carney-Shea-5.Technetbloggers.De/
トラックバック:christoffersen-stiles.thoughtlanes.net official website
トラックバック:Oddershede-Howe-2.Thoughtlanes.Net
トラックバック:new post from Bridgehome
トラックバック:Retro fridge Freezers
トラックバック:Https://Marvelvsdc.Faith/Wiki/The_Reason_Everyone_Is_Talking_About_New_Mobility_Scooters_For_Sale_Right_Now
トラックバック:регистрация Кэт казино
トラックバック:good Fridge freezer Brands
トラックバック:fsquan8.cn`s statement on its official blog
トラックバック:Electronics Lg Refrigerator
トラックバック:powertool
トラックバック:تحميل برنامج 1xbet للعب الكازينو على الإنترنت – الإصدار الرسمي لمصر
トラックバック:boot scooters
トラックバック:4 Seater couch leather
トラックバック:Newport Pagnell Gas Safe Engineers
トラックバック:stentoft-wise.technetbloggers.de
トラックバック:elsau.ru
トラックバック:3 wheel Stroller For running
トラックバック:best cordless power tool set
トラックバック:more about Daoqiao
トラックバック:Handicap 4 Wheel Scooters
トラックバック:auto Folding Mobility scooter with suspension
トラックバック:dinghyhose72.bravejournal.Net
トラックバック:l bunk Bed
トラックバック:you can try telegra.ph
トラックバック:Pavement scooters
トラックバック:cool training
トラックバック:class 3 mobility Scooter
トラックバック:Mystrikingly`s statement on its official blog
トラックバック:chest freezers for garages uk
トラックバック:4 Wheel Mobility
トラックバック:Cheap Mobility Scooters For Sale
トラックバック:love Seat sale
トラックバック:Https://Www.Bioguiden.Se/Redirect.Aspx?Url=Https://Www.Demilked.Com/Author/Traincopy12
トラックバック:https://posteezy.com/
トラックバック:Bunk Bed single bed
トラックバック:wp hosting
トラックバック:space saving bunk beds for kids
トラックバック:Gunnerojtgw.Thebindingwiki.Com
トラックバック:Handicap mobility Scooters
トラックバック:cheapest automatic folding mobility scooter
トラックバック:best 2 in 1 Stroller
トラックバック:extractor Fan for island
トラックバック:Electric Mobility Scooters For Adults
トラックバック:Electric mobility scooters
トラックバック:sofa Fabric 2 seater
トラックバック:Best Refrigerator Products
トラックバック:folding mobility scooters for sale Near me
トラックバック:green power electric mobility Scooter
トラックバック:Twin Pushchair From Birth
トラックバック:American Fridge Freezer Large
トラックバック:reviews over at Valetinowiki
トラックバック:new content from pattern-wiki.win
トラックバック:Führerschein Sonderfälle
トラックバック:dual-fuel range style cookers
トラックバック:Car seat Pushchair 2 in 1
トラックバック:Cabin Beds With Storage
トラックバック:Black built In single oven
トラックバック:best leather Couch
トラックバック:single and double stroller
トラックバック:Find
トラックバック:https://sears-murphy.blogbright.net/could-leather-recliner-settees-uk-be-the-key-To-achieving-2024/
トラックバック:patterned Fabric 2 seater sofa
トラックバック:cheap double stroller
トラックバック:https://stack.amcsplatform.com/user/reportwind8
トラックバック:https://WWW.Goodspeedcomputer.com/question/demande-de-pret-et-bourse-en-ligne-simplicite-et-accessibilite-a-votre-portee-2/
トラックバック:Intergrated Oven
トラックバック:socialistener.Com
トラックバック:built-in oven
トラックバック:What Do Treadmill Incline Numbers Mean
トラックバック:Https://digibookmarks.com
トラックバック:childrens bedroom ideas With Bunk beds
トラックバック:minecraftcommand.science blog post
トラックバック:use massagebodybodyparis.com here
トラックバック:dual Fuel range cooker With hot plate
トラックバック:l Shaped sleeper sofa
トラックバック:leather gray recliner
トラックバック:Https://minecraftcommand.science
トラックバック:Built-In electric Ovens
トラックバック:man united 24/25 kit
トラックバック:Casino Coin Crypto
トラックバック:Small double Buggy
トラックバック:oven comparison
トラックバック:repair keys near me
トラックバック:kids furniture
トラックバック:built in Microwave
トラックバック:https://fsquan8.Cn/
トラックバック:treadmill Foldable Electric
トラックバック:blog post from 120.zsluoping.cn
トラックバック:landlord gas safety certificate cp12
トラックバック:range style Dual fuel cookers
トラックバック:gas Safe Newport Pagnell
トラックバック:Best Rated Folding Treadmill
トラックバック:Images.Google.Com.My
トラックバック:tots And Cots
トラックバック:Bbs.01bim.com
トラックバック:written by images.google.is
トラックバック:single Oven dual Fuel cooker
トラックバック:Https://Fenger-Sanchez.Technetbloggers.De/
トラックバック:car key lost
トラックバック:curved Couches for sale
トラックバック:visit roboshayka.ru`s official website
トラックバック:http://Aprogramforchange.com/__media__/js/netsoltrademark.php?d=theterritorian.com.auindex.phppageuseractionpub_profileid1235441
トラックバック:Metal Bunk Bed With Desk
トラックバック:u shaped Leather Sectional
トラックバック:island cooker
トラックバック:Precise Cooking
トラックバック:gas certificates milton keynes
トラックバック:Range dual fuel cookers
トラックバック:Top 3 Wheel strollers
トラックバック:3 Wheeler Stroller
トラックバック:https://theterritorian.com.au/index.php?page=user&action=pub_profile&id=1237593
トラックバック:Kitchen Upgrade
トラックバック:oven built in
トラックバック:floating Loft bed
トラックバック:zoogosi.ru
トラックバック:Best twin Bunk Beds
トラックバック:Innovative design
トラックバック:https://www.dalusionfwx.co.nz/proxy.Php?link=Https://www.ovensandhobs.uk/
トラックバック:redirect to historydb.date
トラックバック:Xylvip officially announced
トラックバック:fabric two seater sofa
トラックバック:http://energypop.co.kr/Gnuboard5/bbs/board.php?bo_table=qna&wr_id=102706
トラックバック:mid sleeper cabin bed with drawers
トラックバック:smart Oven
トラックバック:built In microwave small
トラックバック:single oven sale
トラックバック:gas service engineer near me
トラックバック:types of upvc door hinges
トラックバック:cheap Couches for sale
トラックバック:thorhauge-reyes.thoughtlanes.net
トラックバック:double glazing door handle repairs
トラックバック:window hinge repair cost
トラックバック:replacement handles for upvc front doors
トラックバック:sofas Sleeper
トラックバック:프라그마틱 슬롯 조작
トラックバック:american Leather Sleeper sofa
トラックバック:http://Www.9kuan9.com/home.php?mod=space&uid=1205814
トラックバック:repair upvc door handle
トラックバック:composite door Hinges Adjustment
トラックバック:Window hinges
トラックバック:nlvbang.com
トラックバック:cooking
トラックバック:Glass hinge
トラックバック:Replacement conservatory roofs
トラックバック:check out this one from Procyon
トラックバック:Bunk beds with slides and Stairs
トラックバック:upvc hinges
トラックバック:3 wheeled pushchair
トラックバック:Ongoing
トラックバック:conservatory repairs
トラックバック:Conservatory Repairs In My Area
トラックバック:Double Glazed Door Handle Repair
トラックバック:3 wheeled Pushchairs
トラックバック:emergency car key replacement near Me
トラックバック:door handle repairs near me
トラックバック:double glazing hinge repairs near me
トラックバック:https://humanlove.stream/wiki/macleodstephansen4658
トラックバック:3 Wheeler Buggies
トラックバック:maxi cosi Tobi car seat
トラックバック:read on
トラックバック:ebooksworld.com.pl
トラックバック:Car Key repair Company
トラックバック:https://developmentmi.com/author/drymark3-47132/
トラックバック:replacement door handles for aluminium door
トラックバック:Pushchair Car Seat
トラックバック:Powell-Bowles-2.Federatedjournals.Com
トラックバック:Https://Www.98E.Fun/Space-Uid-8539174.Html
トラックバック:Car Seat Newborn Insert
トラックバック:1001pump.com
トラックバック:cheap gas engineer Near me
トラックバック:door Handle repair Plate
トラックバック:https://www.footballzaa.com/out.php?url=https://telegra.ph/10-no-fuss-ways-to-Figuring-the-buy-pallets-near-me-youre-looking-for-12-11
トラックバック:Pallet Buying
トラックバック:Kitchen cooker island
トラックバック:fahren lernen ohne prüfung
トラックバック:three Seater fabric sofa
トラックバック:Upvc doors hinges
トラックバック:Childrens shorty Bunk beds
トラックバック:front door handle repair
トラックバック:upvc Door hinges replacement
トラックバック:friction Stay hinges
トラックバック:tilt and turn windows hinges
トラックバック:Www.Google.pt
トラックバック:built in ovens with dial controls
トラックバック:https://nerdgaming.science/wiki/11_methods_to_totally_defeat_your_gas_engineer_Milton_keynes
トラックバック:sonare.jp
トラックバック:gas certificates
トラックバック:conservatory door glass replacement
トラックバック:grey corner chesterfield sofa
トラックバック:best kids bunk bed
トラックバック:Mosabqat.net
トラックバック:Fahrerlaubnis kaufen legal
トラックバック:http://ezproxy.cityu.edu.hk/login?url=https://salebus7.bravejournal.net/the-10-most-scariest-things-about-buy-a-driving-license
トラックバック:Gas Safety Inspection Newport Pagnell
トラックバック:https://Www.metooo.Co.uk
トラックバック:pvc Window hinges
トラックバック:http://Www.Bitspower.com/Support/User/rategrill04
トラックバック:Conservatory Door Repairs
トラックバック:like it
トラックバック:glass to Glass Hinges
トラックバック:spectr-sb116.ru
トラックバック:she said
トラックバック:single oven electric cooker 60cm
トラックバック:Two seater fabric Sofa
トラックバック:good Bunk beds
トラックバック:begleitetes fahren kaufen
トラックバック:best Bunk
トラックバック:b197 führerschein Seriös
トラックバック:conservatory sliding door repairs
トラックバック:https://Xs.Xylvip.com
トラックバック:door handles repair near me
トラックバック:replacement Conservatory Doors
トラックバック:Replacement wooden conservatory doors
トラックバック:childrens bunk beds With slide
トラックバック:Hulkshare noted
トラックバック:home-page
トラックバック:combination microwave oven built in
トラックバック:relevant web site
トラックバック:Keep Reading
トラックバック:baking
トラックバック:Fix door hinge
トラックバック:replacement Front door Handles
トラックバック:head to www-x.phys.se.tmu.ac.jp
トラックバック:https://ai-db.science/wiki/14_questions_you_might_be_uneasy_To_ask_gas_safe_buckingham
トラックバック:Door hinges upvc
トラックバック:door Handle repair
トラックバック:aluminium Window hinges
トラックバック:bunk-beds-for-kids31158.blogdal.com
トラックバック:leather pull out couch
トラックバック:integrated oven and microwave
トラックバック:Newport Pagnell Gas Safe Registered Engineers
トラックバック:b197 führerschein kaufen Seriös
トラックバック:http://79Bo2.com/Space-uid-7958074.html
トラックバック:Repair Door Handle
トラックバック:small u shaped Kitchen ideas
トラックバック:Check Out Maoflag
トラックバック:http://taikwu.Com.tw
トラックバック:bunk Bed Single
トラックバック:mozillabd.science site
トラックバック:http://delphi.larsbo.org/user/crosspacket0
トラックバック:double pram with reversible seats
トラックバック:Wooden conservatory repairs
トラックバック:read this blog post from postheaven.net
トラックバック:https://kingranks.com/author/Skinbull90-1509064/
トラックバック:Kitchen Ventilation
トラックバック:newcastle united kit 24 25
トラックバック:Gas-Safety-Certificate97635.Homewikia.Com
トラックバック:Range cooker Dual fuel
トラックバック:best VIP programs
トラックバック:Fahrerlaubnis Erkaufen erfahrungen
トラックバック:https://telegra.ph/The-10-Most-Terrifying-Things-About-Built-In-Combination-Microwave-01-15
トラックバック:Microwaves built In
トラックバック:b197 führerschein machen
トラックバック:landlord gas safety certificates newport pagnell
トラックバック:landlord Gas safety certificates Buckingham
トラックバック:https://www.youtube.com/watch?v=4APsoQWjKZ4
トラックバック:Online FüHrerschein Erwerben
トラックバック:Built In Microwave 25 Litre
トラックバック:soto-ebsen-2.mdwrite.net
トラックバック:Newport Pagnell gas safe engineer
トラックバック:autofüHrerschein erwerben
トラックバック:Single Oven electric
トラックバック:https://postheaven.net/laketoast0/7-easy-tips-For-totally-rolling-with-your-driving-license-without-test
トラックバック:https://www.scdmtj.com/home.php?Mod=space&Uid=2582150
トラックバック:over island extractor Fan
トラックバック:black single Oven electric
トラックバック:führerschein günstig kaufen
トラックバック:Durable built in ovens
トラックバック:gas hob
トラックバック:Island hoods kitchen
トラックバック:fahren ohne fahrprüFung
トラックバック:http://wzgroupup.Hkhz76.badudns.cc/
トラックバック:Http://bwisl.ca/language.php?url=www.cartoexpressodeportugal-96b.com/
トラックバック:Suggested Internet site
トラックバック:private psychiatrist online
トラックバック:broken double glazing replacement
トラックバック:cs-upgrade.top
トラックバック:how to open volvo truck door without key
トラックバック:www.google.co.ao
トラックバック:local psychiatrists near me
トラックバック:Bifold Door Repair
トラックバック:psychiatric practice near me
トラックバック:jako Parrot for Sale
トラックバック:bioguiden.se
トラックバック:Https://Willysforsale.Com/Author/Kettlehyena7/
トラックバック:Best Car Seat Newborn Uk
トラックバック:permis de conduire provisoire français
トラックバック:https://ucgp.jujuy.edu.Ar/profile/fuelnumber0/
トラックバック:spa-sibir.ru
トラックバック:fäLschungen online bestellen
トラックバック:kup prawo Jazdy a1 online
トラックバック:Nissan Navara Key programming
トラックバック:www.kratc.com
トラックバック:second Hand Containers For sale uk
トラックバック:Fulton-adair.technetbloggers.de wrote
トラックバック:buy A grey parrot
トラックバック:jjj555.Com
トラックバック:bandar Togel resmi
トラックバック:https://king-wifi.win/wiki/10_Things_Everybody_Gets_Wrong_Concerning_2_In_1_Infant_Car_Seat_And_Stroller
トラックバック:www.car-custom-club.ru
トラックバック:https://81.pexeburay.com
トラックバック:Bedside Cosleeper
トラックバック:remedies for adhd in adults
トラックバック:windows and doors upvc
トラックバック:pediascape.science
トラックバック:Double Glazing Bedfordshire
トラックバック:Http://Www.4Mbs.Net/
トラックバック:click here to visit funsilo.date for free
トラックバック:Soudfa.it5h.com
トラックバック:window Refurbishment london
トラックバック:Köpa taxilicens Körkort
トラックバック:Top Psychiatrist Near Me
トラックバック:Best crib
トラックバック:Automatic folding lightweight mobility scooter
トラックバック:Gas Safety Certificate Milton Keynes Cost
トラックバック:wheelchair self propelled folding
トラックバック:Https://Aegitas.Ru/
トラックバック:lightweight folding self Propelled wheelchair
トラックバック:https://scientific-programs.science
トラックバック:Reinrassiger SchäFerhund
トラックバック:www.haidong365.com
トラックバック:https://Images.google.as/
トラックバック:Fkwiki officially announced
トラックバック:mobile
トラックバック:Refrigerator company List
トラックバック:best psychiatrist uk
トラックバック:carwood38.werite.net
トラックバック:Https://Git.Jerrita.Cn
トラックバック:Internet Page
トラックバック:use Werite here
トラックバック:Kopirki.Net
トラックバック:https://www.bearhugger.net/
トラックバック:Ford transit replacement key
トラックバック:4Mph Boot Scooter
トラックバック:Privatementalhealth48763.Topbloghub.Com
トラックバック:ansökan Om nytt körkort
トラックバック:https://ai-db.science/wiki/7_Simple_Secrets_To_Totally_Making_A_Statement_With_Your_Exercise_Cycle_Bike
トラックバック:http://bbs.zhizhuyx.com/home.php?mod=space&uid=11869134
トラックバック:https://maps.google.com.pr/url?q=https://telegra.ph/why-nobody-cares-about-microwave-oven-built-in-11-10
トラックバック:installers
トラックバック:redirect to Ligapack
トラックバック:glass door repair near me
トラックバック:read this blog post from Blogdanica
トラックバック:go to this website
トラックバック:try these guys
トラックバック:opencbc.Com
トラックバック:read full article
トラックバック:Cheap Cordless power tool Kits
トラックバック:Www.louloumc.com
トラックバック:horn-marks.hubstack.net
トラックバック:What Is A French Door Fridge Freezer
トラックバック:composite door hinge replacement
トラックバック:Multistore Containers
トラックバック:https://reelsama.com/
トラックバック:https://Www.metooo.es/u/67a2e1caf100dc6809c9469C
トラックバック:www.littlescrapsofheavendesigns.com explained in a blog post
トラックバック:https://zenwriting.net/stonemitten7/youll-be-unable-to-Guess-private-psychiatrist-near-mes-tricks
トラックバック:l shaped Outdoor Couch
トラックバック:mystery box Sites
トラックバック:emergency boarding up Birmingham
トラックバック:replacement key for citroen c1
トラックバック:http://www.francite.com/
トラックバック:Lawshare.Tw
トラックバック:Http://Mrainflowinccom.Spmd.Mobi
トラックバック:Gas safe engineer near Me
トラックバック:where-to-get-A-macaw35701.blogdanica.com
トラックバック:Https://aztc.ru/bitrix/redirect.php?goto=https://www.iampsychiatry.com/
トラックバック:glass windows Repair
トラックバック:car Seat 2 in 1 stroller
トラックバック:https://anykey-design.ru
トラックバック:adhd assessment for adults Free
トラックバック:http://jibunryoku1.info
トラックバック:mbo99
トラックバック:Gizmo Newborn african grey parrot
トラックバック:foldable electric Wheelchair for sale
トラックバック:stack.Amcsplatform.com
トラックバック:47.108.249.16
トラックバック:Robot vacuum cleaners
トラックバック:tabi-mile.com
トラックバック:프라그마틱 슬롯버프
トラックバック:similar resource site
トラックバック:Adhd tests Uk
トラックバック:breum-robles.hubstack.net website
トラックバック:Cabin Bed single
トラックバック:Greenpower Mobility
トラックバック:Adhd For Adults Test
トラックバック:https://dyhr-lundqvist-3.technetbloggers.de/are-buy-category-a-driving-license-The-most-effective-thing-that-ever-was/
トラックバック:Mild Adhd Symptoms In Adults
トラックバック:Car Key programming cost
トラックバック:seat Car Keys
トラックバック:führerschein kaufen seriös
トラックバック:Köp körkort utan test
トラックバック:Https://middlecord3.bravejournal.net/10-unexpected-situs-togel-Resmi-tips
トラックバック:Https://hindujobs.org/companies/gotogel-real
トラックバック:8Ft Shipping Containers
トラックバック:https://M.jjfd.co.kr/member/login.html?noMemberOrder=&returnUrl=https://tonymacdrivingschool.com/
トラックバック:https://blogs.Cornell.edu/advancedrevenuemanagement12/2012/03/28/department-Store-industry/comment-page-3422/
トラックバック:acheter un véritable permis de conduire français
トラックバック:mebel50-nn.ru
トラックバック:https://socialbookmarknew.win/story.php?title=why-we-do-we-love-battery-powered-scooters-and-you-Should-Too
トラックバック:Convertible Sleeper Sofa
トラックバック:jazda motorem
トラックバック:private psychiatrist london
トラックバック:www.viewtool.com
トラックバック:Dyna.boe.ttct.edu.tw
トラックバック:Modular Buildings Containers – #https://Www.globosapiens.net/about/030200.html?from=jamienuh&subject=купить аккаунт фейсбук с бизнес менеджером&message=Правильная настройка бизнес-ме
トラックバック:www.usbstaffing.com
トラックバック:bedside crib travel cot
トラックバック:Private Psychiatrist Cardiff
トラックバック:prawo jazdy kat c
トラックバック:Energy Efficient Chest Freezer Uk
トラックバック:Picture window repair
トラックバック:Leatherette Recliner Sofa
トラックバック:psychological assessment near me
トラックバック:Https://Lovewiki.Faith/Wiki/How_Order_New_Drivers_License_Transformed_My_Life_For_The_Better
トラックバック:Fiat punto key Replacement
トラックバック:Https://K12.Instructure.Com
トラックバック:Deutsche SchäFerhundwelpen
トラックバック:5Oclock.ru
トラックバック:https://Hyg.w-websoft.co.kr/
トラックバック:composite door Handle replacement
トラックバック:American fridge
トラックバック:repairing Upvc door
トラックバック:Adhd In Women Adult
トラックバック:izbumagi.net blog post
トラックバック:Personality Disorder Psychiatrist Near Me
トラックバック:read this blog post from palangshim.com
トラックバック:Https://Apk.Tw/
トラックバック:körkort framtagning
トラックバック:This Resource site
トラックバック:outdoor Rollator walker With seat
トラックバック:double Glazed Window repairs near me
トラックバック:from spacedinner63.werite.net
トラックバック:internationellt körkort – transportstyrelsen
トラックバック:Https://Wwwfrydgeuk50106.Snack-Blog.Com/28621276/Say-Yes-To-These-5-Samsung-Fridge-Freezer-With-Water-Dispenser-Tips
トラックバック:fewpal.com wrote
トラックバック:Https://Www.Footballzaa.Com/
トラックバック:repairing
トラックバック:Buy A Macaw
トラックバック:https://canvas.instructure.com/
トラックバック:Najlepsza SzkołA Jazdy Motocyklowej
トラックバック:Bromley sash windows
トラックバック:Macaw bird cost
トラックバック:private psychiatrist london uk
トラックバック:Bocoran togel
トラックバック:Http://139.129.25.55/
トラックバック:Thoughtlanes`s statement on its official blog
トラックバック:Silver Dual Fuel Range Cookers
トラックバック:glass cat flap installation near me
トラックバック:bork-Winters-2.blogbright.net
トラックバック:elliottnuycf.digiblogbox.com
トラックバック:windows and doors aluminium
トラックバック:Yuzhno-sakhalinsk.vzv.su
トラックバック:https://situs-gotogel65562.win-Blog.com/
トラックバック:gas safety certificate Cp12
トラックバック:adhd Symptoms women adult
トラックバック:Online FüHrerschein A2 Shop
トラックバック:where to get adhd diagnosis
トラックバック:operkor.net
トラックバック:kupić prawo jazdy szybko I legalnie
トラックバック:new post from Bravejournal
トラックバック:Walters-haley-2.blogbright.net
トラックバック:Https://Championsleage.Review/
トラックバック:get a mental health assessment
トラックバック:express-deutsche-kartes14687.wikiworldstock.Com
トラックバック:more resources
トラックバック:bariatric Wheelchair recliner
トラックバック:Metal Bunk Bed for adults
トラックバック:visit the site
トラックバック:www.yapfiles.ru
トラックバック:Microwave And Grill Built In
トラックバック:best male adult toys
トラックバック:Skoda Key Programming
トラックバック:www.oakee.cn
トラックバック:Sliding patio door repairs
トラックバック:amazon Bedside cot
トラックバック:best lightweight folding mobility scooter uk
トラックバック:https://ortokraft.ru/bitrix/redirect.php?goto=https://Falschgeldkaufenonline.com/
トラックバック:Führerschein verlängern
トラックバック:https://www.dermandar.com
トラックバック:new dewalt tools
トラックバック:3 wheeled mobility Scooters For sale
トラックバック:African Grey Parrot For Sale
トラックバック:Http://114.115.218.230/
トラックバック:alcohol psychiatrist near me
トラックバック:pram for newborn
トラックバック:bentley Key fob Price
トラックバック:when adhd goes untreated
トラックバック:how do i get my son assessed for adhd
トラックバック:www.jvc.jaeys.de
トラックバック:Footballzaa.Com
トラックバック:Check Out Akva Market
トラックバック:https://www.youtube.com/redirect?q=https://watson-stallings.thoughtlanes.net/who-is-responsible-for-the-robot-cleaner-budget-12-best-ways-to-spend-Your-money
トラックバック:adhd test adult
トラックバック:My Web Page
トラックバック:via autoexotic.lv
トラックバック:bookmarkvids.Com
トラックバック:Https://Privatehd.Org
トラックバック:https://Pilgaard-meier-2.blogbright.Net/the-reasons-why-repair-patio-door-is-everyones-passion-in-2023
トラックバック:fitting a cat flap
トラックバック:bmw new Key
トラックバック:Cat Flap Cost Near Me
トラックバック:Adhd Inattentive Type Women
トラックバック:50/50 Freezer fridge
トラックバック:Cost of replacement bmw key
トラックバック:http://www.hondacityclub.com/
トラックバック:do macaws make Good pets
トラックバック:Broken key repair
トラックバック:repair upvc windows
トラックバック:double strollers with one hand Fold
トラックバック:Small Rollator With Seat
トラックバック:https://kidsmax.Ru
トラックバック:Upvc Door panel with cat Flap
トラックバック:mouse click for source
トラックバック:how Often gas safety certificate
トラックバック:size
トラックバック:Linkagogo.Trade
トラックバック:207.180.250.114
トラックバック:zopedirectory.com
トラックバック:Tiwauti.Com
トラックバック:upvc Back doors milton keynes
トラックバック:gratisafhalen.be noted
トラックバック:try here
トラックバック:driving license For sale uk
トラックバック:under desk treadmill Uk
トラックバック:Trafikverket FöRarprov BoråS Photos
トラックバック:Dewalt Power Tools Set
トラックバック:Https://Securityholes.Science/Wiki/Why_Everyone_Is_Talking_About_Website_Gotogel_Alternatif_Today
トラックバック:Falschgeld Online Kaufen
トラックバック:Humanlove blog entry
トラックバック:https://auto-Locksmiths06422.newbigblog.com/36512767/speak-yes-to-these-5-car-stolen-with-keys-in-it-tips
トラックバック:에볼루션 바카라사이트
トラックバック:Container Storage
トラックバック:2Ch-Ranking.Net
トラックバック:3 wheel scooter sale
トラックバック:windows and doors uk
トラックバック:African Blue Parrot For Sale
トラックバック:where to Buy Macaws
トラックバック:https://shapshare.com/
トラックバック:https://ember.Lineage66.com/home.php?mod=Space&uid=1101792
トラックバック:http://www.kuniunet.com/
トラックバック:Https://Bookmarkfeeds.Stream/Story.Php?Title=10-Meetups-On-Remote-Key-Repair-You-Should-Attend
トラックバック:https://clinfowiki.win/wiki/Post:20_Situs_Toto_Websites_Taking_The_Internet_By_Storm
トラックバック:Source Webpage
トラックバック:KöRkort På Ett Enkelt SäTt
トラックバック:bakistudio22.com
トラックバック:writes in the official Wj 10001 blog
トラックバック:Recommended Browsing
トラックバック:Elearnportal said in a blog post
トラックバック:Buy a macaw parrot
トラックバック:http://brewwiki.win/
トラックバック:Kupić Prawo Jazdy Za Granicą
トラックバック:Seat Car Key Stuck
トラックバック:photomatic.nl
トラックバック:tool shop online
トラックバック:remote automatic folding Scooter
トラックバック:upvc windows and doors
トラックバック:Mobility Scooters Usa
トラックバック:https://wifidb.science
トラックバック:Shipping Container Hire Uk
トラックバック:Music.Nguza.com
トラックバック:adjustable Wheelchair
トラックバック:Oblogation said
トラックバック:Https://Www.Metooo.It/U/676A31E6B4F59C1178D3A31D
トラックバック:private psychiatrist London adhd
トラックバック:private adhd assessment Warrington
トラックバック:https://mini-bulldogge-kaufen64836.jasperwiki.com
トラックバック:Adult Toys Buy Online
トラックバック:flush Casement Upvc windows
トラックバック:Macaw pets
トラックバック:Combined Adhd Symptoms in adults
トラックバック:to finforum.pro
トラックバック:Adhd In Adults Untreated
トラックバック:replacement car Key near me
トラックバック:milton keynes gas engineers
トラックバック:realistic sex doll cost
トラックバック:hyundai replacement key cost
トラックバック:replacement double glazing Handles
トラックバック:auto locksmiths milton Keynes
トラックバック:Https://Blogfreely.Net/Sushidrink4/Why-Composite-Door-Repair-Is-Right-For-You
トラックバック:Https://Moparwiki.Win/Wiki/Post:A_Look_At_Conversions_Containerss_Secrets_Of_Conversions_Containers
トラックバック:deutscher schäferhund kaufen österreich
トラックバック:Shop power tools
トラックバック:gas Safe registered engineers Buckingham
トラックバック:Private Psychologist
トラックバック:https://coopers-Chicago98053.blogzag.com/
トラックバック:try Morphomics
トラックバック:you can try here
トラックバック:locksmiths Near me for cars
トラックバック:Bioimagingcore.Be
トラックバック:best car seats for Infants
トラックバック:commander un permis de conduire français
トラックバック:Home window Glass Repair
トラックバック:key bak Mini
トラックバック:프라그마틱 정품 사이트
トラックバック:Replacement lock for composite door
トラックバック:Treat Adhd
トラックバック:patio door repairs
トラックバック:Going at Trade Britanica
トラックバック:ssgrid-git.cnsaas.Com
トラックバック:windows manufacture Renovation london
トラックバック:leather sofas Near me
トラックバック:cost replacement car Key
トラックバック:tops-directory.com
トラックバック:best sturdy bunk beds for adults
トラックバック:car locksmith near bedford
トラックバック:Https://urcollegia.ru/
トラックバック:Mini Cooper Key Replacement Near Me
トラックバック:Whoswho.Propertyeu.Info
トラックバック:Http://Loserwhiteguy.Com/Gbook/Go.Php?Url=Https://Www.Robotvacuummops.Uk/
トラックバック:Non stimulant adhd medication
トラックバック:hydraulic-balance.ru
トラックバック:Articlescad blog article
トラックバック:http://taikwu.com.tw/dsz/home.Php?mod=space&uid=1196196
トラックバック:mouse click on git.mhurliman.net
トラックバック:Https://clever-wombat-g487n2.mystrikingly.com/blog/14-companies-doing-an-excellent-job-at-green-power
トラックバック:Letoile-Du-Destin.Xooit.Fr
トラックバック:byrd-viborg-2.technetbloggers.De
トラックバック:https://jusojula75971.myparisblog.com/31638176/15-top-pinterest-boards-of-all-time-about-address-collection-site
トラックバック:Robot Floor cleaner
トラックバック:Mofaführerschein kaufen
トラックバック:najlepsze miejsce do Kupna prawa jazdy
トラックバック:https://bookmarkfeeds.stream/story.php?title=A-peek-inside-the-secrets-of-adhd-assessment-For-Adults-uk
トラックバック:honda accord Car key
トラックバック:프라그마틱 게임
トラックバック:agen togel Terbesar
トラックバック:Moparwiki.Win
トラックバック:makeuplyre5.bravejournal.net
トラックバック:King Wifi published a blog post
トラックバック:view Peatix
トラックバック:automatic folding mobility scooters
トラックバック:pncdgts.com
トラックバック:Bedside cot co sleeper
トラックバック:profiteplo.com
トラックバック:Can Anxiety Disorder Cause Nausea
トラックバック:pram Uk
トラックバック:cream fabric corner sofa
トラックバック:Www.google.com.gi
トラックバック:http://www.yya28.com/home.php?Mod=space&uid=541972
トラックバック:windows doors Upvc
トラックバック:Buy rollators with seats
トラックバック:best practice mental health Assessment
トラックバック:read this blog post from 044300
トラックバック:Psychiatric clinic near me
トラックバック:www.skaterka.ru
トラックバック:http://eric1819.Com/
トラックバック:Where To Buy Adult Sex Toys
トラックバック:Https://Bbs.Pku.Edu.Cn
トラックバック:Situs togel Pasaran lengkap
トラックバック:Replace Honda Car Key
トラックバック:acheter un faux permis de Conduire français
トラックバック:Artmarker.ru
トラックバック:https://morphomics.science
トラックバック:https://api.sanjagh.com/
トラックバック:private psychiatric assessment london
トラックバック:Attention deficit Hyperactivity disorder Adhd symptoms
トラックバック:https://humanlove.Stream/wiki/Mental_Health_Psychiatrist_Tips_That_Will_Change_Your_Life
トラックバック:use yogicentral.science
トラックバック:adhd in women quiz
トラックバック:redirect to Technetbloggers
トラックバック:https://brockca.com/home.php?mod=space&uid=555193
トラックバック:german shepherd kaufen
トラックバック:related web site
トラックバック:recent Wikimapia blog post
トラックバック:Full Statement
トラックバック:recent post by www.hulkshare.com
トラックバック:https://elearnportal.Science/wiki/10_things_we_love_about_buy_category_a_driving_license
トラックバック:simply click Wifidb
トラックバック:Www.Crazys.Cc
トラックバック:mercedes Replacement key
トラックバック:http://wzgroupup.hkhz76.badudns.cc/home.php?mod=space&uid=2423881
トラックバック:Dewalt tools Kit
トラックバック:Key replacement bmw
トラックバック:Diagnosing Adhd
トラックバック:https://www.Gblnet.net
トラックバック:mckee-rivera-4.blogbright.net
トラックバック:trafikverket förnya Körkort
トラックバック:Köp Am Körkort Online
トラックバック:cps.qixin18.com
トラックバック:Mdwrite`s latest blog post
トラックバック:Spix Macaw characteristics
トラックバック:Kitchen remodeling
トラックバック:power tool Accessories
トラックバック:wooden cot bed Uk
トラックバック:https://chessdatabase.science/wiki/5_Clarifications_On_Evolution_Baccarat_Site
トラックバック:psychiatric assessment brighton
トラックバック:leather Sofa with chaise
トラックバック:Https://vuf.minagricultura.gov.co
トラックバック:https://plesheevo-lake.ru/bitrix/redirect.php?event1=click_to_call&event2=&event3=&Goto=https://oi2bv4qg7fba.com/
トラックバック:www.recyclingpool.de
トラックバック:frydgeuk09539.tokka-blog.com
トラックバック:repair Windows
トラックバック:Exercisebikesonline64801.like-blogs.Com
トラックバック:click the next website
トラックバック:Chessdatabase published a blog post
トラックバック:https://trade-britanica.trade/wiki/the_companies_that_are_the_least_wellknown_to_follow_in_the_gotogel_Industry
トラックバック:4 wheel mobility scooter electric scooters
トラックバック:http://mm.yxwst58.com
トラックバック:französische bulldogge kaufen Berlin
トラックバック:double running buggy
トラックバック:Volkswagen Jetta Key Replacement Near Me
トラックバック:Telegra blog article
トラックバック:new content from Frewwebs
トラックバック:mazda keyless remote
トラックバック:10-Situs-Togel-Terpercaya69447.Blogproducer.Com
トラックバック:psychiatry private Practice
トラックバック:uk Power tools
トラックバック:medical mobility scooter for sale
トラックバック:https://telegra.ph/Its-Enough-15-Things-About-Bedside-Cot-Sale-Were-Fed-Up-Of-Hearing-12-07
トラックバック:Container Modifications Ideas
トラックバック:Anxiety treatment meds
トラックバック:visit Idblogmaker now >>>
トラックバック:Newsbasket4.werite.net published an article
トラックバック:this website
トラックバック:cabin beds mid Sleeper
トラックバック:https://canvas.instructure.com/eportfolios/3381759/home/robot-vacuum-best-explained-in-fewer-than-140-Characters
トラックバック:Adult Sex dolls
トラックバック:Glass replacement Windows
トラックバック:realistic tpe Sex Doll
トラックバック:keys Repair near me
トラックバック:the window doctors
トラックバック:https://blogfreely.net/Canceryard0/youll-never-guess-this-sexmachine-uks-benefits
トラックバック:replacing lock on upvc door
トラックバック:Convertible Bunk Beds
トラックバック:gas Safe registered Engineer
トラックバック:Https://git.Protokolla.Fi/Falschgeldkaufenonline1935
トラックバック:Exercise bike Workout
トラックバック:Adhd Symptoms
トラックバック:https://kittyhose28.werite.net/what-is-the-buy-driving-license-category-b-Online-term-and-how-to-utilize-it
トラックバック:adhd titration Meaning
トラックバック:vad kostar det Att bestäLla nytt körkort
トラックバック:ferrari lost Key
トラックバック:https://www.demilked.com/author/parkarm98
トラックバック:http://www.jinritongbai.com
トラックバック:commercial windows near Me
トラックバック:macaw For sale near me
トラックバック:Bi Folding Door Repair
トラックバック:Marvelvsdc published a blog post
トラックバック:official italianculture.net blog
トラックバック:Bulit-In Ovens
トラックバック:http://gtrade.cc
トラックバック:Eastleigh frames
トラックバック:to algowiki.win
トラックバック:Replacement Mercedes Key
トラックバック:Acheter Un Permis De Conduire
トラックバック:Forum.Ressourcerie.Fr
トラックバック:reviews over at www.stes.tyc.edu.tw
トラックバック:Window Repair Bromley
トラックバック:best Rollator walker with seat
トラックバック:bifold door repairs near me
トラックバック:Altdeutscher SchäFerhund Kaufen
トラックバック:Game judi togel
トラックバック:signs and symptoms of adhd in women
トラックバック:Sectional Sleepers
トラックバック:Https://Vladivostok.Defiletto.Ru/Bitrix/Redirect.Php?Goto=Https://Oi2Bv4Qg7Fba.Com
トラックバック:https://ballard-atkinson.thoughtlanes.net/this-is-the-senior-scooters-case-study-youll-never-forget/
トラックバック:Telebookmarks website
トラックバック:www.stes.tyc.edu.tw wrote in a blog post
トラックバック:replacement Key Fobs for cars
トラックバック:Extension.Unimagdalena.Edu.Co
トラックバック:https://social.mirrororg.com/read-blog/6298_20-b1-driving-license-websites-taking-the-Internet-by-storm.html
トラックバック:Togel terlengkap
トラックバック:http://www.sysuimars.cn:3000/topsadulttoys9119/nicolas1980/wiki/why you should focus on improving Rabbit toy adult
トラックバック:Lost Car Key Replacement
トラックバック:에볼루션게이밍
トラックバック:Composite Door replacement keys
トラックバック:car Key repairs
トラックバック:https://skyfish.ru/
トラックバック:right here on penza-sputnik.ru
トラックバック:Wonnews.Kr
トラックバック:Bariatric foldable electric Wheelchair
トラックバック:how to become a autowatch Ghost installer
トラックバック:www.medflyfish.com
トラックバック:Https://Minecraftcommand.Science/Profile/Bankertimer0
トラックバック:https://hogan-beck.technetbloggers.de
トラックバック:locked keys in fiat 500
トラックバック:getting diagnosed With adhd as an adult
トラックバック:mental health symptoms of depression
トラックバック:nutris.net
トラックバック:collapsible motor scooter
トラックバック:Automatic fold up mobility scooter
トラックバック:treadmill with Incline uk
トラックバック:git.881221.xyz
トラックバック:shop power Tool sets
トラックバック:2 Seater fabric lounge
トラックバック:kup prawo jazdy a a1 A2 bez Testu
トラックバック:Http://bbs.theviko.com/
トラックバック:Git.Bubbleioa.Top
トラックバック:Electric Integrated oven
トラックバック:bariatric Folding wheelchair
トラックバック:private adhd Assessment isle of wight
トラックバック:male Adult toy
トラックバック:Double Glazing Repair Near Me
トラックバック:women and attention deficit Disorder
トラックバック:Https://Www.Xaphyr.Com
トラックバック:https://situsgotogel81279.blogsmine.com/33224293/how-alternatif-gotogel-terpercaya-is-a-secret-life-secret-life-of-alternatif-gotogel-terpercaya
トラックバック:fitness Bike
トラックバック:agen togel deposit Termurah
トラックバック:adhd assessment For adults private
トラックバック:windows & doors company
トラックバック:Bi-Fold door repairs Near me
トラックバック:sash
トラックバック:replacement glass for windows
トラックバック:treadmill without electric
トラックバック:Adult Add Adhd Test
トラックバック:power wheelchair foldable
トラックバック:Exercise Cycle Home
トラックバック:online Test for adhd In adults
トラックバック:myclassictv.com official
トラックバック:how to get a Private adhd assessment
トラックバック:https://longshots.wiki/
トラックバック:shipping container design
トラックバック:Double glazing Manchester
トラックバック:Lg Freezers
トラックバック:Buy Bariatric Wheelchair
トラックバック:http://110.42.178.113:3000/Sofasandcouches1966
トラックバック:dokuwiki.stream officially announced
トラックバック:3 wheel tandem stroller
トラックバック:Tool Bundles
トラックバック:Double Galzed Windows
トラックバック:Sp-Cosmetics.Ru
トラックバック:adhd Screening test
トラックバック:https://historydb.date
トラックバック:container tunneling
トラックバック:click through the following web page
トラックバック:Cushioned Wheelchair
トラックバック:https://hildebrandt-acevedo.Mdwrite.net
トラックバック:Light leather Couch
トラックバック:adhd Private Test
トラックバック:Private Mental Health Assessment Near Me
トラックバック:related website
トラックバック:Shop front repairs birmingham
トラックバック:https://elearnportal.science/wiki/The_Most_Underrated_Companies_To_Watch_In_The_Battery_Tool_Kit_Industry
トラックバック:french-bulldog79970.theblogfairy.com
トラックバック:Read Bravejournal
トラックバック:http://formika.site
トラックバック:check out this blog post via Xintangtc
トラックバック:Fmagency.Co.Uk
トラックバック:cs battle case
トラックバック:mobile locksmith near me For Cars
トラックバック:yakutsk.academica.ru
トラックバック:battery
トラックバック:treadmills
トラックバック:Formula Togel
トラックバック:http://freeok.cn/home.php?mod=space&uid=6761399
トラックバック:window frame Repair
トラックバック:adhd Treatment in Adults
トラックバック:199.115.228.41
トラックバック:Ordait officially announced
トラックバック:replacement mercedes key Near Me
トラックバック:Http://Demo.Reviveadservermod.Com/Prodara_Revi402/Www/Delivery/Ck.Php?Ct=1&Oaparams=2__Bannerid=29__Zoneid=18__OXLCA=1__Cb=0Bf3930B4F__Oadest=Https://Swedishdrivers-License.Com/
トラックバック:smokebike57.bravejournal.net
トラックバック:mystery boxes websites
トラックバック:Https://Www2.Hamajima.Co.Jp:443/~Mathenet/Wiki/Index.Php?Stefansenwind905051
トラックバック:b197 führerschein legal In der eu
トラックバック:https://images.google.cf/url?q=https://click4r.Com/posts/g/18422923/20-trailblazers-lead-the-way-in-how-to-get-assessed-for-adhd
トラックバック:https://scalescrew28.werite.net/whats-the-point-of-nobody-caring-about-retro-fridge-freezer-50-50
トラックバック:offer
トラックバック:Check Out www.metooo.co.uk
トラックバック:köP Am Körkort
トラックバック:Https://Bookmark4You.Win/Story.Php?Title=Double-Strollers-Tools-To-Streamline-Your-Daily-Lifethe-One-Double-Strollers-Trick-That-Everybody-Should-Be-Ab
トラックバック:high-capacity Mobility Scooters
トラックバック:https://fakenews.win/wiki/Ten_Best_Sex_Toy_To_Make_Women_Squirts_That_Really_Change_Your_Life
トラックバック:https://www.Youtube.com/
トラックバック:ritchie-ipsen-2.blogbright.net
トラックバック:best anxiety disorder Treatment
トラックバック:being diagnosed with adhd in adulthood
トラックバック:hyundai car Key Replacement cost
トラックバック:94.224.160.69
トラックバック:bariatric mobility Scooters
トラックバック:stewjet68.werite.net
トラックバック:boiler Gas Engineer
トラックバック:gas-safety-check07234.dm-blog.com
トラックバック:Manchester Window
トラックバック:https://xintangtc.com/home.php?mod=Space&uid=3687301
トラックバック:Best brands refrigerators
トラックバック:wooden bunk beds with storage
トラックバック:how to program Land rover lr3 key fob
トラックバック:Diagnosis of adult Adhd
トラックバック:Falschgeld Im Darknet Kaufen
トラックバック:Highest Rated Robot Vacuum
トラックバック:door repair Birmingham
トラックバック:Back Door With Cat Flap Fitted
トラックバック:Saab Key
トラックバック:Www.Xiaodingdong.Store
トラックバック:replacement lexus key
トラックバック:https://ask.mgbg7b3bdcu.net/user/angerguilty61
トラックバック:dynamax runningpad folding Treadmill
トラックバック:double stroller lightweight
トラックバック:Kia picanto Car Key replacement
トラックバック:private adhd assessment medway
トラックバック:double glazed front doors maidstone
トラックバック:2 in 1 travel System
トラックバック:Http://142.93.151.79/Cooperschicago4653
トラックバック:shaffer-Vilhelmsen.technetbloggers.de
トラックバック:Adhd In Adults Characterization Diagnosis And Treatment
トラックバック:프라그마틱 무료 슬롯버프
トラックバック:how can i get an adhd diagnosis
トラックバック:psychiatric Assessment Services
トラックバック:Treadmills sale
トラックバック:Floor robot
トラックバック:www.google.mn
トラックバック:maanation.com
トラックバック:Treartex.Ru
トラックバック:Lost car key Skoda
トラックバック:repair Window
トラックバック:프라그마틱 무료스핀
トラックバック:small Built in microwave Oven
トラックバック:Https://historydb.date/
トラックバック:http://nutris.Net/
トラックバック:more about yanyiku.cn
トラックバック:sapphire-mango-n59wj6.mystrikingly.com
トラックバック:Best Masterbators
トラックバック:Adult adhd Diagnosis northern ireland
トラックバック:maps.google.no official
トラックバック:adhd test online
トラックバック:에볼루션 사이트
トラックバック:Top 10 Robot Vacuum Cleaner
トラックバック:gdeotveti.Ru
トラックバック:Pediascape`s latest blog post
トラックバック:fridge Freezers with water dispenser
トラックバック:https://morphomics.science/wiki/Learn_To_Communicate_Link_Login_Gotogel_To_Your_Boss
トラックバック:Best Electric Treadmill For Home
トラックバック:What Happens In A Psychiatric Assessment
トラックバック:https://cameradb.review/
トラックバック:tsolus.com
トラックバック:G28Carkeysolutions35613.Mycoolwiki.Com
トラックバック:Best Car seats
トラックバック:honda Keys replacement
トラックバック:best fridge-freezer
トラックバック:https://friendly-lichee-fzlhdz.mystrikingly.com/blog/why-you-should-concentrate-on-improving-shop-anal-toy
トラックバック:Cheapest Adhd Assessment Uk
トラックバック:DeWalt Clearance UK Online
トラックバック:Cordless tool Sets
トラックバック:crystal-seal-hvt1z7.mystrikingly.com
トラックバック:Electric Fold up wheelchairs
トラックバック:Exercise Bike Review
トラックバック:106.15.41.156
トラックバック:2003 jaguar x type key replacement
トラックバック:köRkort flexibelt
トラックバック:Space Saving Side By Side Fridge Freezer
トラックバック:treadmills Fold Up
トラックバック:Newport Pagnell gas Engineer
トラックバック:Bmw key fob replacement cost
トラックバック:comicviewer.net
トラックバック:köp körkort b96 utan examen online
トラックバック:scenep2P.com
トラックバック:upvc repairs near me
トラックバック:youtube.com
トラックバック:Netvoyne.Ru
トラックバック:best one time mystery Box
トラックバック:reviews over at I Hire
トラックバック:leading refrigerator Brands
トラックバック:licencefrancexpress56018.blogoscience.com
トラックバック:https://blogfreely.net/Foodsphynx37/the-10-most-worst-buy-registered-drivers-license-Fails-of-all-time-could
トラックバック:here
トラックバック:https://cosmos.phys.sci.ehime-u.ac.jp:443/~kobayashi/COSMOS20_wiki/index.php?laustsenmueller823710
トラックバック:https://maps.google.com.pr/url?Q=https://k12.instructure.com/Eportfolios/825587/home/10_pinterest_accounts_to_follow_online_mystery_box
トラックバック:land rover Key replacement cost
トラックバック:köRkort Via post
トラックバック:Http://Www.Gunmamap.Gr.Jp/Refer.Cgi?Url=Https://Www.Exercisebikesonline.Uk
トラックバック:Woodworking Power Tool Set
トラックバック:black dual fuel range cooker
トラックバック:braceshears92.Bravejournal.net
トラックバック:Leather Couch L Shaped
トラックバック:https://Getdota2.ru/
トラックバック:from the bbs.pku.edu.cn blog
トラックバック:psychiatrist For add near me
トラックバック:distressed Leather sofa
トラックバック:Http://Bioimagingcore.be/
トラックバック:Http://Wx.Abcvote.Cn/
トラックバック:Mental health Checkup
トラックバック:https://cratewind5.bravejournal.net/10-wrong-answers-for-common-link-Login-gotogel-questions-do-you-know-the-Right
トラックバック:https://loont.com/wiki/User:Heylink1842
トラックバック:Https://Www.Google.Fm/
トラックバック:Yogicentral site
トラックバック:best 3 wheel Mobility scooter
トラックバック:reviews over at 58
トラックバック:Bank-Craig-3.Blogbright.Net
トラックバック:https://metaprom.ru
トラックバック:Https://Ekaterinburg.Mavlad.Ru/
トラックバック:realistic sex Dolls
トラックバック:audi remote key
トラックバック:www.wulanbatuoguojitongcheng.com
トラックバック:Online Tools Shopping
トラックバック:New skoda key
トラックバック:Dsm Anxiety Disorders
トラックバック:https://www.bioguiden.se/redirect.aspx?url=https://teague-humphrey-2.mdwrite.net/the-no-one-question-that-everyone-working-in-situs-togel-terpercaya-should-be-able-answer-1739407774
トラックバック:Realsex dolls
トラックバック:hola666.com
トラックバック:modern mobility scooters
トラックバック:Click at www.hulkshare.com
トラックバック:https://funsilo.date/wiki/Link_Daftar_Gotogel_The_Good_The_Bad_And_The_Ugly
トラックバック:published on marvelvsdc.faith
トラックバック:Childrens midi cabin beds
トラックバック:Www.Meetme.Com
トラックバック:Mental Health Assessment London
トラックバック:http://www.pcnews.com.Tw/DiscuzBBS/home.php?Mod=space&uid=173669
トラックバック:Https://Kingranks.Com
トラックバック:Https://unibrave.ru:443/bitrix/redirect.php?goto=https://jazzagecomics.com/
トラックバック:lightweight self propelled wheelchairs
トラックバック:Tyc`s blog
トラックバック:Meetme site
トラックバック:written by Zenwriting
トラックバック:https://menwiki.Men/wiki/5_killer_Qoras_answers_to_toto_macau
トラックバック:Advanced safety Features scooters
トラックバック:Single Seat stroller
トラックバック:add Women
トラックバック:www-x.phys.se.tmu.ac.jp
トラックバック:good exercise bike
トラックバック:upvc Windows repair Near me
トラックバック:Gas Safety Certificate Replacement
トラックバック:visit Nerdgaming now >>>
トラックバック:power tool combo Kit deals
トラックバック:serialesseria.ru
トラックバック:Black Fabric 3 Seater Sofa
トラックバック:geldfälschung kaufen
トラックバック:fxprimer.Ru
トラックバック:Single Oven Integrated
トラックバック:New jaguar Key
トラックバック:African Grey Parrots For Adoption
トラックバック:Visit Hulkshare
トラックバック:self propelled wheelchairs uk
トラックバック:robot Vacuum deals black friday
トラックバック:https://shenasname.ir/
トラックバック:KöPa KöRkortonline
トラックバック:car locksmiths near Bedford
トラックバック:Emergency glass repair near me
トラックバック:2013 kia sorento key Fob
トラックバック:https://linkingbookmark.com/story16338981/the-advanced-guide-To-treadmill-used-for-sale
トラックバック:Private Adhd Diagnosis Uk Cost
トラックバック:double glazing upvc windows
トラックバック:easho.co.uk
トラックバック:Door Seal Repair Near Me
トラックバック:Car Unlockers
トラックバック:Media.Nudigi.Id
トラックバック:Soft Leather Couch
トラックバック:Demilked official website
トラックバック:Https://Glamorouslengths.Com/Author/Quietcall53
トラックバック:https://Current.pacunion.com
トラックバック:Top-rated Mobility Scooters
トラックバック:Can A Doctor Prescribe Adhd Medication Without A Diagnosis
トラックバック:double glazed Windows repairs
トラックバック:lg fridge freezer models
トラックバック:best Dildo
トラックバック:köRkort Köpa
トラックバック:best Online Mystery boxes
トラックバック:Lsrczx website
トラックバック:fuhrerschein-kaufen-ohne-Vorkasse
トラックバック:class 2 mobility Scooters for sale
トラックバック:assessment For mental Health
トラックバック:https://nativ.Media:443/wiki/index.php?lambglue577
トラックバック:2 Seater fabric couch
トラックバック:Bentley flying spur key
トラックバック:2 in 1 baby pram
トラックバック:citroen jumper Key
トラックバック:Upton-Mackinnon.Technetbloggers.De
トラックバック:Google blog entry
トラックバック:bbs.tejiegm.com
トラックバック:fixa Nytt köRkort
トラックバック:desk treadmills
トラックバック:에볼루션바카라
トラックバック:KöPa Nytt KöRkort
トラックバック:duplicate car key
トラックバック:randomwalk.co.Kr
トラックバック:Double Hlazing
トラックバック:most Realistic sex Doll review
トラックバック:2 in 1 car seat Stroller
トラックバック:https://powertool37344.wikiusnews.com/
トラックバック:Gas engineer Newport pagnell
トラックバック:Adhd assessment for adult women
トラックバック:Adult Male Adhd Symptoms
トラックバック:adhd symptoms in man
トラックバック:lightweight collapsible mobility scooters
トラックバック:writes in the official www.demilked.com blog
トラックバック:Composite Doors High Wycombe
トラックバック:Window Repair
トラックバック:bedside rocking Crib
トラックバック:shorty cabin bed
トラックバック:Fabric 2 Seater Sofas sale
トラックバック:review
トラックバック:3 seater Beige fabric sofa
トラックバック:Read More On this page
トラックバック:glass window Repair
トラックバック:psychiatrist Private practice
トラックバック:door Doctor
トラックバック:www.aupeopleweb.com.Au
トラックバック:Small Chaise sofa
トラックバック:remote key fob repairs
トラックバック:http://rutelochki.ru/
トラックバック:Best self cleaning robot vacuum
トラックバック:Adhd Diagnosis Tools For Adults
トラックバック:Can You Self Diagnose Adhd
トラックバック:amazon double Stroller
トラックバック:programmer
トラックバック:double Glazing London
トラックバック:view jobs.linttec.com
トラックバック:bunk beds for kids
トラックバック:writes in the official Writeablog blog
トラックバック:psychiatric assessment uk
トラックバック:private Adhd assessment harrogate
トラックバック:Power Tools Online Uk
トラックバック:carpentry tool Kit
トラックバック:strongest adhd medication
トラックバック:new post from cameradb.review
トラックバック:Where To Repair Car Key Remote
トラックバック:American fridge Freezer 90Cm wide
トラックバック:Private Adhd Assessment Taunton
トラックバック:What does treadmill incline Mean
トラックバック:https://www.weatheravenue.com/fr/https://niedlichfranzsischebulldoggenwelpen-0qd.de
トラックバック:http://www.annunciogratis.net/Author/aprilshirt29
トラックバック:Folding lightweight mobility Scooter
トラックバック:http://www.crazys.cc/forum/space-uid-1191493.html
トラックバック:mental health screening Uk
トラックバック:animalhome27.werite.Net
トラックバック:https://profi-art.ru
トラックバック:köp Svenskt Körkort
トラックバック:lost Car keys Replacement
トラックバック:Private psychiatrist Slough
トラックバック:inexpensive Electric treadmills
トラックバック:Best Portable Electric Mobility Scooter
トラックバック:compact treadmill with incline for home
トラックバック:home window Glass Repair near me
トラックバック:key repair shops near me
トラックバック:Modemvein46.Werite.net
トラックバック:cost of Spare car key
トラックバック:Power Tools Co Uk
トラックバック:double glazed window suppliers near me
トラックバック:Replacement Window Panes Double Glass
トラックバック:Adhd Medication For Adults Uk
トラックバック:how to get adhd diagnosis adults uk
トラックバック:maps.google.gg
トラックバック:Https://Imoodle.Win
トラックバック:프라그마틱 무료체험
トラックバック:https://articlescad.com/10-stroller-2-in-1-related-projects-to-stretch-your-creativity-212150.html
トラックバック:treadmill without Electricity
トラックバック:Small leather couch
トラックバック:slim island range hood
トラックバック:Discover More Here
トラックバック:Https://Www.Google.Co.Vi/Url?Q=Http://Brewwiki.Win/Wiki/Post:What_Is_Gas_Engineers_Near_Me_And_How_To_Utilize_What_Is_Gas_Engineers_Near_Me_And_How_To_Use
トラックバック:https://images.google.td/url?q=https://fakenews.win/wiki/10_Unexpected_Fridge_Freezers_Retro_Tips
トラックバック:What Is The Best Fridge Brand
トラックバック:Experts
トラックバック:workout
トラックバック:best
トラックバック:How Do I Get Assessed For Adhd
トラックバック:Large Bedside Crib
トラックバック:untreated adhd In adults relationships
トラックバック:skoda car key replacement Cost
トラックバック:psychological indicators of depression
トラックバック:crypto wild casino
トラックバック:https://posteezy.com/productive-Rant-about-best-treatment-adhd-adults
トラックバック:are all treadmill Inclines the same
トラックバック:adhd adults Diagnosis
トラックバック:how do i get a adhd diagnosis
トラックバック:Olderworkers said
トラックバック:3 Wheeler pushchairs from birth
トラックバック:Jurypink54.Bravejournal.Net
トラックバック:private adhd assessment east sussex
トラックバック:Emergency
トラックバック:58 blog post
トラックバック:Best infant cribs
トラックバック:samsung fridge freezer uk
トラックバック:Adhd Symptoms in Adults Uk
トラックバック:https://bunk-beds-store96669.blog-a-story.com/8408181/ten-bunk-beds-uk-sales-that-really-make-your-life-better
トラックバック:go directly to Telegra
トラックバック:Https://itkvariat.com
トラックバック:harrison-Krabbe.technetbloggers.de
トラックバック:körkort föRnya
トラックバック:lightweight car boot mobility Scooters
トラックバック:fridge Freezer retro
トラックバック:lzdsxxb.com explained in a blog post
トラックバック:loveseat Pull out couch
トラックバック:childrens white bunk beds
トラックバック:Foldable electric Treadmill
トラックバック:Leather Couches For Sale
トラックバック:U Shaped Sofa Beds
トラックバック:1moli official website
トラックバック:skoda fabia key programming
トラックバック:careers.Jabenefits.com
トラックバック:Best Places To Buy Bunk Beds
トラックバック:adhd testing online For adults
トラックバック:pushchair 2 in 1 Sale uk
トラックバック:Car key replacement service
トラックバック:Wizdomz.wiki
トラックバック:Best travel mobility scooter
トラックバック:robot vacuum cleaner Black friday
トラックバック:Zwangerschapspagina website
トラックバック:Going to Abort 73
トラックバック:http://srv29897.ht-test.ru/
トラックバック:Local Gas engineers near me
トラックバック:best crypto online casino
トラックバック:Wooden Bunk Beds For Kids
トラックバック:https://elearning.hcbeauty.com/
トラックバック:adhd evaluation Tools
トラックバック:click here to visit menwiki.men for free
トラックバック:robot vacuum cleaner Review
トラックバック:right here on images.google.com.pa
トラックバック:leather recliner Grey
トラックバック:slide and hide single oven
トラックバック:Real Leather sofa
トラックバック:assess Your mental health
トラックバック:Bedside Crib To Cot
トラックバック:jusomo-eumsaiteu40219.Theobloggers.com
トラックバック:how much is A ghost immobiliser
トラックバック:metal Bunk bed double and single
トラックバック:peugeot 207 key fob programming
トラックバック:Slide Bed
トラックバック:프라그마틱 사이트
トラックバック:Car key fob repair service
トラックバック:car key repair near me
トラックバック:uncommon Adhd symptoms
トラックバック:Criteria for adhd diagnosis
トラックバック:Best french door fridge with water dispenser
トラックバック:Auto Folding Mobility Scooter near Me
トラックバック:cheap couches for Sale under $100
トラックバック:wood and Metal
トラックバック:Treating depression without antidepressants
トラックバック:green Power
トラックバック:Https://Www.Ahmstlambert.Com
トラックバック:Private Psychiatrist Yorkshire
トラックバック:https://images.google.co.il/url?q=http://valetinowiki.racing/index.php?title=steelepaulsen8826
トラックバック:3 wheel Stroller set
トラックバック:How much is a private adhd assessment uk
トラックバック:Adhd In Adult Women Treatment
トラックバック:french door Fridge nz
トラックバック:http://canuckstuff.com
トラックバック:Electric single ovens
トラックバック:Car Seat Pram
トラックバック:adhd test adult Women
トラックバック:large american fridge freezers
トラックバック:Adhd Assessment Tools For Adults Online
トラックバック:What is ghost immobiliser
トラックバック:http://153.126.169.73/question2answer/index.php?Qa=user&qa_1=Teampuffin07
トラックバック:combination microwave oven built-in
トラックバック:Small couch
トラックバック:private practice psychiatrist
トラックバック:https://click4r.com/posts/g/18618881/watch-out-what-robotic-cleaner-and-mop-Is-taking-over-and-what-to-do
トラックバック:bunk Beds for teenagers
トラックバック:laursen-roberson.hubstack.net
トラックバック:comfortable couches For sale
トラックバック:tappat körkort göRa nytt
トラックバック:adhd Anxiety symptoms
トラックバック:Blog officially announced
トラックバック:https://marvelvsdc.faith/
トラックバック:adhd diagnostic assessment tool
トラックバック:test for Adhd in Adults
トラックバック:psychology today mental health assessment
トラックバック:built in single fan oven
トラックバック:buy power tools
トラックバック:jisuzm.tv
トラックバック:collapsible Scooters
トラックバック:http://www.eriest.com
トラックバック:viking-chairs.com
トラックバック:car Key copy service
トラックバック:Adhd symptoms Adults test
トラックバック:maxi cosi pearl 360 car seat
トラックバック:www.thecadforums.com
トラックバック:Black Recliner Leather
トラックバック:best power tool set for home
トラックバック:marvelvsdc.faith writes
トラックバック:historydb.date blog article
トラックバック:how to test For Adhd in adults
トラックバック:replacement Lost car keys
トラックバック:Adult electric mobility Scooter
トラックバック:integrated Fridge Freezer 50/50 uk
トラックバック:car Boot mobility Scooter
トラックバック:private Psychiatry Uk
トラックバック:Duplicate Car Key Near Me
トラックバック:veleco mobility scooter for sale
トラックバック:https://frydge71601.ja-blog.com
トラックバック:pushchairs-and-prams39626.blogunok.com
トラックバック:Top 5 Refrigerator Brands
トラックバック:Going at Instructure
トラックバック:self cleaning vacuum cleaner
トラックバック:visit images.google.com.pa`s official website
トラックバック:90Cm Single oven range cooker
トラックバック:Adhd Assessment uk
トラックバック:Double Pushchairs for toddlers
トラックバック:head to the 143 site
トラックバック:Single Running Stroller
トラックバック:2.viromin.com
トラックバック:Misplaced
トラックバック:Adult Adhd diagnosis scotland
トラックバック:adhd symptoms adults Treatment
トラックバック:adhd medication and Pregnancy
トラックバック:best Online tool store
トラックバック:Bed for kids
トラックバック:click here to visit Icrosswalk for free
トラックバック:Best Adhd Medication Uk
トラックバック:recent post by heavenarticle.com
トラックバック:single bunk bed with desk underneath
トラックバック:http://47.107.29.61:3000/robotvacuummops7712
トラックバック:Generalized Anxiety disorder diagnosis
トラックバック:stove
トラックバック:Under Bed Treadmill With Incline
トラックバック:built in single oven With Grill
トラックバック:how to get diagnosed with adult add
トラックバック:mouse click on moparwiki.win
トラックバック:anxiety Treatment symptoms
トラックバック:Http://Raiana.Ru/Redirect?Url=Https://Oi2Bv4Qg7Fba.Com
トラックバック:Https://ray-brogaard-2.Technetbloggers.De/
トラックバック:Https://Trade-britanica.trade/wiki/15_Things_Youre_Not_Sure_Of_About_Leather_Sofa_And_Recliner
トラックバック:cost of replacing lost car keys
トラックバック:adhd impulsivity treatment
トラックバック:Https://Humanlove.Stream
トラックバック:Ghost Ii immobiliser
トラックバック:single Bed bunk Bed
トラックバック:https://Ucgp.jujuy.edu.ar/profile/warmneed55/
トラックバック:Car key services
トラックバック:https://Veengy.com
トラックバック:Green Power mobility
トラックバック:Https://Bro-Russell-2.Mdwrite.Net/
トラックバック:treatment Resistant Anxiety
トラックバック:Best Bunk Bed In The World
トラックバック:offshore containers
トラックバック:Stolen Car keys
トラックバック:car key Remote replacement
トラックバック:mobility scooters for sale Near me
トラックバック:Tappat KöRkort Vad GöRa
トラックバック:how long does adhd titration take
トラックバック:luxury Mobility Scooters
トラックバック:https://vadaszapro.eu/user/profile/1336945
トラックバック:credit-hall.ru
トラックバック:l shaped bed
トラックバック:adhd symptoms In adult men
トラックバック:collapsible mobility scooters Uk
トラックバック:www.hebian.cn
トラックバック:https://www.metooo.io/u/66e85d15B6d67d6d178207a4
トラックバック:french door fridge india
トラックバック:lost keys in car
トラックバック:Adult Adhd Test
トラックバック:https://Mccoy-mchugh-6.blogbright.net/
トラックバック:https://imoodle.win/wiki/Why_People_Dont_Care_About_ADHD_Test_Adult
トラックバック:women with attention deficit disorder
トラックバック:low maintenance side by Side fridge freezer
トラックバック:https://cos-com.net/
トラックバック:weblink
トラックバック:4 seater corner leather Sofa
トラックバック:French door Fridge Sale
トラックバック:Check Out www.hondacityclub.com
トラックバック:symptoms of Add and adhd in adults
トラックバック:Memory Foam Mattress Toppers
トラックバック:franklin-torres.Mdwrite.net
トラックバック:https://Qooh.Me/
トラックバック:keyrepair
トラックバック:auto locksmiths in Milton keynes
トラックバック:costs
トラックバック:3 Wheel baby strollers
トラックバック:best brand in refrigerator
トラックバック:hendrix-calhoun-3.blogbright.net
トラックバック:Lshaped Bunk beds
トラックバック:echten führerschein kaufen erfahrungen
トラックバック:Bysee3.com
トラックバック:Fitted
トラックバック:https://jespersen-buhl-3.federatedjournals.com/10-quick-tips-about-cabin-bed-mid-sleeper
トラックバック:scooters Mobility For sale
トラックバック:private Test For adhd
トラックバック:Motorized Mobility Scooters
トラックバック:https://Menwiki.men/wiki/how_to_tell_the_right_counterfeit_german_banknotes_for_you
トラックバック:https://salarygerman4.werite.net/The-12-Worst-types-of-the-twitter-accounts-that-you-follow
トラックバック:Google.com.Pk
トラックバック:French door fridge in India Price
トラックバック:via Hubstack
トラックバック:https://pollock-wilkerson.hubstack.net/this-is-The-advanced-guide-to-kids-bed-with-slide-1736130337
トラックバック:Adhd Symptom Test For Adults
トラックバック:Bunk Beds For Cabins
トラックバック:french Door fridge with ice maker no plumbing
トラックバック:scooters 4 wheels
トラックバック:most expensive robot vacuum
トラックバック:dewalt power tools deals
トラックバック:Vauxhall Corsa Key
トラックバック:https://clicavisos.com.ar/
トラックバック:Newport Pagnell gas safe Registered Engineer
トラックバック:psychological treatment for adhd in Adults
トラックバック:Best Fridges
トラックバック:Kids Bunk Beds With Mattresses
トラックバック:ghost Immobiliser review
トラックバック:dokuwiki.stream published a blog post
トラックバック:most energy efficient chest freezer uk
トラックバック:porsche Remote
トラックバック:https://click4r.com/posts/G/19723252/what-freud-can-teach-us-about-pragmatic-free
トラックバック:savage-thorup-2.technetbloggers.de
トラックバック:Faktes.Ru
トラックバック:falschgeld-Kaufen65176.Wikijournalist.com
トラックバック:Https://Car-Locksmith11116.Hyperionwiki.Com/
トラックバック:bunk Bed Cheap
トラックバック:Lg Tall fridge
トラックバック:fäLschungen legal kaufen
トラックバック:Http://dudoser.com
トラックバック:recent post by Bannyydom
トラックバック:Corgi Gas Engineer Near Me
トラックバック:https://writeablog.net/temperfan9/11-ways-to-completely-redesign-your-skoda-key
トラックバック:qualitatives Falschgeld bestellen
トラックバック:Integrated Microwave
トラックバック:treehouse Toddler Bed
トラックバック:anzforum.com post to a company blog
トラックバック:mobility boot scooter
トラックバック:small Fabric 2 seater Sofa
トラックバック:car locksmith Milton keynes
トラックバック:annual gas safety check Newport Pagnell
トラックバック:www.question-ksa.com
トラックバック:best hobs Uk
トラックバック:Metal Loft bunk bed
トラックバック:New lg refrigerator
トラックバック:top 10 Refrigerator brands
トラックバック:French Door Fridge Ice Dispenser
トラックバック:Cooker Island Hood
トラックバック:Https://Falschgeldkaufen56079.Birderswiki.Com
トラックバック:https://fakenews.win
トラックバック:keyless
トラックバック:fridge Freezer uk sale
トラックバック:replacements
トラックバック:nissan qashqai replacement key Cost
トラックバック:betflix
トラックバック:Fridges Brands
トラックバック:Single Bunk bed with desk
トラックバック:mahler-warren-2.blogbright.net
トラックバック:installation
トラックバック:Pattern Wiki explained in a blog post
トラックバック:electric Mobility scooter foldable
トラックバック:beds bunk Beds
トラックバック:https://Championsleage.review
トラックバック:childrens treehouse bed
トラックバック:retro fridges Freezers
トラックバック:3 Wheel Battery Powered Scooter
トラックバック:https://hikvisiondb.webcam/wiki/Middletonblair5767
トラックバック:images.Google.com.pa
トラックバック:from the Posteezy blog
トラックバック:Mobility scooter for sale near Me
トラックバック:cost for car key replacement
トラックバック:Https://menwiki.men/
トラックバック:Green Power Mobility reviews
トラックバック:Telegra post to a company blog
トラックバック:Integrated American Fridge Freezer Uk
トラックバック:https://norris-rodgers.technetbloggers.de/why-wood-frame-twin-bunk-beds-could-be-a-lot-more-hazardous-than-you-thought/
トラックバック:cheapest Fridge freezers uk
トラックバック:cheap wooden bunk beds
トラックバック:best fridge freezers
トラックバック:forexmob.ru
トラックバック:3 wheel Double pushchair
トラックバック:gas Safe registered engineer buckingham
トラックバック:sectional Sleeper sofa Queen
トラックバック:4 Wheel mobility scooters For Sale
トラックバック:Integrated fan oven
トラックバック:visit Qooh`s official website
トラックバック:lillelund-damsgaard-2.blogbright.net
トラックバック:101.33.255.60
トラックバック:best Retro fridge freezer
トラックバック:Extra Firm Mattress Topper
トラックバック:https://www.easyfie.com/rocketscent63
トラックバック:stampe-ballard-2.technetbloggers.De
トラックバック:https://www.google.com.pe/
トラックバック:sofa sofa sale
トラックバック:just click Google
トラックバック:Key Replacement Car
トラックバック:leather Modular sofa
トラックバック:Https://Lab.Evlic.Cn
トラックバック:retro fridge Freezers best prices
トラックバック:frydge89973.ktwiki.com
トラックバック:Werite officially announced
トラックバック:landlord gas safety certificate Newport Pagnell
トラックバック:Children’s Pine Bunk Bed
トラックバック:ball-frederick-2.blogbright.Net
トラックバック:Leather Sofa And Recliner
トラックバック:https://e-Sungwoo.co.kr/
トラックバック:check out this one from Menwiki
トラックバック:buketik39.ru
トラックバック:Best Bunk Beds For small rooms
トラックバック:refridgerator Uk
トラックバック:which Fridge brand is best
トラックバック:Green mobility Scooters
トラックバック:Double Bed And Single Bed Bunk
トラックバック:Www.Google.Bt
トラックバック:4 seater split leather sofa
トラックバック:Sectional Sleeper
トラックバック:Seo.Ruituoyun.com
トラックバック:https://chara-deco.Com
トラックバック:http://www.fluencycheck.com/user/islandbeer28
トラックバック:international driving License
トラックバック:best place to buy Mobility scooter
トラックバック:https://www.hulkshare.com/shapepail1/
トラックバック:http://Www.optionshare.Tw
トラックバック:brandstrup-Conrad.hubstack.net
トラックバック:frydge67070.blogsvirals.com post to a company blog
トラックバック:countryside scooters
トラックバック:bedside Cot Used
トラックバック:written by Moparwiki
トラックバック:lg electronics Refrigerators
トラックバック:car spare key cost
トラックバック:fridge Best price
トラックバック:Inbuilt Ovens
トラックバック:heavy duty mobility scooters for sale
トラックバック:French door fridge good Guys
トラックバック:Wifidb wrote
トラックバック:Corner Sofas leather Fabric
トラックバック:built Microwave oven combo
トラックバック:boot Scooters for sale
トラックバック:2 In 1 pram
トラックバック:mobility scooters collapsible
トラックバック:autofold mobility scooter
トラックバック:head to the Pvpgames site
トラックバック:Refrigerator Brand
トラックバック:casino crypto coin
トラックバック:images.google.co.il
トラックバック:https://www.google.com.Ag/
トラックバック:https://telegra.ph/15-things-you-didnt-know-about-mines-gamble-11-24
トラックバック:oven Reviews
トラックバック:douerdun.com
トラックバック:molina-mccall-2.technetbloggers.De
トラックバック:hur får man nytt körkort
トラックバック:best mobility scooters For sale near me
トラックバック:double glazed Doors high wycombe
トラックバック:leather Recliner Tan
トラックバック:retro American fridge freezers uk
トラックバック:intimity.shop said
トラックバック:recliner sofas leather
トラックバック:Https://Zenwriting.Net/Beggarprofit27/Seven-Explanations-On-Why-Oven-Uk-Is-Important
トラックバック:Cheapest Mobility Scooters For Sale
トラックバック:case battle Run
トラックバック:Green Mobility
トラックバック:Https://Bookmarks4.Men/Story.Php?Title=The-Most-Prevalent-Issues-In-All-Crypto-Casinos
トラックバック:securityholes.science’s website
トラックバック:Best brand For fridge freezer
トラックバック:http://delphi.Larsbo.org/user/sharksun3
トラックバック:Workshop power Tool set
トラックバック:compact travel pram
トラックバック:Monobookmarks.Com
トラックバック:he said
トラックバック:samsung Samsung fridge
トラックバック:https://footwood7.bravejournal.net/pavement-Mobility-scooter-with-lithium-batterys-history-of-Pavement-mobility
トラックバック:best sturdy Bunk beds
トラックバック:Chest Freezer Most Energy Efficient
トラックバック:Best Pull out couch
トラックバック:120.Zsluoping.cn
トラックバック:Island Extractors
トラックバック:Going to Fuwafuwa
トラックバック:fabric 2 seater
トラックバック:Fightlyre5.Werite.net
トラックバック:best 3 wheel stroller travel System
トラックバック:https://telegra.ph/A-Look-At-The-Future-How-Will-The-Double-Loft-Bed-Adults-Industry-Look-Like-In-10-Years-06-28
トラックバック:3 Wheel Jogger
トラックバック:Cot Bed Natural Wood
トラックバック:beds With a slide
トラックバック:bbs.Sanesoft.cn
トラックバック:fold away Treadmill uk
トラックバック:https://images.google.td
トラックバック:Comfy Couches For Sale
トラックバック:Fabric 2 Seater Sofas
トラックバック:pushchair
トラックバック:에볼루션카지노
トラックバック:Island Hob
トラックバック:wikimapia.org officially announced
トラックバック:Slide Bunk Bed For Kids
トラックバック:gas safety certificate for landlords
トラックバック:Rn.Rnsh.Net
トラックバック:Going in qooh.me
トラックバック:casino Crypto
トラックバック:in built microwave oven
トラックバック:https://morphomics.science/wiki/what_is_cs2_case_battles_and_why_is_everyone_talking_about_it
トラックバック:2 Seater fabric Sofa
トラックバック:Home gym
トラックバック:maps.google.nr
トラックバック:Convection oven
トラックバック:Interwood Bunk Bed
トラックバック:Modern Kitchen
トラックバック:Images.Melonland.Net
トラックバック:https://fatherbox11.werite.net
トラックバック:https://munk-torp.federatedjournals.com/why-do-so-many-people-want-to-know-about-best-car-seats-for-newborns/
トラックバック:In built oven
トラックバック:double Bed bunk beds adults
トラックバック:https://botdb.win/wiki/Take_A_Look_At_One_Of_The_Gas_Safety_Check_In_Buckingham_Industrys_Steve_Jobs_Of_The_Gas_Safety_Check_In_Buckingham_Industry
トラックバック:www.myworlds.ru
トラックバック:corner couches For sale
トラックバック:Top rated infant car Seats
トラックバック:Modular Couches For Sale
トラックバック:open a car Door
トラックバック:camisetas futbol
トラックバック:Double stroller sale
トラックバック:https://Ring-mahmoud.thoughtlanes.net/
トラックバック:L Shaped Low Bunk Beds
トラックバック:mattress Topper Single
トラックバック:49.51.81.43
トラックバック:similar internet page
トラックバック:Built in microwave oven black
トラックバック:에볼루션 게이밍
トラックバック:top prams
トラックバック:wood Bunk Beds
トラックバック:range style cookers dual fuel
トラックバック:kitchen
トラックバック:over at this website
トラックバック:Www.Bitspower.Com
トラックバック:kids Beds
トラックバック:3 wheel infant stroller
トラックバック:2 in 1 Stroller With car seat
トラックバック:Professional cooking
トラックバック:Socialfactories.Com
トラックバック:Worldsocialindex.com
トラックバック:btpars.com
トラックバック:Best Bunk bed with Desk
トラックバック:http://emseyi.com/
トラックバック:single To double buggy
トラックバック:kids Beds bunk beds
トラックバック:3 Wheel Reversible Stroller
トラックバック:Jogging Strollers
トラックバック:benton-klemmensen.technetbloggers.de writes
トラックバック:atoms-demo.qualica.co.jp
トラックバック:replacement Car Key fob
トラックバック:All Terrain Stroller
トラックバック:Https://click4r.Com/posts/g/18570493/20-fun-facts-about-best-bunk-bed
トラックバック:state-of-the-art appliances
トラックバック:Prams
トラックバック:research by the staff of Thoughtlanes
トラックバック:www.kaseisyoji.com write an article
トラックバック:Pipeeel99.bravejournal.Net
トラックバック:egg stroller 2 in 1
トラックバック:double Size loft Bed
トラックバック:faux leather couch
トラックバック:double Pushchair
トラックバック:Fitted Oven
トラックバック:biggest crypto casino
トラックバック:hob and oven
トラックバック:http://www.auto-software.org
トラックバック:extractor Fan for island hob
トラックバック:Bunk Beds stores
トラックバック:e-Pages.Ua
トラックバック:landlord gas certificate milton keynes
トラックバック:Prams for Newborns
トラックバック:Spare Car Keys Cut
トラックバック:https://wikimapia.org
トラックバック:handberg-donaldson.blogbright.net
トラックバック:https://evolution-slot20947.wikiinside.com/1459900/5_reasons_to_be_an_online_evolution_baccarat_site_business_and_5_reasons_to_not
トラックバック:Parent-Facing Prams
トラックバック:https://intern.ee.aeust.edu.tw/home.php?mod=space&uid=896268
トラックバック:island cookers
トラックバック:extrabookmarking.com official website
トラックバック:best 3 wheel Pushchair
トラックバック:Folding Pram
トラックバック:Spare car key cost uk
トラックバック:Https://mensvault.men/story.php?title=15-gifts-for-the-couch-in-uk-lover-in-your-life
トラックバック:goldman-putnam-2.technetbloggers.de
トラックバック:Three Wheel Buggies
トラックバック:http://Dtyzwmw.com/comment/html/?10671.html
トラックバック:Вулкан Платинум игры с живыми дилерами
トラックバック:https://jobtracko.com/employer/14393/pushchairs-and-prams
トラックバック:Stroller Single
トラックバック:sofascouchesuk97531.look4blog.com
トラックバック:best site
トラックバック:fabric corner sofa sale
トラックバック:Leather Power Recliner
トラックバック:https://ucgp.jujuy.Edu.ar/
トラックバック:bed Settee for Sale
トラックバック:Contemporary leather recliner Sofa
トラックバック:gas Safety engineers Newport Pagnell
トラックバック:Oven Microwave Built In Combo
トラックバック:4 seater leather lounge
トラックバック:Window Lock Repair Near Me
トラックバック:island cooker hood with ducting
トラックバック:emergency local locksmith
トラックバック:Replacement Upvc window Locks
トラックバック:upvc window lock Repair Cost
トラックバック:https://telegra.ph/Window-Hinge-Replacement-The-Good-The-Bad-And-The-Ugly-09-20
トラックバック:best car locksmiths in watford
トラックバック:click here to visit pediascape.science for free
トラックバック:upvc window Replacement Hinges
トラックバック:misty window Repairs near me
トラックバック:best northamptonshire auto locksmith
トラックバック:Https://informatic.wiki
トラックバック:무료에볼루션
トラックバック:locksmith Near me
トラックバック:car key lost No spare
トラックバック:Car Key Replacements
トラックバック:where to get Pallets
トラックバック:Purchase wood pallets
トラックバック:Cost of a replacement Car key
トラックバック:car Key Cutting service
トラックバック:question-ksa.com
トラックバック:auto locksmith near High wycombe
トラックバック:https://beretbeggar63.werite.net/
トラックバック:types of Window handle
トラックバック:Mobile Car Key Repair Near Me
トラックバック:Pallet Prices
トラックバック:new car key Replacement
トラックバック:http://dingshangkongjian.com/__media__/js/netsoltrademark.php?d=icfoodseasoning.combbsboard.phpbo_tablefreewr_id217195
トラックバック:Wooden palette
トラックバック:new wood pallet for Sale
トラックバック:Https://Theflatearth.Win/Wiki/Post:14_Questions_You_Might_Be_Uneasy_To_Ask_Best_Car_Locksmith_Buckinghamshire
トラックバック:Replacing a Upvc window handle
トラックバック:broken window seal Repair cost
トラックバック:에볼루션 무료체험
トラックバック:https://pehrson-nyborg.thoughtlanes.net/why-sash-Windows-is-fast-becoming-the-hottest-trend-of-2024/
トラックバック:Webb-staal-3.federatedjournals.com
トラックバック:pallet Distributors
トラックバック:Sell Pallets Near Me
トラックバック:cheap car key replacement near me
トラックバック:my car key fob was stolen
トラックバック:Emergency Car Locksmith
トラックバック:Best Car Locksmith Northamptonshire
トラックバック:auto locksmith near buckinghamshire
トラックバック:new post from dokuwiki.stream
トラックバック:https://algowiki.win/wiki/Post:10_Startups_Thatll_Change_The_Evolution_Free_Experience_Industry_For_The_Better
トラックバック:Purchase Used Pallets
トラックバック:Key Fob Repairs
トラックバック:best auto locksmiths near high wycombe
トラックバック:window and door doctor near me
トラックバック:repair Window lock
トラックバック:Misted Double Glazing Repair Near Me
トラックバック:upvc Windows hinges
トラックバック:used pallets for sale
トラックバック:Key Lost
トラックバック:check out this one from Elearnportal
トラックバック:https://frederiksen-north-2.blogbright.net/10-real-reasons-people-dislike-new-wood-pallet-for-Sale-new-Wood-pallet-For-sale/
トラックバック:research by the staff of Google
トラックバック:Upvc Replacement Window Handles
トラックバック:window Handle repair near me
トラックバック:fridge Door seal repair
トラックバック:Window sash replacement
トラックバック:ignition key Won’t come out
トラックバック:https://flagcolumn9.bravejournal.Net/what-is-large-pallets-and-why-is-everyone-talking-About-it
トラックバック:Car Locksmiths Near Northamptonshire
トラックバック:Best Auto Locksmith Near Bedfordshire
トラックバック:Auto locksmith In buckinghamshire
トラックバック:Https://sovren.media/U/closetspruce3/
トラックバック:upvc patio door Repairs
トラックバック:double glazed windows seal replacement
トラックバック:Cost of replacing misted double glazing units
トラックバック:electric Oven
トラックバック:Replace lost key
トラックバック:Emergency locksmith
トラックバック:Car Locksmiths in watford
トラックバック:Locksmiths car
トラックバック:Near me Locksmith
トラックバック:betflix2k
トラックバック:Car Key Cover replacement
トラックバック:aluminium window seal replacement
トラックバック:spare key maker near me
トラックバック:Key Fob programming
トラックバック:car mobile locksmith
トラックバック:auto locksmiths in bedfordshire
トラックバック:tilt and turn Windows Aluminium
トラックバック:locksmith near me Open now
トラックバック:Keyless Car Stolen
トラックバック:valetinowiki.racing blog post
トラックバック:Talkofsuncity website
トラックバック:buying an african grey parrot
トラックバック:best Car locksmiths Bedford
トラックバック:djkok.co.kr
トラックバック:www.cruzenews.com
トラックバック:adhd stimulant Medication
トラックバック:leather grey recliner
トラックバック:https://ottosen-magnussen.hubstack.net/
トラックバック:Rentry website
トラックバック:Willadsen-goodman.technetbloggers.de
トラックバック:lexus key replacement uk
トラックバック:big American fridge freezer
トラックバック:Https://Weheardit.Stream/Story.Php?Title=15-Window-Companies-Leeds-Benefits-Everyone-Needs-To-Be-Able-To-9
トラックバック:Aycock-Batchelor-2.Technetbloggers.De
トラックバック:heavy duty Wheelchair
トラックバック:Macaw-for-sale15169.nytechwiki.com
トラックバック:Where Can I Buy A Macaw
トラックバック:http://daoqiao.net/copydog/home.php?mod=space&uid=3154357
トラックバック:Https://Jochumsen-Guldager-3.Technetbloggers.De/10-Websites-To-Help-You-Become-An-Expert-In-Pragmatic-Slot-1740043230
トラックバック:Echte Banknoten Bestellen
トラックバック:http://www.tianxiaputao.com/bbs/home.php?mod=space&uid=1132651
トラックバック:Windows & Doors near Me
トラックバック:Mens Sex Toy
トラックバック:all-terrain stroller Lightweight
トラックバック:Https://Mozillabd.Science/Wiki/Delaneypope1381
トラックバック:window glass replacement double pane
トラックバック:Repairing bifold Doors
トラックバック:http://www.codyenglish.com/guest_book/Go.php?url=https://bezauberndeyorkiewelpen.de/
トラックバック:https://www.bioguiden.se/redirect.aspx?url=https://posteezy.com/15-and-coming-psychiatrist-near-me-depression-bloggers-you-need-follow
トラックバック:window glass Replacements near me
トラックバック:Icorporate.Ru
トラックバック:Cat deposit bonuses
トラックバック:learn more about Gastore
トラックバック:A80-FüHrerschein Kaufen
トラックバック:Adhd Symptoms treatment
トラックバック:online Adhd test
トラックバック:upvc door panel with dog flap
トラックバック:exigences du Permis de conduire françAis
トラックバック:Citroen ds3 Replacement Key Cost
トラックバック:types Of adhd medication
トラックバック:can you get frost free chest freezers
トラックバック:Best 3 wheel travel system
トラックバック:Container Building
トラックバック:https://Dawson-lykke-5.blogbright.net/how-to-install-a-cat-flap-1728281758/
トラックバック:how do you get diagnosed with add
トラックバック:Men Lovense
トラックバック:119.45.49.212
トラックバック:cardio machine
トラックバック:Express-Deutsche-Kartes95957.Wikimillions.Com
トラックバック:https://historydb.date/wiki/20_Questions_You_Need_To_To_Ask_About_Buy_A_Polish_Driving_License_Before_Buying_It
トラックバック:Free Psychiatric Assessment
トラックバック:https://dirtfall5.bravejournal.Net/5-reasons-to-be-an-online-adhd-in-adult-women-symptoms-buyer-and-5-reasons-not
トラックバック:Dealing with Adhd Without medication
トラックバック:deutscher schäferhund kaufen
トラックバック:Double Glazing aylesbury
トラックバック:best car locksmith milton keynes
トラックバック:to mentalhealthassessment34147.wikikali.com
トラックバック:프라그마틱 슬롯 무료
トラックバック:Green scooters
トラックバック:http://www.Kuniunet.com/home.php?mod=space&Uid=1700678
トラックバック:gotogel07034.blogunok.com
トラックバック:Sciencewiki official website
トラックバック:Https://algowiki.win/
トラックバック:how to Repair car Key Fob
トラックバック:where is the best Place to buy bunk Beds
トラックバック:mazda 3 replacement key fob
トラックバック:2 seater couch For sale
トラックバック:Kaufen Oder Adoptieren
トラックバック:patio sliding doors repair
トラックバック:Adult Mens Toys
トラックバック:http://bbs.0817ch.com
トラックバック:b197 führerschein betrugsfälle
トラックバック:https://www.belmio.com/en/language/nl/aHR0cHM6Ly94bi0tb2kyYnY0cWc3ZmJhLmNvbS8
トラックバック:african Grey parrot adoption
トラックバック:Psychiatry Private
トラックバック:nitka.by
トラックバック:How much Is a realistic sex doll
トラックバック:Online psychiatrist near me
トラックバック:Lineyka.Org
トラックバック:private psychiatrist cardiff Cost
トラックバック:upvc window and door repairs near me
トラックバック:https://morphomics.science/wiki/who_is_sash_window_refurbishment_and_why_you_Should_take_a_look
トラックバック:rollators for tall Person
トラックバック:Bezaubernde-Yorkie-Welpen83374.Empirewiki.Com
トラックバック:hardin-hatcher.thoughtlanes.Net
トラックバック:https://www.google.fm/url?q=https://steele-bradley.mdwrite.net/15-reasons-why-you-shouldnt-ignore-folding-treadmills
トラックバック:mercedes benz key Replacement
トラックバック:De köRkort
トラックバック:Www.Ddhszz.Com
トラックバック:3 Wheel Baby buggy
トラックバック:replacement sealed units
トラックバック:egzamin praktyczny A1
トラックバック:https://blogfreely.net/
トラックバック:reviews over at Saehanfood
トラックバック:Electric Single Ovens Built Under
トラックバック:heavy-duty tool kit
トラックバック:https://broe-alston.thoughtlanes.net/10-amazing-graphics-about-driving-license-category-a1/
トラックバック:Mercades Key
トラックバック:simply click the up coming website page
トラックバック:how to Get diagnosed with adhd In adults
トラックバック:Window glass Repair service
トラックバック:Online Adhd Test Adults
トラックバック:http://Www.028bbs.com/space-uid-514948.html
トラックバック:visit matthiesen-lamont-2.technetbloggers.de now >>>
トラックバック:double glazing Window locks replace
トラックバック:führerschein ohne schufa
トラックバック:Glass replacement near me
トラックバック:bedside travel Crib
トラックバック:Window Repair Specialists
トラックバック:deutscher schäferhund Welpen kaufen
トラックバック:Scooter green Power
トラックバック:Hyper Anxiety Disorder
トラックバック:Acheter Permis De Conduire En Ligne
トラックバック:auto locksmiths in high wycombe
トラックバック:right here
トラックバック:Http://Taikwu.Com.Tw/Dsz/Home.Php?Mod=Space&Uid=1100856
トラックバック:Schofield-Fenger.Mdwrite.Net
トラックバック:Custom wheelchair
トラックバック:Bifold Doors repair
トラックバック:https://geertsen-aagesen-3.blogbright.net
トラックバック:forum-en.gw2Archive.eu
トラックバック:Metooo writes
トラックバック:Https://Www.Clubseatateca.Com
トラックバック:g2826578.corpfinwiki.com
トラックバック:lovense Masturbation
トラックバック:https://K12.instructure.com/eportfolios/895559/home/10-Mobile-apps-that-Are-the-best-for-case-battle
トラックバック:double glazing doctor
トラックバック:Frost Free Upright freezer
トラックバック:Https://Basinspy0.Bravejournal.Net/
トラックバック:bike home Exercise
トラックバック:Indoor mobility scooters
トラックバック:fun Bunk beds
トラックバック:Electric folding treadmill with incline
トラックバック:power tool kit set
トラックバック:best car locksmiths near high wycombe
トラックバック:www.Maoflag.cc
トラックバック:read this blog post from Articlement
トラックバック:bmk39.ru
トラックバック:retourneren.nl blog entry
トラックバック:https://fkwiki.win/wiki/post:15_trends_to_watch_in_the_new_year_keene_buy_french_bulldog
トラックバック:How To replace rubber seal on upvc door
トラックバック:Tilt And Turn Window Hinge Covers
トラックバック:vintage couch For sale
トラックバック:Togel Wap
トラックバック:mccormick-oakley-4.mdwrite.Net
トラックバック:realsexdolls
トラックバック:Cassidy-Lindberg.Hubstack.Net
トラックバック:fitting a cat flap in a upvc door
トラックバック:10situstogelterpercaya34508.blogdun.com
トラックバック:situs-togel-terbesar38082.blogunteer.com
トラックバック:Acheter Permis De Conduire Authentique
トラックバック:Double Glazing Window
トラックバック:mental health assessments near me
トラックバック:https://muopt.ru/bitrix/redirect.php?goto=https://gotogelreal.lol
トラックバック:bipolar psychiatrist Near Me
トラックバック:google.co.uz
トラックバック:Diagnosing Adhd in adults uk
トラックバック:Https://Te.Legra.Ph/7-Simple-Secrets-To-Totally-Intoxicating-Your-Audi-Key-Replacement-Cost-08-28
トラックバック:https://Ucgp.jujuy.edu.ar/Profile/fleshfang9/
トラックバック:Http://Planforexams.Com/Q2A/User/Brickwhite3
トラックバック:에볼루션 코리아
トラックバック:ask.mgbg7b3bdcu.net
トラックバック:Кэт казино онлайн официальный сайт
トラックバック:by Adminplanet
トラックバック:Wayranks explains
トラックバック:reviews over at yogicentral.science
トラックバック:testing Adhd in adults
トラックバック:aboutdirectorofnursingjobs.com
トラックバック:Wood Pallet Provider
トラックバック:https://Maki-dez.ru:443/redirect?url=https://ukdrivinglicense.co.uk/
トラックバック:https://git.hb3344.com
トラックバック:Hulkshare.Com
トラックバック:automatic fold up scooter
トラックバック:https://kornum-secher-4.technetbloggers.de/the-reason-you-shouldnt-think-about-making-improvements-to-your-link-login-gotogel-1738320559/
トラックバック:exercise bike in home
トラックバック:window lock repairs Near me
トラックバック:https://git.fuwafuwa.moe/radarbeer69
トラックバック:can my general Practitioner Prescribe adhd medication
トラックバック:high wycombe double glazing
トラックバック:reinrassiger deutscher schäFerhund kaufen
トラックバック:best medication for Adhd and anxiety
トラックバック:nexbook.co.kr
トラックバック:Http://Ezproxy.Cityu.Edu.Hk/Login?Url=Https://Jones-Nielsen-3.Technetbloggers.De/Ten-Things-You-Learned-In-Kindergarden-Theyll-Help-You-Understand-Adhd-Medication-Titration
トラックバック:www.buzzbii.com
トラックバック:Small Sectional with chaise
トラックバック:click this link now
トラックバック:psychiatrists for adhd near me
トラックバック:http://Eric1819.com
トラックバック:Legal FüHrerschein Kaufen
トラックバック:adults Toys
トラックバック:Www.Optionshare.Tw
トラックバック:Antique chesterfield Sofa
トラックバック:natural Ways to treat adhd
トラックバック:Single Mid Sleeper Cabin Bed
トラックバック:click here to visit martinsen-cooley.blogbright.net for free
トラックバック:read this post from Thoughtlanes
トラックバック:hl0803.com
トラックバック:exercise Bike Benefits
トラックバック:www.jinritongbai.com
トラックバック:Realistic Sex Doll Silicone
トラックバック:www.Singuratate.ro
トラックバック:https://scientific-programs.science/wiki/Whats_The_Point_Of_Nobody_Caring_About_Best_Automatic_Vacuum_Cleaner
トラックバック:auto Locksmith in northamptonshire
トラックバック:via Benny
トラックバック:vacuum mop Cleaner robot
トラックバック:Large American Style Fridge Freezers
トラックバック:Replacement bag for Rollator Walker
トラックバック:http://eric1819.com/home.php?mod=space&uid=1213752
トラックバック:Upvc Door Panels Replacements
トラックバック:fix Window hinge
トラックバック:visit www.metooo.io
トラックバック:Mystery Box Online Opening
トラックバック:source for this article
トラックバック:Http://Visagatedev.Sherpalize.Com
トラックバック:Interactive adult toys
トラックバック:Http://Www.Kaseisyoji.Com/Home.Php?Mod=Space&Uid=2127182
トラックバック:https://molespain92.Bravejournal.net
トラックバック:https://hikvisiondb.webcam/wiki/Ashleytemple9018
トラックバック:recumbent exercise bike
トラックバック:Lightweight Mobility Scooters For Sale
トラックバック:Www.Ask-People.Net
トラックバック:Ghost 2 Immobiliser Near Me
トラックバック:https://www.google.Pn/url?Q=https://offersen-benton-3.hubstack.net/crypto-casino-usa-explained-in-Less-than-140-Characters
トラックバック:private consultant psychiatrist
トラックバック:Crypto live Casino
トラックバック:Landlord Gas safety certificate Buckingham
トラックバック:aplikasi togel Online
トラックバック:www.google.co.Ck
トラックバック:how to program land rover lr2 key fob
トラックバック:Independent psychiatry
トラックバック:ivanovo-trikotag.ru
トラックバック:psychiatrists near me Adhd
トラックバック:landlord Gas safety Certificate uk
トラックバック:recliner l shape sofa
トラックバック:check out this blog post via mobile.myprice74.ru
トラックバック:Symptoms Of Adhd In Adults Test
トラックバック:All-Volgograd.Ru
トラックバック:köRkortonline
トラックバック:cartage3.bravejournal.net
トラックバック:Deutschen FüHrerschein Kaufen
トラックバック:Supplier-uat.mercedes-benz.com
トラックバック:Situsgotogel22182.Wiki-Racconti.Com
トラックバック:Bmw Keyless Entry
トラックバック:bedside cot sale
トラックバック:patio repair near me
トラックバック:veleco Scooters
トラックバック:loft Bed with drawer stairs
トラックバック:Window panes replacement
トラックバック:Windows cambridge
トラックバック:Bauexpertenforum.de
トラックバック:official www.pdc.edu blog
トラックバック:guestbook.Sahoyan.com
トラックバック:Power Tools Sets
トラックバック:daojianchina.com
トラックバック:http://Cdbaixin.cn/
トラックバック:lock smith For cars
トラックバック:transponder Key Replacement
トラックバック:car keys Repairs
トラックバック:http://Www.daoban.org/
トラックバック:Https://Api.Refyn.Org
トラックバック:hyacinth Macaw price
トラックバック:gitea.cloud.enkisoft.ru
トラックバック:u p v C window repairs
トラックバック:Grey Sectional Sofa
トラックバック:adhd medication Uk
トラックバック:https://pediascape.science/wiki/10_Facts_About_Integrated_Ovens_That_Insists_On_Putting_You_In_An_Optimistic_Mood
トラックバック:https://www.buzzbii.com
トラックバック:tunnel Logistics
トラックバック:bmw replacement key fob
トラックバック:Bedside Cots For Newborns
トラックバック:wooden windows Maidstone
トラックバック:http://pc.d-Linxs.com
トラックバック:Aluminium Windows & Doors
トラックバック:Https://sparedirectory.com/
トラックバック:47.102.102.152
トラックバック:bariatric wheelchair For Sale
トラックバック:large Pallets
トラックバック:patio door lock repairs near me
トラックバック:car locksmiths milton keynes
トラックバック:sleeper couch
トラックバック:flying Anxiety symptoms
トラックバック:psychiatric Testing near Me
トラックバック:Adhd Depression symptoms
トラックバック:my latest blog post
トラックバック:heart rate
トラックバック:Foldaway Electric wheelchair
トラックバック:Code.Dsconce.Space
トラックバック:tailor1.ru
トラックバック:lolipop-777masa777.Ssl-lolipop.jp
トラックバック:Gas Safety Engineer Newport Pagnell
トラックバック:http://www.kratc.com/bbs/home.php?mod=space&uid=86625
トラックバック:https://58apartamentov.ru/redirect?url=https://tonymacdrivingschool.com/
トラックバック:repairing upvc doors
トラックバック:Adhd Diagnosis Near Me
トラックバック:refrigerators Brands
トラックバック:mental health assessments For Adults
トラックバック:vibrating adult Toys
トラックバック:Https://Bager-Stephansen.Hubstack.Net
トラックバック:psychiatrist Near me
トラックバック:Hur Skaffar Man Nytt KöRkort
トラックバック:best auto Locksmith bedfordshire
トラックバック:Upvc Door Handles Replacement
トラックバック:Upvc doors with windows
トラックバック:buy German Shepherd dog austria
トラックバック:Cheapest Power Tools Online
トラックバック:Skoda Remote Key
トラックバック:Private Adhd Assessment Worcestershire
トラックバック:best Fridge Freezer
トラックバック:upvc sash Windows
トラックバック:small kitchen solutions
トラックバック:Leather Lounge suite
トラックバック:Cat Flap Installation Near Me
トラックバック:Macaw Online Store
トラックバック:try sovren.media
トラックバック:medication for Autism and adhd
トラックバック:rasmussen-colon-2.blogbright.net
トラックバック:ghost Immobiliser car
トラックバック:adult adhd test Online
トラックバック:replacement Mercedes keys
トラックバック:Most realistic Sex dolls
トラックバック:single bunk with desk
トラックバック:sibirles.Ru
トラックバック:Http://Giroshop24.Ru
トラックバック:Https://Setiathome.Berkeley.Edu/Show_User.Php?Userid=11568573
トラックバック:open car door without key
トラックバック:experience
トラックバック:Ditlevsen-Austin-2.Technetbloggers.De
トラックバック:mental health Diagnostic assessment
トラックバック:realistic young Sex doll
トラックバック:view publisher site
トラックバック:standard wood pallet
トラックバック:letterbox for upvc Doors
トラックバック:Secondary Double Glazing Milton Keynes
トラックバック:Spix’s macaw Lifespan
トラックバック:Https://Cameradb.Review/Wiki/Are_You_Responsible_For_The_Buy_Driving_License_Online_Budget_12_Ways_To_Spend_Your_Money
トラックバック:Https://Www.Gensp.Ru/
トラックバック:Thoughtlanes official
トラックバック:4 wheel rollator With seat
トラックバック:93.177.65.216
トラックバック:auto locksmiths near bedford
トラックバック:Cost of replacement car keys
トラックバック:best fridge freezers uk
トラックバック:metal frame triple Bunk bed
トラックバック:Commercial Exercise Bike
トラックバック:http://Emseyi.Com
トラックバック:lancaster-hagen.blogbright.net
トラックバック:tribuna.com.Ru
トラックバック:Pallet Auctions
トラックバック:Window upvc door
トラックバック:adult Testing for Adhd
トラックバック:macau pet Shop
トラックバック:rabbit toys Adult
トラックバック:New Panel For Upvc Door
トラックバック:git.lain.church
トラックバック:BestäLla Nytt KöRkort Online
トラックバック:comfy leather couch
トラックバック:https://adcock-matzen.thoughtlanes.net/a-journey-back-in-time-what-people-said-about-collapsible-electric-wheelchairs-20-years-ago
トラックバック:upvc Windows bromley
トラックバック:green power mobility scooters uk
トラックバック:Adult Toy For Men
トラックバック:best car Locksmiths near bedford
トラックバック:https://www.northwestu.edu/?url=https://zenwriting.net/italyself1/the-most-hilarious-complaints-weve-heard-about-adhd-and-anxiety-medication
トラックバック:valetinowiki.racing published an article
トラックバック:guestbook.buytiresonline.co
トラックバック:Euro fälschungen online bestellen
トラックバック:Private adhd assessment gloucestershire
トラックバック:Private psychiatrist cambridge
トラックバック:car-key-reprogramming66557.blogrelation.com blog entry
トラックバック:analbutt
トラックバック:private psychiatrist adhd assessment
トラックバック:private adhd titration
トラックバック:Glass Repairing
トラックバック:this page
トラックバック:Cot For Bedside
トラックバック:bmw replacement key
トラックバック:2 in 1 pram and Car seat
トラックバック:mental state assessment
トラックバック:loft bed With stairs
トラックバック:S.Tamahime.Com
トラックバック:Fun toddler beds with slides
トラックバック:board-de.farmerama.com
トラックバック:Permis de conduire en france
トラックバック:compact treadmill With incline
トラックバック:treatment for adhd in Adults Uk
トラックバック:Electric Single Oven With Grill
トラックバック:brown recliner sofa leather
トラックバック:45cm built In microwave
トラックバック:wooden cot and bed
トラックバック:cost for Replacement car key
トラックバック:Easy fold Electric Wheelchair
トラックバック:clarity Windows manchester
トラックバック:official zenwriting.net blog
トラックバック:mm.gd
トラックバック:www.google.ps
トラックバック:deutscher Schäferhund pflege
トラックバック:gas Safety checks Milton keynes
トラックバック:schäferhund welpen österreich kaufen
トラックバック:visit Werite now >>>
トラックバック:Fix double glazed windows
トラックバック:deerchange16.bravejournal.net
トラックバック:mercedes Car Key
トラックバック:sex Machines uk
トラックバック:Policemanx8.Werite.Net
トラックバック:Dokupię prawo Jazdy
トラックバック:bandar-togel-terpercaya43804.bloggactivo.com
トラックバック:repair a door
トラックバック:Http://mem168new.com/home.php?mod=space&uid=2050268
トラックバック:Visit nerdgaming.science
トラックバック:fronttest4.bravejournal.net writes
トラックバック:Sex Toy Panties
トラックバック:tarifkchr.net
トラックバック:white And wooden cot Bed
トラックバック:Mcintosh-hill.blogbright.net
トラックバック:bunk Beds single Bed
トラックバック:macaw Bird diet
トラックバック:Staino.Ru
トラックバック:Window & Door
トラックバック:Visit www.footballzaa.com
トラックバック:b197 Führerschein ohne wartezeit
トラックバック:Hartley-Waller-2.Technetbloggers.De
トラックバック:https://kirkeby-pilegaard-2.federatedjournals.com/
トラックバック:Handle For Double Glazed Window
トラックバック:Self Propelled All Terrain Wheelchair
トラックバック:how do you unlock A car without a key
トラックバック:Https://Xintangtc.Com/
トラックバック:Https://Wolfbowl8.Werite.Net
トラックバック:information from Postheaven
トラックバック:Senior Mobility scooter for sale
トラックバック:Adhd without medication
トラックバック:tonic greens reddit
トラックバック:ghost 2 Immobiliser
トラックバック:Lightweight Self Propelled Folding Wheelchair
トラックバック:Folding treadmills For home
トラックバック:https://k12.instructure.com/eportfolios/899131/home/20-tools-that-will-make-you-More-efficient-at-robot-vacuum-and-mop
トラックバック:freezers77170.wikiannouncement.Com
トラックバック:https://fewpal.com/Post/1752083_https-willoughby-bernstein-thoughtlanes-net-a-look-at-the-myths-And-facts-behind.Html
トラックバック:general psychiatric assessment
トラックバック:click the following website
トラックバック:ray-terrell.thoughtlanes.net
トラックバック:Https://Www.Google.Co.Cr
トラックバック:agen Togel Resmi
トラックバック:Adhd Test Ireland
トラックバック:wm.makeding.com
トラックバック:hyundai tucson key replacement cost
トラックバック:http://psicolinguistica.letras.ufmg.br/Wiki/index.php/20-top-tweets-of-all-time-concerning-evolution-baccarat-site-m
トラックバック:Mystery Boxes
トラックバック:Voyage-orsk.ru
トラックバック:visit Google`s official website
トラックバック:zephyrrub80.bravejournal.Net
トラックバック:Double Glazing windows replacement
トラックバック:Upvc door Frame repair
トラックバック:Www.graphicscience.jp
トラックバック:macaw representative species
トラックバック:hobs Uk
トラックバック:best macaw breed
トラックバック:glazed Partitions eastleigh
トラックバック:www.auto-software.org published a blog post
トラックバック:non prescription adhd treatment
トラックバック:anxiety disorder cure Naturally
トラックバック:Pram And Pushchair 2 In 1
トラックバック:first line treatment For adhd in Adults
トラックバック:next
トラックバック:iblog.iup.edu explains
トラックバック:signedsociety.com
トラックバック:Online Psychiatric assessment
トラックバック:how to get psychiatric assessment
トラックバック:three Wheel Electric mobility scooters
トラックバック:Double Ended Sex Toys
トラックバック:Foggy window repair
トラックバック:Huffman-Stevens-2.Technetbloggers.De
トラックバック:Automatic Folding Electric Scooter
トラックバック:gitlab.innive.com website
トラックバック:artron.ru
トラックバック:www.oodji.com
トラックバック:space key Lamborghini
トラックバック:www.Thehispanicamerican.com
トラックバック:gas safety certificate price
トラックバック:20 ft tunnel container
トラックバック:heylink99728.blogchaat.Com
トラックバック:repair double Glazed windows
トラックバック:Posteezy said in a blog post
トラックバック:https://www.Metooo.it/
トラックバック:healthcare equipment
トラックバック:Www.Civisbook.Ru
トラックバック:http://arcdog.com/
トラックバック:gamma the memory wave
トラックバック:Fold up electric wheelchair
トラックバック:car locksmith Near northamptonshire
トラックバック:casino game Crypto
トラックバック:Glass Doctor Near Me
トラックバック:Moesgaard-Drew.mdwrite.net
トラックバック:Best Power Tool Set Uk
トラックバック:https://licence-france-xpress32345.ktwiki.com
トラックバック:에볼루션 바카라 무료체험
トラックバック:Https://Wikimapia.Org/External_Link?Url=Http://Www.Stes.Tyc.Edu.Tw/Xoops/Modules/Profile/Userinfo.Php?Uid=2900502
トラックバック:https://Www.Yourtahoeplace.com/
トラックバック:honda jazz Replacement Key cost uk
トラックバック:Programmers
トラックバック:Sciencewiki explains
トラックバック:Electric drill set
トラックバック:http://79bo2.com/Space-uid-337917.html
トラックバック:workshop
トラックバック:jaguar smart Key
トラックバック:에볼루션카지노사이트
トラックバック:mens adult sex Toys
トラックバック:Http://Delphi.Larsbo.Org/
トラックバック:http://www.meseoulclinic.co.kr
トラックバック:situstoto75447.wikiitemization.com
トラックバック:my website
トラックバック:Leather corner couch
トラックバック:git.Hulianmofang.cn
トラックバック:Treadmill home Gym
トラックバック:https://wifidb.science/wiki/10_Misconceptions_Your_Boss_Shares_Regarding_Situs_Gotogel
トラックバック:what is A Mental health assessment
トラックバック:Https://telegra.ph/what-kia-ceed-replacement-key-experts-want-You-to-learn-06-03
トラックバック:https://ondashboard.win
トラックバック:price
トラックバック:Viewsdirectory.Com
トラックバック:Item Upgrader Mod
トラックバック:opensourcebridge.science`s blog
トラックバック:https://pennswoodsclassifieds.com
トラックバック:https://scientific-programs.science/wiki/20_Resources_That_Will_Make_You_Better_At_Tunnel_Containers
トラックバック:www.Gardenstew.com
トラックバック:myokan.okan.jp
トラックバック:BestäLla KöRkort Online Billigt
トラックバック:best travel Stroller
トラックバック:Private psychiatrists London
トラックバック:Https://gallegos-ratliff-2.Hubstack.net
トラックバック:Replacement Key For Land Rover Discovery Sport
トラックバック:from the moparwiki.win blog
トラックバック:https://bbs.pku.edu.cn/v2/jump-to.php?url=https://marvelvsdc.faith/wiki/the_little_known_benefits_of_electronic_car_key_repair_near_me
トラックバック:Pavement mobility scooters with suspension
トラックバック:official Google blog
トラックバック:Mozillabd official
トラックバック:treatments for adhd
トラックバック:Masterbator for men
トラックバック:aluminium Door handle
トラックバック:g28carkeys01931.Therainblog.Com
トラックバック:Pragmatickrcom24455.Vigilwiki.Com
トラックバック:Adhd symptoms and Treatment in adults
トラックバック:adult toys sex
トラックバック:https://www.metooo.it/u/67530f20d267403879f9b6eb
トラックバック:Best Car Locksmith Near Bedfordshire
トラックバック:www.followmedoitbbs.Com
トラックバック:dual Fuel range Cookers
トラックバック:to Cameradb
トラックバック:Upvc Window Lock Repairs Near Me
トラックバック:éChange Permis De Conduire France
トラックバック:프라그마틱 정품 확인법
トラックバック:Wheelchair Ramps For Steps
トラックバック:tironorm.ru
トラックバック:new
トラックバック:Most Realistic Sex Doll In The World
トラックバック:cabin Bed High sleeper
トラックバック:https://marvelvsdc.faith/wiki/The_History_Of_Evolution_Site
トラックバック:Light Weight foldable Wheelchair
トラックバック:Lightweight wheelchair
トラックバック:B197 FüHrerschein Erfahrung
トラックバック:upvc window repair near me
トラックバック:peugeot 208 Spare key
トラックバック:best car locksmiths buckinghamshire
トラックバック:Black Friday Sofa Sale
トラックバック:https://Mullen-moreno.blogbright.net/
トラックバック:slim retro fridge freezer
トラックバック:Annunciogratis.net
トラックバック:dsm v adhd symptoms
トラックバック:adhd symptoms in women
トラックバック:car remote programming Locksmith Near Me
トラックバック:Water Dispenser Fridges
トラックバック:handles For Patio Doors
トラックバック:Metal Double Bunk Beds For Adults
トラックバック:Gas safety certificate homeowner
トラックバック:What Is Adhd Symptoms In Adults
トラックバック:best solid wood Bunk Beds
トラックバック:wheelchair Bariatric transit 24 Inch
トラックバック:window handles for upvc
トラックバック:Longisland`s statement on its official blog
トラックバック:reynolds-koch-2.technetbloggers.de
トラックバック:right here on chavez-ryberg.mdwrite.net
トラックバック:stairways.wiki
トラックバック:legit crypto Casino
トラックバック:https://www.metooo.io/U/67631783acd17a117725287d
トラックバック:Window Supplier Cambridge
トラックバック:https://situs-gotogel69340.liberty-blog.com/
トラックバック:home Exercise equipment
トラックバック:small shipping containers for Sale
トラックバック:Best Dewalt power tools
トラックバック:Intuitive adhd Medication
トラックバック:Cheap Male Masturbators
トラックバック:spare car key maker
トラックバック:Read Northwestu
トラックバック:Www.Freettm.Com
トラックバック:private psychiatrist staffordshire
トラックバック:hush adult toy
トラックバック:korkot online
トラックバック:Https://Nii-Pm.Ru/Bitrix/Redirect.Php?Goto=Https://Petparrot.Com/
トラックバック:read the article
トラックバック:The Best 3 Wheel Stroller
トラックバック:Adult adhd Symptoms test
トラックバック:https://chessdatabase.science/wiki/10_Basics_about_buy_a_german_driving_license_you_didnt_learn_in_school
トラックバック:https://Felixgorcu.wiki-promo.com/
トラックバック:which Fridge
トラックバック:Upvc Door Hinge Repairs Near Me
トラックバック:https://vtb.generation-startup.ru/bitrix/redirect.php?goto=https://pragmatickr.com/
トラックバック:Https://utahsyardsale.com/author/sideslave34
トラックバック:spare Car key Cut
トラックバック:Replacement Key For Bentley Continental Gt
トラックバック:try Fsquan 8
トラックバック:replacement remote Car keys
トラックバック:jinhon-info.com.tw
トラックバック:Salomonsen-Monaghan-3.Technetbloggers.De
トラックバック:Single bunk bed with storage underneath
トラックバック:Adult Intimate toys
トラックバック:labor Day couch sales
トラックバック:locksmith that makes Car keys near me
トラックバック:git.Kaiyuancloud.cn
トラックバック:walking rollator with seat
トラックバック:you can try blogfreely.net
トラックバック:wooden sash windows
トラックバック:chiverabbi22.bravejournal.net
トラックバック:casement window hinge Types
トラックバック:Muyin 2024 blog post
トラックバック:glass repair for windows
トラックバック:www.writingforums.Org
トラックバック:standing Wheelchair
トラックバック:container transport
トラックバック:electrical tool kit
トラックバック:KöRkort Utan Prov
トラックバック:Sieusi says
トラックバック:https://m.en.common-unique.com/
トラックバック:https://densyakun.hateblo.jp/iframe/hatena_bookmark_comment?canonical_Uri=https://exercisebikesonline.uk
トラックバック:window replacement panes
トラックバック:best Exercise bicycle
トラックバック:ghost immobiliser price
トラックバック:Shipping Containers
トラックバック:http://www.lumc-online.org/System/Login.asp?id=44561&Referer=https://prawo-jazdy-wyszkow.Pl/
トラックバック:Gas Safety certificate
トラックバック:blog post from Dermandar
トラックバック:Meshbookmarks blog article
トラックバック:patio Door lock repair
トラックバック:what Fridge freezer Is best
トラックバック:http://zhongneng.net.cn/home.php?mod=space&uid=314952
トラックバック:how to get an adult adhd diagnosis
トラックバック:Private Psychiatrist devon
トラックバック:http://www.xuetu123.Com/home.php?mod=space&uid=10006123
トラックバック:scanbox.wpenginepowered.com
トラックバック:oyanihanaisho.Com
トラックバック:Https://Nativ.Media:443/Wiki/Index.Php?Yardheaven594
トラックバック:Https://Images.Google.Be/
トラックバック:https://peatix.com/user/25221616
トラックバック:replacement Car keys for skoda octavia
トラックバック:mid bunk bed
トラックバック:online test For Adhd
トラックバック:Condorpoppy7.Bravejournal.Net
トラックバック:what is a landlord gas safety certificate
トラックバック:https://www.harvard.edu/
トラックバック:Https://Www.Google.Co.Vi/Url?Q=Https://Baun-Henneberg.Blogbright.Net/The-Reason-Why-Adding-A-Repair-Car-Key-To-Your-Life-Can-Make-All-The-The-Difference
トラックバック:Fridge frost free freezer
トラックバック:https://vuf.minagricultura.gov.co/Lists/Informacin Servicios Web/DispForm.aspx?ID=7697580
トラックバック:published on Stairways
トラックバック:Daftar togel
トラックバック:door-repairs57063.wikicorrespondence.com
トラックバック:Gas engineer
トラックバック:Dermandar’s website
トラックバック:https://Maps.google.com.ua
トラックバック:sunlightbulb.com
トラックバック:icanfixupmyhome.com
トラックバック:symptoms of adhd in adult males
トラックバック:www.Google.fm
トラックバック:Glass Replacement For Window
トラックバック:single bunk bed with trundle
トラックバック:complete power tool set
トラックバック:head to the telegra.ph site
トラックバック:https://Everest24.ru/
トラックバック:visit Alonegocio here >>
トラックバック:Small Double Mattress Topper
トラックバック:Self-Balancing Mobility Scooters
トラックバック:https://Gm6699.com/home.php?mod=Space&uid=3941277
トラックバック:https://postheaven.net/piewriter5/what-adults-toys-shop-experts-would-like-you-to-be-educated
トラックバック:Https://Valetinowiki.Racing/Wiki/Cramerdreyer4037
トラックバック:Triple Sleeper Bunk Beds Uk
トラックバック:adhd in adult women symptoms
トラックバック:check out this blog post via Metooo
トラックバック:electric treadmill for small spaces
トラックバック:förnya Körkort borås trafikverket
トラックバック:How To Fix Mazda Key Fob
トラックバック:Treadmill Folding
トラックバック:best retro fridge freezer uk
トラックバック:window hinge Fix
トラックバック:best Cure For anxiety Disorder
トラックバック:couches for Sale london
トラックバック:Körkort Utan hinder
トラックバック:https://maps.google.com.cu/url?sa=i&rct=j&url=https://expressdeutschekartes.com
トラックバック:fridge freezer 50 50 split frost free
トラックバック:french door fridge with water dispenser inside
トラックバック:mystery box opening Online
トラックバック:Depression treatment Private
トラックバック:Https://Minecraftcommand.Science/Profile/Mealswan4
トラックバック:upvc Door handle replacement
トラックバック:motorised mobility Scooters for sale
トラックバック:Mens masterbator
トラックバック:Adult toys united kingdom
トラックバック:Click on Saveyoursite
トラックバック:right here on Bandit 400
トラックバック:Adhd Women Assessment
トラックバック:Windows doctor
トラックバック:who can treat adhd in adults
トラックバック:bookmarkingworld.review
トラックバック:kids treehouse bed
トラックバック:https://telegra.ph/the-advanced-guide-to-travel-bedside-crib-12-06
トラックバック:https://sl-rus.ru/bitrix/redirect.php?goto=https://www.repairmywindowsanddoors.co.uk
トラックバック:best sex toy to make a woman squirt
トラックバック:Https://nodevacuum0.bravejournal.net
トラックバック:upvc windows repairs near me
トラックバック:real madrid black and gold tracksuit
トラックバック:Https://batwine18.werite.net/the-no
トラックバック:replacement Windows cost
トラックバック:lg refrig
トラックバック:http://appc.cctvdgrw.com/home.php?mod=Space&uid=1800461
トラックバック:sliding glass patio door repair
トラックバック:Locksmiths Nearby
トラックバック:https://www.Longisland.com/
トラックバック:simply click gsean.lvziku.cn
トラックバック:Power tools online
トラックバック:cabin beds single
トラックバック:Replacement Double Glazed Sealed Units Near Me
トラックバック:https://dfes.net/home.Php?mod=space&uid=1799526
トラックバック:https://yogicentral.science/wiki/malikthomas3500
トラックバック:Best 3 Wheel Stroller
トラックバック:lost Car keys
トラックバック:Which Doctor Treats Adhd
トラックバック:what is A ghost immobiliser
トラックバック:Collapsible Mobility scooters
トラックバック:Understanding Women With adhd
トラックバック:Sovren write an article
トラックバック:Initial Mental health assessment
トラックバック:what is the best fridge freezer Brand
トラックバック:replace upvc window handle
トラックバック:https://larsen-rode-2.technetbloggers.de/an-guide-to-extractor-fan-kitchen-island-in-2024-1735925218/
トラックバック:double Glazing lock repairs
トラックバック:pvc doctor Near me
トラックバック:images.google.so
トラックバック:www.feicard.top writes
トラックバック:https://www.google.ci/url?q=https://www.bunkbedsstore.uk
トラックバック:https://compravivienda.com/
トラックバック:mental health assessment near me
トラックバック:Glass Replacement Double Glazing
トラックバック:glass window replacements Near me
トラックバック:adhd Symptoms in adulthood
トラックバック:small cabin bed
トラックバック:Tested for adhd Near Me
トラックバック:emergency psychiatric Assessment
トラックバック:https://zenwriting.net/fogcolt0/14-businesses-are-doing-a-fantastic-Job-at-folding-mobility-scooters-for-sale
トラックバック:comfortable mobility scooters
トラックバック:foldable treadmills
トラックバック:https://morphomics.science/wiki/15_UpAndComing_Renault_Clio_Replacement_Key_Cost_Bloggers_You_Need_To_Be_Keeping_An_Eye_On
トラックバック:mental health diagnosis assessment
トラックバック:peugeot replacement key cost
トラックバック:skoda key fob not working
トラックバック:Water And ice refrigerator
トラックバック:https://sharpe-bay-3.blogbright.net
トラックバック:new content from fridge-freezers64212.wikibuysell.com
トラックバック:lost Car key How to replace
トラックバック:reviews over at www.footballzaa.com
トラックバック:Https://Jusomo-Eumsaiteu17409.Thenerdsblog.Com
トラックバック:smart vacuum cleaner
トラックバック:Gitea.carmon.co.Kr
トラックバック:how to get diagnosed with adhd In adulthood
トラックバック:http://www.0551gay.com/space-uid-250990.html
トラックバック:American Fridges
トラックバック:Gas Safety Check Milton Keynes
トラックバック:american fridge Freezers
トラックバック:Https://Canvas.Instructure.Com
トラックバック:link webpage
トラックバック:https://peatix.com/user/24847135
トラックバック:Electric Walking Treadmill
トラックバック:right here on comunidadeqm.marcelodoi.com.br
トラックバック:real wood bunk beds
トラックバック:best bunk Beds
トラックバック:best mobility scooter
トラックバック:Baby pram
トラックバック:private Psychiatrist in london
トラックバック:Adhd Psychiatrist
トラックバック:3 wheel all terrain buggy
トラックバック:http://www.e10100.com/home.php?mod=space&uid=662044
トラックバック:immobiliser
トラックバック:vauxhall key cutting
トラックバック:Gas safety certificate Milton keynes
トラックバック:https://Images.google.ms/url?q=https://www.metooo.io/U/666b8c4e54f4e211b017bae9
トラックバック:https://www.givehigher.com.au
トラックバック:mobility scooters uk
トラックバック:modern bunk beds
トラックバック:Car Boot Ramp For Mobility Scooter
トラックバック:http://www.xuetu123.com/home.Php?mod=space&uid=10031294
トラックバック:adhd assessment tools
トラックバック:from shorl.com
トラックバック:read this blog post from puggaard-deleon-3.federatedjournals.com
トラックバック:https://yourbookmark.stream
トラックバック:Samsung fridges
トラックバック:side by side double Stroller
トラックバック:2 Seater chaise sofa
トラックバック:skoda octavia key synchronisation
トラックバック:https://dugoutsword0.bravejournal.net
トラックバック:Single oven range cooker 90Cm
トラックバック:replace upvc window Hinge
トラックバック:veleco Scooter
トラックバック:couch With chaise lounge
トラックバック:Testing for adhd near me
トラックバック:https://images.google.com.sv/url?q=https://spears-somerville-3.federatedjournals.Com/learn-the-diagnosis-adhd-tricks-the-celebs-are-making-use-of
トラックバック:Fridge Freezer Sale
トラックバック:adhd testing
トラックバック:Deep couches for sale
トラックバック:french door fridge singapore
トラックバック:adhd assessment Psychiatrist
トラックバック:How to get a adhd assessment
トラックバック:Online FüHrerschein Bestellen A2
トラックバック:Adhd Private Assessment Ireland
トラックバック:top Fridge
トラックバック:Skoda key fob replacement
トラックバック:Gas Safe Engineer
トラックバック:get diagnosed with adhd
トラックバック:https://signumvent.ru
トラックバック:Hidden Symptoms Of Adhd In Adults
トラックバック:Red Couches For Sale
トラックバック:can A private Psychiatrist prescribe medication
トラックバック:Psychiatry uk assessment
トラックバック:comprehensive
トラックバック:mobile auto locksmiths
トラックバック:Psychiatrist appointment
トラックバック:Single Double Stroller
トラックバック:Https://Olderworkers.Com.Au
トラックバック:https://siberiatravel.ru/bitrix/redirect.php?Goto=https://www.Frydge.uk/
トラックバック:Mobility scooters for sale
トラックバック:demo2-ecomm.in.ua
トラックバック:Double stroller for newborn Twins
トラックバック:ghost 2 Immobiliser Reviews
トラックバック:Cribs beds
トラックバック:lesser known Adhd symptoms
トラックバック:beställa köRkort Bankid
トラックバック:landlord gas safety certificate cost
トラックバック:lost keys for car
トラックバック:Https://Www.Google.Bt/
トラックバック:Https://Mohamed-Strand.Hubstack.Net/10-Apps-To-Help-You-Control-Your-Anxiety-Depression-Treatment
トラックバック:information from Google
トラックバック:Double Single Bunk Bed
トラックバック:writes in the official king-wifi.win blog
トラックバック:adhd ring of fire symptoms
トラックバック:check out this one from Yogicentral
トラックバック:treatment for inattentive Adhd In Adults
トラックバック:http://www.nzdao.cn
トラックバック:https://oneill-wood.blogbright.net/the-most-underrated-companies-to-monitor-in-the-leatherette-recliner-industry
トラックバック:wwwfrydgeuk22987.Blogrelation.Com
トラックバック:Double car seat stroller
トラックバック:adhd in Adults Women symptoms
トラックバック:https://maps.google.com.sl/
トラックバック:assessing mental health
トラックバック:Private adhd assessment Dublin
トラックバック:Blogbright noted
トラックバック:volkswagen key programming
トラックバック:private titration adhd
トラックバック:Redirect.li
トラックバック:mental health physical Assessment
トラックバック:Power tools
トラックバック:integrated Fridge freezer 60/40
トラックバック:4 seater sofa leather recliner
トラックバック:hessellund-christiansen.thoughtlanes.net
トラックバック:L-Shaped Bunk Bed
トラックバック:Car Boot Scooter
トラックバック:dcfs mental health assessment
トラックバック:windowdoctor
トラックバック:read more on King Wifi`s official blog
トラックバック:wise-lemon-fhc36Q.mystrikingly.com
トラックバック:https://writeablog.net/
トラックバック:integrated fridge freezer frost free 50/50
トラックバック:writes in the official Security Hub blog
トラックバック:Retro fridge freezer
トラックバック:double bunk bed adults
トラックバック:strattera adhd medication
トラックバック:lowest price
トラックバック:http://xojh.cn/home.Php?mod=space&uid=1890783
トラックバック:titration adhd meds
トラックバック:diagnosis for adhd in adults
トラックバック:Google.Co.Cr
トラックバック:retro style fridge freezer uk
トラックバック:KöPa KöRkort Utan Stress
トラックバック:Private Adhd Assessment Hampshire
トラックバック:Http://Ezproxy.Cityu.Edu.Hk/Login?Url=Https://Pace-Kondrup-2.Thoughtlanes.Net/10-Adhd-Assessments-Related-Projects-That-Stretch-Your-Creativity
トラックバック:contemporary Leather reclining sofa
トラックバック:http://netvoyne.ru/user/plaincement69
トラックバック:best Fridge make
トラックバック:upvc window fixed panel
トラックバック:where to get diagnosed for Adhd
トラックバック:childrens bunk bed with desk
トラックバック:who can diagnose Adhd adults
トラックバック:adhd Diagnosis and Stigma
トラックバック:Click To See More
トラックバック:volveter.ru
トラックバック:toddler bunk Beds with slide
トラックバック:types of adhd In women
トラックバック:natural methods to treat anxiety
トラックバック:https://www.voiceofca.in/frm.php?url=aHR0cHM6Ly93d3cubXltb2JpbGl0eXNjb290ZXJzLnVrLw
トラックバック:frost free Fridge freezers
トラックバック:best auto vacuum
トラックバック:cabin Bed Mid
トラックバック:Http://Xintangtc.com
トラックバック:can a doctor Prescribe adhd medication
トラックバック:leather modular lounge
トラックバック:my babiie stroller
トラックバック:Automatic Floor cleaner
トラックバック:50/50 fridge freezer integrated
トラックバック:https://articlescad.com/why-2-in-1-pram-system-could-be-more-dangerous-than-you-believed-106907.html
トラックバック:information from Pku
トラックバック:mid sleeper cabin bunk Bed
トラックバック:large Fridge freezers uk
トラックバック:Couches black
トラックバック:Www.Google.Pl
トラックバック:Ferguson-Kemp.Technetbloggers.De
トラックバック:american Fridge Frezzer
トラックバック:anxiety Disorders
トラックバック:longshots.wiki
トラックバック:Tupalo.com
トラックバック:lamsn.Com
トラックバック:French Style Fridge Freezer With Water And Ice Dispenser
トラックバック:Visit telegra.ph
トラックバック:please click Botdb
トラックバック:triple bunk with stairs
トラックバック:Guldbrandsen-Bright-2.Mdwrite.Net
トラックバック:Double buggy 3 wheels
トラックバック:fold up treadmill
トラックバック:mini key fob repair
トラックバック:Https://Blair-Skovsgaard-3.Technetbloggers.De/The-Top-5-Reasons-People-Thrive-In-The-King-Size-Pull-Out-Couch-Industry/
トラックバック:https://www.youtube.com/redirect?q=https://womble-coates-2.technetbloggers.de/10-quick-tips-about-single-fan-oven
トラックバック:space-saving design side by side fridge Freezer
トラックバック:durable Mobility scooters
トラックバック:Lost car keys what to Do
トラックバック:tinted-hyacinth-fjsb1c.mystrikingly.com
トラックバック:Metooo official
トラックバック:https://www.graphicscience.jp
トラックバック:gas safety engineers Buckingham
トラックバック:Single Bunk Desk
トラックバック:https://clashofcryptos.trade/wiki/the_3_greatest_moments_in_link_collection_site_history
トラックバック:https://mcintosh-meadows-3.blogbright.net/10-misconceptions-your-boss-shares-about-mobility-scooter-automatic-folding-mobility-scooter-automatic-folding/
トラックバック:automatic electric folding Portable lightweight mobility scooter
トラックバック:high-zacho-3.technetbloggers.de
トラックバック:Bunk beds With Slide
トラックバック:Best roborock vacuum
トラックバック:http://bbs.worldsu.org/
トラックバック:Misted up double glazing
トラックバック:french Door fridge home depot
トラックバック:Leather U Shape Sectional
トラックバック:fridge freezer French doors uk
トラックバック:https://bbs.pku.edu.cn/v2/Jump-to.php?url=https://menwiki.men/wiki/ten_easy_Steps_to_launch_your_own_driving_test_Online_business
トラックバック:Best Robot vacuum for large house
トラックバック:cabin bed mid sleeper
トラックバック:small american fridge freezers
トラックバック:vauxhall key replacement prices
トラックバック:l shaped leather couch
トラックバック:rodriguez-jepsen-3.mdwrite.net
トラックバック:mensvault.men
トラックバック:bunk bed Online
トラックバック:http://agromag.ru/
トラックバック:Personal Mobility
トラックバック:autowatch ghost immobiliser Cost
トラックバック:Car keys spare
トラックバック:midi Bunk bed
トラックバック:best 8mph mobility scooters Uk
トラックバック:local emergency Locksmith
トラックバック:50/50 Integrated fridge Freezer uk
トラックバック:Https://git.frankdeweers.com/evolutionkr3987
トラックバック:Https://www.google.co.ao/Url?q=https://telegra.ph/20-things-that-only-the-most-devoted-Car-boot-mobility-scooters-fans-are-aware-of-09-18
トラックバック:images.google.Be
トラックバック:Slide Bunk Beds
トラックバック:Mitolyn reviews
トラックバック:efficient cooking built in ovens
トラックバック:fold up mobility scooters for sale
トラックバック:bolton-eriksen-2.mdwrite.net
トラックバック:cleaning robot mop and vacuum
トラックバック:에볼루션 슬롯
トラックバック:Gas fire engineers near me
トラックバック:Convertible Sectional Sofa
トラックバック:Top Rated Frost Free Fridge Freezers
トラックバック:templegreen76.werite.net
トラックバック:please click clashofcryptos.trade
トラックバック:brandsphere1.Werite.net
トラックバック:3 Seater fabric recliner sofa
トラックバック:mid cabin Bed with Storage
トラックバック:powertool Kits
トラックバック:leather sleeper couch
トラックバック:http://lineyka.org/user/bumperschool74/
トラックバック:wooden cot Bed
トラックバック:www.Rkm-Electro.ru
トラックバック:full sleeper sofa
トラックバック:Sleeper Sofa with chaise
トラックバック:Baby Cot
トラックバック:Fridges For sale uk
トラックバック:mobility scooters on pavements Law
トラックバック:shokz-russia.ru
トラックバック:Read A lot more
トラックバック:https://infozillon.com/User/peanutrouter4/
トラックバック:repairing patio Doors
トラックバック:davenport-Robles-4.blogbright.net
トラックバック:Https://Www.Xinweiyu.Com/
トラックバック:Green Electric Scooter
トラックバック:Sit n stand double stroller
トラックバック:independent living scooters
トラックバック:dev.fleeped.Com
トラックバック:Https://Buffetcrush5.Werite.Net/
トラックバック:Guerra-Kamper-2.Mdwrite.Net
トラックバック:our website
トラックバック:check
トラックバック:best dual range Cookers
トラックバック:Integrated hob and oven
トラックバック:french door fridge plumbed
トラックバック:Buying A Mobility Scooter
トラックバック:box sash window
トラックバック:Buckingham gas Safe engineer
トラックバック:robot vacuum cleaner ebay
トラックバック:french door refrigerator With double freezer drawers
トラックバック:lg fridge Freezer uk
トラックバック:reviews over at Olderworkers
トラックバック:skillmask3.bravejournal.net
トラックバック:Built Oven Single
トラックバック:grey Fabric corner recliner sofa
トラックバック:sofa sets for sale
トラックバック:Https://Www.Bioguiden.Se/Redirect.Aspx?Url=Https://Articlescad.Com/The-Little-Known-Benefits-Of-Power-Tool-Store-164507.Html
トラックバック:Fridge Freezer
トラックバック:boot mobility scooter near me
トラックバック:notabug.Org
トラックバック:try bunk-beds-for-kids38584.blog2learn.com
トラックバック:makes of Fridges
トラックバック:2In1 Pushchair
トラックバック:https://cableberet9.werite.net/
トラックバック:buy electric mobility Scooter
トラックバック:fridge water dispenser Cleaner
トラックバック:freshwibe.online officially announced
トラックバック:Great Bunk Beds
トラックバック:replacement upvc door panel
トラックバック:Cheap single ovens
トラックバック:frydge41550.wikilentillas.com
トラックバック:dewalt hand tools
トラックバック:Terrain Pram
トラックバック:coolpot.stream
トラックバック:read this post from Jportal
トラックバック:Duel Fuel Ovens
トラックバック:leather sofa 4 seater recliner
トラックバック:Maxi Cosi Kore Pro I Size Car Seat
トラックバック:Island cooker hoods
トラックバック:landlord gas safety certificate how often
トラックバック:video bokep viral terbaru indonesia
トラックバック:double pram and Pushchair
トラックバック:dual fuel range Cooker sale
トラックバック:xiaodingdong.store
トラックバック:leather and fabric sofa
トラックバック:learn more about images.google.com.ly
トラックバック:Mid-Century modern sleepers
トラックバック:cheap cordless power tool sets
トラックバック:Lightweight double pushchair
トラックバック:research by the staff of kingranks.com
トラックバック:cabinet microwave Built In
トラックバック:Bedside Cot Wooden
トラックバック:https://wikimapia.org/
トラックバック:https://Setiathome.berkeley.edu/show_user.php?userid=11867460
トラックバック:sofa 2 seater fabric
トラックバック:https://git.zbliuliu.top/ovensandhobs9862
トラックバック:https://hikvisiondb.webcam/
トラックバック:Airav said in a blog post
トラックバック:kartupoker
トラックバック:Black friday power tool set Deals
トラックバック:3 wheel baby stroller
トラックバック:single Oven or double
トラックバック:published on sciencewiki.science
トラックバック:www.sklep.zdunpol.pl
トラックバック:Darcy sofa chaise
トラックバック:kupić prawo jazdy Na raty
トラックバック:best Travel pram
トラックバック:L Shaped Loft Bed
トラックバック:https://Sofaseeder94.werite.net
トラックバック:corner sofa Grey fabric
トラックバック:beställa köRkort snabb leverans
トラックバック:head to the Thoughtlanes site
トラックバック:2 In 1 Car Seat And Pram
トラックバック:dominickafilp.designi1.Com
トラックバック:shop window glaziers birmingham
トラックバック:bitsdujour.com
トラックバック:https://ottesen-abrams-3.Blogbright.net/the-reasons-Sectional-couch-l-shaped-is-Everywhere-this-year/
トラックバック:valuesunday2.werite.net
トラックバック:Idgconnect.Idg.es
トラックバック:Köp europeiskt köRkort
トラックバック:4 seater Leather settee
トラックバック:bokep hijab viral indo
トラックバック:baby Car seat
トラックバック:http://guestbook.topagentura.com/?G10E_language_selector=de&r=https://www.exercisebikesonline.uk
トラックバック:Bunk Beds With Slides
トラックバック:modern couch
トラックバック:maps.google.com.ua
トラックバック:prams 2 In 1
トラックバック:Webookmarks.Com
トラックバック:Best Online Mystery Box Site
トラックバック:top article
トラックバック:order Driving license Uk online
トラックバック:visit writeablog.net now >>>
トラックバック:Auto Vacuum cleaner
トラックバック:ирвин казино
トラックバック:blog post from botdb.win
トラックバック:gas safety milton keynes
トラックバック:upvc doors in milton Keynes
トラックバック:3 Seater sofa Sale
トラックバック:http://www.daoban.org/Space-Uid-1218148.html
トラックバック:www.155Bookpic.com
トラックバック:Leather Recliner Sofa 4 Seater
トラックバック:visit Bos 7`s official website
トラックバック:Glass Doctor of birmingham
トラックバック:Wooden windows And doors cambridge
トラックバック:audio.voxnest.com
トラックバック:http://153.126.169.73/question2answer/index.php?qa=user&qa_1=Restnumber7
トラックバック:sectional u shape Sofa
トラックバック:windows And Doors Birmingham
トラックバック:oven and Hob
トラックバック:Servergit.Itb.Edu.Ec
トラックバック:metizy54.Ru
トラックバック:2 Seat Fabric sofa
トラックバック:writes in the official curlercloud61.bravejournal.net blog
トラックバック:replacement double glazed glass Only Near me
トラックバック:built in oven uk
トラックバック:Upvc Door Repair Near Me
トラックバック:Double Glazing Glass Repair
トラックバック:Leather Electric recliner
トラックバック:lanrenclub.com
トラックバック:repairs to upvc doors
トラックバック:patio Door lock repair near me
トラックバック:bromley Windows
トラックバック:dewalt Battery powered Tools
トラックバック:Www.google.com.eg
トラックバック:repairing Glass
トラックバック:Pushchair pram 2 In 1
トラックバック:Double Glazing Windows Repair
トラックバック:which mattress toppers are best
トラックバック:best Cryptocurrency online Casino
トラックバック:Window Refurbishment
トラックバック:window caulking
トラックバック:Uk Driving License Points
トラックバック:best sectional sleeper sofa
トラックバック:Storage Sectional Sleeper
トラックバック:couch l shaped Leather
トラックバック:Local Window Repair
トラックバック:rapid Rise doors repair Birmingham
トラックバック:pop up sleeper sectional
トラックバック:kolding-allen-3.Blogbright.net
トラックバック:Mid Century Modern Leather Sofa
トラックバック:double glazing company Bromley
トラックバック:reconditioned dual fuel range Cookers
トラックバック:Heavenarticle published a blog post
トラックバック:double glazing repair
トラックバック:learn more about garrett-bateman-5.technetbloggers.de
トラックバック:carrotrubber77.werite.net
トラックバック:Cheap tools online
トラックバック:best price power tools
トラックバック:sash window Repairs east london
トラックバック:built in microwaves with trim kits
トラックバック:genuine Leather sofa
トラックバック:Repair Timber Windows
トラックバック:aluminium windows birmingham
トラックバック:Couch l shaped
トラックバック:Double Glazing Installer Luton
トラックバック:read more on Bioimagingcore`s official blog
トラックバック:Made To Measure Double Glazed Windows Manchester
トラックバック:Bitsdujour`s blog
トラックバック:restore sash windows high wycombe
トラックバック:https://telegra.ph/a-provocative-remark-about-Windows-and-doors-manchester-05-27
トラックバック:Repair A Window
トラックバック:Emergency Locksmith High Wycombe
トラックバック:mid sleeper cabin bed with stairs
トラックバック:patio door glass repair
トラックバック:fix window Leaks
トラックバック:Https://Fakenews.Win/Wiki/12_Facts_About_Repairing_Patio_Doors_To_Make_You_Think_Smarter_About_Other_People
トラックバック:Patio Doors Repairs Near Me
トラックバック:window Wizard Luton
トラックバック:csgo Battle Case
トラックバック:https://ryan-copeland.Blogbright.net/12-companies-leading-the-way-in-high-wycombe-door-panels/
トラックバック:Vodka jackpot slots
トラックバック:linked site
トラックバック:premium built In ovens
トラックバック:Repair double glazing window
トラックバック:Double glazing Repairs aylesbury
トラックバック:https://infozillon.com/User/Markindex74
トラックバック:jobs.Defsmart.In
トラックバック:Gztongcheng.Top
トラックバック:power Tool set finance
トラックバック:read more on Wifidb`s official blog
トラックバック:Double glazing leeds
トラックバック:upvc Door locks birmingham
トラックバック:https://www.google.co.mz/url?q=https://sledred2.bravejournal.net/how-To-make-a-profitable-foldable-treadmill-entrepreneur-even-if-youre-not
トラックバック:repairs to double glazed windows
トラックバック:sash window repair maidstone
トラックバック:https://karta-xpress-poland95592.Activoblog.com
トラックバック:crypto casino online
トラックバック:equipacion arsenal 2025
トラックバック:conservatories in eastleigh
トラックバック:viagra x3 amazon
トラックバック:yanyiku.cn link for more info
トラックバック:Chic coffee-themed phone covers
トラックバック:segunda equipacion inter de milan
トラックバック:http://Dtyzwmw.com/comment/html/?10410.html
トラックバック:игорный клуб Лев официальный
トラックバック:read more on Sucuri`s official blog
トラックバック:Cloudadvent.com
トラックバック:Vodka казино официальный
トラックバック:penis enlargement stem cell
トラックバック:jepang77 slot gacor
トラックバック:maillot pays bas 2025
トラックバック:Www.music-Salon.com
トラックバック:sudadera del dortmund
トラックバック:Buy Sumatra Slim Belly Tonic
トラックバック:soldering project kits
トラックバック:Best SEO Backlinks
トラックバック:http://secretsearchenginelabs.com/add-url.php?subtime=1741973013&newurl=https://www.kenpoguy.com/phasickombatives/profile.phpid2503477
トラックバック:https://thezam.co.kr/member/login.html?noMemberOrder=&returnUrl=https://Dtyzwmw.com/comment/html/?11491.html
トラックバック:https://tangguifang.dreamhosters.com/comment/html/?1299305.html
トラックバック:http://kunalab.ru/go/url=https://tangguifang.dreamhosters.com/comment/html/?1293197.html
トラックバック:http://lyadovschool.ru/go/url=https://Theterritorian.COM.Au/index.php?page=user&action=pub_profile&id=1238629
トラックバック:deneme bonusu veren siteler
トラックバック:hat chia tim uc
トラックバック:wWw.PAtchWork-QuILT-FoRUm.de
トラックバック:https://Radio-Magic.ru/component/search/?searchword=…&searchphrase=all&Itemid=102
トラックバック:دکتر فرزاد روشن ضمیر
トラックバック:https://Oke.zone/profile.php?id=488273
トラックバック:garage door services
トラックバック:DainELEE.neT
トラックバック:VisiSoothe
トラックバック:http://hev.Tarki.hu/hev/author/AntwanRose
トラックバック:click me now
トラックバック:“https://mozillabd.science/wiki/User:WilfredoSchwing”
トラックバック:fuck
トラックバック:“https://pubhis.w3devpro.com/mediawiki/index.php?title=Exsrocket.ru_62R”
トラックバック:maillot angleterre
トラックバック:irwin-playsprout.wiki
トラックバック:Official VisiSoothe Website
トラックバック:pick up poop service
トラックバック:Kometa казино официальный
トラックバック:Chicago-Faucet-Shoppe.com
トラックバック:Westhomesconstruction.org
トラックバック:비아그라 구매
トラックバック:перевод криптовалюты на банковский счет
トラックバック:игры казино Cat
トラックバック:medicine online order
トラックバック:Effective Keto Supplement For Weight Loss
トラックバック:http://Gotanproject.net/node/25097837?——WebKitFormBoundaryC2VZmyxfqvNbtGmEContent-Disposition:form-data;name=titleLaCliniquedePhysiothrapieMontral-Nord:VotrePartenairepourlaSantetlaRhabilitation——WebKitFormBoundaryC2VZmyxfqvNbtGmEContent-Dispositi
トラックバック:https://Blog-KR.Dreamhanks.com/question/maquillage-permanent-joliette-lanaudiere-yeux-sourcils-levres-16/
トラックバック:camiseta argentina 2025
トラックバック:Sykaaa user experience
トラックバック:sex người lớn
トラックバック:Irwin Casino
トラックバック:ruay หวย
トラックバック:Vodka bet официальный сайт
トラックバック:DentiCore teeth-strengthening Solution
トラックバック:mitolyn reviews 2025
トラックバック:Vodka мобильная версия
トラックバック:https://socialrator.com/story9940785/exterminateurs–gatineau-extermination-mike-roy
トラックバック:viktorzi goodbye fckrs
トラックバック:Naismithrules.net
トラックバック:Mr. Bee Removal (Carrollton)
トラックバック:Fast Lean pro
トラックバック:Unlim casino вход в личный кабинет
トラックバック:Bokep Indonesia Terbaru
トラックバック:Раменбет
トラックバック:Jetton withdrawal
トラックバック:black dortmund kit
トラックバック:Keto-Friendly Appetite Suppressant
トラックバック:http://Gotanproject.net/node/25098004?——WebKitFormBoundaryW6ciFRtK1EwmRwPBContent-Disposition:form-data;name=titleCommentChoisirSonAgenceoptimisationdusiteWeb:LestapesCruciales——WebKitFormBoundaryW6ciFRtK1EwmRwPBContent-Disposition:form-data;name=
トラックバック:prime biome gummies reviews
トラックバック:Fred Winocur
トラックバック:Vacationwonder.com
トラックバック:비아그라 약국
トラックバック:phim cach nhiet
トラックバック:vovan casino промокод
トラックバック:wplay
トラックバック:http://Clarkaviation.com/__media__/js/netsoltrademark.php?d=blog-kr.dreamhanks.comquestionvente-de-devises-etrangeres-guide-pratique-123
トラックバック:http://blog-kr.dreamhanks.com/
トラックバック:http://WWW.Gotanproject.net/node/25105649?——WebKitFormBoundaryfdoNpi595LUaVEPGContent-Disposition:form-data;name=titlePrtetBourse:ServicesenlignesurleCanada——WebKitFormBoundaryfdoNpi595LUaVEPGContent-Disposition:form-data;name=bodyAuCanada,atarget
トラックバック:Cat gaming licenses
トラックバック:Honest Overhead Door
トラックバック:Cumberlanddesigns.com
トラックバック:http://gotanproject.net/node/25104171?——WebKitFormBoundaryknQBn7UgyJv7gagCContent-Disposition:form-data;name=titleCentresdeYogasurleQubec:DcouvrezlaSrnitetleBien-tre——WebKitFormBoundaryknQBn7UgyJv7gagCContent-Disposition:form-data;name=bodyLeQubec
トラックバック:Absurdity.us
トラックバック:Mesa Kitchen and Bathroom Remodeling
トラックバック:http://efactgroup.com/bbs/board.php?bo_table=free&wr_id=1134990
トラックバック:Www.Rclawnmowers.com
トラックバック:The Memory Wave
トラックバック:https://cloudadvent.com/indexed?domain=ramique.krbbsboard.phpbo_tablefreewr_id743167
トラックバック:uruguay kit
トラックバック:https://Cert.zero.camp/safeguard/?site=Www.Gotanproject.netnode25106773——WebKitFormBoundaryXQNKji6b9TbkRaywContent-Dispositionform-datanametitleMtalGalvanis——WebKitFormBoundaryXQNKji6b9TbkRaywContent-Dispositionform-datanamebodySchmadelacorrosionl
トラックバック:unlim-casinodynasty.lol
トラックバック:PENIPUAN !!!
トラックバック:denticore fresh breath
トラックバック:camiseta paris saint germain
トラックバック:imagineonline.net
トラックバック:Blue Ridge Concrete & Construction LLC
トラックバック:Cellucare for diabetes
トラックバック:http://Gotanproject.net/node/25115700?——WebKitFormBoundarylltqBNDZRQKf9rzrContent-Disposition:form-data;name=titleNettoyagePrventifdesConduitsd’Air:MaximisezlaQualitdel’AirIntrieur——WebKitFormBoundarylltqBNDZRQKf9rzrContent-Disposition:form-data
トラックバック:http://Zh.767638.com/indexed?domain=Www.Gotanproject.net/node/25110782——WebKitFormBoundaryukbnutMViLCegbY9Content-Dispositionform-datanametitleYogaPrnatalUnePratiqueDouceetBienveillanteparlesFuturesMamans——WebKitFormBoundaryukbnutMViLCegbY9Content
トラックバック:http://nsbackup.net/__media__/js/netsoltrademark.php?d=Ramique.krbbsboard.phpbo_tablefreewr_id744703
トラックバック:เว็บสล็อต888
トラックバック:private jet charter flights
トラックバック:Jetton casino promotions
トラックバック:AnTiCipatOrYinSIgHtWorld.CoM
トラックバック:Prediksi Keramat
トラックバック:비아그라 구매 사이트
トラックバック:https://Cloudadvent.com/indexed?domain=HOW2Youtube.comgbbsboard.phpbo_tablefreewr_id2028059
トラックバック:chair Massage Rahway nj
トラックバック:wps office下载
トラックバック:fitspresso official Website
トラックバック:bethand
トラックバック:vodka-fun.buzz
トラックバック:aLotiANcluB.CoM
トラックバック:Petm.kr
トラックバック:anal dengan anjing
トラックバック:new post from Rvolchansk
トラックバック:http://Toniajanzen.com/__media__/js/netsoltrademark.php?d=Mersin.OGO.Org.trquestionhydraulic-parts-in-laval-canada-sourcing-solutions-for-industrial-needs-2
トラックバック:Increase Energy With Keto Flow Gummies
トラックバック:казино Starda
トラックバック:Fitspresso Supplement
トラックバック:http://Frltd.biz/__media__/js/netsoltrademark.php?d=Www.Bkeye.Co.krbbsboard.phpbo_tablefreewr_id1277738
トラックバック:stv-Media.ru
トラックバック:video bokep jepang
トラックバック:https://vulkan-rush.top/
トラックバック:Http://Gotanproject.Net
トラックバック:bokep terbaru gratis
トラックバック:Lipozem reviews
トラックバック:Aqua Tower reviews
トラックバック:Dovehomesinspections.Com
トラックバック:Auldridge.com
トラックバック:Teeth strengthening Solutions with probiotics
トラックバック:http://HOT-Affiliates.com/ad/www/delivery/ck.php?oaparams=2__bannerid=519__zoneid=1396__cb=9a6636b962__oadest=https://ramique.kr/bbs/board.php?bo_table=free&wr_id=746892
トラックバック:Unlim registration
トラックバック:https://www.baidu.com/s?wd=shop.ororo.co.krbbsboard.phpbo_tablefreewr_id1810230
トラックバック:http://www.Monitoring-serveru.cz/hledani-stranek?url_ip=utahsyardsale.comauthorfinnwlu121
トラックバック:Shotgun
トラックバック:Data Hongkong Lotto
トラックバック:Jetton
トラックバック:https://cert.zero.camp/safeguard/?site=www.gotanproject.netnode25114803——WebKitFormBoundarypsyLGjZOgYbMyRM0Content-Dispositionform-datanametitleDfiMtalMontralInc——WebKitFormBoundarypsyLGjZOgYbMyRM0Content-Dispositionform-datanamebodyspanstylefont-
トラックバック:https://www.Kgasuclan.ru/component/kide/istoriya/-/inhttps://cl-system.jp/question/-/index.php?option=com_kide
トラックバック:Profile
トラックバック:slot demo
トラックバック:Visisoothe Vision clarity
トラックバック:VisiSoothe Supplement For Clear Vision
トラックバック:http://Gotanproject.net/node/25137039?——WebKitFormBoundaryn6cQC1gkFKcxh6XFContent-Disposition:form-data;name=titleChangementd’HuileDomicileQubec:ConfortetPraticit——WebKitFormBoundaryn6cQC1gkFKcxh6XFContent-Disposition:form-data;name=bodySivousaus
トラックバック:useful content
トラックバック:http://www.wildleaf.org/bbs/lounge.cgi?page=80">https://Kenpoguy.com/phasickombatives/profile.phpid=2385961
トラックバック:hkg999 login
トラックバック:игорный клуб Лев
トラックバック:Биоревитализация рук
トラックバック:useful site
トラックバック:Pr1bookmarks.com
トラックバック:Reader.elisdn.ru
トラックバック:https://Rallysportmag.Com.au/wp-content/plugins/rally-sport-ads/ad_tracking_count.php?id=SubaruMotorsport&redirect=httpfairviewumc.churchbbsboard.phpbo_tablefreewr_id6131278&type=click
トラックバック:Buy Shortener Backlinks
トラックバック:Vodka slots
トラックバック:Проблемная кожа
トラックバック:Джетон
トラックバック:sharechat download kannada
トラックバック:A1z.rMpeNn.CoM
トラックバック:mitolyn scam
トラックバック:“http://investorswiki.com/index.php/Steam_Hippo_22C”
トラックバック:The Money Wave reviews
トラックバック:http://images.google.com.pa/url?q=http://manisa.ogo.org.tr/question/la-meilleure-secheuse-en-2023-sur-le-canada-performances-et-efficacite-10/
トラックバック:syair hk
トラックバック:http://NRS-Ndc.info/freecgi/EasyBBS/index.cgi?bid=2&popup=1&desc->https://cl-System.jp/question/entrepreneur-en-construction-au-quebec-trouvez-le-partenaire-ideal-par-vos-projets-47/
トラックバック:The Memory Wave reviews
トラックバック:Акне после 30
トラックバック:http://Gotanproject.net/node/25161153?——WebKitFormBoundaryYCQPqzSXgEncDfFUContent-Disposition:form-data;name=titleCanac:Toutcequevousdevriezsavoirlecheminsurlesgouttires——WebKitFormBoundaryYCQPqzSXgEncDfFUContent-Disposition:form-data;name=bodyspa
トラックバック:Irwin азартные игры
トラックバック:memek
トラックバック:Как лечить акне
トラックバック:Акне фото
トラックバック:Гормональные изменения
トラックバック:putlocker
トラックバック:mitolyn reviews and complaints
トラックバック:Lemon Balm Recipe for Weight Loss
トラックバック:Situs Slot Gacor
トラックバック:Уход после акне
トラックバック:Биоревитализации груди
トラックバック:purple peel weight loss
トラックバック:Website source
トラックバック:Акне лечение
トラックバック:Препараты от акне
トラックバック:Pelvic Floor reviews
トラックバック:Биоревитализация глаз
トラックバック:web development melbourne
トラックバック:http://Www.Gotanproject.net/node/25163136?——WebKitFormBoundaryaoB5En3fOjak5RggContent-Disposition:form-data;name=titleChoisirleBonVentilateurparSalledeBain:Confortetvacuationdel’Humidit——WebKitFormBoundaryaoB5En3fOjak5RggContent-Disposition:form-
トラックバック:more about zooma-play.top
トラックバック:Types of Acne
トラックバック:Лечение винных пятен
トラックバック:CAB주소
トラックバック:communis
トラックバック:Teacher Porn
トラックバック:whatsapp group blaster
トラックバック:that site
トラックバック:purple peel exploit
トラックバック:Борьба с акне
トラックバック:Ageverificationblog.com
トラックバック:mitolyn scam or legit
トラックバック:Косметика и акне
トラックバック:https://tangguifang.dreamhosters.com/comment/html/?1317591.html
トラックバック:mitolyn reviews and complaints reddit
トラックバック:paito hk lotto live draw
トラックバック:https://proxies123.com/
トラックバック:https://shop.compacthydro.co.ke/members/delorast21956/profile/
トラックバック:EFAcTGRouP.Com
トラックバック:sap data sphere certification
トラックバック:official Oke blog
トラックバック:chinese wedding dinner dress
トラックバック:Джеттон способы оплаты
トラックバック:Dongjin21.kr
トラックバック:Антиакне
トラックバック:https://Www.Kenpoguy.com/phasickombatives/profile.php?id=2531787
トラックバック:Косметика при акне
トラックバック:https://Aben75.cafe24.com
トラックバック:nude naked indian native porn
トラックバック:niks indian videos
トラックバック:alpha gummy reviews
トラックバック:Responsible Gaming
トラックバック:check my blog
トラックバック:Эстетическая косметология
トラックバック:Премиум косметология Строгино
トラックバック:Косметологический салон Строгино
トラックバック:sunny leone nude photos
トラックバック:Эстетическая косметология Строгино
トラックバック:https://f-i.us/
トラックバック:non gamstop casinos 2020
トラックバック:official Site for Herpafend Purchase
トラックバック:situs penipu dan phising
トラックバック:Zooma casino онлайн
トラックバック:denticore advanced dental care
トラックバック:Cellucare by sup-cellucare.com
トラックバック:best supplement for eye health
トラックバック:nagano Lean belly tonic
トラックバック:casino Sykaaa официальный
トラックバック:Инновационная косметология Строгино
トラックバック:Provadent Probiotics
トラックバック:Nagano Lean Body Tonic customer reviews
トラックバック:VisiSoothe Customer testimonials
トラックバック:SungearPro commits to providing safe
トラックバック:Профессиональный косметолог Строгино
トラックバック:Natural Oral Care
トラックバック:Provadent Advanced dental care
トラックバック:VisiSoothe ingredients And benefits
トラックバック:How antioxidants support eyesight
トラックバック:DentiCore Probiotics for strong teeth
トラックバック:Лечение потоотделения
トラックバック:Пот на ладонах и стопах
トラックバック:Косметология высокого уровня Строгино
トラックバック:mitolyn reviews consumer reports
トラックバック:Why choose Keto Flow gummies?
トラックバック:translation company mississauga
トラックバック:Healthy Teeth And Gums Support
トラックバック:Nagano Lean Body Tonic Supplement Review
トラックバック:Advanced Dental wellness with DentiCore
トラックバック:1GO online registration
トラックバック:Лечение потливости
トラックバック:VisiSoothe official Store
トラックバック:Cellucare supplement
トラックバック:Arialief reviews
トラックバック:Cellucare herbal formula for glucose regulation
トラックバック:Проблемы с потовыми железами
トラックバック:Keto Flow weight loss results
トラックバック:Папилломы лечение
トラックバック:Папилломы на коже
トラックバック:виды ботокса
トラックバック:website traffic contextual links
トラックバック:Папилломы на лице
トラックバック:go to my blog
トラックバック:Botox in legs
トラックバック:http://studiomurdolo.com/__media__/js/netsoltrademark.php?d=blogs.Koreaportal.combbsboard.phpbo_tablefreewr_id3618217
トラックバック:MIKIGAMING
トラックバック:bokep viral terbaru abg
トラックバック:Botox in the neck
トラックバック:See details
トラックバック:Уход за кожей
トラックバック:Organic Herbal formula for slimming
トラックバック:italian soccer jerseys
トラックバック:InstaDoodle reviews
トラックバック:Профилактика гипергидроза
トラックバック:best essay writing service reviews
トラックバック:Папилломы на шее
トラックバック:Крем для проблемной кожи
トラックバック:https://www.fishstripes.com/users/pallet-racking-system
トラックバック:bokep viral terbaru 2023
トラックバック:restbet
トラックバック:daftar jepang77
トラックバック:situs JHONBET77
トラックバック:Joint Genesis reviews
トラックバック:Jackpot Bet
トラックバック:Website Penipu
トラックバック:Дианостика гипергидроза
トラックバック:Джеттон казино
トラックバック:daftar emakbet
トラックバック:valencia white jersey
トラックバック:Ботокс от мигрени
トラックバック:Online Betting
トラックバック:https://vodka-battle.buzz/
トラックバック:Облегчение приступов
トラックバック:Unlim casino
トラックバック:Медицина и ботулотоксин
トラックバック:Ботулотоксин
トラックバック:Home Page
トラックバック:website traffic solo ad sellers
トラックバック:fuel pressure sensor
トラックバック:bandar55
トラックバック:Лечение гипергидроза
トラックバック:Акция на пилинг
トラックバック:Метод профилактики мигрени
トラックバック:Народные средства от гипергидроза
トラックバック:Крем анти акне
トラックバック:Брови как искусство
トラックバック:unlim-casinoodyssey.site
トラックバック:Зума казино официальный
トラックバック:index url google
トラックバック:Зарядные устройства постоянного тока для электромобилей
トラックバック:sykaaa casino официальный сайт
トラックバック:Профилактика неврологических болей
トラックバック:link daftar slot gacor EMAKBET
トラックバック:uruguay jersey
トラックバック:Антибиотики при розацеа
トラックバック:Уход за лицом
トラックバック:bokep anal
トラックバック:Кремы при акне
トラックバック:1GO программа вознаграждений
トラックバック:Неврология
トラックバック:faq контурная пластика
トラックバック:Терапия без боли
トラックバック:Ботулинотерапия
トラックバック:Girls in Hotels Beauty
トラックバック:VertiFree reviews
トラックバック:round rock car window tinting
トラックバック:https://botdb.win/wiki/User:LilyVanish5366
トラックバック:https://www.wikidelta.org/index.php/User:MollyHelm777692
トラックバック:check this
トラックバック:Vertigenics reviews
トラックバック:bokep india
トラックバック:http://it-viking.ch/index.php/Cs2case_53O
トラックバック:primebiome scam
トラックバック:https://menuaipedia.menuai.id/index.php/User:KendraKirschbaum
トラックバック:Безоперационный фейс лифтинг
トラックバック:TheraFoot Pro reviews
トラックバック:GlucoTonic reviews
トラックバック:Хроническая мигрень
トラックバック:look at this website
トラックバック:bokep gay
トラックバック:Vinsanoat.uz
トラックバック:prodentim reviews
トラックバック:Sugar Defender reviews
トラックバック:https://subscribe.ru/member/quick?email=&addgrp=httponestopclean.krbbsboard.phpbo_tablefreewr_id1137046
トラックバック:Nerve Fresh reviews
トラックバック:delhi call girls
トラックバック:казино Адмирал Х
トラックバック:Cредства от акне
トラックバック:หวยฮานอยปกติย้อนหลัง
トラックバック:Advanced Oral Care Probiotics
トラックバック:http://ww17.yhsn.com/__media__/js/netsoltrademark.php?d=Blogs.Koreaportal.combbsboard.phpbo_tablefreewr_id3680633
トラックバック:http://Sunnynodakrecords.com/__media__/js/netsoltrademark.php?d=Fromkorea.krbbsboard.phpbo_tablefreewr_id21514
トラックバック:Подошвенная бородавка
トラックバック:What is acne
トラックバック:Косметология
トラックバック:Ретинол против акне
トラックバック:equipacion real betis
トラックバック:http://Churchstreetmortgagemd.org/__media__/js/netsoltrademark.php?d=thebestgamesites.Awardspace.infoindex.phpastatsusylvesterleichha
トラックバック:camiseta de portugal
トラックバック:https://ec2-52-21-113-188.Compute-1.Amazonaws.com/baradundental.co.kr
トラックバック:Pawbiotix reviews
トラックバック:Water Bottles Manufacturers
トラックバック:Ledelog.net
トラックバック:The Wealth Dream Code reviews
トラックバック:enfant maillot de foot
トラックバック:http://Funkihelp.com/__media__/js/netsoltrademark.php?d=Pasarinko.Zeroweb.krbbsboard.phpbo_tablenoticewr_id5276533
トラックバック:Gunnpod Evo
トラックバック:IGET Pro in Australia
トラックバック:Removal of papillomas
トラックバック:Минимальная реабилитация
トラックバック:primebiome reviews consumer reports
トラックバック:Eden reviews
トラックバック:meth
トラックバック:Профилактика морщин
トラックバック:sugarmd
トラックバック:ботокс
トラックバック:check my reference
トラックバック:Ernieciccotelli.com
トラックバック:Nagano Tonic reviews
トラックバック:ikaria juice reviews
トラックバック:additional reading
トラックバック:red bull leipzig 3rd jersey
トラックバック:CA
トラックバック:бк с фрибетом без депозита
トラックバック:https://orphelins-apocalypse.synology.me/mediawiki/index.php?title=Discussion_utilisateur:VirgilMorford99
トラックバック:비아그라
トラックバック:Новое Ретро казино
トラックバック:Arkada быстрые выплаты
トラックバック:bokep hijab
トラックバック:bar jazz montreal
トラックバック:https://flynonrev.com/airlines/index.php/User:DustyEddy71657
トラックバック:рейтинг букмекерских контор
トラックバック:ботулотоксин сущность
トラックバック:ngentot anjing
トラックバック:Лучшие технологии для волос
トラックバック:ラツィオ ユニフォーム 2025
トラックバック:Индивидуальный подход в ботоксе
トラックバック:Эффект от Ботокса
トラックバック:Эффекты ботокса на ресницы
トラックバック:Профессиональная консультация косметолога
トラックバック:Лечение волос
トラックバック:trash cans were made out of metal
トラックバック:Кожа без морщин
トラックバック:Новая жизнь без пота
トラックバック:Безопасная методика
トラックバック:Ботокс как выбрать
トラックバック:Побочные эффекты Ботокса
トラックバック:Ботокс для бруксизма
トラックバック:Как выбрать клинику Ботокса
トラックバック:Блондирование после Ботокса
トラックバック:Избегаем активности после ботокса
トラックバック:Ботокс эффект
トラックバック:Ботокс последствия
トラックバック:Ботокс упругость
トラックバック:Здоровье волос после Ботокса
トラックバック:Молодость и красота кожи
トラックバック:Визуальное сравнение
トラックバック:Ограничения по алкоголю
トラックバック:Маски для восстановления
トラックバック:Избавление от бруксизма
トラックバック:Снятие напряжения
トラックバック:Секреты красоты
トラックバック:Ботулинический токсин
トラックバック:Уход в домашних условиях
トラックバック:Профессиональный ботокс в лоб
トラックバック:Ботокс эффекты
トラックバック:Молодая кожа
トラックバック:ดูหนังฟรี
トラックバック:Уход за кожей лица
トラックバック:Заказать ботокс в лоб
トラックバック:Ботокс губ эффекты
トラックバック:Стресс для волос
トラックバック:daftar jepangbet
トラックバック:Алкоголь после ботокса
トラックバック:blue salt trick for men
トラックバック:Методы омоложения
トラックバック:Преимущества
トラックバック:Безаммиачная краска
トラックバック:Избегать после Ботокса
トラックバック:Преимущества пилинга
トラックバック:Консультация по ботоксу
トラックバック:Ботокс в лоб цена
トラックバック:Ботокс квалификация
トラックバック:Влияние алкоголя
トラックバック:Ботокс преимущества
トラックバック:Уход за собой
トラックバック:Нитевой лифтинг
トラックバック:KOMERCE PENIPU
トラックバック:Выбор клиники Ботокс
トラックバック:Бруксизм
トラックバック:https://www.youtube.com
トラックバック:Ботокс специалисты
トラックバック:Розацеа
トラックバック:Секреты молодости кожи
トラックバック:แทงหวย100
トラックバック:Proxies Buy
トラックバック:Affiliate marketing done for you
トラックバック:Kitchen cookware Area manufacturer
トラックバック:grandpashabet
トラックバック:레비트라 구매
トラックバック:New Retro RTP
トラックバック:高浜市 リラクゼーション
トラックバック:what is the salt trick for men
トラックバック:Ботокс в носогубки фото до и после
トラックバック:nlifelab.org
トラックバック:adhesive tapes
トラックバック:important source
トラックバック:Безопасный ботокс
トラックバック:Волосы
トラックバック:check my site
トラックバック:penipu phising
トラックバック:Пористость волос
トラックバック:mikigaming login
トラックバック:Улучшение состояния кожи
トラックバック:https://online-learning-initiative.org/wiki/index.php/Cvety_52s
トラックバック:Data Sydney Lotto
トラックバック:1xSlots payment methods
トラックバック:Buy Best Proxies
トラックバック:Результаты Ботокса
トラックバック:cach su dung qua oc cho
トラックバック:teens big tits
トラックバック:https://utahsyardsale.com/author/spencera366/
トラックバック:Practice billing solutions
トラックバック:Щадящее окрашивание
トラックバック:Удаление сосудов жёлтым лазером
トラックバック:big tits russian mature
トラックバック:สถิติหวยลาวruay
トラックバック:predator revo shaft for sale
トラックバック:Best Usa Proxies
トラックバック:norma yang dibuat dan dikeluarkan oleh pemerintah adalah norma
トラックバック:https://tktube.ru
トラックバック:scam
トラックバック:garage door spring repair Kansas City
トラックバック:pemerintah
トラックバック:Phising
トラックバック:http://www.infinitymugenteam.com:80/infinity.wiki/mediawiki2/index.php/User:LasonyaPaul
トラックバック:important site
トラックバック:Cheapest Proxies
トラックバック:audit servives
トラックバック:Seo Proxies
トラックバック:scammer
トラックバック:https://www.totoframe.com
トラックバック:sofas de segunda mano madrid
トラックバック:Purchase of Flight Tickets
トラックバック:Образование будущего
トラックバック:Техподдержка от Яндекс Маркета
トラックバック:bet on red
トラックバック:sabong online
トラックバック:Тылсымлы муфин (зур кара әтәч белән анал вакытлары өчен фекаль тарту)
トラックバック:fortune tiger demo gratis
トラックバック:red on bet
トラックバック:fortune tiger bonus gratis sem deposito
トラックバック:plinko balls
トラックバック:เซ็กซี่24
トラックバック:http://wiki.kurusetra.id/index.php?title=Kolpak_45e
トラックバック:https://www.ventura.wiki/index.php/User:AngelesFlq
トラックバック:fortune tigrinho
トラックバック:Online Casino
トラックバック:http://unpop.org/blog/member.asp?action=view&memName=MayHeffner5865805
トラックバック:is plinko legit
トラックバック:AdaKami
トラックバック:bet on red free spins
トラックバック:Xxx
トラックバック:iptv deutsch
トラックバック:Cerita Dewasa gak sengaja
トラックバック:дешевые проститутки метро просвещения
トラックバック:austin texas reliable wooden deck installation
トラックバック:Phising dan scammer
トラックバック:fortune and mouse
トラックバック:Proxies Cheap
トラックバック:aviator game
トラックバック:Proxies123.com
トラックバック:sky88
トラックバック:proxy best price
トラックバック:company website
トラックバック:plinko betrugsmasche
トラックバック:Penipu dan Phising
トラックバック:Cheap Socks Proxies
トラックバック:deck installation
トラックバック:Акция
トラックバック:https://weekend4you.com
トラックバック:Phising dan Scam
トラックバック:구글 Google 실명 ID 판매
トラックバック:jogo plinko paga mesmo
トラックバック:Hoffman Tactical Super Safety
トラックバック:United Kingdom
トラックバック:ラブドールエロ
トラックバック:dog breed registries
トラックバック:lồn học sinh
トラックバック:Лазерное лечение телеангиоэктазии сосудистых звёздочек
トラックバック:Ботокс в лоб
トラックバック:Антивозрастные методы
トラックバック:Ботокс в лоб от морщин
トラックバック:стоимость надувного ангара
トラックバック:купить надувной ангар
トラックバック:пневмокаркасный ангар цена
トラックバック:надувные склады ангары цена
トラックバック:Luz Vacations
トラックバック:patriot voices
トラックバック:Phising dan penipu
トラックバック:http://Indoorairhygieneinstitute.com/__media__/js/netsoltrademark.php?d=sl860.comcommenthtml180167.html
トラックバック:False Eyelashes in Dubai
トラックバック:DCVGFRTR2321
トラックバック:Cca.juneauchamber.com
トラックバック:витамины для планирования беременности
トラックバック:Images.google.Co.uk
トラックバック:Forum
トラックバック:Drivered.tv
トラックバック:Expertnov.ru
トラックバック:Cheap Private Proxies
トラックバック:Современные вкусы}
トラックバック:Facebook ban
トラックバック:پک سوغاتی
トラックバック:Newchallenges.Org
トラックバック:Cerita Dewasa gambar ngentot
トラックバック:Free Template
トラックバック:Christopher Nathoo
トラックバック:https://Bolaopaulista.com/author/isobelbacon/
トラックバック:wewe.Eu.org
トラックバック:Porno-Gallery.ru
トラックバック:truffe noire fraîche (Tuber Melanosporum) de A-qualité
トラックバック:کانکس
トラックバック:https://anunciosclassificados.org/author/mickeymassa/
トラックバック:Www.rAVaNsHena30.com
トラックバック:Br.U.C.E.L.Eebes.T@WWW7A.Biglobe.Ne.jp
トラックバック:کلینیک زیبایی ارکیده
トラックバック:sweet bonanza
トラックバック:다파벳주소
トラックバック:http://Www.Gotanproject.net/node/25300132?——WebKitFormBoundarysFE3w5ecgx06W7ZhContent-Disposition:form-data;name=titleEntretiendesquipementsdeProduction:AssurerlaPerformanceetlaDurabilit——WebKitFormBoundarysFE3w5ecgx06W7ZhContent-Disposition:form-
トラックバック:WOoRIwEBS.Com
トラックバック:https://Classifieds.Ocala-News.com/author/emely482077
トラックバック:کلینیک لیلیوم سفید
トラックバック:http://www.cqcici.com/comment/html/?483855.html
トラックバック:https://www.89u89.com/author/fidelialama/
トラックバック:https://Vknigah.com/user/CharleyArchdall/
トラックバック:https://www.kenpoguy.com/phasickombatives/profile.php?id=2631650
トラックバック:sildenafil 20
トラックバック:icon139 rtp
トラックバック:clinic
トラックバック:codeine for sale
トラックバック:icon139
トラックバック:Укол внутримышечно
トラックバック:situs
トラックバック:http://poochesrcool.com/__media__/js/netsoltrademark.php?d=www.general-merchandise.sblinks.netNewsboutiques-chic-chez-vous
トラックバック:https://a.slashdotmedia.com/www/delivery/ck.php?ct=1&oaparams=2__bannerid=31784__zoneid=28998__cb=0d8700b61d__oadest=https://tecza.org.pl/author/michal/
トラックバック:lisinopril 20 tablet
トラックバック:Buy Usa Proxies
トラックバック:http://www.rtinetwork.org/about-us/advisory-council/deshler-don
トラックバック:yummymeets cams
トラックバック:WhatsApp LDPlayer hash extractor
トラックバック:https://www.fescina.com.br/group/mysite-231-group/discussion/d8cebead-a9d4-46a1-bc97-423ec7ae7c43
トラックバック:Buy Cheap Vape
トラックバック:Big Discount Sale
トラックバック:Vapor E-Liquids
トラックバック:home solar water heater
トラックバック:http://rtinetwork.org/rti-blog-archives/archive?start=20
トラックバック:https://succes.ro/blog/page/107/
トラックバック:https://bebedourosgoiania.com.br/descubra-o-jogo-fortune-tiger-dicas-e-estrategias-27/
トラックバック:orkidehbc.com
トラックバック:https://sumo.app/sl/forum/tutorials-and-techniques/plinko
トラックバック:Антивозрастной уход
トラックバック:https://foro.rune-nifelheim.com/recent/?start=50;PHPSESSID=eaf60250cbc0ef1976f4372a00e9dbb1
トラックバック:mikigaming link alternatif
トラックバック:https://desifaceup.in/Ivario12?lang=arabic
トラックバック:http://www.6555555.com/1198.html?replyTo=28110
トラックバック:https://vattuanhuy.com/author/phuongcd/page/311/
トラックバック:https://collage.sa/the-ultimate-guide-to-the-aviator-casino-game-app-2/
トラックバック:https://forum.ostrowmaz24.pl/search.php?st=0&sk=t&sd=d&sr=posts&author_id=1442
トラックバック:https://git.mythiccraft.io/-/snippets/977
トラックバック:GRATIS VIAGRA
トラックバック:http://www.6555555.com/1198.html?replyTo=27666
トラックバック:forum.issabel.org
トラックバック:cukimai
トラックバック:go to my site
トラックバック:Vads.in
トラックバック:mines demo
トラックバック:dragon tiger
トラックバック:ebony sex
トラックバック:viet xf casino
トラックバック:Megatangkas Togel Bandung
トラックバック:Accutek Packaging Equipment Company
トラックバック:Chat with Psychologist
トラックバック:College assignment help Bathurst
トラックバック:Criminology assignment help Australia
トラックバック:Online assignment help Ballarat
トラックバック:the memory wave reviews and complaints youtube
トラックバック:racy
トラックバック:Удаление тату
トラックバック:Are replica Hermès bags worth it?
トラックバック:maps.google.com.qa post to a company blog
トラックバック:buying fake designer bags
トラックバック:trendy glasses made from green materials
トラックバック:Hermes Kelly gris asphalt loyalty rewards
トラックバック:Hermès replica bags with real leather
トラックバック:viton replica
トラックバック:vach ngan ve sinh
トラックバック:Hermes Kelly gris asphalt online exclusives
トラックバック:Fake HermèS Bags
トラックバック:marijuanaclonesonline.com breeder facing federal charges
トラックバック:home staging companies
トラックバック:Labeling Machine
トラックバック:subtle eco-inspired vision wear
トラックバック:London Mobile Massage
トラックバック:Dewacasino Togel Amanah – www.rsstop10.com
トラックバック:replica viton
トラックバック:gay
トラックバック:CIATOTO
トラックバック:کاشت ابرو
トラックバック:p831642
トラックバック:removal of existing concrete foundations
トラックバック:casino online stealing user information
トラックバック:casino online childporn sex
トラックバック:slot thailand
トラックバック:London escort agency
トラックバック:Discover More
トラックバック:Get rich quick now
トラックバック:fundraiser Meetup
トラックバック:concrete cutting services
トラックバック:cick
トラックバック:텐텐벳도메인
トラックバック:Vionic Bunion sandals
トラックバック:안전놀이터 순위
トラックバック:주안쓰리노
トラックバック:Vòng Quay May Mắn
トラックバック:Reddit accounts for sale
トラックバック:Sochi-psiholog-Russia
トラックバック:https://www.e-cigaretteshop.de/puffmi-tx600-pro-mango-ice-20mg
トラックバック:word counter for articles writer
トラックバック:Home Generators
トラックバック:weight loss medicine for sale
トラックバック:smile makeover
トラックバック:lose money sunwin debet
トラックバック:plusone bullet vibrator
トラックバック:Уход за кожей при диабете
トラックバック:British London Escorts near me
トラックバック:echolink florida
トラックバック:porn sex bokep porno bokep indo
トラックバック:shemales
トラックバック:Vulkan Platinum быстрые выплаты
トラックバック:гостиница моздок телефон
トラックバック:гостиницы в моздоке адреса и телефоны
トラックバック:Trade 350 App
トラックバック:машина напрокат в сочи без водителя
トラックバック:аренда машин геленджик
トラックバック:Www.Onlinespielearchiv.de
トラックバック:click resources
トラックバック:гостиница льюис моздок официальный сайт
トラックバック:enobahis güncel giriş
トラックバック:porn movie
トラックバック:моздок гостиница на усанова
トラックバック:다파벳가입
トラックバック:thietbibmc.vn
トラックバック:exploring the world of provocative porn
トラックバック:Super Trader App
トラックバック:краснодарский край фото россия
トラックバック:yupoo
トラックバック:eno bahis
トラックバック:Power Trades
トラックバック:area188
トラックバック:Immediate Smart
トラックバック:Wealth Phantom
トラックバック:https://dokuwiki.stream/wiki/Auto_97r
トラックバック:https://americanspeedways.net/index.php/Auto_82N
トラックバック:6a9a9.mssg.me
トラックバック:https://ashwoodvalleywiki.com/index.php?title=Auto_99A
トラックバック:Ondmatex App
トラックバック:yupoo,
トラックバック:webradio hosting
トラックバック:apex legends mod
トラックバック:basf chemicals
トラックバック:Arbionis
トラックバック:furniture factory
トラックバック:Roxun Ledger
トラックバック:Maple Venture
トラックバック:personalized furniture
トラックバック:dayz hacks
トラックバック:https://neptunepokertournament.com/7-cards-poker.html
トラックバック:apk Slot gacor 777
トラックバック:True North Capital
トラックバック:Skyline Nexus Pro
トラックバック:Instant 9.1 Akpro
トラックバック:부산 통증치료 한의원
トラックバック:omgprice5 cc
トラックバック:situs phising
トラックバック:https://neptunepokertournament.com/Online-poker-is-easy-to-play.html
トラックバック:fragpunk stream
トラックバック:Aurevia Pine
トラックバック:https://sdsle.sk/forum/profile/dominiccashin9/
トラックバック:Yield Xyvor
トラックバック:https://mozillabd.science/wiki/User:DannySalkauskas
トラックバック:y2mate
トラックバック:Immediate Zenex
トラックバック:scaming
トラックバック:yupoo,
トラックバック:Vexoen Nodeon
トラックバック:Immediate Maximum
トラックバック:Virello Nexa
トラックバック:get closer to intimate porn
トラックバック:buy viagra online cheap
トラックバック:Quantum Ogen
トラックバック:Xeldor Saldo
トラックバック:Paddle wheel flow installation procedures overview
トラックバック:Coinspire
トラックバック:Azorilix
トラックバック:Tolfex
トラックバック:Magreza
トラックバック:카지노솔루션
トラックバック:Buy Aprobarbitone Online
トラックバック:demo slot
トラックバック:best backlinks
トラックバック:buy cheap insurance
トラックバック:Immediate Avonex
トラックバック:Capstone Growth
トラックバック:Finance Quantum
トラックバック:CASAS PREFABRICADAS PUERTO RICO
トラックバック:https://telegra.ph/주요-놀이터에서의-큰-성공-스토리-02-25
トラックバック:terviraltv.pro
トラックバック:belfast local escorts
トラックバック:mexican pharmacies online
トラックバック:DominionX
トラックバック:Surge Finansörler
トラックバック:Glass Partitions
トラックバック:Immediate Edge App
トラックバック:Bitcoineer Ai
トラックバック:máy nén khí trục vít
トラックバック:quora.com
トラックバック:Ekskluzywne produkty z Tajlandii – wybierz unikalne artykuły prosto z Tajlandii.
トラックバック:Double Glazing
トラックバック:masterinbusinessadministration.com.my
トラックバック:теплоходы на прокат
トラックバック:Dedicated Private Proxies
トラックバック:Room For Rent in Karachi
トラックバック:เรตินอล
トラックバック:Wonderful Mind
トラックバック:hardware store
トラックバック:padlet.com
トラックバック:Bilad R Uni
トラックバック:house for rent Malaysia
トラックバック:instagram.com/korotkovlakanfreud
トラックバック:InovaRisePro
トラックバック:kraken tor marketplace
トラックバック:Truenorth
トラックバック:pierre
トラックバック:https://valetinowiki.racing/wiki/User:Trevor25H3750742
トラックバック:Window Installation
トラックバック:Dr Farzad Roshanzamir
トラックバック:https://mediawiki.novastega.me/index.php/Syndicate_Black_11z
トラックバック:https://wikibuilding.org/index.php?title=User:WilliamsO21
トラックバック:Tłumaczenia przysięgłe niderlandzki na niderlandzki.online
トラックバック:business
トラックバック:http://www.annunciogratis.net/author/eldenteasda
トラックバック:ครีมซองเซเว่น
トラックバック:topup chip ungu
トラックバック:5yucMCMAAAAJ
トラックバック:pendiri crypto – www.rsstop10.com
トラックバック:Yupoo Gucci
トラックバック:situs pkv games
トラックバック:GRATIS VIAGRA
トラックバック:purple peel exploit reviews
トラックバック:adu303
トラックバック:Menang Togel
トラックバック:Betonred login
トラックバック:keto flow acv gummies australia
トラックバック:zamorano01
トラックバック:PrimeAurora
トラックバック:Switch Hiprex
トラックバック:Prime Aurora
トラックバック:Bit 1000 Lexipro
トラックバック:Evolution Zenith
トラックバック:Aqua Sculpt reviews
トラックバック:Portefeuille Vexo
トラックバック:Nitric Boost Ultra reviews
トラックバック:Exodus Trading AI
トラックバック:pornhub
トラックバック:website bokep
トラックバック:polyurea rv roof
トラックバック:Mitolyn Side effects
トラックバック:Windows 10 Pro Universal Activation Key
トラックバック:Robo Lispro 70
トラックバック:panen138-official.it.com
トラックバック:situs bodong
トラックバック:jiwa bola
トラックバック:Highlands Сhainix
トラックバック:Tool.Chinaz.com
トラックバック:traditional furniture design
トラックバック:Ультразвуковая биоревитализация
トラックバック:Địt cả lò nhà Mic
トラックバック:CanFirst
トラックバック:86.wugumil.com
トラックバック:PhenQ reviews
トラックバック:pgslotcc
トラックバック:Solana Olaset
トラックバック:Judi Slot Online Terpercaya
トラックバック:Boostaro reviews
トラックバック:SlimJaro reviews
トラックバック:HepatoBurn reviews
トラックバック:Breathe Drops reviews
トラックバック:Bos138
トラックバック:Finovixus
トラックバック:Trader Cipro
トラックバック:Nerve Renew reviews
トラックバック:Packaging Machinery
トラックバック:Quantaryxis
トラックバック:หวยลาวพัฒนาวันนี้
トラックバック:Gemforex
トラックバック:Удаление новообразований
トラックバック:hhddld644.weebly.com
トラックバック:Obsidian Quantrex
トラックバック:best seduxen medicince reviews
トラックバック:theobroma cacao for weight loss
トラックバック:Plantsulin reviews
トラックバック:Stonelith Tradence
トラックバック:Nearest Boost
トラックバック:best misoprostol reviews
トラックバック:VigrX reviews
トラックバック:สูตรเลขเด็ดงวดนี้
トラックバック:Sollumin Ledger
トラックバック:slot resmi
トラックバック:collard greens tonic
トラックバック:Swap Sanorex
トラックバック:Immediate Matrix
トラックバック:macbook air что это в мск
トラックバック:what is control cable
トラックバック:joy.link free kredit rm100
トラックバック:Daily news
トラックバック:acjradio.co.uk
トラックバック:Vrymnex
トラックバック:casino online
トラックバック:petpet.wiki
トラックバック:Soluciones Zelvo
トラックバック:https://yogicentral.science/wiki/User:AdamNash8558
トラックバック:ETH Olux
トラックバック:Student Escorts in Islamabad
トラックバック:Quantum Maxair 6.0
トラックバック:mor med barn
トラックバック:download mission impossible 4k bluray
トラックバック:Instant 2X Akpro
トラックバック:buy loperamide for child
トラックバック:best Lenacapavir reviews
トラックバック:Keep Reading
トラックバック:https://t.me/s/bbwcamsnet
トラックバック:Feldzorb
トラックバック:Newmans0Wn.com
トラックバック:rare trx
トラックバック:메이저놀이터 추천
トラックバック:Keyword:
トラックバック:Phising dan website penipu
トラックバック:Удаление бородавок лазером
トラックバック:Yupoo Balenciaga
トラックバック:FortuixAgent
トラックバック:Детские ювелирные изделия
トラックバック:how to start home care business Michigan
トラックバック:rtp slot
トラックバック:casino not on gamestop
トラックバック:Finance Legend
トラックバック:jerk
トラックバック:what should i know about sex
トラックバック:CanWealth
トラックバック:eliminate Bad breath with prodentim
トラックバック:Spot Lasix
トラックバック:Pocket Watch Hallmarks and Dating
トラックバック:https://wiki.ragnaking.com/index.php/Gehartet.ru_48l
トラックバック:round rock auto interior detailing
トラックバック:Robo iFex +X2
トラックバック:https://wiki.snooze-hotelsoftware.de/index.php?title=Benutzer:AidaKershner
トラックバック:lipo austin tx
トラックバック:传奇私服一条龙制作
トラックバック:Phising dan website Scame
トラックバック:http://Tastypoke.com/__media__/js/netsoltrademark.php?d=Sl860.comcommenthtml199932.html
トラックバック:Zeylor Pacte
トラックバック:18CAM.ORG
トラックバック:austin double locked hemmed roof installation
トラックバック:4blabla writes
トラックバック:mercedes air suspension
トラックバック:consignment engagement rings austin
トラックバック:ผักไฮโดรโปนิกส์
トラックバック:custom deck installation austin
トラックバック:Pocketwaterbottle.com
トラックバック:Kenyan Escorts
トラックバック:top deck builders austin austin tx near me
トラックバック:VisiSoothe formula for vision Clarity
トラックバック:Macro Tracker
トラックバック:improve gum health with denticore
トラックバック:how to start home care business Nebraska
トラックバック:how to start home care business Mississippi
トラックバック:how to start home care business Montana
トラックバック:alexistogel agen togel
トラックバック:scam dan situs bokep
トラックバック:opentransexualhot
トラックバック:DentiCore Probiotics
トラックバック:https://sahyjux6035.weebly.com/
トラックバック:Trixo Fund
トラックバック:ETH Cormax
トラックバック:crime against humadity
トラックバック:Play Real Btc Casino Spot
トラックバック:Quantum Income
トラックバック:Cooltisyntrix
トラックバック:more helpful hints
トラックバック:joy.link free credit
トラックバック:MAB instructor certification
トラックバック:how to start home care business New Mexico
トラックバック:kra30 сс
トラックバック:Private Jets Charter
トラックバック:vape store
トラックバック:https://www.vapingreal.com/vgod-pro-mech-mod-vape
トラックバック:https://www.vapeinterest.com/four-seasons-e-liquids-desert-tobacco-30ml-nic-salt-vape-juice
トラックバック:bonus judi bola
トラックバック:Exclusive
トラックバック:Join Highroll Casino
トラックバック:quickloan com
トラックバック:FerixiumPro
トラックバック:website phising dan tunnel
トラックバック:speedrun
トラックバック:pbyqu800.weebly.com
トラックバック:how to start home care business North Dakota
トラックバック:how to start home care business South Dakota
トラックバック:Forge Qlyden
トラックバック:Betting
トラックバック:remont mieszkania Wola
トラックバック:toto macau
トラックバック:актуальная ссылка на кракен
トラックバック:Prime Wealth
トラックバック:有道翻译假网站
トラックバック:Immediate X Ai
トラックバック:Real Estate in Kenya
トラックバック:ผลบอลสด
トラックバック:Удаление папилломы на веке
トラックバック:Bit GPT AI Avis
トラックバック:quickloan
トラックバック:software testing jobs in nigeria
トラックバック:Ethereum Cormax
トラックバック:정품 비아그라 파는곳,
トラックバック:Immediate Luminary review
トラックバック:CryptoX App review
トラックバック:ดินสอเขียนคิ้ว
トラックバック:การขนส่งทางอากาศ
トラックバック:ครีมลดรอยสิว
トラックバック:Robo Mentax +15X Review
トラックバック:Bitcord Verdis review
トラックバック:Bit GPT App Avis
トラックバック:break-bulk
トラックバック:คาร์โก้ขนส่ง
トラックバック:450 bushmaster ammo
トラックバック:Parrot Birds
トラックバック:Immediate Path review
トラックバック:Angolo Della Cartomanzia
トラックバック:cialis pills
トラックバック:FinoTechPro
トラックバック:situs slot qris
トラックバック:ZPQMTG56C
トラックバック:Pole Portfelvista Recenzja
トラックバック:토토사이트 추천
トラックバック:best medicine for pregnancy
トラックバック:Yupoo Celine
トラックバック:Instant V8 Exalgo
トラックバック:XBT 0.6 Bumex
トラックバック:Xybero Renda
トラックバック:abm888
トラックバック:link baru free credit
トラックバック:atvip.ru
トラックバック:BlueQubit
トラックバック:Andreas
トラックバック:0410.ru
トラックバック:AZndreas
トラックバック:gift shop items
トラックバック:bristol escort girl
トラックバック:Kilt
トラックバック:kado bar vape flavors
トラックバック:PENIPU PHISING SCAM
トラックバック:Сильная потливость при стрессе
トラックバック:pegging
トラックバック:mobile phones
トラックバック:download cs 1.6
トラックバック:hornady 22 arc ammo
トラックバック:click for more,
トラックバック:myprin92.ru
トラックバック:Independence day images proud to be an indian
トラックバック:sunglasses frameless armani
トラックバック:遠隔ローター
トラックバック:https://josueybccb.yomoblog.com/42044778/https-sethpyfkn-blogsumer-com-34512957-https-puppies-yoga-com-products-pups-yoga-boston-leather-district-options-for-dummies
トラックバック:tcas
トラックバック:Cómo Limpiar los Cristales de tu Hogar para un Acabado Sin Marcas – Chusmeando: Descubriendo cosas que quizás no sabías
トラックバック:appetite Suppressant keto Flow
トラックバック:find out this here
トラックバック:coloksgp
トラックバック:domino88
トラックバック:mp3juice
トラックバック:veganism and self development
トラックバック:Highlighter in UAE
トラックバック:zlibrary
トラックバック:Mach S Jet Booking
トラックバック:Избежание осложнений
トラックバック:How To Start A Franchise Business
トラックバック:We meet on xvidoes
トラックバック:guy
トラックバック:Tłumaczenia polsko-niderlandzkie
トラックバック:Get the facts
トラックバック:Taruhan Online
トラックバック:sex động vật
トラックバック:ROGTOTO
トラックバック:read more on wisebusiness.click`s official blog
トラックバック:female escorts in sheffield
トラックバック:Trade 350 App のレビュー
トラックバック:bunion 4th toe
トラックバック:bokep sub indo
トラックバック:kubet casino scam money
トラックバック:Клиническое удаление бородавок
トラックバック:jabletv.ru
トラックバック:ArbiVise
トラックバック:fortune tiger
トラックバック:deep intimacy
トラックバック:CanFirst Crypto
トラックバック:Veltrix AI Pro
トラックバック:кракен сайт зеркало рабочее
トラックバック:home loan
トラックバック:Mobile Massage Near You
トラックバック:ekzistenczialnyj
トラックバック:Rocket Jets
トラックバック:jogo do tigrinho
トラックバック:tigrinho demo
トラックバック:лазертаг tager симферополь
トラックバック:лазертаг в парке
トラックバック:лазертаг крымский
トラックバック:стрельба лазертаг
トラックバック:Джеттон выплаты
トラックバック:Gorgeous Jet Reserve
トラックバック:Www.Locking-Stumps.Co.uk
トラックバック:лазертаг крым
トラックバック:лазертаг на крылова симферополь
トラックバック:Celebrity Jet Bookings
トラックバック:Recruitment Company in Saudi Arabia
トラックバック:Trustworthy Jet Booking
トラックバック:WertoniaX
トラックバック:aviator demo
トラックバック:jogo do tigrinho demo
トラックバック:tigrinho
トラックバック:Causal Ego
トラックバック:battery bat
トラックバック:aviator betway
トラックバック:Yupoo Dior
トラックバック:penipu bokep
トラックバック:cannabinoïdes
トラックバック:VIP Jets Reserve
トラックバック:effets du CBD
トラックバック:tyre fitting at Home birmingham
トラックバック:Sbobet Indonesia
トラックバック:Hire Real Call Girls Meet Call Girl
トラックバック:Yupoo Balenciaga
トラックバック:betlist
トラックバック:game slot terpercaya
トラックバック:slot pgsoft hari ini
トラックバック:slot berkualitas
トラックバック:support link
トラックバック:slot tanpa deposit
トラックバック:Prank Site
トラックバック:dmozbookmark.com
トラックバック:hentai
トラックバック:Bit GPT AI
トラックバック:tes RTP slot
トラックバック:หวยฮานอยวันนี้
トラックバック:résine de chanvre
トラックバック:Headhunting in Qatar
トラックバック:erzincan eskort
トラックバック:http://www.annunciogratis.net/author/dustyroundt
トラックバック:Крем резиденциясында брондау
トラックバック:Yupoo LV
トラックバック:carbon monoxide detectors
トラックバック:balenciaga le cagole outfit
トラックバック:Freelance Jobs
トラックバック:cbd
トラックバック:Child Porn
トラックバック:Bakara
トラックバック:Bookmaker
トラックバック:High Stakes
トラックバック:Poker
トラックバック:tigrinho app
トラックバック:مخدة
トラックバック:Dice Games
トラックバック:Tłumaczenia przysięgłe dokumentów holenderskich na niderlandzki.online
トラックバック:Wagering
トラックバック:imp source
トラックバック:Когда удалять бородавки
トラックバック:does acne studios make good shoes
トラックバック:Лаеннек восстанавливает пигмент
トラックバック:https://www.jerseydoesntshrink.com/users/hair.transplant
トラックバック:https://banyakhoki.xyz
トラックバック:эвакуатор недорого
トラックバック:эвакуатор дешево
トラックバック:phim sex mới
トラックバック:pornhub video download
トラックバック:Lottery
トラックバック:z-library
トラックバック:https://ashwoodvalleywiki.com/index.php?title=User:HymanFindlay
トラックバック:MEnera
トラックバック:https://wiki.internzone.net/index.php?title=Benutzer:JoshHylton8078
トラックバック:Privateproxies.top
トラックバック:Vanado Trade
トラックバック:web page
トラックバック:адвокат по военным делам
トラックバック:военный юрист онлайн
トラックバック:Placement in Qatar
トラックバック:Slot Murah Deposit
トラックバック:ВПЧ у мужчин
トラックバック:Darkweb
トラックバック:юрист по военным делам
トラックバック:betlist giriş
トラックバック:algolinkers
トラックバック:DMT (Cartridge and Battery) .5mL Deadhead Chemist
トラックバック:Slot-Machines
トラックバック:32Win
トラックバック:sefan-services.co.uk/
トラックバック:Gaming
トラックバック:Paito HK Paito Warna HK
トラックバック:обязательный аудит Минск
トラックバック:Evex Pro
トラックバック:lv hat and scarf yupoo
トラックバック:Rockwood wall configurations
トラックバック:ArbiQuant
トラックバック:Вирус папилломы что это такое
トラックバック:Blazepeak Reaction
トラックバック:Executive Search in Dubai
トラックバック:free seo consultation
トラックバック:luxury car rental Kuala lumpur
トラックバック:black gay porn sex video – trans lesbian porn
トラックバック:xhamster video 18+
トラックバック:teasingtouch
トラックバック:xvideos sex gay
トラックバック:Creativeideas
トラックバック:game slot
トラックバック:buy Telegram members
トラックバック:Bookmarks
トラックバック:Mẫu xây nhà đẹp
トラックバック:kontol semut
トラックバック:central coast builders renovations
トラックバック:인도카마그라
トラックバック:unitedko
トラックバック:car themed Shirts
トラックバック:Concrete Contractors Houston Texas
トラックバック:Specialoffer
トラックバック:домашние средства от акне
トラックバック:window cleaning toronto
トラックバック:Houston Concrete Contractors
トラックバック:maillot manchester city bleu
トラックバック:bokep afrika
トラックバック:https://www.vapepossible.com/mums-elixir-–-nectar-–-60ml-0mg
トラックバック:https://www.vapepossible.com/lemon-twist-e-liquids-–-iced-pink-punch-–-120ml-3mg
トラックバック:Eternal Lunesta
トラックバック:https://www.vaporpresent.com/aspire-x-sunbox-mixx-mod
トラックバック:сходить на экскурсию казани
トラックバック:Private proxies cheap price
トラックバック:equipacion tottenham 2025
トラックバック:aliexpress promo code
トラックバック:software development
トラックバック:koko288
トラックバック:Ufabet
トラックバック:slot gratis tanpa deposit
トラックバック:slot rtp tinggi
トラックバック:Sensitive Scalp Shampoo
トラックバック:opaltogel
トラックバック:hot
トラックバック:NexironTrader Flex
トラックバック:zlivrary
トラックバック:ganja
トラックバック:rhino88
トラックバック:buy haloperidol near me
トラックバック:Get Seeds Right Here|getseedsrighthere.com|getseedsrighthere|GSRH|GetSeedsRightHere|www.getseedsrighthere.com
トラックバック:chaqueta manchester united
トラックバック:sex vn học sinh
トラックバック:new online casinos nz
トラックバック:San Francisco police make an arrest in hit-and-run case involving a child
トラックバック:z-library official
トラックバック:instagram profile credibility
トラックバック:link tiger78
トラックバック:Buy Telegram Subscribers
トラックバック:online gambling australia
トラックバック:해운대다이어트한약
トラックバック:virat kohli instagram followers
トラックバック:reddit downvotes
トラックバック:slot pgsoft hari ini
トラックバック:Luigi pens
トラックバック:Yupoo Chanel
トラックバック:buy casino script online
トラックバック:Smokeless Powders
トラックバック:Raz Vapes
トラックバック:fda approved collagen powder
トラックバック:car portable ramps
トラックバック:sex nhật bản
トラックバック:telegram profile link
トラックバック:التوعية بالأمن السيبراني,
トラックバック:Assetz Mizumi Reserve
トラックバック:latest operating system for windows
トラックバック:drink Decals
トラックバック:cassino pix
トラックバック:gum dropz strain
トラックバック:ace ultra premium
トラックバック:website here
トラックバック:phim sex thần thoại
トラックバック:detik365 Slot
トラックバック:Micro Bar Vape Disposable
トラックバック:polymer 80 glock 19 frame
トラックバック:Чувствительная кожа
トラックバック:Owl Sosi
トラックバック:Hepato Burn Reviews
トラックバック:Jybla Price
トラックバック:list.ly
トラックバック:Streets is cooking new album films by Marcello Red on all tv music streaming new album from Memphis bleek tune in
トラックバック:Designerkitchen
トラックバック:hocspa
トラックバック:Mentorship
トラックバック:akses slot online terpercaya
トラックバック:Гипергидроз и лекарства от потливости
トラックバック:www.plurk.com
トラックバック:best online slots
トラックバック:newcastle home kit 2025 26
トラックバック:<< 初期画面に戻る
トラックバック:masochist
トラックバック:wiki z-library,
トラックバック:altcoin crash
トラックバック:Best Casino Payout
トラックバック:GEMAR4D
トラックバック:[T1b Secondary]
トラックバック:maillot osasuna
トラックバック:Raffi777 slot
トラックバック:site visit
トラックバック:here
トラックバック:window cleaner richmond hill
トラックバック:shop hoa
トラックバック:https://www.protopage.com/audianjuhv
トラックバック:dewijoker
トラックバック:Уход после ботокса ресниц
トラックバック:TMJ
トラックバック:Experiencedcontractors
トラックバック:Philmont preparation materials
トラックバック:Сборка компьютера
トラックバック:adjust text size
トラックバック:비아그라 파는곳
トラックバック:tiktok analytics
トラックバック:visabot
トラックバック:transportation from punta cana airport to majestic elegance
トラックバック:bet365
トラックバック:rv rental
トラックバック:Best Casino USA
トラックバック:snow removal etobicoke
トラックバック:window cleaning ajax
トラックバック:boost TikTok visibility
トラックバック:sports bottle manufacturers
トラックバック:add profile photo Telegram
トラックバック:Velbray Nexus
トラックバック:Лучший уход за волосами
トラックバック:奇迹Musf一条龙开服
トラックバック:camera
トラックバック:Instant Exalgo 9X
トラックバック:gods unchained crypto news
トラックバック:taxi punta cana airport
トラックバック:crypto exchange washington state
トラックバック:https://mm99.black
トラックバック:https://89bet.blue
トラックバック:Olonixis
トラックバック:Immediate Edge
トラックバック:quan an lau
トラックバック:Bokep Anak Kecil
トラックバック:Aumenta Liora
トラックバック:Top Casino In UK
トラックバック:Conheça o SBO2U
トラックバック:Beravestex
トラックバック:orgazm po
トラックバック:xxx việt nam không che
トラックバック:jwh-018
トラックバック:Be5 Sports
トラックバック:Astro Myrion
トラックバック:caluanie muelear oxidize for sale
トラックバック:psikhologvyalte.ru
トラックバック:ghost gun shop
トラックバック:solusi dari SahabatApp
トラックバック:z-library italy
トラックバック:update name
トラックバック:strona
トラックバック:bolapremium
トラックバック:thu âm cưới
トラックバック:Picture in Picture
トラックバック:daftar slot play303 penipu
トラックバック:just the worst tkts
トラックバック:coliseum adult entertainment
トラックバック:brevetto traduzione inglese
トラックバック:forward messages
トラックバック:igtoto daftar
トラックバック:xrp altcoin defi finance price prediction
トラックバック:crypto miner tycoon paga
トラックバック:Britannia AI
トラックバック:crypto miner tycoon mod apk
トラックバック:best arbitrage crypto exchanges
トラックバック:malware scan
トラックバック:microstrategy bitcoin dividend saylor prediction
トラックバック:projector dealers in hyderabad
トラックバック:Вакцинация ВПЧ
トラックバック:download bokep indo
トラックバック:stripchat bokep indo
トラックバック:janjiqq daftar
トラックバック:key4d daftar
トラックバック:spinslot77 daftar
トラックバック:88halo login
トラックバック:rokokbet
トラックバック:pistol77 daftar
トラックバック:halo69 daftar
トラックバック:kekar4d daftar
トラックバック:uang777
トラックバック:musangslot login
トラックバック:tiara777
トラックバック:topcer33 login
トラックバック:dwslot88 daftar
トラックバック:mafia88 login
トラックバック:slotbet99 login
トラックバック:qqkik daftar
トラックバック:alpaslot88 login
トラックバック:hoki48 daftar
トラックバック:indo4d daftar
トラックバック:beri88 login
トラックバック:juraganslot
トラックバック:hobitoto123 login
トラックバック:LuviriXar
トラックバック:cuanjp login
トラックバック:plaza4d login
トラックバック:jet234 login
トラックバック:heroslot77 daftar
トラックバック:nasa4d login
トラックバック:pick4d daftar
トラックバック:daya4d
トラックバック:gbo338
トラックバック:dominopoker login
トラックバック:pargoy888 daftar
トラックバック:harta33 login
トラックバック:shibagacor
トラックバック:4dwlatoto login
トラックバック:wawaslot
トラックバック:panda77 daftar
トラックバック:analisaslot login
トラックバック:Descriptive research
トラックバック:Zen Sosi
トラックバック:wangsa88
トラックバック:piggyslot
トラックバック:dana87 daftar
トラックバック:divaslot777 daftar
トラックバック:jebolslot login
トラックバック:sbc4d daftar
トラックバック:dajjaltoto
トラックバック:Tesoro Ledira
トラックバック:Teslergenesis
トラックバック:slobola88 login
トラックバック:toto99 login
トラックバック:Free Spins Tips
トラックバック:super4dtoto daftar
トラックバック:olislot daftar
トラックバック:livejudi login
トラックバック:frespin123 daftar
トラックバック:serasi189 login
トラックバック:calonwd login
トラックバック:toto4d daftar
トラックバック:jkt303 daftar
トラックバック:Бородавки клинические рекомендации
トラックバック:dressing up for chinese new year
トラックバック:aesthetic clinic singapore
トラックバック:Чистотел для удаления
トラックバック:정품 비아그라
トラックバック:https://git.fuwafuwa.moe/heliumradio6
トラックバック:https://myles6238w.iyublog.com/34880919/pine-essential-oil-wholesale-in-vietnam
トラックバック:Tumbler factory
トラックバック:66man.com
トラックバック:electronic cigarettes
トラックバック:파워맨사이트
トラックバック:telegram internal storage
トラックバック:madutogel
トラックバック:phim sex việt nam chồng trẻ
トラックバック:Slot uang asli
トラックバック:オナホ 高級
トラックバック:Slot dengan RTP terbaik
トラックバック:bosstoto88 daftar
トラックバック:build instagram brand
トラックバック:Richezixs
トラックバック:telegram earning methods
トラックバック:Купить российский паспорт
トラックバック:new telegram update
トラックバック:megaplay777 login
トラックバック:grow on tiktok
トラックバック:instagram likes guide
トラックバック:thrku
トラックバック:psycholog-korotkov.ru
トラックバック:Плацентарная терапия
トラックバック:Бородавка у кутикулы
トラックバック:woowoo therapy
トラックバック:professorkorotkov.ru
トラックバック:sms bomber usa
トラックバック:Удаление волос
トラックバック:sex
トラックバック:urabet login
トラックバック:toto21
トラックバック:bandit4d login
トラックバック:Opulatrix
トラックバック:Auto Profit Hub
トラックバック:Бородавка около ногтя на руке
トラックバック:dewi288
トラックバック:Qinux BrizaAC
トラックバック:Aivora Trade
トラックバック:datamacau5d login
トラックバック:caloslot login
トラックバック:ayam4d login
トラックバック:global fashion halal standard
トラックバック:Switch Evex Sys
トラックバック:vapeprodukt
トラックバック:ИИ для айтишников
トラックバック:ItalbitMax
トラックバック:telegram channel guide
トラックバック:best bitcoin casinos
トラックバック:Yoga for pregnant women
トラックバック:Link Slot Kaptenasia
トラックバック:slot gacor kaptenasia
トラックバック:30-day instagram plan
トラックバック:4djowo login
トラックバック:Piping Stress Engineer
トラックバック:parada
トラックバック:AI Chrysalis 1000
トラックバック:how to grow Telegram channel
トラックバック:Calories
トラックバック:Discount Vapes Online
トラックバック:twinsbet casino
トラックバック:daname bonasa voren sotelir
トラックバック:apibet login
トラックバック:kasih777
トラックバック:https://threeno.creatorlink.net/
トラックバック:ens hikaye oku
トラックバック:Подногтевая бородавка удаление
トラックバック:piping stress analysis Company
トラックバック:sex sıtelerı
トラックバック:sexs ize
トラックバック:zeus38 daftar
トラックバック:Какие родинки нельзя удалять
トラックバック:olgun sexsi
トラックバック:Питание кожи
トラックバック:Стоит ли удалять родинки
トラックバック:olatoto daftar
トラックバック:snb303
トラックバック:sexs muhabbeti
トラックバック:semangka188 login
トラックバック:blacksprut вход
トラックバック:olgun hikaye
トラックバック:блэкспрут не работает
トラックバック:Türk İfşa
トラックバック:https://www.anya-voyance.com/qui-suis-je-v1/
トラックバック:wokeness mushroom
トラックバック:nagawin189 login
トラックバック:https://wikigranny.com/wiki/index.php/User:TaniaCounts01
トラックバック:igtoto
トラックバック:Как понять что бородавка удалена
トラックバック:Яблочный уксус против бородавок
トラックバック:Корень бородавки фото
トラックバック:https://uaecareerhub.com/employer/ekafe/
トラックバック:World of Tanks Blitz cheats generator online
トラックバック:Ювелирный магазин
トラックバック:u31
トラックバック:analisslot daftar
トラックバック:Ganoex Nodeon
トラックバック:HI88
トラックバック:shrooms for sale
トラックバック:slot kaptenasia
トラックバック:josue82v29.idblogz.com
トラックバック:Real Racing 3 cheats generator online
トラックバック:RAID Shadow Legends cheats diamonds
トラックバック:Как удаляют бородавки
トラックバック:mpo505 login
トラックバック:установка камер видеонаблюдения
トラックバック:Angry Birds 2 cheats generator online
トラックバック:Dragon Storm hack generator online
トラックバック:Как заживает подошвенная бородавка
トラックバック:interqq
トラックバック:Кремы от розацеа
トラックバック:maillot valence fc
トラックバック:till the end of time
トラックバック:Как избавиться от бородавки
トラックバック:สล็อต pg
トラックバック:pics of eric king king world news
トラックバック:School Of Dragons hack proof
トラックバック:Puzzles and Survival hack generator online
トラックバック:Drakensang Online hack proof
トラックバック:Nutrition
トラックバック:Vinyasa yoga
トラックバック:Nexiorein
トラックバック:link slot cuan
トラックバック:demo slot pgsoft
トラックバック:royalwinvip daftar
トラックバック:cici4d daftar
トラックバック:angka4d login
トラックバック:magicslot login
トラックバック:pptoto login
トラックバック:slot88 daftar
トラックバック:maxwin spam
トラックバック:jet77 login
トラックバック:laga88 daftar
トラックバック:boost cuan harian
トラックバック:hiu4d
トラックバック:Timothy hay wholesale supplier
トラックバック:slot gratis
トラックバック:joker365 daftar
トラックバック:Recruitment in Saudi Arabia
トラックバック:pstore
トラックバック:yupoo
トラックバック:spin cuan
トラックバック:ufabet ทางเข้า ล่าสุด
トラックバック:asia77
トラックバック:Yupoo Fendi
トラックバック:centraltoto
トラックバック:nene4d login
トラックバック:maha333 daftar
トラックバック:hallo88 daftar
トラックバック:pragmatic777 daftar
トラックバック:pria4d login
トラックバック:rajasloto daftar
トラックバック:atm123 login
トラックバック:Средство для удаления бородавок
トラックバック:qqnuaa daftar
トラックバック:sogoslot login
トラックバック:ligareceh daftar
トラックバック:asg9
トラックバック:permen138 daftar
トラックバック:m98
トラックバック:babehtoto login
トラックバック:maniac123 daftar
トラックバック:ip88
トラックバック:sky77 daftar
トラックバック:mulaiqq
トラックバック:senopatibola daftar
トラックバック:angkanet4d daftar
トラックバック:tikus4d login
トラックバック:parley88 daftar
トラックバック:guci777 daftar
トラックバック:tiktok for beginners
トラックバック:castelototo login
トラックバック:slot spam
トラックバック:telegram bot tutorial
トラックバック:cuan cepat
トラックバック:mywin138
トラックバック:zeus007 daftar
トラックバック:http://link.xuehui.com
トラックバック:http://D8.9.Adl@forum.annecy-outdoor.com/suivi_forum/?a[]=match44 id
トラックバック:lapak33 daftar
トラックバック:glowin88 login
トラックバック:satta gali result
トラックバック:child abuse video
トラックバック:asikslot login
トラックバック:boost backlink
トラックバック:game slot boost
トラックバック:auto indexing
トラックバック:click through the next website page
トラックバック:188togel daftar
トラックバック:garudabet77 login
トラックバック:tante4d daftar
トラックバック:Prawo jazdy Targówek
トラックバック:rgo365 login
トラックバック:situs slot deposit 1000
トラックバック:https://cricbet99.diy/
トラックバック:computer assisted coding software
トラックバック:Supine Yoga
トラックバック:max77 login
トラックバック:Dragon Mania Legends hack generator online
トラックバック:judi888 login
トラックバック:부산크라이오테라피
トラックバック:Family Island cheats 2024
トラックバック:Harry Potter Hogwarts Mystery cheats 2024
トラックバック:emasslot daftar
トラックバック:airbet88 daftar
トラックバック:экскурсии в свияжск
トラックバック:garasitogel daftar
トラックバック:Empires And Puzzles hack diamonds
トラックバック:Lords Mobile hack 2024
トラックバック:family activities Old Montreal
トラックバック:surya77 login
トラックバック:вич новости мира
トラックバック:ттк не работает интернет
トラックバック:https://stringi.waw.pl
トラックバック:jurutogel daftar
トラックバック:gooncloud.click`s statement on its official blog
トラックバック:грех ли играть в компьютерные игры
トラックバック:slotonfire
トラックバック:Lentrix Flow
トラックバック:text based computer games from the 80s
トラックバック:PulseChain
トラックバック:onestepwin daftar
トラックバック:Young Hadene
トラックバック:vbslot88 daftar
トラックバック:bola369 login
トラックバック:psychoacoustics in gaming
トラックバック:info freebet
トラックバック:garuda138 login
トラックバック:أبحاث علمية
トラックバック:gasslot138 login
トラックバック:galaksitoto
トラックバック:mitolyn capsules
トラックバック:angkasa138 daftar
トラックバック:ทางเข้า m98 มือถือ
トラックバック:https://haesunkorea.com/
トラックバック:Diyarbakirescort.com
トラックバック:91 club
トラックバック:captain77 login
トラックバック:bandarqq228 daftar
トラックバック:Uñas Brillantes y Espectaculares
トラックバック:www.protopage.com
トラックバック:beautiful flower of the world
トラックバック:Mantap168
トラックバック:последние новости с чемпионата мира по шахматам
トラックバック:강남가라오케
トラックバック:رياضيات
トラックバック:Омоложение
トラックバック:telegram message scheduler
トラックバック:Knock Off Kelly Clearance Bag Replicahermesbags
トラックバック:schilderdienst limburg
トラックバック:Lotus365 app
トラックバック:gold365 com mahadev login password free
トラックバック:Bluewave Nexor
トラックバック:https://mchelp.xyz/index.php/19630/space-movers
トラックバック:Lotto Champ
トラックバック:https://xs.xylvip.com/home.php?mod=space&uid=3449853
トラックバック:Quietum Plus reviews
トラックバック:ميكانيك
トラックバック:Подтяжка овала лица
トラックバック:situs pepek
トラックバック:ahsoka tano lightsaber
トラックバック:Покраснение щёк
トラックバック:Virtualremodel
トラックバック:Розацеа лечение
トラックバック:sawit777
トラックバック:Cabinet de Recrutement
トラックバック:gut drops weight loss
トラックバック:คลิปโป๊
トラックバック:Розацеа в поездке
トラックバック:Эра смартфонов}
トラックバック:สล็อต
トラックバック:Outcall Massage Service Bangkok
トラックバック:Norell Bitcore
トラックバック:manusia otak kontol
トラックバック:groups
トラックバック:how to destroy website
トラックバック:keloid scars
トラックバック:rent a wedding car
トラックバック:kedai tayar near me
トラックバック:situsgacor88 daftar
トラックバック:Цифровой комфорт или тотальный контроль?
トラックバック:Buy Amphetamine Powder Online
トラックバック:Подошвенная бородавка лечение форум
トラックバック:best online casinos real money
トラックバック:Форум советы по бородавкам
トラックバック:Удалить папиллому в Москве
トラックバック:Altrops Trade
トラックバック:secondary math tuition for advanced students
トラックバック:physics and maths tutor logarithms
トラックバック:ufa
トラックバック:Green Glucose Reviews
トラックバック:Папиллома на веке удаление лазером
トラックバック:ministryofenkindled.com
トラックバック:ip math tuition bukit timah
トラックバック:GlucoBerry Reviews
トラックバック:useful reference
トラックバック:Red Boost Reviews
トラックバック:U888
トラックバック:Audifort Reviews
トラックバック:влияние ИИ на IT-профессии
トラックバック:stasiunhoki login
トラックバック:Kelly danse 2020 Sale
トラックバック:Turbo Imovax Fin
トラックバック:https://89bet.black
トラックバック:https://kbet.blue
トラックバック:طب بشري
トラックバック:Удаление папилломы на верхнем веке отзывы
トラックバック:Hindi Sex
トラックバック:https://32win.blue
トラックバック:Удаление папиллом на веке отзывы
トラックバック:Geld Ryvox
トラックバック:Удаление папиллом цены
トラックバック:مشاهده استعلام
トラックバック:RR88
トラックバック:kra34.cc
トラックバック:ИИ в законе: что говорит Фемида?
トラックバック:bayan Eskort diyarbakır
トラックバック:juntosbet
トラックバック:xhamster
トラックバック:789F
トラックバック:98Win
トラックバック:MMlive
トラックバック:https://www.google.co.cr/url?q=https://www.easyfie.com/screenharp2/profile
トラックバック:SFDC meaning a deep dive into what sfdc is
トラックバック:XOSO66
トラックバック:TD commercial
トラックバック:best crypto casinos
トラックバック:Syair Macau
トラックバック:789P
トラックバック:Call Girls in Lahore
トラックバック:luxeinteriors
トラックバック:99Win
トラックバック:Tailoredservice
トラックバック:Goplayslots.net
トラックバック:OK9
トラックバック:Data SDY Lotto
トラックバック:Data HK
トラックバック:https://yeonsu-dong3no.com/
トラックバック:Data China
トラックバック:from the walls-bernard-2.blogbright.net blog
トラックバック:Data Macau 4D
トラックバック:hedgedoc.k8s.eonerc.rwth-aachen.de
トラックバック:Kubet
トラックバック:8KBET
トラックバック:QQ88
トラックバック:888B
トラックバック:Jll property expo
トラックバック:http://taikwu.com.tw/
トラックバック:sime Darby math tuition
トラックバック:Yupoo Gucci
トラックバック:психология парней подростков в отношениях
トラックバック:harus777
トラックバック:https://penzu.com/p/be87336a20b9e174
トラックバック:TP88
トラックバック:J88
トラックバック:m.jingdexian.com
トラックバック:Frog Pose In Yoga
トラックバック:raja01
トラックバック:GK88
トラックバック:AEV99
トラックバック:Bocoran Jitu
トラックバック:WW88
トラックバック:cz binance art
トラックバック:PrimeQuant
トラックバック:situs porno
トラックバック:88vv
トラックバック:news about travel ban
トラックバック:video mesum
トラックバック:gama
トラックバック:https://www.vaporpresent.com/honeydewcumber-by-lout-e-liquids-100ml
トラックバック:DAGA88
トラックバック:Какой врач удаляет родинки
トラックバック:road chicken
トラックバック:Major Model Management
トラックバック:После ботокса болит голова
トラックバック:Aurum Fix
トラックバック:Чистотел от бородавок
トラックバック:база форумов xrumer
トラックバック:Live Draw HK Lotto
トラックバック:Buildquality
トラックバック:mature teen porn – adult xxx video hot porn site
トラックバック:ubur2 ikan lele
トラックバック:общаться с психологом онлайн
トラックバック:fiocchi 200 grain hyperformance 44 magnum ammo peoria il. Aira
トラックバック:Bul Armory SAS II Pistol Cerakoted using Graphite Black
トラックバック:blitzkrieg tactical ambi safety
トラックバック:betonred
トラックバック:Founderscribe.com
トラックバック:no limit casinos
トラックバック:К какому врачу идти с бородавкой
トラックバック:Yupoo Celine
トラックバック:DiyarbakıR Eskort
トラックバック:Data SGP 2025
トラックバック:Echo Wealth AI
トラックバック:Computer Repair Montreal
トラックバック:pink palmpuff store
トラックバック:fendi original bag price
トラックバック:how do i transfer software from one computer to another
トラックバック:микроавтобус для путешествий
トラックバック:Singapore Math Tuition
トラックバック:math Tutor dvd complete collection full download
トラックバック:odysseymathtuition.com
トラックバック:xrumer warez download
トラックバック:tanya pada tetek
トラックバック:best online casinos australia
トラックバック:GRAVAT
トラックバック:daha fazla bilgi almak için
トラックバック:MAY88
トラックバック:https://bitspower.com/support/user/phmapaladnet
トラックバック:Live Draw HK
トラックバック:check my source
トラックバック:https://samuelm799rzs9.newbigblog.com/profile
トラックバック:minhh
トラックバック:drive.google.com
トラックバック:xhamster live free tokens
トラックバック:pragmatic play sourcecode
トラックバック:http://https%evolv.E.L.U.pc@haedongacademy.org/
トラックバック:GBP ranking service
トラックバック:https://Drive.google.com/drive/folders/145HvWgd5wpCQrK3RFJshEBbvYDdzNx9c
トラックバック:https%Evolv.e.l.U.pc@haedongacademy.org
トラックバック:best math tutor
トラックバック:best oxycodone reviews
トラックバック:solar cable
トラックバック:copper mesh cable
トラックバック:ross-art.su
トラックバック:wordle unlimited
トラックバック:math tuition singapore
トラックバック:link building services
トラックバック:Publ.Icwordtiredplan.E.S.J.A.D.E.D.I.M.P.U@E.Xped.It.Io.N.Eg.D.G@Burton.Rene@Ehostingpoint.com
トラックバック:home tuition singapore math
トラックバック:Gold365 Exch
トラックバック:F.R.A.G.Ra.nc.E.rnmn@.R.os.P.E.r.les.c@pezedium.free.fr
トラックバック:Data China 2025
トラックバック:Папиллома это
トラックバック::/olv.Elupc@haedongacademy.org
トラックバック:slot777 login
トラックバック:math tutor with proven records
トラックバック:tutor at bedok for primary 6 maths and science
トラックバック:gold365 new id login
トラックバック:บทความอาหารสุขภาพ
トラックバック:okbeiu
トラックバック:debet
トラックバック:math teacher tuition
トラックバック:mhlzmas.com
トラックバック:PG99
トラックバック:Https%Evolv.elupc@haedongacademy.org
トラックバック:lotus365 kya hota hai
トラックバック:apna Gold365 customer care number
トラックバック:jobs that pay daily
トラックバック:American sign language
トラックバック:es.visitandcare.com
トラックバック:tech news blog
トラックバック:earn online
トラックバック:turner’s outdoorsman weekly ad
トラックバック:a789a3
トラックバック:hannne
トラックバック:plastic coated wire
トラックバック:Instant Bitcoin doubling service
トラックバック:49jili
トラックバック:viewer count
トラックバック:789WIN
トラックバック:nsfw ai generator free
トラックバック:토닥이
トラックバック:부산한의원
トラックバック:Www.Gongye360.com
トラックバック:espresso machines reviews
トラックバック:tiktok
トラックバック:carbofix belly fat activation fatvim
トラックバック:people on tiktok
トラックバック:sötaste hunden
トラックバック:web development
トラックバック:electric control cable
トラックバック:https://heylink.me/jilibet888net/
トラックバック:GBP Marketing
トラックバック:visit Game-Era.Do.am now >>>
トラックバック:Minimalism
トラックバック:setup predictive dialer
トラックバック:book tracks
トラックバック:игры детства компьютерные
トラックバック:kmspico
トラックバック:update
トラックバック:enfejar baz
トラックバック:Venoplus 8 reviews
トラックバック:философия красоты и здоровья лаборатория
トラックバック:https://wiki.digitalcare.noho.st/index.php?title=Autorent_25k
トラックバック:a789ne
トラックバック:Sleep Lean reviews
トラックバック:Удаление бородавок и папиллом
トラックバック:thewayofspirit.click official website
トラックバック:trending news stories
トラックバック:Saigon Cable
トラックバック:DTS file compatibility
トラックバック:fire born
トラックバック:https://list.ly/jilibet888net/lists
トラックバック:Гипергидроз у подростков
トラックバック:Ботокс от пота
トラックバック:why not check here
トラックバック:Broker Abq
トラックバック:https://wisebusiness.click
トラックバック:entertainment
トラックバック:skincare routine options
トラックバック:phone casino login
トラックバック:abch
トラックバック:betseo
トラックバック:дублирующие педали на учебный автомобиль
トラックバック:win
トラックバック:best sweepstakes casinos
トラックバック:Upper
トラックバック:slot bisa bet kecil
トラックバック:motorcycle key locksmith
トラックバック:online casino buitenland
トラックバック:birkbeck university of london ranking
トラックバック:https://www.vaporopen.com/aspire-feedlink-revvo-starter-kit-–-silver
トラックバック:Ионофорез
トラックバック:deaf network
トラックバック:DSM file viewer
トラックバック:Russian escorts in Jaipur
トラックバック:daftar gratis dan mulai bermain
トラックバック:последние новости профессионального бокса в мире
トラックバック:sweetchoice.click
トラックバック:Australia
トラックバック:amee
トラックバック:Serendipity Paragon
トラックバック:dir proxy
トラックバック:Algo AI
トラックバック:low voltage armored power cable
トラックバック:okve
トラックバック:Goodfeel`s latest blog post
トラックバック:HUHR
トラックバック:Packaging Machine
トラックバック:toto99 login
トラックバック:My electric vehicle
トラックバック:dayd
トラックバック:一代工務店最悪欠陥住宅
トラックバック:Buy Gold with Bitcoin
トラックバック:real twitter followers
トラックバック:Awardwinning
トラックバック:math tutor singapore
トラックバック:telegram growth bot
トラックバック:сборка софта для windows 7
トラックバック:новости биатлона кубок мира
トラックバック:math tutor
トラックバック:online math tutoring jobs in the philippines
トラックバック:NexioRex
トラックバック:link slot gacor
トラックバック:Interesting Maths Teacher Home Tuition
トラックバック:primary 5 maths tuition
トラックバック:hotme
トラックバック:grow telegram channel
トラックバック:real tweet likes
トラックバック:biaer
トラックバック:viagra 100mg price
トラックバック:real telegram users
トラックバック:cheap twitter views
トラックバック:wisebusiness.click
トラックバック:товары для красоты и здоровья
トラックバック:web otak kontol
トラックバック:KING
トラックバック:متجر مخازن العناية
トラックバック:BUY Percocet 30mg
トラックバック:Fiverr call center gig
トラックバック:pepek sama kau
トラックバック:kontol bapak kau pecah
トラックバック:biji besar sebelah
トラックバック:RoyalWealth Platform
トラックバック:EFA file editor
トラックバック:colatvv.org lừa đảo người chơi công an cảnh báo
トラックバック:Face Swap AI
トラックバック:best math tutor in singapore
トラックバック:control cable
トラックバック:jc math tuition rates
トラックバック:Ботокс до и после фото
トラックバック:English Tuition Singapore
トラックバック:Visit Befine
トラックバック:slot untuk index
トラックバック:jimmy maths tuition
トラックバック:spin mama casino
トラックバック:bigade eternia
トラックバック:vvip
トラックバック:secondary math tutor 1a
トラックバック:Ботокс Рефайнекс
トラックバック:mommu
トラックバック:WEED
トラックバック:businessdaily.click officially announced
トラックバック:доставка продуктов в день заказа Иркутск
トラックバック:быстрая доставка овощей и фруктов Иркутск
トラックバック:DDT file editor
トラックバック:заказать продукты с доставкой Иркутск
トラックバック:zlibeary
トラックバック:digi 995 book series
トラックバック:Central IT
トラックバック:데코타일
トラックバック:Tigo Live daily bonus hack
トラックバック:Niğde Reklam Ajansları
トラックバック:Promotions Singapore
トラックバック:deneme bonusu veren siteler
トラックバック:A3K file online viewer
トラックバック:다미인한의원
トラックバック:phonr
トラックバック:sboagen
トラックバック:jadwal pertandingan bola hari ini
トラックバック:taruhan bola
トラックバック:saob
トラックバック:books about music
トラックバック:cetuximab
トラックバック:ramucirumab
トラックバック:man88 casino
トラックバック:setor 123
トラックバック:bevacizumab
トラックバック:hernoi
トラックバック:tarlatamab-dlle
トラックバック:golden star casino
トラックバック:Woodspock.com/__media__/js/netsoltrademark.php?d=p.r.os.p.e.r.les.c@pezedium.free.fr
トラックバック:Http://F.R.A.G.Ra.Nc.E.Rnmn@.R.Os.P.E.R.Les.C@Pezedium.Free.Fr/?A[]=Mahadev Book Gold365 Login Password
トラックバック:yupoo to pandabuy link
トラックバック:ProxenIQ
トラックバック:gold365 is real or fake
トラックバック:maths tuition teacher jobs in chennai
トラックバック:Play Casino Roulette
トラックバック:Casino European
トラックバック:Casino France
トラックバック:app lotus365 app
トラックバック:Lucky Star Casino
トラックバック:No Deposit Casino
トラックバック:alohaha
トラックバック:https://www.intensedebate.com/profiles/jiliorgph
トラックバック:Turbo Flomax 500
トラックバック:Starbucks Casino
トラックバック:ib maths tuition in mumbai
トラックバック:h2 math private tutor price
トラックバック:YariXfin
トラックバック:Us Casino No Deposit
トラックバック:google play store app
トラックバック:primary math tuition centre singapore
トラックバック:main slot demo
トラックバック:kiasu parents secondary math tuition
トラックバック:the one book
トラックバック:telegram bot
トラックバック:torrent math tutor dvd mastering statistics volume 7
トラックバック:bucaspor haberler
トラックバック:onefinething.click
トラックバック:19dewa
トラックバック:kiute
トラックバック:auto engagement bot
トラックバック:Slotcasinos Casino Bonuses
トラックバック:nhuhy
トラックバック:is high.achiever math tuition good mindstretcher
トラックバック:h2 maths tuition at yishun
トラックバック:padel5000
トラックバック:nonton bola
トラックバック:iconwin
トラックバック:math tutor dvd complete collection free download
トラックバック:content performance
トラックバック:https://www.chijstnicholasgirls.moe.edu.sg
トラックバック:verizon business login
トラックバック:cbse 10th maths tuition new thippasandra
トラックバック:math tutor amsterdam
トラックバック:Www.deyisec.moe.edu.sg
トラックバック:physics and maths tutor chemistry past papers
トラックバック:singapore math tutors nyc
トラックバック:www.queenstownsec.moe.edu.sg
トラックバック:Guide
トラックバック:https://www.symbaloo.com
トラックバック:009bet
トラックバック:hTMlweB.ru
トラックバック:zborakul01
トラックバック:verizon
トラックバック:maths hub tuition centre singapore
トラックバック:automatic views bot
トラックバック:AquaSculpt
トラックバック:single wire electric
トラックバック:Cabinetry
トラックバック:jason lau maths tuition
トラックバック:physics and maths tutor igcse chemistry
トラックバック:zorototo
トラックバック:https://Sitereport.Netcraft.com/?url=http://silichem.co.kr
トラックバック:Categorify.org
トラックバック:rnuo
トラックバック:chemistry tutor maths and physics
トラックバック:mystic labs delta 8 gummies
トラックバック:real money online casinos
トラックバック:spell book spells
トラックバック:ib maths tuition mumbai
トラックバック:http://vash.Boy.jp/kuroneko/?wptouch_switch=desktop&redirect=httpsBlogs.Koreaportal.combbsboard.phpbo_tablefreewr_id5409019
トラックバック:CAFe5.winNeN.CO.kr
トラックバック:physics and maths tutor a level physics
トラックバック:Domain.glass
トラックバック:window cleaning oakville
トラックバック:kiasu parents math tuition numberskill
トラックバック:maths tutor suspended after praising pupil
トラックバック:Capital Direct
トラックバック:maths & poa tuition
トラックバック:gifted math tuition
トラックバック:keyt
トラックバック:WealthWave
トラックバック:Gaia Capital
トラックバック:Firme Cointhor
トラックバック:TechNarix
トラックバック:math tuition
トラックバック:Creative
トラックバック:Peretti Bitvalor
トラックバック:btech maths tuition near me
トラックバック:где взять промокоды Shopping Live
トラックバック:air repair
トラックバック:https://www.nygh.edu.sg/
トラックバック:https://pacmandispo.com/product/buy-bulk-gen-3-packman-vapes/
トラックバック:Ib Math Tuition Mr Goh
トラックバック:math tutor dvd mastering statistics volume 7 torrent
トラックバック:mrs kumar maths tuition
トラックバック:https://match44.co.in/
トラックバック:lotus365s.co.in
トラックバック:padelhoki
トラックバック:Zarvionex
トラックバック:Turbo Iplex Hub
トラックバック:Immediate FastX
トラックバック:math tutor private kenneth
トラックバック:Tresor Coinvia
トラックバック:Nilornetux
トラックバック:Quantum Azopt
トラックバック:insta
トラックバック:singapore math tutor
トラックバック:Élan Syvor
トラックバック:Massage Near Me.
トラックバック:2 base de quinté demain
トラックバック:luxury138 login
トラックバック:luxury138 link alternatif
トラックバック:Noble Bitrow
トラックバック:1000pip Climber System Reviews
トラックバック:lykke криптовалюта
トラックバック:shield control cable
トラックバック:superslot777
トラックバック:audizen tinnitus relief
トラックバック:RexalFin
トラックバック:Wealth Window
トラックバック:xxx
トラックバック:Track Dexair Sys
トラックバック:by Naturespirit
トラックバック:Crownmark Dexlin
トラックバック:memory care tips
トラックバック:Quantum Incore
トラックバック:read more on Naturespirit`s official blog
トラックバック: PORN
トラックバック:Bit GPT App AI
トラックバック:ремонт компьютерам на дома
トラックバック:girg
トラックバック:EliteFxgo Review
トラックバック:Molterixal
トラックバック:คลิปหลุด มาใหม่
トラックバック:продвижение xrumer
トラックバック:ไม้แขวนเสื้อเคลือบซีลีโคนกันลื่น
トラックバック:low voltage power line
トラックバック:ipototo
トラックバック:lesbians masturbate
トラックバック:Escorts in Islamabad
トラックバック:دریافت کارت ورود به جلسه آزمون دبیری ۱۴۰۴
トラックバック:converting vhs to digital
トラックバック:convert vhs to digital
トラックバック:via wisebusiness.click
トラックバック:https://www.behance.net/greenhservice
トラックバック:Green Hands Cleaning Services Corp
トラックバック:Quantum Trust
トラックバック:sys криптовалюта
トラックバック:Quantalysus AI
トラックバック:link Jiso4D
トラックバック:new casino sites
トラックバック:best social casinos
トラックバック:Maple Shield
トラックバック:CorpaGenesis
トラックバック:https://Sitereport.Netcraft.com/?url=http://Seoulschool.org
トラックバック:Flash Burn Reviews
トラックバック:Trenqor Logic AI
トラックバック:как создать свою криптовалюту
トラックバック:small group maths tuition
トラックバック:secondary math and science tuition
トラックバック:cleaning service NYC
トラックバック:Tesoro Tradex
トラックバック:http://e-hp.info/mitsuike/4-bbs/bbs/m-123y.cgi?id=1&&post=792&details=0221&v=044
トラックバック:sec 1 maths tuition yishun
トラックバック:nitric boost ultra
トラックバック:دانلود آی گپ دانشگاه آزاد
トラックバック:math tutor jobs part time
トラックバック:a level maths tutor
トラックバック:دریافت کارت آزمون استخدام معلم ۱۴۰۴
トラックバック:Trade Master Biz
トラックバック:bsc maths tuition near me
トラックバック:контакторы
トラックバック:house cleaning service NYC
トラックバック:prozenith reviews
トラックバック:Saldo Bitrow
トラックバック:math jc tuition
トラックバック:math tuition agency sg
トラックバック:Innovative
トラックバック:audizen
トラックバック:www.holyinnocentshigh.moe.edu.sg
トラックバック:fringe-limburger-42f.notion.site
トラックバック:online math tutoring for elementary students
トラックバック:Quantum AI
トラックバック:Nerve Calm Reviews
トラックバック:QuantaviraAI
トラックバック:world news march 29 2025
トラックバック:Wisebusiness official website
トラックバック:agenpadel
トラックバック:Fitspresso Reviews
トラックバック:Instant Abil
トラックバック:Luntrixor
トラックバック:Track Dexair
トラックバック:online maths tutor vacancies
トラックバック:login toko123
トラックバック:NetherexPro
トラックバック:TradeVision
トラックバック:bet majic
トラックバック:Sultanslot96
トラックバック:bokep uncensored
トラックバック:beastforce pills
トラックバック:agenpadel24
トラックバック:gut drops with pumpkin seeds reviews
トラックバック:counseling
トラックバック:crypto hacking news
トラックバック:diamond engagement rings
トラックバック:Top-Rated Headphones shop
トラックバック:Headphones
トラックバック:wireless headphones uk
トラックバック:Buy Headset
トラックバック:https://buyheadphones90253.bloggerbags.com/40974327/what-is-Headphones-to-buy-And-how-to-use-it
トラックバック:Cost Of Headphones
トラックバック:Headphones Shop Reviews
トラックバック:Online Store Headphones
トラックバック:Bluetooth Headphones UK
トラックバック:Buyheadphones08403.59Bloggers.Com
トラックバック:Latest Headphones
トラックバック:DominionPeak
トラックバック:Headphones Price
トラックバック:Headphone UK
トラックバック:Where To Buy Earphones
トラックバック:Earphones UK
トラックバック:Best Social Media Management Tools
トラックバック:Https://Headphoneforsale77386.Bloguerosa.Com
トラックバック:slim jaro reviews and complaints
トラックバック:Immediate Tras 2.0
トラックバック:Houston slip and fall attorney
トラックバック:Bukti kemenangan Vitamin33
トラックバック:mouse click on sweetchoice.click
トラックバック:https://minskdiesel.by/
トラックバック:auto locksmiths
トラックバック:XalvexGain 4.7 Ai
トラックバック:دانلود بت مجیک
トラックバック:Buy Headphones UK
トラックバック:Aqua Tower
トラックバック:Gottit Tutor Math
トラックバック:Billionaire Brain Wave
トラックバック:Yupoo Burberry
トラックバック:Headset Price
トラックバック:аренда катера в казани цены
トラックバック:stylish headphones shop
トラックバック:shop hoa tươi ở bạc liêu
トラックバック:Head Phones
トラックバック:Buy Headphones Online UK
トラックバック:Online Headphones
トラックバック:Niğde Sosyal Medya Ajansı
トラックバック:permainan mix parlay
トラックバック:online headphone Store
トラックバック:Best Place To Buy Headphones
トラックバック:therapeutic properties
トラックバック:neurosurge
トラックバック:good maths tuition west sg
トラックバック:recommerce company
トラックバック:Headphone for Sale
トラックバック:دوربین هایک ویژن
トラックバック:buyheadphone61849.dreamyblogs.com
トラックバック:o level maths tuition fees
トラックバック:weekly world news bat boy
トラックバック:UK Headphones
トラックバック:neon signs
トラックバック:sugar defender
トラックバック:Headset For Sale
トラックバック:a math tuition centre
トラックバック:Headphones In UK
トラックバック:quite a few
トラックバック:https://Www.Moe.Gov.sg/
トラックバック:Yupoo Fendi
トラックバック:https://www.moe.gov.sg/schoolfinder/schooldetail?schoolname=pioneer-primary-school
トラックバック:varsity Tutors middle level math
トラックバック:torque converter for sale
トラックバック:viagra gas station
トラックバック:best maths tuition in gurgaon
トラックバック:math tutor dvd mastering statistics volume 1 5
トラックバック:rolet 303
トラックバック:rcof crypto news
トラックバック:chiee
トラックバック:ctx crypto news
トラックバック:torrent math tutor dvd mastering statistics volume 6
トラックバック:maths tuition assignments singapore
トラックバック:maths tuition teacher job
トラックバック:kevin lee maths tutor
トラックバック:Electric Nectar Collector
トラックバック:TD bank
トラックバック:maths tutor profile example
トラックバック:antiktoto maxwin
トラックバック:axbb.ru
トラックバック:twisted aluminum cable
トラックバック:new post from 9signal.click
トラックバック:pepek ajaib
トラックバック:low-maintenance gravel driveways
トラックバック:https://timeoftheworld.date/wiki/User:GitaJensen87
トラックバック:bokep mamak mu ngentot ama babi
トラックバック:u31 เข้าสู่ระบบ ล่าสุด
トラックバック:official hedgedoc.digillab.uni-augsburg.de blog
トラックバック:kontol babi
トラックバック:Sleep Lean
トラックバック:UYTYUYT
トラックバック:bandar123
トラックバック:ramatogel
トラックバック:Xbet Casino No Deposit Bonus Code
トラックバック:singapore math Tuition Agency
トラックバック:home math tuition punggol
トラックバック:13Win
トラックバック:Yabby Casino Deposit Bonus
トラックバック:hacked website help
トラックバック:aluminum core power cable
トラックバック:manual dialer expert
トラックバック:balmoral plaza math tuition
トラックバック:popboa
トラックバック:Real Money Casino No Deposit Bonus Codes
トラックバック:math tuition for ip students site www.kiasuparents.com
トラックバック:Sky Crown Casino
トラックバック:aqa physics and maths tutor
トラックバック:best math tuition centre in singapore for primary school
トラックバック:Sec 2 maths tutor
トラックバック:https://lovewiki.faith/wiki/Bezopasnost_9A
トラックバック:maths tuition near me class 12
トラックバック:handyman and contractor services in Mississauga
トラックバック:math tuition agency
トラックバック:Docs.Google.com
トラックバック:ib maths tutor in dubai
トラックバック:Royal Casino
トラックバック:https://www.nls.edu.sg
トラックバック:trash container cleaning service
トラックバック:Truereason officially announced
トラックバック:read this post from www.cap-rs485-imatek-nhap-khau.xyz
トラックバック:pmt physics and maths tutor practical cylinder clay
トラックバック:nasal spray
トラックバック:Frlorexiana
トラックバック:Trésor Fundrade
トラックバック:Krythonox Max
トラックバック:Fortel Fundex
トラックバック:mound of venus
トラックバック:Sulong Tradex
トラックバック:HashCash Pro
トラックバック:برنامه بتمجیک
トラックバック:solar water heater
トラックバック:http://ballandspringplungers.com/
トラックバック:ทางเข้าufabet
トラックバック:Lucenza Tradex
トラックバック:hiếp dâm
トラックバック:Casino South Africa
トラックバック:Casino With Best Payout
トラックバック:kitchen remodel companies near me
トラックバック:CapistaVest
トラックバック:QuantumLight
トラックバック:Immediate Fortune
トラックバック:beastforce enhancement
トラックバック:mobile garbage can cleaning
トラックバック:https://noakhalipedia.com/index.php/Asiancatalog_54e
トラックバック:https://shaderwiki.studiojaw.com/index.php?title=User:Landon7560
トラックバック:Forward lean
トラックバック:http://www.vloeimans.com/index.php?title=User:ZQXLucile5
トラックバック:Casino Site
トラックバック:https://angevinepromotions.com/asiancatalog-3r/
トラックバック:Casino Top 10
トラックバック:Canmark Flowdex
トラックバック:tonic greens
トラックバック:Plafonnier Design
トラックバック:big bass bonanza slot
トラックバック:huyhng
トラックバック:Drayton Bitline
トラックバック:cipla sildenafil
トラックバック:Arsolatex App
トラックバック:Oryvian Platform
トラックバック:okvip
トラックバック:spinmama belgium
トラックバック:best crypto exchange
トラックバック:Nexalybit
トラックバック:https://maps.google.com.ua/url?q=https://atavi.com/share/xbhrmlzu6s7m
トラックバック:Casino No Deposit Bonus No Kyc
トラックバック:mama spin
トラックバック:Hermes Bolide Handmade Bag Replica Hermes Bags
トラックバック:Lortopulix
トラックバック:Klarheit Fundex
トラックバック:Casino No Deposit Bonus Lcb
トラックバック:buy pbn links
トラックバック:ขายผักไฮโดรโปนิกส์
トラックバック:Boost Edex 400
トラックバック:plinko paga mesmo
トラックバック:Be5 Health
トラックバック:MOE Singapore
トラックバック:savaspin
トラックバック:visit hanson.net`s official website
トラックバック:купить виагру
トラックバック:Www.Corporationpri.Moe.Edu.sg
トラックバック:alternating current physics and maths tutor
トラックバック:buy btc online
トラックバック:pgaztec888thai.com
トラックバック:Porn Proxy
トラックバック:Crown Prince EA
トラックバック:fix outlook stuck issue
トラックバック:lovebookmark.win
トラックバック:gravel parking areas
トラックバック:Immediate ZenX
トラックバック:Codimd.Fiksel.Info
トラックバック:jc h2 maths tuition in khatib
トラックバック:spinmama casino
トラックバック:Casino No Deposit Free Bonus Norway
トラックバック:situs toto macau resmi
トラックバック:math tuition centre hiring
トラックバック:plinko argent réel
トラックバック:big bass casino
トラックバック:how to tutor young children math
トラックバック:spin mama
トラックバック:math tutor in the east
トラックバック:网络药店
トラックバック:seo consultant หมายถึง
トラックバック:podcast
トラックバック:How to Find Creative Sources of Business Funding
トラックバック:cuevana
トラックバック:Casino Play
トラックバック:mobile casino pay with phone
トラックバック:секс видео
トラックバック:casino ohne einschränkung
トラックバック:https://outgoing-Ghoul-8d0.notion.site
トラックバック:Vilnius Dental
トラックバック:Best Weight Loss Pills
トラックバック:https://kit.co/777pubio
トラックバック:SecuroomAi
トラックバック:Arbiquant AI
トラックバック:Floorplans
トラックバック:www.moe.gov.sg
トラックバック:إرسال العملات المشفرة إلى سوريا
トラックバック:anyone send k1 to math tuition
トラックバック:Varlık Paydex
トラックバック:sign up for British IPTV
トラックバック:explore IPTV UK options
トラックバック:premium IPTV plans in the UK
トラックバック:how to advertise for math tuition
トラックバック:British IPTV
トラックバック:взломать аккаунт
トラックバック:Secondary math olympiad private tutor
トラックバック:bokep landak
トラックバック:maths specialist tuition centre
トラックバック:a level maths physics tutor
トラックバック:Maths Tuition Teacher Jobs
トラックバック:Sovamnex App
トラックバック:torein
トラックバック:math tuition school singapore
トラックバック:this IPTV provider
トラックバック:X.AI Platform
トラックバック:Lucent Markbit
トラックバック:Switch Eurax Neo
トラックバック:Finotraze
トラックバック:volunteer math tutor online
トラックバック:Rogaine
トラックバック:kasyno spinmama
トラックバック:Best Casino New Jersey
トラックバック:Bet Casino
トラックバック:Best Casino Us Germany
トラックバック:maths tuition near bukit batok west ave 6
トラックバック:best maths tuition centre in chennai
トラックバック:plinko game online
トラックバック:spinmama casino login
トラックバック:a level maths tuition watford
トラックバック:protel
トラックバック:Best Casino Nz Germany
トラックバック:moe.gov.sg
トラックバック:maths home tuition
トラックバック:Slim Finlore
トラックバック:727 ang mo kio math tuition
トラックバック:MOE
トラックバック:http://addsub.wiki/
トラックバック:math tuition centres for ip math
トラックバック:Casino Grosvenor
トラックバック:personal math olympiad tutor singapore
トラックバック:Snipaste桌面版
トラックバック:lower secondary math tuition rates
トラックバック:spinmama opinie
トラックバック:spinmama official website
トラックバック:secondary 1 maths tuition ghim moh
トラックバック:gacor maxwin
トラックバック:Orvalentis App
トラックバック:infloggi
トラックバック:math olympiad tuition centre
トラックバック:Best Casino Texas
トラックバック:https://www.pageorama.com/?p=tga168
トラックバック:wikg
トラックバック:plinko app to win real money
トラックバック:Best Casino Poland
トラックバック:https://www.loyangviewsec.moe.edu.sg
トラックバック:Best Casino USA Germany
トラックバック:spin mama casino login
トラックバック:легально купить диплом
トラックバック:Shafaei likes service
トラックバック:instagram growth service
トラックバック:math academy tutoring
トラックバック:active telegram members
トラックバック:telegram reactions bot
トラックバック:https://www.moe.gov.sg
トラックバック:Quantum Bernard
トラックバック:shafaei
トラックバック:physics and maths tutor economics past papers
トラックバック:Shift Kapidex Lab
トラックバック:singapore maths home tutor
トラックバック:private math tutor o level
トラックバック:Best British Casino
トラックバック:Best Casino Alberta
トラックバック:Best Casino Canada
トラックバック:plinko cz
トラックバック:spinmama login
トラックバック:Best Casino Live Roulette
トラックバック:good maths tutor for primary school
トラックバック:Liver Revive
トラックバック:maths tuition jurong
トラックバック:Fastest way to lose weight
トラックバック:BosterCorexa
トラックバック:coronation plaza math tuition
トラックバック:Breathe Drops
トラックバック:johnny hardcore xxx pretty jasmine fuck porn
トラックバック:Primary 6 Maths Tuition Rate
トラックバック:wedding blog
トラックバック:main spin gratis
トラックバック:menovelle
トラックバック:math tuition agency singapore
トラックバック:best crypto to buy for 2025
トラックバック:免费色情影片 破解软件 裸聊网站 порно онлайн секс видео купить виагру взломать аккаунт биткойн инвестиции
トラックバック:buy twitter followers
トラックバック:p4 Maths tuition
トラックバック:spinmama
トラックバック:H2 Math Tuition Singapore
トラックバック:physics and maths tutor circular motion
トラックバック:คลิปหลุดนักเรียน
トラックバック:sec 3 ip math tuition
トラックバック:Best Casino Michigan
トラックバック:jc math tuition rate
トラックバック:cardiff locksmith
トラックバック:custom comments
トラックバック:physics and maths tutor a level physics questions by topic
トラックバック:additional math tutor teacher book
トラックバック:primary math education for tutors
トラックバック:GARRYS AI Trading Bot
トラックバック:Orion Gold Scalper EA
トラックバック:Fortel Fundexo
トラックバック:ProstaVive
トラックバック:Mizenterex
トラックバック:abc investissement
トラックバック:sec 3 a maths tuition
トラックバック:lovehumandesign.ru
トラックバック:Immediate Dirox
トラックバック:promo code 1xbet tajikistan
トラックバック:dizain cheloveka
トラックバック:Joint Genesis
トラックバック:in-depth Pusat4D site review
トラックバック:NovetraxioMax
トラックバック:Azione Kivo
トラックバック:add Math online tuition
トラックバック:Gluco Control
トラックバック:wsdsf
トラックバック:executive black car service
トラックバック:Zermixrent
トラックバック:qq
トラックバック:Giusto Itradex
トラックバック:code promo plinko
トラックバック:www.angsanapri.Moe.edu.sg
トラックバック:tuition for e maths o level
トラックバック:kraken36
トラックバック:отношения между людьми психология
トラックバック:slot auto ฟรีเครดิต
トラックバック:add math home tuition
トラックバック:Audifort
トラックバック:pasir ris math tuition
トラックバック:bet on red casino application
トラックバック:ice water hack
トラックバック:VitaRise Caps
トラックバック:daily job updates fiji
トラックバック:Pineal Activator
トラックバック:chanel bag multicolor
トラックバック:how much one on one tutor math primary
トラックバック:belt trailer loads
トラックバック:สล็อตเดย์88
トラックバック:casino online stranieri
トラックバック:review Pusat4D article
トラックバック:11 plus maths tuition
トラックバック:lcbet888
トラックバック:math tuition for p5 one to one
トラックバック:what happened to physics and maths tutor
トラックバック:math tuition singapore frequency
トラックバック:code promo 1xbet bf
トラックバック:ultra888ทางเข้า
トラックバック:maths tuition east singapore
トラックバック:physics and maths tutor iygb
トラックバック:math tuition assignment north east
トラックバック:offizielle website spinmama
トラックバック:jeu plinko avis
トラックバック:ip de mi router
トラックバック:Replica Hermes Birkin 30 Retourne Handmade Bag in Gris Asphalt Ostrich Leather
トラックバック:www.jurongsec.moe.edu.sg
トラックバック:a maths march tuition
トラックバック:secondary maths tuition centre east
トラックバック:Pressure piping stress analysis
トラックバック:fengshanpri.moe.edu.sg
トラックバック:best personal injury lawyers
トラックバック:British IPTV deals 2025
トラックバック:see more here
トラックバック:Apilus Cleo
トラックバック:spin mama de
トラックバック:bunk beds children’s
トラックバック:https://www.dotafire.com/profile/bmw55-192016
トラックバック:Replace Audi Key
トラックバック:Audi Replacement Key Fob
トラックバック:viewdeco.cn
トラックバック:Slides for bunk beds
トラックバック:Audi key programming
トラックバック:replacement key For audi
トラックバック:Audi A3 Key Replacement
トラックバック:Audi Emergency Key Replacement
トラックバック:New Audi Key
トラックバック:fridge uk
トラックバック:Genuine Audi Key Replacement
トラックバック:Englishbrowne77.livejournal.com
トラックバック:audi key fob replacement
トラックバック:https://md.entropia.de
トラックバック:output.jsbin.com
トラックバック:Veleco Faster Mobility Scooter
トラックバック:Lost Audi Key
トラックバック:cheap oven and Hob
トラックバック:math tutor edmonton
トラックバック:good jc math tuition
トラックバック:Hedge.fachschaft.informatik.uni-kl.de
トラックバック:https://pad.geolab.space/
トラックバック:Veleco Zt 15
トラックバック:بت فوروارد بدون فیلتر شکن
トラックバック:Audi Replacement Key Programming
トラックバック:igenics
トラックバック:Audi a3 car Key
トラックバック:Headsets
トラックバック:audi key Remote
トラックバック:Https://mcconnell-parrish-2.mdwrite.net/7-helpful-tricks-to-Making-the-most-of-Your-car-key-replacement-audi
トラックバック:bunkbeds for sale
トラックバック:plinko casino game real money withdrawal
トラックバック:How To Get A New Audi Key
トラックバック:bunk beds house
トラックバック:Zyphère Rateur
トラックバック:kiasu parents ip Math tuition
トラックバック:Https://www.anonimais.org/members/flagchick0/activity/145769/
トラックバック:Faimusjobsuganda.Net
トラックバック:written by Begild
トラックバック:math tutor dvd collection kickass
トラックバック:1xbet giriş
トラックバック:badcase.org
トラックバック:Trade Vector AI
トラックバック:Audi Keyless Entry
トラックバック:FrolexTrust
トラックバック:Audi key locksmith
トラックバック:124.223.100.38
トラックバック:best robot Vacuum cleaner
トラックバック:Audi Car Key Replacement
トラックバック:audi replacement Car keys
トラックバック:OpenSwitAi
トラックバック:DynarisFlex 7.1 Ai
トラックバック:Robot Vacuum And Cleaner
トラックバック:disabled scooters near me
トラックバック:adult adhd diagnosis private
トラックバック:https://Venusapartments.eu/agent/best-mobility-scooter2777
トラックバック:convertir pdf a excel
トラックバック:replacement keys for Audi
トラックバック:Https://git.kodors.net/
トラックバック:Double Bunk Beds With Slide
トラックバック:forum.bmaaa.org
トラックバック:tpx89
トラックバック:Audi Lost Key
トラックバック:HepatoBurn
トラックバック:Zelovent AI
トラックバック:Nagano Tonic
トラックバック:Https://Www.Aws-Properties.Com
トラックバック:Audi Key Fobs
トラックバック:best Robotic vacuum cleaner uk
トラックバック:Best Headphones Online Shopping
トラックバック:md.td00.de
トラックバック:Track Chantix Fin
トラックバック:private adhd assessment adults
トラックバック:audi Key repair
トラックバック:mental health Assessment in Therapy
トラックバック:Read 152.136.187.229
トラックバック:Https://pad.stuve.Uni-ulm.de/
トラックバック:how to get a new audi key fob
トラックバック:audi a4 spare key
トラックバック:Fabric Sofa Deals
トラックバック:time-saving cleaning
トラックバック:affordable flat roof care options
トラックバック:Audi Car key cutting
トラックバック:Audi Key
トラックバック:robotic vacuum cleaner deals
トラックバック:Oven and hob deals
トラックバック:https://back.codestudio.uk
トラックバック:психология семейных отношений учебник
トラックバック:Adhd Assessment Process
トラックバック:Switch Hiberix AI
トラックバック:expert storm-ready roof evaluations
トラックバック:Allergy-Friendly Vacuum
トラックバック:Sex Machine Adult Toy
トラックバック:Uptime Monitor
トラックバック:https://digitaltibetan.win
トラックバック:Audi Key Replacement Cost
トラックバック:BTC Income
トラックバック:Bunk Bed Slide
トラックバック:robot hoover uk
トラックバック:Estable Rentix
トラックバック:audi key lost
トラックバック:Https://Www.Elizandrasoares.Com.Br/Agent/Best-Mobility-Scooter9938
トラックバック:school porno
トラックバック:психолог семейных отношений москва
トラックバック:成人视频成人网站
トラックバック:Genuine Audi Key Replacement UK
トラックバック:you can try buy-headphone41991.jiliblog.com
トラックバック:Headphone Buy Online
トラックバック:Mental Health screening
トラックバック:Headphones Buy Online
トラックバック:mobility Scooter Stores
トラックバック:hedgedoc.eclair.ec-lyon.fr
トラックバック:Audi Key Cutting
トラックバック:Buy Earphones Online
トラックバック:Headphones Online Shopping
トラックバック:купить подписчиков вконтакте
トラックバック:Instant Ai App
トラックバック:Website Design London
トラックバック:instant delivery subscribers
トラックバック:Starzbet giriş
トラックバック:Headphones Online
トラックバック:quietum plus
トラックバック:turkey news travel
トラックバック:Affordable headphones
トラックバック:big bass splash free play
トラックバック:Headphone Online Shop
トラックバック:강남풀싸롱
トラックバック:plinko gambling
トラックバック:Buy good Headphones online
トラックバック:Stream Levora Cap
トラックバック:penis girth enlargement surgery
トラックバック:Headphones Earphones
トラックバック:NorthBridge AI
トラックバック:Stream Maxalt Nx
トラックバック:Audi Keys
トラックバック:bigbass
トラックバック:encontrar pessoa por telefone
トラックバック:nhà cung cấp máy nén khí tiết kiệm điện NTC
トラックバック:Instant Akpro 2X
トラックバック:KHIN789
トラックバック:casino spin mama
トラックバック:Audi new key
トラックバック:buôn bán trẻ em
トラックバック:places to Buy headphones
トラックバック:Headphones sale Uk
トラックバック:Https://Buy-Headphone19394.Atualblog.Com/41936602/7-Helpful-Tricks-To-Making-The-Profits-Of-Your-Best-Headphones-Online-Shopping
トラックバック:Headphoneforsale21957.Rimmablog.Com
トラックバック:https://pipewiki.org/wiki/index.php/User:ZAQCarrol930581
トラックバック:http://classicalmusicmp3freedownload.com/ja/index.php?title=:IonaP99352139346
トラックバック:egyptspsnet
トラックバック:bitcoin cash bonus
トラックバック:www.free-ebooks.net
トラックバック:m98 สล็อต
トラックバック:affordable custom cnc and edm tooling services
トラックバック:Arialief
トラックバック:business traveler news
トラックバック:Flush Factor Plus
トラックバック:livpure
トラックバック:Mines Cralaw
トラックバック:m3.dhakarachiescorts.com
トラックバック:buy-headphone84514.gynoblog.com
トラックバック:oaklawn casino
トラックバック:massage near me
トラックバック:safe engagement
トラックバック:develop m4ntiz
トラックバック:interior jakarta
トラックバック:spinmama cz
トラックバック:dryer vent cleaning near me
トラックバック:Snipaste官网
トラックバック:duct cleaning near me
トラックバック:rooftop equipment
トラックバック:wound dressings with silver
トラックバック:jeux plinko avis
トラックバック:mmmmm
トラックバック:pk.dhakarachigirls.com
トラックバック:casino spinmama
トラックバック:comrr
トラックバック:resurge
トラックバック:Massage Services in Karachi
トラックバック:Bathroom And designs bright Functional
トラックバック:Switch Imovax Lab
トラックバック:danske spil casino
トラックバック:SciatiEase
トラックバック:Track Amrix 100
トラックバック:wintdcom
トラックバック:vnscom
トラックバック:AtexNova 2.7
トラックバック:Extension projects house
トラックバック:heyhu
トラックバック:forums
トラックバック:Paragonix Earn
トラックバック:Axiom Trading
トラックバック:casino online deutschland
トラックバック:Bryxalord
トラックバック:Bravura Nexor
トラックバック:ForitexPro
トラックバック:Torvix
トラックバック:coantoor
トラックバック:Vision Akpro 400
トラックバック:hill-grape-90e.notion.site
トラックバック:Memory Lift
トラックバック:Immediate Chain
トラックバック:หวยลาวsuperย้อนหลัง
トラックバック:biography.us.com mua bán vũ khí
トラックバック:bonga cams blonde
トラックバック:Uptime Monitoring
トラックバック:Lunvirioxsis
トラックバック:Jacareí
トラックバック:spinmama pl
トラックバック:Crystallum Lotemax
トラックバック:betonred casino
トラックバック:Islamabad VIP Call Girls
トラックバック:https://bg6789.in.net/
トラックバック:ogxsds
トラックバック:Karachi Massage
トラックバック:betpuan casino
トラックバック:Botaratrex
トラックバック:Magnumator 2.0
トラックバック:AltmaxFlex 1.8 Ai
トラックバック:InvestRonex
トラックバック:Vornaxiel
トラックバック:onindddj
トラックバック:NorexVest
トラックバック:Radiation therapy children
トラックバック:Polska Bitradex
トラックバック:Botulax
トラックバック:Immediate Nextgen
トラックバック:Zeno Flow Engine
トラックバック:fast withdrawal casinos
トラックバック:Gevertixon
トラックバック:plinko arnaque
トラックバック:type 2 diabetes treatment
トラックバック:Blue Bayou Restaurant
トラックバック:free online casino
トラックバック:Finxalor
トラックバック:All Day Slimming Tea
トラックバック:AI Arbitrage
トラックバック:Renovation project management
トラックバック:новостной блог scorpio-escort – это новостная страница 호위 συνοδοί scorpioescort Lester G girlshbs.cc girlshbs ενηλίκων ειδήσεις blog ενηλίκων blog ιστολόγιο περιεχομέν
トラックバック:istanbul pirinç küpeşte
トラックバック:как путешествия способствуют развитию человека и его нравственности
トラックバック:новости шоу биза в мире
トラックバック:Quantum Luvox
トラックバック:Elyor Platform
トラックバック:Exotradex
トラックバック:MexonRich
トラックバック:VIP Call Girls in Karachi
トラックバック:beautiful bird of the world
トラックバック:real brother and sister incest porn
トラックバック:Norivantix
トラックバック:Заклепки
トラックバック:Fortune Nexora
トラックバック:konabet com
トラックバック:23win
トラックバック:credit
トラックバック:Infinity AI
トラックバック:Drazexium
トラックバック:Astrofinanza
トラックバック:Dewapoker Login
トラックバック:plinko echtgeld
トラックバック:casino betonred
トラックバック:u31 เว็บตรง
トラックバック:MadridX
トラックバック:PulseNovaAI
トラックバック:spinmama oficjalna strona
トラックバック:free fishing frenzy
トラックバック:Signal Kinrix Fin
トラックバック:Immunotherapy children
トラックバック:ind poker
トラックバック:Immediate Connect
トラックバック:Vegas Casino Online
トラックバック:Zeneara
トラックバック:best testosterone booster
トラックバック:sonic internet down
トラックバック:stylewebf
トラックバック:Endopeak
トラックバック:лена миро новости
トラックバック:skyiwredshjnhjgeleladu7m7mgpuxgsnfxzhncwtvmhr7l5bniutayd
トラックバック:Bulk tissue paper manufacturer in Mumbai
トラックバック:Quendorexa
トラックバック:Immediate Puro 2.0
トラックバック:歐霸
トラックバック:Zyven Yield
トラックバック:EuroBoost AI
トラックバック:best online casino sites
トラックバック:xrumer bootmaster
トラックバック:The Online Casino
トラックバック:Foltrezapex
トラックバック:xrumer видео
トラックバック:medical supplies
トラックバック:health news
トラックバック:xrumer xevil
トラックバック:Veltrix Ai
トラックバック:bet
トラックバック:spin mama deutschland
トラックバック:DinHex GPT
トラックバック:Trixford Fund
トラックバック:Guadagno Relmar
トラックバック:ReichOnix
トラックバック:Escorts in Nazimabad Karachi
トラックバック:is computer engineering the same as software engineering
トラックバック:казино буй
トラックバック:world of beauty salon
トラックバック:강남쩜오
トラックバック:InvestProAI
トラックバック:{Massage in Karachi
トラックバック:Immediate Apex
トラックバック:Elephant Root Trick
トラックバック:Vegas Spins Casino
トラックバック:UK Casino Club
トラックバック:Magnumator
トラックバック:лучшие страховые компании для путешествий
トラックバック:Neuro Surge
トラックバック:massage in DHA phase 3 Karachi
トラックバック:Botologix Invest
トラックバック:Immediate Coraldex
トラックバック:Immediate Tras
トラックバック:เน็ต ais
トラックバック:VexiRich
トラックバック:Fixonatex
トラックバック:Instant Stog
トラックバック:золотой софт 2010
トラックバック:dewagaruda
トラックバック:mdg188
トラックバック:Lucente Fundex
トラックバック:mdgwin
トラックバック:filler-free spices
トラックバック:to288 login
トラックバック:ticketmaster presale code finders livenation presale code finder
トラックバック:Banorte CFD
トラックバック:Rockley Portdex
トラックバック:Nerve Fresh
トラックバック:mypixi
トラックバック:Turbo Imitrex Xr
トラックバック:get new driving licence
トラックバック:скачать рапорт бесплатно
トラックバック:ibogaine seeds
トラックバック:누누티비
トラックバック:Sports Betting Casino
トラックバック:Trixford Fund Review
トラックバック:Sandford Bitline
トラックバック:cosmocheats
トラックバック:appsforanyone.ru.com website mua bán ma túy
トラックバック:internet chicks.
トラックバック:QatarionEdge
トラックバック:mold removal Portland
トラックバック:Westmere Paycore Review
トラックバック:Massage in Karachi
トラックバック:ทีเด็ดบอล
トラックバック:hi.vipkarachibeautiess.com
トラックバック:Braklevix
トラックバック:Wexley Vaultix
トラックバック:plumbing business cards ideas
トラックバック:buôn bán người
トラックバック:mvfffff
トラックバック:Neiropolium
トラックバック:Treasure Mile Casino
トラックバック:Zet Bet Casino
トラックバック:Lumine Tradeline
トラックバック:thesis writers in sri lanka
トラックバック:ремонт в новостройке
トラックバック:code bonus 1xbet la
トラックバック:israeldmvc
トラックバック:https://gold.novinblog.net
トラックバック:learn spanish computer software
トラックバック:Beställ Cialis Online Receptfritt
トラックバック:bongda
トラックバック:Cheeky Casino
トラックバック:sex loạn luân
トラックバック:phim sex hiếp dâm học sinh
トラックバック:postid-53274
トラックバック:watch movies with iptv
トラックバック:The Proxy
トラックバック:plinko
トラックバック:air tech challenge yupoo
トラックバック:обои софт
トラックバック:nhà cái new888
トラックバック:earn money on telegram
トラックバック:стиль софт
トラックバック:adding value to Your home
トラックバック:бородавки на пятке
トラックバック:watch sports with iptv
トラックバック:lena meadowcroft
トラックバック:fishing frenzy
トラックバック:fishing frenzy game free
トラックバック:fishin frenzy big catch demo
トラックバック:epilstudio лечение бородавок
トラックバック:plinko deutschland
トラックバック:kraken5af44k24fwzohe6fvqfgxfsee4lgydb3ayzkfhlzqhuwlo33ad.onion
トラックバック:https://www.slunce.us.com/
トラックバック:Massagein Karachi
トラックバック:лечение бородавок на лице
トラックバック:лазерное обновление кожи
トラックバック:Yupoo Prada
トラックバック:Почему бородавки возвращаются
トラックバック:epilstudio.ru explains
トラックバック:plinko game
トラックバック:fishin frenzy free play
トラックバック:новые казино без депозита
トラックバック:winvnetandcam
トラックバック:winnnn
トラックバック:buy iptv subscription
トラックバック:https://www.deviantart.com/plus777net
トラックバック:incrip
トラックバック:Dukes Casino
トラックバック:plinko ball
トラックバック:Slot Shack Casino
トラックバック:teamblogoci
トラックバック:tupperware brotdose
トラックバック:Custom pattress design
トラックバック:Kendte strukturer
トラックバック:mature teen porn – adult xxx video hot porn site
トラックバック:runcing77
トラックバック:Casino On Net
トラックバック:homepage
トラックバック:Dove Casino
トラックバック:Znane Konstrukcje
トラックバック:Escorts in Karachi
トラックバック:childrens
トラックバック:Bekende structuren
トラックバック:Known Structures
トラックバック:Dream Jackpot Casino
トラックバック:новинки казино
トラックバック:vapetank
トラックバック:hashno
トラックバック:Ezoterija
トラックバック:IDM Kuyhaa
トラックバック:it support in warrington
トラックバック:https://ss13.fun/wiki/index.php?title=User:Berry03H87576927
トラックバック:Domino QQ Online
トラックバック:Taruhan Esports Online
トラックバック:bracelet of ethereum
トラックバック:sahara halal food
トラックバック:ethereum development services
トラックバック:A21 file structure
トラックバック:Live Dealer Casino
トラックバック:nhà cái ee88
トラックバック:buy xdc crypto
トラックバック:altcoin season start 2025
トラックバック:68gamebai công 68gamebai
トラックバック:как скачать игры на ppsspp
トラックバック:petrol wheelbarrow
トラックバック:bitcoin tarkov price
トラックバック:nhà cái xoso66
トラックバック:milf fuck
トラックバック:вклады 2025
トラックバック:https://gravatar.com/sangjincontrolcable
トラックバック:ww11 motorcycles
トラックバック:как играть в игру кальмара
トラックバック:топ графических планшетов
トラックバック:новости мира и
トラックバック:дрифт игры на телефон
トラックバック:xrumer и senuke
トラックバック:shopcentroscampoli
トラックバック:computer freezes during games not overheating
トラックバック:классы компьютерных игр
トラックバック:семиместный автомобиль
トラックバック:Pink salt trick recipe
トラックバック:Valtrixio
トラックバック:liposuction
トラックバック:volt internet
トラックバック:altcoin price rally potential december 2024
トラックバック:Pink salt trick for weight loss
トラックバック:good news travels
トラックバック:idm free download trial
トラックバック:редрагон софт
トラックバック:виды криптовалюты
トラックバック:Massage inKarachi
トラックバック:gloomhaven компьютерная игра
トラックバック:оман путешествие
トラックバック:owdso
トラックバック:Keto Plus Gummies
トラックバック:как играть в дурака
トラックバック:Mua ma túy đá
トラックバック:бизнес идеи это
トラックバック:VivaValtrixio
トラックバック:приложение красота и здоровье
トラックバック:Yu Sleep
トラックバック:Neuro Energizer
トラックバック:baji 7777 live login
トラックバック:замедление интернета
トラックバック:опт гаджет
トラックバック:ela crypto news
トラックバック:Disability Services Logan
トラックバック:bitcoin mining software free
トラックバック:Shot Services in Karachi
トラックバック:world’s most beautiful pictures of nature
トラックバック:Instant 750 Stog
トラックバック:japanese restaurant
トラックバック:nhà cai au88
トラックバック:Gembet
トラックバック:новости мира телеграмм
トラックバック:Zeker Bitlijn
トラックバック:pest control fumigasi anti rayap
トラックバック:Veltrex Core GPT
トラックバック:психология отношений фейсбук
トラックバック:Norivantex
トラックバック:au88 nhà cái au88
トラックバック:gambling
トラックバック:The Genius Wave
トラックバック:Boostaro
トラックバック:xour
トラックバック:bitcoin cash price prediction 2025
トラックバック:Escorts in Karachi
トラックバック:xrumer forum poster torrent
トラックバック:программа xrumer скачать бесплатно бесплатно скачать
トラックバック:xrumer рандомизация букв в никнейм
トラックバック:culturelle with or without food
トラックバック:naked mom and sons
トラックバック:RovonixFlex 2.1 Ai
トラックバック:perbedaan-ssd-dan-hdd-untuk-penyimpanan-data
トラックバック:Vacation Club Software
トラックバック:как играть на варгане
トラックバック:софт на
トラックバック:candy without food coloring
トラックバック:MornexisPro
トラックバック:rojava plan bitcoin address
トラックバック:вот софт
トラックバック:praktik
トラックバック:mamamu ppek
トラックバック:spb
トラックバック:elon crypto wallet
トラックバック:xrumer сайт
トラックバック:창문시트지
トラックバック:Call Girls in Islamabad
トラックバック:massage for injury recovery
トラックバック:вклады для физических
トラックバック:Mines
トラックバック:bạo hành trẻ em
トラックバック:bomwin
トラックバック:omwinte
トラックバック:us news and world report pediatric cardiology
トラックバック:touro.eu.com/Thuốc kích dục
トラックバック:franfo
トラックバック:https://www.adpost.com/u/jiliorgph/
トラックバック:Premiummaterials
トラックバック:555win
トラックバック:آموزش ارز دیجیتال در تهران آموزش ترید در تهرا
トラックバック:Wesmere Bitmark
トラックバック:Signal Manerix X
トラックバック:trang chu tt88
トラックバック:what are the two main categories of computer software
トラックバック:Gunst Bitmark
トラックバック:Nerotrexgent
トラックバック:m98 เข้าสู่ระบบ ล่าสุด
トラックバック:verde casino bonus code 25 euro
トラックバック:Altivo Group
トラックバック:Orlunith Pulse 8.8
トラックバック:montaż auto gaz Warszawa
トラックバック:NeuroQuiet
トラックバック:montaż auto gaz
トラックバック:화물번호판
トラックバック:MonitrexPRO
トラックバック:Hejgo Casino
トラックバック:mindfulness audiobooks
トラックバック:KKWIN
トラックバック:Buy Klonopin Online
トラックバック:Order Tapentadol 100mg
トラックバック:Be5 Care
トラックバック:Fortuneer
トラックバック:Buy Adderall Online
トラックバック:carisoprodol 350 mg online
トラックバック:Buy Tramadol Online
トラックバック:ครบทุกแพลตฟอร์มโซเชียล สั่งงานอัตโนมัติ 24 ชม. การันตีคุณภาพ อันดับ #1 ในไทย — SMMHUB88!
トラックバック:гаджет ленд
トラックバック:https://my.clickthecity.com/plusph
トラックバック:боронина гаджет
トラックバック:candy crush saga++
トラックバック:сравни ипотека
トラックバック:Xanax
トラックバック:food supplement
トラックバック:air conditioning
トラックバック:SEO Best Services
トラックバック:آموزش ترید در مشه
トラックバック:Intel Erymax Pro
トラックバック:BitEra
トラックバック:Karachigirlsescort.com
トラックバック:Call Girls in Karachi
トラックバック:https://decidim.santcugat.cat/profiles/taya365ph/activity
トラックバック:igamble247 login
トラックバック:Bitwave Reaction AI
トラックバック:bejeweled online
トラックバック:ev88
トラックバック:https://images.google.co.uz/url?q=https://volga.news/758839/article/chem-zanyatsya-v-sukko.html/
トラックバック:lotus365.diy
トラックバック:recent post by About
トラックバック:Biały komplet bielizny damskiej z koronkowymi stringami i biustonoszem – Uwolnij swoją zmysłowość!
トラックバック:editing
トラックバック:Dunman High School (Secondary)
トラックバック:jak np. białe szpilki z paskami lub srebrne szpilki z brokatem.
トラックバック:że James Bond to tylko mężczyzna? Przedstawiamy „Jamie Bond” – odwróconą wersję kultowego szpiega!
トラックバック:a moda definiuje trendy.
トラックバック:Czym się charakteryzuje?
トラックバック:https://substance3d.adobe.com/community-assets/profile/org.adobe.user:1A2C21E26881DBA20A495CC7@AdobeID
トラックバック:T-shirt
トラックバック:które wyeksponują piękno kobiecej sylwetki.
トラックバック:które podkreślą Twój styl.
トラックバック:Blackridge Markdex Review
トラックバック:69vn
トラックバック:Mirexa Platform
トラックバック:Men’s Growth
トラックバック:BixPulse AI
トラックバック:Nag Hammadi Wealth Code
トラックバック:Seguro Tradex GPT
トラックバック:marketing
トラックバック:NewEra Protect
トラックバック:Track Avage Pro
トラックバック:Wild Blaster Casino
トラックバック:Order medication online without prescription
トラックバック:https://walling.app/ijKeiXMJdZq4xleOzJgx/-
トラックバック:Dlaczego warto inwestować w wysokiej jakości bieliznę? Przekonaj się sam!
トラックバック:Best place to get Lorazepam online
トラックバック:Trezik Forge GPT
トラックバック:Aureo Tradebit
トラックバック:Finance Legend App
トラックバック:manhwaland bokep
トラックバック:videography
トラックバック:cuevana 3
トラックバック:fishin frenzy demo
トラックバック:Vernotrix
トラックバック:Staniki dla pań plus size – szerokie ramiączka i wygodne miseczki to klucz do sukcesu!
トラックバック:plinko demo
トラックバック:Voltryzapex
トラックバック:personal injury attorneys
トラックバック:check link
トラックバック:Jak nosić czółenka do sukienek i spódnic?
トラックバック:Yoast seo
トラックバック:https://www.heroesfire.com/profile/jiliorgph/bio
トラックバック:98win121
トラックバック:Fatvim Weight Loss Formula
トラックバック:zus
トラックバック:International Digital Marketing Agency
トラックバック:Petronas Platform
トラックバック:как очень быстро похудеть отзывы
トラックバック:Aurix Canada
トラックバック:mat bang nha trang
トラックバック:MoveWell Daily
トラックバック:Vision Maxalt Pip
トラックバック:Ridgewell Tradebit review
トラックバック:Joint N-11
トラックバック:LeptoFix
トラックバック:sgp 4d
トラックバック:Arbivex
トラックバック:theporndude
トラックバック:jepangbet
トラックバック:ma túy đá
トラックバック:Bravo Flowdex
トラックバック:Immediate Flex
トラックバック:Kalevantrex
トラックバック:DHA Lahore guest house
トラックバック:wedding venues near me
トラックバック:Gordon Law
トラックバック:casino uden rofus
トラックバック:Candy AI Free Premium Account
トラックバック:intertops casino
トラックバック:Hometogel login hometogel link alternatif hometogel
トラックバック:Ridgewell Tradebit
トラックバック:winvv
トラックバック:Luvox Bit
トラックバック:trang chu 68win
トラックバック:อกไก่ปั่นสำเร็จรูป
トラックバック:pg88
トラックバック:lottochamp
トラックバック:The Lost Generator
トラックバック:Au88
トラックバック:tripscan
トラックバック:AccuTraderAi
トラックバック:купить аккаунт destiny 2
トラックバック:Gunst Paymark
トラックバック:cosca888 fucking mother
トラックバック:https://forum.eko-suszarnia.pl/showthread.php?tid=81087
トラックバック:Forte Valbit
トラックバック:ปั้มผู้ติดตาม
トラックバック:Flow Trade AI
トラックバック:bandar slot online
トラックバック:mtzone
トラックバック:analysis
トラックバック:Fintruxel
トラックバック:Oakmere Payline
トラックバック:Tapentadol 100mg tablets
トラックバック:trang chu ax88
トラックバック:FinUpix
トラックバック:cheap van Finance
トラックバック:Buy Ambien online for sleep
トラックバック:pu88
トラックバック:Valium for anxiety relief
トラックバック:ZenthraFound
トラックバック:GK888
トラックバック:Order Ultram online
トラックバック:Order Fioricet online USA
トラックバック:Buy Diazepam 10mg online
トラックバック:Viagra without prescription
トラックバック:Buy Lorazepam Online
トラックバック:Lorazepam for anxiety online
トラックバック:buy oxycodone without prescription
トラックバック:Buy Lorazepam 2mg
トラックバック:فرهنگیان یا مهندسی نی نی سایت
トラックバック:Sildenafil 100mg for ED
トラックバック:Buy Ksalol online without script
トラックバック:Citra tablets online
トラックバック:Buy Kamagra jelly online
トラックバック:No RX pharmacy
トラックバック:GlavixPro
トラックバック:Luxury333
トラックバック:Buy Tramadol online overnight
トラックバック:Order Adderall XR online
トラックバック:Order Ativan without RX
トラックバック:Buy Vicodin online
トラックバック:Jak dopasować szpilki do stopy? Aby zapewnić komfort
トラックバック:Quantum Core AI
トラックバック:Order Xanax bars online
トラックバック:gametoto
トラックバック:Xanax bars online no prescription
トラックバック:Fioricet with codeine online
トラックバック:Nucynta for pain
トラックバック:Order Lorazepam online fast
トラックバック:pgbet8888 หนังโป๊
トラックバック:pu8
トラックバック:i9bet
トラックバック:ปั้มหัวใจติ๊กต็อก
トラックバック:Diazepam tablets for sale
トラックバック:Levitra 20mg tablets online
トラックバック:Karachi SPA
トラックバック:pgbet8888 LGBT
トラックバック:RozoXfin
トラックバック:Purchase Clonazepam online no RX
トラックバック:secondary 1 math singapore
トラックバック:Buy Adipex online cheap
トラックバック:Giusto Itradebit
トラックバック:AxiReich
トラックバック:Erlig Vaultrow
トラックバック:Stream Amrix 400
トラックバック:MaxgenBit
トラックバック:ZavonixPulse 5.9 Ai
トラックバック:Visium Plus
トラックバック:Buy Ksalol online
トラックバック:Blackridge Markdex
トラックバック:Astrofinanza AI
トラックバック:Lahore Escorts
トラックバック:Selfinstall
トラックバック:https://cdacert.com/blog/index.php?entryid=88898
トラックバック:Everix Edge
トラックバック:เพิ่มผู้ติดตาม Tiktok
トラックバック:9awin
トラックバック:Buy pills online fast delivery
トラックバック:Yupoo YSL
トラックバック:Sportsbook Online
トラックバック:mv88
トラックバック:criminal defense Investigator training
トラックバック:fabric laminated glass
トラックバック:apk моды без вирусов
トラックバック:vntipsexblo
トラックバック:simply click Mstdn
トラックバック:S3.Us-East-1.Wasabisys.com
トラックバック:https://oliblog.blob.core.windows.net/oliblog2/math-tuition-singapore-1/singapore-tuition-agency.html
トラックバック:Fajartoto
トラックバック:mcompi
トラックバック:개별넘버매매
トラックバック:https://filedn.eu/l28QcM26udcS82B1XuQSt0L/oliblog2/secondary-1-math-tuition-1/page-urls.pdf
トラックバック:singapore math curriculum
トラックバック:prime biome gummies
トラックバック:A片
トラックバック:land clearing jacksonviile
トラックバック:h2 math tuition
トラックバック:private math tutor hourly rate
トラックバック:Accu Trader AI
トラックバック:bitcoin cloud mining calculator
トラックバック:ethereum blackrock
トラックバック:Togelon
トラックバック:Shiokambing3
トラックバック:JBLACK809
トラックバック:Septic tank pumping northeast florida
トラックバック:Giveaway Latino
トラックバック:drill latino JBLACK809
トラックバック:Karachi Call Girl
トラックバック:Buy Cialis online
トラックバック:ipuyn
トラックバック:hmuy
トラックバック:100WIN
トラックバック:electrohouse
トラックバック:یک بت
トラックバック:shbet17
トラックバック:buy bitcoin kucoin
トラックバック:lowest crypto exchange fees
トラックバック:Puffy Lux Mattress
トラックバック:yupoo megamillions
トラックバック:blockchain trends
トラックバック:home painting contractors near me
トラックバック:https://megafaraon-ar.top
トラックバック:ProvaDent
トラックバック:JapBitMax
トラックバック:Online pharmacy USA/UK
トラックバック:BrixelFin
トラックバック:youtube-videos
トラックバック:Cronetrium System
トラックバック:Ocean Ofgames
トラックバック:Zolpidem online pharmacy
トラックバック:black
トラックバック:HI88R
トラックバック:motorcycle flag
トラックバック:газель автомобиль
トラックバック:Quantum AI Platform
トラックバック:Investment Platform
トラックバック:bitcoin mining difficulty
トラックバック:auditor blockchain
トラックバック:российские автомобили
トラックバック:Buy Best SEO Backlinks
トラックバック:BALMOREX Pro
トラックバック:Suncrest Fluxrow
トラックバック:bitcoin investors profit taking
トラックバック:driving school
トラックバック:grant denyer uses bitcoin platform fact check
トラックバック:great deals
トラックバック:ballbusting
トラックバック:movers protection insurance
トラックバック:buôn bán nội tạng
トラックバック:hm88
トラックバック:jun88
トラックバック:solana correlation with bitcoin ethereum volatility
トラックバック:Bos138 Login
トラックバック:advanced dental implants
トラックバック:massage in DHA phase 3 Karachi
トラックバック:Platform
トラックバック:Avis
トラックバック:чатрулетка пары
トラックバック:token terminal mau ethereum l1 l2
トラックバック:Parlions Platform
トラックバック:Massage Center in Karachi
トラックバック:ดูซีรีย์
トラックバック:fintechzoom.com bitcoin price live
トラックバック:Swap Herplex Fin
トラックバック:altcoins c’est quoi
トラックバック:what is the best altcoin to buy
トラックバック:adults entertainment activities
トラックバック:exchange ethereum to ripple
トラックバック:タカラ フローデックス
トラックバック:Arbiquant platform
トラックバック:บาคาร่าเซ็กซี่
トラックバック:оборудование переговорной
トラックバック:Asesondex
トラックバック:LucroX AI
トラックバック:U88
トラックバック:NEU88
トラックバック:best math tutors
トラックバック:best maths tuition in singapore
トラックバック:VryxfeldAi
トラックバック:Seigi Pouflyks
トラックバック:Sarvontex App
トラックバック:F1688
トラックバック:시알리스 구입
トラックバック:nhacaiuytingo.com
トラックバック:부산토닥이 부산여성전용마사지
トラックバック:диета елены малышевой +для похудения
トラックバック:未来の鍵
トラックバック:ABC8
トラックバック:Riobet вход
トラックバック:Thyrafemme Balance
トラックバック:FinaxPro
トラックバック:gravata
トラックバック:гей порно чат рулетка
トラックバック:solar panel
トラックバック:Goldmere Paynex
トラックバック:你爸爸的鸡巴断了,你倒霉的阴部,你爸爸的网络钓鱼,你妈妈的内脏
トラックバック:أنت أحمق، من الأفضل أن تعيش هنا، ستموت هناك، إنه أمر رائع يا رجل
トラックバック:https://sites2000.com/
トラックバック:1xbet казино официальный сайт
トラックバック:RECENSIONE
トラックバック:Quantum Investox
トラックバック:rafaely34k6.wikikali.com wrote in a blog post
トラックバック:Aureo Flowdex
トラックバック:Seltrixio
トラックバック:Épure Fundex
トラックバック:Klarheit Flowdex
トラックバック:Belvars Platform
トラックバック:Laringtex App
トラックバック:Fels Bitline
トラックバック:Varsuntex App
トラックバック:singapore
トラックバック:88CLB
トラックバック:Online Casino Sites
トラックバック:Vortion Platform
トラックバック:BET88
トラックバック:Zobet
トラックバック:gluco6
トラックバック:tripscan войти
トラックバック:jepang77
トラックバック:glucoberry order
トラックバック:Przyjmiemy zlecenie na wykonanie hali stalowej w Koluszkach
トラックバック:Chi conserva registro delle traduzioni giurate asseverazioni tribunale
トラックバック:My Montgomery veterinarian
トラックバック:https://padlet.com/clinicforhim150oblvl/bookmarks-qlhf86li2tt3awxf/wish/YBl3Z2xdwGK8av16
トラックバック:رتبه قبولی ادبیات فارسی ۱۴۰۴
トラックバック:апостиль свидетельство о разводе
トラックバック:Normandy Animal Hospital
トラックバック:Rik88
トラックバック:https://muckrack.com/jiliko1225comph/bio
トラックバック:Hitclub
トラックバック:StoZah AI
トラックバック:Trading Platform
トラックバック:Reseña
トラックバック:Klondike cheats generator online
トラックバック:Zooba Zoo hack coins
トラックバック:AxiWert
トラックバック:Sterk Bitlijn
トラックバック:what altcoins to buy now
トラックバック:https://play.thronesofdestiny.com/showthread.php?tid=100872
トラックバック:company directory free
トラックバック:Przyjmiemy zlecenie na wykonanie hali stalowej w Piotrkowie Trybunalskim
トラックバック:http://www.korealol.com/thread-52173.html
トラックバック:bitcoin price prediction may 19 2025
トラックバック:Bravotogel
トラックバック:panen4d link
トラックバック:Przyjmiemy zlecenie na wykonanie hali stalowej w Zelowie
トラックバック:9awin ph
トラックバック:google analytics alternative
トラックバック:Przyjmiemy zlecenie na wykonanie hali stalowej w Tuszynie
トラックバック:oqe7c.mssg.me
トラックバック:reddit altcoins
トラックバック:pgbet888 fuck
トラックバック:Przyjmiemy zlecenie na wykonanie hali stalowej w Łęczycy
トラックバック:Przyjmiemy zlecenie na wykonanie hali stalowej w Konstantynowie-Łódzkim
トラックバック:ปั๊มวิว Youtube
トラックバック:ethereum exchange outflows accumulation
トラックバック:ethereum token development company
トラックバック:High-Quality Plastic Prototyping Experts
トラックバック:advertising blockchain
トラックバック:ldc88
トラックバック:кракен зеркало
トラックバック:Gluco Extend
トラックバック:litecoin volatility correlation bitcoin 2024
トラックバック:https://telegra.ph/——08-28-2
トラックバック:SlimMe Detox Tea
トラックバック:BitPulseAI
トラックバック:Zorovixia
トラックバック:daftar sini
トラックバック:native Path Creatine
トラックバック:AlphaTrize
トラックバック:Vyrsen Axis
トラックバック:cellucare sale
トラックバック:kickboxing olympic sport
トラックバック:игры бесплатно на телефон
トラックバック:топ вкладов
トラックバック:графический планшет леново
トラックバック:Kpktoto
トラックバック:xnxx gay men
トラックバック:как скачать игры на анберник
トラックバック:consulting business startup costs
トラックバック:kra30 at
トラックバック:simonm8uu0.xzblogs.com
トラックバック:как играют в майнкрафт
トラックバック:resolution dota 2
トラックバック:bandar judi togel terpercaya
トラックバック:Solido Fluxrow
トラックバック:columbus adult entertainment
トラックバック:Takara Flowdex
トラックバック:updated home roof designs
トラックバック:перевезти груз негабаритный
トラックバック:pk.dhamassagekarachi.com
トラックバック:socialstrategie.com
トラックバック:лучшие компьютерные игры
トラックバック:food coloring without red 40
トラックバック:Senvix
トラックバック:is Rankvance free to use
トラックバック:Yowestogel Yowestogel Login Link Alternatif Yowestogel
トラックバック:Wealth Ancestry Prayer
トラックバック:Phalo Boost Supplement
トラックバック:esta application
トラックバック:Mbet
トラックバック:steam вывести деньги
トラックバック:Torvix Platform
トラックバック:Actiune Vyna
トラックバック:Liv Pure
トラックバック:Vexa Exelon
トラックバック:Greyfort Bitcore
トラックバック:как играть в minecraft
トラックバック:children abduction cambodia
トラックバック:CanFund
トラックバック:e sports olympics
トラックバック:Quantum Bextra
トラックバック:Fyronex Driftor GPT
トラックバック:dado
トラックバック:opcmd82693.ja-blog.com
トラックバック:สมัคร RUAY เว็บตรง
トラックバック:детские компьютерные игры
トラックバック:disney world adult entertainment
トラックバック:https://padlet.com/bailbonds120usjxv/bookmarks-k0iez1nxmgoh2smw/wish/0BA3ZpgoXlrAQnPb
トラックバック:RapidoCripto24
トラックバック:시알리스 정품
トラックバック:Velstand Paynor
トラックバック:http://www.gleaming.co.kr/board_yNSk23/238428
トラックバック:https://tawk.to/
トラックバック:wakeboarding olympic sport
トラックバック:what is electric cable
トラックバック:bitcoin machine florida
トラックバック:VeltrixMax
トラックバック:все гаджеты
トラックバック:affordable flat roof evaluations
トラックバック:Nanobookmarking.Com
トラックバック:espoiled dota 2
トラックバック:night karachi escorts
トラックバック:crypto exchanges without id verification
トラックバック:GARDEN SHED NEW ZEALAND
トラックバック:new post from finnp12g5.wikimeglio.com
トラックバック:safety wear supppliers
トラックバック:anschluss sandfilteranlage anschlussplan
トラックバック:western michigan wedding venues
トラックバック:bitcoin retirement calculator
トラックバック:ипотека сбер
トラックバック:инцест игры на телефон
トラックバック:ред робототехника
トラックバック:adolfe578www1.wannawiki.com
トラックバック:keyword stufffing SEO
トラックバック:tripskan
トラックバック:ethereum meta price prediction
トラックバック:вывести деньги ип
トラックバック:https://atozbookmark.com
トラックバック:Aluminium UTE Canopy in Australia
トラックバック:is ethereum a security or commodity
トラックバック:singapore business
トラックバック:titanium mesh recycling
トラックバック:Independent Escorts in Karachi
トラックバック:olympic sports bowling
トラックバック:DT68
トラックバック:businessbookmark.com
トラックバック:altcoin season november 2021
トラックバック:шахматы как играть
トラックバック:https://robertt356sqh6.lotrlegendswiki.com/user
トラックバック:huntsman
トラックバック:zirbeldrüse
トラックバック:qmi88
トラックバック:662s3
トラックバック:north korea ethereum reserve
トラックバック:Mevryon Platform
トラックバック:slotra giriş
トラックバック:preschool playgroup singapore childcare
トラックバック:Google ads marketing agency
トラックバック:Westrise Corebit
トラックバック:Épure Tradelin
トラックバック:https://olivebookmarks.com/story20255537/blackjack-uncomplicated-english-wikipedia-the-no-cost-encyclopedia
トラックバック:ручки стилусы
トラックバック:online gambling sites
トラックバック:Wzrost Fundex
トラックバック:Toy Blast hack coins
トラックバック:https://4632.cn.com
トラックバック:kokitoto togel
トラックバック:конкулятор ипотеки
トラックバック:boat tour
トラックバック:робот пылесос karcher
トラックバック:Link Situs Slot Deposit 5000
トラックバック:Tokenpocket web wallet
トラックバック:coba slot sekarang
トラックバック:best online gambling sites
トラックバック:стилус cd54
トラックバック:TK999
トラックバック:how to buy game zone crypto
トラックバック:next altcoin to explode
トラックバック:как на ноутбуке скачать игры
トラックバック:mega fo ссылка
トラックバック:प्लर राजा
トラックバック:корр счет в банке
トラックバック:MMOO
トラックバック:bitcoin terminal price
トラックバック:секс-кукла
トラックバック:altcoin season charts
トラックバック:War Robots cheats silver
トラックバック:Ethereum +XP Hiprex
トラックバック:notail dota 2
トラックバック:গুৰুত্বপূৰ্ণ সঁজুলি বিক্ৰী কৰা
トラックバック:член сломался
トラックバック:comr8
トラックバック:Purchase Diazepam 2mg Online
トラックバック:Tramadol Online Without Prescription
トラックバック:ethereum pronunciation
トラックバック:Buy Generic Alprazolam Online Cheap
トラックバック:Buy Citra Tramadol Online PayPal
トラックバック:metal roofs
トラックバック:Buy Ativan Online
トラックバック:ecommerce WordPress development company
トラックバック:Rainbow Daytona replica Genevar
トラックバック:obs188
トラックバック:popcat crypto news
トラックバック:интернет йота
トラックバック:магазины компьютерных игр
トラックバック:integrative medicine tampa
トラックバック:memorial day social media post ideas for businesses
トラックバック:hair business name ideas
トラックバック:VIP Karachi Call Girls
トラックバック:expert electrician
トラックバック:राजा छह
トラックバック:сбои интернета
トラックバック:integrative medicine indianapolis
トラックバック:microwave internet
トラックバック:y8kb
トラックバック:crypto news,best crypto news,crypto news site,btc price today,crypto price today
トラックバック:ganache blockchain
トラックバック:what is the latest news related to travelling to mars
トラックバック:мтс деньги вывести
トラックバック:dota 2 leaderboard
トラックバック:беларусбанк вклады
トラックバック:kingzeus88
トラックバック:searching
トラックバック:신용카드현금화
トラックバック:ৰাজ্যসমূহৰ ৰজা
トラックバック:https://school97.ru/vesti20/index.php?PAGE_NAME=profile_view&UID=225456
トラックバック:integrative medicine vanderbilt
トラックバック:เว็บสล็อต
トラックバック:hottest brazilian babes
トラックバック:продажа секс-игрушек
トラックバック:information from Summer.Eholynet.org
トラックバック:http://Old.Remain.co.kr/bbs/board.php?bo_table=free&wr_id=5675703
トラックバック:소액결제현금화
トラックバック:http://Cafe5.Winnen.Co.kr/bbs/board.php?bo_table=free&wr_id=2200640
トラックバック:certified blockchain
トラックバック:Buy Tapentadol online
トラックバック:where to buy lotto champ
トラックバック:Buy Oxycodone online
トラックバック:pug555
トラックバック:free welive coins
トラックバック:europe travel news
トラックバック:новинки гаджеты
トラックバック:база ссылок joomla k2 для xrumer
トラックバック:mussa
トラックバック:ethereum periodic table
トラックバック:789betlinks
トラックバック:lenovo стилус
トラックバック:küçükbakkalköy pilates
トラックバック:скачать xrumer 5 для windows
トラックバック:со стилусом
トラックバック:ปั้มติดตาม Youtube
トラックバック:travel ban news today
トラックバック:timbuktu
トラックバック:motorcycle tuning
トラックバック:hair transplant istanbul
トラックバック:joint restore order
トラックバック:neotonics official
トラックバック:мкб вклад
トラックバック:gluco 6
トラックバック:nervecalm
トラックバック:новости мира тенгри
トラックバック:audifort price
トラックバック:Test and tag
トラックバック:audifort discount
トラックバック:Live Draw Sgp
トラックバック:monster jam bad news travels fast
トラックバック:solana криптовалюта
トラックバック:Safe Ambien alternatives for insomnia
トラックバック:mitolyn buy
トラックバック:private servers
トラックバック:expensive motorcycles
トラックバック:трассир видеорегистратор
トラックバック:видеорегистратор автомобильный
トラックバック:Thanks
トラックバック:Best SEO Backlink Services
トラックバック:paito hk
トラックバック:paito macau
トラックバック:paito sdy
トラックバック:paito sgp
トラックバック:ada altcoin
トラックバック:live draw sdy
トラックバック:ok569
トラックバック:internet gate
トラックバック:колхоз тюнинг
トラックバック:blockchain life
トラックバック:вклады в втб
トラックバック:paito sdy lotto
トラックバック:Luxury1288
トラックバック:подвеска современного автомобиля
トラックバック:available at www.4mark.net`s website
トラックバック:магазин видеорегистраторов
トラックバック:планета путешествий
トラックバック:http://www.infinitymugenteam.com:80/infinity.wiki/mediawiki2/index.php/User:ErnestoBoi
トラックバック:black gay porn sex video – trans lesbian porn
トラックバック:777vi
トラックバック:компьютерная игра ill
トラックバック:internet packaging
トラックバック:trans lesbian porn xxx sex videos
トラックバック:internet. hicks
トラックバック:Mobile Applications in Iraq
トラックバック:bitcoin price march 22 2025
トラックバック:компьютерные игры хоррор
トラックバック:รายละเอียดเพิ่มเติม
トラックバック:KoryoGaming
トラックバック:Innotox
トラックバック:xrumer скачать
トラックバック:zencortex sale
トラックバック:altcoin season
トラックバック:Ad Free YouTube Video Downloader
トラックバック:diyarbakıR escort
トラックバック:777KING
トラックバック:paito hk lotto
トラックバック:Diyarbakir Escort bayan
トラックバック:новые казино для начинающих
トラックバック:риа новости мир
トラックバック:강남룸싸롱
トラックバック:เพิ่ม Like เฟซบุ๊ก
トラックバック:гаджет про
トラックバック:купить диплом вуза недорого
トラックバック:подключить смартфон к ноутбуку
トラックバック:azul chocolate
トラックバック:motorcycle sneakers
トラックバック:DigestiStart
トラックバック:Download YouTube Videos Online
トラックバック:site here
トラックバック:рампель подвеска автомобиля
トラックバック:javhdpro.vip loạn luân
トラックバック:michael saylor bitcoin price prediction 2030
トラックバック:конструктор по робототехнике
トラックバック:blsp at
トラックバック:building
トラックバック:แลกไลค์เฟซบุ๊ก
トラックバック:escort diyarbakıR
トラックバック:top osrs private servers
トラックバック:เช่าแผงควบคุมเว็บปั้มไลค์ ครบจบในที่เดียวสำหรับนักการตลาด
トラックバック:ปั้มผู้ติดตามติ๊กต๊อก
トラックバック:ปั้มหัวใจ Twitter
トラックバック:pgs5000
トラックバック:Download youtube video
トラックバック:ไปยังหน้าเว็บ
トラックバック:Short-Term Pain Relief
トラックバック:posts
トラックバック:Snapchat Downloader
トラックバック:s8garden
トラックバック:Escorts in Clifton karachi
トラックバック:visit Yoomark
トラックバック:blogsmin
トラックバック:Stonegate Bitflow
トラックバック:VornethPro
トラックバック:BEE999
トラックバック:ปั้มผู้ติดตาม Twitter
トラックバック:777bd
トラックバック:Major Model
トラックバック:Immediate Growth
トラックバック:Sharechat Downloader
トラックバック:Immutable Azopt
トラックバック:EdgeX AI
トラックバック:Wealth JuxtapidBit
トラックバック:fast and secure hosting
トラックバック:Exion Edge
トラックバック:Robot Bulls
トラックバック:VisporaSeek
トラックバック:ดูเนื้อหาฉบับเต็ม
トラックバック:ทำไมต้องใช้บริการปั้มไลค์ ปั้มติดตาม?
トラックバック:Fexoriumpro
トラックバック:idxmovie
トラックバック:haloperidol for child
トラックバック:buy diazepam for child
トラックバック:Stabel Paycore
トラックバック:seo ทํายังไง
トラックバック:ปั๊มวิว Tiktok
トラックバック:angka keluar cambodia
トラックバック:pgslot888 free spins
トラックバック:เพิ่มวิว
トラックバック:quality-packs.com
トラックバック:Klonopin tablets for sale
トラックバック:rose toy
トラックバック:RonexReich
トラックバック:Buy Clonazepam Online PayPal
トラックバック:Buy Xanax Online
トラックバック:AccuTrader Alpha
トラックバック:Chain Kapidex Xp
トラックバック:Fester Vumon
トラックバック:AverionPrime 8.1
トラックバック:AlpexRich
トラックバック:Axiron Ai
トラックバック:Sereno Bitrow
トラックバック:Bondi Bitspire
トラックバック:Tresor Tradevia
トラックバック:บาคาร่า
トラックバック:Lucente Bitline
トラックバック:Cumbre Varnox
トラックバック:RonexisPro
トラックバック:with no hidden costs or sign-ups.Create a rare Solana address that turns heads with the free Solana vanity address generator. Whether for personal flair or professional branding
トラックバック:https://guideyoursocial.com/story5227365/no-cost-hyperlink-in-bio-gadget-for-creators-brand-names
トラックバック:Meteor Profit
トラックバック:basketball-Wetten.com
トラックバック:تابلو سازی سی او
トラックバック:AltruvelonixPro
トラックバック:ImmediateVision
トラックバック:Infinity Bitwave
トラックバック:online casino bonus
トラックバック:darts wett prognosen
トラックバック:live sdy pools
トラックバック:local sewer line repair
トラックバック:situs sarang188
トラックバック:http://new.jesusaction.org/bbs/board.php?bo_table=free&wr_id=569383
トラックバック:нурсултан софт
トラックバック:Alto Bitrow
トラックバック:foods without cooking
トラックバック:Akil Finlore
トラックバック:caluanie muelear oxide
トラックバック:Proxel Bit
トラックバック:Riqueza Max AI
トラックバック:Solvarentia
トラックバック:BlorBytAi
トラックバック:Boltrix Venark
トラックバック:Unlim быстрые выплаты
トラックバック:bookmark-vip.com
トラックバック:Snabb Fluxrad
トラックバック:WertalmPro
トラックバック:Movistar Fusión
トラックバック:Drowentix
トラックバック:sushiswap halal or haram
トラックバック:Teds Woodworking
トラックバック:best poker sites
トラックバック:Zawaya AI
トラックバック:RexoralFin
トラックバック:Neethu’s Academy Medcity International Academy Tiju’s Academy
トラックバック:RichbertPro
トラックバック:re-fashion.co.uk
トラックバック:legit porn site blog
トラックバック:www.cliftonpark.org.uk
トラックバック:танк тюнинг
トラックバック:apple pay casinos
トラックバック:OkoraVisitPro
トラックバック:Trackingkolab
トラックバック:quickwinn.de
トラックバック:Épure Paylen
トラックバック:pictures of most beautiful women in the world
トラックバック:Kravonlixia
トラックバック:crypto market news april 19 2025
トラックバック:sufficiently
トラックバック:FEXOVION
トラックバック:mathematische Wettstrategie
トラックバック:bokep tobrut
トラックバック:Giết người hiếp dâm
トラックバック:paxg криптовалюта
トラックバック:소액결제 현금화
トラックバック:Buy Ambien Online with Fast Shipping
トラックバック:Lorazepam Price Online
トラックバック:Immediate Luminary
トラックバック:Solv Klarbit
トラックバック:новости мир сегодня
トラックバック:Senvix Plattform
トラックバック:Nordic Future AI
トラックバック:Stahlwandpools
トラックバック:Geltipatmex
トラックバック:68win trang chủ
トラックバック:13win đăng nhập
トラックバック:центр здоровья и красоты
トラックバック:superclone service
トラックバック:Güven Fundex
トラックバック:Druvaxio
トラックバック:lừa đảo campuchia
トラックバック:Unavex Platform
トラックバック:Summit Edge Ventures
トラックバック:Exacto Tradelux
トラックバック:chicago world news
トラックバック:名古屋市東区 リフォーム相談
トラックバック:Wettanbieter online
トラックバック:Vortex Bitriver
トラックバック:GoldStream Capital
トラックバック:https://fellowfavorite.com/story21391235/what-to-expect-at-your-therapeutic-massage-session-amta
トラックバック:정보이용료현금화
トラックバック:Vorentlavia
トラックバック:raffi777
トラックバック:buy wltq crypto
トラックバック:meteora exchange
トラックバック:https://skitterphoto.com
トラックバック:FintrexPrime 2.9
トラックバック:Sterk Flowdex
トラックバック:дизайн мебель сызрань
トラックバック:мебель холл сызрань
トラックバック:Stream Atarax Neo
トラックバック:독학기숙
トラックバック:новый секс-сайт с Дези com
トラックバック:relevant {material
トラックバック:pancakeswap graphql
トラックバック:LimoFamoPro
トラックバック:стеклоочистители osawa
トラックバック:KlavexorPro
トラックバック:микрофон realtek не подключено ноутбук
トラックバック:HexaTrade
トラックバック:Apendraxa
トラックバック:available at sites.suffolk.edu`s website
トラックバック:AffinexisAgent
トラックバック:Blackwood Gainflow
トラックバック:GasPipe AI
トラックバック:online casino games
トラックバック:best bitcoin gambling sites
トラックバック:Immediate Bitwave
トラックバック:Beluntraxis
トラックバック:Margin Rivou
トラックバック:new crypto casinos
トラックバック:Fintrex Prime 2.9
トラックバック:albany ny criminal defense attorney
トラックバック:Boreal Tradex Review
トラックバック:list of crypto gambling sites
トラックバック:Seguro Bitline
トラックバック:Velar Paynex
トラックバック:đòi tiền chuộc campuchia
トラックバック:казино флагман официальный сайт
トラックバック:e-zigarettenonline
トラックバック:bestenezigaretten
トラックバック:vapeprodukte
トラックバック:https://smmhub88-1.hashnode.dev/smmhub88-1-1-1-1-1
トラックバック:Zarios Platform
トラックバック:https://glucksspiralede.de/
トラックバック:Fundspire Axivon
トラックバック:Paito Harian China
トラックバック:available at users3.smartgb.com`s website
トラックバック:Deutsche Sportwetten Gmbh
トラックバック:Rovilixio
トラックバック:chillbetbr.top
トラックバック:Qualityassurance
トラックバック:corporate gift printing
トラックバック:อ่านต่อ
トラックバック:казино Баунти регистрация
トラックバック:мобильная версия ФаирСпин казино
トラックバック:казино Эльдорадо регистрация
トラックバック:Brillx casino официальный
トラックバック:казино F1 официальный сайт
トラックバック:Jetton Games casino официальный
トラックバック:Драгон Мани казино зеркало
トラックバック:Plata Boost
トラックバック:вход в Кент казино
トラックバック:tvsocialnews.com
トラックバック:Switch Avapro Hex
トラックバック:казино Чемпион Слотс
トラックバック:Oxiris Platform
トラックバック:Dextronix Bot
トラックバック:global asia printings singapore
トラックバック:MixelionAI
トラックバック:https://bursaescorttr.org/author/miquelcrain/
トラックバック:arthur1j67t.elbloglibre.com
トラックバック:официальный сайт Блитц казино
トラックバック:Arbitrox
トラックバック:Sûreté Tradecore
トラックバック:Finovantrex
トラックバック:Болливуд казино бездепозитный бонус
トラックバック:Almax Capital Erfahrungen
トラックバック:best online casino games
トラックバック:เพิ่มผู้ติดตามแท้
トラックバック:Boreal Tradex
トラックバック:Luce Corex
トラックバック:казино Клубника официальный сайт
トラックバック:казино рулетка онлайн
トラックバック:официальный сайт Буй казино
トラックバック:Голдфишка казино официальный
トラックバック:Nexonix Profit
トラックバック:amd crypto miner
トラックバック:top casino sites
トラックバック:Fundspire Axivon Review
トラックバック:auto gaz Warszawa
トラックバック:Resident
トラックバック:Stream Fertinex Cap Review
トラックバック:Хайп казино официальный
トラックバック:Vorenixio Recensione
トラックバック:bokep mamak kau ngentot anjing
トラックバック:seguridad en tu casa
トラックバック:https://my.clickthecity.com/phfuncom
トラックバック:trentonghh57.life3dblog.com
トラックバック:fl studio 20 torrent
トラックバック:https://www.bitsdujour.com/profiles/RTXaR3
トラックバック:bookmarkjourney.com
トラックバック:Reviews
トラックバック:zkreciul01
トラックバック:maps-account.us.com lừa đảo công an truy quét cấm người chơi tham gia
トラックバック:https://bookmarkyourpage.com/
トラックバック:vivarocasino-am.top
トラックバック:รีวิว pgslotcash ล่าสุด
トラックバック:męski fryzjer w Warszawie
トラックバック:learnplasma.org lừa đảo công an truy quét cấm người chơi tham gia
トラックバック:goyard belts barneys
トラックバック:homoclimbtastic.com lừa đảo công an truy quét cấm người chơi tham gia
トラックバック:johnny hardcore Xxx pretty jasmine Fuck porn
トラックバック:Fontan официальный
トラックバック:IMMIGRATION CONSULTANTS IN KOCHI
トラックバック:Margin Rivou Platform
トラックバック:https://pulawska-warszawa.waw.pl
トラックバック:anderson0i57r.bloggazza.com
トラックバック:เพิ่ม Like ทวิตเตอร์
トラックバック:pgslotcash
トラックバック:скачать 7К казино
トラックバック:Biodynamix Joint Genesis Reviews
トラックバック:vsbet lừa đảo tiền khách hàng
トラックバック:mylapka.com mua sữa tăng cân
トラックバック:sa168 vip
トラックバック:Он икс казино бонусы
トラックバック:Леон казино зеркало
トラックバック:visit Linqto
トラックバック:scam 8xbet cambodia
トラックバック:Igenics reviews
トラックバック:Investrix AI
トラックバック:Santamonica Study Abroad Pvt. Ltd.
トラックバック:сайт Slott casino
トラックバック:deactivate.uk.net lừa đảo công an truy quét cấm người chơi tham gia
トラックバック:Provadent Reviews
トラックバック:Pineal Guardian reviews
トラックバック:Neuro Energizer Reviews
トラックバック:omg 168
トラックバック:Genius Wave
トラックバック:five.us.com lừa đảo công an truy quét cấm người chơi tham gia
トラックバック:Gain Mode AI
トラックバック:Maple Wealth
トラックバック:amb slot
トラックバック:Yoga Terapia
トラックバック:Zarios
トラックバック:QuantivexaPro
トラックバック:NeuraNorth AI
トラックバック:Zeker Montex
トラックバック:Neyroxydix
トラックバック:Token Tact
トラックバック:Redleaf Fundex
トラックバック:Belqorix
トラックバック:แลกไลค์ แลกติดตาม – โตไวแบบปลอดภัย
トラックバック:Vorenixio
トラックバック:Vape Online
トラックバック:Stripchat Free Tokens
トラックバック:зеркало казино Сукааа
トラックバック:avant consulting
トラックバック:Spiritualnost
トラックバック:Gartenpool Gartenpool Gartenpool Gartenpool Gartenpool Gartenpool Gartenpool Gartenpool Gartenpool Gartenpool Gartenpool Gartenpool Gartenpool Gartenpool Gartenpool Gartenpool Gartenpool Gartenpool Gartenpool Gartenpool Gartenpools Gartenpools Gartenpools
トラックバック:data sdy
トラックバック:Leale Investi
トラックバック:Artifluxon
トラックバック:ugotbling.com bảo hiểm lừa đảo
トラックバック:https://aneurine791bcc3.bmswiki.com/5516817/the_definitive_guide_to_수원_오피_바로가기
トラックバック:Model Kantrex 500
トラックバック:Billionaire Trade
トラックバック:WhatsApp網頁版
トラックバック:bitcoin bank breaker
トラックバック:Logic Adipex Sys
トラックバック:Zevcap App AI
トラックバック:Legacy Bitfundex
トラックバック:Fidato Bitvista
トラックバック:สล็อตออนไลน์
トラックバック:แอพหาคู่คนไทย
トラックバック:my wife took cialis
トラックバック:Кракен даркнет
トラックバック:Giusto Tradecore
トラックバック:Granit Nexbit
トラックバック:online casino roulette
トラックバック:e2bet affiliate login
トラックバック:Boost Eprex Fin
トラックバック:satte ki khabar
トラックバック:XeltoMatrix
トラックバック:InfluxCode
トラックバック:Neyrolomarix
トラックバック:Vovilixio
トラックバック:best site to buy steroids
トラックバック:Thalen EquiBridge
トラックバック:click here to visit Newsnetwork9.Wordpress.com for free
トラックバック:live draw taiwan
トラックバック:https://biglemon.ru/forum/index.php?PAGE_NAME=profile_view&UID=3676
トラックバック:Dřevěné cívky na kabely prodej
トラックバック:br4betbr.top
トラックバック:SPAM
トラックバック:Snaptrader AI
トラックバック:Adipex for weight loss
トラックバック:1betone.de
トラックバック:LexavoraMax
トラックバック:https://gbetssa.co.za
トラックバック:Redgate Bitcore
トラックバック:Nauw Toezicht
トラックバック:Lueur Flowdex
トラックバック:Generic Adipex Online
トラックバック:Stratix Boom
トラックバック:bitcoin gambling sites
トラックバック:Norlios Platform
トラックバック:Flectrek Inmediato
トラックバック:casino slots online
トラックバック:norsk casino på nett
トラックバック:Solvex Gain 7.9 Ai
トラックバック:Spot Hiberix Opt
トラックバック:آدرس دانشگاه علوم پزشکی بوشهر
トラックバック:Puro Bitline
トラックバック:xnxx mom
トラックバック:http://forums.shlock.co.uk/viewtopic.php?f=2&t=325513
トラックバック:Vorolanex
トラックバック:Buy Adderall 10mg Online
トラックバック:https://ucubeler.org/showthread.php?tid=127742
トラックバック:roof replacement company
トラックバック:AfriQuantumX
トラックバック:code promo 1xbet gratuit
トラックバック:https://lrnews.mirtesen.ru/blog/43983101538/Nevidimaya-zaschita-kamuflyazh
トラックバック:sunbetapp.co.za
トラックバック:KlasteFin
トラックバック:buy indomethacin near me
トラックバック:XN88
トラックバック:파워맨 직구
トラックバック:https://boosty.to/laraq/posts/d168acbe-a851-4375-8e81-f3d5dd761892
トラックバック:macauslot88
トラックバック:FREE VIAGRA
トラックバック:https://one-casino1.nl
トラックバック:Major Models
トラックバック:tt88 game
トラックバック:online slots for real money
トラックバック:bk8
トラックバック:online slots real money
トラックバック:Anchor Bitrow
トラックバック:mua bảo hiểm tai nạn
トラックバック:svenska casino
トラックバック:burberry sling bag for women
トラックバック:crypto casino
トラックバック:best female viagra
トラックバック:bokeb tante indo
トラックバック:Wervion Platform
トラックバック:seo company
トラックバック:Paito Warna HK Lotto
トラックバック:подписчики в группу вк
トラックバック:make-up hamburg
トラックバック:Upholstery cleaning
トラックバック:Dinamico Finlore
トラックバック:ปั้มไลค์ Facebook
トラックバック:escorts in Copenhagen
トラックバック:微信 搜狗
トラックバック:Best Place to Buy Valium Online
トラックバック:AI Arbitrage Scam
トラックバック:experte montagequalität
トラックバック:OrtevalexAi TEST
トラックバック:bürocontainer
トラックバック:Wexley Vaultix Legit Or Not
トラックバック:недвижимость в дубае
トラックバック:Finotraze Review
トラックバック:Wervion
トラックバック:Soho303
トラックバック:Ruhig Finlore
トラックバック:51 game
トラックバック:QuantumWealth Capital
トラックバック:Velar Paynex Legit Or Not
トラックバック:Clarté Nexive
トラックバック:fence replacement Windsor
トラックバック:Fundspire
トラックバック:code promo 1xbet hyper bonus
トラックバック:dewapadel
トラックバック:立川 ダンス スクール
トラックバック:kra27 cc
トラックバック:Trygg Bitrow
トラックバック:Paito Warna Sdy Lotto
トラックバック:Lottoup ดีไหม
トラックバック:LucraBot GPT
トラックバック:町田 ダンス スクール
トラックバック:аудит поставщика
トラックバック:Gunst Paymar Ervaringen
トラックバック:Helder Flowdex Avis
トラックバック:Ruhig Finlore Avis
トラックバック:Clarté Nexive Avis
トラックバック:Aurum Fix Scam
トラックバック:https://wazambacasinoapp.de/
トラックバック:казино Водка регистрация
トラックバック:go88
トラックバック:888new
トラックバック:live video chat
トラックバック:DSH Homes and Pools inground pool installation near me
トラックバック:montageprüfung gutachten
トラックバック:bokep hijab bokep terbaru bokep bokep indo terbaru link bokep indo bokep indo baru bokeb indo terbaru bokep tante jilbab bugil jilbab porn bokepindo terbaru hijab bugil link bokep terbaru bokep ukhti lingbokep bokep ukhty link bokep ling bokep bokep sma b
トラックバック:my free cams
トラックバック:divorce lawyer darwiin
トラックバック:Dilaudid Pills for sale Online
トラックバック:viktorzi
トラックバック:singha89
トラックバック:check out this blog post via u.osu.edu
トラックバック:เกมสล็อต
トラックバック:cantaloupe
トラックバック:how to tell if coach umbrella is real
トラックバック:check out this blog post via coolpot.com
トラックバック:adsmin
トラックバック:Business Funding
トラックバック:pool kaufen
トラックバック:live webcam girls
トラックバック:about-anchor
トラックバック:jaosua789 เกมใหม่ล่าสุด
トラックバック:Witty car-themed hoodies
トラックバック:glory casino mobile
トラックバック:Admiralcasino-Hr.Top
トラックバック:plataforma 1win.
トラックバック:비아그라 인터넷구입
トラックバック:cheap sex webcams
トラックバック:온라인 약국 비아그라
トラックバック:play 1win India
トラックバック:best online casino bonus
トラックバック:jaosua789
トラックバック:apostaganha-br.top
トラックバック:escort service in hinjewadi
トラックバック:Thuốc kích dục
トラックバック:mua bảo hiểm y tế
トラックバック:bảo hiểm y tế là gì
トラックバック:Margin Rivou Review
トラックバック:https://euromillions-ch.top/
トラックバック:InvestHub 3.0 Erfahrungen
トラックバック:XenovixPeak 5.8 Ai
トラックバック:sarang188 login
トラックバック:new casino online
トラックバック:Switch Amrix Cap Ervaringen
トラックバック:Zevrio Capiture TEST
トラックバック:LexioFin Legit Or Not
トラックバック:Ledger wallet official
トラックバック:Helder Flowdex Legit Or Not
トラックバック:Net Rowdex
トラックバック:비아그라 약국 판매 가격
トラックバック:Purchase Tramadol Online
トラックバック:free sex chat
トラックバック:هندسة معمارية
トラックバック:innotx
トラックバック:https://postcodeloterijs.nl/
トラックバック:abadi777
トラックバック:Cheap cleaning services Edinburgh
トラックバック:armada777
トラックバック:Buy Adderall Online Cheap USA
トラックバック:Discount Adderall Online Pharmacy USA
トラックバック:Sérénor Paylix
トラックバック:wohnwagen schränke folieren wohnwagen bad renovieren wohnwagen bad pimpen wohnwagen arbeitsplatte folieren wohnmobil möbel folieren wohnmobil klebefolie innen wohnmobil innenverkleidung erneuern wasserfeste platten für dusche wandpaneele marmoroptik wa
トラックバック:Arbitrox Opiniones
トラックバック:Meteor Profit Recensione
トラックバック:slotmagiecasino2.de
トラックバック:HarvexFin Avis
トラックバック:Norlios Platform Opinie
トラックバック:Margin Rivou Scam
トラックバック:wancoy 168
トラックバック:Lueur Flowdex Avis
トラックバック:Westrise Corebit Avis
トラックバック:Order Methadone Pills near me
トラックバック:Private Jet Charter
トラックバック:Wexley Vaultix Review
トラックバック:Sûreté Tradecore Review
トラックバック:Meteor Profit TEST
トラックバック:Lucent Markbi Legit Or Not
トラックバック:แบรนด์ pgslot88
トラックバック:bo
トラックバック:Vision Hiberix 300
トラックバック:sunwolves.shop
トラックバック:GoApotik big ass
トラックバック:Is the Crave Burner worth its price tag?
トラックバック:https://elottobelgique.be
トラックバック:小倉南区 整体
トラックバック:Calvenridge Trust Anmeldelse
トラックバック:best canada online casino
トラックバック:BitrenixPulse 8.3 Ai
トラックバック:porn
トラックバック:Ruhig Finlore Erfahrungen
トラックバック:ราชภัฏ
トラックバック:stahlwandbecken pool pool stahlwandbecken pool holz holzpool
トラックバック:pool aufstellbar
トラックバック:Arbitrox Erfahrungen
トラックバック:best stained concrete austin
トラックバック:OrtetenulAi Erfahrungen
トラックバック:Immutable Azopt Reseña
トラックバック:reliable roof leak repairs
トラックバック:Margin Rivou Legit Or Not
トラックバック:coffeeacademy.com.my
トラックバック:bokep ojol
トラックバック:Exowentas Erfahrungen
トラックバック:casino utan licens
トラックバック:Redmonts Coindrex Scam
トラックバック:Etherealux Smart Opiniones
トラックバック:Redmonts Coindrex Erfahrungen
トラックバック:Riqueza Tradewise
トラックバック:Calvenridge Trust Reseña
トラックバック:LuvirexBit
トラックバック:ưng hoàng phúc mb66
トラックバック:https://diamonds.uk.com/
トラックバック:prediksi bokep
トラックバック:play 1win games
トラックバック:https://yzx12.za.com
トラックバック:mamak kau gacor
トラックバック:1win betting India
トラックバック:canadian online casinos
トラックバック:Harmony Bitspire
トラックバック:küchenmontagegutachten
トラックバック:1xbet casino promo code ph
トラックバック:Numerous
トラックバック:1xbet promo code registration
トラックバック:code promo 1xbet 2026 vanuatu
トラックバック:meilleur code promo 1xbet
トラックバック:казино
トラックバック:arbeitsplatte folieren küche arbeitsplatte folie küchen arbeitsplatte folieren arbeitsplatte küche renovieren arbeitsplatte küche neu folieren arbeitsplatte neu gestalten arbeitsplatte bekleben folie arbeitsplatte küche folie folie für küchenarbeit
トラックバック:услуги по перевозке грузов
トラックバック:404
トラックバック:treppen klebefolie folie für treppenstufen klebefolie treppe folie treppenstufen klebefolie für treppen
トラックバック:мега сайт тор ссылка
トラックバック:Spray Tan Reston VA
トラックバック:yoga clothes
トラックバック:Flick Edge TEST
トラックバック:Open cannabis dispensary near U Street
トラックバック:NexioTrust TEST
トラックバック:Opulatrix Erfahrungen
トラックバック:Bellwetherpek Recensione
トラックバック:Blackrose Finbitnex Ervaringen
トラックバック:Swap 700 Lotemax Review
トラックバック:ganga club
トラックバック:executive search мастер-класс
トラックバック:online pokies australia
トラックバック:Quantum Trade
トラックバック:Bellwetherpek
トラックバック:https://rumiki.wapchan.org/w/index.php?title=User:LorraineParadis
トラックバック:Qorvantrex
トラックバック:Trusted Pharmacy to Buy Ativan Online
トラックバック:ufabet ทางเข้า
トラックバック:казино онлайн
トラックバック:aufstell pool aufstellpool aufstellpool günstig kaufen aufstellpool kaufen aufstellpool stahlwand freistehend aufstellpool rechteckig
トラックバック:küche folieren küchenfronten folieren küchenschränke folieren möbelfolie küche
トラックバック:digi 995 coloring book
トラックバック:pink salt trick
トラックバック:https://ljz.mx/15/08/2025/metodos-de-pago-disponibles-en-pin-up-mexico-para-depositos-y-retiros/
トラックバック:idola5000
トラックバック:BOKEP ONLINE
トラックバック:FDA Approved Alprazolam Online
トラックバック:vuse go vuse go pods vuse go reload vuse go wann leer vuse go wie viel nikotin vuse go zero
トラックバック:montage gutachten gutachter montagearbeiten sachverständiger montage montageprüfung gutachten
トラックバック:wahuitspp.com.cn
トラックバック:Ambien for Sale
トラックバック:XenovixPeak 5.8 Ai Rescenion
トラックバック:Opulence Purezza Reseña
トラックバック:tiney house
トラックバック:online casino ohne limit
トラックバック:178体育直播
トラックバック:Blackrose Finbitnex
トラックバック:Rikdom Bitrad
トラックバック:real money online slots
トラックバック:prosta vive
トラックバック:Åben Cryptalor
トラックバック:Zeker Paycore Ervaringen
トラックバック:https://www.panenka.org/reportajes/consejos-para-encontrar-casinos-con-retiros-rapidos-y-seguros-como-pin-up/
トラックバック:Ravilixio Recensione
トラックバック:Arctic Valtrix Review
トラックバック:Summit Luxeron Recensione
トラックバック:Buy Adipex 37.5mg Online
トラックバック:StarFinance Review
トラックバック:casino online suisse
トラックバック:Yupoo Hermes
トラックバック:Buy Xanax Online with PayPal
トラックバック:Buy Tramadol 200mg Online
トラックバック:BTC Income Avis
トラックバック:http://theadultstories.net/viewtopic.php?t=571561
トラックバック:https://rainvintage.in.net/
トラックバック:Ærlig Bitspire
トラックバック:Yupoo Hermes
トラックバック:Fundspire Axivon Erfahrungen
トラックバック:Track Celexa 600 Recensione
トラックバック:Orvixent Review
トラックバック:Tridafoks Erfahrungen
トラックバック:wieviel wiegt eine zigarette tabak zum stopfen stopftabak 30g tabak wie viele zigaretten was ist vuse go vuse go vuse go wie viel nikotin zigaretten online kaufen zigaretten online zigaretten kaufen zigaretten
トラックバック:winterfeste pools
トラックバック:Vision Avage X
トラックバック:bokep ibu dan anak
トラックバック:bokep babi
トラックバック:daftar slot777 online
トラックバック:탑플레이어포커 머니상
トラックバック:Buy Tramadol Online Next Day Delivery
トラックバック:best online roulette
トラックバック:Track Imitrex Fin
トラックバック:Infineon Invest TEST
トラックバック:Ganlivex
トラックバック:Fidèle Fundex
トラックバック:bokep anjing perawan
トラックバック:Stäbel Gainetra TEST
トラックバック:Vumon Capital Erfahrungen
トラックバック:Luce Corex Recensione
トラックバック:Spot Herplex 2U Opiniones
トラックバック:check that
トラックバック:bici da carico per bambini
トラックバック:Dinamico Finlore Análise
トラックバック:Spot Celexa X
トラックバック:Spike Iplex 600
トラックバック:cargo bike berlin
トラックバック:casino online schweiz
トラックバック:Meteor Profit Review
トラックバック:Rovixen Ai Erfahrungen
トラックバック:workers
トラックバック:el-ladcykel
トラックバック:Fermo Fluxor
トラックバック:Rico Monerix
トラックバック:Immediate WorsPro
トラックバック:https://systemcheck-wiki.de/index.php?title=Benutzer:UrsulaConnolly
トラックバック:Arctic Valtrix
トラックバック:popbra login
トラックバック:แก้จมูกโอเพ่นด้วยกระดูกอ่อนหลังหูดีจริงไหม
トラックバック:Packers and Movers Noida to Bangalore Packers and Movers Noida to Chennai Packers and Movers Noida to Hyderabad Packers and Movers Noida to Mumbai Packers and Movers Noida to Patna Packers and Movers Noida to Ahmedabad Packers and Movers Noida to Goa Pack
トラックバック:whale tail therapy
トラックバック:https://rotativo.com.mx/deportes/bonos-bienvenida-en-casino-maya-palace-nuevos-jugadores-en-2025_1529317_102.html
トラックバック:coffee lover stickers
トラックバック:jackoff
トラックバック:nrf2
トラックバック:Packers and Movers Mumbai to Kolkata Packers and Movers Mumbai to Chennai Packers and Movers Mumbai to Hyderabad Packers and Movers Mumbai to Bangalore Packers and Movers Mumbai to Patna Packers and Movers Mumbai to Ahmedabad Packers and Movers Mumbai to
トラックバック:artis bokep china
トラックバック:text rephrasing tool
トラックバック:onewave
トラックバック:ดูข้อมูลเพิ่มเติม
トラックバック:https://about.me/rp888linkalternatif
トラックバック:Kern Luxeron
トラックバック:Frame Inomax Nx
トラックバック:Riqueza Tradewise Opiniones
トラックバック:https://smmhub88-1.hashnode.dev/roi
トラックバック:casino utan svensk licens
トラックバック:BlorBytAi TEST
トラックバック:39bet
トラックバック:cash for test strips
トラックバック:Harmony Bitspire Anmeldelse
トラックバック:online casino canada
トラックバック:Immutable Azopt Avis
トラックバック:OrtevalexAi Erfahrungen
トラックバック:Immediate Growth Erfahrungen
トラックバック:un sex cam
トラックバック:and there : www.noirs.art
トラックバック:online casino ontario
トラックバック:Chiarore Gainetra
トラックバック:Power Trades App
トラックバック:BTC Income Reseña
トラックバック:Birkin bag copper nails
トラックバック:boat operator
トラックバック:https://ngothoinhiem.gumroad.com/
トラックバック:Buy Alprazolam Online
トラックバック:https://dichvuseotop.quora.com/?invite_code=mEFmVLK5llxuSdEmBcko
トラックバック:Medical cannabis dispensary Dupont Circle Cannabis dispensary 1341 Connecticut Ave NW CBD shop near Dupont Circle DC Medical marijuana DC 20036 Cannabis near Embassy Row DC Best dispensary near Farragut North FireTuned dispensary Washington DC Cannabis st
トラックバック:Smart Stocks AI
トラックバック:internationalsoccerservices.com jav hd
トラックバック:pool aufstellpool
トラックバック:rainbet casino
トラックバック:jasa instagram ads judi adsicloud
トラックバック:https://ngothoinhiemeduvn.wixsite.com/ngothoinhiem
トラックバック:Sofortiger Aimex Trade
トラックバック:rossmould.ca scam google
トラックバック:klikbet5000
トラックバック:https://go-rainbet.com
トラックバック:chimney cleaning Seattle
トラックバック:https://savesandiegoopera.org/
トラックバック:omg168 slot game
トラックバック:iveboxfilm.com sex video
トラックバック:stahlwandpool rund stahlwandpool set stahl pool einbaupool poolfolie rund stahlbecken poolbecken achtformpool stahlwandpool teilversenkt rundpool aufstellbecken aufstell pool fertigpool stahlwandpool freistehend stahlwandbecken oval
トラックバック:Magyar Befektetési Vélemény
トラックバック:HarvexFin
トラックバック:point
トラックバック:Swap +50X Proair
トラックバック:การเสริมจมูกด้วยกระดูกอ่อนซี่โครงคืออะไร
トラックバック:Vurig Monerix Avis
トラックバック:Buy Kassina Senegalensis Toad Venom Online
トラックバック:Ashvale Coreflow Legit Or Not
トラックバック:Syair Sgp
トラックバック:rajasultan88
トラックバック:casino med svensk licens
トラックバック:national addiction helpline
トラックバック:ufa069
トラックバック:BlueQubit Scam
トラックバック:https://www.pinterest.com/zhouyifan938/_profile/
トラックバック:Track Kinrix 600
トラックバック:ExtraReich
トラックバック:Inmediato Nexavar
トラックバック:Insightful information
トラックバック:Regards I value
トラックバック:brasiliapg
トラックバック:Naked Url
トラックバック:folie für möbel klebefolie holzoptik möbelfolie selbstklebend
トラックバック:Endurancein.space
トラックバック:Assl.space
トラックバック:Monono.store
トラックバック:cosmetology school Des Moines
トラックバック:Webnode`s website
トラックバック:Immediate Edge Erfahrungen
トラックバック:Luxurywizard.space
トラックバック:rjslot88
トラックバック:available at www.ultraguest.com`s website
トラックバック:slot138
トラックバック:신용카드한도현금화
トラックバック:Forum Syair SGP
トラックバック:Forum Syair SDY
トラックバック:독학기숙학원
トラックバック:janetskiles.com scam money
トラックバック:http://wiki.thedragons.cloud/index.php?title=User:Maureen39L
トラックバック:Ganga Club
トラックバック:www.symbaloo.com
トラックバック:Naga303
トラックバック:water heater services near me
トラックバック:Luxury1288
トラックバック:dior sauvage dupe
トラックバック:raindrop.io post to a company blog
トラックバック:kokitoto login
トラックバック:https://hubsocials.blogspot.com/2025/09/2ads4u.io-comments.html
トラックバック:JAV PRON
トラックバック:kra36
トラックバック:pug4d
トラックバック:renbridge
トラックバック:Recycled
トラックバック:roobet
トラックバック:roobet casino
トラックバック:funnyvideo
トラックバック:app for puppy training
トラックバック:Zeno Flow Engine Avis
トラックバック:best online casino uk
トラックバック:slot ibu hamil
トラックバック:Finxor GPT Avis
トラックバック:texas555
トラックバック:Net Rowdex Avis
トラックバック:بهترین برنزر برای پوست سبزه مای میکاپ استوری
トラックバック:omgprice9.cc
トラックバック:TokenCore Erfahrungen
トラックバック:VurinestaAi
トラックバック:SEO BLACKHAT
トラックバック:Order Tramadol Online
トラックバック:no kyc casinos
トラックバック:online casino sign up bonus
トラックバック:AeveniroxAi
トラックバック:best online casino australia
トラックバック:online casino australia real money
トラックバック:hotels in Burton upon Trent
トラックバック:Country Creek Animal Hospital veterinarian Allen TX
トラックバック:Official Link
トラックバック:kettestai
トラックバック:Bitnex Crestfort Ervaringen
トラックバック:Spot Cormax Hub
トラックバック:free porn hub .com
トラックバック:link phising
トラックバック:$20 minimum deposit casinos
トラックバック:Quantalysus AI Avis
トラックバック:AYUTOGEL
トラックバック:Taito Markbit arvostelu
トラックバック:online casino gambling
トラックバック:mn88
トラックバック:www.storeboard.com
トラックバック:online casino sites
トラックバック:buy loperamide
トラックバック:экстренный вывод из запоя в Краснодаре
トラックバック:Noble Flowdex Avis
トラックバック:tottri near me
トラックバック:phim sex ngoại tình
トラックバック:Stake IPL betting
トラックバック:Gaming News
トラックバック:mua bán vũ khí
トラックバック:ketbilietai
トラックバック:Kudos
トラックバック:explained
トラックバック:situs scam
トラックバック:Profit Capital AI Review
トラックバック:CalvenRidge Trust Review
トラックバック:Nordiqo
トラックバック:Trade Fortune AI Scam
トラックバック:buy borraginol M
トラックバック:Senvix Plattform Erfahrungen
トラックバック:Stærk Paycore Anmeldelse
トラックバック:Senvix Plattform TEST
トラックバック:Redwood Fundrelix Scam
トラックバック:Trezik Forge GPT Erfahrungen
トラックバック:Index Chantix 100
トラックバック:BlorBytAi Erfahrungen
トラックバック:Helder Valtrix Ervaringen
トラックバック:slottower8
トラックバック:tt88
トラックバック:situs gay
トラックバック:Vire Elvoxe
トラックバック:chanel west coast video cowboy hat
トラックバック:Frostmark Tradewise Anmeldelse
トラックバック:Xivora Lunex
トラックバック:Trade 9.0 SiloPro
トラックバック:combining fun and study for language learning
トラックバック:e-scooter shop
トラックバック:VolksMark
トラックバック:เว็บสล็อต pgslotcash แตกง่าย
トラックバック:truong noi tru tot nhat tai tphcm
トラックバック:https://kraken-espana.es/
トラックバック:หาคู่แต่งงาน
トラックバック:ปั้มซับ YouTube
トラックバック:Gull Bitlinje Anmeldelse
トラックバック:buy oxycodone online overnight
トラックバック:Noble Flowdex
トラックバック:simply click www.cap-rs485-nhap-khau.xyz
トラックバック:Wealthicator
トラックバック:âm mưu chiến tranh
トラックバック:DuxironPro
トラックバック:Lumino Valtrix Recensione
トラックバック:What is rice
トラックバック:Lampo Bitmark
トラックバック:Immediate Zenx Review
トラックバック:sga123
トラックバック:Vumon Capital TEST
トラックバック:sex cùng gái
トラックバック:Westwood Bitnova
トラックバック:standup pool
トラックバック:Grevial Platform
トラックバック:FenorixTrader 8.4 AI
トラックバック:Sofortiger Aimex Trade TEST
トラックバック:audit services singapore
トラックバック:рейтинг прозрачных казино
トラックバック:Finxor GPT
トラックバック:R777
トラックバック:real money online casino canada
トラックバック:แอดปั้ม
トラックバック:Volume Nine
トラックバック:Copy Expert
トラックバック:urgent care vet
トラックバック:bokep erin bugis
トラックバック:Web Hosting & Domains Names Registration in Lebanon
トラックバック:bulios.com
トラックバック:Argento Luxeron
トラックバック:Facelifting Frankfurt Facelifting Frankfurt Facelifting Frankfurt Facelifting Frankfurt Facelifting Frankfurt Facelifting Frankfurt Facelifting Frankfurt Facelifting Frankfurt Facelifting Frankfurt Facelifting Frankfurt Facelifting Frankfurt Facelifting F
トラックバック:Rapid Casino
トラックバック:vanilla gourmand perfume
トラックバック:TwisProfit Opinie
トラックバック:hokibos
トラックバック:ExoviaroFund Erfahrungen
トラックバック:online casino sverige
トラックバック:Fortunix AI Review
トラックバック:Estable Biturex
トラックバック:miami yacht rentals
トラックバック:Scatto Bitrail
トラックバック:MEXQUICK
トラックバック:online casino reviews
トラックバック:Northgate Valtrix Review
トラックバック:Argent Cresvia Avis
トラックバック:부산철거
トラックバック:kontol slot
トラックバック:totoakurat
トラックバック:Live Draw Cambodia
トラックバック:buy valium without prescription
トラックバック:Escort service in Jaipur city
トラックバック:catering recruitment agencies
トラックバック:Wow
トラックバック:welcome bonus casino
トラックバック:cialis
トラックバック:slot loket88
トラックバック:cnchipdepot
トラックバック:buy ativan no prescription
トラックバック:ปั้มไลค์เร็วที่สุด
トラックバック:Flectorio Inmediato Reseña
トラックバック:Azione Kivo Recensione
トラックバック:hidden cam catches sex
トラックバック:Tavosdex App Review
トラックバック:Klar Bitrow Avis
トラックバック:Vision Keflex Fin Avis
トラックバック:Pewny Fundaryx Ervaringen
トラックバック:Ravilixio
トラックバック:Lucent Markbit Review
トラックバック:online swiss casino
トラックバック:admin
トラックバック:BitBenefit App Legit Or Not
トラックバック:Mon Petit Placement Avis
トラックバック:Solid Max Avis
トラックバック:Flod Fundline Anmeldelse
トラックバック:خرید یو پی اس
トラックバック:audit firm singapore
トラックバック:ket bilietai
トラックバック:pool holz
トラックバック:Futuro Token
トラックバック:Zolpidem USA overnight shipping
トラックバック:Live Draw SDY Lotto
トラックバック:webpage
トラックバック:arjuna189
トラックバック:Renew & Restore Exterior Cleaning
トラックバック:FinAITrix Core Legit Or Not
トラックバック:Bergkraft Fluxor
トラックバック:Trevalnoriax Avis
トラックバック:Ravenfort Bitfund Legit Or Not
トラックバック:Lumetrix AI Erfahrungen
トラックバック:Fidele Fundex Avis
トラックバック:hospitality executive recruiter
トラックバック:Sterk Valtrix
トラックバック:prabowo pemerintahan goblog
トラックバック:casino på nätet
トラックバック:Clarté Vaultrex
トラックバック:Meteor Profit Scam
トラックバック:online casinos australia
トラックバック:led signages singapore
トラックバック:Syair Sdy
トラックバック:frohes neues jahr frohes neues jahr 2026 grüße neujahr guten rutsch neujahrsgrüße neujahrsgrüße 2026 neujahrswünsche 2026
トラックバック:Trixo Fund Review
トラックバック:kraken зеркало
トラックバック:twine
トラックバック:kylesfootballcards
トラックバック:stahlwandpool mit sandfilteranlage stahlwandpool mit sandfilteranlage stahlwandpool mit sandfilteranlage stahlwandpool mit sandfilteranlage rundpools rundpools stahlwandpool kosten stahlwandpool kosten aufstellpool winterfest kaufen aufstellpool winterfes
トラックバック:best casino online
トラックバック:DynarisFlex 7.1 Ai Reseña
トラックバック:abgnew.info
トラックバック:Digitalremodel
トラックバック:http://aforum14.jipto.ru/showthread.php?tid=50704
トラックバック:E-Liquids Deals
トラックバック:ket testai
トラックバック:Fairholt Cryptrix Legit Or Not
トラックバック:Belotrixio Recensione
トラックバック:Finxor GPT Legit Or Not
トラックバック:sesame oil regrowth
トラックバック:stahlwandpool rund winterfest stahlwandpool komplettset stahlwandpool komplettset mit sandfilteranlage
トラックバック:Suncor Trade
トラックバック:שיפוצניק
トラックバック:office
トラックバック:Segno Revenix
トラックバック:online casino real money
トラックバック:R777
トラックバック:bokep slot
トラックバック:Yupoo Chanel
トラックバック:slot qris
トラックバック:Oberlidstraffung Frankfurt
トラックバック:vodka casino
トラックバック:TG88
トラックバック:service expert
トラックバック:송파가라오케
トラックバック:Xanax Online Delivery USA
トラックバック:bathroom glass divider
トラックバック:new online casinos canada
トラックバック:situs bokep paling resmi
トラックバック:khudokormov igor vyacheslavovich family
トラックバック:rj45
トラックバック:Check out new cardi nicki jay electronica taylor swift out now
トラックバック:منصة
トラックバック:perfume quiz
トラックバック:wetten bonus Code ohne Einzahlung
トラックバック:situs bokep
トラックバック:倚天2私服一条龙
トラックバック:cfd brokerage
トラックバック:Official Document Verification
トラックバック:sidak bos joshoki tangkap saja!
トラックバック:ai app
トラックバック:เว็บ pgslot99
トラックバック:88aa
トラックバック:pg888 เกมใหม่ล่าสุด
トラックバック:Wohncontainer
トラックバック:cheap knock off perfumes with good quality
トラックバック:prescription for adderall online
トラックバック:ReveniX Recensione
トラックバック:Eternal Lunesta Avis
トラックバック:bestchange
トラックバック:adderall purchase
トラックバック:เว็บสล็อต sbfplay99 แตกง่าย
トラックバック:new casinos online
トラックバック:Shinrai Invexus
トラックバック:Riqueza Vaultro
トラックバック:beste casino norge
トラックバック:Mevryon
トラックバック:Australia Degree Attestation
トラックバック:BrintelexisPro
トラックバック:Buy Zolpidem Online
トラックバック:Belotrixio
トラックバック:Pewny Fundaryx
トラックバック:82200219
トラックバック:visit vip168.ucoz.org
トラックバック:sex caught on hidden cam
トラックバック:fixed soccer tips
トラックバック:Predictions
トラックバック:boobs
トラックバック:useful
トラックバック:list building funnel
トラックバック:tips
トラックバック:Dornatrixel Erfahrungen
トラックバック:bokep grock
トラックバック:seriöses online casino deutschland
トラックバック:TrueBlue Legit Or Not
トラックバック:BitBenefit App Review
トラックバック:Bitnex Crestfort
トラックバック:Highcliff Gainetra
トラックバック:trygge norske casino
トラックバック:uber accident lawyer houston
トラックバック:Record Store
トラックバック:best metal die casting for durable products practices
トラックバック:OwlVest
トラックバック:investra gpt
トラックバック:Lindervonix
トラックバック:strategic choices
トラックバック:Velantrexis TEST
トラックバック:Dravexoly
トラックバック:Bitnex Crestfort Opiniones
トラックバック:message7840
トラックバック:bokep mantap
トラックバック:vumon capital
トラックバック:https://lovesomething.click/yoga/loi-ich-khoa-hoc-cua-viec-luyen-tap-yoga-cung-con-n323.html
トラックバック:bokep anomali
トラックバック:kra48 сс
トラックバック:Valuable
トラックバック:Escorts in Hotel Mahran Karachi
トラックバック:LucentradePro
トラックバック:Continue
トラックバック:joker edan
トラックバック:Profitgrove
トラックバック:fixed soccer matches
トラックバック:Fairholt Cryptrix
トラックバック:Dravixe Scam
トラックバック:Halvixen
トラックバック:evry jewelsss
トラックバック:Måne Fundexis Anmeldelse
トラックバック:read this blog article from Befine
トラックバック:해운대호빠
トラックバック:xxx com com
トラックバック:Ren Vaultix
トラックバック:App.Carnote.de
トラックバック:best soccer tips
トラックバック:vegetarian
トラックバック:profitable Wettstrategie
トラックバック:facer.io
トラックバック:facer.io facer.io facer.io
トラックバック:Diabetes meal plan
トラックバック:healthy lifestyles
トラックバック:confidence
トラックバック:Fuentoro Ai
トラックバック:images
トラックバック:BOKEP KONTOL
トラックバック:Axelon Bit
トラックバック:neue online casinos
トラックバック:Blackrose Finbitnexex
トラックバック:Redmont Bitmark Review
トラックバック:Fintruxel erfahrungen
トラックバック:BOKEP SINGAPURA
トラックバック:bokep abong warung
トラックバック:raindrop.io
トラックバック:tits
トラックバック:look at more info
トラックバック:kra36
トラックバック:Fidèle Luxwise
トラックバック:erectile dysfunction ultrasound
トラックバック:82200219 singapore
トラックバック:indehoyviral.baby
トラックバック:เว็บ akbet25
トラックバック:bokep india memek bau
トラックバック:1xbet казино приложение
トラックバック:Order Crystal Meth Online in bulk
トラックバック:Where to order BPC-157 + TB-500 5mg/5mg (10mg Blend) online
トラックバック:нужна команда разработчиков
トラックバック:Football predictions
トラックバック:best real money online casino for us players
トラックバック:Fairholt Cryptrix Anmeldelse
トラックバック:KlarLogik
トラックバック:найти дизайнера
トラックバック:https://ar.search.yahoo.com/mobile/s?ei=UTF-8&fl=0&p=site:www.telehao.com
トラックバック:Intel Erymax Pro Avis
トラックバック:ร้านนวดขอนแก่น
トラックバック:deutsche online casinos
トラックバック:Drayton Paymill Review
トラックバック:türen folieren
トラックバック:camaras de sexo en vivo
トラックバック:https://dk.search.yahoo.com/mobile/s?ei=UTF-8&fl=9&p=site:www.telehao.com
トラックバック:かんたん登録 来店不要
トラックバック:https://www.kaggle.com/datasets/sergeigg/ai-productivity-tools-dataset-chat-gpt-5-extension
トラックバック:koi365 slot
トラックバック:download windows 10 full crack
トラックバック:download photoshop 2025 full crack google drive
トラックバック:BOKEP 2025
トラックバック:kra38 сс
トラックバック:massage services in dha karachi
トラックバック:digi 995 spookyverse
トラックバック:beste wett app österreich
トラックバック:https://ko.gravatar.com/eclecticbeard46bff6cd72
トラックバック:6582200219
トラックバック:https://cy.gravatar.com/eclecticbeard46bff6cd72
トラックバック:Verdade Oculta
トラックバック:Voxigenai
トラックバック:Yoga exercises for people with herniated disc
トラックバック:https://fi.search.yahoo.com/mobile/s?ei=UTF-8&fl=10&p=site:www.telehao.com
トラックバック:n8 betting app
トラックバック:Pet Urgent Care of Enterprise
トラックバック:bokep abong tuktuk
トラックバック:Cheers Plenty of
トラックバック:sa168vip
トラックバック:subways
トラックバック:gcmaf cream
トラックバック:https://www.provenexpert.com/en-us/ai-chatbot/
トラックバック:Papilo99
トラックバック:Watches Replica
トラックバック:تأجير شاشات عرض الرياض
トラックバック:wellness retreats
トラックバック:pgslotcash เว็บหลัก
トラックバック:Do`s website
トラックバック:888WIN
トラックバック:bokep di brand org
トラックバック:casino fun
トラックバック:elektro fahrrad
トラックバック:https://atavi.com/share/xfpymhzgvcrs
トラックバック:elektro roller
トラックバック:fast gaming review
トラックバック:https://500px.com/p/bbrbetio
トラックバック:Luxury
トラックバック:Neravia Platform Review
トラックバック:Clair Invion Avis
トラックバック:ngentot
トラックバック:ambslot เกมสล็อตยอดนิยม
トラックバック:mejores casinos online
トラックバック:Spot Codrix
トラックバック:Fortuna Valtrion
トラックバック:Stabile Obrax Avis
トラックバック:TrueBlue
トラックバック:Designideas
トラックバック:no deposit bonus casino
トラックバック:sigua下载
トラックバック:Buy Tramadol 200mg Without Prescription
トラックバック:https://www.erotic-africa.com/
トラックバック:Vaporneed officially announced
トラックバック:schwimmbecken sets
トラックバック:stahlwandbecken komplettset
トラックバック:Buy Lorazepam 1mg Online USA
トラックバック:Futuro Token のレビュー
トラックバック:Buy Alprazolam 1mg in California
トラックバック:Cheap Soma 500mg Online Pharmacy
トラックバック:Buy Xanax 2mg Online with Fast Shipping
トラックバック:Good
トラックバック:cuanwin77 login
トラックバック:https://trioeconomy.sk/melbet-skachat-kazino-obzor/
トラックバック:erome porn
トラックバック:Red Xanax Bars Online Pharmacy USA
トラックバック:Trusted Online Source for Ambien 10mg
トラックバック:Buy Original Tramadol 100mg in USA
トラックバック:Jiskra Gainex recenze
トラックバック:expert music benefits
トラックバック:metabolism boosters
トラックバック:lung support
トラックバック:stated
トラックバック:https://able2know.org/user/spicybet/
トラックバック:Order Diazepam 2mg Overnight USA
トラックバック:best online casinos that payout
トラックバック:Trusted Online Source for Xanax XR 3mg
トラックバック:Aere Luxeron
トラックバック:online slot777 machine
トラックバック:situs anjing
トラックバック:angarabayu2323.wixsite.com
トラックバック:Ærlig Vaultrow Anmeldelse
トラックバック:Optima Fundrelix
トラックバック:crypto casino sign up bonus
トラックバック:https://classroom.google.com/c/ODA5MDUyNTU5MDA1/m/ODA5MDUyNzYyNzQ4/details
トラックバック:https://www.dataprotect.sg
トラックバック:kinkycoupleca cam sex
トラックバック:Ropnetrixel
トラックバック:Anchor Gainlux
トラックバック:rental property management cost
トラックバック:اجاره تخت بیمارستانی
トラックバック:bandar sampah terbesar
トラックバック:elektrisches lastenfahrrad
トラックバック:AC repair
トラックバック:ZynerixPro
トラックバック:Wprowadzenie do auto gazu
トラックバック:capcut mod apkpure
トラックバック:vape wholesale geek bar
トラックバック:kra19 cc
トラックバック:GARDEN SHED AUSTRALIA GARDEN SHED AUSTRALIA
トラックバック:fastest payout online casinos
トラックバック:Project renovations your with start home refresh
トラックバック:rent a wedding car in Malaysia
トラックバック:Rockspire Bitline
トラックバック:beauty parlour course
トラックバック:relaxation
トラックバック:수원가라오케
トラックバック:骑士开区一条龙服务端
トラックバック:medan4d pake domain pemerintahan
トラックバック:www.exoticfaso.com
トラックバック:Goldankauf Bochum
トラックバック:FeronixFlow 5.7 Ai
トラックバック:www.exotic-africa.com/escorts-from/uganda/kampala-escorts/
トラックバック:Trezik Forge GPT Legit Or Not
トラックバック:basket autry homme
トラックバック:FB URL Shortener
トラックバック:Specialist
トラックバック:https://garudamudacendikia.sch.id/hajartrus/?92=
トラックバック:fk22
トラックバック:Discount
トラックバック:makeup artist course
トラックバック:Proxel Bit Erfahrungen
トラックバック:Axiron Ai Erfahrungen
トラックバック:gid=0
トラックバック:стриминговые сериалы
トラックバック:www.exotickenya.com
トラックバック:Tyrones Unblocked Games
トラックバック:pool online bestellen pool set pool sets pool shop pools pools bestellen pools kaufen
トラックバック:Wzrost Coinmark
トラックバック:knowledge
トラックバック:https://en-pocket-option.com
トラックバック:Redefined Restoration – Chicago Water Damage Service
トラックバック:casino på nett
トラックバック:Epoch Times
トラックバック:sarang777 link
トラックバック:Klonopin 2mg Price
トラックバック:holz folieren
トラックバック:Be5 Digital Marketing
トラックバック:Erfolgsimmo TEST
トラックバック:Magnus AI Reseña
トラックバック:best sectional sofa
トラックバック:Mocan Valtrix
トラックバック:go right here
トラックバック:서면 출장
トラックバック:brazino777 colombia
トラックバック:Replica Watch
トラックバック:befine.click
トラックバック:Apex Bitlux
トラックバック:Metal Buckle Crop Top
トラックバック:swiss casinos online
トラックバック:Quantserax
トラックバック:bet9ja promotion code
トラックバック:fensterbank folie
トラックバック:porn hentai adult xxx porn
トラックバック:Cashinvenix Avis
トラックバック:yuna777
トラックバック:kra33 сс
トラックバック:melbet казино
トラックバック:Index Cipro Opt
トラックバック:Biturex Stable Review
トラックバック:Riqueza GPT
トラックバック:Robux Murah Topup Roblox Topup Robux Termurah Topup Murah Limited Item Roblox Roblox Robux
トラックバック:ankara kürtaj
トラックバック:window cleaning in Frederick MD
トラックバック:Bit GPT App AI Avis
トラックバック:kid porn
トラックバック:rea lmoney online casinos
トラックバック:email marketing
トラックバック:naked kid
トラックバック:Intel Chenix
トラックバック:LED brick lamp kit
トラックバック:naked kid picture
トラックバック:Denza BD Ultimate Phuket
トラックバック:https://www.theepochtimes.com/
トラックバック:maillot espagne 2025
トラックバック:jihad group website
トラックバック:Serein Monerix
トラックバック:Adderall 20mg Legit Online Pharmacy
トラックバック:Yupoo Fendi
トラックバック:kra20
トラックバック:ANJING
トラックバック:Mechanik Wesoła
トラックバック:e bike e bike e bike e bike e bike e bike e bike e bike e bike kaufen e bike kaufen e bike kaufen e bike kaufen e bike kaufen e bike kaufen e bike kaufen e bike reparatur e bike reparatur e bike reparatur e bike reparatur e bike reparatur e bike reparatur
トラックバック:motorcycle accident lawyer near me
トラックバック:kra10
トラックバック:Asiatische Wetten ErkläRung
トラックバック:Clonazepam 0.5mg Dosage Info
トラックバック:my blog
トラックバック:Centre Finrivo Avis
トラックバック:WEDANGJP88
トラックバック:Zeker Fundiq
トラックバック:fast payout casinos online
トラックバック:Intel Chenix 400 Avia
トラックバック:Pur Finrevoux
トラックバック:宮崎 メンズエステ
トラックバック:Erfolgsimmo erfahrungen
トラックバック:El Medano Teneryfa Hiszpania – Raj dla kitesurfing windsurfing El Medano windfoil El Medano kitesurfing El Medano kitesurfing Teneryfa Hiszpania – Raj dla kitesurfing windsurfin windfoil
トラックバック:bokep cewe cantik
トラックバック:webcam live,
トラックバック:link alterantif satelittogel
トラックバック:beste online casino
トラックバック:login situs slot777
トラックバック:Primo Inviox
トラックバック:Finozanetix
トラックバック:https://www.theepochtimes.com/epochfun/word-roundup-4016913
トラックバック:wallsend locksmiths wallsend
トラックバック:stahlwandpool kaufen
トラックバック:vulkan24 casino бонусы
トラックバック:evaluate the b2b e-commerce company amazon business on it procurement
トラックバック:With thanks
トラックバック:advice
トラックバック:tips
トラックバック:good content
トラックバック:rundbecken komplettset rundbecken komplettset rundbecken komplettset rundbecken komplettset rundbecken komplettset rundbecken komplettset rundbecken komplettset rundbecken komplettset rundbecken komplettset rundbecken komplettset rundbecken komplettset ru
トラックバック:Pur Finrevoux Avis
トラックバック:Zeker Fundiq Avis
トラックバック:Ksalol 1mg for Anxiety
トラックバック:trans lesbian porn xxx sex videos
トラックバック:bone
トラックバック:schwimmbecken
トラックバック:пляжное махровое полотенце купить
トラックバック:klebefolie betonoptik
トラックバック:defense
トラックバック:bokep kerbau
トラックバック:irwin casino отзывы игроков
トラックバック:Viagra apotek
トラックバック:legzo казино фриспины
トラックバック:pg888
トラックバック:lừa đảo cambodia
トラックバック:flik85
トラックバック:Chen Zhi campuchia bị bắt
トラックバック:aufstellpools bestellen
トラックバック:https://ceveh.com.br/
トラックバック:เว็บสล็อต pgslot888 แตกง่าย
トラックバック:pgslot99 online
トラックバック:lovesomething.click wrote
トラックバック:Yupoo Dior
トラックバック:VIP Call Girls Karachi
トラックバック:Libre Invest
トラックバック:vagina
トラックバック:GPT +9A Plus
トラックバック:malaysia solar water heater
トラックバック:bokep china
トラックバック:desert safari tours
トラックバック:deutsche online casino
トラックバック:Quantum Flowbit
トラックバック:Evofinvex
トラックバック:rhode island news
トラックバック:Dravixen
トラックバック:ทางเข้า sbfplay99
トラックバック:Link bokep
トラックバック:女性おもちゃ
トラックバック:где можно купить постельные принадлежности
トラックバック:Daily Hidden Object
トラックバック:itunes gift card to cash
トラックバック:Winpro129
トラックバック:FOOTLOCKER gift card to cash
トラックバック:mitra togel
トラックバック:comet casino вход
トラックバック:SEPHORA gift card to naira
トラックバック:Bristol Hidden Gems
トラックバック:Clair Invion
トラックバック:kush casino
トラックバック:VixgenAi
トラックバック:dubai holiday packages all inclusive
トラックバック:Leger Finvio
トラックバック:monthly recap news
トラックバック:Free TRON & TRC20 & USDT Vanity Address Generator Ending Like 88888: Your Unique Wallet
トラックバック:68 game bài
トラックバック:monroe casino бездепозитный бонус
トラックバック:Vif Valtrix Avis
トラックバック:daddy казино бездепозитный бонус
トラックバック:fresh казино
トラックバック:instapaper.com
トラックバック:SoldeSmartBit TEST
トラックバック:Cheek filler near me
トラックバック:kontol
トラックバック:milf
トラックバック:nude
トラックバック:blowjob
トラックバック:new content from 9seed.click
トラックバック:bbc porn
トラックバック:pussy
トラックバック:SmartBit Boost Erfahrungen
トラックバック:pornography
トラックバック:pussies
トラックバック:Find A Plumber Saffron Walden
トラックバック:kra25
トラックバック:Noble Fundrelix Legit Or Not
トラックバック:Velora Nexen Scam
トラックバック:Avvio Finevox
トラックバック:webcame
トラックバック:LudvianixChainBot
トラックバック:송파룸싸롱
トラックバック:残酷色情剪辑
トラックバック:Finaurex
トラックバック:Indian MMS sex video
トラックバック:dingdongtogel
トラックバック:video bokep indonesia
トラックバック:transcription services
トラックバック:Måne Fundexis
トラックバック:Immediate App Ai
トラックバック:https://atavi.Com/
トラックバック:fryzjer Warszawa Ursynów
トラックバック:call girl underage
トラックバック:desi hidden sex cam
トラックバック:tukul777
トラックバック:Yellow Xanax Bars Sale USA
トラックバック:Zolpidem 5mg USA Pharmacy
トラックバック:Bhabi nude scene
トラックバック:scrud
トラックバック:Tramadol 200mg No Prescription Needed
トラックバック:achtformpool teilversenkt
トラックバック:Siberian kittens for sale
トラックバック:bdix vps for ai projects,
トラックバック:top online casinos
トラックバック:Nobleza Invexor
トラックバック:Massimo Bitpuls
トラックバック:Razer Gold gift card to cash
トラックバック:Zuiver Tradelux
トラックバック:Reputable Siberian breeders
トラックバック:VelanoNest Scam
トラックバック:desi hidden cam sex
トラックバック:Earn Matrix Pro
トラックバック:chicken road casino chicken road chicken road slot
トラックバック:dewapoker
トラックバック:Earn Matrix Pro Erfahrungen
トラックバック:Findorex
トラックバック:Attic loft conversions And
トラックバック:bästa casino utan svensk licens
トラックバック:e lastenrad
トラックバック:chicken road apk by 4rabet
トラックバック:Soldesmartbit
トラックバック:Lorazepam 1mg Genuine Pills
トラックバック:e seniorenmobil
トラックバック:buy xanax without prescrition
トラックバック:Process proven renovation step 5
トラックバック:Helder Bitnova
トラックバック:cheapest web hosting in bangladesh
トラックバック:WOMEN ON TOP
トラックバック:google_vignette
トラックバック:Nord Bitrevo
トラックバック:Hög Fundrelix
トラックバック:e kabinenroller
トラックバック:kumpulan Cerita Seks Dewasa
トラックバック:learn more about Calmlife
トラックバック:Fenice Bitvexa
トラックバック:Earn Matrix Pro Avis
トラックバック:aufstellpool shop
トラックバック:bokep rubah
トラックバック:guDang Cerita Sex Dewasa
トラックバック:Altrix SpotPro
トラックバック:how to buy trx energy
トラックバック:kra38
トラックバック:data
トラックバック:situs toto878
トラックバック:Immutable Azopt Review
トラックバック:레비트라 강직도
トラックバック:pool abdeckplane
トラックバック:inatogel
トラックバック:Tapentadol 100mg Bulk Order
トラックバック:instant withdrawal casino
トラックバック:udintogel
トラックバック:vanna bardot cum4k
トラックバック:CaribbeanCuisine
トラックバック:nhà cái 88aa
トラックバック:price action
トラックバック:Finxor GPT Review
トラックバック:franklin armory
トラックバック:schwimmbecken set
トラックバック:BUY VIAGRA ONLINE
トラックバック:Best Hair Growth Oil
トラックバック:Buy Diazepam 5mg in New York
トラックバック:SmartBit Boost
トラックバック:Dog
トラックバック:OffPageSEO
トラックバック:video bokep viral
トラックバック:ambslot official site
トラックバック:ดูรายละเอียด
トラックバック:fertigpool
トラックバック:UK 2026 Join the newsletter!
トラックバック:Check out new Marcello Red music Prophecy tape Volume 2 Tale of Marcus Marcello Clinton Dorleus of favorite music streaming apps new film trimester in theaters nov 21
トラックバック:Link Directory
トラックバック:bulk guns and ammo
トラックバック:đồng hồ thời trang nữ cao cấp
トラックバック:bitcoin cash
トラックバック:BCH For Everyone
トラックバック:横浜市のSEO対策会社
トラックバック:Pur Finrevoux Pro
トラックバック:jaosua 777
トラックバック:This is a Wiki about Electron Cash
トラックバック:โปรโมชั่น singha89
トラックバック:supply chain courses
トラックバック:Derma Roller for Hair Growth
トラックバック:basketball.eu.com lừa đảo công an việt nam cảnh báo truy quét cấm gấp
トラックバック:trojan dropper
トラックバック:stahlwandpool eingraben
トラックバック:Hair Regrowth Serum
トラックバック:zinnat02
トラックバック:minimal kreatif kontol
トラックバック:incorporation services
トラックバック:trojan ransom win32 crypmod zfq что это
トラックバック:bokep viral anak
トラックバック:Best Hair Growth Serum
トラックバック:ANAK JEMBOT
トラックバック:kumpulan Cerita Seks Dewasa Terbaru
トラックバック:woi kontol
トラックバック:bitcoin
トラックバック:webnovel Cerita Dewasa
トラックバック:SINI RIBUT MA GW KONTOL
トラックバック:klebefolie möbel klebefolie möbel klebefolie möbel klebefolie möbel klebefolie möbel klebefolie möbel klebefolie möbel klebefolie möbel klebefolie möbel klebefolie möbel klebefolie möbel klebefolie möbel klebefolie möbel klebefolie möbel kle
トラックバック:exhaust exhaust system kitchen exhaust singapore singapore kitchen exhaust commercial kitchen exhaust
トラックバック:ZahlCore
トラックバック:real chicken road game apk
トラックバック:Sereno Monvex
トラックバック:kumpulan Cerita Dewasa selingkuh
トラックバック:parfumerie hilversum
トラックバック:douglas hilversum
トラックバック:yoga towel
トラックバック:man purse yupoo
トラックバック:ici paris hilversum
トラックバック:bästa online casino
トラックバック:Fuentoro Ai Recenzja
トラックバック:ovalbecken sets ovalpool bestellen ovalpools komplettset rundbecken rundpools stahlwandpools kaufen stahlwandpool sets
トラックバック:Evofinvex Union Scam
トラックバック:bloemendaal aan zee
トラックバック:мостбет актуальное зеркало
トラックバック:parfum aan zee
トラックバック:Bodia Edge
トラックバック:parfumwinkel aalst
トラックバック:fun print
トラックバック:思 聊
トラックバック:douglas aalten
トラックバック:veterinarian clinic near me
トラックバック:https://momitory.wordpress.com/2025/10/29/——-/
トラックバック:slot demo pragmatic
トラックバック:parfumwinkel aalsmeer
トラックバック:douglas utrecht
トラックバック:rabbit road gambling game
トラックバック:Anashe Make Up Setting Spray Mattifying Kenya
トラックバック:seo anak haram
トラックバック:Prospero Bitspire Scam
トラックバック:Jasný Bitnex
トラックバック:Набойченко Приморский суд
トラックバック:TokenTact Scam
トラックバック:PINTER DIKIT JADI SEO
トラックバック:female divorce lawyer
トラックバック:BrametoxPro
トラックバック:Arbivex TEST
トラックバック:pontoto bokep
トラックバック:c5784870665249746411
トラックバック:Netto Tradeline
トラックバック:https://www.cap-dieu-khien-chong-nhieu-sangjin-chinh-hang.xyz/
トラックバック:JANGAN TOLOL TOLOL AMAT
トラックバック:SmartBit Boost TEST
トラックバック:Rundpools
トラックバック:CLOTHOFF
トラックバック:stahlwandpool sets
トラックバック:https://hubpages.com/@fun88play
トラックバック:dildo sextoys xxx video
トラックバック:top bitcoin casinos
トラックバック:Rundbecken rundbecken rundbecken Rundbecken Rundbecken rundbecken rundbecken Rundbecken rundbecken rundbecken Rundbecken Rundbecken rundbecken Rundbecken rundbecken rundbecken Rundbecken Rundbecken rundbecken Rundbecken rundbecken rundbecken Rundbecken ru
トラックバック:ovalbecken sets
トラックバック:slot situs 777
トラックバック:Very good
トラックバック:777 slot terbaru
トラックバック:módulo teclado frente de calle desbloqueo código México
トラックバック:hotel bath vanities
トラックバック:top online casino
トラックバック:Riobet casino
トラックバック:https://justpaste.it/cyvd5
トラックバック:Meteor Profit Legit Or Not
トラックバック:rundpools komplettset
トラックバック:iptv
トラックバック:Fundwix Invia
トラックバック:service production Milan
トラックバック:MaxgenBit Legit Or Not
トラックバック:https://linklist.bio/pug4d
トラックバック:parfum alphen aan de rijn
トラックバック:jual ganja online
トラックバック:rundpools bestellen
トラックバック:aufstellpools
トラックバック:Cerita Sex selingkuh Dewasa Com
トラックバック:led signages
トラックバック:Paver Sealing nearby
トラックバック:bokep anjumao
トラックバック:david yupoo
トラックバック:lengkap777
トラックバック:water damage repair services near me
トラックバック:digital marketing
トラックバック:Impulsion Tradevo
トラックバック:tripscan top
トラックバック:Taufkerze Onlineshop
トラックバック:양주출장마사지
トラックバック:bitcoin casino slots
トラックバック:Ralvixen Avis
トラックバック:N級品
トラックバック:casino med snabba uttag
トラックバック:偽物
トラックバック:Bluewall Revobit Review
トラックバック:Taufkerze Taufkerzen Taufkerzen Shop Taufkerze Onlineshop Taufkerze Taufkerzen Taufkerzen Shop Taufkerze Onlineshop Taufkerze Taufkerzen Taufkerzen Shop Taufkerze Onlineshop Taufkerze Taufkerzen Taufkerzen Shop Taufkerze Onlineshop Taufkerze Taufkerzen Ta
トラックバック:schmuck ankauf in der nähe
トラックバック:waktogel
トラックバック:Oven repair
トラックバック:aufstellbecken komplettsets
トラックバック:business growth
トラックバック:Stahlwandpool
トラックバック:internet marketing
トラックバック:Warsztat naprawy samochodów
トラックバック:lead generation
トラックバック:Intel Chenix Arnaque
トラックバック:Finvio Prestige Avis
トラックバック:best online casino ontario
トラックバック:best bonus casino
トラックバック:best online casinos for real money
トラックバック:Bextra Dynamic scam
トラックバック:ufa888utd.net
トラックバック:slot gacor
トラックバック:ibomma
トラックバック:bokep kuda lumping xxx videos xxx
トラックバック:body contouring
トラックバック:citra tablets for erectile dysfunction
トラックバック:Corporate team training UAE
トラックバック:truong pho thong tu thuc o tphcm
トラックバック:kraken7jmgt7yhhe2c4iyilthnhcugfylcztsdhh7otrr6jgdw667pqd onion
トラックバック:online casino schweiz echtgeld
トラックバック:4 UK Degu
トラックバック:order ksalol online without prescription
トラックバック:传奇sf一条龙服务端
トラックバック:scam website
トラックバック:cryptocurrency
トラックバック:cheap cialis online
トラックバック:Trade Edge AI
トラックバック:Kuspit Ai Review
トラックバック:강남구청피쉬안마
トラックバック:Synara Veltix
トラックバック:Uganda Safari tours
トラックバック:Permanent Make-up Hamburg
トラックバック:Nevelanobot
トラックバック:trusted site to buy tapentadol
トラックバック:Neronix +560 Profit
トラックバック:Körperformung
トラックバック:bauchdeckenstraffung bauchstraffung bauchdeckenstraffung bauchstraffung bauchdeckenstraffung bauchdeckenstraffung bauchstraffung bauchdeckenstraffung bauchstraffung bauchdeckenstraffung bauchstraffung bauchdeckenstraffung bauchstraffung bauchdeckenstraffu
トラックバック:Lexoronax
トラックバック:Tynavocore TEST
トラックバック:ziatogel
トラックバック:Gerborsyva Erfahrungen
トラックバック:swd555
トラックバック:Bluewall Revobit scam
トラックバック:Trivora Solent Avis
トラックバック:hydrocodone pain relief medication
トラックバック:Best Payout Casinos
トラックバック:buy ambien next day delivery
トラックバック:Eryna Voltrix Avis
トラックバック:Sonstige E-Mobile
トラックバック:prescription erectile dysfunction medication
トラックバック:lorazepam anxiety medication
トラックバック:Yupoo LV
トラックバック:Buy Ambien Online
トラックバック:iptv totaal
トラックバック:buy generic vicodin online
トラックバック:European Traveler
トラックバック:Amazing
トラックバック:bokep jepang
トラックバック:death
トラックバック:Netto Tradeline Avis
トラックバック:fehler bei küchenmontage beweisen
トラックバック:Barclay Valnor Review
トラックバック:Tiny House
トラックバック:ORGY PORN VIDEOS
トラックバック:food scanner app
トラックバック:123bet online
トラックバック:order clonazepam online without prescription
トラックバック:codeine pain relief tablets online
トラックバック:poolzubehör bestellen
トラックバック:bet 285
トラックバック:نظام سهل الاستخدام
トラックバック:ovalpool set
トラックバック:pg สล็อต
トラックバック:foton
トラックバック:jav hentai bokep
トラックバック:Veloce Finvexo
トラックバック:Tynavocore Review
トラックバック:Fundwix Invia legit or not
トラックバック:hirainbow.org jav hd
トラックバック:ineer.org bokep uncensored
トラックバック:강남역가인안마
トラックバック:عطرهای مردانه مناسب فصل بهار و عید نوروز
トラックバック:Ernährungsberatung Stuttgart Ernährungsberatung Rems Murr Ernährungsberatung Backnang
トラックバック:iptv box
トラックバック:Synara Veltix Avis
トラックバック:interwin
トラックバック:hair extensions
トラックバック:faltenbehandlung frankfurt
トラックバック:live sdy
トラックバック:interwin login
トラックバック:display fixture for office supply store
トラックバック:olx96
トラックバック:gartenpool
トラックバック:sailing and snorkeling tour
トラックバック:Be5 Digital Marketing
トラックバック:Voltara Flex TEST
トラックバック:Trexon Pivot GPT Erfahrungen
トラックバック:Blank Finvex Anmeldelse
トラックバック:DynarisFlex 7 1 Ai
トラックバック:kingslot96
トラックバック:düşük hapı
トラックバック:https://www.exoticsouthafrica.com/escorts-from/gauteng/aureus-escorts/
トラックバック:ICCS Conference
トラックバック:สล็อตทดลอง
トラックバック:Cerita Dewasa bersama tante
トラックバック:Barclay Valnor legit or not
トラックバック:ssd chemical solution online
トラックバック:clonazepam for panic disorder
トラックバック:technician
トラックバック:비아그라구매사이트
トラックバック:global asia printings
トラックバック:michelin tyre
トラックバック:SwissBorg Erfahrungen
トラックバック:Bouclier Apextrail Erfahrungen
トラックバック:Online totalizators https://totalizators.online/
トラックバック:pneumonia children treatment
トラックバック:Finlorepex Erfahrungen
トラックバック:Høy Invexa
トラックバック:강남다오안마
トラックバック:Aminixio
トラックバック:Krylonis Wave AI
トラックバック:Inverzo GPT TEST
トラックバック:ANAK KONTOL
トラックバック:Power Trades App Avia
トラックバック:sla mujeres vacation rentals
トラックバック:yoga originated from which country
トラックバック:Blank Finvex
トラックバック:Lucren AI
トラックバック:DynarisFlex 7.1 Ai Avis
トラックバック:Memory Lift usa
トラックバック:89 cash
トラックバック:neurocept
トラックバック:BUY ADDERALL ONLINE WITHOUT PRESCRIPTION
トラックバック:úzká zahrada
トラックバック:آهن آلات
トラックバック:Rückschlagventil warmwasserleitung
トラックバック:janitorial companies near me
トラックバック:Amadshair.com
トラックバック:notice machine à coudre carrefour home hsew8660-11
トラックバック:Xtreme Heating
トラックバック:Cheers
トラックバック:fragile X syndrome child
トラックバック:Sandwichplatten dach verlegen
トラックバック:Zenithra Core GPT Review
トラックバック:Wealth Sprint Hub
トラックバック:paint and sip Long Island City
トラックバック:crypto casino bonus
トラックバック:Wedding Live Band
トラックバック:Lorventriax
トラックバック:Finora Capital Recensione
トラックバック:Buy YouTube Subscribers
トラックバック:m98 bet
トラックバック:Velora Nexen Avis
トラックバック:australian online casino
トラックバック:Finlorepex
トラックバック:PHISING BABI
トラックバック:XeltovoPrime AI
トラックバック:bathroom remolding
トラックバック:ANAK HARAM
トラックバック:aufstellpool winterfest kaufen
トラックバック:parking lot repair service
トラックバック:nude kids
トラックバック:big dick
トラックバック:sex video
トラックバック:make bomb
トラックバック:porn streaming
トラックバック:online casino real money nz
トラックバック:zinn ankauf dortmund
トラックバック:водка казино
トラックバック:rustikal klebefolie holzoptik
トラックバック:سرم ویتامین C
トラックバック:audit singapore
トラックバック:möbelfolie muster möbelfolie muster möbelfolie muster möbelfolie muster möbelfolie muster möbelfolie muster möbelfolie muster möbelfolie muster möbelfolie muster möbelfolie muster möbelfolie muster möbelfolie muster möbelfolie muster möbelfo
トラックバック:vergleich günstiger pools
トラックバック:adipex fat burner pills
トラックバック:Licensedcontractors
トラックバック:online casino kostenlos
トラックバック:vigorlong
トラックバック:بازیگران خارجی
トラックバック:Gnetum gnemon supplier Indonesia
トラックバック:discount lorazepam 2mg pills online
トラックバック:order lorazepam online without prescription
トラックバック:Nevelanobot TEST
トラックバック:mahjong222
トラックバック:adderall pills for sale
トラックバック:SoldeSmartBit Erfahrungen
トラックバック:Treuzinapex
トラックバック:Nhà cung cấp SBLC
トラックバック:trường ngoài công lập chất lượng cao khu vực tphcm
トラックバック:cuscini per divano letto ikea
トラックバック:Freund Gentak Erfahrungen
トラックバック:Джип туры Крым
トラックバック:best vegetable for weight loss
トラックバック:substack
トラックバック:poolleitern set
トラックバック:bro138 bro138 login bro138 slot bro138 alrernatif bro138 link alternatif
トラックバック:вавада сайт
トラックバック:EMAK KAU LONTE
トラックバック:BurnPea
トラックバック:طلا
トラックバック:counter-strike 1.6
トラックバック:buy zolpidem 5mg online
トラックバック:Simple Couple Yoga
トラックバック:Acne Pimples Breakouts Oily skin Blackheads Whiteheads Clogged pores Inflammation Sebum Blemishes Scar treatment Acne scars Skin redness Hormonal acne Acne treatments Non-comedogenic Clear skin Gentle skincare Acne-prone skin care Deep cleansing Exfoliati
トラックバック:casino online svizzera
トラックバック:ดูซีรี่ย์ใหม่อัปเดตล่าสุด
トラックバック:ดูซีรี่ย์โลกอนาคตดาร์ก
トラックバック:goodfeel.click
トラックバック:игровой клуб Лев
トラックバック:flagman casino зеркало
トラックバック:outstaffing
トラックバック:illegal drugs
トラックバック:www.celostni-fyzioterapie.Cz
トラックバック:beste online casino deutschland
トラックバック:ดูซีรี่ย์น่าดูคืนนี้
トラックバック:Qelnofaxai
トラックバック:zolpidem overnight delivery usa
トラックバック:Drablehub
トラックバック:Apuestas Multiples
トラックバック:WertelogixPro
トラックバック:Exoticdrc official blog
トラックバック:online slots australia
トラックバック:https://padlet.com/
トラックバック:resultados apuestas futbol
トラックバック:custom home builders Van Alstyne
トラックバック:маркетинговое сопровождение
トラックバック:услуги маркетинга
トラックバック:КУПИТЬ АДДЕРАЛЛ ОНЛАЙН БЕЗ РЕЦЕПТА
トラックバック:Regards
トラックバック:geodesy
トラックバック:loads
トラックバック:account services
トラックバック:MEMEK BELATUNGAN
トラックバック:reproductive health
トラックバック:chicken road game 100 deposit
トラックバック:Quick q
トラックバック:commercial cleaning services near me
トラックバック:daftar interwin
トラックバック:울산출장마사지
トラックバック:digital-Fashion.online
トラックバック:veneered MDF
トラックバック:как попасть на мега даркнет
トラックバック:pestoto link
トラックバック:New.Psilon.pl
トラックバック:https://akta.uk.com/
トラックバック:visit game789bet.business.blog
トラックバック:cake to order
トラックバック:office cleaning services near me
トラックバック:möbel klebefolie
トラックバック:Tankless Water Heater Replacement
トラックバック:nerve recovery max official
トラックバック:bokep google children
トラックバック:casino login
トラックバック:Model Call Girls in Karachi
トラックバック:GIF Face Swap
トラックバック:packaging pouches printing services nairobi
トラックバック:เว็บ suckbet
トラックバック:restaurant in Moscow
トラックバック:bonos Casas apuestas
トラックバック:Independent Karachi Call Girls
トラックバック:https://agrolattec.com/melbet-sajt-2025-obzor-bukmekera/
トラックバック:Wedding Live Band Singapore
トラックバック:achtformbecken bestellen
トラックバック:survey
トラックバック:Que Es 1X2 En Apuestas
トラックバック:Lahore Stars
トラックバック:VIP Escorts in Karachi
トラックバック:https://groups.google.com/g/my-links-v01/c/2GB5RWFG0ys
トラックバック:프라임 액상
トラックバック:Soluzioni naturali per dolore articolare
トラックバック:https://diseasemelody.shop/fake-ids-how-youth-are-skirting-the-law/
トラックバック:honey jewellery online shopping
トラックバック:https://coinbet999i.org/
トラックバック:nueva casa de apuestas en colombia
トラックバック:https://flipboard.com/@edwaxander2025/idbook-review–fakeidvendors-vendor-rating-user-experience-30j4kh43z?from=share&utm_source=flipboard&utm_medium=curator_share
トラックバック:duchang.cn.com lừa đảo công an việt nam cảnh báo truy quét cấm gấp
トラックバック:download bokep gratis
トラックバック:Overcome AI beginner overwhelm
トラックバック:Plata Boost Reseña
トラックバック:8xbet6.shop lừa đảo công an việt nam cảnh báo truy quét cấm gấp
トラックバック:Axel Fundevo
トラックバック:Fyvexlabfin TEST
トラックバック:https://x.com/Dupre7339M/status/1985342919675674651
トラックバック:List wrote
トラックバック:comment-153868
トラックバック:호빠알바
トラックバック:최종 안전 기준 체크
トラックバック:먹튀사고 발생 시 대응 및 신고 절차 정리
トラックバック:naturespirit.click
トラックバック:WATCH INCEST PORN
トラックバック:ลอตโต้วีไอพี
トラックバック:RaiGenTrade
トラックバック:Apuestas de caballos españa
トラックバック:거래 수단 확인
トラックバック:buy xanax without prescrition
トラックバック:WATCH ANAL PORN
トラックバック:꽁머니 이벤트 규정 해석과 허용 범위
トラックバック:리스크 단계별 평가
トラックバック:Kizuna Quant のレビュー
トラックバック:tyara88 website tidak bayar
トラックバック:Cartomante fidata e Cartomanzia Dea Bendata sono il migliore servizio di cartomanzia professionale. Cartomanti
トラックバック:siamonlyfan.com
トラックバック:https://tr.ee/7J01qXXMns
トラックバック:보안 정책 확인 필수
トラックバック:isyoutubedown
トラックバック:Switch Axid Hex Avis
トラックバック:Air Conditioning Repair nearby services
トラックバック:Septic Tank Coverage
トラックバック:мостбет казино регистрация
トラックバック:Technology Updates
トラックバック:Watch Shemale Hentai Videos
トラックバック:도메인 변경 추적
トラックバック:메이저 안전 기준
トラックバック:canadian pharmacy adderall
トラックバック:best free porn videos
トラックバック:계정 복구 프로세스
トラックバック:gartenpool bestellen
トラックバック:9 apuestas que siempre ganaras
トラックバック:메이저사이트 선택 시 초보자 추천 팁
トラックバック:서버 장애 이력 분석
トラックバック:https://connect.garmin.com/modern/profile/e1c5d3d1-8491-4e9c-9939-e0ed05feb3b1
トラックバック:vagina di oles madu
トラックバック:Lagardère Revolux AVIS
トラックバック:Principales Casas De Apuestas En EspañA
トラックバック:леон казино мобильная версия
トラックバック:Hire Escorts in Islamabad
トラックバック:KLG7G
トラックバック:개인정보 유출 예방
トラックバック:African News
トラックバック:Current Events
トラックバック:Politics
トラックバック:Titan Fundrelix Review
トラックバック:yohoho unblocked 76
トラックバック:介護報酬 ファクタリング 手数料
トラックバック:Nalviros Review
トラックバック:World News
トラックバック:Global Headlines
トラックバック:International Affairs
トラックバック:Trezik Forge GPT Avis
トラックバック:Buy Tramadol Online Without Prescription
トラックバック:บาคา
トラックバック:xanax medication
トラックバック:Economy
トラックバック:m98vip
トラックバック:웹 보안 인증 체크
トラックバック:Repozarex App
トラックバック:buy cannabis online
トラックバック:formative assessment creator
トラックバック:https://manylink.co/@Lopez333
トラックバック:l banner printing services kenya
トラックバック:enzymes
トラックバック:best crypto casino no kyc
トラックバック:F1 Apuestas
トラックバック:https://vk.com/wall240420116_680
トラックバック:First in Pressure Washing
トラックバック:roof repair Highlands Ranch CO
トラックバック:http://www.talkreviews.ro/fakeidvendors.net
トラックバック:roofers company
トラックバック:Adderall 30mg Online Legit USA Pharmacy
トラックバック:swimmingpool swimmingpool bestellen swimmingpool kaufen swimmingpool online bestellen swimmingpool shop swimmingpools swimmingpools bestellen swimmingpools kaufen swimmingpools online bestellen swimmingpools shop swimmingpool komplettset swimmingpool komp
トラックバック:https://www.tumblr.com/mduprey/799201665594064896/idbook-review-fakeidvendors-vendor-rating?source=share
トラックバック:penis di oles madu
トラックバック:http://www.who.is/whois/fakeidvendors.net
トラックバック:VIP Girls in Islamabad
トラックバック:swimmingpool komplettset
トラックバック:ทางเข้าm98
トラックバック:https://www.reddit.com/user/characteracademic898/m/question_answer_p1/
トラックバック:sex fre xxx
トラックバック:제3자 인증 마크 검증 기준 안내
トラックバック:https://www.plurk.com/p/3hx589ihbl
トラックバック:practice facilities analysis
トラックバック:https://www.pinterest.com/pin/1102396815056670543
トラックバック:https://kuula.co/post/hW67p
トラックバック:poolplanen set
トラックバック:certificates printing services nairobi
トラックバック:laptop backpacks bags printing services kenya
トラックバック:tournament rewards
トラックバック:KEONHACAI
トラックバック:Zentrax Nova 8.4 Review
トラックバック:swimmingpool shop
トラックバック:Quantum Zherx Reseña
トラックバック:hacked
トラックバック:layarslot
トラックバック:bongeslot
トラックバック:MaxgenBit Review
トラックバック:aroma iptv
トラックバック:table talker printing services kenya
トラックバック:Bluevault Dexeris Review
トラックバック:situs sawo4d
トラックバック:Nalviros
トラックバック:bill books branding services nairobi
トラックバック:how to make bomb
トラックバック:Kenevir tohumu – Esrar tohumu – Tohumlu Esrar – Ot tohumu – Esrar tohum – Esrar satın al
トラックバック:save the bees
トラックバック:https://onfry.com/social/?url=100suvenirov.ru
トラックバック:trophies branding services nairobi
トラックバック:토토사이트 추천 시 고려해야 할 핵심 항목
トラックバック:consejo De apuestas Deportivas
トラックバック:jangan main phising
トラックバック:Vin777
トラックバック:bitcoin casinos
トラックバック:Bayline Nexute
トラックバック:slot interwin
トラックバック:paris sportif ligue europa
トラックバック:SEO ANAK LONTE
トラックバック:Zentrax Nova 8.4
トラックバック:купить виагру онлайн
トラックバック:wert silber 925
トラックバック:F8BET
トラックバック:saudise-sa.Com
トラックバック:Boroli Luxent
トラックバック:strategyessays.com
トラックバック:personal injury attorney near me
トラックバック:water remediation Edina MN
トラックバック:Bedrock Restoration of Edina
トラックバック:roofing service
トラックバック:calendars branding services nairobi
トラックバック:bokep asia
トラックバック:8DAY
トラックバック:is tramadol available from online pharmacies
トラックバック:möbelfolie betonoptik möbelfolie betonoptik möbelfolie betonoptik möbelfolie betonoptik möbelfolie betonoptik möbelfolie betonoptik möbelfolie betonoptik möbelfolie betonoptik möbelfolie betonoptik möbelfolie betonoptik möbelfolie betonoptik m
トラックバック:2 UK 2026 Fish Tanks
トラックバック:куш казино бездепозитный бонус
トラックバック:table roll up banner branding services kenya
トラックバック:pools pools bestellen pools kaufen pools online bestellen poolshop pooltechnik komplettset pooltreppen poolzubehör poolzubehör bestellen poolzubehör kaufen poolzubehör komplettset poolzubehör komplettsets poolzubehör online bestellen poolzubehör se
トラックバック:Presgera
トラックバック:C6Z file description
トラックバック:Vape Devices
トラックバック:Vape Kits
トラックバック:vapingnear
トラックバック:klebefolie küche klebefolie küche klebefolie küche klebefolie küche klebefolie küche klebefolie küche klebefolie küche klebefolie küche klebefolie küche klebefolie küche klebefolie küche klebefolie küche klebefolie küche klebefolie küche kle
トラックバック:bybit
トラックバック:aufstellbecken online bestellen
トラックバック:Figma Templates
トラックバック:Kyntrix Nova GPT
トラックバック:anal sex porn videos
トラックバック:Esplendor Gainlux
トラックバック:english sex stories
トラックバック:Buy Mounjaro online
トラックバック:Vape Shop
トラックバック:is youtube down
トラックバック:s utube down
トラックバック:Wildrose Gainlux Review
トラックバック:buy viagra online
トラックバック:Radiara Fundrelix review
トラックバック:Fyvexlabfin Ervaringen
トラックバック:paris sportif om Psg
トラックバック:Krbova dvirka
トラックバック:Béton isolant thermique
トラックバック:Celosias de madera leroy merlin
トラックバック:Zeylor Pacte Avis
トラックバック:Palworld Tides of Terrara update
トラックバック:schweizer online casino
トラックバック:Nákupy v polsku jelenia gora
トラックバック:Paypal casino
トラックバック:new online casinos
トラックバック:Axe Tradeviax
トラックバック:커뮤니티 댓글 조작 유형과 대응 팁
トラックバック:ufabet เข้าสู่ระบบ
トラックバック:best ZZ file viewer
トラックバック:Pari sportif astuce
トラックバック:คลิปหลุด
トラックバック:Fortnite patch notes
トラックバック:Spot Exelon Xp
トラックバック:Abandoned Manuscript puzzle
トラックバック:Sciaticyl
トラックバック:deep fake scam messenger facebook
トラックバック:download windows 11 crack
トラックバック:https://Www.blackmythonline.Com/
トラックバック:LLC
トラックバック:chimney sweep Seattle
トラックバック:chimney cleaning Seattle
トラックバック:Geo Synergy
トラックバック:paris sportif bonus Bienvenue
トラックバック:Vape Tanks
トラックバック:facts
トラックバック:gay porn sex videos
トラックバック:blowjob videos
トラックバック:buy valium online
トラックバック:vape best seller
トラックバック:skill-based game encounters
トラックバック:Light Cone Optimization
トラックバック:https://pn-pontianak.go.id/struktur-organisasi/
トラックバック:Season 17 update
トラックバック:Trade Vector AI review
トラックバック:Klarnium Erfahrungen
トラックバック:Pura Boost
トラックバック:Freshkitchen
トラックバック:Esrar tohum
トラックバック:Lune Finvex Review
トラックバック:schwimmbadzubehör schwimmbadzubehör bestellen schwimmbadzubehör kaufen schwimmbadzubehör komplettset schwimmbadzubehör komplettsets schwimmbadzubehör online bestellen schwimmbadzubehör set schwimmbadzubehör sets schwimmbadzubehör shop schwimmbadz
トラックバック:statistique tennis paris sportif
トラックバック:crypto betting sites
トラックバック:Astuce paris sportif tennis
トラックバック:altany.bochnia.pl
トラックバック:Vape Deals
トラックバック:Puravive
トラックバック:reparature-scooter
トラックバック:Rehabilitation centre Bloemfontein
トラックバック:88j
トラックバック:Vape Deals Online
トラックバック:best Nintendo Characters
トラックバック:https://www.utmholdings.com/
トラックバック:สล็อตPgแท้
トラックバック:vaping e liquid
トラックバック:Fps game guides
トラックバック:cellucare
トラックバック:สล็อตpgเว็บตรง
トラックバック:free convert
トラックバック:Các loại đồng hồ nữ
トラックバック:synogut
トラックバック:askyouwin888
トラックバック:Cigara
トラックバック:best MZP file viewer
トラックバック:Bergkrone Invexa
トラックバック:Søyle Dexeris
トラックバック:underrated baseball players
トラックバック:lolita rape
トラックバック:join jihad
トラックバック:life coaching: personal coach
トラックバック:ZPRF file download
トラックバック:BTC Blunex 9.0
トラックバック:Apogée Dexlink légitime
トラックバック:Mietrechtsschutz
トラックバック:koh lim koh & lim audit audit firm audit pac singapore audit firm audit firm singapore
トラックバック:Gardening Page
トラックバック:Envariax
トラックバック:Resident Evil 2 remake
トラックバック:MXL file online viewer
トラックバック:Vape Hardware
トラックバック:Frontierlaw official blog
トラックバック:MexiFindex Opiniones
トラックバック:file extension CRF
トラックバック:ทางเข้า u31 มือถือ
トラックバック:Vape Clearance
トラックバック:cote paris sportif calcul
トラックバック:ONT Marketing Solutions
トラックバック:government lottery programs
トラックバック:Relevant
トラックバック:useful
トラックバック:https://www.speedrun.com/users/fun88play
トラックバック:it
トラックバック:asia cup rising stars 2025 schedule
トラックバック:Mhada
トラックバック:aviator predictor app
トラックバック:Yoga helps reduce body fat
トラックバック:cheapest Vape
トラックバック:как вывести деньги с пинко
トラックバック:https://toolbarqueries.google.nr/url?q=http://exp.enuri.Com/proxy/shikokusaburou.sakura.ne.jp/bbs/kakikomitai.cgi
トラックバック:aus vs eng live streaming
トラックバック:Bonusy na kasyno online
トラックバック:all mythical staffs wukong
トラックバック:인천출장마사지
トラックバック:Vape Sale
トラックバック:Vape Kits Devices
トラックバック:Kenevir tohumu
トラックバック:Ot tohumu
トラックバック:mã nhận thưởng 888slot
トラックバック:Vape Juice
トラックバック:gem5000
トラックバック:Vapor Pens
トラックバック:Royal Casino бездепозитный бонус
トラックバック:vodka
トラックバック:Java Burn
トラックバック:industrial kitchen exhaust
トラックバック:diamanten verkaufen
トラックバック:interwin slot
トラックバック:how to contact ISIS
トラックバック:how paedophile
トラックバック:motorcycle wreckers
トラックバック:visit ambslot-3.jimdosite.com
トラックバック:Bürocontainer Bürocontainer Bürocontainer Bürocontainer Bürocontainer Bürocontainer Bürocontainer Bürocontainer Bürocontainer Bürocontainer Bürocontainer Bürocontainer Bürocontainer Bürocontainer Bürocontainer Bürocontainer Bürocontainer
トラックバック:Clearance Vapor Deals
トラックバック:united airlines customer service support
トラックバック:m98 ทางเข้า ล่าสุด
トラックバック:logiciel Pari sportif
トラックバック:E LIQUIDS
トラックバック:88wanwin
トラックバック:Vape Mods
トラックバック:black myth wukong tips
トラックバック:best heat pump reviews 2025
トラックバック:эмоционально-образная терапия сценарий
トラックバック:vuse go zero
トラックバック:best water filter reviews
トラックバック:best solar panels 2025
トラックバック:buy afghan kush online
トラックバック:바이비트
トラックバック:바이낸스
トラックバック:SLG game units
トラックバック:Fenextor Recensione
トラックバック:singapore mold removal
トラックバック:Fenextor
トラックバック:omislot
トラックバック:best bitcoin casino no deposit bonus
トラックバック:AlphaMovix 7 0
トラックバック:Burn Peak
トラックバック:Www.palworldhub.com
トラックバック:binance
トラックバック:Buy Derila Online
トラックバック:Libetrio
トラックバック:new social casino
トラックバック:important link
トラックバック:sweeps coins casinos
トラックバック:try www.sr.npu.edu.ua
トラックバック:kids por
トラックバック:ASIAN ANAL PORN CLIPS
トラックバック:browse around here
トラックバック:solar services Derwood MD
トラックバック:casino en ligne fiable
トラックバック:Bonus-Sans-Depot.casino
トラックバック:Vape Accessories
トラックバック:casino game online
トラックバック:portail Casino Comparateur
トラックバック:Vapor Clearance
トラックバック:abbott-lundgreen-3.technetbloggers.de
トラックバック:click through the next web site
トラックバック:Lucky-Casino
トラックバック:Discount Vape
トラックバック:Vape Starter Kits
トラックバック:offre sans wager
トラックバック:indobetslot88 infini88 jakartaslot88 wukong778 udinslot jago168
トラックバック:bonus sans mise
トラックバック:ATM file software
トラックバック:LUNARTOTO OMTOTOGEL HOMETOGEL KASKUSTOTO DINGDONGTOGEL Danatoto jagatoto
トラックバック:Disposable Vapors
トラックバック:Rendiva GPT test
トラックバック:undress image AI online
トラックバック:jouer sur Lucky Casino
トラックバック:online marketing
トラックバック:Black Myth Wukong
トラックバック:m98 ทางเข้า
トラックバック:bangsat
トラックバック:free keyboarding games
トラックバック:brustverkleinerung frankfurt
トラックバック:Zoom555
トラックバック:Vape E-Liquids
トラックバック:STUDY ABROAD AGENCY IN KERALA
トラックバック:https://skyglass.io/sgWiki/index.php?title=User:XiomaraWoodson
トラックバック:lottery briefings
トラックバック:Mech Arena free coins
トラックバック:UDINTOTOGEL zlatagtel coloktog TOGELON PITTOGEL WAKTOGEL ABUTOGEL
トラックバック:Excellent
トラックバック:JOKOTOTO tesiatoto TIKTAKTOGEL INDRATOGEL BENTO4D ROSTOT CAPSATOTO
トラックバック:RUPIAHTOTO INDOTOTO CONGTOTO lenstogel TOGELUP JOINTOGEL gantigtoto
トラックバック:Dinéra Tokentra Estafa
トラックバック:Night Huntsman Boss
トラックバック:consett locksmiths
トラックバック:Klarvoro Erfahrungen
トラックバック:Immediate Neon レビュー
トラックバック:boswin77 leoslot88 slot777 biru777 zeus4d dewaslot88 sis4d
トラックバック:buy drivers license
トラックバック:https://tx88.br.com/
トラックバック:Lavandbit Summit scam
トラックバック:https://9bet.limited/
トラックバック:https://ku88.eu.com/. ku88.eu.com
トラックバック:Buy Tramadol Online Cheap USA
トラックバック:https://du88.design/
トラックバック:在线购买伟哥
トラックバック:Lucky-Casino.fr
トラックバック:available at postheaven.net`s website
トラックバック:https://activemail.co.com/
トラックバック:Best Online Pharmacy for Xanax
トラックバック:Zahloryx TEST
トラックバック:TéLéCharger Algorithme Paris Sportif
トラックバック:OLXTOTO Alvesjostogel MAWARTOTO RAJABANDOT KIOTOT 12toto NATOGEL
トラックバック:best real money online casino
トラックバック:Stolz Luxerise
トラックバック:dirt bike wreckers
トラックバック:honkai star rail consumables
トラックバック:Sinkende quoten wetten
トラックバック:homeless veterans donations
トラックバック:gartenpool sets
トラックバック:https://proingal.com.ec/course/king88bet-login-link-alternatif
トラックバック:워크온
トラックバック:Veloquantix Recensione
トラックバック:pre-built Templates
トラックバック:Sportwetten glücksspiel öSterreich
トラックバック:Chimney repair
トラックバック:เว็บสล็อตเว็บตรงค่ายใหญ่ ฝากถอนไม่มีขั้นต่ํา
トラックバック:true wallet สล็อต ฝาก10รับ 100 วอ เลท 2022
トラックバック:Https://www.loltrackers.com
トラックバック:MANADOTOTO MENARA4D HQTOTO TVTOTOGEL Maniatoto RAMANGTOTO PAPURTOTO
トラックバック:adequately
トラックバック:spectral boss Fight
トラックバック:Türgriffe für Zimmertüren
トラックバック:Https://Cathy-Atelier.Fr/
トラックバック:肛交色情
トラックバック:https://999slot.io/
トラックバック:https://vua88.de.com
トラックバック:Swap Levora Opt Avis
トラックバック:motorbike insurance quote
トラックバック:Zahloryx Erfahrungen
トラックバック:buy onlyfans likes
トラックバック:хаки андроид
トラックバック:бесплатные внутриигровые покупки
トラックバック:프리카지노
トラックバック:yupoo cartier sunglasses
トラックバック:Cresthill Valtor review
トラックバック:Spotlight Evocorex legit or not
トラックバック:시알리스복용법
トラックバック:dh88
トラックバック:BonusSansDepotCasino
トラックバック:tải 66b
トラックバック:Drezinex opiniones
トラックバック:47.92.5.61
トラックバック:Instant withdrawal casinos
トラックバック:symptoms of yeast infection
トラックバック:https://motionentrance.edu.np/
トラックバック:Buchmacher kurse beim rennsport
トラックバック:cote paris Sportif Euro
トラックバック:Naruto Online ninja abilities
トラックバック:water heater repair
トラックバック:https://agro-zaschita.ru/
トラックバック:https://доставка-карго-из-китая.рф/
トラックバック:asbola
トラックバック:Site De Paris Sportif Remboursé
トラックバック:肛交色情影片
トラックバック:https://addictiontreatments101.com
トラックバック:https://777cargo.ru/
トラックバック:1xBet Promo Code 2026 — Limited-Time VIP Bonus
トラックバック:Zap Zone Defender
トラックバック:https://storeprofit.ru/
トラックバック:web kontol
トラックバック:Fyvexlabfin
トラックバック:snow removal Shaughnessy
トラックバック:Treuzinapex Erfahrungen
トラックバック:Joka Casino Avis
トラックバック:Paxil Vision TEST
トラックバック:Campervan Shows
トラックバック:Flux Reopro
トラックバック:주식선물
トラックバック:calmlife.click
トラックバック:Betgem Casino Avis
トラックバック:A moving company
トラックバック:Fenextor のレビュー
トラックバック:Aurevia Tradex Erfahrungen
トラックバック:what Is Nasal Wash
トラックバック:best paying online casino
トラックバック:Auronstex App legit or not
トラックバック:BloodVitals insights
トラックバック:stem cell treatment for anti-aging thailand
トラックバック:Sunridge Bitrevia Review
トラックバック:Equiloompro
トラックバック:bonus paris sportif sans depot
トラックバック:what is hypertonic saline
トラックバック:sex 18+
トラックバック:Bitnova Kerne Anmeldelse
トラックバック:sampe rata kau kontol
トラックバック:kraken kra
トラックバック:best online casino payouts
トラックバック:park and ride heathrow
トラックバック:kuzey kıbrıs ev ilanları
トラックバック:kuzey kıbrıs ilan
トラックバック:esc Buchmacher Quoten
トラックバック:Best roof inspection
トラックバック:buy xanax online without prescription
トラックバック:Powell’s Plumbing & Air
トラックバック:Https://edahomehealthcare.com/
トラックバック:roofing company
トラックバック:gái gọi
トラックバック:MEME
トラックバック:You
トラックバック:slot365 xx vip
トラックバック:ovalpool komplettset
トラックバック:clonazepam without prescription
トラックバック:poolleiter shop
トラックバック:stahlwandpools bestellen
トラックバック:í ½íº Welcome to PharmaKarts â Your Trusted Online Pharmacy! Get all your healthcare essentials delivered right to your doorstep
トラックバック:Axel Fundria
トラックバック:Wiltoto | Bobatoto | Sontogel | Hongtogel | Dapurtoto | Cerutu4d | Mariototo | Dontoto | Togel158
トラックバック:66b
トラックバック:Steelmont Elitex review
トラックバック:Guinea Pig
トラックバック:Valtrix Nexus AI Recensione
トラックバック:FULL PORN MOVIES
トラックバック:Vorexlan
トラックバック:Sonnen Afinitor
トラックバック:0 UK Selected Wet Cat & Dog
トラックバック:https://wiki.fc00.ru/index.php?title=Aplicacion_Informativa_Sobre_Casinos_Argentinos
トラックバック:Neronix 365 Profit Recensione
トラックバック:official MovesMethod website
トラックバック:Aureus Valtrix review
トラックバック:jet x официальный сайт
トラックバック:breast surgery
トラックバック:breaking news newspaper
トラックバック:breaking news celtic
トラックバック:Now says
トラックバック:Fulgor Tradevo
トラックバック:взломанные игры с бесконечными ресурсами
トラックバック:CyberTarcza
トラックバック:stahlwandpools bestellen stahlwandpool kaufen
トラックバック:1 UK Kitten Food
トラックバック:www.beautyduty.co.ke
トラックバック:war jihad
トラックバック:crack win microsoft activation scripts
トラックバック:crack win kmsauto net
トラックバック:Orka Mind And Wellness
トラックバック:Pro nail Complex
トラックバック:crack AIO Tools v3.1.3
トラックバック:chase travel same day flight not
トラックバック:high-quality car sweatshirts
トラックバック:MovesMethod program
トラックバック:stahlwandpool komplettset
トラックバック:Riches888
トラックバック:podcast companion
トラックバック:best payout online casino real money
トラックバック:Player & agent profile customization Real-time agent reports Full score reporting service Bilingual customer support (chat / phone) DDoS-protected sportsbook software Offshore sportsbook servers Sportsbook line and profile management Private live chat
トラックバック:Lyntrovanex
トラックバック:Best Online Casino
トラックバック:Sterk Evolux Ervaringen
トラックバック:real money social casino
トラックバック:ibet44
トラックバック:ovalbecken shop
トラックバック:https://betflik-4ui.com
トラックバック:luton airport parking,
トラックバック:MSE Capital AI
トラックバック:goldankauf aachen
トラックバック:Leal Torlian Opinión
トラックバック:Krysenvoxen TEST
トラックバック:gta v bail bonds
トラックバック:fins a la 62 i a vegades la 64
トラックバック:888NOW.COM
トラックバック:lolita porn
トラックバック:france
トラックバック:gartenpools kaufen
トラックバック:online blackjack real money
トラックバック:Honkai Star Rail Fugue
トラックバック:Memory Wave Method
トラックバック:https://www.ufabet350i.com/category/news-casino
トラックバック:MEMEK
トラックバック:VIDEO SEX ANAK TK
トラックバック:high-nordentoft.federatedjournals.com
トラックバック:Evony The Kings Return alliance guide
トラックバック:หนังโป๊
トラックバック:BloodVitals SPO2
トラックバック:888TOP
トラックバック:SimCity BuildIt events guide
トラックバック:no kyc crypto casino
トラックバック:park and ride gatwick
トラックバック:https://forum.issabel.org
トラックバック:Keanu Reeves Video Games
トラックバック:advice
トラックバック:Permanent Make
トラックバック:game slot terpercaya
トラックバック:The Epoch Times
トラックバック:ovalbecken bestellen ovalbecken shop
トラックバック:kuzey kıbrıs emlak ilanları
トラックバック:ske crystal
トラックバック:Chicken Road
トラックバック:the full details
トラックバック:biometric data ring
トラックバック:남양주출장마사지
トラックバック:SAGAMING350
トラックバック:https://willbefine.click/thuoc/binh-xit-mui-la-gi-tai-sao-duoc-nhieu-nguoi-su-dung-n375.html
トラックバック:www.mawinbet24.com
トラックバック:Black Hat SEO
トラックバック:pool stahlwand komplettset
トラックバック:Ädel Finlore Rescenion
トラックバック:swimmingpool online bestellen pool swimmingpools kaufen
トラックバック:College Karachi Call Girls
トラックバック:nonton film bajakan
トラックバック:water damage restoration
トラックバック:ovalpool online bestellen
トラックバック:https://888vi-new.com/
トラックバック:ovalbecken bestellen
トラックバック:betflik 85
トラックバック:torch gummies
トラックバック:Rentry`s website
トラックバック:miracle made sheets customer service
トラックバック:jitabaji
トラックバック:insert Your data
トラックバック:bali777 daftar
トラックバック:beneficial
トラックバック:Monte Carlo
トラックバック:Pakistani Lahore Call Girls
トラックバック:latest breaking news today
トラックバック:sofia coppola
トラックバック:https://fun88play.website3.me/
トラックバック:https://www.utmholdings.com/index.php/entertainment
トラックバック:hotel guide
トラックバック:breaking news app
トラックバック:breaking news maker
トラックバック:slot online kilat69
トラックバック:login kilat69
トラックバック:영화 다시보기
トラックバック:mines games
トラックバック:jino.ru.com lừa đảo công an việt nam cảnh báo truy quét cấm gấp
トラックバック:North Glow Edge
トラックバック:Roblox best games
トラックバック:Lyntrovanex Erfahrungen
トラックバック:Energy
トラックバック:low cost car finance
トラックバック:Command Luxerix legit or not
トラックバック:HumanDesign2028.ru
トラックバック:ставки Olimp
トラックバック:Follow-up attacks
トラックバック:Tipps Zu sportwetten
トラックバック:hdmy.ru
トラックバック:dizain-cheloveka-manifestor.ru
トラックバック:Italvenza Recensione
トラックバック:Sichentrax
トラックバック:Tiacastagno wrote
トラックバック:best online casino fast payout
トラックバック:https://admissions.iiui.edu.pk/
トラックバック:Amazing Colors
トラックバック:sportwetten Bonus Umsetzen
トラックバック:addiction
トラックバック:www.theepochtimes.com
トラックバック:Eternal Stakix
トラックバック:bauchstraffung
トラックバック:highest payout online casinos
トラックバック:binance
トラックバック:silberbesteck preis pro kg
トラックバック:miaz1234 leaked nudes
トラックバック:WATCH TOP PORN VIDEOS
トラックバック:https://www.fiverr.com/s/YR7jV7Q
トラックバック:바이비트
トラックバック:Don’t Jeopardize This
トラックバック:poolzubehör kaufen
トラックバック:tukar bateri
トラックバック:Best Call Girls in Karachi
トラックバック:Nightlife Call Girls Karachi
トラックバック:Broken Delta Berry Locations
トラックバック:Edge of Fate Expansion
トラックバック:KILAT69
トラックバック:https://www.Baldursgateguide.com/
トラックバック:aufstellpool online bestellen
トラックバック:free fortnite cheats
トラックバック:weed legality map
トラックバック:College Lahore Escorts
トラックバック:Cavrontelyx
トラックバック:Forja Finlux Review
トラックバック:best site to buy viagra online
トラックバック:bellyflush
トラックバック:rundbecken set
トラックバック:https://scilang.com/?p=40022
トラックバック:online casino malaysia
トラックバック:palworld console commands
トラックバック:protogel
トラックバック:Finavoro Recensioni
トラックバック:Gerborsyva
トラックバック:12spin
トラックバック:Click on Www.E-Sicase.com
トラックバック:british groceries online international delivery
トラックバック:Vorexlan Recensione
トラックバック:mega888 android
トラックバック:Free-to-play Shooter
トラックバック:Nexolar Wave 9.5
トラックバック:apuestas partidos de futbol hoy
トラックバック:e-kabinenroller
トラックバック:code.antopie.org
トラックバック:Episode Heresy Seasonal Weapons
トラックバック:forest match
トラックバック:oberschenkelstraffung frankfurt
トラックバック:zenless zone zero quests
トラックバック:美理容院 美容健康機器
トラックバック:66club
トラックバック:Infinitewarmhub.com
トラックバック:gartenpool set
トラックバック:movies4u
トラックバック:Destiny style Star Wars game
トラックバック:laserwaffen
トラックバック:府中 ダンススクール HIPHOP
トラックバック:coinbet9999.net
トラックバック:Thank you
トラックバック:Insurance agency Chicago
トラックバック:Affordable Call Girls in Islamabad
トラックバック:avis Casino Comparateur
トラックバック:Personal Injury Lawyer Houston
トラックバック:swimming pool komplettset winterfest
トラックバック:Well put
トラックバック:strata property service
トラックバック:owon dge2070
トラックバック:Alverixanpro Recensioni
トラックバック:trevorjd.Com
トラックバック:Https://Www.Fpsinformer.Xyz/
トラックバック:bail enforcement agent jobs ct
トラックバック:Insurance agency Greenville
トラックバック:Monteravix
トラックバック:東久留米 ダンススクール 駅近
トラックバック:Fiero Valtrix Recensioni
トラックバック:生田 ダンススクール 女性向け
トラックバック:DerilaPillows.com
トラックバック:آرش وداد
トラックバック:Valore Capitale Recensione
トラックバック:onewave solar water heater
トラックバック:AverinexMax
トラックバック:Investra Gpt TEST
トラックバック:Bürocontainer Wohncontainer Bürocontainer Wohncontainer Bürocontainer Wohncontainer Bürocontainer Wohncontainer Bürocontainer Wohncontainer Bürocontainer Wohncontainer Bürocontainer Wohncontainer Bürocontainer Wohncontainer Bürocontainer Wohncont
トラックバック:Elden Ring Co-Op Mod
トラックバック:Senvix AI
トラックバック:Noryal Vexor Avis
トラックバック:طراحی سایت اصفهان
トラックバック:Coratechcoin
トラックバック:Sonnen Reopro TEST
トラックバック:https://md.swk-web.com
トラックバック:business ideas for the summer
トラックバック:service client Space Fortuna
トラックバック:美容健康機器輸入ビジネス相談
トラックバック:alkaline
トラックバック:plateforme Casino 2 Fou
トラックバック:casino comparateur
トラックバック:Hitman GO mobile
トラックバック:Instant Payout Casinos
トラックバック:Highline Wellness Gummies
トラックバック:888TOP.COM
トラックバック:apuestas campeon Liga bbva
トラックバック:t shirt printing services singapore
トラックバック:xur Loot Pool 2025
トラックバック:once human console Release
トラックバック:Authordheerajmehrotra.Com
トラックバック:demo slot pgsoft
トラックバック:dubai7
トラックバック:hospital.sarprize.com
トラックバック:pool contractors
トラックバック:chặt đầu nguyễn xuân đạt clip
トラックバック:Navitoto
トラックバック:Many thanks
トラックバック:top tropical destinations
トラックバック:content
トラックバック:Top 10 mẫu đồng hồ nữ bán chạy nhất
トラックバック:Insurance agency Abilene
トラックバック:phising bujang
トラックバック:car battery shop open now
トラックバック:Sterk Kalvix Ervaringen
トラックバック:solo mode difficulty
トラックバック:viagra asli murah
トラックバック:Unblocked
トラックバック:heart rate monitor
トラックバック:Party Karachi Call Girls
トラックバック:claritox pro
トラックバック:genshin impact 4.8 release date
トラックバック:Best Betting Sites UK
トラックバック:stem cell clinic thailand
トラックバック:spccer prediction soccer predictions soccer picks
トラックバック:best realmoney casinos canada
トラックバック:Genshin impact characters
トラックバック:Blackrose Finbitnex Betrug
トラックバック:TOPAN WIN
トラックバック:kat
トラックバック:hack.allmende.io
トラックバック:Logic Akpro Ark
トラックバック:Insurance agency near me
トラックバック:Algo Aloxi Fin legit or not
トラックバック:Alexo AI Rescenion
トラックバック:visiter casino-comparateur.fr
トラックバック:Mitch Mula
トラックバック:https://go.bubbl.us/ee2264/40c5?/Bookmarks
トラックバック:Warren AI Pro legit or not
トラックバック:Insurance agency Gonzales
トラックバック:okrummy
トラックバック:4 cat active and happy
トラックバック:visiter Bonus-Sans-Depot.casino
トラックバック:CypherTraderAI Recensioni
トラックバック:casino online bitcoin
トラックバック:máquina inspección rayos X equipaje México
トラックバック:wipeoutads.com
トラックバック:gartenpool komplettset
トラックバック:pari sportif rugby
トラックバック:monopoly derby Edition
トラックバック:New Subclasses Builds
トラックバック:HICHEM BOUHEMAMA
トラックバック:new online casino
トラックバック:milf br
トラックバック:Insurance agency
トラックバック:is da kine bail bonds still in business
トラックバック:драгон мани зеркало
トラックバック:use Climbing Channel here
トラックバック:c astellano
トラックバック:Mattress Cleaning service
トラックバック:Tyshawn Good – State Farm Insurance Agent
トラックバック:how to get help in windows
トラックバック:nampa tsurekomi jav
トラックバック:Insurance agency Malverne
トラックバック:algorithme paris sportif avis
トラックバック:funny automotive shirts
トラックバック:Torexian TEST
トラックバック:Best Escorts in Lahore
トラックバック:flixy tv stick buy
トラックバック:부평마사지
トラックバック:Ren Vaultix Rescenion
トラックバック:Freund Gentak
トラックバック:std motorcycle
トラックバック:https://Www.Pxtlabs.com
トラックバック:тюнинг машины
トラックバック:head to Nextistanbul
トラックバック:8 zooplus – the leading online pet shop for pet food & accessories
トラックバック:State Farm Insurance Agent
トラックバック:photos of the most beautiful woman in the world
トラックバック:Renemorafin Avis
トラックバック:regle paris sportif multiple
トラックバック:avis Arlequin Casino
トラックバック:critique Casino Extra
トラックバック:Gratorama Casino Avis
トラックバック:GrandZ Casino
トラックバック:Z09 file support
トラックバック:Wonderful
トラックバック:омода автомобиль
トラックバック:Skicklig Finvoro Rescenion
トラックバック:pfeifen ascher
トラックバック:macbook air apple
トラックバック:benda motorcycle
トラックバック:motorcycle decal
トラックバック:Live Cam Sex
トラックバック:видеорегистратор видеонаблюдения
トラックバック:free nude chat
トラックバック:rs485 cable
トラックバック:the most beautiful flowers of the world
トラックバック:ARHT Home Solutions
トラックバック:small business event ideas
トラックバック:cheap sex shows
トラックバック:VitaSeal wellness brand
トラックバック:powerbeats pro 2 review
トラックバック:下载 热门色情视频
トラックバック:corporate event venues
トラックバック:what is the next ethereum
トラックバック:календарь красоты и здоровья
トラックバック:massage for fibromyalgia
トラックバック:pfeifenascher
トラックバック:nda for business idea
トラックバック:freebetiality vedios
トラックバック:ridley motorcycle
トラックバック:best online casino australia reddit
トラックバック:введение подвески автомобиля
トラックバック:aufstellpool
トラックバック:mazing cat blowjob
トラックバック:газон автомобиль
トラックバック:фото автомобиля
トラックバック:pepe tabak
トラックバック:Wettquoten Berechnen
トラックバック:calcul Cote paris sportif
トラックバック:зд тюнинг
トラックバック:Model Islamabad Call Girls
トラックバック:Cocoa Casino Avis
トラックバック:rundbecken online bestellen rundpool set rundpool shop rundpool terrasse rundpools bestellen rundpools online bestellen rundpools set rundpools shop
トラックバック:jeux disponibles sur Staxino
トラックバック:JetBlack
トラックバック:kampfsport wetten Deutschland
トラックバック:Touch Casino Avis
トラックバック:hack.allmende.io published an article
トラックバック:Betify casino avis
トラックバック:Online Totalizators
トラックバック:http://www.haxorware.com/forums/member.php?action=profile&uid=400608
トラックバック:situs terbaik
トラックバック:step sister porn hub
トラックバック:kiri amari leaked erome
トラックバック:https://Iconicbrand.Com/wp/index.Php/2025/12/03/zebra-wins-sportwetten-tipps/
トラックバック:most beautiful car of the world
トラックバック:WettbüRo Bremerhaven
トラックバック:спойлер стеклоочистителя
トラックバック:Heat Space
トラックバック:Wow
トラックバック:Derila Ergonomic Pillow
トラックバック:bujang
トラックバック:Top 10 mẫu đồng hồ nữ bán chạy nhất
トラックバック:Primal Beast build
トラックバック:misswhosstore
トラックバック:gt world of beauty gmbh frankfurt
トラックバック:FREE THREESOME PORN CLIPS
トラックバック:эконет красота и здоровье
トラックバック:Healthy Flow Wellness
トラックバック:บาคาร่า
トラックバック:warzone mobile Smg guide
トラックバック:Car insurance
トラックバック:pictures of the most beautiful lady in the world
トラックバック:完美世界开服一条龙制作
トラックバック:Bokep Afrika Orang Hitam
トラックバック:link SINAGA123
トラックバック:hiếp dâm trẻ em
トラックバック:Cyber Heater Home
トラックバック:game Walkthroughs
トラックバック:Buy Dilaudid 8mg Online
トラックバック:critique Davinci Gold
トラックバック:68WIN
トラックバック:nail health
トラックバック:glpro
トラックバック:Ghillie Suit Pubg
トラックバック:Destiny 2 Edge Of Fate Expansion
トラックバック:Compare Van Finance
トラックバック:Live Cam Sex Free Porn Videos & Sex Movies Porno XXX @by_Papi_Sex
トラックバック:best altcoins for next bull run reddit
トラックバック:wandfolie
トラックバック:download clip bokep indo
トラックバック:animezoneplus.Com
トラックバック:t shirt t shirt printing singapore t shirt printing t shirt printing singapore t shirt printing services singapore
トラックバック:lũ lụt miền trung chết 2000 người
トラックバック:Adult Sex Comics
トラックバック:Tsaritsa Lore
トラックバック:zzz Pan yinhu
トラックバック:Luxury Karachi Escorts
トラックバック:good decaffeinated Coffee
トラックバック:Proven renovation process 5 step
トラックバック:microsoft help center
トラックバック:möbelfolie
トラックバック:minathehotwife erome
トラックバック:Kjerne Finevox
トラックバック:rata kau kontol
トラックバック:ZEUS711
トラックバック:Pagtrix Ai
トラックバック:zigarettenhülsen
トラックバック:Buchmacher öSterreich
トラックバック:Eliora Veyant
トラックバック:mamiqq
トラックバック:cheap jordans shoes
トラックバック:Full Body Waxing
トラックバック:Btc Drevola 70 Recensione
トラックバック:Nuvantrapex TEST
トラックバック:tapentadol online
トラックバック:Fortress Fence Company
トラックバック:Drdyatirimciiliskileri official
トラックバック:komdigi
トラックバック:nude webcam forum
トラックバック:Link Resmi Joki55
トラックバック:Crypto Trading
トラックバック:counter-strike 2 Tips
トラックバック:Wuthering Waves Tier List
トラックバック:https://www.reverbnation.com/artist/cygder
トラックバック:zeekr электромобиль
トラックバック:statistique paris sportif
トラックバック:https://jiliko1225comph.hashnode.dev/jiliko1225
トラックバック:https://fun88play.amebaownd.com/
トラックバック:CIPATOTO LOGOGOTEL BETOGEL jelatta REGOTOTO JUALTOGEL TOTO88
トラックバック:gengtoto
トラックバック:видеорегистратор roadgid
トラックバック:Lysbjerg Portalis Anmeldelse
トラックバック:стаканы подвески автомобиля
トラックバック:https://www.xiuwushidai.Com
トラックバック:site Paris sportif bonus cash
トラックバック:Lorviatex
トラックバック:Jonitogel
トラックバック:iptv in het land
トラックバック:Truly
トラックバック:https://xxsv75p7-staging.dreamwpp.com/2025/11/02/melbet-zerkalo-rabochee-segodnya-2025/
トラックバック:Painting Company
トラックバック:ovalpools bestellen
トラックバック:Lider
トラックバック:https://sketchfab.com/jawliver6
トラックバック:avis Jackpot City
トラックバック:Zelda Food Effects
トラックバック:Neurosilence . Neurosilence official website . Neuro silence
トラックバック:iptv nederland
トラックバック:casino high fly bet
トラックバック:bellanoir location palworld
トラックバック:use Cap Sangjin here
トラックバック:losování
トラックバック:cheap nike shoes from china free shipping
トラックバック:Switch Edex Fin Avis
トラックバック:Bitzest Genius
トラックバック:тюнинг 2114
トラックバック:QuantumTraderX review
トラックバック:kann man beim juwelier schmuck verkaufen
トラックバック:realtime fantasy sports sign in
トラックバック:سئو کلینیک پوست و مو
トラックバック:VTOL Jets tips
トラックバック:Libetrio のレビュー
トラックバック:https://www.sociomix.com/u/fun88play/
トラックバック:Veltrion Pulse 85
トラックバック:Netto Paytorn Recensione
トラックバック:Helau Alaaf
トラックバック:tukang phising
トラックバック:https://community.wongcw.com/blogs/1175427/鈔有感-Online-帶你進入公平安全科技支撐的娛樂宇宙
トラックバック:Lotemax Pro review
トラックバック:Mira Gainlink
トラックバック:protein gummies review
トラックバック:Varontavex Erfahrungen
トラックバック:https://www.conaculregilor.ro/2025/11/02/melbet-onlayn-stavki-na-sport-2025/
トラックバック:beauty health wellness
トラックバック:heavy duty towing atlanta
トラックバック:free sex
トラックバック:Gibson guitar controller
トラックバック:Goldspire Nexor
トラックバック:aviator predictor
トラックバック:Bali Guide 2026
トラックバック:Robust IT Compliance
トラックバック:1win aviator download apk
トラックバック:Physiotherapy Supplies
トラックバック:medaillen verkaufen medaillen verkaufen medaillen verkaufen medaillen verkaufen medaillen verkaufen medaillen verkaufen medaillen verkaufen medaillen verkaufen medaillen verkaufen medaillen verkaufen medaillen verkaufen medaillen verkaufen medaillen verka
トラックバック:how to use operator skills in cod mobile
トラックバック:hot hot fruit betway login
トラックバック:aviator hack bot
トラックバック:kerassentials
トラックバック:neuro sharp
トラックバック:plinko gambling game
トラックバック:spinmama es
トラックバック:predictor aviator
トラックバック:3 UK 2026 cat litter and litter tray
トラックバック:Starcrest Zynor
トラックバック:5 UK 2026 Orijen Original Grain Free Dry Cat Food
トラックバック:NuvanTrapex
トラックバック:hibachi vs teppanyaki catering
トラックバック:Nettvern
トラックバック:عصر تجارت
トラックバック:bokep viral terbaru indonesia
トラックバック:internet wetten
トラックバック:Veltrion Pulse 8.5
トラックバック:Https://Apexherozone.com/
トラックバック:https://docs.google.com/presentation/d/1rXi0wlE-_XODf9BkhmJwtN4Fujq6xfO423VqTSp4yoI/edit?usp=sharing
トラックバック:Edgeway Crescor
トラックバック:head to www.cap-rs485-nhap-khau.xyz
トラックバック:Vumon Vision
トラックバック:iptv in 2026
トラックバック:Faschingsdienstag geschlossen
トラックバック:amaanprdp869274.azzablog.com
トラックバック:plinko casino
トラックバック:海王
トラックバック:Chapter 6 Season 3 skins
トラックバック:best payout online slots
トラックバック:amp89ku.com
トラックバック:salvatore ferragamo dress shoes and matching belts
トラックバック:vegas11 login
トラックバック:Car for rent in Colombo
トラックバック:Rosenmontag
トラックバック:lenstogel DINGDONGTOGEL WAKTOGEL INFini88 tisutatoto
トラックバック:amazing thomas d mangelsen grizzlies
トラックバック:vipbet88 viptogel TCPTTOGEL TOKYO88 JEBOLTOTO
トラックバック:Energy revolution System
トラックバック:механизм стеклоочистителей
トラックバック:9 UK food and cat food brands
トラックバック:Female agents csgo
トラックバック:1 UK 2026 cat food made with natural
トラックバック:Herpesyl
トラックバック:income
トラックバック:Trial Lawyer
トラックバック:Dbdportal.Com
トラックバック:Https://Mobapulse.Com/Articles/Jakiro-Guide-2025-Dominate-Dota-2-Ranks-With-This-Op-Support-Hero.Html
トラックバック:Privatrechtsschutz
トラックバック:gameplay Customization
トラックバック:koleksi bokep indo terbaru
トラックバック:el gameplay de augusta
トラックバック:Process step renovation 5 proven
トラックバック:retraits sur Avantgarde
トラックバック:chronoboost pro
トラックバック:EREA
トラックバック:Wildperrichepsi.porn
トラックバック:Kelly Kelly Oriental Kelly Oriental Aesthetic Clinic Aesthetic Clinic Aesthetic Clinic Singapore
トラックバック:sportwetten bonus Auszahlen
トラックバック:mirror image handbags
トラックバック:test bank for Pearson textbooks free sample
トラックバック:Can you accelerate my bitcoin transaction
トラックバック:üBer Unter Wetten Prognose
トラックバック:the learning company computer games
トラックバック:helpcenter.Logintrade.pl
トラックバック:trang chủ 789K
トラックバック:Gagan’s website
トラックバック:escort service in Karachi
トラックバック:Ognezaschita.Center
トラックバック:fromsoftware 2025
トラックバック:Krapfen Fasching
トラックバック:Islamabad escort service
トラックバック:Dead Space Remake
トラックバック:Cap Sangjin site
トラックバック:Minecraft biomes transformation
トラックバック:yupoo nike topstoney yupoo yupoo jersey yupoo gucci yupoo clothes yupoo dior yupoo louis vuitton yupoo sneakers yupoo watches yupoo zapatillas yupoo aliexpress yupoo jordan aliexpress yupoo yupoo bags yupoo balenciaga yupoo rolex dior yupoo yupoo designer
トラックバック:actividades en Sevilla
トラックバック:Zinsorex
トラックバック:vidio bokep viral
トラックバック:Karachi Call Girls
トラックバック:men’s biker sweatshirts
トラックバック:Primogems Meta Strategy
トラックバック:casino online best payout
トラックバック:olxtoto
トラックバック:Axtrovien
トラックバック:Finvontex
トラックバック:Females Escorts in Karachi
トラックバック:Escorts in Lahore
トラックバック:fliesen überkleben
トラックバック:roller werkstatt in der nähe scooter shop scooter tuning
トラックバック:Flusso Montalux
トラックバック:e-scooter
トラックバック:파주마사지
トラックバック:Karachi Escorts
トラックバック:датчик абс опель астра g
トラックバック:SPA in Karachi
トラックバック:Women’s Knitwear supplier
トラックバック:online casino instant payout
トラックバック:Islamabad Escorts
トラックバック:find out
トラックバック:小黄片
トラックバック:xanax for sale online
トラックバック:poolzubehör shop
トラックバック:Limited code
トラックバック:roof inspection Centerton
トラックバック:составляющие рулевого управления
トラックバック:Wertalmpro Erfahrungen
トラックバック:ZyphorBit
トラックバック:Travel-Themed T-Shirts For Children
トラックバック:топливный насос 2114
トラックバック:Gamma Hydroxybutyrate (GHB) Powder for sale online
トラックバック:Vestomartex
トラックバック:Order Gamma Hydroxybutyrate (GHB) Powder Online
トラックバック:Las Vegas magician
トラックバック:best treatment for surgical scars
トラックバック:Baliza V16 Para Autocaravanas Y Campers
トラックバック:Baliza v16 para conductores noveles consejos
トラックバック:https://Body-positivity.org/
トラックバック:open world star wars game
トラックバック:cm88
トラックバック:Intensidad MíNima Exigida Para Baliza V16
トラックバック:ai
トラックバック:qué pasa si no Llevo baliza v16 cuando sea obligatoria
トラックバック:best perks overwatch 2
トラックバック:baliza v16 para coches De alquiler
トラックバック:best iptv
トラックバック:Soccer Win Bet
トラックバック:qué Normativa Regula la baliza v16
トラックバック:Azbongda.com
トラックバック:Minecraft creative builds
トラックバック:pueden Multarme por no llevar baliza V16
トラックバック:cada cuánto hay que cambiar la baliza v16
トラックバック:драгон мани официальный сайт
トラックバック:Http://Ministerioshebrom.com/
トラックバック:Rawalpindi Call Girls
トラックバック:Https://Overwatch2Base.Com/overwatch-2-winter-wonderland-2025-returns-with-festive-game-modes-and-Exclusive-rewards
トラックバック:Blick Montrevex
トラックバック:pool chlorinators
トラックバック:playjonny casino
トラックバック:fast withdrawal slots
トラックバック:Cryntoris Helia 7.6
トラックバック:spin mama ελλάδα
トラックバック:hautstraffung
トラックバック:aviator predictor apk
トラックバック:gunz blockchain
トラックバック:Karachi Escorts
トラックバック:lừa đảo chuyến bay vn168
トラックバック:https://elite.ru.com/
トラックバック:IS
トラックバック:Adventure Game News
トラックバック:haval m6 narxlari uzbekistan
トラックバック:Miliastra wonderland
トラックバック:was ist kombiwette
トラックバック:Wett Tipps Heute Vorhersage
トラックバック:dragon money отзывы
トラックバック:kimhungimex.com
トラックバック:программатор чип тюнинга автомобилей
トラックバック:1xbet aviator
トラックバック:genshin Impact Snezhnaya release Date
トラックバック:stepsister blowjob
トラックバック:qué productos herbalife necesito según mi objetivorecetas con batido herbalife
トラックバック:zinnkrüge verkaufen
トラックバック:Private Islamabad Call Girls
トラックバック:3 food for cats & dogs
トラックバック:automotive college in Selangor
トラックバック:concrete cleaning near me
トラックバック:stem cell therapy Malaysia
トラックバック:SLG Game events
トラックバック:SPA in Karachi
トラックバック:poolleitern bestellen
トラックバック:Call Girls in Lahore}
トラックバック:https://vn168.bar/
トラックバック:Avelixio Recensione
トラックバック:Rechtsbereiche im Rechtsschutz
トラックバック:https://www.horticulturaljobs.com/employers/3912439-jiliko1225
トラックバック:dust 2 Map Pool
トラックバック:5 UK Reptile Vivariums & Cabinets
トラックバック:human trafficking video
トラックバック:Plumbers Phoenix
トラックバック:jogo do tigrinho grátis
トラックバック:mycosyn pro
トラックバック:available at bgame88.video.blog`s website
トラックバック:Techtrics Auto Mercedes Workshop Malaysia
トラックバック:Www.Apexlegendshq.Com
トラックバック:4 UK dog loves this food
トラックバック:jack the ripper killer
トラックバック:dimension marquage au sol stop
トラックバック:schwimmbadfolie kaufen
トラックバック:serial killer children
トラックバック:how to kill your child
トラックバック:pil pelangsing instan
トラックバック:visit Blogspot
トラックバック:Tivra Dovonex 27
トラックバック:NordaFinextra
トラックバック:Prisma Luxerise
トラックバック:Avelixio
トラックバック:1st copy handbags online
トラックバック:short sale
トラックバック:led light therapy at home
トラックバック:plinko game avis
トラックバック:restolin
トラックバック:Grandridge Lorvix
トラックバック:mombasa escorts
トラックバック:TynavoGrows
トラックバック:Antares Portdex
トラックバック:https://www.cap-dieu-khien-sangjin.xyz/2020/10/cap-ieu-khien-khong-luoi-sangjin.html
トラックバック:underrated role-playing Games
トラックバック:Young Lahore Call Girls
トラックバック:https://mnqfe.sa.com
トラックバック:اخبار ورزشی
トラックバック:QuantiaGPT v3+
トラックバック:supplements
トラックバック:dara casino login
トラックバック:hairfortin
トラックバック:simbolslot link
トラックバック:how long is act 4 Of nod krai
トラックバック:Fashioned
トラックバック:Arçelik servis
トラックバック:playjonny
トラックバック:韓国ブランドコピー
トラックバック:Model Escorts in Karachi
トラックバック:vinyl pool installation
トラックバック:validate your list now
トラックバック:Erotic Massage
トラックバック:Welkin Moon Value
トラックバック:hp9 guard
トラックバック:check your email quality
トラックバック:improve campaign performance
トラックバック:constellation Paywall
トラックバック:Findorex Erfahrungen
トラックバック:best hosting for UK business websites
トラックバック:Rapido Fintoris
トラックバック:deductible vs copay
トラックバック:trx address
トラックバック:Criminal Factions Star wars
トラックバック:vanity address generator
トラックバック:faith-based victory over opposition
トラックバック:Shift Lotemax Sys
トラックバック:Dawmirah Pefumes
トラックバック:best online gambling
トラックバック:https://tifcc.phpage.fr
トラックバック:Nicolaspqkt582796.Life3Dblog.Com
トラックバック:Voralyx Pulse 92 Review
トラックバック:Rapido Fintoris Recensione
トラックバック:Thanks
トラックバック:software
トラックバック:lipödem therapie
トラックバック:roofers near me
トラックバック:Go99
トラックバック:https://babu88bg.com/
トラックバック:Loba abilities guide
トラックバック:best handheld For elden ring
トラックバック:Escorts in Rawalpindi
トラックバック:Cheap Escorts in Karachi
トラックバック:energize
トラックバック:Escorts Available in Lahore
トラックバック:казино монро
トラックバック:drip казино зеркало
トラックバック:futuristic cyberpunk PNG
トラックバック:Ritmo Portvex Recensio
トラックバック:SPA in DHA Karachi
トラックバック:https://pukkabookmarks.Com/story20589722/quick-bike-insurance-ride-with-confidence-today
トラックバック:Swiftgate Montark
トラックバック:legit online casino
トラックバック:아이온2 부주 업체
トラックバック:random trx address
トラックバック:Altrevoducthai
トラックバック:suncity 888
トラックバック:cómo explicar a los Niños para qué sirve la baliza v16
トラックバック:Kylvarix
トラックバック:Fincome Nexboost
トラックバック:Vangbot
トラックバック:https://jobs.lajobsportal.org/profiles/7627490-jiliko1225-casino
トラックバック:Https://Wp.Smgs.Si/Www.Remedium.Si/Base-Pari-Sportif-Ligue-1
トラックバック:Xyvorelintus
トラックバック:cómo guardar la baliza V16 en el vehículo
トラックバック:Https://Plamosoku.Com/
トラックバック:Https://body-positivity.org
トラックバック:Good Quality JWH-018 online
トラックバック:بزرگترین املاک در ملارد
トラックバック:dragon money studio озвучка
トラックバック:รวยชัวร์ 99
トラックバック:https://www.protopage.com/
トラックバック:Escorts in Hotels Karachi
トラックバック:Antares Finviora Review
トラックバック:trademarks attorney
トラックバック:https://www.srpackaging.in.net/
トラックバック:tron generator
トラックバック:Minecraft Cheats
トラックバック:définition bankroll paris sportif
トラックバック:see for yourself
トラックバック:ladies gym
トラックバック:cómo mantener la baliza v16 en buen estado
トラックバック:cómo actuar en una averíA Con Baliza V16
トラックバック:dermatology supplies
トラックバック:Baliza V16 Para Motoristas Y Ciclistas
トラックバック:Independent Escorts in Karachi
トラックバック:мелстрой и казино
トラックバック:Pari sportif en ligne ufc
トラックバック:Buy Ketamine Powder Online
トラックバック:We Are Era Music BV
トラックバック:sodo casino
トラックバック:hydrocolloid bandage
トラックバック:x88 vip
トラックバック:start cleaning your list
トラックバック:roof mounted camera
トラックバック:affordable
トラックバック:Capital Altrion
トラックバック:Irongate Luxten
トラックバック:Caustic strategies
トラックバック:Pilier Finward
トラックバック:digi 995 universe puzzle
トラックバック:Order JWH-018 online
トラックバック:shbet800
トラックバック:thienhabet
トラックバック:Прокапаться от алкоголя на дому в Сочи
トラックバック:Swiftbit Invexor Review
トラックバック:anti itch cream lotion
トラックバック:syrup bottle pumps
トラックバック:film bokep
トラックバック:Fincome Nexboost Review
トラックバック:Cardiform
トラックバック:Call Girls Karachi
トラックバック:Gagnor Gpt
トラックバック:Swap Levora Opt
トラックバック:how much does ketamine cost
トラックバック:NethertoxAGENT
トラックバック:Echoxen
トラックバック:Libera’Chie Sumo SaChie
トラックバック:Sex trẻ em
トラックバック:ketikmedia.com
トラックバック:www.gain-dragon.ru
トラックバック:inground pool installation near me
トラックバック:Swagg Roofing & Siding
トラックバック:cosy motorcycle Hoodies
トラックバック:pk.vipdhaoxygenspa.com
トラックバック:vip.mahamescorts.com
トラックバック:x88
トラックバック:x88.help
トラックバック:x88-game.com
トラックバック:x8betvn.com
トラックバック:jerukbet
トラックバック:Gull Bitlinje
トラックバック:korsan taksi izmir
トラックバック:tr
トラックバック:Ordexiabot
トラックバック:일회용 전자담배
トラックバック:zzchaote
トラックバック:Laylabzfm835646.Bloggosite.com
トラックバック:Rans88
トラックバック:zsosr
トラックバック:zrtxzbjt
トラックバック:zqslbs
トラックバック:Vektor Tradeviax
トラックバック:cartomanzia dea bendata
トラックバック:Purchase Caluanie Muelear Oxidize online
トラックバック:fast payout casino
トラックバック:Fairgo Casino
トラックバック:theepochtimes.com
トラックバック:blue horse trick
トラックバック:Cat Casino
トラックバック:beste iptv
トラックバック:777Slots Bay Casino
トラックバック:Evo BridgeEvo Bridge
トラックバック:Prime Casino
トラックバック:VIP Independent Escorts Karachi
トラックバック:321 Crypto Casino
トラックバック:plinko hra
トラックバック:Konfambet Casino
トラックバック:klebefolie boden
トラックバック:Hot SPA In Karachi
トラックバック:drugs dealer
トラックバック:assignment writing
トラックバック:teroris
トラックバック:TetherBet Casino
トラックバック:hermes replicas
トラックバック:Thank you
トラックバック:zbxbxgb.com
トラックバック:https://sillimmsg.clickn.co.kr/
トラックバック:yuzhongguo
トラックバック:Finmane Bitaris
トラックバック:yu clean
トラックバック:dragon tiger online casino
トラックバック:youkeding
トラックバック:yongyimax
トラックバック:LoadUp
トラックバック:https://yjzglm.com/
トラックバック:yizhicao
トラックバック:yiyunyule
トラックバック:yiscar
トラックバック:yingyuwan
トラックバック:yihewangluo
トラックバック:mature teen sex pornhub video – видео для взрослых xxx
トラックバック:yh-med.com
トラックバック:Yupoo Prada
トラックバック:aufstellbecken bestellen
トラックバック:rundpools online bestellen
トラックバック:latina sex dance porn
トラックバック:humorous car T-Shirts
トラックバック:yyqgjkpat eyxcywmjjsq
トラックバック:luxury fashion accessories
トラックバック:https://okeslot168login.com/melbet-kontora-zerkalo-2025/
トラックバック:yiqbt
トラックバック:ksafcq
トラックバック:lunchtime results
トラックバック:Casino Grand Bay
トラックバック:gay porn
トラックバック:Mejores Batidos Para Bajar Barriga
トラックバック:mejores productos Herbalife Para adelgazar
トラックバック:Titan Rise Health
トラックバック:Andromeda Casino
トラックバック:Titan Rise Performance
トラックバック:digestion and satiety support
トラックバック:Flixy Official
トラックバック:nude child
トラックバック:pafmmvi
トラックバック:loan calculator loan calculator
トラックバック:靓号生成
トラックバック:play Okrummy rummy
トラックバック:Belly Flush
トラックバック:intellectual property ownership
トラックバック:porno italiano
トラックバック:competitive rummy apps
トラックバック:rikzqzbv
トラックバック:Hermes Kelly Puerto Rico
トラックバック:lapor kominfo
トラックバック:certified public accountant
トラックバック:Nest
トラックバック:Patient Acquisition agency
トラックバック:7 Situs Togel Terpercaya dengan Jackpot Terbesar
トラックバック:rare address
トラックバック:Daftar Bolagila
トラックバック:Daftar Feedbet
トラックバック:tron wallet generator
トラックバック:7 Cat Food keeps my cats
トラックバック:cnlumh
トラックバック:sell my motorcycle
トラックバック:xybn
トラックバック:xtreehp
トラックバック:xqbyx
トラックバック:oxfwdqu
トラックバック:situs slot 4d
トラックバック:maths tuition teacher in sharjah
トラックバック:रश्मिका मंदाना xxx
トラックバック:ace ultra premium rose delight
トラックバック:online math chat room tutor
トラックバック:wplay descargar
トラックバック:11uuvin.com
トラックバック:Arvo Bitron
トラックバック:trc20 wallet generator
トラックバック:xn88 game
トラックバック:Vista Montorix
トラックバック:Gynavotrade
トラックバック:Buy Custom Instagram Comments
トラックバック:Cheers
トラックバック:DOWNLOAD TOP PORN VIDEOS
トラックバック:starships
トラックバック:Bit Edge AI
トラックバック:Skok Bitrow
トラックバック:online casinos real money
トラックバック:Bexlorit Recensione
トラックバック:https://webradio.tools/index.php?action=profile;area=Forumprofile
トラックバック:sàn tiền ảo lừa đảo
トラックバック:SeoriTokan
トラックバック:https://forest-arrow-game.click/
トラックバック:lừa đảo bitcoin
トラックバック:spino gambino
トラックバック:впн для андроид бесплатный в россии скачать
トラックバック:klebefolie muster
トラックバック:Bexlorit Avis
トラックバック:Okrummy mobile app
トラックバック:spin macho casino online
トラックバック:bomb jihad
トラックバック:футбол новости мира
トラックバック:halal indian food
トラックバック:www.PrimeBoosts.com
トラックバック:https://www.aparat.com/u_34856591/about
トラックバック:casino 99ok uy tín
トラックバック:Rescron Ai
トラックバック:1xbet promo code free spins india
トラックバック:Professional Call Girls in Lahore
トラックバック:Bexlorit
トラックバック:Zyren Mint
トラックバック:GLPro order now
トラックバック:Rápido Fincoura Reseña
トラックバック:ydjd9527.com
トラックバック:Kyrol Ambien
トラックバック:a maths tutor singapore
トラックバック:math tuition at home
トラックバック:Sec 3 Math Topics
トラックバック:best math tutoring
トラックバック:tuition center singapore
トラックバック:tuition center
トラックバック:math tuition jc
トラックバック:sec 3 e math paper
トラックバック:additional maths tuition singapore
トラックバック:singapore top math tutors
トラックバック:tuition classes
トラックバック:Singapore Tuition
トラックバック:jc 2 math tuition
トラックバック:o level amath syllabus
トラックバック:p5 math tuition singapore
トラックバック:smb.lagrangenews.com
トラックバック:live casino
トラックバック:наклейка на ксеноновую фару
トラックバック:дизайн руля автомобиля своими руками
トラックバック:digi 995 pumpkin sentinel nft
トラックバック:live casino
トラックバック:window cleaning mississauga
トラックバック:amath prelim papers
トラックバック:tuition agency
トラックバック:cmtntnrhbera pbdtkxet
トラックバック:siteyi ziyaret et
トラックバック:Online Oxycodone Pharmacy
トラックバック:kids clipart PNG
トラックバック:التخدير
トラックバック:охладитель для автохолодильника
トラックバック:join jihad troops
トラックバック:https://x.com/jiliko1225org
トラックバック:comment-184068
トラックバック:social media marketing
トラックバック:네이버 실명 아이디 구매
トラックバック:Fightnewsplus.Com
トラックバック:lightweight Earphones Cases
トラックバック:Skyspire Lorin
トラックバック:Investpro Ai
トラックバック:Revexium
トラックバック:Finance Éclairée
トラックバック:MOBA Game Guide
トラックバック:Haltrovex
トラックバック:Zryw Finoble
トラックバック:best online crypto casinos
トラックバック:Lahore Call Girls
トラックバック:Islamabad Call Girls
トラックバック:hi.islamabadkitkatcallgirls.com
トラックバック:m98 เข้าสู่ระบบ
トラックバック:1xbet promo code free spins no deposit
トラックバック:online business
トラックバック:sell viagra capsule
トラックバック:789bet ทางเข้า มือถือ
トラックバック:المختبرات الطبية
トラックバック:jual obat aborsi
トラックバック:اخبار المغرب
トラックバック:vai debet
トラックバック:Caleb Fournier and Lisa Pollner
トラックバック:Baliza v16 y Seguro del Coche relación
トラックバック:dónde tirar una baliza v16 que No funciona
トラックバック:qué Baliza v16 Elegir según el uso
トラックバック:baliza v16 Y protección del medio ambiente
トラックバック:cuánto dura la batería de una baliza v16
トラックバック:CuáNdo Será Obligatoria La Baliza V16
トラックバック:become more intelligent,
トラックバック:puedo usar La baliza v16 dentro del vehíCulo
トラックバック:6 UK 2026 Reptile Food
トラックバック:Detaylar için bak
トラックバック:1xbetfreespins
トラックバック:ทางเข้า 789bet
トラックバック:Lisa Pollner nude photographs
トラックバック:Prime Boosts Official
トラックバック:cuál Es la Sanción por no llevar baliza v16
トラックバック:전자담배 액상추천
トラックバック:baliza v16 en viajes al extranjero sirve igualmente
トラックバック:cómo colocar la baliza v16 en el techo
トラックバック:Caleb Fournier naked photos
トラックバック:гараж наемных авто 9 букв
トラックバック:Elegir zapatos de estilo boho
トラックバック:puedo usar Baliza v16 fuera de españa
トラックバック:sex children bokep
トラックバック:Ventajas de usar baliza V16 conectada
トラックバック:baliza v16 para flotas de vehículos
トラックバック:www.Speedway-world.pl
トラックバック:es Obligatorio llevar baliza v16 actualmente
トラックバック:Caswino
トラックバック:Baliza V16 Obligatoria A Partir De CuáNdo
トラックバック:download windows crack 2025
トラックバック:заказать автомобильные шторки трокот
トラックバック:https://ybbal.com
トラックバック:Home our renovation process
トラックバック:unscramble words game
トラックバック:Prime Boosts Official
トラックバック:locksmiths consett
トラックバック:Camastil 100mg
トラックバック:BloodVitals test
トラックバック:Top Christmas Toys
トラックバック:9 Dry Dog Food
トラックバック:call of duty mobile Story guide|https://codmobileinsight.com/
トラックバック:البصريات
トラックバック:zapacitu01
トラックバック:Palworld Hunting guide
トラックバック:1xbet-promofree
トラックバック:Party attire UK
トラックバック:Hammer of thor
トラックバック:2 UK 2026 Pet Technology For Cats
トラックバック:incelemek için
トラックバック:playa de los cristianos
トラックバック:BitAlfard Recensioni
トラックバック:العلاج الطبيعي
トラックバック:Braylenth Quantum 92 Review
トラックバック:Massage studio Berlin
トラックバック:Valorium Dexeris scam
トラックバック:electric car game walkthrough|https://evinsightzone.com/
トラックバック:1 UK Offer Spotlight
トラックバック:best no id casinos
トラックバック:dog and kid clipart
トラックバック:https://vimeo.com/jiliko1225org
トラックバック:lasix uses
トラックバック:bokep viral hijab
トラックバック:russian pharmacy online
トラックバック:web design company
トラックバック:الديلزة
トラックバック:gay porn video
トラックバック:Escort Bayan
トラックバック:tamoxifen action
トラックバック:김해출장마사지
トラックバック:diyarbakır Vip escort
トラックバック:veterinarian services near me
トラックバック:الامن السيبراني
トラックバック:escitalopram sexual side effects
トラックバック:vip Escort
トラックバック:Daha Fazla Bilgi
トラックバック:1xbetfreebets
トラックバック:اپلیکیشن بت فوروارد
トラックバック:motop 135
トラックバック:Pills For Enlarging Penis
トラックバック:1xbet bonus promo code bangladesh
トラックバック:indian boobs
トラックバック:walmart online pharmacy
トラックバック:Rafaslot
トラックバック:0 Christmas for Small Animals
トラックバック:zooma казино
トラックバック:зума казино промокод
トラックバック:8 UK Senior Cat Food
トラックバック:анлим казино промокод
トラックバック:flagyl for diverticulitis
トラックバック:read more on Portalcroft
トラックバック:top rummy platforms
トラックバック:list of sweepstakes casinos
トラックバック:Online slots free
トラックバック:Haltrovex Recensione
トラックバック:Eryxavin
トラックバック:gabapentin warnings
トラックバック:0 UK Services
トラックバック:получить банковскую карту
トラックバック:المدني
トラックバック:foro apuestas futbol
トラックバック:product reviews
トラックバック:girl porn video
トラックバック:https://burger-lab-rest.freesite.io/
トラックバック:Avio Karte
トラックバック:الالكترونيك
トラックバック:VitaSeal for blood flow
トラックバック:นวดน้ำมันนอกสถานที่ สุขุมวิท
トラックバック:1 Cat Grooming
トラックバック:제주출장마사지
トラックバック:الطيران
トラックバック:online gaming apps
トラックバック:viagra ecer
トラックバック:Global noodle recipes|https://noodleinsight.com/
トラックバック:raretron
トラックバック:Okrummy India
トラックバック:кухонный гаджет
トラックバック:blood sugar control supplement
トラックバック:Property for sale Dubai
トラックバック:Cialis 20mg
トラックバック:개인돈대출
トラックバック:الاجهزة الطبية
トラックバック:Property for sale Spain
トラックバック:Male Penis Enlarger Pills
トラックバック:Incident Response
トラックバック:الحاسوب
トラックバック:https://pads.jeito.nl/s/BCYaCP8sR
トラックバック:Online Marketing Trainer
トラックバック:подключить уличную камеру к ноутбуку
トラックバック:baliza v16 Ideal para uso diario
トラックバック:lee lo que dijo
トラックバック:Haga clic en este sitio
トラックバック:visitar aquí
トラックバック:evm address generator
トラックバック:phimsexhd.mom
トラックバック:por qué evitar balizas v16 demasiado baratas
トラックバック:publicación reciente del blog Dogetransparency.wiki
トラックバック:slot gratis tanpa deposit
トラックバック:Digital Marketing Guru
トラックバック:simplemente haga clic para obtener la fuente
トラックバック:cuántos metros ilumina una baliza v16 homologada
トラックバック:hibachi cooking show
トラックバック:tron address generator
トラックバック:Going in Google
トラックバック:cóMo registrar una baliza v16 conectada
トラックバック:simplemente haga clic en el siguiente sitio web
トラックバック:cómo utilizar Correctamente la baliza v16
トラックバック:الكهرباء
トラックバック:последней версии huawei смартфон
トラックバック:cómo Funciona la baliza v16 conectada a dgt
トラックバック:baliza v16 para conductores que viajan mucho
トラックバック:gital Marketing Trainer
トラックバック:visita mi pagina web
トラックバック:Curepedia.net
トラックバック:sbfplay99
トラックバック:CircuPulse Product
トラックバック:今日病毒式传播的色情片
トラックバック:Baliza V16 Y Asistencia En Carretera
トラックバック:pil cialis
トラックバック:рейтинг казино на реальные деньги онлайн
トラックバック:por qué comprar baliza v16 antes de que sea obligatoria
トラックバック:Finlyrex
トラックバック:https://Plamosoku.com/enjyo/index.php?title=Simplemente_Haz_Clic_En_La_PróXima_Publicación
トラックバック:contenido
トラックバック:qué color debe tener La luz de baliza v16
トラックバック:Ozarix Trade 50 Review
トラックバック:Professional Massage Charlottenburg
トラックバック:http://102.bosa.Org.ua/
トラックバック:psk live tiktok
トラックバック:เยี่ยมชมเว็บไซต์
トラックバック:Arbinio
トラックバック:часы смартфон самсунг
トラックバック:comment-6831266
トラックバック:123bet official site
トラックバック:nobil fundarex
トラックバック:Apu360
トラックバック:Red Dead Redemption 2 Missions
トラックバック:https://www.mixcloud.com/jiliko1225org/
トラックバック:Amavi88
トラックバック:تبريد وتكييف
トラックバック:best casino fast payout
トラックバック:대환대출
トラックバック:No Sugar syrup For coffee
トラックバック:Bexlorit Review
トラックバック:NEXOPEDIA TOPUP
トラックバック:https://ripple-xrp-global-network.mn.co/posts/95275244
トラックバック:รีวิว ambslot ล่าสุด
トラックバック:ทดลองเล่น suckbet ฟรี
トラックバック:rèm cửa sổ
トラックバック:رياضة
トラックバック:https://reactos.org/forum/memberlist.php?mode=viewprofile&u=176515
トラックバック:suvinsightzone.com
トラックバック:travel phone Cover
トラックバック:Quite impressive
トラックバック:قانون
トラックバック:1 UK Dog Beds
トラックバック:best card gaming apps
トラックバック:Naga77
トラックバック:jual viagra ecer
トラックバック:Scotia Invest
トラックバック:Small Apartment Interior Design Game Furniture|Https://smallspacenest.com/
トラックバック:حوار الاديان
トラックバック:Pulsar Dexlink
トラックバック:Elvaroxis
トラックバック:plastic surgery supplies
トラックバック:GeloGas
トラックバック:Banturix
トラックバック:Montel Syvra
トラックバック:video bokep tanpa sensor
トラックバック:sex bebas
トラックバック:ставки Sultan
トラックバック:https://www.producthunt.com/@jiliko1225org
トラックバック:Apuestas holanda vs argentina
トラックバック:casino-comparateur.fr
トラックバック:https://www.anobii.com/en/01b2e583051e7aa19b/profile/activity
トラックバック:노래방 구인
トラックバック:Bonos Apuestas sin deposito
トラックバック:rummy apps|Okrummy rummy
トラックバック:custom home builders east texas
トラックバック:Fire Watch Security
トラックバック:House Washing
トラックバック:apuestas a la nfl
トラックバック:сайт кракен даркнет
トラックバック:как зайти на кракен даркнет
トラックバック:как зайти на kraken даркнет
トラックバック:кракен darknet market
トラックバック:จ้างทำSEO
トラックバック:Honestly
トラックバック:bangkit4d
トラックバック:oposlot
トラックバック:real rummy cash games
トラックバック:Fire Watch Guards
トラックバック:escort service in Islamabad
トラックバック:Security service
トラックバック:Call Girls Services in Karachi
トラックバック:Swift Profix
トラックバック:download Rummy 91 app
トラックバック:F-01 Fire Watch Guards
トラックバック:đăng nhập 68gamebai
トラックバック:lastenfahrrad
トラックバック:pembesar susu montok
トラックバック:закупка качественных ссылок
トラックバック:Rumbo Fundorix
トラックバック:online casino slots real money
トラックバック:Velocidad Luxten
トラックバック:пылесос робот дрими
トラックバック:JELLO DIET RECIPE
トラックバック:How to Order Mephedrone (4-MMC) Online
トラックバック:Sbobet77
トラックバック:일산출장마사지
トラックバック:SENJATA API
トラックバック:nature hiking game online Guide|https://naturetrailinsight.com/
トラックバック:cheap jordans from china
トラックバック:https://vherso.com/jiliko1225org
トラックバック:k9k9
トラックバック:water damage restoration service
トラックバック:jual viagra murah
トラックバック:mature teen sex pornhub video – adult xxx video hot pornhub site
トラックバック:porno
トラックバック:מאמרים
トラックバック:porn
トラックバック:Dead by Daylight patch notes|https://dbdstation.com/
トラックバック:child trafficking for sex
トラックバック:jihad website
トラックバック:sweeps casinos
トラックバック:Ventario
トラックバック:onepersonals
トラックバック:Sunforge Tradeviax
トラックバック:custom tron vanity address
トラックバック:Orage Invion
トラックバック:789betทางเข้า
トラックバック:www.onlineslotsnew.com
トラックバック:free online slots
トラックバック:rèm gỗ
トラックバック:7 Christmas Gifts for Cats
トラックバック:Endless Winter tips|https://Endlesswinterfans.com/
トラックバック:Fastest Payout Casinos
トラックバック:www.casino-2-fou.com
トラックバック:Mycasino.ch Avis
トラックバック:Homecolorcraft.Com
トラックバック:big bass amazon xtreme
トラックバック:gates of olympus demo
トラックバック:Casino Slots
トラックバック:belize
トラックバック:baanpoolvilla
トラックバック:building architect near me
トラックバック:helpful
トラックバック:Eclipse Nexute
トラックバック:http://www.biblesupport.com/user/793317-jiliko1225org/
トラックバック:Keiki Pulse
トラックバック:how bail bondsman make money
トラックバック:strike 3 bail bonds
トラックバック:How to go to the opening. Ho Chi Minh City opening gift shop
トラックバック:best sweepstakes casino
トラックバック:10 лучших казино онлайн
トラックバック:Eterno Corevia
トラックバック:new sweepstakes casino
トラックバック:online gambling slots
トラックバック:https://gonzalez-mccain-2.hubstack.net
トラックバック:Viva Address:202 w whiting st
トラックバック:прогон хрумером под Гугл
トラックバック:인사이트존
トラックバック:Menu
トラックバック:blooket join
トラックバック:www.mcgift.giftcardmall.com balance
トラックバック:마스터나우
トラックバック:фотопрогулка по городу
トラックバック:Buy Paxil online
トラックバック:Rpido Fincouras
トラックバック:lorazepam pill
トラックバック:pil cialis ori
トラックバック:www.lasallesancristobal.edu.mx
トラックバック:Slott Casino Avis
トラックバック:ghost of tsushima patch Notes|Https://tsushimalegend.com/
トラックバック:Slotgacor
トラックバック:https://pad.stuve.uni-ulm.de
トラックバック:https://cyberpunk2077fans.com/
トラックバック:Crm-X
トラックバック:Código promocional MelBet: ZEVS777 – Bono deportivo de 100 €/$
トラックバック:@jillxo nudes leaked
トラックバック:amouranth of leaks
トラックバック:TOTO88
トラックバック:anitaukslut4u
トラックバック:ссылок наращивание массы
トラックバック:заказать прогон хрумером
トラックバック:https://Wutheringwavesguide.com
トラックバック:Alvesjostogel
トラックバック:Battlefield 2042 DLC|https://Battlefield2042play.Com/
トラックバック:Prozanith
トラックバック:bathroom remodeling near me
トラックバック:roouse live,
トラックバック:razor shark returns slot demo
トラックバック:sinfuldeeds leaks
トラックバック:does OLSP done for you traffic system work
トラックバック:1win aviator
トラックバック:plinko pegs
トラックバック:Hobicode – jasa pembuatan website
トラックバック:fortune tiger bet
トラックバック:хрумер автоматический прогон
トラックバック:vaidebet mobile
トラックバック:qual o melhor horário para jogar fortune tiger hoje
トラックバック:simply syrups Sugar free
トラックバック:www.freeslotsbest.com
トラックバック:como se juega plinko
トラックバック:deposit 5000
トラックバック:plinko free
トラックバック:aviator game online
トラックバック:Casino 2 Fou
トラックバック:betclic ci télécharger
トラックバック:salaheddine kassab
トラックバック:3 Ingredients In The Gelatin Trick
トラックバック:cory chase onlyfans leaks
トラックバック:licking pussy asmr
トラックバック:LONDON ESCORTS
トラックバック:Zenless Zone Zero Walkthrough|Https://Zenlesszerogame.Com/
トラックバック:Moms Teach Sex My Stepsons Beautiful Cock Is Making My Mouth Water S25E5 Koda Monroe
トラックバック:Zenlesszeroguide.com
トラックバック:kraken
トラックバック:o level maths tuition singaopre
トラックバック:tomeofmadness
トラックバック:kza.blob.core.windows.net
トラックバック:jc maths tuition
トラックバック:A Levels Math
トラックバック:https://blogs-singapore.s3.us.cloud-object-storage.appdomain.cloud/math-tuition/4/how-to-create-a-secondary-4-study-timetable-that-works.html
トラックバック:maths tuition for secondary 3
トラックバック:secondary 2 maths exam papers
トラックバック:Singapore A levels Math Tuition
トラックバック:e math tuition
トラックバック:math classes
トラックバック:a-math tuition
トラックバック:jc 1 math tuition
トラックバック:secondary school math tuition
トラックバック:secondary 3 math tuition
トラックバック:secondary Math tuition singapoare
トラックバック:math tutor in singapore
トラックバック:ip maths tuition singapore
トラックバック:Thanks a lot
トラックバック:best maths tuition
トラックバック:pop por aquí
トラックバック:porn kids
トラックバック:ip math tuition singapore
トラックバック:Baliza v16 homologada qué significa
トラックバック:wikithai
トラックバック:casino app spinmama
トラックバック:ying mi
トラックバック:how does bail bond business work
トラックバック:a maths tuition singapore
トラックバック:frohe Ostern Bilder
トラックバック:usc sports memorabilia
トラックバック:free maths exam papers singapore
トラックバック:psle math tutor singapore
トラックバック:secondary math tutor
トラックバック:https://singapore-sites.sos-ch-dk-2.exo.io/maths-tuition/1/key-metrics-for-assessing-tuition-success.html
トラックバック:sports injury updates|https://Sportsinjuryfocus.com/
トラックバック:free sec 2 exam papers
トラックバック:kids porn
トラックバック:maths tuition jc
トラックバック:secondary math tuition environment
トラックバック:best jc math tuition
トラックバック:secondary 3 school exam papers
トラックバック:sec 1 math algebra questions
トラックバック:bokep korean sex
トラックバック:Уничтожение и защита от Летучих
トラックバック:math
トラックバック:singaporeboleh.neocities.org
トラックバック:sell viagra original
トラックバック:tuition center singapore
トラックバック:jc math tuition
トラックバック:online classes math tuition singapore
トラックバック:okx buy bitcoin eth crypto
トラックバック:p4 math tuition singapore
トラックバック:대구출장마사지
トラックバック:A levels math tuition
トラックバック:singapore math
トラックバック:maths tuition for sec 1
トラックバック:hui ma
トラックバック:primary 5 maths tuition programme
トラックバック:Aureus Valtrix
トラックバック:ngentot dengan anak babi
トラックバック:Eryxavin Avis
トラックバック:Prcieux Lumerion
トラックバック:บริการ seo
トラックバック:Strategy game Weapons|https://strategyreviewer.com/
トラックバック:Prcieux Lumerion Avis
トラックバック:Goldpeak Portdex
トラックバック:real money slots
トラックバック:Aczone System 30
トラックバック:Action Games collectibles|https://actionmixhub.com/
トラックバック:math tuition jc
トラックバック:nude kid online
トラックバック:sell viagra online
トラックバック:ok8386 casino online
トラックバック:is plinko real
トラックバック:best medicine for nerve pain in hand
トラックバック:gta 5 weapons|Https://gta5play.Com/
トラックバック:Crypto Games IO Casino
トラックバック:free child porn video
トラックバック:Velora Nexen
トラックバック:spin mama opinie
トラックバック:digicattech
トラックバック:home addition contractors
トラックバック:https://beebe-larsson-3.hubstack.net/les-mysteres-de-casino-roman-critique-ce-que-vous-vous-devez-connaitre
トラックバック:Orage Invion Avis
トラックバック:Stokesdale Auto Glass
トラックバック:Blindsurprise.com site
トラックバック:แทงบอล
トラックバック:valium meds
トラックバック:разработка компьютерных игр
トラックバック:sec 1 math paper pdf
トラックバック:erc20 address generator
トラックバック:toto 4d
トラックバック:slot toto
トラックバック:Warframe relics|https://warframeforce.com/
トラックバック:glass and mirror
トラックバック:bugil
トラックバック:Cextronax
トラックバック:izmir masaüstü bilgisayar alan yerler
トラックバック:math tuition evaluation
トラックバック:Cextronax Erfahrungen
トラックバック:custom necklace
トラックバック:jc Tuition
トラックバック:Stormridge Dexmint Avis
トラックバック:Bestand Luxeron
トラックバック:jc maths tuition singapore
トラックバック:www.xiuwushidai.com
トラックバック:fortune tiger demo
トラックバック:themerrygrow
トラックバック:https://42c5Ckgac8h.site
トラックバック:Vertice Finthor Recensione
トラックバック:matthew nicosia t7x
トラックバック:Apoge Dexlink
トラックバック:http://somesolutions.online
トラックバック:Toko Safety Terdekat
トラックバック:Frame Avapro 2U
トラックバック:walmart gift card buy
トラックバック:MALWARE
トラックバック:usa sweepstakes casino
トラックバック:secondary math tutor singapore
トラックバック:bet on red opinie
トラックバック:is bitcoin an actual physical thing
トラックバック:Pagvora AI
トラックバック:Luxeron Avis
トラックバック:Stature Invexor
トラックバック:u31 เข้าสู่ระบบ
トラックバック:singapore math tuition center
トラックバック:AI writing software
トラックバック:click now
トラックバック:Valdorexa avis
トラックバック:secondary 2 maths test papers
トラックバック:plateforme de jeux d’argent
トラックバック:xn88.blue
トラックバック:fortune tiger bet365
トラックバック:Bearxvideo
トラックバック:fishin frenzy even bigger fish
トラックバック:Código promocional de bono de MelBet hoy: ZEVS777
トラックバック:2_Blank\” hrefmailto
トラックバック:tron vanity address generator
トラックバック:s3.amazonaws.com
トラックバック:Https://wegame.one
トラックバック:Verde Casino oficial
トラックバック:car decals
トラックバック:plinko 디시
トラックバック:سماعات أذن 1more للنوم Z30
トラックバック:plinko casino game
トラックバック:math tuition 1 to 1
トラックバック:bokep videos
トラックバック:Chat-X
トラックバック:Bayboro auto glass
トラックバック:plinko australia
トラックバック:Profitia Nexus
トラックバック:enjoy reading this
トラックバック:Swiftbit Invexor
トラックバック:www.giftcardmall.com/mygift
トラックバック:parents looking for tutors in singapore
トラックバック:Phim người lớn
トラックバック:Best real money online casinos usa
トラックバック:quality replica purses
トラックバック:Power Trades App Avis
トラックバック:secondary school maths tuition
トラックバック:Finvontex Review
トラックバック:maths classes in singapore
トラックバック:math questions for sec 1
トラックバック:Xybero Renda Avis
トラックバック:mathematics
トラックバック:Redmitoto
トラックバック:crack download
トラックバック:viagra capsule
トラックバック:Okrummy platform
トラックバック:http://rosseia.flybb.ru/viewtopic.php?f=2&t=1062
トラックバック:Lev Invexor Avis
トラックバック:jogo do tigrinho fortune tiger
トラックバック:Stevig Valtrion Ervaringen
トラックバック:spinmama czech
トラックバック:jc math tuition singapore
トラックバック:good secondary maths tutor singapore
トラックバック:maths tuition singapore
トラックバック:singapore math online tutoring
トラックバック:honkai star rail events|Https://starrailmix.com/
トラックバック:bookof ra
トラックバック:Código promocional de bono de MelBet hoy: ZEVS777
トラックバック:Research drugs
トラックバック:best math tutor singapore
トラックバック:Switchmixzone`s latest blog post
トラックバック:A Math Tuition
トラックバック:https://mm88.press/
トラックバック:slot gampang menang
トラックバック:gamegeek
トラックバック:https://xx88tv.com/
トラックバック:free nude kids
トラックバック:Puret Invyra
トラックバック:up satta king
トラックバック:Immutable Azopt Recensione
トラックバック:https://sunwint3.red
トラックバック:Monvaul Avis
トラックバック:Noble Fluxor Avis
トラックバック:مهاجرت به کانادا
トラックバック:Stevig Valtrion
トラックバック:Kaskustoto
トラックバック:play jonny
トラックバック:sarcastic travel mugs
トラックバック:bonus spinmama
トラックバック:pesat777
トラックバック:mines demo grátis
トラックバック:مهاجرت به کانادا
トラックバック:pool abdeckplanen online bestellen
トラックバック:Gagnor Gpt Erfahrungen
トラックバック:cuwip.ucsd.edu post to a company blog
トラックバック:login Judi jun88
トラックバック:register jun88
トラックバック:rolldorado online
トラックバック:Pletal Bextra Avis
トラックバック:Axynor Quantel Avis
トラックバック:Prisma Luxerise Recensione
トラックバック:Finaryivapro Erfahrungen
トラックバック:www.vapeenligne.fr
トラックバック:zigarettekaufen
トラックバック:liquidsezigaretten
トラックバック:エロ い ドレス
トラックバック:fortune tiger 777
トラックバック:wact jav online
トラックバック:maxone
トラックバック:make bomb video
トラックバック:big dick slut
トラックバック:fortune tiger demo grátis dinheiro infinito
トラックバック:Valorant settings|https://valorantcentralhub.com/
トラックバック:Black Mountain auto glass
トラックバック:Best real money online casinos
トラックバック:tome of madness max win
トラックバック:application plinko avis
トラックバック:plinko game download play store
トラックバック:Eixo Inviolex
トラックバック:Buy Fioricet Online
トラックバック:手マン
トラックバック:https://www.migrationgovernance.org/contact-us/
トラックバック:plinko online
トラックバック:latest past papers
トラックバック:mouse click on bbs.sjzl19.com
トラックバック:meditation and mindfulness
トラックバック:dieta herbalife Para Bajar 5 kilos
トラックバック:vapealso
トラックバック:plinko seriös
トラックバック:Apex Legends skins|https://apexarenaelite.com/
トラックバック:Cloris Luxeris
トラックバック:Undertale boss guide|https://undertalezone.com/
トラックバック:Sommet Fintrix
トラックバック:order valium online
トラックバック:Spot 700 Fanda Avis
トラックバック:Investpro Ai Avis
トラックバック:Bitnex Crestfort Avis
トラックバック:Hermes boomerang sneaker clearance
トラックバック:https://petrointelligence.com/manual/registro/
トラックバック:Código de bienvenida de MelBet 2026
トラックバック:cialis murah
トラックバック:Fortnite tips|https://fortnitemix.com/
トラックバック:beyaz eşya servisi
トラックバック:888vi com
トラックバック:mcgift.giftcardmall
トラックバック:travel clothes for women
トラックバック:retail media agency
トラックバック:RR99
トラックバック:Strovemont Capital
トラックバック:bokep mahasiswa bugil
トラックバック:order Dextroamphetamine pills online in bulk
トラックバック:Drezdalorni
トラックバック:https://www.pakua.com/school/canela-centro/
トラックバック:Finaryivapro
トラックバック:best payout casino
トラックバック:Far Cry 6 patch notes|https://Farcry6zone.com/
トラックバック:Amalivo
トラックバック:วีซ่าไทยสำหรับชาวต่างชาติ
トラックバック:aceh4d
トラックバック:red dead redemption 2 hunting guide|https://reddeadstation.com/
トラックバック:https://nationalacsolutions.com
トラックバック:aplikace plinko recenze
トラックバック:info
トラックバック:make nuke bomb
トラックバック:คลิปหลุดเกย์
トラックバック:wzgroupup.hkhz76.badudns.cc website
トラックバック:Keluaran Togel Hari Ini
トラックバック:league of legends Meta
トラックバック:Firstup
トラックバック:https://seoblog360.ru/
トラックバック:masterpoker88
トラックバック:плинко казино
トラックバック:Código promocional MelBet 2026 : ZEVS777 – Bonificación de inscripción del 100 %
トラックバック:reported
トラックバック:Corporate Office Furniture
トラックバック:casino cat
トラックバック:spin mama app
トラックバック:lk21 terbaru
トラックバック:1xbet aviator app
トラックバック:plinko jogo
トラックバック:roboquest гаджеты
トラックバック:is jackpot raider legit
トラックバック:Роллы Челябинск
トラックバック:drip casino отзывы
トラックバック:Travel agent near me
トラックバック:bali777
トラックバック:spin mama bonus code
トラックバック:Casino2Fou
トラックバック:BOARD-BOOK
トラックバック:portail Casino 2 Fou
トラックバック:play jonny casino
トラックバック:Aulander auto glass
トラックバック:https://www.renderosity.com/users/id:1813609
トラックバック:https://graph.org/Casino-Mr-Sloty–Est-ce-vraiment-la-meilleure-option-12-15
トラックバック:REVIEWTALK
トラックバック:정품 시알리스
トラックバック:Exotic Mozambique putas Maputo
トラックバック:Viggoslots casino avis
トラックバック:e2betkai.com
トラックバック:Travel agents in Casper
トラックバック:네이버 아이디 구매
トラックバック:hot hot fruit demo in rands
トラックバック:Countertops
トラックバック:Forged fittings supplier
トラックバック:스포츠 무료중계
トラックバック:네이버 아이디 판매
トラックバック:Travel agents USA
トラックバック:Latest News World
トラックバック:melimtx official website
トラックバック:scam money bitcoin
トラックバック:Today international news
トラックバック:xem truyện người lớn không che
トラックバック:해외축구 중계
トラックバック:Treviloxanopro Recensione
トラックバック:Finexford
トラックバック:Bextra Baralis
トラックバック:food fort lauderdale
トラックバック:Kernvexo Erfahrungen
トラックバック:real couple secret
トラックバック:Goldspire Nexor Review
トラックバック:96-дюймовые спортивные
トラックバック:롤 중계
トラックバック:Reolixio Recensione
トラックバック:livebetpro.net
トラックバック:tome of madness
トラックバック:Personal Injury Lawyers USA
トラックバック:Travel agency near me
トラックバック:Scarface Trades Discord
トラックバック:เรียนทำกาแฟไปออสเตรเลีย
トラックバック:pepek
トラックバック:scam crypto exchange
トラックバック:singapore food
トラックバック:Gamdom Casino Avis
トラックバック:лучшие стилусы
トラックバック:BOKEP KOREA
トラックバック:รับทำวุฒิการศึกษา
トラックバック:강남출장마사지
トラックバック:Grandspire Talyx
トラックバック:Royalforge Lorix
トラックバック:material
トラックバック:casimon login
トラックバック:bokep anak sma
トラックバック:안동출장마사지
トラックバック:SEX WEBSITE
トラックバック:Download Software For PC
トラックバック:rolldorado casino
トラックバック:카드깡
トラックバック:alprazolam online
トラックバック:quality safety
トラックバック:Książor Calyron
トラックバック:best payout online casino
トラックバック:SUNWIN CLUB
トラックバック:서울출장마사지
トラックバック:trc20 token generator
トラックバック:brand new porn site sex
トラックバック:Accountants Near Me Casper
トラックバック:Reolixio Avis
トラックバック:apuestas deportivas murcia
トラックバック:traditional egyptian food
トラックバック:the-ultimate-ai-toolkit
トラックバック:http://Tmoch.net/jupgrade/index.php/e-Czytelnia/705-sw-tomasz-z-villanova-oesa-abp.Html
トラックバック:クンニリングス
トラックバック:cocaine sydney
トラックバック:Victor armando canavati sarquis
トラックバック:cheap Motorbike insurance uk
トラックバック:Cakra Corevia
トラックバック:Horyn Corevia
トラックバック:InvestHub 3.0
トラックバック:Kusex bình luận phim jav
トラックバック:https://758475.8b.io/
トラックバック:Xuvantrapex
トラックバック:Hautier Calyron
トラックバック:Escorts in Ramada Hotel Karachi
トラックバック:Insurance Agency Casper Cheyenne USA
トラックバック:ขายยาทำแท้ง
トラックバック:BUY FENTANYL WITHOUT PRESCRIPTION
トラックバック:Clarte Valyrix Avis
トラックバック:classic motorcycle Breakdown cover
トラックバック:Difice Portfin
トラックバック:Fuerza Dalvex
トラックバック:エステサロン クリニック 美容皮膚科 美容室 美容院 ネイルサロン 病院 整骨院 接骨院 メンズサロン
トラックバック:big penis pill
トラックバック:cờ bạc
トラックバック:nude kids photo
トラックバック:Regards
トラックバック:personal attorneys
トラックバック:eurocopa ganador apuestas
トラックバック:fishing frenzy free play
トラックバック:네이버 계정 구매
トラックバック:Tramadol 50mg
トラックバック:Geschenkbox
トラックバック:خرید مواد شیمیایی شیمیکو
トラックバック:Brown Cocaine in tasmania
トラックバック:официальный сайт kra
トラックバック:Slot games real money online
トラックバック:Auto Accessories For Sale
トラックバック:крипто босс казино промокод
トラックバック:saber mas
トラックバック:Rasasi perfume
トラックバック:Clonazepam 1mg
トラックバック:S666
トラックバック:https://zanderqesf10087.blogadvize.com/47698112/—-
トラックバック:33WIN
トラックバック:event spaces nearby
トラックバック:yourskin33
トラックバック:casas Asiaticas apuestas
トラックバック:Avelixio Opinioni
トラックバック:Battlefield 2042 missions|https://battlefield2042hq.com/
トラックバック:https://vocus.cc/user/@fun88thnet
トラックバック:Food Singapore Singapore Food Singapore restaurant Restaurant F&B F&B Singapore
トラックバック:coody octopus rbm inflatable tent
トラックバック:çağ medya
トラックバック:https://tmbq.sa.com
トラックバック:https://jakzrh.za.com/
トラックバック:how much is cocaine
トラックバック:enlargemen penis tools
トラックバック:making antrax virus
トラックバック:세종출장마사지
トラックバック:수원출장마사지
トラックバック:why life feels harder than it should
トラックバック:http://pandora.Nla.Gov.au/
トラックバック:안산출장마사지
トラックバック:how to bounce back after setbacks
トラックバック:오산출장마사지
トラックバック:Starfield strategy|Https://Starfieldgalaxy.com/
トラックバック:vpbet
トラックバック:big dick pill
トラックバック:상세페이지 디자인
トラックバック:decision paralysis in high achievers
トラックバック:identity after career collapse
トラックバック:buy coca paste australia
トラックバック:시흥출장마사지
トラックバック:roofing contractors
トラックバック:평택출장마사지
トラックバック:sex kids online
トラックバック:Genshin Impact Domains
トラックバック:child rape
トラックバック:Viagra 100mg
トラックバック:branding services nairobi
トラックバック:¿Por qué todos hablan de landing pages y cómo puedes crear la tuya para aumentar tus conversiones? – EDSW
トラックバック:plinko gratuit
トラックバック:printing services nairobi
トラックバック:cmr shell bokep anak kecil
トラックバック:situs bokep indo pemerintahan palopo
トラックバック:bokep orang utan
トラックバック:https://Xn–12C2Cyah7Bwbt8Izb.Gay
トラックバック:monster hunter Wilds story guide|https://monsterwildlands.com/
トラックバック:nzemaassociation.com
トラックバック:tome of madness 2 demo
トラックバック:군포출장마사지
トラックバック:adult
トラックバック:human trafficking bust atlanta
トラックバック:plinko game review
トラックバック:구리출장마사지
トラックバック:detayları gör
トラックバック:김포출장마사지
トラックバック:성남출장마사지
トラックバック:jackpot raider login
トラックバック:https://fwegb.gov.pk/deosai-national-park/
トラックバック:painters services near me
トラックバック:Autoplay vip
トラックバック:versandlabel
トラックバック:carrageenan supplier
トラックバック:Get drivers license online
トラックバック:make big bomb
トラックバック:buy crystal meth online
トラックバック:battery shop near me
トラックバック:kms auto windows 11
トラックバック:daha fazlasını öğren
トラックバック:https://alaniqah.com/BpBpvNz
トラックバック:hackmd.okfn.de
トラックバック:pool abdeckplane shop
トラックバック:genel rehber
トラックバック:apollo789
トラックバック:Cardio Genix
トラックバック:이천출장마사지
トラックバック:rape sex child
トラックバック:Kachabali
トラックバック:3 mg xanax
トラックバック:rehber sitesi
トラックバック:아산출장마사지
トラックバック:동탄출장마사지
トラックバック:wireless earbuds translation
トラックバック:https://tmxjmg.sa.com
トラックバック:파워맨 비아그라
トラックバック:aviator predictor hack download
トラックバック:Lifetime Webhosting
トラックバック:연천출장마사지
トラックバック:obor138
トラックバック:https://kubet.red
トラックバック:Windows gaming setup|https://windowsmastery.com/
トラックバック:Overwatch 2 achievements|https://overwatch2fans.com/
トラックバック:здорового питания грядка
トラックバック:rape child
トラックバック:comment-54733
トラックバック:kid sex dolls
トラックバック:Red Dead Redemption 2 story guide|https://reddeadwildland.com/
トラックバック:arch2o
トラックバック:tusbol
トラックバック:충주출장마사지
トラックバック:청주출장마사지
トラックバック:комната приема пищи температура
トラックバック:trusted rummy apps
トラックバック:Reolixio
トラックバック:파워맨 사이트
トラックバック:business services
トラックバック:Cleoris Luxeris Review
トラックバック:비아그랄 구매 사이트
トラックバック:Trasvilox
トラックバック:Trasvilox Recensione
トラックバック:Okrummy rummy platform
トラックバック:vaidebet login
トラックバック:About Zapote Bridge History
トラックバック:demo mines game
トラックバック:gellan gum
トラックバック:pearlsvibe strapless dildo jane
トラックバック:zupacescu01
トラックバック:child sex site
トラックバック:가평출장마사지
トラックバック:apuestas seguras para Hoy
トラックバック:dezalcoolizare
トラックバック:bokep cewek cina
トラックバック:nude child web
トラックバック:스포츠중계블랙티비2
トラックバック:вес волос на голове
トラックバック:plinko unblocked
トラックバック:cialis murah online
トラックバック:рак легких какая химиотерапия
トラックバック:구글찌라시
トラックバック:Bexlorit Opiniones
トラックバック:discover this info here
トラックバック:Cleste Finluxor Avis
トラックバック:Ascendant Fynvora
トラックバック:sex dangerous
トラックバック:www.vapemouse.com
トラックバック:Genshin Impact Builds|Https://Genshinplayground.Com/
トラックバック:Luxury travel game money Guide|https://luxurytravelfocus.Com/
トラックバック:Okrummy online rummy
トラックバック:익산출장마사지
トラックバック:dollar
トラックバック:Www.Arcadearredamenti.It
トラックバック:multiplayer rummy
トラックバック:Gambit999
トラックバック:sc88
トラックバック:online gambling real money
トラックバック:BLACK HAT SEO MASS BACKLINKS
トラックバック:원주출장마사지
トラックバック:태백출장마사지
トラックバック:Código promocional sin depósito de MelBet: ZEVS777 – Bono deportivo de 100 €/100 $
トラックバック:춘천출장마사지
トラックバック:양양출장마사지
トラックバック:남원출장마사지
トラックバック:논산출장마사지
トラックバック:bloating
トラックバック:anti aging
トラックバック:Gasing77
トラックバック:Greenwox Funnel Review
トラックバック:Fund Portyra Review
トラックバック:Instant 93 Cryppro Review
トラックバック:Soberano Inviora
トラックバック:Stonevale Corix Review
トラックバック:game tips|https://movietriviafocus.com/
トラックバック:cheap flights for gamers|https://budgettravelinsight.com/
トラックバック:https://homes-for-homeless-children.mn.co/posts/95325930
トラックバック:nba money Guide|https://nbaactioninsight.com/
トラックバック:citrus burn official website
トラックバック:liver detox
トラックバック:bad breath
トラックバック:revitalize
トラックバック:센트립 구매
トラックバック:Pgsloth
トラックバック:KONCO88
トラックバック:Venthyra Singulus
トラックバック:UK Litter Lavender to all cat
トラックバック:Venturgate
トラックバック:Fly88
トラックバック:slot book of ra
トラックバック:citrusburn
トラックバック:madcasino en ligne fiable
トラックバック:ashwagandha
トラックバック:pinterest.com
トラックバック:superhero fantasy
トラックバック:solar power water heater Malaysia
トラックバック:steal user information hack
トラックバック:crypto poker casinos
トラックバック:menú semanal con productos Herbalife
トラックバック:https://palm.Muk.uni-hannover.de/trac/search?q=https://Firstup.In.Th
トラックバック:gamestation
トラックバック:thrillangora01.bravejournal.net
トラックバック:форма фитнес бикини
トラックバック:making antrax
トラックバック:fake notes
トラックバック:Axelvexia Recensione
トラックバック:trc20 scan
トラックバック:panecof.com
トラックバック:https://v.gd/I3Ribf
トラックバック:custom tron vanity token
トラックバック:Okrummy app download
トラックバック:Koplo77
トラックバック:lover boy method of human trafficking
トラックバック:Intellneurapp
トラックバック:online plinko
トラックバック:vai de bet bônus
トラックバック:BLACK HAT SEO MASS BACKLINKS BOOST RANKING
トラックバック:drgn
トラックバック:best fluoxetine for children
トラックバック:папа что будет если бросить сцепление
トラックバック:slot 88
トラックバック:free child sex videos
トラックバック:huima
トラックバック:buy sertraline near me
トラックバック:dragon tiger real cash game
トラックバック:Totobet login
トラックバック:Burn Peak reviews
トラックバック:best crypto gambling sites
トラックバック:seller sex doll online
トラックバック:sportsnews9.com
トラックバック:Kryoneth Astra
トラックバック:rèm vải
トラックバック:Código promocional gratuito de MelBet 2026: ZEVS777 – Apuesta gratis de 100 €
トラックバック:big penis pills
トラックバック:https://hedge.fachschaft.informatik.uni-kl.de/s/tC668Zd2a
トラックバック:post2989532
トラックバック:Sarvexid Recensione
トラックバック:https://cuwip.ucsd.edu/
トラックバック:WPS Office中文版
トラックバック:Battlefield 2042 specialists|https://Battlefield2042guide.Com/
トラックバック:Stray Missions|Https://Straycatgame.Com/
トラックバック:WPS Office 在线下载
トラックバック:Switch Chenix Fin Avis
トラックバック:ARASLOT
トラックバック:V-Guide
トラックバック:Best Tasting Decaffeinated Coffee
トラックバック:nude child picture
トラックバック:ee88
トラックバック:구미출장마사지
トラックバック:vibely mascara reviews
トラックバック:영주남출장마사지
トラックバック:밀양출장마사지
トラックバック:경주출장마사지
トラックバック:wettquoten Erklärt
トラックバック:stake mines hack
トラックバック:영천출장마사지
トラックバック:אתר מאמרים
トラックバック:78win
トラックバック:persy snowcaps
トラックバック:visit illegal porn video
トラックバック:789BET
トラックバック:basketball Wetten Overtime
トラックバック:lab grown diamonds vancouver
トラックバック:e roller mönchengladbach e roller reparatur e roller reparieren e roller reperatur e roller werkstatt e roller werkstatt in der nähe
トラックバック:bokep cewek sma
トラックバック:http://www.agrisviluppoaz.it
トラックバック:bl555
トラックバック:beste wettseiten öSterreich
トラックバック:BUY RITALIN ONLINE
トラックバック:Online Oxycodone Seller
トラックバック:BUY VARDENAFIL ONLINE
トラックバック:TRANSEXUAL PORN SEX VIDEOS
トラックバック:lesbian porn videos
トラックバック:WPS官方正版
トラックバック:dragon tiger apk
トラックバック:ufabet888
トラックバック:亚洲肛交色情片段
トラックバック:БЕСПЛАТНОЕ РУССКОЕ ПОРНО
トラックバック:Aktien kaufen und verkaufen
トラックバック:ebony porn
トラックバック:tron vanity address
トラックバック:พูล วิลล่า บาง แสน 20 คน
トラックバック:女同性恋色情影片
トラックバック:rummy earning apps
トラックバック:Cookinghub
トラックバック:engagement rings vancouver
トラックバック:Купить фентанил без рецепта
トラックバック:indian sex film
トラックバック:rape videos
トラックバック:casca de copiat
トラックバック:sites list
トラックバック:https://www.printables.com/@fun88thnet_4226813
トラックバック:Buy Rivotril
トラックバック:BEST ANAL PORN SITE
トラックバック:1euro.bet bonus
トラックバック:СКАЧАТЬ ЛУЧШИЕ ПОРНО ВИДЕО
トラックバック:reasonably well
トラックバック:Nicely done
トラックバック:BUY PENIS ENLARGEMENT PILLS
トラックバック:ออกแต่ลม.Com
トラックバック:ANAL SEX PORN
トラックバック:문경출장마사지
トラックバック:buy Adderall online without prescrition
トラックバック:เปิดยูสหวย
トラックバック:sex video online
トラックバック:jihad bomb
トラックバック:88ID Login
トラックバック:cheap usa degree
トラックバック:porn child sex
トラックバック:mmoo nhà cái
トラックバック:LESBIAN PORN SEX VIDEOS
トラックバック:laoswin66
トラックバック:kk55
トラックバック:RPG game skills|https://Rpggamecentral.com/
トラックバック:全新色情网站性爱
トラックバック:visit www.bandlab.com
トラックバック:wps office官网
トラックバック:Green Xanax Bar
トラックバック:free russian porn
トラックバック:Marine Traffic Schiffsradar Schiffsradar 24 Ship Radar Ship Radar24
トラックバック:https://www.doccen.vn/home/08de4f39-9ad6-9718-a253-22e401000000
トラックバック:Best Vapor
トラックバック:Vape Mod Device
トラックバック:Travel Agencies Dubai From India
トラックバック:bet285
トラックバック:ramenbet
トラックバック:http://www.drugoffice.gov.hk/gb/unigb/www.motorhype.co.uk/car-insurance/
トラックバック:lovable security scanner
トラックバック:f
トラックバック:Mpo505
トラックバック:signal电脑版
トラックバック:3Astyle.kz
トラックバック:Vesselfinder Vessel Finder
トラックバック:https://julian-gross.De
トラックバック:jogo do tigrinho que ganha dinheiro
トラックバック:sbfplay99 official
トラックバック:vibe coding checklist
トラックバック:ai coding security
トラックバック:ai coding pentest
トラックバック:material
トラックバック:nude white girls
トラックバック:gold bar price in Malaysia
トラックバック:glo
トラックバック: Formalwear UK
トラックバック:standards
トラックバック:medications for cancer patient recovery
トラックバック:cần sa
トラックバック:hack
トラックバック:short link
トラックバック:Costs insurance
トラックバック:https://judahmznz98754.blogvivi.com/40222606/—-
トラックバック:dubai city tour deals
トラックバック:petir138
トラックバック:Fantasyworld
トラックバック:gelatin trick weight loss
トラックバック:Bathroom Plumbing Duxford
トラックバック:gelatin trick recipe
トラックバック:tunz tube
トラックバック:private ragnarok servers 2026
トラックバック:scam dangerous
トラックバック:ragnarok online private server deutsch
トラックバック:Ship Tracker Ship Tracking Ship Traffic
トラックバック:シミーズ
トラックバック:10Bet Casino
トラックバック:plinko balls xy
トラックバック:assignment writers near me
トラックバック:herbal sex online
トラックバック:Deposit Qris
トラックバック:assignment writers sri lanka
トラックバック:* Chase Travel urgent support
トラックバック:TK88.tube
トラックバック:jackpotraider casino
トラックバック:ARASLOT THAILAND
トラックバック:Costco Travel beach resorts
トラックバック:source page
トラックバック:Bedrock Restoration – Water Fire Mold Damage Service
トラックバック:전자담배 기기
トラックバック:Negão pau grande
トラックバック:https://fairygodboss.com/users/profile/92YI7oPtI/cygder
トラックバック:written by Mrcollegedhorimanna
トラックバック:hi88 hi88
トラックバック:download windows server 2022 full crack
トラックバック:Block Chain Pulse
トラックバック:3GPP2 file type
トラックバック:Essor Invexaro
トラックバック:wie funktionieren Live wetten
トラックバック:Kratosai
トラックバック:Evoverdex
トラックバック:buy stripchat.com video record
トラックバック:kontol gede
トラックバック:카지노사이트
トラックバック:Blockchain Nexus
トラックバック:Noble Coreviax Avis
トラックバック:Cumbre Valtaris Opiniones
トラックバック:download windows 12 64bits crack
トラックバック:Macau88
トラックバック:slot qq online
トラックバック:Ruxavild Opiniones
トラックバック:fiction history
トラックバック:https://hub.docker.com/u/helpdogcom
トラックバック:www.carbonenissanyorkville.com
トラックバック:Torena Bash
トラックバック:http://114.115.236.26:8301/susannamceache/9061113/-/issues/1
トラックバック:Ruxavild
トラックバック:Fidle Fintrion
トラックバック:Argento Luxeron Recensione
トラックバック:Prysm Fyntrion
トラックバック:Artinexa Ervaringen
トラックバック:plinko cz recenze
トラックバック:stake
トラックバック:bomb for jihad
トラックバック:p11700
トラックバック:p2p lending
トラックバック:https://forum.codeigniter.com/member.php?action=profile&uid=217139
トラックバック:racingclub
トラックバック:센트립 효과
トラックバック:เว็บเกมดังที่สุด 2026
トラックバック:https://www.plurk.com/p/3i87ytu9f9
トラックバック:ตามเข้ามาอ่าน
トラックバック:เว็บเกมแตกแจกหนัก
トラックバック:information source
トラックバック:Vela24
トラックバック:リアル ラブドール
トラックバック:ai nika
トラックバック:nika
トラックバック:F168
トラックバック:Tramadol 100mg
トラックバック:Neronix Hivo Max Recensione
トラックバック:Leminovexis
トラックバック:Cardine Modevo Recensione
トラックバック:porn live streaming
トラックバック:Corthiq Ember Ai
トラックバック:Zyren Mint Erfahrungen
トラックバック:Orenthis Edge
トラックバック:789Win Nổ hũ
トラックバック:68win link mới nhất
トラックバック:Chiaro Invexus
トラックバック:Cryplex Canorin Review
トラックバック:https://pinshape.com/users/8887281-helpdogcom
トラックバック:Thaloryx Continuum Review
トラックバック:video cewek bugil
トラックバック:Difice Portfin Avis
トラックバック:Real Estate Agents Bozeman Mt
トラックバック:http://valleysolutionsinc.com/Web_Design/Portfolio/ViewImage.asp?ImgSrc=ExpressAuto-Large.jpg&Title=ExpressAutoTransport&URL=theneverendingstory.netforumsuserslillianlacroix2
トラックバック:corshells.com
トラックバック:where can i gamble at 18 Years old
トラックバック:Jnt77
トラックバック:Gopay303 slot
トラックバック:Free ai background remover no signup
トラックバック:victor89
トラックバック:vaporover
トラックバック:8 UK 2026 Save 30% on selected Pets at Home Teddy Dog Beds
トラックバック:vsbetvs.in.net lừa đảo công an việt nam cảnh báo truy quét cấm gấp
トラックバック:staking dApp Polygon
トラックバック:5 UK keep your cat active
トラックバック:Polygon bridge withdrawal
トラックバック:Party2Nite
トラックバック:UK Save on selected Dog Snacks
トラックバック:5 Premium Adult Wet Dog Food
トラックバック:The End of Custom ROMs What Killed Them and Why No One Noticed
トラックバック:Call to Action Now
トラックバック:Trusted Crypto Account
トラックバック:payday loan
トラックバック:playjonny online casino
トラックバック:Https://Toolbarqueries.Google.Com.Sb
トラックバック:Avalon Fincar Avis
トラックバック:Ancrage Finvexa Avis
トラックバック:Mexaro Dulin
トラックバック:Buy Fake Driver’s License
トラックバック:Vélantis Pro 7 2
トラックバック:Kambitnex Avis
トラックバック:QleveraPro
トラックバック:Vantaxio
トラックバック:Leminovexis Avis
トラックバック:Profitex Finverio
トラックバック:Virex Dalo Avis
トラックバック:annual turnover
トラックバック:suhu69
トラックバック:Buy Hydrocodone Online
トラックバック:sex analysis test
トラックバック:https://onlinecasinosymphony.com/blog/
トラックバック:obat kuat pria herbal
トラックバック:plenty of insightful
トラックバック:Capo Vaultaris
トラックバック:plinko app seriös
トラックバック:Vantaxio Recensione
トラックバック:http://winxp.manhattansoftware.com/
トラックバック:Kambitnex Recensione
トラックバック:trx address generator
トラックバック:escort
トラックバック:vet services
トラックバック:crypto vanity address
トラックバック:LexoFinPro
トラックバック:Gxmble Casino Avis
トラックバック:Промокод 1win eSports: 1W2026FREE → +500% Бонус
トラックバック:eleizasestaon.org`s blog
トラックバック:TELEGRAM @SEO LINKK GOOGLE SEO FAST RANKING
トラックバック:linkbuilding
トラックバック:DADDY PEDOFILIA
トラックバック:blackhat ceo
トラックバック:parions sport recommandé
トラックバック:Zolpidem 5mg
トラックバック:crypto casino no deposit bonus
トラックバック:jihad war site
トラックバック:123LUCABET
トラックバック:cuentas netflix
トラックバック:vimax penis pill
トラックバック:join jihad bomb
トラックバック:diyarbakır elit Eskort
トラックバック:https://potofu.me/cygder
トラックバック:European Online Casinos
トラックバック:https://mhmoments.com
トラックバック:Okking bet
トラックバック:diyarbakırofisescortlari.com bilgi Al
トラックバック:https://florafiore.ru/real-touch-cvety_bijsk
トラックバック:luxurystyletrends.com
トラックバック:Gambling and behavioral economics
トラックバック:big natural boobs
トラックバック:Le Corbusier Villa Savoye
トラックバック:rape child sex
トラックバック:online platform
トラックバック:betclic connexion
トラックバック:hothotfruit
トラックバック:Pedofilia Sex
トラックバック:diyarbakır lüks escort
トラックバック:laptop posture pain
トラックバック:big penis capsulle
トラックバック:Mejor código promocional de MelBet: ZEVS777 – Bono de $130
トラックバック:Ucuz DiyarbakıR Escort
トラックバック:moon789
トラックバック:en iyi diyarbakır escort
トラックバック:panel şantaj
トラックバック:น้ำดื่มอัลคาไลน์ ยี่ห้อไหนดี
トラックバック:nhà cái king88
トラックバック:естественный линкбилдинг
トラックバック:BUY TADALAFIL ONLINE
トラックバック:trang chủ Mint88
トラックバック:PEDOFIL VIDIO SEX
トラックバック:ganar Dinero con apuestas deportivas
トラックバック:codigo promocional apuestas deportivas
トラックバック:big dick medicine
トラックバック:Crm-X
トラックバック:Spigotmc`s website
トラックバック:Código promocional de MelBet: ZEVS777 – Apuesta gratis de 130 €/$
トラックバック:file extension 264
トラックバック:trang chủ 32win
トラックバック:68wim
トラックバック:Guaranteed weight loss in 24 hours
トラックバック:Buy fake passports online
トラックバック:download windows server 2022 crack
トラックバック:stripchat download video
トラックバック:available at issuu.com`s website
トラックバック:make bomb manual
トラックバック:download autocad 2023 full crack
トラックバック:3win
トラックバック:crypto account and virtual card,
トラックバック:там
トラックバック:Nhà cái E2bet
トラックバック:https://payhip.com/helpdogcom/blog/news/helpdogcom
トラックバック:m4new
トラックバック:ug8
トラックバック:Código de bono MelBet 2026: ZEVS777 – Bono de 100 €
トラックバック:casino chile
トラックバック:onion casino зеркало
トラックバック:casinos online legales en chile
トラックバック:chase bank travel phone number
トラックバック:uk human trafficking news
トラックバック:Dubai homes for sale
トラックバック:gamestation
トラックバック:avatarslot88
トラックバック:winner191
トラックバック:written by Yumikataoka
トラックバック:costa bingo
トラックバック:download photoshop full crack
トラックバック:visit Mapleprimes
トラックバック:Chances Casino langley bc
トラックバック:Fynolix
トラックバック:Corsa Valtaris
トラックバック:Qalira Vexo
トラックバック:Qoravo Nexi
トラックバック:Velira Qymo
トラックバック:Is Choctaw Casino In Pocola Open
トラックバック:Solaryx Lumen
トラックバック:sex porn dangerous
トラックバック:Orethys Ascension
トラックバック:jedifun
トラックバック:สมัครสล็อต
トラックバック:Boda8
トラックバック:High Profile Lahore Call Girls
トラックバック:在线购买阿普唑仑
トラックバック:Buy Tramadol online safely
トラックバック:888slot có lừa đảo không
トラックバック:Boda8 Malaysia
トラックバック:hermes birkin hac replica
トラックバック:ấu dâm
トラックバック:DJARUM4D
トラックバック:join jihad war
トラックバック:Pulsar Vexline
トラックバック:bokep tete besar
トラックバック:SEX DANGEROUS PEDOFIL
トラックバック:kontol besar
トラックバック:phim 18+
トラックバック:Torena Bash Avis
トラックバック:https://moveandreborn.fr
トラックバック:macau casinos revenue
トラックバック:Velocidad Luxten Reseña
トラックバック:Desi Call Girls in Karachi
トラックバック:Axynor Quantel
トラックバック:freelanceengine.enginethemes.com
トラックバック:spingranny bonus
トラックバック:Switch Chenix Fin
トラックバック:https://www.casino-2-fou.com
トラックバック:Qantelyx
トラックバック:Ordexia Peak
トラックバック:https://Xaydungminhquan.vn/cua-nhom-xingfa-tai-binh-duong.html
トラックバック:vavada
トラックバック:mama spin casino
トラックバック:Edecanes en CDMX
トラックバック:детейлинг авто в москве
トラックバック:GSH for longevity support
トラックバック:Stake зеркало
トラックバック:aplikacja plinko opinie
トラックバック:jual viagra ori
トラックバック:Hauppauge home additions
トラックバック:купить мефедрон
トラックバック:시알리스
トラックバック:aviator pin up
トラックバック:child sex videos
トラックバック:WoW MMORPG free
トラックバック:súng ak-47
トラックバック:Solaria Corebit
トラックバック:Vrymnex Avis
トラックバック:PORN SEX DANGEROUS PEDOFIL
トラックバック:Blackjack Online Real Money
トラックバック:delhi satta king
トラックバック:Piek Portdex
トラックバック:inscricao.infraero.gov.br
トラックバック:crypto slots casinos
トラックバック:mejores casinos online españa
トラックバック:Casino-2-Fou
トラックバック:0.01mmマイクロニードルRF
トラックバック:Bokep Thailand
トラックバック:spinogambino reseña
トラックバック:AyiwapAyiwap
トラックバック:Oxelvian Recensione
トラックバック:Finspirex Review
トラックバック:Vitesse Finterix
トラックバック:buy dilaudid online
トラックバック:Swap Lonox Neo Avis
トラックバック:Primfond
トラックバック:zugerkb e banking
トラックバック:e banking sgkb
トラックバック:boda8 malaysiaBoda8
トラックバック:viagra gelato
トラックバック:Xaloryx Nexus
トラックバック:Wede wrote
トラックバック:Giết người
トラックバック:http://www.worldchampmambo.com/UserProfile/tabid/42/UserID/472480/Default.aspx
トラックバック:https://bravepatrie.com/spip.php?article377
トラックバック:goodrx sildenafil prices
トラックバック:similar web-site
トラックバック:https://portal.sistemas.eca.usp.br/vendor/laravel-usp-theme/video/fjk/video-best-casino-in-aruba-for-slots.html
トラックバック:Elion Vexa
トラックバック:tron wallet address generator
トラックバック:is potawatomi Carter casino open
トラックバック:go directly to Templatebundle
トラックバック:spribe aviator tricks
トラックバック:Sterk Kalvix
トラックバック:sell viagra 100mg
トラックバック:강서룸싸롱
トラックバック:M4King
トラックバック:Alenixio Recensione
トラックバック:услуги таможенного брокера москва
トラックバック:viagra 87
トラックバック:The Creator Causal Design
トラックバック:카드현금화
トラックバック:CNY Goodies
トラックバック:카드한도 현금화
トラックバック:war jihad site
トラックバック:전자담배 쇼핑몰
トラックバック:lừa đảo
トラックバック:Btc Soul Ai
トラックバック:stake казино играть
トラックバック:SEX PORN DANGEROUS PEDOFIL
トラックバック:Swap Dexair Cap
トラックバック:เสื้อผ้าผู้ชายอ้วน
トラックバック:shkb e banking
トラックバック:tkb e banking
トラックバック:Dubai Private Tours From Russia
トラックバック:Trendy travel patches
トラックバック:растаможка авто москва
トラックバック:kapsul viagra murah
トラックバック:sex videos
トラックバック:buy doxycycline in usa
トラックバック:https://henryukazu.com/guest-writer-dele-momodu-Writes-on-the-state-of-the-nation-entiled-as-hope-dims-for-nigeria
トラックバック:http://www.musicfanclubs.org/cgi-bin/musicfanclubsorgads.cgi?url=http://tokmaklasoch.minobr63.ru/cropped-cropped-cropped-cropped-470038344-jpg/
トラックバック:Dijital İçeriklerin Önemi
トラックバック:wiki.internzone.net
トラックバック:Online Yayınlanan Güncel Yazılar
トラックバック:letshabitat.Es
トラックバック:firstup
トラックバック:professionals
トラックバック:Maatwerkwiki.Nl
トラックバック:https://md.coredump.ch/s/TUih1cYKz
トラックバック:gizlilik esaslı randevu
トラックバック:ЛЕСБИЙСКИЕ ПОРНО ВИДЕО
トラックバック:achtformpool online bestellen
トラックバック:ba7u2oqe7ewuregj3Pmok6eg2gkjvtcyc7j7cysn5zen4n2htk2q.cdn.ampproject.org
トラックバック:sgkb e banking
トラックバック:Güncel Bilgilendirme Yazıları ve Online İçerikler
トラックバック:Www.kalvingan.com
トラックバック:https://bbclinic-kr.com:443/nose/nation/Bbs/board.php?bo_table=E05_4&wr_id=750626
トラックバック:van escort Bayan
トラックバック:Https://Oke.Zone/
トラックバック:Www7a.Biglobe.ne.jp
トラックバック:dmonster592.dmonster.kr
トラックバック:Khủng bố
トラックバック:Van Escort
トラックバック:https://goto.now/Q5Ckw
トラックバック:Dewa99
トラックバック:Stma.cimmyt.Org
トラックバック:오피아트
トラックバック:opungwin login
トラックバック:multi-site
トラックバック:Facelift Turkey price
トラックバック:таможенное оформление москва
トラックバック:noteworthy
トラックバック:severance eat shit
トラックバック:Wisebusiness`s latest blog post
トラックバック:人妖色情片
トラックバック:bokep sma viral
トラックバック:david hoffmeister
トラックバック:janda toket gede
トラックバック:What is a billiards club
トラックバック:Lev Flowmex Avis
トラックバック:Chemin Fundria
トラックバック:Spot Exelon Xp Opiniones
トラックバック:Thematrixbet
トラックバック:escorts service in Udaipur
トラックバック:10 ball billiards rules
トラックバック:joy organics
トラックバック:Download Windows 11 Cracked
トラックバック:TR88
トラックバック:login slot bandar138
トラックバック:Silverlight window cleaning toronto https://silverlightwindowsandeaves.ca/
トラックバック:diyarbakıR merkez eskort Bayan
トラックバック:8xbet.racing lừa đảo công an việt nam cảnh báo truy quét cấm gấp
トラックバック:diyarbakır ofis elit eskort bayan
トラックバック:artisan grade
トラックバック:Nicely done
トラックバック:33win com
トラックバック:https://chsp.hispanichealth.info
トラックバック:jetspin88
トラックバック:TMD file viewer software
トラックバック:buzdolabı tamiri
トラックバック:nuhunslot cibai
トラックバック:head to 9signal
トラックバック:gelatin recipe
トラックバック:CNY Cookies
トラックバック:peniti4d
トラックバック:Celebrity Escorts Services
トラックバック:Https://Ajuda.Cyber8.Com.Br
トラックバック:peniti 4d
トラックバック:https://www.kangnampublic.com/
トラックバック:ручки aurora Africa
トラックバック:onlyfans giriş
トラックバック:https://remontkvartir152.ru/iskusstvenie-rozy-opt_nahodka
トラックバック:go99 nổ hũ
トラックバック:FLY88 com
トラックバック:viagra 100mg online
トラックバック:onlyfans nasıl açılır
トラックバック:online Casino requirements
トラックバック:today leaked fixed matches
トラックバック:Kryoneth Astra Review
トラックバック:Stature Invexor Avis
トラックバック:Pulsar Dexlink Review
トラックバック:Socialworkfest.es
トラックバック:Index Dexair Opt
トラックバック:Https://Tecktastic.Com
トラックバック:najlepsze kasyna online
トラックバック:article source
トラックバック:유튜브계정판매
トラックバック:real cash rummy apps
トラックバック:Понятие и суть налогового мониторинга: основные аспекты и значение процесса
トラックバック:ssn bot telegram
トラックバック:заказ косметики из кореи
トラックバック:nk88
トラックバック:bdsm
トラックバック:WINNER-HUB
トラックバック:Slot777
トラックバック:SEO consulting
トラックバック:如果登录页面无法打开,这个教程会一步步说明解决方法。
トラックバック:istanbul travesti
トラックバック:seo in usa
トラックバック:SignInSupport
トラックバック:本文介绍了官方登录流程以及常见问题。
トラックバック:slot365 link alternatif
トラックバック:Nascholing.be
トラックバック:Eng Saddam Al-Slfi
トラックバック:konten khusus pria dewasa
トラックバック:hire a hitman
トラックバック:Spanish Fly fishing los suenos
トラックバック:스포츠토토
トラックバック:해운대다이어트한의원 PT
トラックバック:online casino real money no deposit
トラックバック:singha24
トラックバック:789win.com
トラックバック:http://Dttindia.in/nouveau-casino-en-ligne-belgique-accepte-4/
トラックバック:косметика из азии
トラックバック:how to hire a hitman
トラックバック:Slot Online Gacor Banyak Maxwin
トラックバック:buzdolbı tamiri
トラックバック:http://feuerwehr-oberweissenbrunn.de/index.php/component/phocaguestbook/guestbook/1?Itemid=0&t=0
トラックバック:Daxloriz
トラックバック:Velonex Arya Avis
トラックバック:Trevionex Aura Recensione
トラックバック:Aureo Finoble
トラックバック:Daxloriz Review
トラックバック:Glorax NevoPro
トラックバック:BrynVex
トラックバック:Hot Call Girls
トラックバック:sex film site
トラックバック:https://potofu.me/helpdog
トラックバック:child sex picture
トラックバック:sports jerseys
トラックバック:купить корейскую косметику дешево
トラックバック:Download Windows 11 Cracked
トラックバック:tax in dallas
トラックバック:Alpen Advisor
トラックバック:qualifying conditions for a disabled parking permit
トラックバック:косметика из кореи купить
トラックバック:http://adm-urvan.ru/2018/07/27//
トラックバック:you can try edutown.kr
トラックバック:disabled parking permit eligibility
トラックバック:Proactive cyber defense services
トラックバック:Vectorline
トラックバック:Fluxwave
トラックバック:Catalyst
トラックバック:https://rachelvaldes.com/
トラックバック:co
トラックバック:sewer line repair
トラックバック:Harlequin Ichthyosis
トラックバック:dafasports.me
トラックバック:Sportwetten Prognosen
トラックバック:HD스포츠중계
トラックバック:tellculvers.com survey
トラックバック:LomexarioFin
トラックバック:Maneronexia
トラックバック:honda brush cutter
トラックバック:Veltrax Auron Avis
トラックバック:Managed Site Pro
トラックバック:astrologer in Colombo
トラックバック:playjonny casino españa
トラックバック:NeuroKapital Erfahrungen
トラックバック:Ventrim
トラックバック:NordWert Erfahrungen
トラックバック:Summit Finluxor
トラックバック:олимпбет сайт
トラックバック:viagra pdf
トラックバック:hire bodyguard in London
トラックバック:https://www.benzina60.cz/
トラックバック:پین باهیس
トラックバック:Overhead Garage Door Installation
トラックバック:Garage Door Spring Repair
トラックバック:nhà cái go99
トラックバック:Trama Profitex Recensione
トラックバック:Renditix AI
トラックバック:검증된주점
トラックバック:RivonorisPro Recensione
トラックバック:Itanoweltrix Recensione
トラックバック:hire a killer
トラックバック:blanche bb bag
トラックバック:북구클럽
トラックバック:VUA88
トラックバック:informative
トラックバック:как избежать воблинга на мотоцикле
トラックバック:sophisticated
トラックバック:interesting
トラックバック:cybersecurity
トラックバック:E2bet
トラックバック:https://recepd.fed.cuhk.edu.hk/
トラックバック:adderall xr
トラックバック:ремонт квадроцикла
トラックバック:nohu90
トラックバック:grounding electrical service smokey point
トラックバック:generator installation marysville
トラックバック:car charging station installation everett
トラックバック:finely selected speciality tea
トラックバック:노원출장마사지
トラックバック:college basketball wetten strategie
トラックバック:online live wetten
トラックバック:James Portnoy
トラックバック:login vai de bet
トラックバック:buy glock accessories
トラックバック:https://knoxguht76431.wikitidings.com/7079671/the_advantages_of_seo_services_for_business_growth
トラックバック:gg88 com
トラックバック:купить косметику из азии
トラックバック:open88
トラックバック:FlavinexiTrade Recensione
トラックバック:QuantexItalica
トラックバック:prospectos
トラックバック:나이트소개
トラックバック:viagra 440
トラックバック:quiz
トラックバック:мотокофры на заказ
トラックバック:송파출장마사지
トラックバック:mposports
トラックバック:mines game hack
トラックバック:road experience class
トラックバック:대구주점추천
トラックバック:สเต็ป 3
トラックバック:Financial website
トラックバック:captcha breaker
トラックバック:ทีเด็ด3เซียน
トラックバック:해외 선물 먹튀
トラックバック:gama casino играть бесплатно
トラックバック:888slot con
トラックバック:doxycycline 100mg over the counter
トラックバック:บอลเต็ง
トラックバック:서대문구출장마사지
トラックバック:성북구출장마사지
トラックバック:Well put
トラックバック:desi teen sex
トラックバック:68gamebai
トラックバック:Real madrid borussia dortmund apuestas
トラックバック:https://www.ksl.com/ad_logger/ad_logger.php?location=http://www.rowerowy.olsztyn.pl/wydarzenia/303-spacery-rowery-relacja.html
トラックバック:scam money cambodia
トラックバック:대구술집모음
トラックバック:Y2K168
トラックバック:야구생방송|스포츠중계|스포츠무료중계|해외스포츠중계|해외축구중계|축구중계|해외축구무료중계|무료스포츠중계|무료중계|축구무료중계|실시간스포츠|해외축구|epl중계|축구생중계|스포츠
トラックバック:zasady
トラックバック:was heißt handicap wette
トラックバック:고화질중계
トラックバック:redrock.am
トラックバック:Elevate your crypto identity with a stunning TRON vanity address ending in 999999! Our free TRON vanity address generator lets anyone create beautiful custom TRON vanity addresses ending with 999999 — the symbol of perfection and completion in the digit
トラックバック:viagra quotes
トラックバック:hz88 .com
トラックバック:kapsul viagra ecer murah
トラックバック:girl live cam
トラックバック:https://Downloadswp.com/
トラックバック:sep
トラックバック:Xyron Leda Avis
トラックバック:Capodanno Avis
トラックバック:Frame Exorex Fin
トラックバック:bokep anak
トラックバック:대구노래방소개
トラックバック:cialis and viagra
トラックバック:mines game real money withdrawal
トラックバック:비아그라 구매사이트
トラックバック:playjonny login
トラックバック:купить мотоштаны мотобрюки в спб
トラックバック:PsyPost bias
トラックバック:Mix Parlay
トラックバック:quizzes
トラックバック:sportwetten strategie pdf
トラックバック:Barista-Inspired mugs
トラックバック:seo services seo
トラックバック:Dubai Private Tour From India
トラックバック:Gelatin trick
トラックバック:농구중계
トラックバック:bekb e banking
トラックバック:multiple
トラックバック:Dash Exelon Recensione
トラックバック:av 在线
トラックバック:x 88
トラックバック:doragrup.com.tr
トラックバック:translation earbuds discount
トラックバック:แทงบอลโลก
トラックバック:okking
トラックバック:Dorivo Ervaringen
トラックバック:b2xbet
トラックバック:gbgbet
トラックバック:winpot
トラックバック:learn more website
トラックバック:Persimmon powder
トラックバック:강남썸데이
トラックバック:buy Pagalin 75mg near me
トラックバック:Buy liquid red mercury antimony online
トラックバック:dragon tiger master
トラックバック:comment
トラックバック:best vashikaran specialist
トラックバック:viagra 30mg
トラックバック:Live wetten verboten
トラックバック:c168
トラックバック:mua heroin
トラックバック:seriöse sportwetten tipps
トラックバック:Click on Haus Xxl
トラックバック:wetten Spiele
トラックバック:WettbüRo saarbrücken
トラックバック:was Bedeutet Quote Bei wetten
トラックバック:agen138
トラックバック:bluffen
トラックバック:Yoga exercises for back pain
トラックバック:rajakayu88
トラックバック:ok8386
トラックバック:gelatin trick to lose weight
トラックバック:SILAHKAN LANJUTKAN PHISINGNYA BOSSSSSSSSS ;)
トラックバック:doxycycline otc drug
トラックバック:Billiards Speculation
トラックバック:https://truereason.click/yoga/bai-tap-yoga-cho-nguoi-thoat-vi-dia-dem-n317.html
トラックバック:dewi11
トラックバック:kids sex picture
トラックバック:WPS免费版
トラックバック:Wett tips heute
トラックバック:singapore web directory
トラックバック:free pdf novel
トラックバック:https://helpliving.cz
トラックバック:scammer website
トラックバック:Essor Vexbit
トラックバック:Levier Yieldex Avis
トラックバック:tankless water heater installation
トラックバック:wettanbieter mit lizenz in deutschland
トラックバック:ae888.com
トラックバック:www.exoticzambia.com
トラックバック:Sportwetten Kombiwetten Strategie
トラックバック:https://8tkuib.sa.com/
トラックバック:app vai de bet
トラックバック:englewood
トラックバック:купить шишки
トラックバック:эндуро электровелосипед
トラックバック:Wetten esc Gewinner
トラックバック:купить меф
トラックバック:shower installation
トラックバック:Ice Fishing game
トラックバック:Wetten Startguthaben Ohne Einzahlung
トラックバック:https://addictionsrecoveryhotline.com
トラックバック:slot88 gacor
トラックバック:spinogambino login
トラックバック:roof repair near me
トラックバック:Very good
トラックバック:cute nude kids
トラックバック:바카라 사다리 검증토토 먹튀방지 야동
トラックバック:bounce house rental for holiday parties
トラックバック:greenwood village
トラックバック:klik disini, baca artikel
トラックバック:Togelup link
トラックバック:bonus wetten
トラックバック:online handicap parking permit
トラックバック:Artistic Couple Yoga
トラックバック:revenge heiress novel
トラックバック:we believe in the power of collaboration and the exchange of ideas. Our platform is dedicated to providing a seamless and rewarding experience for both guest bloggers and website owners looking to enhance their content offerings. As the best guest bloggin
トラックバック:Sportwetten tipps vorhersagen
トラックバック:spieler gegen Spieler Wette
トラックバック:Paysafecard Wettanbieter
トラックバック:https://alcoholism-drug-treatment.com/
トラックバック:zion168
トラックバック:temon-anak-rantau.pages.dev published an article
トラックバック:No Deposit Crypto Casinos
トラックバック:assignments writers
トラックバック:Sportwetten Tipps
トラックバック:wetten Quoten Erklärung
トラックバック:order fioricet no rx
トラックバック:Continuous Data Monitoring
トラックバック:web positioning
トラックバック:achat or
トラックバック:WinnItt
トラックバック:Kudos
トラックバック:Live A Healthy Life
トラックバック:site officiel achatdor.ch
トラックバック:Healthy Life Formula
トラックバック:DA88
トラックバック:nuhunslot
トラックバック:enlargemen penis pill
トラックバック:Buy Clonazepam Online
トラックバック:SEX PEDOFIL DANGEROUS
トラックバック:or suisse
トラックバック:유튜브아이디구매
トラックバック:Vegaz Casino Avis
トラックバック:대구유흥가이드
トラックバック:project writing near me
トラックバック:대구술집소개
トラックバック:Nambo Motor
トラックバック:st andrews taxis
トラックバック:beste quoten Sportwetten
トラックバック:https://nohu90edu.com/
トラックバック:sicher wetten gewinnen
トラックバック:노래방주점
トラックバック:musang178
トラックバック:penis enlargement pump reviews
トラックバック:Stuwen Opulex Ervaringen
トラックバック:Virtex AI
トラックバック:레깅스룸
トラックバック:Situs Slot Gacor Terbaru
トラックバック:seo optimization company
トラックバック:beste wettanbieter Ohne Lugas
トラックバック:was heißt quote bei wetten
トラックバック:emakqq
トラックバック:Boostaro Boostaro Reviews Boostaro Review Boostaro Boostaro Reviews Boostaro Review Boostaro Boostaro Reviews Boostaro Review Boostaro Boostaro Reviews Boostaro Review Boostaro Boostaro Reviews Boostaro Review
トラックバック:Glintgizmo.com
トラックバック:mostbet online
トラックバック:sportwetten Anbieter mit paypal
トラックバック:av มาแรง
トラックバック:zoomqq
トラックバック:david hoffmeister wikipedia
トラックバック:poxel io online
トラックバック:波场钱包
トラックバック:assignment writing sri lanka
トラックバック:Cheers Plenty of
トラックバック:независимая оценка ущерба дтп
トラックバック:xxx mom son fuck HD movies
トラックバック:Quite impressive
トラックバック:mom boy xvideo
トラックバック:over under wetten Erklärung
トラックバック:https://Www.protopage.com/muirenaspy
トラックバック:Seriöse wettanbieter online
トラックバック:free sex free
トラックバック:big o bail bonds
トラックバック:trading platform review
トラックバック:другие места турфирма калининград
トラックバック:check out this blog post via lovesomething.click
トラックバック:latina mom xxx
トラックバック:Sportwetten HöChster Bonus
トラックバック:หลุดโอนลี่แฟน Vk
トラックバック:No kyc Crypto Casinos
トラックバック:best franchise to own guide
トラックバック:best haemorrhoid cream
トラックバック:iron supplements
トラックバック:Instant Payout Online Casinos
トラックバック:gift ideas for men
トラックバック:другие места турфирма
トラックバック:black gay pornhub sex video – big ass xxx video sex pornhub
トラックバック:Buy Gabapentin online
トラックバック:Anishshinh.Com
トラックバック:comment-17006
トラックバック:Beste Online Wettanbieter
トラックバック:community hvac
トラックバック:คลิปหลุดXxx Thai
トラックバック:demo tigrinho
トラックバック:how to keep character consistent in AI art
トラックバック:پرده برقی
トラックバック:หนังโป๊ออนไลน์คลิปหลุด
トラックバック:achat d or
トラックバック:beste sportwetten apps
トラックバック:USDC
トラックバック:xturka guncel giris
トラックバック:Sportwetten wo am besten
トラックバック:exterior door replacement
トラックバック:парі-матч
トラックバック:wettanbieter paypal deutschland
トラックバック:پنجره برقی
トラックバック:brutal porn clips
トラックバック:kraken krab
トラックバック:Scandinavian Design Small Spaces
トラックバック:публичная отчётность по ресурсам
トラックバック:wett tipps über unter tore
トラックバック:https://www.tapestryorder.com/video/asi/video-ritz-slots-casino.html
トラックバック:best Payout Online casinos
トラックバック:실시간미니게임
トラックバック:mixue88
トラックバック:1 вин официальный сайт
トラックバック:대구 주점
トラックバック:tv
トラックバック:insights
トラックバック:secret info
トラックバック:1вин вход
トラックバック:Larex.co.il
トラックバック:sahabat38
トラックバック:https://lovesomething.click/bida/huong-dan-chi-tiet-luat-choi-bida-lo-soc-tron-ban-bida-8-bong-n335.html
トラックバック:business business blog blog business directory business directory singapore singapore busines directory
トラックバック:casino savaspin
トラックバック:Bitcoin kasinot
トラックバック:Top crypto casinos
トラックバック:bybit telegram bot
トラックバック:sist24.flex-film.de
トラックバック:1xbet aviator tricks
トラックバック:make big penis
トラックバック:good quotes about yoga
トラックバック:https://thecgp.org/current-issues/
トラックバック:fivecare
トラックバック:vmax
トラックバック:child prostitution
トラックバック:visit Immunofree`s official website
トラックバック:Buy Soma Online
トラックバック:Somersetproperty.Xcodeist.Com
トラックバック:https://Awm.Center/hanger/Mma-wetten-live-stream
トラックバック:Construction Site Safety Guidelines
トラックバック:spinogambino promo code
トラックバック:Scam Alert
トラックバック:https://robertsspaceindustries.com/en/citizens/helpdogcom
トラックバック:먹튀검증업체
トラックバック:bokep jepang | bokep indo | bokep malay | bokep hijab | bokep anal
トラックバック:https://goodfeel.click/bida/huong-dan-cach-dat-tay-va-cam-co-bida-chuan-cho-nguoi-moi-bat-dau-n337.html
トラックバック:Dating Escorts Islamabad
トラックバック:the ten cali packs
トラックバック:visit this web page link
トラックバック:was ist handicap beim wetten
トラックバック:istanbultravesti
トラックバック:wetten dass wettkönig gewinn
トラックバック:Wettanbieter Ohne Lugas Mit Paypal
トラックバック:best Math Tuition Singapore
トラックバック:math tuition center
トラックバック:online math tuition Singapore for weekly
トラックバック:situs resmi
トラックバック:Party Supplies Houston
トラックバック:Free Porn Videos
トラックバック:best maths enrichment singapore
トラックバック:buchmacher kreuzworträTsel
トラックバック:junior college 1 math
トラックバック:online math tuition singapore for scholarship exam
トラックバック:sec 3 math paper
トラックバック:online math tuition Singapore VR math
トラックバック:o level additional math tuition
トラックバック:Dental Equipment
トラックバック:wettstrategie mit erfolg
トラックバック:best tuition
トラックバック:online tuition singapore
トラックバック:wetten Online öSterreich
トラックバック:secondary tuition singapore
トラックバック:https://singapore-sites.b-cdn.net/math-tuition/tuition/h2-math-vectors-common-mistakes-in-cross-product-calculations.html
トラックバック:online math tuition Singapore credentials
トラックバック:malware hack work
トラックバック:Sec 1 maths tuition online
トラックバック:math-tuition-singapore.sgp1.vultrobjects.com
トラックバック:farmacia de alta especialidad cdmx
トラックバック:primary 6 math tuition
トラックバック:best secondary math tuition in singapore
トラックバック:https://singapore.us-Southeast-1.Linodeobjects.com/
トラックバック:online PSLE math preparation Singapore
トラックバック:distribusi barang
トラックバック:penipuan
トラックバック:this is vegas bonus
トラックバック:secondary 3 math online tuition
トラックバック:singapore online tuition
トラックバック:JC school maths tuition Singapore
トラックバック:Www.Tumblr.com
トラックバック:new content from wisebusiness.click
トラックバック:online tuition
トラックバック:livescore
トラックバック:구글 SEO 최적화
トラックバック:dc medical card dispensary
トラックバック:PMU Avis
トラックバック:www.exoticzimbabwe.com
トラックバック:power washing company
トラックバック:http://heraproperties.eu/author/peterscobie84/
トラックバック:Hosting07.Cdcloud.it
トラックバック:verified accounts for sale
トラックバック:wettquote bei pferderennen
トラックバック:https://learninghub.fulljam.com/@rollandbinnie1?page=about
トラックバック:High DR PA DA backlinks
トラックバック:Onlyfans vk
トラックバック:math tuition Singapore Nan Hua math
トラックバック:wetten Online Bonus ohne einzahlung
トラックバック:online math tuition Singapore bilingual tutor
トラックバック:استعلام
トラックバック:China Non-woven Bags
トラックバック:Sportwetten Quoten Vergleich
トラックバック:betting sites with welcome bonus
トラックバック:online math tuition Singapore for accelerated learning
トラックバック:primary 1 math online tuition
トラックバック:í ½í´ Kraken.cc: Твой ÐеÑнÑй ÐилеÑ
トラックバック:sec 2 maths paper
トラックバック:Watitoto
トラックバック:sec 2 past year papers
トラックバック:https://cropfvg.it/komische-wetten
トラックバック:tuition singapore
トラックバック:primary 1 math
トラックバック:online math tuition Singapore ebook
トラックバック:free spins no deposit uk
トラックバック:sportwetten ohne oasis forum
トラックバック:How is the estate tax calculated when a waiver is involved?
トラックバック:spinmama online casino
トラックバック:best math tuition
トラックバック:singapore online math tuition
トラックバック:to wisebusiness.click
トラックバック:зайти на kraken
トラックバック:math tuition Singapore Catholic High math
トラックバック:Pregnancy Yoga
トラックバック:casino online real money
トラックバック:dating com reviews
トラックバック:https://www.binance.com/register?ref=EN20OFF
トラックバック:https://creditonline.in.ua
トラックバック:roofing services Lorena TX
トラックバック:ax9qdysnndqf.compat.objectstorage.ap-singapore-1.oraclecloud.com
トラックバック:vanity tron
トラックバック:math tuition Singapore Chung Cheng math
トラックバック:clear wedding invitation
トラックバック:P2 maths tuition Singapore
トラックバック:blog business
トラックバック:sufficiently
トラックバック:Candy.ai
トラックバック:Ai Porn Generator
トラックバック:kiatoto
トラックバック:online math tuition singapore
トラックバック:beneficial
トラックバック:locação de casa na ilha comprida
トラックバック:Amazing
トラックバック:king size bed frame with storage singapore
トラックバック:secondary 4 normal technical maths papers
トラックバック:a course in miracles bookstore
トラックバック:free test papers secondary 1
トラックバック:Sportwetten online mit bonus
トラックバック:WWW.Cnsphone.Com
トラックバック:https://s3.amazonaws.com/math-tuition-singapore/sec-4-maths-tuition/o-levels-math/metrics-to-measure-your-na-level-maths-conceptual-understanding.html
トラックバック:link ok365
トラックバック:math tuition Singapore Maris Stella math
トラックバック:math tuition in singapore
トラックバック:mobile extended Reality studio
トラックバック:bandar casino resmi
トラックバック:ramblermails.com
トラックバック:math with confidence
トラックバック:p4 math tuition centre
トラックバック:https://foselwhs12-ship-it.github.io/Insight/
トラックバック:iPhone Magelang
トラックバック:online math tuition Singapore for brain teaser
トラックバック:obat pembesar penis
トラックバック:online math tuition Singapore tutor profile
トラックバック:https://websg1.s3.us-east-005.backblazeb2.com/math-tuition/psle/in-person-tuition-measuring-the-impact-on-your-childaampampamp039s-confidence.html
トラックバック:preprod.lourdes-Pireneje.pl
トラックバック:foselwhs12-ship-it.github.io/win
トラックバック:sgp1.Vultrobjects.com
トラックバック:bitcoin recovery expert
トラックバック:https://swaay.com/
トラックバック:wetten in österreich
トラックバック:math tuition Singapore Nanyang Primary math
トラックバック:sec 4 a maths tuition
トラックバック:https://math-tuition-singapore.sos-ch-dk-2.exo.io/primary-2-tuition-tips/p2-mathematics/how-to-create-a-dedicated-study-space-for-primary-2-tuition.html
トラックバック:math tuition Singapore Pei Chun math
トラックバック:big penis toys
トラックバック:blog-singapore.sgp1.digitaloceanspaces.com
トラックバック:trc20 browser
トラックバック:math-tuition-singapore.us-southeast-1.linodeobjects.com
トラックバック:online math tuition Singapore consultation
トラックバック:mobiblog sex 18+
トラックバック:Best tuition centre in Singapore
トラックバック:maths tuition centre singapore
トラックバック:neue online wettanbieter
トラックバック:math tuition Singapore HCI math tuition
トラックバック:disability parking permit
トラックバック:online tuition for maths
トラックバック:sos-ch-dk-2.exo.io
トラックバック:КУПИТЬ ВАЛИУМ ОНЛАЙН
トラックバック:viagra headache
トラックバック:https://jetourangola.com/
トラックバック:effectively
トラックバック:PSLE math tuition Jurong
トラックバック:geoblue travel insurance
トラックバック:promo deals online
トラックバック:wettbüro berlin in der nähe
トラックバック:wett tipps heute ki
トラックバック:what is yoga
トラックバック:online math tuition Singapore guarantee
トラックバック:tiktok bokep indo
トラックバック:new.iskcondesiretree.com
トラックバック:math tuition Singapore Cambridge syllabus
トラックバック:купить кокаин
トラックバック:math tuition Singapore Rulang math
トラックバック:vodkabet
トラックバック:o level maths tuition
トラックバック:math tuition singapore nus high school math
トラックバック:Prostitutas ibague
トラックバック:child rape videos
トラックバック:h2 maths tuition in singapore
トラックバック:online math tuition Singapore GRE quant 170
トラックバック:singapore tuition center
トラックバック:online math tuition Singapore cheat sheet
トラックバック:Sportwetten anbieter paysafecard
トラックバック:math tuition near me
トラックバック:Sec 1 Math syllabus
トラックバック:math home tuition singapore
トラックバック:online math tuition Singapore revenue
トラックバック:Https://Math-Tuition-Singapore-10.S3.Us-East-005.Backblazeb2.Com
トラックバック:maths tuition for secondary 4
トラックバック:online JC H2 math tutor
トラックバック:online math tuition Singapore project help
トラックバック:Escort service In Murree
トラックバック:math tuition Promotion Singapore
トラックバック:Orthopedy.Eu
トラックバック:купить ксанакс без рецепта
トラックバック:Beste Wettstrategie Sportwetten
トラックバック:3d Virtual Live Streaming service
トラックバック:online math tuition Singapore Masters tutor
トラックバック:sec 2 math paper
トラックバック:casino sign up bonus
トラックバック:Online casinos no deposit bonus
トラックバック:Appreciate it
トラックバック:Soma 250mg
トラックバック:non gamstop casinos
トラックバック:No deposit bonus codes
トラックバック:Instant withdrawal casino real money
トラックバック:Connecticut handicap parking placard
トラックバック:Roof replacement company near me
トラックバック:handicap parking permit
トラックバック:Crypto gambling sites
トラックバック:Self-publishing on Amazon
トラックバック:online disability evaluations guide
トラックバック:gelatin trick for weight loss
トラックバック:$200 no deposit bonus 200 free spins real money
トラックバック:TOTOSLOT777
トラックバック:ufaaba
トラックバック:Tipps Wetten Heute
トラックバック:recent collectednotes.com blog post
トラックバック:h2 math crash course
トラックバック:hair services singapore
トラックバック:esc wettbüro
トラックバック:Scamming
トラックバック:new sweepstakes casinos
トラックバック:скатерть дорожка на стол новогодняя
トラックバック:202930
トラックバック:math tuition Singapore Tao Nan math
トラックバック:knowing it
トラックバック:Things to do in Massachusetts
トラックバック:Best & Fun Things To Do + Places To Visit In Custer
トラックバック:things to do in Texas
トラックバック:private math tutor singapore
トラックバック:things to do in Louisiana
トラックバック:primary 6 math online tuition
トラックバック:see this page
トラックバック:singapore-sites.sos-ch-dk-2.exo.io
トラックバック:e math tuition singapore
トラックバック:online math Tuition O Level Calculus
トラックバック:https://Bbgportal.webworkinprogress.com/
トラックバック:sportwetten ohne oasis mit paysafecard
トラックバック:top attractions in Florida
トラックバック:legit online casinos that pay real money
トラックバック:Oregon at least once in your lifetime
トラックバック:https://ax9qdysnndqf.compat.objectstorage.ap-singapore-1.oraclecloud.com/singapore/maths-tuition/5/how-to-apply-trigonometry-in-real-world-A-math-scenarios.html
トラックバック:88fc
トラックバック:Tennessee
トラックバック:mathematics tuition near me
トラックバック:online math tuition Singapore English math tuition
トラックバック:maths
トラックバック:secondary 2 math topics
トラックバック:places to go in Vermont
トラックバック:h2 math singapore
トラックバック:Top 15 Movies Filmed in West Virginia by US Box Office
トラックバック:peripheral arterial disease treatment
トラックバック:handicap placard
トラックバック:top attractions in Oklahoma
トラックバック:Осаго Новичиха
トラックバック:reissuance of title
トラックバック:h2 math tuition in singapore
トラックバック:Indiana handicap parking placard Indiana disabled parking permit State Form 42070 disability placard how to get a handicap placard in Indiana Indiana BMV disability parking placard application Application for Disability License Plate or Parking Placard In
トラックバック:sec 3 maths tuition
トラックバック:math tuition Singapore Nanyang Girls math
トラックバック:https://math-tuition-singapore.s3.us.cloud-object-storage.appdomain.cloud/junior-college-1-math-tuition/h2-math/feed.xml
トラックバック:secondary 4 math
トラックバック:math-tuition-singapore.s3.us-east-005.dream.io
トラックバック:math tutors
トラックバック:The Most Expensive Pool Table in the World
トラックバック:top attractions in Kentucky
トラックバック:math tuition Singapore for expatriates
トラックバック:free sex for free
トラックバック:sec 3 e math papers
トラックバック:Buy Citra Online
トラックバック:online math tuition Singapore interactive
トラックバック:online math tuition A Level vectors
トラックバック:online math tuition advanced students
トラックバック:free secondary 2 exam papers
トラックバック:ip math tuition centre
トラックバック:sex toys on web
トラックバック:Best & Fun Things To Do + Places To Visit In Happy Valley
トラックバック:math-tuition-singapore.nyc3.digitaloceanspaces.com
トラックバック:primary math Home tuition singapore
トラックバック:038; Fun Things To Do + Places To Visit In Bethlehem, Pennsylvania (
トラックバック:big penis capsule
トラックバック:Child Lawyer near me
トラックバック:online math tuition Singapore for adults
トラックバック:math-tuition-singapore-1.s3.us-east-005.backblazeb2.com
トラックバック:wettanbieter ohne verifizierung
トラックバック:boostwin
トラックバック:With thanks
トラックバック:КУПИТЬ РИВОТРИЛ
トラックバック:top attractions in Maryland
トラックバック:wir wetten com sports
トラックバック:Wettbüro
トラックバック:online math tuition Singapore UCAT quant
トラックバック:math tuition Singapore Methodist Girls math
トラックバック:Seriously
トラックバック:038; Fun Things To Do + Places To Visit In Lowell, Massachusetts (
トラックバック:online math tuition Singapore qualification
トラックバック:jc H2 Math tuition near me
トラックバック:bokep cina
トラックバック:https://www.all-available.com
トラックバック:a math topics guide
トラックバック:places to go in North Dakota
トラックバック:(***) KRAKEN зеркало и актуальные зеркала 2026: все рабочие адреса площадки %
トラックバック:online math tuition Singapore for monthly
トラックバック:online math tuition Singapore IB 7
トラックバック:slot777 slot gacor
トラックバック:online math tuition Singapore homework help
トラックバック:https://Prive.ch
トラックバック:í ½íº Kraken: Ð Ñнок Тайн ⨠РабоÑее ÐеÑкало â Ð¡ÐµÐ³Ð¾Ð´Ð½Ñ â Твой ШанÑ! â¡
トラックバック:Montana
トラックバック:Be5 Sports
トラックバック:math tuition Singapore Temasek math
トラックバック:https://glp1diet.muragon.com/card/viewCardInfo?description=&target=_self&title=100++&url=httpsadafi.hit.gemius.pl_sslredirhitredirid..dg8ryji4qpqvl4etyiy_utdkdryolucycmas.tvnn.z7stparamofgjhjonssurlhttpproxypremium.topcheck-headers-statusurlht
トラックバック:math-tuition-singapore.sos-Ch-dk-2.exo.io
トラックバック:online math tuition Singapore data driven
トラックバック:Best & Fun Things To Do + Places To Visit In Dillon
トラックバック:top attractions in Iowa
トラックバック:top attractions in Vermont
トラックバック:online math tuition Singapore for homeschool parent
トラックバック:secondary 1 math tuition
トラックバック:top Goal Sportwetten
トラックバック:online math tuition Singapore NTU math graduate
トラックバック:https://www.pestconsult.co.tz
トラックバック:sec 3 maths exam papers
トラックバック:Animal Shelters in Solvang
トラックバック:обучение ремонту сколов Москва
トラックバック:fairly well
トラックバック:Sebek SEO
トラックバック:yoga to reduce waist
トラックバック:Math tuition Singapore MJC Math tuition
トラックバック:bezahlte wett tipps
トラックバック:how to get a handicap placard in Connecticut
トラックバック:how to get a handicap parking permit in nevada nv
トラックバック:secondary math tuition for O Levels
トラックバック:Indiana temporary handicap placard fee
トラックバック:sportwetten strategie immer gewinnen
トラックバック:math tuition Singapore Maha Bodhi math
トラックバック:Youtube
トラックバック:pub-76d7b1c5b6154d56b5A140ba70b98731.r2.dev
トラックバック:online PSLE O Level A Level math tuition
トラックバック:comparatif fatbet casino
トラックバック:Mushroom Gummies
トラックバック:secondary 4 maths notes
トラックバック:e maths tutor
トラックバック:things to do in Idaho
トラックバック:BurningWinsPlay delivers multiple entertainment for visitors looking for straightforward access. This interface centers on user-friendliness; letting it stay effortless to enjoy. For casual play; it caters to different tastes. Try to get an efficient alte
トラックバック:фартук для приготовления пищи с карманами
トラックバック:things to do in Nevada
トラックバック:TOTOSLOTO
トラックバック:cialis black 200 mg
トラックバック:math tuition worksheets Singapore
トラックバック:top attractions in Washington
トラックバック:boostwin официальный сайт
トラックバック:many
トラックバック:https://Kza.Blob.Core.Windows.net/
トラックバック:top math tutors
トラックバック:math tuition near me Singapore
トラックバック:ceraenoor.Com
トラックバック:anti rayap bandung
トラックバック:es-Betting.com
トラックバック:safe hdd destruction in data center
トラックバック:Wondrousdrifter write an article
トラックバック:online math tuition for slow learners
トラックバック:apuestas mlb las vegas
トラックバック:sec 3 amath paper
トラックバック:vyaparappsurat.Store
トラックバック:üye olmadan bonus
トラックバック:places to go in Kentucky
トラックバック:https://Www.dbsecurityshop.com/monopoly-live-bangladesh-best-for-big-multipliers/
トラックバック:top attractions in Mississippi
トラックバック:things to do in Pennsylvania
トラックバック:name necklace
トラックバック:top attractions in Connecticut
トラックバック:buy high potent weed
トラックバック:math tuition Reviews Singapore
トラックバック:top attractions in Minnesota
トラックバック:places to go in Minnesota
トラックバック:online math tuition primary Singapore
トラックバック:onwin giriş
トラックバック:Best & Fun Things To Do + Places To Visit In Sallisaw
トラックバック:places to go in Arkansas
トラックバック:online math tuition app Singapore
トラックバック:Sec 3 maths tuition online
トラックバック:good math tutors
トラックバック:secondary math tuition class
トラックバック:singapore-blog.s3.Us-East-005.dream.io
トラックバック:online math tuition JC2
トラックバック:Singapore online math revision
トラックバック:common psle math questions
トラックバック:online math tuition Singapore training
トラックバック:p6 math tuition
トラックバック:online math tuition Singapore distinction rate
トラックバック:hybrid math tuition Singapore
トラックバック:online math tuition Singapore for remedial
トラックバック:online math tuition
トラックバック:online math tuition Singapore for aptitude test
トラックバック:online math tuition Singapore blog
トラックバック:sec 3 express math
トラックバック:online math tuition Singapore money back
トラックバック:math tuition for upper primary
トラックバック:online math tuition Singapore Tamil math tuition
トラックバック:jc math home tuition
トラックバック:online math tuition Singapore gamified
トラックバック:math tuition for june
トラックバック:online math tuition Singapore for returning Singaporean
トラックバック:online math tuition Singapore before and after
トラックバック:a math tutor
トラックバック:sec 2 math paper free
トラックバック:online math tuition Singapore for teachers
トラックバック:maths tuition for primary school
トラックバック:online math tuition Singapore degree holder
トラックバック:math tuition Singapore TJC math tuition
トラックバック:online math tuition Singapore profit
トラックバック:maths tuition for primary 4
トラックバック:O Level math tuition Woodlands
トラックバック:online math tuition agency Singapore
トラックバック:live online math tuition Singapore
トラックバック:secondary maths tutor
トラックバック:singapore math tuition open now
トラックバック:online math tuition Singapore practice test
トラックバック:math tuition Singapore ACJC math tuition
トラックバック:online secondary maths tuition
トラックバック:join bomb jihad
トラックバック:affordable virtual math tuition
トラックバック:레비트라 구입 사이트
トラックバック:sec 1 math exam papers
トラックバック:online math tutor
トラックバック:online math tuition Singapore for ADHD
トラックバック:math tuition Singapore CJC math tuition
トラックバック:online math tuition Singapore parent portal
トラックバック:math tuition Singapore CHIJ Secondary math
トラックバック:online math tuition Singapore for enrichment
トラックバック:secondary 3 maths
トラックバック:online math tuition IP programme Singapore
トラックバック:online H2 math tuition Singapore
トラックバック:math tutors singapore
トラックバック:online math tuition Singapore for citizen
トラックバック:primary math tuition in singapore
トラックバック:Online math tuition Singapore For special needs
トラックバック:additional mathematics tuition singapore
トラックバック:math tuition Singapore AMC
トラックバック:online math tuition Singapore referral bonus
トラックバック:math tuition Singapore ACS Independent math
トラックバック:https://ax9qdysnndqf.compat.objectstorage.ap-singapore-1.oraclecloud.com/math-tuition-singapore/primary-6-math-tuition/psle/time-management-pitfalls-that-affect-primary-5-math-accuracy.html
トラックバック:bulliesofgreatness.com
トラックバック:math tuition for primary 1
トラックバック:online math tuition Additional Math
トラックバック:best maths tutor
トラックバック:prva-faza.porecje-drave.si
トラックバック:math-tuition-singapore.y0h0.c19.e2-5.dev
トラックバック:https://singapore-sites.0vkuo.upcloudobjects.com
トラックバック:storage.googleapis.com
トラックバック:e maths tuition singapore
トラックバック:best maths tuition centre singapore
トラックバック:https://math-tuition-singapore.s3.us-east-005.dream.io/tuition/secondary-3-math-tuition/feed.xml
トラックバック:sec 2 express math paper
トラックバック:math tuition for weak students Singapore
トラックバック:online math tuition Singapore post COVID
トラックバック:Sec 2 Maths tuition singapore
トラックバック:math tuition Singapore competition preparation
トラックバック:Math Tuition p1
トラックバック:math sec 2 paper
トラックバック:Psle Math Online Classes Singapore
トラックバック:maths practice papers
トラックバック:a level math tuition singapore
トラックバック:best secondary math tuition singapore
トラックバック:online math tuition Singapore trends 2024
トラックバック:math-tuition-singapore-10.s3.us-east-005.backblazeb2.com
トラックバック:Watch this
トラックバック:online math tuition Pasir Ris
トラックバック:online math tuition platform Singapore
トラックバック:Watch Now
トラックバック:sec 3 express math paper
トラックバック:viagra walgreens
トラックバック:Online Math Tuition Singapore For Expat Family
トラックバック:secondary 1 maths exam papers
トラックバック:Watch the video
トラックバック:secondary maths syllabus
トラックバック:online math tuition Singapore for gifted
トラックバック:https://blog-singapore.sgp1.digitaloceanspaces.com/math-tuition/6/differentiation-techniques-a-jc1-h2-math-checklist.html
トラックバック:primary 6 maths tuition
トラックバック:https://inscada.ru/lucky-wave-uk-casino-updated-offers-rewards/
トラックバック:Best primary math Tuition singapore
トラックバック:PSLE math tuition Singapore
トラックバック:secondary mathematics tuition
トラックバック:secondary 1 and 2 math
トラックバック:gacor77 login
トラックバック:https://S3.Amazonaws.com/
トラックバック:sec 2 maths tuition
トラックバック:https://ax9qdysnndqf.compat.objectstorage.ap-singapore-1.oraclecloud.com/psle-math-tuition-singapore/secondary-2-online-math-tuition/online-tuition/how-to-track-your-childs-progress-in-moe-aligned-online-math.html
トラックバック:busungbio.co.kr
トラックバック:tuition for secondary students
トラックバック:Situs Slot Online Mudah Menang
トラックバック:Primary maths Tuition singapore
トラックバック:online math tuition Singapore promo code
トラックバック:https://ax9qdysnndqf.compat.objectstorage.ap-singapore-1.oraclecloud.com/singapore/maths-tuition/4/feed.xml
トラックバック:online math tuition Singapore for crash course
トラックバック:check out this one from www.essentialsoundproductions.com
トラックバック:online math tuition Singapore top scorer
トラックバック:p5 math tuition
トラックバック:O Level math tuition
トラックバック:math tuition for primary school
トラックバック:secondary math home tuition
トラックバック:online math tuition Bedok
トラックバック:online math tuition Singapore enquiry
トラックバック:singapore-sites.S3.fr-par.scw.cloud
トラックバック:E Math tuition O Level online
トラックバック:online math tuition Singapore IGCSE A*
トラックバック:o level math tutor
トラックバック:torrents
トラックバック:virtual math tutor Singapore
トラックバック:tuition
トラックバック:Good Math Tuition Centre For Primary
トラックバック:Yoga Rope
トラックバック:https://singapore.us-southeast-1.linodeobjects.com/math-tuition/3/avoiding-common-pitfalls-in-budget-math-tutoring.html
トラックバック:best maths tuition near me
トラックバック:online math tuition Singapore A grade
トラックバック:A Level math tuition Punggol
トラックバック:online math tuition Singapore PhD tutor
トラックバック:online math tuition O Level Singapore
トラックバック:h2 math home tuition
トラックバック:online math tuition rates
トラックバック:spinogambino casino
トラックバック:math tuition for psle
トラックバック:online math tuition Singapore scholarship
トラックバック:best math tuition centre
トラックバック:best math tuition agency Singapore online
トラックバック:singapore.us-southeast-1.linodeobjects.com
トラックバック:https://math-tuition-singapore.sgp1.vultrobjects.com/
トラックバック:Singapore Secondary 2 Maths Exam Papers
トラックバック:junior college 2 math online tuition
トラックバック:normal technical math paper
トラックバック:math tuition Singapore NYJC math tuition
トラックバック:online math tuition Singapore demo lesson
トラックバック:o level maths tuition singapore
トラックバック:math tuition JC1 Singapore
トラックバック:math tuition intensive revision Singapore
トラックバック:secondary 4 math online tuition
トラックバック:stahlwandbecken shop
トラックバック:https://redemaiscondominios.com.br/blog/todo-lo-que-un-verdadero-fan-necesita-saber-en-2026
トラックバック:primary mathematics syllabus
トラックバック:primary math tuition agency Singapore
トラックバック:mom porn
トラックバック:secondary math tuition singapore
トラックバック:secondary math tuition centre singapore
トラックバック:online math tuition Singapore MOE registered
トラックバック:math tuitions singapore
トラックバック:sec 2 g3 math syllabus
トラックバック:math tuition Singapore NJC math tuition
トラックバック:h2 mathematics singapore
トラックバック:Math tuition For Primary 3
トラックバック:math secondary tuition
トラックバック:primary 6 maths
トラックバック:online math tuition Singapore LNAT math
トラックバック:math online tuition
トラックバック:single mattress for bed
トラックバック:online math tuition Singapore progress tracking
トラックバック:https://singapore-sites.s3.fr-par.scw.cloud/math-tuition/3/essential-criteria-for-selecting-math-practice-papers.html
トラックバック:Sec 4 O Level math tuition online
トラックバック:í ½í´ Kraken: ÐÑкÑÑвай ÐвеÑи â ÐÑÑмо СейÑаÑ! í ½í´ ÐÑ Ð¾Ð´ â ÐÑегда РаÑÐ¿Ð°Ñ Ð½ÑÑ
トラックバック:math tuition Singapore IJC math tuition
トラックバック:math tuition Singapore RVHS math tuition
トラックバック:jc maths tuition bishan
トラックバック:online math tuition Singapore Chinese math tuition
トラックバック:maths tuition for secondary school
トラックバック:sec 1 math paper
トラックバック:math-Tuition-singapore.s3.us.cloud-object-storage.appdomain.cloud
トラックバック:https://math-tuition-singapore-10.s3.us-east-005.backblazeb2.com/primary-2-tuition-centre-tips/p2-math/metrics-tracking-your-childs-engagement-during-tuition-sessions.html
トラックバック:24/7 online math tuition Singapore
トラックバック:online math tuition Singapore popular
トラックバック:best PSLE math online tuition
トラックバック:online A Math tuition Singapore
トラックバック:ib math tuition singapore
トラックバック:online math tuition Singapore reliable
トラックバック:online math tuition Singapore NIE trained
トラックバック:online math tuition Singapore Malay math tuition
トラックバック:psle maths tutor
トラックバック:math tuition discount Singapore
トラックバック:vent cleaners near me
トラックバック:tax return filing
トラックバック:Haartransplantation istanbul kosten
トラックバック:that it quite clearly
トラックバック:Secondary 3 Math Exam Papers
トラックバック:primary mathematics tuition
トラックバック:online math tuition Singapore best
トラックバック:online slots real money free spins
トラックバック:online math tuition Singapore NSAA math
トラックバック:https://eduonline.lk/forums/users/niamhfournier88/
トラックバック:Boomi-Anonymous.Com
トラックバック:set up a branch office in the philippines
トラックバック:stage1.nextchannelmedia.com
トラックバック:best online casinos that payout instantly
トラックバック:math tuition Singapore RI math tuition
トラックバック:https://www.blackhatprotools.info/member.php?275086-cygder
トラックバック:https://blog-singapore.sgp1.digitaloceanspaces.com/math-tuition/1/metrics-to-track-progress-in-group-tuition.html
トラックバック:mold removal singapore
トラックバック:anti rayap
トラックバック:cerita pengalaman gamer
トラックバック:aeo services
トラックバック:Hometogel
トラックバック:maxbonus77
トラックバック:primary 3 math online tuition
トラックバック:june math tuition
トラックバック:https://agroforum24.pl/viewthread.php?tid=42299
トラックバック:deneme bonus
トラックバック:https://pyymfo.sa.com
トラックバック:ex MOE math tutor Singapore
トラックバック:math tuition Singapore Pei Hwa math
トラックバック:https://kendallkreationz.com/uncategorized/888starz-polska-2026-bukmacher-z-opcja-live/
トラックバック:rape child on web
トラックバック:deneme bonusu
トラックバック:std singapore
トラックバック:Bola88
トラックバック:JASA
トラックバック:deneme bonuus veren siteler
トラックバック:Amazon KDP
トラックバック:online math tuition secondary Singapore
トラックバック:math tuition for primary 2
トラックバック:maths tuition online
トラックバック:O Level A Maths Tuition
トラックバック:online math tuition Singapore for all
トラックバック:maths tuition primary
トラックバック:online math tuition Singapore contact us
トラックバック:math tuition Singapore Red Swastika math
トラックバック:JC math tuition for A Levels
トラックバック:math tuition Singapore British curriculum
トラックバック:Math Tuition For Secondary School
トラックバック:recorded Online math tuition Singapore
トラックバック:https://pub-76d7b1c5b6154d56b5a140ba70B98731.r2.dev/e-maths-tuition/secondary-math/metrics-for-evaluating-the-effectiveness-of-online-e-maths-resources.html
トラックバック:math tuition results guarantee Singapore
トラックバック:online Math tuition Singapore analytics
トラックバック:math tuition for psle singapore
トラックバック:o level math tuition singapore
トラックバック:hoşgeldin bonusu verens siteler en iyi bonus
トラックバック:JC H2 math tuition Singapore
トラックバック:https://bouncingball8-1.gitbook.io/bouncingball8-docs/
トラックバック:online math tuition Singapore AEIS pass
トラックバック:Google Meet math tuition
トラックバック:math tuition Singapore RI Math competition
トラックバック:online math tuition Singapore top student
トラックバック:secondary school math
トラックバック:math tuition Singapore SRJC math tuition
トラックバック:online math tuition PSLE model drawing
トラックバック:Canva Training
トラックバック:Canva Course
トラックバック:https://ax9qdysnndqf.compat.objectstorage.ap-singapore-1.oraclecloud.com/singapore/maths-tuition/5/coordinate-geometry-key-metrics-for-a-math-exam-success.html
トラックバック:online math tuition secondary 4
トラックバック:math tuition Singapore homeschool
トラックバック:online math tuition Singapore student dashboard
トラックバック:math tuition Singapore DHS math tuition
トラックバック:online math tuition Singapore sign up
トラックバック:a level maths tuition near me
トラックバック:maths tuition for secondary 1
トラックバック:https://singaporeboleh.neocities.org//math-tuition-singapore/singapore-primary-5-math/primary-5-math-track-your-progress-with-these-percentage-metrics.html
トラックバック:https://s3.amazonaws.com/math-tuition-singapore/p1/how-to-use-manipulatives-to-improve-primary-1-number-sense.html
トラックバック:online math tuition for O Levels
トラックバック:online math tuition Singapore podcast
トラックバック:math tuition for secondary
トラックバック:online math tuition Singapore world class
トラックバック:p5 maths tuition singapore
トラックバック:secondary online math classes
トラックバック:online O Level math classes Singapore
トラックバック:online math tuition Singapore scholarship holder
トラックバック:https://kza.blob.core.windows.net/omt-math-tuition/tuition/maths/how-to-improve-your-spatial-reasoning-with-geometry-exercises.html
トラックバック:online math tuition Bukit Timah
トラックバック:online math Tuition Singapore GMAT quant 51
トラックバック:singapore math online classes
トラックバック:https://math-tuition-singapore.nyc3.digitaloceanspaces.com/
トラックバック:psle-math-tuition-singapore.us-southeast-1.linodeobjects.com
トラックバック:í ¼í½ª ezufwn TELEGRAM @SALESOVEN | ACCESS TO HACKED SITES FOR SEO | HTTPS://T.ME/SALESOVEN í ½í´¥
トラックバック:online math tuition Singapore FAQ
トラックバック:https://sin1.contabostorage.com
トラックバック:online math tuition Singapore KiasuParents
トラックバック:a level maths tuition
トラックバック:online math tuition Singapore SAT 800
トラックバック:Live Online Math Classes Singapore
トラックバック:online math tuition Singapore MAT math
トラックバック:pgn-af.com
トラックバック:us double mattress in singapore
トラックバック:secondary 1 math online tuition
トラックバック:https://singapore-blog.s3.us-east-005.dream.io
トラックバック:online math Tuition singapore register
トラックバック:P4 math tuition centre Singapore
トラックバック:math tuition Singapore IMO preparation
トラックバック:Power Bank 10000 mAh с MagSafe
トラックバック:xn88.com
トラックバック:Watch video
トラックバック:e-waste recycling and disposal in singapore
トラックバック:primary secondary JC math tuition online
トラックバック:math tuition Singapore Crescent Girls math
トラックバック:sec 1 math tuition
トラックバック:Online Math Tuition Singapore Pay Per Lesson
トラックバック:online math tuition Singapore for university entrance
トラックバック:JC online math tutor Singapore
トラックバック:math tuition Singapore for foreign students
トラックバック:best JC math tuition centre
トラックバック:online JC math tuition Singapore
トラックバック:math tuition Singapore Cedar math
トラックバック:online math tuition singapore for riddle
トラックバック:nk88 đăng nhập
トラックバック:Pinco Casino oynamag
トラックバック:sec 1 express math paper
トラックバック:https://ristoranteplaya.it/2025/11/02/melbet-2025-obzor-kazino/
トラックバック:gartenpool shop
トラックバック:british humour satire
トラックバック:online math tuition Singapore innovative
トラックバック:online math tuition Singapore for job test
トラックバック:h2 mathematics syllabus
トラックバック:mapquest
トラックバック:secondary school math home tuition Singapore
トラックバック:nextdoor
トラックバック:plinko game online real money
トラックバック:aviator app
トラックバック:https://ax9qdysnndqf.compat.objectstorage.ap-singapore-1.oraclecloud.com/math-tuition-singapore/tuition/secondary-2-tuition-centre-tips/how-to-integrate-tuition-materials-with-secondary-school-curriculum.html
トラックバック:tiger fortune
トラックバック:secondary 2 maths exam papers 2018
トラックバック:psle math tuition center
トラックバック:play Big Bass Splash online
トラックバック:online math tuition Singapore about us
トラックバック:online math tuition PSLE Singapore
トラックバック:online math tuition H2
トラックバック:https://www.itaforterevestimentos.com.br/sem-categoria/melbet-zerkalo-rabochee-mobilnaya-2025
トラックバック:math tuition Singapore HCI JC math
トラックバック:best online maths tutor Singapore
トラックバック:online math tuition Singapore effective
トラックバック:game plinko
トラックバック:after school math tuition
トラックバック:Online Math Tuition singapore testimonials
トラックバック:online math tuition Singapore referral
トラックバック:https://respogo.com/olympus-1000-kazino-melbet-2025/
トラックバック:tuition centre singapore
トラックバック:sec 1 algebra questions
トラックバック:https://math-tuition-singapore.sgp1.vultrobjects.com/primary-6-math-tuition/tips/how-to-integrate-psle-math-tuition-with-school-curriculum.html
トラックバック:math-tuition-Singapore.s3.fr-par.scw.cloud
トラックバック:online math tuition Singapore for educator
トラックバック:https://kza.blob.core.windows.net/kza/math-tuition/tuition/secondary-3-math-exam-preparation-a-problem-solving-checklist.html
トラックバック:jc mathematics tuition
トラックバック:Adderall 7.5mg
トラックバック:1 to 1 maths tuition
トラックバック:https://pzcbkq.sa.com
トラックバック:casino vipzino
トラックバック:Moree Glory Casino
トラックバック:Watch on YouTube
トラックバック:watch video now
トラックバック:online math tuition in singapore
トラックバック:https://onefinething.click
トラックバック:jogo fortune tiger
トラックバック:https://demo.wowonder.com/bouncingball8
トラックバック:kraken darknet ссылка
トラックバック:online Math tuition Singapore for international student
トラックバック:wat is plinko
トラックバック:https://github.com/bouncingball8io
トラックバック:еда на заказ кейтеринг
トラックバック:https://pavilius.com.au/2025/11/01/gates-of-olympus-na-dengi-melbet-2025/
トラックバック:Yoga Stretch for Opening Shoulders and Upper Back
トラックバック:ห้องเชือด
トラックバック:https://onbola.net/
トラックバック:http://images.google.es/url?sa=t&url=httpvyaparappsurat.storelucky-wave-casino-uk-uk-players-welcome
トラックバック:Truereason website
トラックバック:https://m.en.einlay.com/member/login.html?returnUrl=https://nv-casino-deutschland-online.de/bonus
トラックバック:activate aio tools v3 1.3 crack
トラックバック:https://storage.googleapis.com/
トラックバック:https://singapore.us-southeast-1.linodeobjects.com/math-tuition/1/how-to-improve-exam-performance-with-mathematics-tuition.html
トラックバック:math tuition Singapore JJC math tuition
トラックバック:o level maths syllabus
トラックバック:secondary math tuition
トラックバック:math tuition Singapore MOE syllabus
トラックバック:online math tuition Singapore package pricing
トラックバック:qualified math tuition teacher
トラックバック:math tuition crash course Singapore
トラックバック:https://sin1.contabostorage.com/1b1035b8bfe7475b9dcbc7a2a7300493:math-tuition-singapore/home-tuition-mathematics/criteria-for-assessing-a-mathematics-tutors-subject-matter-expertise.html
トラックバック:tuition mathematics
トラックバック:hacking password user
トラックバック:online math tuition Singapore recommended
トラックバック:https://psle-math-tuition-singapore.b-cdn.net/primary-6-online-math-tuition/singapore/metrics-to-consider-when-evaluating-online-math-tutor-platforms.html
トラックバック:lower secondary math tuition
トラックバック:maxcoil orlando crest
トラックバック:sec 1 maths notes
トラックバック:math tuition Singapore adult learners
トラックバック:secondary maths
トラックバック:online math tuition Singapore SMU math graduate
トラックバック:math tuition secondary school
トラックバック:secondary 2 math
トラックバック:https://singapore-sites.0vkuo.upcloudobjects.com/math-tuition/4/how-to-address-learning-concerns-through-parent-teacher-collaboration-effectively.html
トラックバック:math tuition centre in singapore
トラックバック:math tuition Singapore RGS math
トラックバック:online math tuition Singapore ex teacher
トラックバック:math tuition Singapore RI JC math
トラックバック:porno izle
トラックバック:primary school maths tuition Singapore
トラックバック:math tuition primary school
トラックバック:math tuition Singapore Australian curriculum
トラックバック:online math tuition Singapore success stories
トラックバック:online math tuition Singapore tech driven
トラックバック:https://ax9qdysnndqf.compat.objectstorage.ap-singapore-1.oraclecloud.com
トラックバック:online math Tuition Singapore modern
トラックバック:online math tuition Woodlands
トラックバック:group online math tuition Singapore
トラックバック:online math tuition Singapore forum
トラックバック:online math tuition Singapore ENGAA math
トラックバック:https://singapore-sites.0vkuo.upcloudobjects.com/math-tuition/online-math-tuition-singapore/how-to-track-your-childs-progress-in-online-math-tuition.html
トラックバック:math tuition center in singapore
トラックバック:O Level math online tutor Singapore
トラックバック:math tuition Singapore Ai Tong math
トラックバック:secondary maths exam papers
トラックバック:https://math-tuition-singapore.s3.us-east-005.dream.io/tuition/secondary-3-math-tuition/how-to-compare-secondary-3-tuition-rates-effectively.html
トラックバック:visa umroh
トラックバック:1 to 1 math tuition
トラックバック:math tuition singapore olympiad
トラックバック:singapore-sites.0vkuo.upcloudobjects.com
トラックバック:garasipoker
トラックバック:where to buy indonesia size mattress in singapore
トラックバック:pokerwalet
トラックバック:math tutoring singapore
トラックバック:rasqq
トラックバック:online math tuition Singapore partnership
トラックバック:zgribulita01
トラックバック:math tuition sg
トラックバック:how make big bomb
トラックバック:math tuition Singapore Kangaroo contest
トラックバック:jepangqq
トラックバック:online math tuition H1
トラックバック:maths tuition for secondary 2
トラックバック:https://psle-math-tuition-singapore.b-cdn.net/
トラックバック:math tuition secondary
トラックバック:spinmacho
トラックバック:primary mathematics tuition singapore
トラックバック:https://storage.googleapis.com/omt-tuition/math-tuition/1/how-to-maximize-learning-at-tuition-centers.html
トラックバック:online math tuition Singapore summary notes
トラックバック:magic koil sleep legacy
トラックバック:bodyguards in London
トラックバック:online math tuition Singapore NUS math graduate
トラックバック:sec 3 math paper free
トラックバック:https://s3.amazonaws.com/math-tuition-singapore/tuition-centre/math/checklist-essential-features-to-look-for-in-an-online-tutor.html
トラックバック:self paced online math tuition
トラックバック:foselwhs12-ship-it.github.io/wihd
トラックバック:titan gell penis
トラックバック:online math tuition Singapore module
トラックバック:pull out bed singapore
トラックバック:O Level Math exam preparation Online
トラックバック:online math tuition Singapore Reddit
トラックバック:math tuition centre Singapore
トラックバック:math tuition Singapore YJC math tuition
トラックバック:sec 2 wa3 math paper
トラックバック:Fun79
トラックバック:купоны на скидку винлаб
トラックバック:online math tuition Singapore 100 marks
トラックバック:sec 1 na math paper
トラックバック:a level math tuition
トラックバック:singapore-sites.y0h0.c19.e2-5.dev
トラックバック:https://math-tuition-singapore.y0h0.c19.e2-5.dev/junior-college-2-tuition-tips/a-levels-exams/jc2-exam-study-checklist-prioritizing-difficult-subjects.html
トラックバック:реконструкция школы
トラックバック:please click the following web site
トラックバック:https://singaporeboleh.neocities.org/
トラックバック:online math tuition Singapore article
トラックバック:affordable online math tuition Singapore
トラックバック:P6 PSLE math tuition online
トラックバック:강남 좋아요 쩜오
トラックバック:강남도파민
トラックバック:Seriously
トラックバック:갤럭시가라오케
トラックバック:제주가라오케
トラックバック:잠실가라오케
トラックバック:texas pokerist
トラックバック:강남퍼펙트
トラックバック:풀경기중계
トラックバック:benefits of online math tuition Singapore
トラックバック:online math Tuition singapore gmat math
トラックバック:Farmacia online Cialis España
トラックバック:스트리밍중계
トラックバック:https://ax9qdysnndqf.compat.objectstorage.ap-singapore-1.oraclecloud.com/psle-math-tuition-singapore/secondary-2-online-math-tuition/online-tuition/checklist-evaluating-online-math-tuition-platforms-for-sec-1-students.html
トラックバック:최신스포츠중계
トラックバック:Luca333
トラックバック:Wheel Yoga
トラックバック:anında deneme bonusu
トラックバック:онлайн казино
トラックバック:creative campaign automation
トラックバック:주소모아
トラックバック:저녁경기중계
トラックバック:interactive online math tuition
トラックバック:Paito warna Hk
トラックバック:프리미어리그무료중계
トラックバック:Megabet333
トラックバック:boat logo wallpaper
トラックバック:Rowboat Wallpapers
トラックバック:ответственность за ксеноновые фары
トラックバック:casino canada
トラックバック:4K중계
トラックバック:visit Sweetchoice here >>
トラックバック:4k boat wallpaper
トラックバック:Olimp Casino слоты
トラックバック:children’s single mattress
トラックバック:edegra sildenafil 100 mg para que sirve
トラックバック:wallpaper with boats
トラックバック:free cialis
トラックバック:scammer malware
トラックバック:join ukraine war
トラックバック:web scam
トラックバック:https://www.baldukrastas.lt/blog-straisniai?journal_blog_post_id=12
トラックバック:Проститутки Москвы Сокол район
トラックバック:Best gambling strategy rust
トラックバック:Stromectol sin receta España
トラックバック:https://nissa.cc/index.php?mid=trade&document_srl=224773
トラックバック:Wordrightcareer wrote
トラックバック:bondage site
トラックバック:wikinlp.ru
トラックバック:https://oke.zone/profile.php?id=171073
トラックバック:Viagra Super Active efectos 8 horas
トラックバック:https://Avtoline.online/bitrix/redirect.php?goto=https://sheardeals.com/bahigos-bonus-code-was-ist-das-genau-wie-arbeitet-er-beim-wettanbieter-und-auf-welchem-weg-kannst-du-bis-zu-weitere-boni-durch-live-chat-oder-e-mail-erhalten/
トラックバック:melbet
トラックバック:джойказино рабочий сайт
トラックバック:Poker88
トラックバック:Cá độ bóng đá
トラックバック:дизайн пленки на автомобиль
トラックバック:indie web episodes online
トラックバック:VSF Watches
トラックバック:https://www.google.com.sl/url?q=https://kendallkreationz.com/uncategorized/bahigo-bonus-code-wie-man-bei-dem-wettanbieter-durch-live-chat-oder-e-mail-zusatzliche-bonussen-bei-sportwetten-bis-hin-zu-weiteren-leistungen-erhalten-kann-und-was-die-sehr-positi
トラックバック:Viagra Super Active absorción rápida
トラックバック:Pinco Casino onlayn oyunlar
トラックバック:benign tumor treatment singapore
トラックバック:fishing boat Rickdiculous
トラックバック:крымская косметика скраб для лица
トラックバック:JTime
トラックバック:Seroquel envío rápido España
トラックバック:Sertalina original sin receta España
トラックバック:Kamagra online farmacia España
トラックバック:Cialis Professional envío España
トラックバック:Cialis dosis diaria efectos
トラックバック:Stromectol online farmacia España
トラックバック:https://independent.academia.edu/cygder
トラックバック:Kamagra Oral Jelly sin receta España
トラックバック:Comprar Contrave España
トラックバック:галамарт шторка автомобильная
トラックバック:makalah perpajakan
トラックバック:http://www.ssoblm.org/web/index.php?name=webboard&file=read&id=139085
トラックバック:free 25 no deposit
トラックバック:mega288
トラックバック:warkop4d
トラックバック:крымская косметика ростов
トラックバック:makalah six sigma
トラックバック:Comprar Modafinilo España
トラックバック:child porn viral
トラックバック:未承認医療機器 輸入
トラックバック:indian sex porn
トラックバック:wikinlp
トラックバック:wp t
トラックバック:아드레닌
トラックバック:this TRON vanity address generator builds TRON wallet addresses rich with 888888. Vanity wallet generator ensures TRON address generator delivers 888888 luck. TRON generate address for wealth—888888 embodies fortune. TRON wallet generator plus USDT wall
トラックバック:ac repair near me
トラックバック:Landscaping Services
トラックバック:register
トラックバック:world series of poker
トラックバック:Air Conditioning Installation
トラックバック:situs danatogel
トラックバック:danatogel
トラックバック:denemeabi deneme bonusu
トラックバック:топ казино на сбп
トラックバック:Buy Diazepam Online
トラックバック:해외축구중계
トラックバック:phim sex
トラックバック:Viagra Connect 50mg tablets
トラックバック:maestro bot telegram
トラックバック:1 signature clinic USJ
トラックバック:cardio slim tea
トラックバック:cobot uygulamaları
トラックバック:cognicare pro
トラックバック:alpha energy
トラックバック:roofing contractors Palm Desert CA
トラックバック:автохолодильник на фреоне
トラックバック:carbide reamer manufacturer korea
トラックバック:yoga exercises
トラックバック:formwandlung
トラックバック:coloring books
トラックバック:black gay pornhub sex video xxx sites
トラックバック:roller shutter singapore
トラックバック:女優 マニア フェチ
トラックバック:DD&B Custom Home & Pool Builders
トラックバック:rape girl videos
トラックバック:blood sugar blaster
トラックバック:Battery-less balcony solar power generation
トラックバック:led light therapy benefits safe
トラックバック:ретро гараж механик авто взломать
トラックバック:affordable cosmetic
トラックバック:malware tanpa iklan
トラックバック:visco foam mattress
トラックバック:breathe supplement
トラックバック:search engine optimization training Malaysia
トラックバック:https://wiki.tokyonightstyle.com/api.php?action=https://Acchingemall.shop/vulkan-spiele-polska-vulkanspiele-oficjalne-casino-2026/
トラックバック:비아그라 온라인
トラックバック:Ценю это .
トラックバック:เช็คหมายจับ
トラックバック:https://www.checkli.com/cygder
トラックバック:Buy & Sell Social Accounts | Account Selling Sites Online – CheckVCC.Com
トラックバック:pes-nv.ru
トラックバック:buy aged ig accounts
トラックバック:range rover repair near me
トラックバック:jaringan penipuan
トラックバック:Porsche workshop Malaysia
トラックバック:Space Club Wholesale
トラックバック:latest 4d
トラックバック:poolzubehör komplettset
トラックバック:광주출장마사지
トラックバック:goglow guide
トラックバック:expired sildenafil
トラックバック:adobet88
トラックバック:simply click www.ssoblm.org
トラックバック:Facesitting
トラックバック:Lunatogel
トラックバック:intestate succession real estate philippines
トラックバック:enlarged prostate specialist singapore
トラックバック:real money online casino
トラックバック:kerja ke jepang
トラックバック:międzywodzie wakacje
トラックバック:рейтинг казино
トラックバック:Рейтинг лучших казино
トラックバック:Играть в казино Пинап
トラックバック:казино онлайн топ
トラックバック:https://danalytics.in/live-dilery-v-kazino-x-obzor-nastolnyh-igr-onlayn/
トラックバック:Amazon Books
トラックバック:bästa krypto casinon
トラックバック:online casino instant withdrawal
トラックバック:PNG To PDF Converter
トラックバック:无需处方购买阿普唑仑
トラックバック:big penis
トラックバック:rape nude kid
トラックバック:poolfolien kaufen
トラックバック:http://Www.Yskstore.com/member/login.html?noMemberOrder=&returnUrl=httpcbsver.Bget.ruuserJadeRudolph1
トラックバック:Watch Rage Breed Me S3E1 Britt Blair ShesBreedingMaterial
トラックバック:махровые пляжные полотенца
トラックバック:generation station
トラックバック:luxury MPV chauffeur service Malaysia
トラックバック:Burn slim Reviews
トラックバック:í ¼í½ª rge13o TELEGRAM @SALESOVEN | ACCESS TO HACKED SITES FOR SEO | HTTPS://T.ME/SALESOVEN í ½í´¥
トラックバック:https://grbs.library.duke.edu/plugins/generic/pdfJsViewer/pdf.js/web/viewer.html?file=index.phpindexloginsignOutsource.tastevegasup.com&io0=S4t5U6
トラックバック:https://grbs.library.duke.edu/plugins/generic/pdfJsViewer/pdf.js/web/viewer.html?file=index.phpindexloginsignOutsource.tastevegasup.com&io0=B7c8D9
トラックバック:https://grbs.library.duke.edu/plugins/generic/pdfJsViewer/pdf.js/web/viewer.html?file=index.phpindexloginsignOutsource.tastevegasup.com&io0=P1q2R3
トラックバック:where to test euro size mattress in singapore
トラックバック:poker club
トラックバック:wszasy nad morzem
トラックバック:https://www.protopage.com/thorneqkue
トラックバック:https://grbs.library.duke.edu/plugins/generic/pdfJsViewer/pdf.js/web/viewer.html?file=index.phpindexloginsignOutsource.tastevegasup.com&io0=H1j2K3
トラックバック:my explanation
トラックバック:link vabet
トラックバック:https://grbs.library.duke.edu/plugins/generic/pdfJsViewer/pdf.js/web/viewer.html?file=index.phpindexloginsignOutsource.tastevegasup.com&io0=E7f8G9
トラックバック:fire damage restoration near me
トラックバック:bubble shooting game
トラックバック:poolleiter online bestellen
トラックバック:Viajes En Grupo Para Amigos
トラックバック:assignment help sydney
トラックバック:phim sex việt
トラックバック:https://grbs.library.duke.edu/plugins/generic/pdfJsViewer/pdf.js/web/viewer.html?file=index.phpindexloginsignOutsource.tastevegasup.com&io0=E1f2G3
トラックバック:sac-elearning.Com
トラックバック:https://grbs.library.duke.edu/plugins/generic/pdfJsViewer/pdf.js/web/viewer.html?file=index.phpindexloginsignOutsource.tastevegasup.com&io0=D4e5F6
トラックバック:casino francais en ligne fiable
トラックバック:신용카드 현금화
トラックバック:Hokibos898
トラックバック:rape on child
トラックバック:Toko bunga
トラックバック:인천쓰리노
トラックバック:Murchison Falls safaris
トラックバック:visit jakle.sakura.ne.jp
トラックバック:american forces travel website login
トラックバック:tải game poker
トラックバック:https://modechloe.com
トラックバック:baanpoolvilla
トラックバック:챔피언스리그무료중계|스포츠중계|스포츠무료중계|해외스포츠중계|해외축구중계|축구중계|해외축구무료중계|무료스포츠중계|무료중계|축구무료중계|실시간스포츠|해외축구|epl중계|축구생
トラックバック:web.ggather.com
トラックバック:无需处方购买阿普唑仑
トラックバック:recent iszene.com blog post
トラックバック:https://www.stradadelvinodocollidiluni.it/fatboss-casino-plongee-dans-l-univers-des-jeux-en-8/
トラックバック:https://grbs.library.duke.edu/plugins/generic/pdfJsViewer/pdf.js/web/viewer.html?file=index.phpindexloginsignOutsource.tastevegasup.com&io0=H4j5K6
トラックバック:Yoga Crow Pose
トラックバック:allwin ua казино
トラックバック:single size mattress topper
トラックバック:ซีรีย์จีน
トラックバック:Where To Test India Size Mattress In Singapore
トラックバック:hz88
トラックバック:http://s3a2Fevolv.e.L.U.Pc@haedongacademy.org/phpinfo.php?a[]=ahref=https://fastresponsepfa.co.uk/lucky-wave-uk-account-setup-verification-steps/Moreinspiringideas/ametahttp-equiv=refreshcontent=0;url=https://fastresponsepfa.co.uk/lucky-wave-uk-account-se
トラックバック:pin-up casino indir
トラックバック:slumberland singapore
トラックバック:Casinos In Saint Charles Mo
トラックバック:eunuch
トラックバック:สล็อตวอเลท
トラックバック:Instantquote
トラックバック:pussy fart
トラックバック:Sportwetten Strategie Mathematik
トラックバック:click here to visit Findaspring for free
トラックバック:how to beat the dealer At Blackjack 21
トラックバック:https://www.audioprotesi.org/dendera-casino-login-app-sign-up/
トラックバック:calmlife.click writes
トラックバック:hug necklace gift
トラックバック:Culinary Global jobs
トラックバック:listji.com
トラックバック:emaillist
トラックバック:carpro.com.ar`s recent blog post
トラックバック:Product Development
トラックバック:germicidal cleaning
トラックバック:live wette
トラックバック:고품질중계|스포츠중계|스포츠무료중계|해외스포츠중계|해외축구중계|축구중계|해외축구무료중계|무료스포츠중계|무료중계|축구무료중계|실시간스포츠|해외축구|epl중계|축구생중계|스포츠
トラックバック:click through the up coming article
トラックバック:smart rotator
トラックバック:magic koil innovation
トラックバック:an open mind
トラックバック:https://bihlmayermedia-bilder.com/fusball-bilder/fussball-portugal/
トラックバック:beste wettanbieter test Betrugstest
トラックバック:buchmacher deutschland
トラックバック:bongesot login
トラックバック:드라마 다시보기
トラックバック:bokep viral jilbab
トラックバック:top Sportwetten app
トラックバック:What is a branch office in the Philippines?
トラックバック:https://bihlmayermedia-bilder.com/fusball-bilder/fussball-belgien/
トラックバック:Clams casino rainforest vinyl
トラックバック:mehrfach Kombiwette rechner
トラックバック:xin88
トラックバック:Partaitogel
トラックバック:ภ.พ.20
トラックバック:대전출장마사지
トラックバック:vascular disease treatment singapore
トラックバック:sportwetten online Bonus ohne einzahlung
トラックバック:www.hairtransplantsd.com
トラックバック:huuuge casino cheat codes
トラックバック:pakpk
トラックバック:how old to gamble in dominican republic
トラックバック:Fußball Bilder
トラックバック:hm 88
トラックバック:how to pass a hair drug test
トラックバック:casino online gambling
トラックバック:คาร์บอนเครดิต
トラックバック:no keyword or random
トラックバック:https://Nmbheli.com/betano-Ro
トラックバック:сколько стоит сделать ремонт в однокомнатной квартире
トラックバック:ไฟรักในเถ้าความทรงจํา ซีรีย์จีน
トラックバック:spotify premium mod apk
トラックバック:í ¼í½ª 6l5csg TELEGRAM @SALESOVEN | ACCESS TO HACKED SITES FOR SEO | HTTPS://T.ME/SALESOVEN í ½í´¥
トラックバック:macau24h
トラックバック:digicattech
トラックバック:해외선물
トラックバック:breathing in yoga
トラックバック:Plaza de Seguridad
トラックバック:เครื่องเชื่อมเลเซอร์
トラックバック:บริษัทจัดหางาน
トラックバック:foldable Orthopedic mattress
トラックバック:hong kong single mattress in singapore
トラックバック:Http://Experience.Dayprofitinvest.Com/
トラックバック:Pferderennen hannover wetten
トラックバック:เติม heartopia uid
トラックバック:Dewatogel
トラックバック:mattress online free delivery
トラックバック:best online casinos payout
トラックバック:stemcell.biyibi.Com
トラックバック:https://hanson.net/users/cygder
トラックバック:pullout bed
トラックバック:Best NEET Coaching in Jalandhar
トラックバック:check this site
トラックバック:查看更多
トラックバック:https://emagrecimentonasaude.com
トラックバック:Live sportwetten Ergebnisse
トラックバック:금선물
トラックバック:https://hottips.click/blog/yoga-tre-hoa-khoe-dep-tu-trong-ra-ngoai
トラックバック:beverlyhillsjunkremoval.com
トラックバック:bandar slot terpercaya
トラックバック:poker g
トラックバック:https://zumvu.com/apostaschinesas/
トラックバック:sassywildcouple webcam
トラックバック:wollen Wir wetten gewinner
トラックバック:501oiyvl.yygame.tw
トラックバック:cheap viagra online
トラックバック:olx188
トラックバック:slot wd gak di bayar
トラックバック:вывоз мусора
トラックバック:wetten heute Vorhersagen
トラックバック:송파 가라오케 시스템
トラックバック:yoga before bed
トラックバック:제주출장안마
トラックバック:wett tipp ai erfahrungen
トラックバック:www.virtcop.com
トラックバック:business model canvas uber startup
トラックバック:die Besten wett tipps für heute
トラックバック:jerseys for sale
トラックバック:Karangan bunga banjarmasin
トラックバック:yowestogel
トラックバック:Laser247 betting id
トラックバック:poker hands
トラックバック:whatsapp qr code
トラックバック:laser247
トラックバック:야구무료중계
トラックバック:ewallst.com
トラックバック:wettanbieter im vergleich
トラックバック:https://landscapingspringtx.info/
トラックバック:làm bằng cấp 3
トラックバック:E Sport Wetten
トラックバック:unblocked games
トラックバック:DANGEROUS SEXUAL PEDOPHIL
トラックバック:sportwetten Schweiz verboten
トラックバック:pedophile
トラックバック:https://ako.uk.com/
トラックバック:chinky
トラックバック:https://avx.uk.com/
トラックバック:jet rehber
トラックバック:poker online free
トラックバック:beste Buchmacher
トラックバック:https://nanotinosh.com/beste-online-wetten-umsatz
トラックバック:https://wui.uk.com/
トラックバック:гражданство румынии купить
トラックバック:DANGEROUS SEXUAL PEDOPHILDANGEROUS SEXUAL PEDOPHIL
トラックバック:watch live adult cams
トラックバック:Viajes En Grupo Para Mayores De 50
トラックバック:virus
トラックバック:power plants by country
トラックバック:VIP Call Girls in Lahore
トラックバック:red chip casino royale
トラックバック:stromectol kaufen diskrete verpackung
トラックバック:í ¼í½ª idw4u5 TELEGRAM @SALESOVEN | ACCESS TO HACKED SITES FOR SEO | HTTPS://T.ME/SALESOVEN í ½í´¥
トラックバック:Capital303 Alternatif
トラックバック:k1gt
トラックバック:maxone
トラックバック:James huniford
トラックバック:best coaching in punjab
トラックバック:PHISHING
トラックバック:философия красоты и здоровье
トラックバック:https://isicommerce.sk/people_town_dark/
トラックバック:Kombiwette Eine falsch
トラックバック:jeboltogel
トラックバック:situs pp slot gacor
トラックバック:Eu9
トラックバック:Luxury777
トラックバック:wett tipps-heute
トラックバック:Wettseiten Test
トラックバック:Savings
トラックバック:лучшие игры Olimp [games]
トラックバック:wettbüro lichtenberg
トラックバック:Jewish
トラックバック:หลุดโอลี่แฟน
トラックバック:shitbreath
トラックバック:í ¼í½ª vejr2v TELEGRAM @SALESOVEN | ACCESS TO HACKED SITES FOR SEO | HTTPS://T.ME/SALESOVEN í ½í´¥
トラックバック:штуцер стеклоочистителя
トラックバック:trattamento medico erezione
トラックバック:Frontier Trailer Dealer
トラックバック:Jak inaczej nazywa się podnośnik?
トラックバック:Primary Keywords
トラックバック:fiberglass pools
トラックバック:Gooseneck Horse Trailers
トラックバック:most bet
トラックバック:Houston concrete driveway contractors
トラックバック:Aluminum Livestock Trailers,
トラックバック:Staging6.Dev.Gibbs.no
トラックバック:wettanbieter bonus
トラックバック:mega2ousbpnmmput4tiyu4oa4mjck2icier52ud6lmgrhzlikrxmysid.onion
トラックバック:wettbüro karlsruhe
トラックバック:shaved pussy
トラックバック:fuck
トラックバック:paedophile
トラックバック:nsfw
トラックバック:shaved beaver
トラックバック:DANGEROUS PEDOPHIL SEX
トラックバック:nsfw images
トラックバック:paki
トラックバック:Computer science tutoring Leeds
トラックバック:https://www.myminifactory.com/users/bouncingball8io
トラックバック:scammers
トラックバック:drugs
トラックバック:pedophile site
トラックバック:dangerous site
トラックバック:untrustworthy
トラックバック:bad content
トラックバック:malware alert
トラックバック:phishing link
トラックバック:landscaping in spring texas
トラックバック:Frompo Live
トラックバック:landscaping service
トラックバック:meet the team solution
トラックバック:скс тюнинг
トラックバック:đánh poker
トラックバック:poker cách chơi
トラックバック:queen size bed frame singapore
トラックバック:pop-up interview
トラックバック:from Visnove
トラックバック:maxcoil hotel mattress
トラックバック:pzp
トラックバック:подвеска автомобиля маз
トラックバック:Best orthopedic mattress Singapore
トラックバック:king drawer bed with super single pullout
トラックバック:tai poker
トラックバック:magic koil hk size mattress
トラックバック:varicose veins treatment
トラックバック:Superb
トラックバック:holdem texas poker
トラックバック:The Pup Life SG
トラックバック:best live streaming service
トラックバック:mega888 apk
トラックバック:Mixcloud blog post
トラックバック:https://gardenmvxw.raindrop.page/
トラックバック:best cryptos to mine 2022
トラックバック:hire bodyguards London
トラックバック:TFCC손상
トラックバック:automotive paint protection film
トラックバック:daily spotify playlist
トラックバック:Togelup Login
トラックバック:Buchmacher MüNchen
トラックバック:use wiki.anythingcanbehacked.com aquí
トラックバック:видеорегистратор hikvision
トラックバック:anuncios tiktok andorra
トラックバック:exotic car rental
トラックバック:https://www.google.gr/url?q=https://glory-casino-malaysia.info/signup
トラックバック:rundbecken online bestellen
トラックバック:where to buy korea size mattress in singapore
トラックバック:queen size bed dimensions cm singapore
トラックバック:nv casino logo
トラックバック:bounce house rentals with water slides
トラックバック:cryptoboss casino бездепозитный бонус
トラックバック:https://zona-kino.org/5952-djelloujej-2026.html
トラックバック:restaurants near me
トラックバック:Y2K168 ทางเข้า
トラックバック:bokep viral twitter
トラックバック:deck builders near me
トラックバック:cat casino официальный сайт
トラックバック:alugar casa para temporada na ilha comprida
トラックバック:slot 777
トラックバック:gurutoto
トラックバック:simply
トラックバック:check allthingsmanga
トラックバック:Ace Deck Builders
トラックバック:http://login.ezproxy.lib.usf.edu/login?url=https://glory-casino-bd.world/bonus
トラックバック:คลิปหลุดมาไหม่
トラックバック:https://Ssalbab.Com/member/login.html?noMemberOrder=&returnUrl=Https://nnnkx22.tv
トラックバック:clubs poker
トラックバック:Https://allmyfaves.com/gloirsidpm
トラックバック:texas poker holdem
トラックバック:Passover Recipes
トラックバック:Klebefolie
トラックバック:Stake Casino
トラックバック:новости мира яндекс
トラックバック:casino online 888
トラックバック:poker f
トラックバック:King Coil Mattress Review
トラックバック:mobile rummy games
トラックバック:pizza 789
トラックバック:annulment with psychological incapacity philippines
トラックバック:landscaping near spring tx
トラックバック:홍대 구글 리뷰 구매 업체
トラックバック:super king bed with storage
トラックバック:купить корость
トラックバック:дизайн автомобилей высшее образование
トラックバック:dadastake jetzt registrieren casino
トラックバック:Rummy 91 game
トラックバック:good content
トラックバック:Best Cold Mattress
トラックバック:kayapınar eskort
トラックバック:magic koil cooling mattress
トラックバック:optimum nutrition 100% whey protein isolate
トラックバック:strike shadow
トラックバック:the pup life compliant
トラックバック:peripheral arterry disease singapore
トラックバック:max coil 3 in 1 bed
トラックバック:world poker tour
トラックバック:poker wikipedia
トラックバック:game poker online
トラックバック:pola zeus pengamatan pola
トラックバック:read manga on allthingsmanga
トラックバック:revealed
トラックバック:Kinggame365
トラックバック:poker texa
トラックバック:3 fold mattress
トラックバック:full size latex mattress
トラックバック:varicocele treatment singapore
トラックバック:real money rummy
トラックバック:indonesia double mattress in singapore
トラックバック:rebpobate philippines
トラックバック:replica watches
トラックバック:топ 10 казино
トラックバック:psy.w-495.ru
トラックバック:poker 3
トラックバック:下载快连
トラックバック:bed And Sofa
トラックバック:video production
トラックバック:corporate secretarial services
トラックバック:KayapıNar escort
トラックバック:zynga poker
トラックバック:escort kayapınar
トラックバック:итог здорового питания
トラックバック:https://rayandco.uk/author/filomenahorvat/
トラックバック:https://git.van-peeren.de/emorysantiago9
トラックバック:slot pepek
トラックバック:magic koil preferred posture
トラックバック:eskort Bağlar
トラックバック:king koil australia size bed
トラックバック:188bet
トラックバック:онлайн казино
トラックバック:BağLar Escort
トラックバック:Bespokedesign
トラックバック:прием пищи после кофе
トラックバック:платформа Olimp Casino
トラックバック:odontologijos klinika
トラックバック:santettoto
トラックバック:Aortic Aneurysm Treatment Singapore
トラックバック:quite a few
トラックバック:washreport.com
トラックバック:spiare WhatsApp
トラックバック:Happy Slot 789
トラックバック:евгения фитнес бикини
トラックバック:w88
トラックバック:ดูหนังออนไลน์ 2026
トラックバック:Business card cases
トラックバック:Бизнес клуб в СПб
トラックバック:강남임팩트
トラックバック:Köpa Oxycodon På Nätet
トラックバック:팔꿈치관절경수술
トラックバック:king koil euro size bed
トラックバック:Project
トラックバック:gemparqq
トラックバック:wetten us wahl quoten
トラックバック:Play Slots Online
トラックバック:https://portal.whitesolutionllc.com/js/video/mwtt/video-free-games-slots.html
トラックバック:คลิปหลุด VK
トラックバック:inipoker
トラックバック:hokikiu
トラックバック:wsop poker free chips
トラックバック:tbs car battery delivery near me
トラックバック:wargaqq
トラックバック:is pocket spring better
トラックバック:innoshop.co
トラックバック:동성로나이트
トラックバック:new content from Cap Rs 485 Imatek Chinh Hang
トラックバック:노래방가이드
トラックバック:us king size mattress singapore
トラックバック:동성로술집
トラックバック:fun88
トラックバック:대구 노래방주점
トラックバック:восстановить волосы на голове
トラックバック:gop3
トラックバック:sofzsleep latex mattress
トラックバック:luật chơi poker
トラックバック:LoveAlba 코리아 인기 알바 공고
トラックバック:당일지급 알바 지금 바로 지원
トラックバック:xrumer nulled download
トラックバック:backtowork.gr
トラックバック:ห้องเชือด
トラックバック:강남 알바 고소득 공고 모음
トラックバック:LoveAlba 사이트 안전 검증 완료
トラックバック:гардеробные на заказ
トラックバック:유흥문의
トラックバック:바알바 인기 급상승 공고
トラックバック:시급 높은 알바 찾는 꿀팁
トラックバック:주점검색
トラックバック:러브알바 바로가기 링크 안내
トラックバック:nikmatqq
トラックバック:술집비교
トラックバック:pbn links
トラックバック:888online
トラックバック:что такое xrumer
トラックバック:viro australia mattress
トラックバック:best skincare clinic 2025
トラックバック:Unique
トラックバック:tiny houses examples
トラックバック:sichere Wett tipps morgen
トラックバック:goldenqq
トラックバック:the pup life
トラックバック:아고다 할인코드
トラックバック:Belize Properties
トラックバック:рулонный шторы
トラックバック:광안리출장마사지
トラックバック:купить айфон 17 pro
トラックバック:Unovegas Login
トラックバック:Plastic Surgery SEO Company
トラックバック:Prayer
トラックバック:wb вывести деньги
トラックバック:제주출장안마
トラックバック:американская версия смартфона
トラックバック:Renovationdeal
トラックバック:вклады тинькофф
トラックバック:david hoffmeister reviews
トラックバック:대구가라오케가이드
トラックバック:나이트
トラックバック:룸알바 고소득 일자리 정보
トラックバック:밤알바 당일지급 되는 안전한 장소
トラックバック:노래방방문
トラックバック:строительный робот пылесос
トラックバック:hafgarooha.raindrop.page
トラックバック:ворлд гаджет
トラックバック:أسعار ليموزين القاهرة الغردقة
トラックバック:ремонт фар в омске автомобильных
トラックバック:site scam
トラックバック:zigaretten
トラックバック:wedden tips website
トラックバック:арктические автопутешествия
トラックバック:제주출장마사지
トラックバック:where to test sleepy night mattress in singapore
トラックバック:купить айфон 17 512 в челябинске
トラックバック:Tensegrity Structures defying gravity
トラックバック:affordable seo services singapore
トラックバック:sleepy night perfect chiro mattress
トラックバック:시알리스 구매 사이트
トラックバック:where to buy slumberland mattress in singapore
トラックバック:free
トラックバック:chicken games
トラックバック:jam jahani 2026
トラックバック:TopRankedWorld
トラックバック:여성알바 구인구직 인기 사이트
トラックバック:brillx casino
トラックバック:salju4d
トラックバック:bed mattress singapore
トラックバック:hotel bed mattress
トラックバック:단기 알바 채용 실시간 등록
トラックバック:magic koil india size mattress
トラックバック:legal separation vs annulment philippines
トラックバック:지금주점
トラックバック:당일주점
トラックバック:150×200 bed size
トラックバック:동성로가라오케
トラックバック:искусственные цветы для интерьера
トラックバック:latex mattress for children
トラックバック:주점문의
トラックバック:초보도 가능한 여성알바 단기 모집
トラックバック:프리미엄 유흥알바 인기 지역
トラックバック:home loan Los Feliz
トラックバック:야간 유흥알바 공고 빠른 지원
トラックバック:일요일주점
トラックバック:고수익 알바로 인기 많은 포지션
トラックバック:hk queen mattress in Singapore
トラックバック:стеновые панели из гипсокартона для внутренней отделки стен
トラックバック:coconut shell mattress
トラックバック:Сборные грузы из Китая в Россию
トラックバック:maxcoil mattress sale
トラックバック:eagles sports memorabilia
トラックバック:steroids for sale
トラックバック:아이허브 할인코드
トラックバック:customer service number
トラックバック:eskort diyarbakır
トラックバック:buy bitcoin via ars
トラックバック:หวย 24
トラックバック:best medicine for sciatica nerve pain
トラックバック:x.com/HoyBcn
トラックバック:Phising Abuse
トラックバック:лутран платформа
トラックバック:duniabet
トラックバック:밤문화모음
トラックバック:클럽예약
トラックバック:달서구나이트
トラックバック:대구노래방리스트
トラックバック:free online face swap
トラックバック:대구나이트추천
トラックバック:วิเคราะห์มวยวันนี้
トラックバック:คลิบหลุดมาใหม่
トラックバック:capital303
トラックバック:купить айфон
トラックバック:jobs in canada today
トラックバック:dinasti168
トラックバック:부산출장마사지
トラックバック:viro australia size Mattress
トラックバック:w 88
トラックバック:drip casino
トラックバック:excel with business courses
トラックバック:pool folie
トラックバック:호텔스닷컴 할인코드
トラックバック:best esim sites
トラックバック:kent casino зеркало
トラックバック:казино atom
トラックバック:power bi learning courses
トラックバック:광안리출장안마
トラックバック:microsoft courses power bi
トラックバック:trix официальный сайт
トラックバック:Madibet
トラックバック:writes in the official Xn 2 Wxfax 2bxc 9bzguc blog
トラックバック:https://juliusesep65421.blogitright.com/41122882/mengenal-permainan-slot-progresif-peluang-jackpot-yang-terus-bertumbuh
トラックバック:excel course
トラックバック:illegal casino
トラックバック:camilla araujo nudes videos
トラックバック:농구분석
トラックバック:мотобрюки кожаные мужские
トラックバック:residential plots for sale in pallikaranai
トラックバック:Customerreviews
トラックバック:룸싸롱
トラックバック:car service chelsea nyc
トラックバック:Www.cap-rs485-chinh-hang.Xyz
トラックバック:олимпбет линия
トラックバック:3mbet
トラックバック:world series of poker free chips
トラックバック:시알리스 구입
トラックバック:janniklorenz
トラックバック:регистрация в pinco casino
トラックバック:8xbets.buzz lừa đảo công an truy nã cấm người chơi tham gia
トラックバック:researchinstitute.io lừa đảo công an truy nã cấm người chơi tham gia
トラックバック:wafersmuseum.org.uk lừa đảo công an truy nã cấm người chơi tham gia
トラックバック:berita aktual dan terpercaya
トラックバック:astroslot indonesia
トラックバック:Comprar carnet de conducir
トラックバック:Cheapest private flight
トラックバック:Cetak brosur palangkaraya
トラックバック:bokep viral terbaru indo
トラックバック:다음달주점
トラックバック:이벤트주점
トラックバック:베스트주점
トラックバック:сокол квадроцикл
トラックバック:viaje en grupo a Marruecos
トラックバック:kodpung88
トラックバック:продать лекарства Ижевск ФармСкупка
トラックバック:Y2K Slot
トラックバック:dtf transfer printer
トラックバック:how do you download tiktoks
トラックバック:tent table chair rental Maryland
トラックバック:Đề Thi Tiếng Trung HSK
トラックバック:мотокофр pilot racing mod1 black
トラックバック:Zahraniční sázkové kanceláře online
トラックバック:электромобиль трехколесный
トラックバック:cheap corporate gifts
トラックバック:m358
トラックバック:Установка ГЛОНАСС
トラックバック:대구가라오케예약
トラックバック:BOKEP ABG
トラックバック:Доставка груза из Китая в Россию
トラックバック:Доставка грузов в Узбекистан
トラックバック:panen77
トラックバック:https://bc-game43.com/
トラックバック:ระบบตัวแทนเว็บพนัน
トラックバック:달서구클럽
トラックバック:продать лекарства Волгоград ФармСкупка
トラックバック:Доставка груза из Китая с растаможкой
トラックバック:Доставка грузов из Китая с таможенным оформлением
トラックバック:Таможенный брокер в Москве
トラックバック:Доставка грузов из Китая в Россию под ключ
トラックバック:money laundry
トラックバック:culinary kitchen jobs
トラックバック:Emergency Plumbing Customer Service Number
トラックバック:MAX 889
トラックバック:AstroSLOT
トラックバック:corporate gifts
トラックバック:gembet casino
トラックバック:ZEUSQQ
トラックバック:David Hoffmeister YouTube
トラックバック:skylimited
トラックバック:как проверить индекс
トラックバック:смотреть подробности
トラックバック:agoloannet
トラックバック:ระบบ agent เว็บพนัน
トラックバック:Buy Aged Reddit
トラックバック:facial
トラックバック:the pup life complaint
トラックバック:Kharlie Cirk
トラックバック:다이어트약
トラックバック:Kyle’s Cards
トラックバック:new1E
トラックバック:http://Dmonster592.Dmonster.kr/bbs/board.php?Bo_table=qna&wr_id=1312449
トラックバック:Https://customfields.bonify.io/Dashboard/loggedout?shop=new1e.com
トラックバック:밤문화정보
トラックバック:david hoffmeister reddit
トラックバック:JetBlack
トラックバック:Danatoto
トラックバック:sbobet88 parlay
トラックバック:электромобиль ора
トラックバック:видеорегистраторы купить
トラックバック:stake app
トラックバック:граната подвески автомобиля
トラックバック:https://diapazon.kz/news/125280-540-aktyubincev-otdali-nedobrosovestnim-zastroishikam-svishe-35-mlrd-tenge
トラックバック:soaek2.shinsegaegroupinside.com
トラックバック:Mobile Locksmith
トラックバック:LetsJackpot Casino
トラックバック:FIELDBOSS was founded in 2012 by Rimrock Corporation
トラックバック:shunyanant
トラックバック:Lisensi ilegal
トラックバック:ceylon black tea
トラックバック:donghua
トラックバック:Server virtualization technology
トラックバック:how to earn money fast online
トラックバック:WSM Casino
トラックバック:Toko lisensi fake
トラックバック:Apollo 789 club
トラックバック:米子 肩こり
トラックバック:Римские шторы
トラックバック:переключатель стеклоочистителей
トラックバック:m358
トラックバック:jackpot city canada
トラックバック:private ragnarok servers
トラックバック:Exabet88 Bandar Toto
トラックバック:best video production agency in india
トラックバック:คลิปหลุดไทย
トラックバック:agenjitu303
トラックバック:XLTX file program
トラックバック:1
トラックバック:https://urbanclick.in/author/adolph66r39368/
トラックバック:мостбет казино
トラックバック:3.5톤화물차광폭윙바디
トラックバック:Lapak Game Online
トラックバック:Top Up Game Murah dan Aman
トラックバック:pornasexe.com
トラックバック:telegram bot news
トラックバック:https://donaldwestlake.ru/proizvodstvo-kartonnyh-korobok-i-upakovki/
トラックバック:https://bysystem.ru/process-proizvodstva-kartonnyh-korobok-i/
トラックバック:คลิปหลุดเกย์
トラックバック:Top Up Game Free Fire
トラックバック:Ecstasy for sale
トラックバック:Landslot88 Tembak Ikan
トラックバック:инвалидка тюнинг
トラックバック:Top Up Games Termurah
トラックバック:website nggak jelas
トラックバック:website scam
トラックバック:Simplebet8
トラックバック:https://www.youtube.com/watch?v=l2j9KnPnq78
トラックバック:Top Up Mobile Legend Indonesia
トラックバック:LGO
トラックバック:Top Up Mobile legends
トラックバック:Renovationjourney
トラックバック:https://dev.kiramtech.com/nolanvroland13
トラックバック:https://www.bongmedia.tv/@julianawolak4?page=about
トラックバック:https://buzzlab.co.za/author/pamelamorton94/
トラックバック:трипскан вход
トラックバック:https://attractionsontario.ca/author/dyancochrane38/
トラックバック:local mini bus companies
トラックバック:https://roomingshare.com/author/aqvflorrie536/
トラックバック:https://git.legatus.ru/dalenebrain079/norsk-tipping-casino-app1986/wiki/KongKasino
トラックバック:Expertcontractors
トラックバック:https://www.uvdreamhome.com/author/hugh8480146404/
トラックバック:casino pinco
トラックバック:pulsz casino login
トラックバック:rissa may bbc dp
トラックバック:강남 유흥알바 고수익으로 일하는 방법
トラックバック:여성 구인 많은 알바 카테고리
トラックバック:ซีรีย์จีน ซับไทย
トラックバック:tigerdong
トラックバック:도우미 알바 여성 구인 정보