タイトル画像:Haplogroup R (Y-DNA).PNG
この記事は執筆中です。
どんな言葉を・どんな人が話しているか。
言語や語学に興味があるひとであれば、誰もが持つ素朴な疑問でしょう。
あるいは、もっとマニアックに(笑)、
ドイツ語やフランス語のルーツは印欧祖語だけど、印欧祖語のルーツは?
古代漢語は印欧祖語に似ているらしいけど、古代漢語を話していたのはどんなひとたち?
など、「いろいろな言語のルーツや系統」について、知りたい方も多いでしょう。
言語のルーツ・系統を探るのは「比較言語学」の役目で、文字情報が豊富な印欧語族の祖語(印欧祖語)再構において、さらには、文献資料のないオーストロネシア語族においても、多くの成果をあげています。
一方で、遺伝子の分析テクノロジーが近年、飛躍的に進歩し、人類の「遺伝子系統」がどんどん明らかになってきています。
そして、「言語(語族)と遺伝子」にかなりの相関関係があることも分かってきたのです。
将来的には(考古学とも協働しつつ)、「印欧祖語のルーツや古代漢語との関係」、さらには、「シュメール語や日本語の起源」、などの解明も進んでいくのではないでしょうか。。。
そんなことも願いつつ、今回は、「言語と遺伝子」の関係について、紹介していきます!
遺伝子とDNA
「言語(語族)と遺伝子」の関係について理解するには、遺伝子、さらに、DNA、染色体、ミトコンドリアについて、基礎的なことを知っておく必要があります。
下図は、「典型的な動物細胞の模式図」です。
①核小体(仁)、②細胞核、③リボソーム、④小胞、⑤粗面小胞体、⑥ゴルジ体、⑦微小管、⑧滑面小胞体、⑨ミトコンドリア、⑩液胞、⑪細胞質基質、⑫リソソーム、⑬中心体
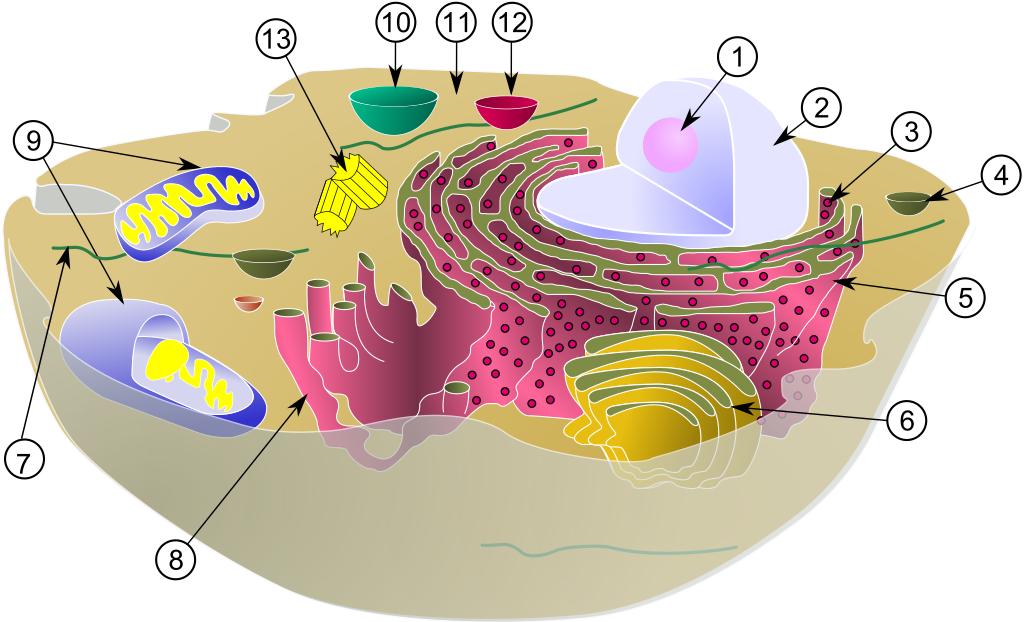
本記事で重要なのは、
②細胞核(厳密には、この中にある染色体)、⑨ミトコンドリア の2つです。
「染色体」「ミトコンドリア」の中に、「DNA」があり、DNAのうちの一部が「遺伝子」です。
ここから先は、『新版 日本人になった祖先たち―DNAが解明する多元的構造』(篠田謙一著、2019年、NHKブックス)という本に、とても分かりやすい(!)説明があるので、これを参考に紹介していきます。(引用は、2007年発行の旧版『日本人になった祖先たち―DNAから解明するその多元的構造』によります)

.PNG){kind=link}
{kind=link}
遺伝子は、私たちの体を構成しているさまざまなタンパク質の構造やそれが作られるタイミングを記述している設計図です。[中略]
私たちの体を作るために2万~3万個の遺伝子があることがわかっています。(p15)この設計図を書いている「文字」にあたるものがDNAです。
DNAはデオキシリボ核酸という化学物質の略号ですが、その文字は全部で4種類しかありません。(p15)この4種類の文字は総称して「塩基」という特別の名称で呼ばれます。
さらにDNAは、複製を作るために2本の鎖状の構造を取っていて、特定の塩基がペアになって存在するので、通常はそのペアのことを「塩基対」という言葉を用いて表現します。(p15)塩基対を単位として考えると、ヒトの持つDNA全体は、それが約30億も連なった長大なものになります。[中略]
私たちのDNA配列には意味のない部分が大量にあります。約95%は、今のところ何の意味もない文字の羅列でできていると考えられているのです。(p15-p16)
遺伝子、DNA、塩基対の関係は、下記「ゲノムの構造図」の下半分をご覧ください。
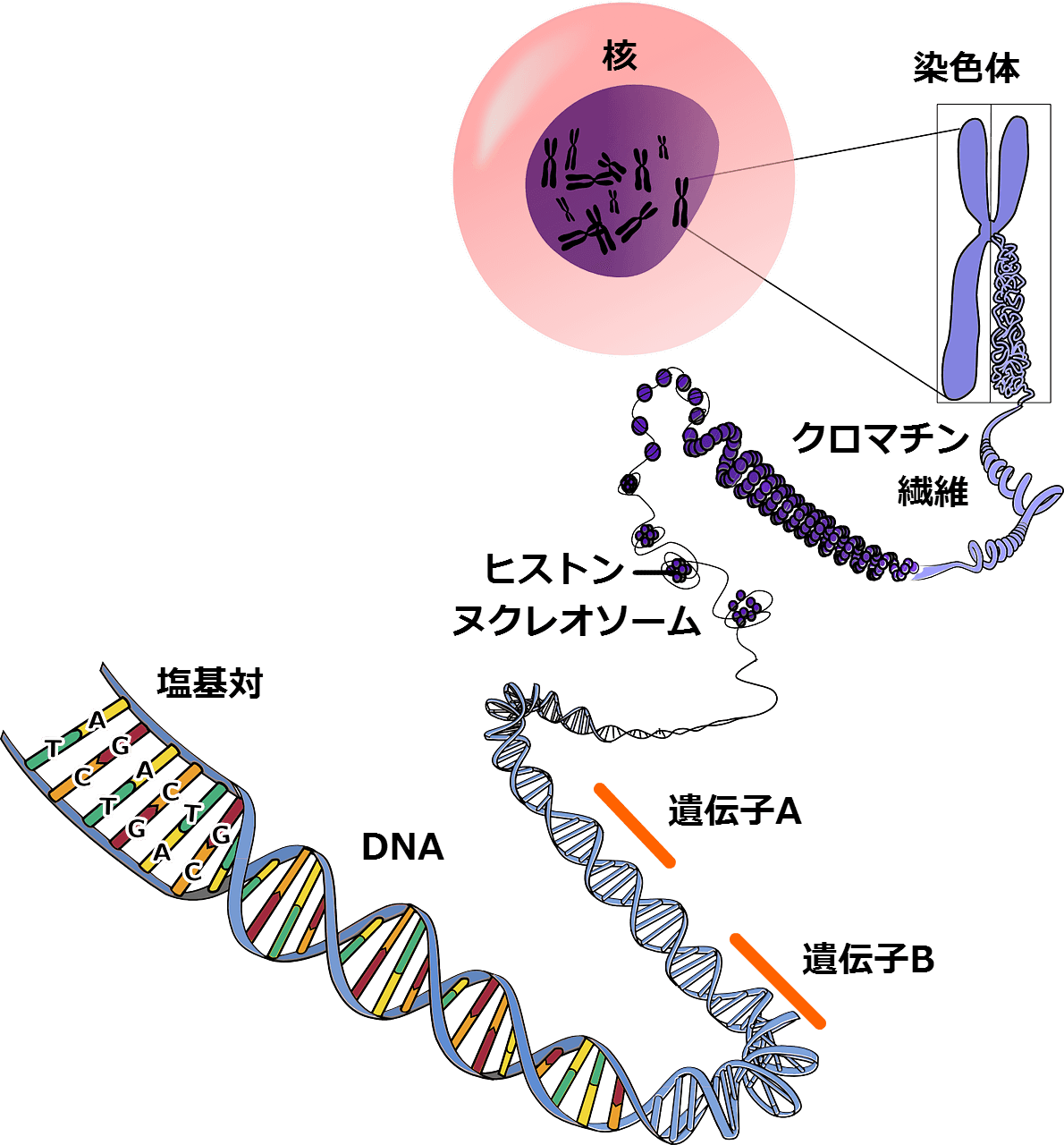
DNAを「らせん階段」に例えるなら、塩基対は「段(ステップ)」に相当します。
下図は、塩基対の構造を示した模式図です。
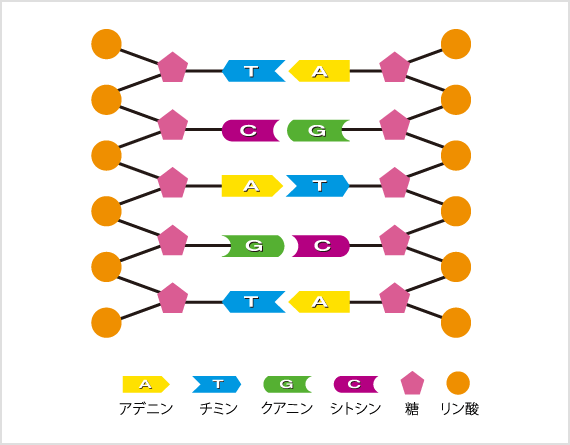
塩基対は、4種類ある塩基物質(Aアデニン、Gグアニン、Cシトシン、Tチミン)のペアで、常に A と T、G と C が対になります。
上図の左側を上から読むと TCAGT、右側を上から読むと AGTCA になります。
塩基対をタテに配列したもの(この例では、TCAGT, AGTCA)を「塩基配列」といいます。
※「DNA配列」「遺伝子配列」とも呼ばれます。
ちなみに、TCAGT = AGTCA です。
なぜなら、左が T であれば右は A、左が C であれば右は G … に一意的に決まるからです。
これを、「塩基の相補性」といいます。
ひとつのDNAを構成する塩基配列は、じっさいには膨大な長さをもつのですが、タンパク質の形成に関わる「コーディング領域」(とびとびに現れ、合計で約5%)と、それ以外の「ノンコーディング領域」(約95%)があります。
おおざっぱに言うと、タンパク質の形成に関わる部分、つまり、「塩基配列のコーディング領域」が「遺伝子」です。
遺伝子は20種類の「アミノ酸」でできており、それぞれのアミノ酸は、塩基対が3つ配列したユニットに対応します。(下記「DNAの遺伝暗号(コドン)表」参照)
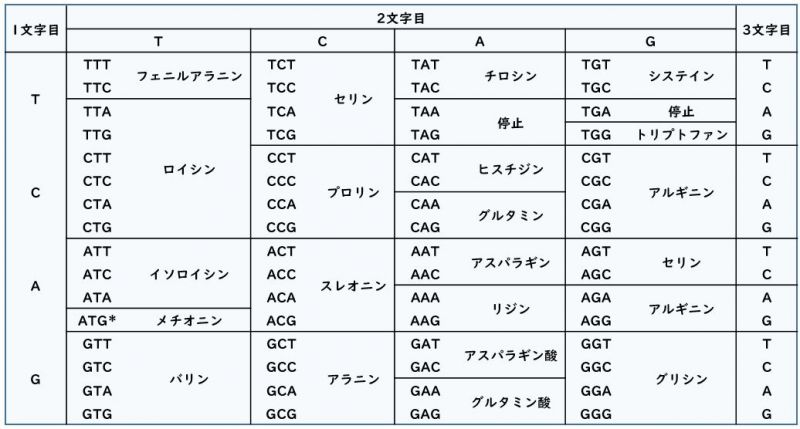
たとえば、・・・・GAA・・・・CAA・・・・という塩基配列があったとして、その途中に「GAA」があればその部分は「グルタミン酸」、「AGG」があればその部分は「アルギニン」というアミノ酸に該当する、というわけです。
染色体
つづいて、「染色体」の話題に移りましょう。
ふたたび『日本人になった祖先たち』に戻ります。
染色体というのは、簡単に言うと遺伝子をまとめて収納する入れものです。(p187)[中略]
総数で2万~3万個あると言われる遺伝子は、バラバラになって核のなかに入っているわけではなく、染色体のなかにグループになって収納されているのです。
大きい染色体では3000個くらい、小さいものでも数百個の遺伝子をまとめて収納しています。(p187)
遺伝子が染色体に収納されているイメージは、前出「ゲノムの構造図」をご覧ください。
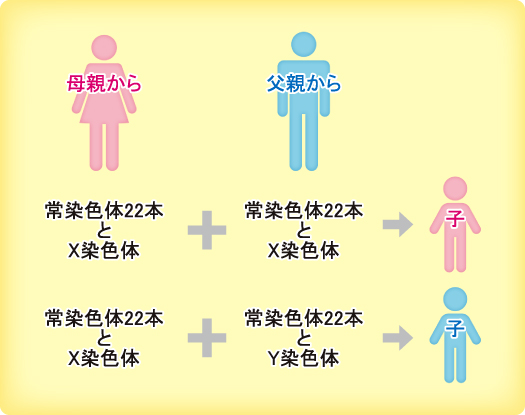
ヒトには全部で23種類の染色体があるのですが、実際には両親から1セットずつを受け取っているので、1つの細胞のなかにその2倍の46本の染色体が存在しています。(p187-p188)
このうち22種類までは男女で同じものを持っています。[中略]
しかし残りの1組は男性と女性で構成が異なっています。
女性はX染色体をペアで持っているのですが、男性はX染色体とY染色体という形の違う染色体を持っています。(p188)
男女で同じである22種類の染色体を「常染色体」、残り1種類の染色体を「性染色体」といいます。
下図のように、生殖時(受精時)に母親から受け継ぐのはX染色体しかあり得ません。
一方、父親からX染色体を受け継いだ子供は女性(XX)に、Y染色体を受け継いだ子供は男性(XY)になります。
{kind=link}
さて、Y染色体は、遺伝子の変化を起こさずにそのまま子孫に伝えられます。
したがって、Y染色体の系統をたどっていくと、父方のルーツが分かるということになります。
ハプロタイプ
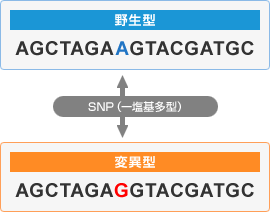
塩基配列の中で、ある特定の一箇所の塩基だけが異なるような現象を、SNP(Single Nucleotide Polymorphism / 一塩基多型)と呼びます。
たとえば下図の場合、普通の配列(野生型)のなかで、1箇所だけ A が G に変異しています。
この状態を「SNP」と呼ぶわけです。
Y染色体の系統
まず、Y染色体の系統図をご覧ください。(Wikipedia > Y染色体ハプログループ より)
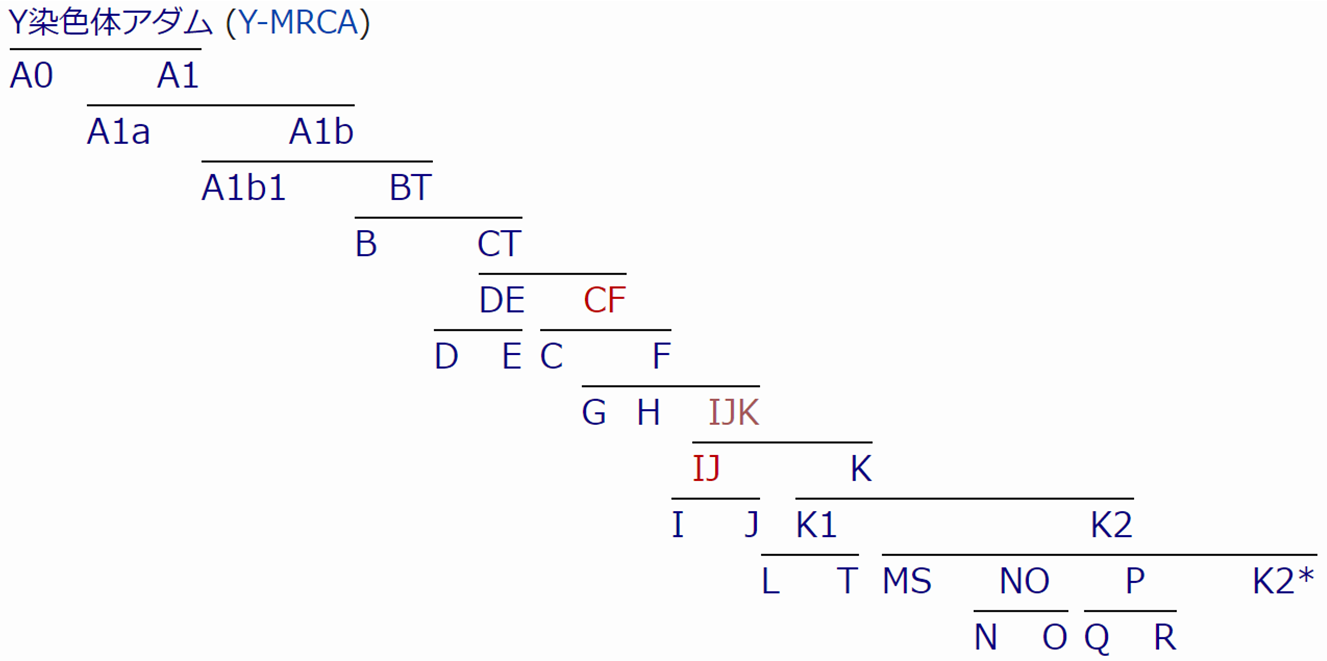 アルファベットが A から R まで、18文字使われていますね。
アルファベットが A から R まで、18文字使われていますね。
それぞれは、Y染色体の大分類に対応しています。
つまり、Y染色体は大きく18分類となっており、これは、2002年に世界の学者が集まった共同研究機関で取り決められたものです。
じっさいには、アルファベットを複数合わせたもの(BT、CT、DEなど)や、数字と小文字を組み合わせたサブグループ(A1b1など)もあり、分類数は膨大なものになっています。
遺伝子(Y染色体)と語族
先ほどの「Y染色体の系統図」を踏まえ、「Y染色体と語族の対応表」を作成したので、ご覧ください。
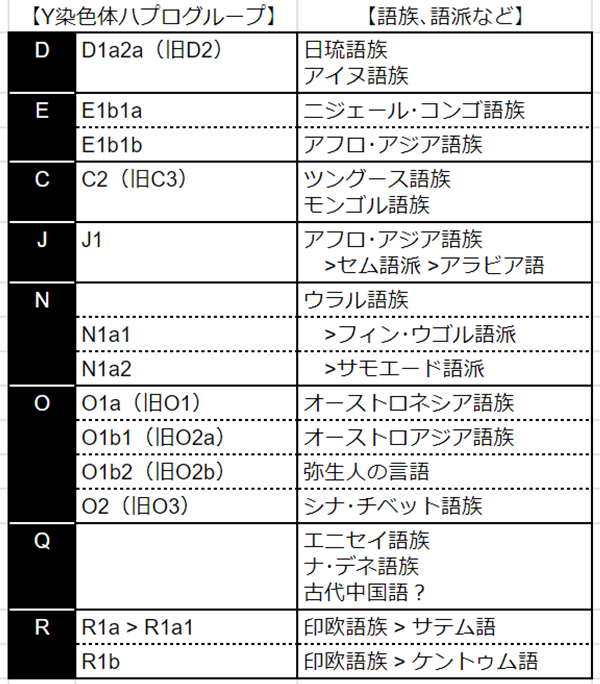
それぞれについて、詳細に見ていきます。
Y-D
まずは、「ハプログループDの分布図」です。
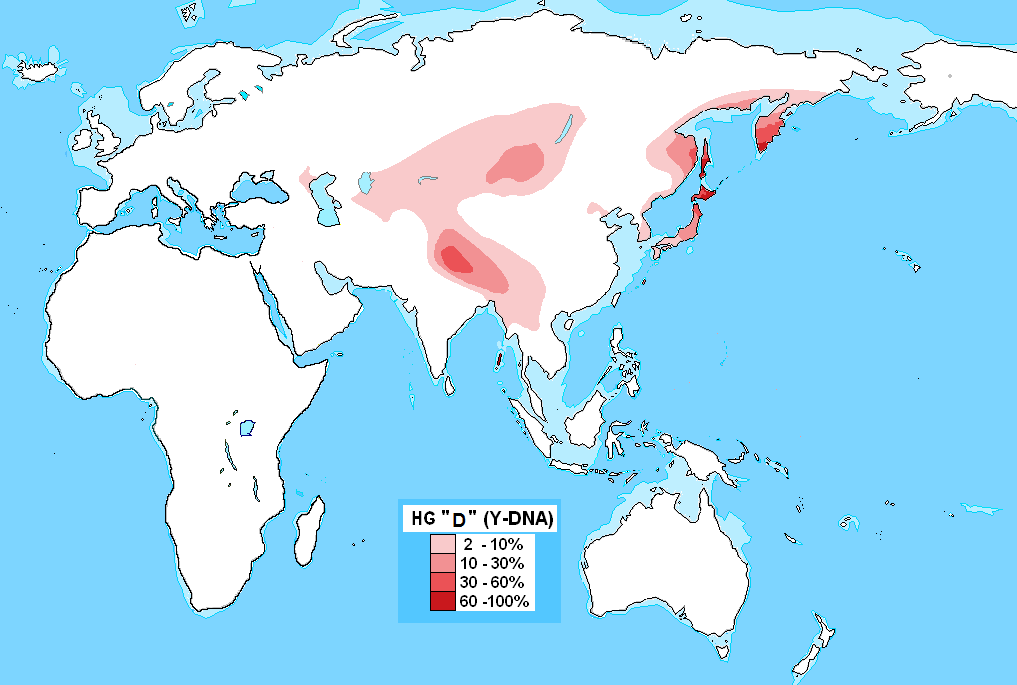
.png){kind=link}
D1a2a(旧Y-D2):日琉語族・アイヌ語族
つぎに、ハプログループD1a2aについて見てみましょう。
「ハプログループDの移動想定経路 (Haber et al. 2019)」をご覧ください。
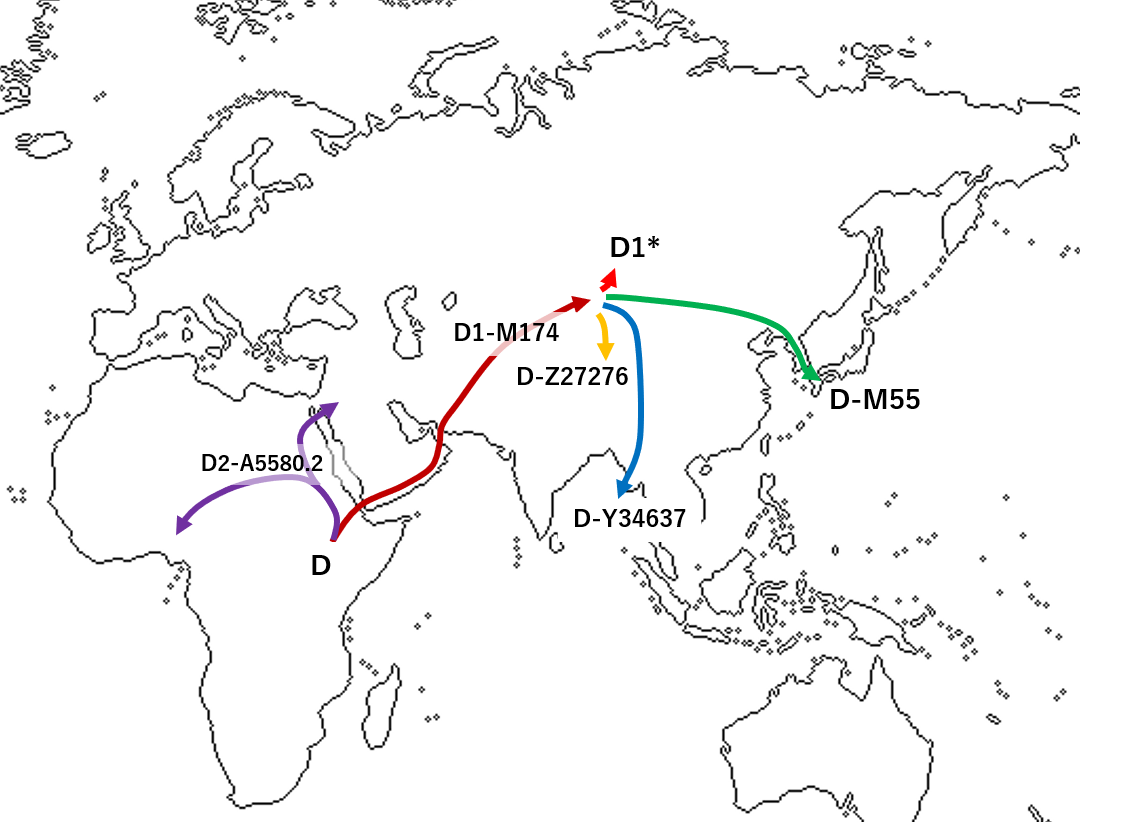
_migration.png){kind=link}
Y-E
「ハプログループEの分布」をご覧ください。
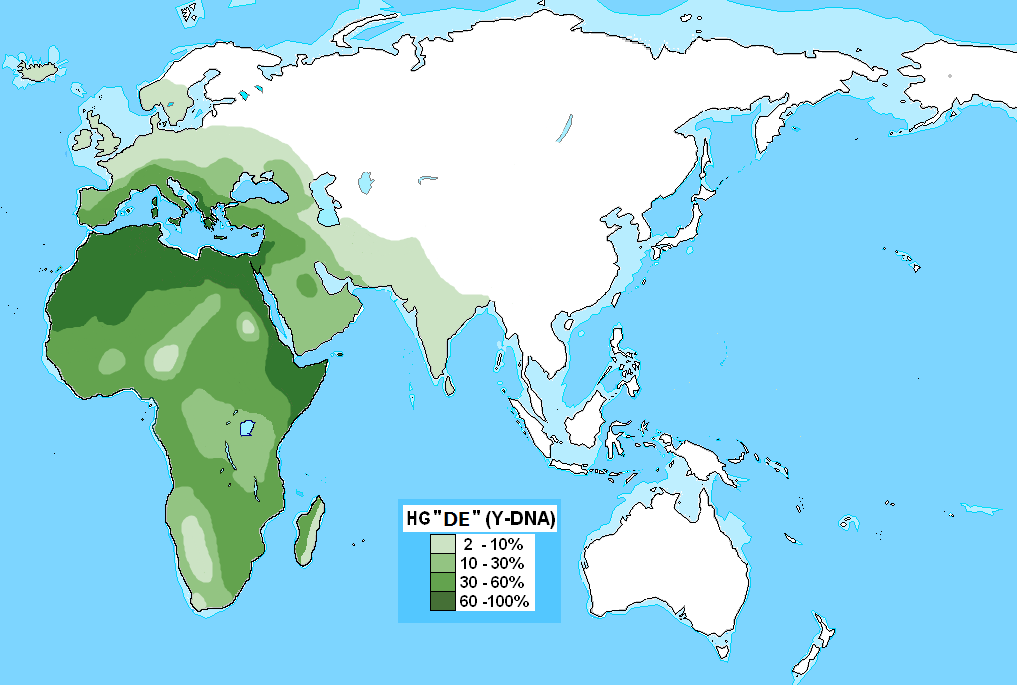
.png){kind=link}
E1b1a:ニジェール・コンゴ語族
「ハプログループE1b1aの分布」です。Wikipedia フランス語版 にありました。
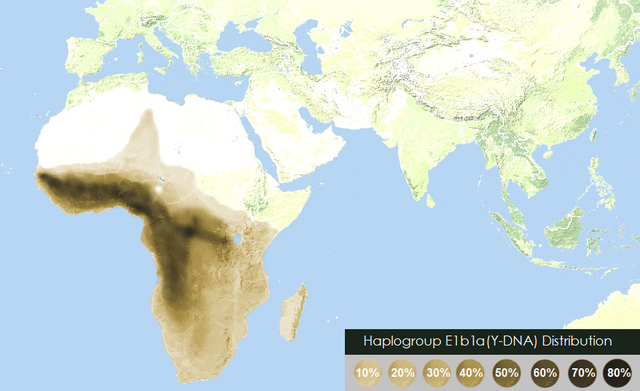
{kind=link}
E1b1b:アフロ・アジア語族
「ハプログループE1b1bの分布」です。Wikipedia フランス語版 より。
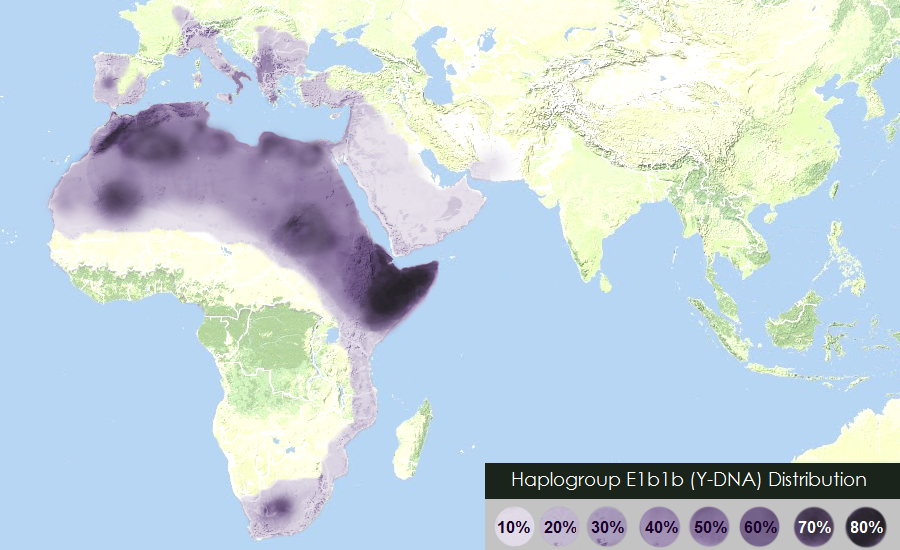
{kind=link}
Y-C
「ハプログループCの拡散経路」をご覧ください。(Wikipedia 日本語・英語版など より)
データは、崎谷満(2009)『DNA・考古・言語の学際研究が示す新・日本列島史 日本人集団・日本語の成立史』勉誠出版 に基づいているようです。
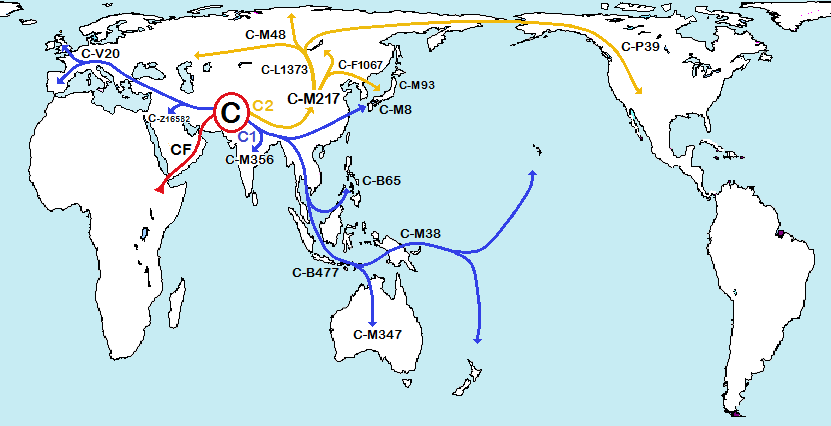
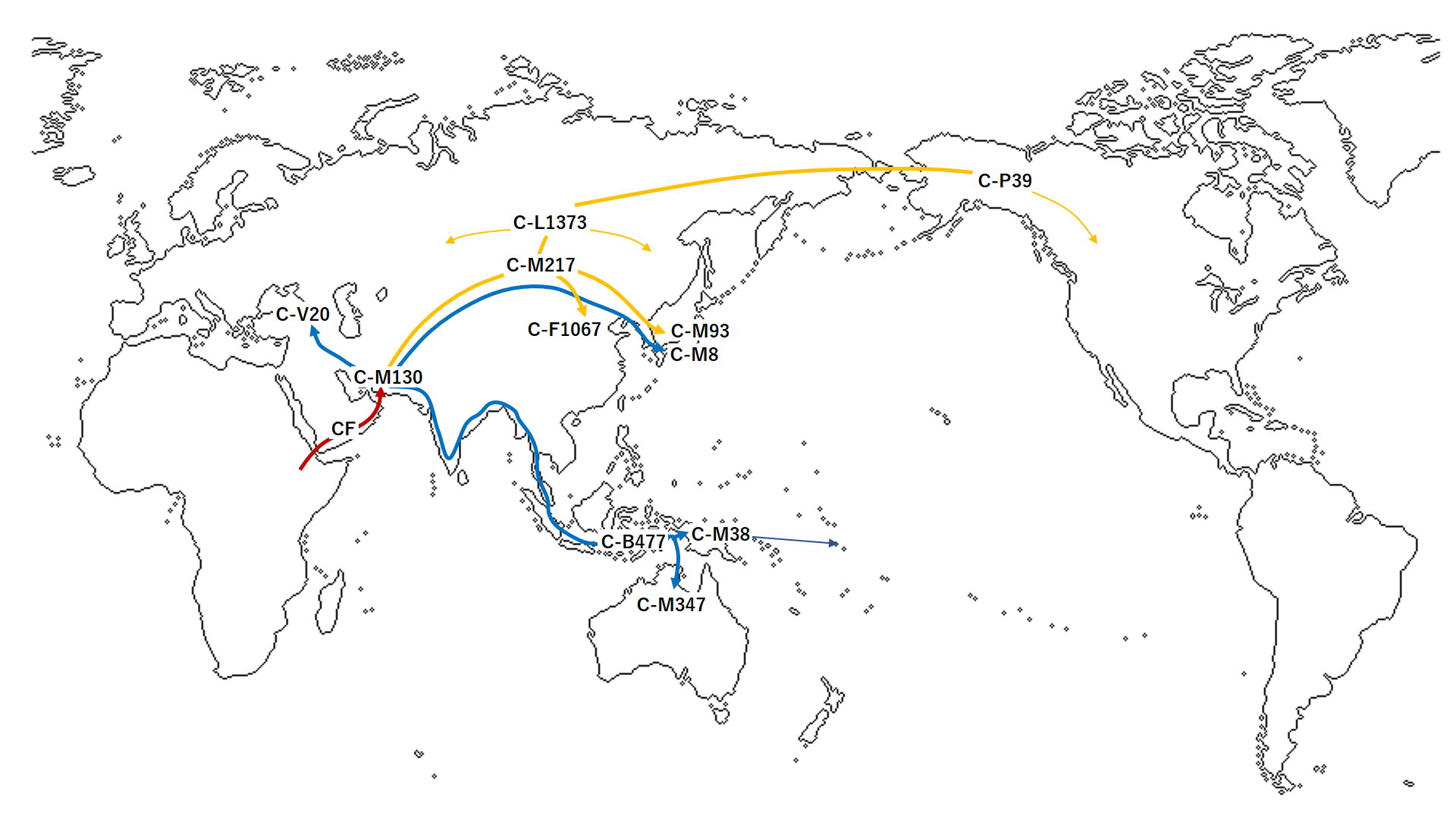 つづいて、「ハプログループCの起源と拡散経路」(2017年作成)をご覧ください。(Wikipedia スペイン語・ロシア語版 より)
つづいて、「ハプログループCの起源と拡散経路」(2017年作成)をご覧ください。(Wikipedia スペイン語・ロシア語版 より)
_migration.png){kind=link}
_2017.png){kind=link}
Wikipedia ロシア語版 には、「ハプログループCの東南アジアにおける拡散経路」(2013年作成)がありましたので掲載します。
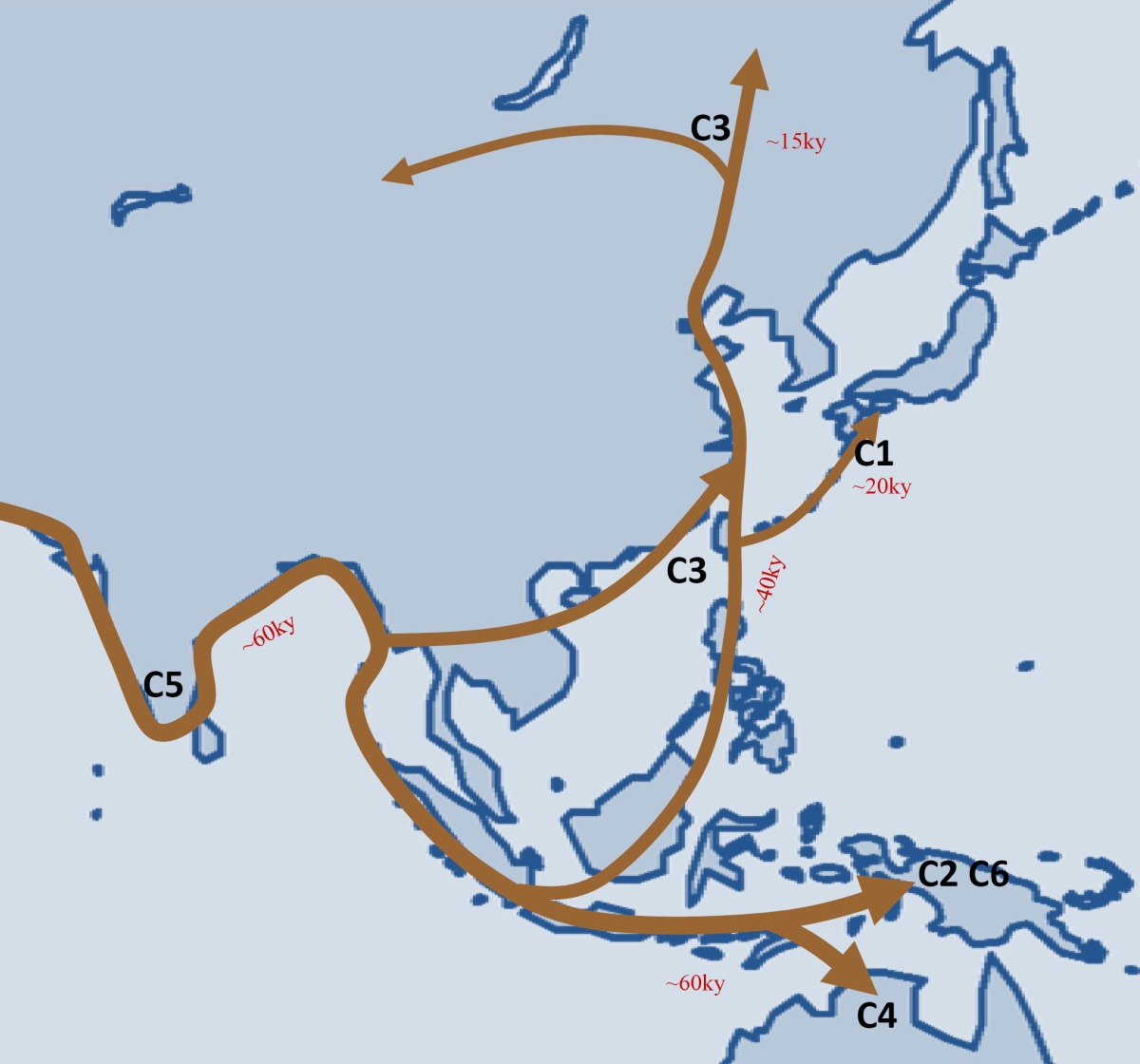
{kind=link}
C2(旧Y-C3):ツングース語族、モンゴル語族
「ハプログループC2の分布図」をご覧ください。
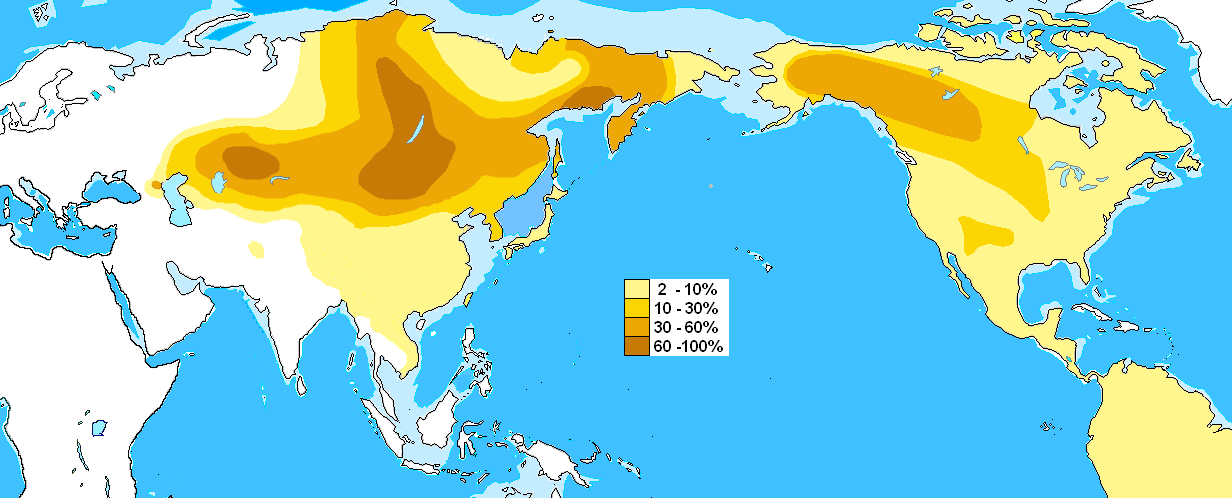
{kind=link}
Y-J
「ハプログループJの分布」をご覧ください。(Wikipedia ドイツ語版 より)
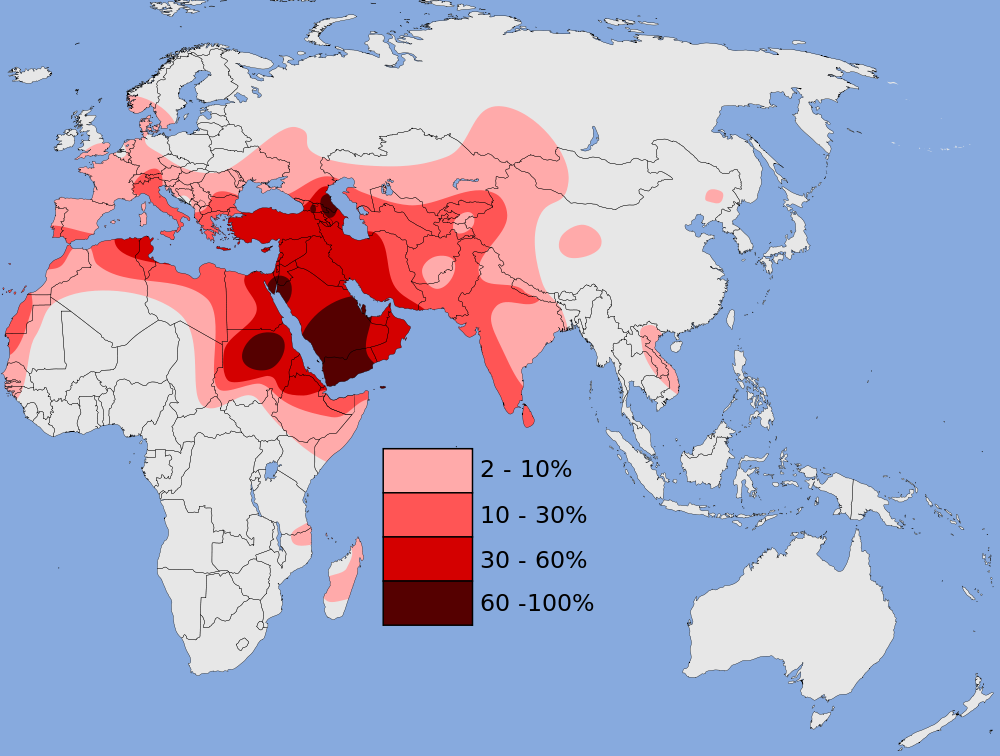
.svg){kind=link}
J1:アフロ・アジア語族>セム語派>アラビア語
「ハプログループJ1の分布」をご覧ください。(Wikipedia スペイン語版 より)
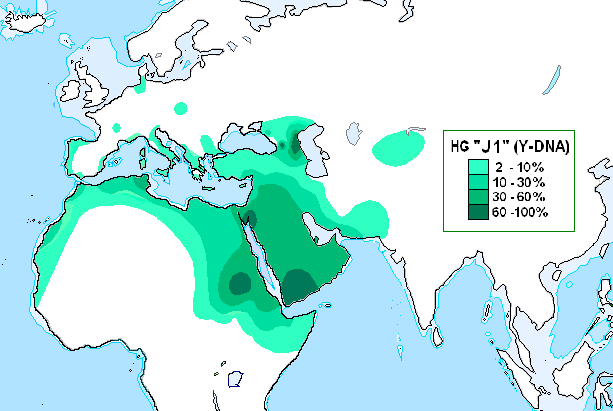
.PNG){kind=link}
参考まで、「ハプログループJ2の分布」も掲載します。(Wikipedia スペイン語版 より)
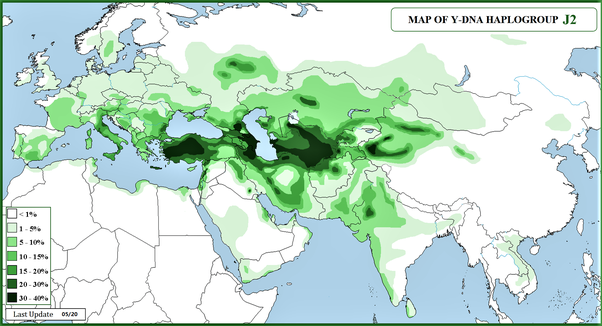
.png){kind=link}
Y-N:ウラル語族
「ハプログループNの分布」をご覧ください。
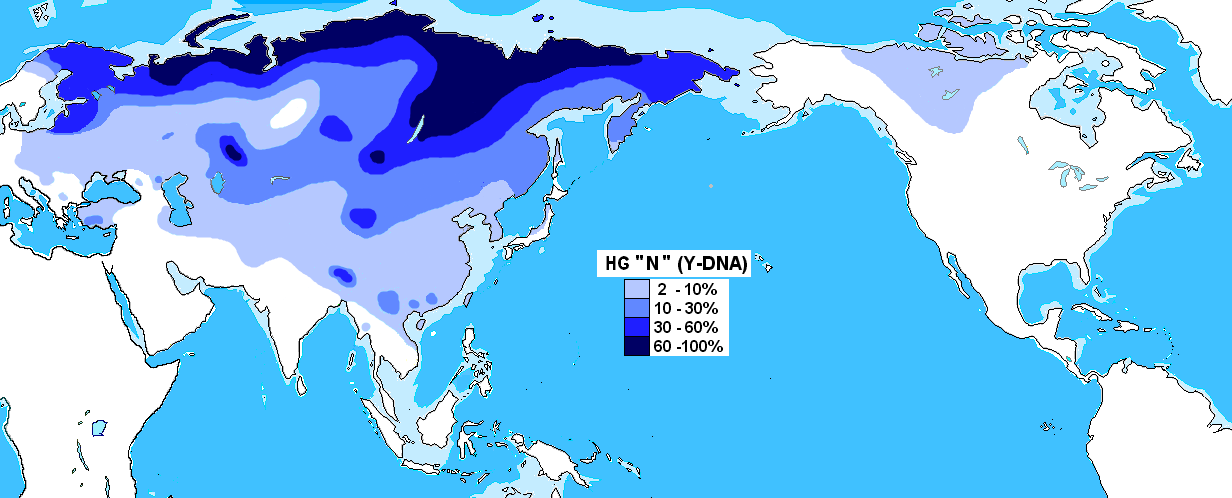
.PNG){kind=link}
つぎに、「ハプログループNの移動経路(青色)」(2017年作成)です。
データは、崎谷満(2009)『DNA・考古・言語の学際研究が示す新・日本列島史 日本人集団・日本語の成立史』勉誠出版 に拠るようです。
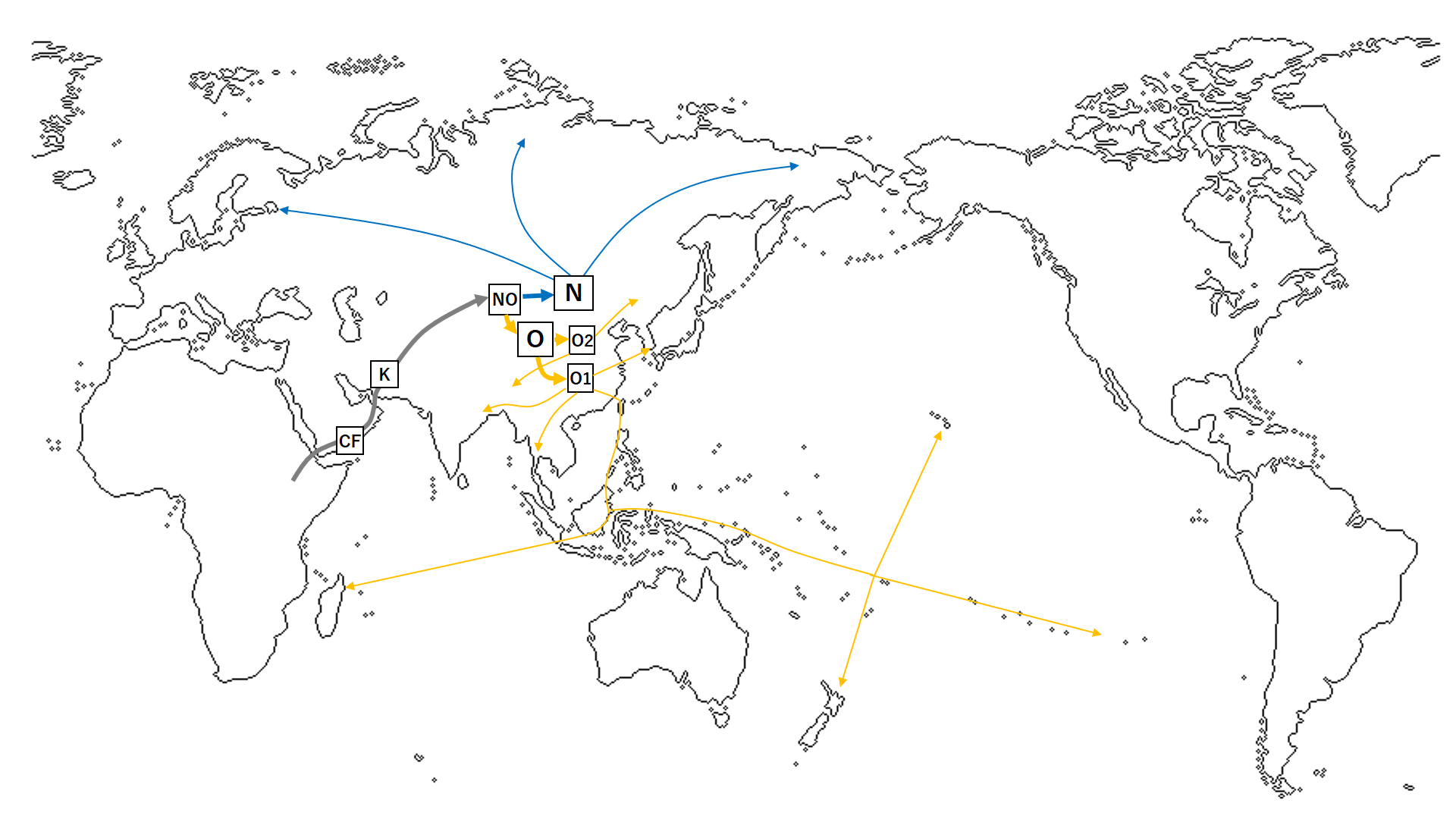 つづいて、「ハプログループN、Oに関連する東アジアの民族移動」(2017年作成)です。
つづいて、「ハプログループN、Oに関連する東アジアの民族移動」(2017年作成)です。
崎谷満『DNA・考古・言語の学際研究が示す新・日本列島史 日本人集団・日本語の成立史』(勉誠出版 2009年)その他の資料をもとに作成されたものです。
_migration.png){kind=link}
_in_East_Asia.png){kind=link}
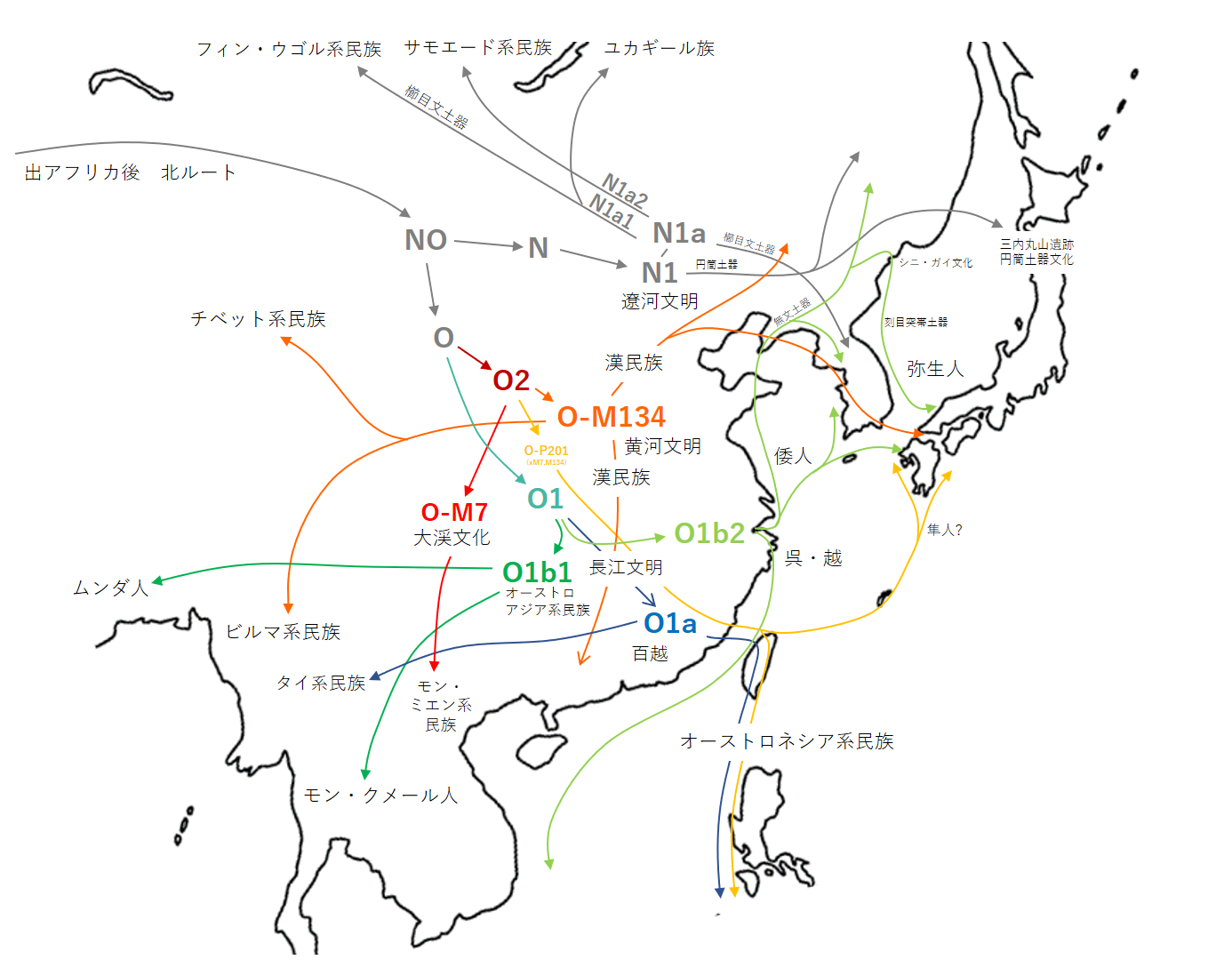
N1a1:フィン・ウゴル語派
N1a2:サモエード語派
Y-O
「ハプログループOの分布」です。
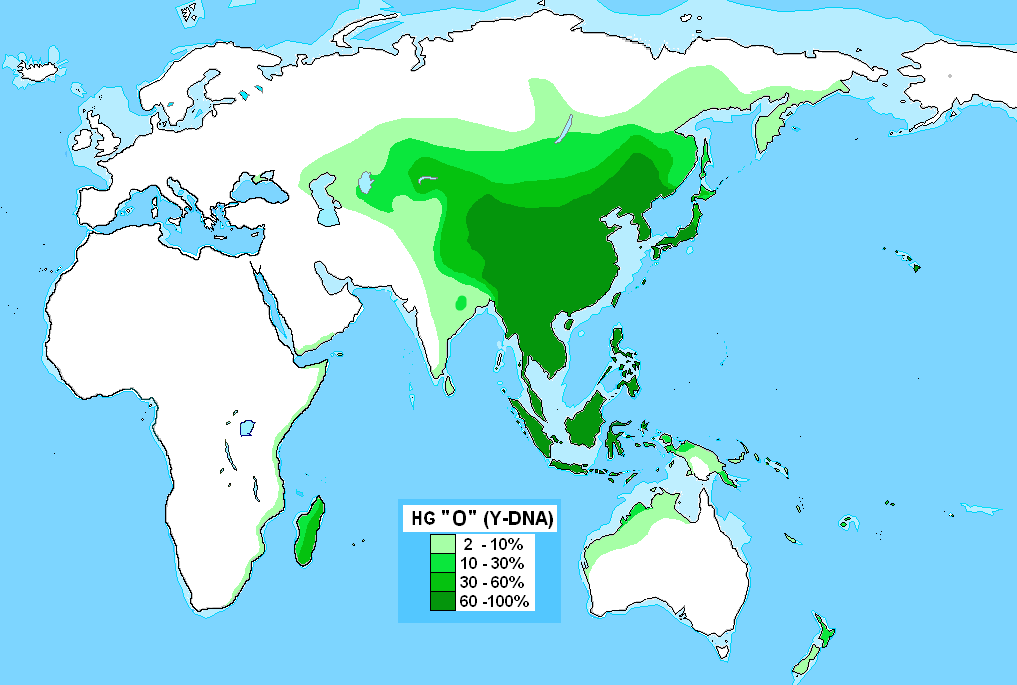
.PNG){kind=link}
O1a(旧Y-O1):オーストロネシア語族
O1b1(旧Y-O2a):オーストロアジア語族
O1b2(旧Y-O2b):弥生人の言語
「弥生人に連なる東アジアのY染色体ハプログループと民族移動」(2017年作成)を掲載します。
崎谷満『DNA・考古・言語の学際研究が示す新・日本列島史 日本人集団・日本語の成立史』(勉誠出版 2009年)などをもとに作成されています。
{kind=link}
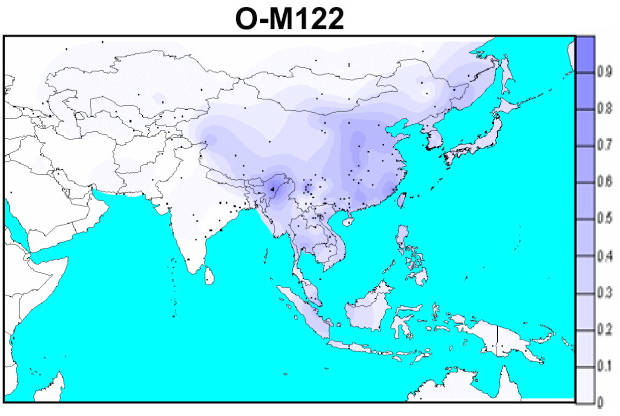
O2(旧Y-O3):シナ・チベット語族
「ハプログループO2-M122の分布」です。
{kind=link}
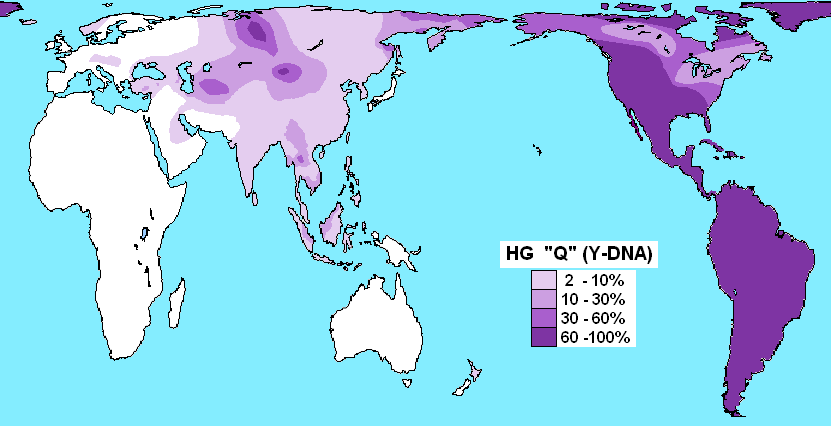
Y-Q:エニセイ語族、ナ・デネ語族、古代中国語
「ハプログループQの分布」をご覧ください。
.PNG){kind=link}
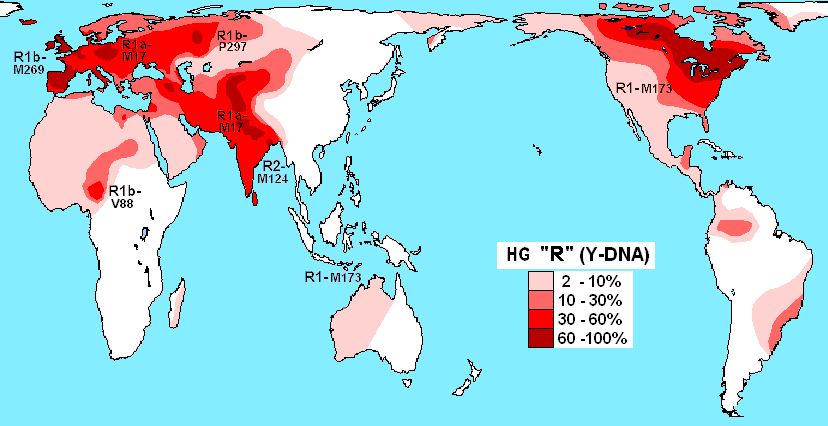
Y-R:印欧語族
「ハプログループRの分布」をご覧ください。
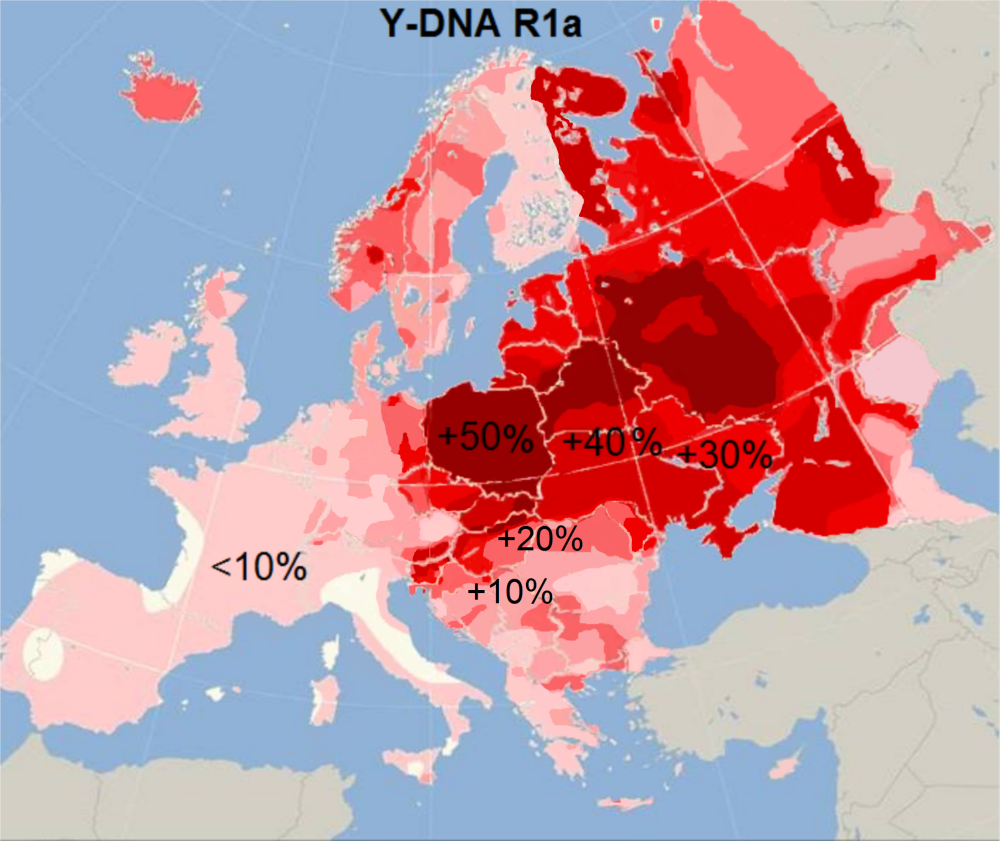
R1a:サテム語
「ヨーロッパにおけるハプログループR1aの分布頻度」をご覧ください。
{kind=link}
R1a の下位系統を、Wikipedia より引用します。
系統はY-DNA Haplogroup R and its Subclades – 2015による。関連言語、文化を付記する。
- R1a L146/M420/PF6229, L62/M513/PF6200, L63/M511/PF6203, L145/M449/PF6175
- R1a* –
- R1a1 M459/PF6235, L120/M516/PF6236, L122/M448/PF6237, Page65.2/PF6234/SRY1532.2/SRY10831.2
- R1a1* –
- R1a1a M512/PF6239, L168, L449/PF6223, M17, M198/PF6238, M514/PF6240, M515
- R1a1a* –
- R1a1a1 M417, Page7
- R1a1a1* –
- R1a1a1a CTS7083/L664/S298
- R1a1a1b S224/Z645, S441/Z647 縄目文土器文化
- R1a1a1b* –
- R1a1a1b1 PF6217/S339/Z283
- R1a1a1b2 F992/S202/Z93 インド・イラン語派 en:Sintashta culture
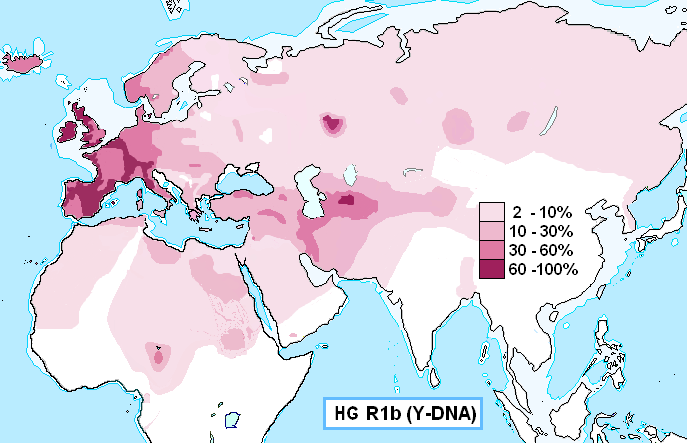
R1b:ケントゥム語
「ハプログループR1bの分布図」です。
.PNG){kind=link}
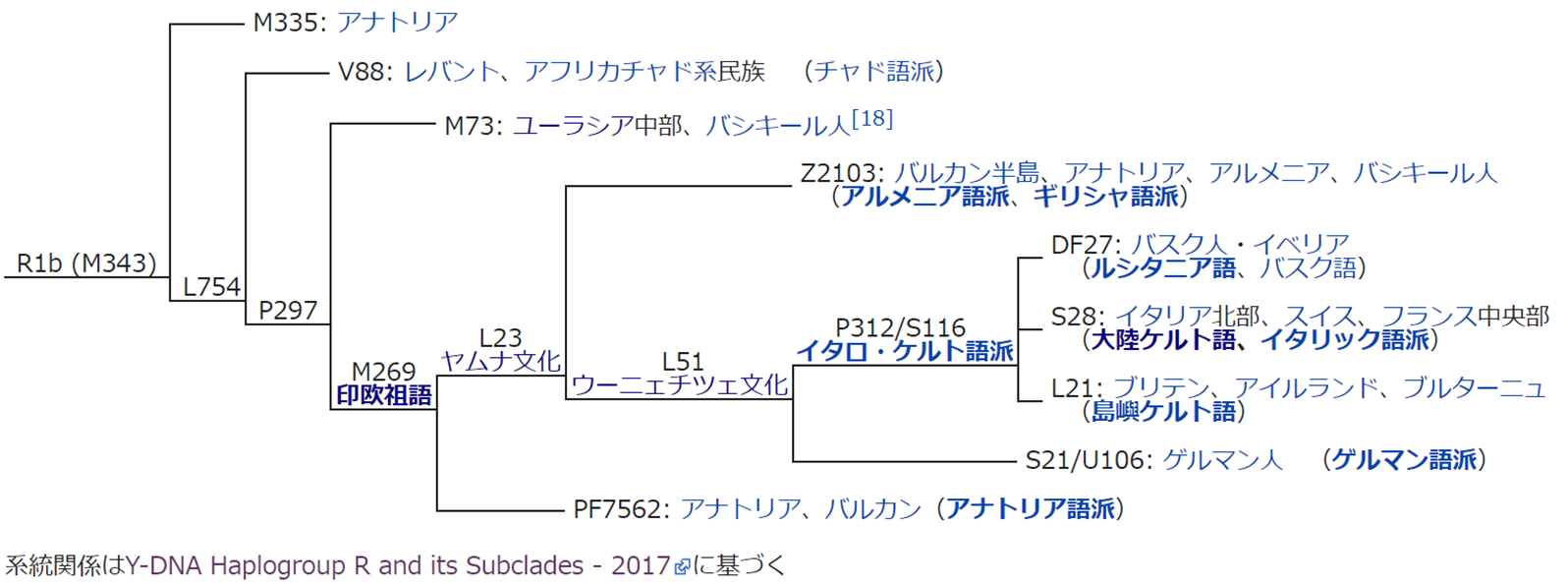
R1b の系統樹を、Wikipedia より転載します。
コメント
この記事へのコメントはありません。
トラックバック:thầu xây dựng
トラックバック:cty xây dựng
トラックバック:công ty xây dựng
トラックバック:xây dựng nhà ở
トラックバック:xây nhà trọn gói Đak nông
トラックバック:nha thau xay dung
トラックバック:kinh nghiệm xây nhà ống
トラックバック:công xây dựng nhà
トラックバック:mẫu thiết kế
トラックバック:công ty xây dựng dân dụng
トラックバック:xây dựng nhà trọn gói
トラックバック:nhà cấp 4
トラックバック:thiết kế nhà cấp 4
トラックバック:xây nhà trọn gói
トラックバック:kinh nghiệm xây biệt thự
トラックバック:thầu xây nhà trọn gói tại Dak Nông
トラックバック:sửa chữa nhà trọn gói
トラックバック:nhân công xây dựng
トラックバック:xây dựng nhà
トラックバック:công ty tư vấn thiết kế xây dựng
トラックバック:mẫu nhà cấp 4 mái thái
トラックバック:công ty thiết kế xây dựng
トラックバック:xây 1 trệt 1 lầu bao nhiêu tiền
トラックバック:الحصول على المزيد من المعلومات
トラックバック:lire plus d’informations
トラックバック:lees trending topic
トラックバック:suivez ces informations
トラックバック:এই বিনামূল্যে পড়ুন
トラックバック:obtenir plus de détails
トラックバック:最高のスロット
トラックバック:слот онлайн
トラックバック:ਵਧੀਆ ਸਲਾਟ
トラックバック:слотты қалай ұтады
トラックバック:слот тоглоомууд
トラックバック:খেলার স্লট
トラックバック:فتحة المال
トラックバック:슬롯 게임
トラックバック:бясплатны слот
トラックバック:સ્લોટ રમો
トラックバック:играйте слот
トラックバック:kinh nghiệm xây nhà
トラックバック:پول اسلات
トラックバック:슬롯 로그인
トラックバック:слот ойындары
トラックバック:슬롯 온라인
トラックバック:tiền đánh bạc
トラックバック:എങ്ങനെ വിജയം സ്ലോട്ട്
トラックバック:સ્લોટ ઓનલાઇન
トラックバック:اسلات بازی
トラックバック:khe miễn phí
トラックバック:বিনামূল্যে স্লট
トラックバック:รับข้อมูลเพิ่มเติม
トラックバック:có thêm thông tin
トラックバック:lire ceci gratuitement
トラックバック:Следите за этой информацией
トラックバック:ਇਸ ਜਾਣਕਾਰੀ ਦੀ ਪਾਲਣਾ ਕਰੋ
トラックバック:basahin ang karagdagang impormasyon
トラックバック:나를 열어
トラックバック:抓住我
トラックバック:ゲットミー
トラックバック:читать больше информации
トラックバック:люби меня
トラックバック:xây dựng giá rẻ
トラックバック:મને પ્રેમ કર
トラックバック:спаси ме
トラックバック:나를 따라와
トラックバック:读我
トラックバック:biết thêm chi tiết
トラックバック:като мен
トラックバック:спаси меня
トラックバック:اقرأ المزيد من المعلومات
トラックバック:私のような
トラックバック:Поймай меня
トラックバック:kinh nghiệm xây nhà cấp 4
トラックバック:sigue esta información
トラックバック:Открой меня
トラックバック:lire le sujet tendance
トラックバック:công ty xây nhà
トラックバック:나처럼
トラックバック:discuss
トラックバック:намайг авраач
トラックバック:阅读更多信息
トラックバック:나를 사랑해
トラックバック:تحبني
トラックバック:امسك بي
トラックバック:私を愛して
トラックバック:اتبعني
トラックバック:像我这样的
トラックバック:得到我
トラックバック:空きスロット
トラックバック:玩老虎机
トラックバック:слот пари
トラックバック:オンラインで無料のもの
トラックバック:ең жақсы слот
トラックバック:ұяшыққа кіру
トラックバック:انقذني
トラックバック:prendi questa roba online
トラックバック:scegli questo gratis online
トラックバック:trova questa roba gratis online
トラックバック:trucs gratuits en ligne
トラックバック:situs judi slot deposit pulsa 10rb tanpa potongan gayabet88
トラックバック:スロットゲーム
トラックバック:leia o tópico de tendência
トラックバック:finde diese kostenlosen Sachen online
トラックバック:trouver ce truc gratuit en ligne
トラックバック:гульнявыя грошы
トラックバック:ahha 4d
トラックバック:在线阅读
トラックバック:lawyer istanbul
トラックバック:網上免費的東西
トラックバック:スロットログイン
トラックバック:прочетете повече информация
トラックバック:在網上找到這個免費的東西
トラックバック:leia isso de graça
トラックバック:在线免费选择这个
トラックバック:elige esto gratis en línea
トラックバック:স্লট অনলাইন
トラックバック:무료 온라인 가입
トラックバック:grátis para se juntar online
トラックバック:weitere Informationen lesen
トラックバック:قراءة موضوع شائع
トラックバック:lesen Sie dies kostenlos
トラックバック:이 정보를 따르십시오
トラックバック:volg deze informatie
トラックバック:打开我
トラックバック:pg slot RatuSlot777
トラックバック:coin master slot RatuSlot777
トラックバック:judi slot deposit pulsa BandarXL
トラックバック:كيف تربح الفتحة
トラックバック:thầu nhân công xây dựng
トラックバック:игровой автомат
トラックバック:прочетете това безплатно
トラックバック:tư vấn xây dựng nhà
トラックバック:Lees verder
トラックバック:thi công xây nhà
トラックバック:날 읽어줘
トラックバック:vind deze gratis dingen online
トラックバック:obtenir ce truc en ligne
トラックバック:lese das kostenlos
トラックバック:apportez ceci gratuitement en ligne
トラックバック:deposit pulsa tanpa potongan slot CikaSlotGacorDepositDana
トラックバック:thiết kế nhà cấp 4 mái thái
トラックバック:स्लॉट ऑनलाइन
トラックバック:فتحة تسجيل الدخول
トラックバック:স্লট গেম
トラックバック:如何赢得老虎机
トラックバック:કેવી રીતે સ્લોટ જીતી
トラックバック:スロットを再生します
トラックバック:բնիկ մուտք
トラックバック:слот игри
トラックバック:ਸਲਾਟ ਲਾਗਇਨ
トラックバック:гуляць у слот
トラックバック:ਇਸ ਮੁਫਤ ਸਮੱਗਰੀ ਨੂੰ ਔਨਲਾਈਨ ਲੱਭੋ
トラックバック:se procurer plus d’information
トラックバック:buy power likes for instagram
トラックバック:প্রবণতা বিষয় পড়ুন
トラックバック:bu bilgiyi takip et
トラックバック:स्लॉट कैसे जीतें
トラックバック:continuer la lecture
トラックバック:if you like and unlike a picture on instagram
トラックバック:безплатен слот
トラックバック:स्लॉट मनी
トラックバック:नि: शुल्क स्लॉट
トラックバック:прочетете актуална тема
トラックバック:дэлгэрэнгүй мэдээлэл авах
トラックバック:この情報に従ってください
トラックバック:makakuha ng karagdagang detalye
トラックバック:https://www.youtube.com/redirect?q=trendingsimple.com&gl=MK
トラックバック:อ่านต่อไป
トラックバック:اقرأ هذا مجانًا
トラックバック:Puffco Peak
トラックバック:nastavi čitati
トラックバック:източник на информация
トラックバック:더 많은 정보를 읽어보세요
トラックバック:daha fazla bilgi al
トラックバック:følge disse oplysninger
トラックバック:encontre isso on-line
トラックバック:saznajte više detalja
トラックバック:прачытаць больш інфармацыі
トラックバック:获取更多信息
トラックバック:자세히 알아보기
トラックバック:थप जानकारी पढ्नुहोस्
トラックバック:अधिक जानकारी पढ़ें
トラックバック:lees meer details
トラックバック:Weiterlesen
トラックバック:сачыце за гэтым у Інтэрнэце
トラックバック:få flere detaljer
トラックバック:krijg dit spul online
トラックバック:ابحث عن هذه الأشياء المجانية عبر الإنترنت
トラックバック:çevrimiçi katılmak için ücretsiz
トラックバック:theo dõi trực tuyến này
トラックバック:bunu ücretsiz çevrimiçi hale getir
トラックバック:leggi questo gratis
トラックバック:bu ücretsiz çevrimiçi seç
トラックバック:bu şeyleri internetten al
トラックバック:kostenlos online beitreten
トラックバック:đọc cái này trực tuyến
トラックバック:الحصول على هذه الأشياء على الإنترنت
トラックバック:miễn phí tham gia trực tuyến
トラックバック:bu ücretsiz şeyleri çevrimiçi bul
トラックバック:breng dit gratis online
トラックバック:이 무료 온라인 가져오기
トラックバック:choisissez ceci gratuitement en ligne
トラックバック:đọc cái này miễn phí
トラックバック:kies dit gratis online
トラックバック:tải nội dung này trực tuyến
トラックバック:اتبع هذا على الإنترنت
トラックバック:أشياء مجانية على الإنترنت
トラックバック:이 무료 물건을 온라인에서 찾으십시오
トラックバック:volg dit online
トラックバック:اقرأ هذا على الإنترنت
トラックバック:folge dem online
トラックバック:قم بإحضار هذا مجانًا عبر الإنترنت
トラックバック:kostenlose Sachen online
トラックバック:wähle das kostenlos online aus
トラックバック:lies das online
トラックバック:이 무료 온라인 선택
トラックバック:이것을 온라인으로 읽으십시오
トラックバック:bring das kostenlos online
トラックバック:Holen Sie sich das Zeug online
トラックバック:tìm nội dung miễn phí này trực tuyến
トラックバック:이것을 무료로 읽으십시오
トラックバック:suivez ceci en ligne
トラックバック:bunu çevrimiçi takip et
トラックバック:portalo online gratis
トラックバック:トレンドトピックを読む
トラックバック:مجاني للانضمام عبر الإنترنت
トラックバック:gratis om online mee te doen
トラックバック:আমাকে খুলুন
トラックバック:продолжить чтение
トラックバック:lees dit gratis
トラックバック:jasa seo instagram
トラックバック:дістань мене
トラックバック:jasa view 4000 jam youtube
トラックバック:यह सामान ऑनलाइन प्राप्त करें
トラックバック:यह सामान ऑनलाइन चुनें
トラックバック:jasa view youtube
トラックバック:jual view youtube
トラックバック:beli jam tayang youtube
トラックバック:beli backlink
トラックバック:jasa seo judi
トラックバック:beli 4000 jam tayang
トラックバック:jual jam tayang youtube
トラックバック:온라인에서 이 물건을 찾으세요
トラックバック:beli impressions instagram
トラックバック:jasa seo
トラックバック:jasa subscriber youtube
トラックバック:Врятуй мене
トラックバック:pragmatic play
トラックバック:WismaBet
トラックバック:slot deposit pulsa tanpa potongan
トラックバック:bola99 slot
トラックバック:Daftar Slot
トラックバック:намайг хайрла
トラックバック:daftar slot online
トラックバック:judi slot
トラックバック:arya slot
トラックバック:Αγάπα με
トラックバック:Kelas 4D
トラックバック:beli stream spotify
トラックバック:Wisma338.com
トラックバック:leggilo online
トラックバック:slot deposit pulsa WismaBet
トラックバック:beli like tiktok pake pulsa
トラックバック:jual listener spotify
トラックバック:beli followers pinterest
トラックバック:resiko beli followers tiktok
トラックバック:rtp slot tertinggi hari ini
トラックバック:bocoran rtp slot hoki99
トラックバック:сачыце за гэтай інфармацыяй
トラックバック:rtp hoki99 slot
トラックバック:beli followers spotify
トラックバック:slot depo pulsa WismaBet
トラックバック:beli viewers tiktok murah
トラックバック:Hoki99 login
トラックバック:slot joker WismaBet
トラックバック:крыніца інфармацыі
トラックバック:slot joker deposit pulsa 5000 tanpa potongan WismaBet
トラックバック:togel 178 login
トラックバック:togel178 link alternatif
トラックバック:Jasa Backlink Authority
トラックバック:Jasa Backlink Murah
トラックバック:Jasa followers instagram
トラックバック:jual followers instagram murah
トラックバック:Jasa Backlink PBN
トラックバック:beli like instagram permanen
トラックバック:seo slot
トラックバック:jual follower instagram tertarget
トラックバック:jasa 4000 jam tayang
トラックバック:ahli seo judi
トラックバック:jasa follower tiktok
トラックバック:situs judi bola terpercaya
トラックバック:demo slot pragmatic maxwin
トラックバック:diigo.com/0d3gm6
トラックバック:situs slot gacor 2022 terbaru
トラックバック:www.evernote.com/shard/s535/sh/e9119433-6c34-4814-80e7-f950368d27a2/798cb87800c850849d989c87b53f547f
トラックバック:www.linkedin.com/feed/update/urn:li:activity:6457430107287060480/
トラックバック:pin.it/tzv7zlgiwj6jvz
トラックバック:beli viewers youtube
トラックバック:ccm.net/profile/user/jumpweasel54
トラックバック:qa.pandora-2.com/index.php?qa=user&qa_1=baitfather9
トラックバック:repo.getmonero.org/pushfather7
トラックバック:intensedebate.com/people/newscoat92
トラックバック:Maglia Norway Mondiali 2022
トラックバック:Twicsy
トラックバック:https://twicsy.com/es
トラックバック:twicsy.com
トラックバック:https://twicsy.com/id/beli-pengikut-instagram
トラックバック:https://twicsy.com/tr/instagram-begeni-satin-al
トラックバック:https://twicsy.com/ar/buy-instagram-followers
トラックバック:https://twicsy.com/uk/kupuyte-pidpysnykiv-v-instagram
トラックバック:Instagram
トラックバック:https://twicsy.com/it/acquista-likes-instagram
トラックバック:https://twicsy.com/pt
トラックバック:https://twicsy.com/ko
トラックバック:https://twicsy.com/nl
トラックバック:https://twicsy.com/it/acquista-follower-instagram
トラックバック:https://twicsy.com
トラックバック:https://twicsy.com/nl/instagram-followers-kopen
トラックバック:https://twicsy.com/de
トラックバック:https://twicsy.com/no/kjop-instagram-folgere
トラックバック:https://twicsy.com/fr/acheter-instagram-likes
トラックバック:https://twicsy.com/ko/buy-instagram-followers
トラックバック:joki view youtube
トラックバック:https://twicsy.com/buy-instagram-followers
トラックバック:https://twicsy.com/tl/buy-instagram-followers
トラックバック:https://twicsy.com/tl/buy-instagram-likes
トラックバック:https://twicsy.com/id/beli-like-instagram
トラックバック:toto88 win
トラックバック:Bagaimana sistem view di YouTube
トラックバック:jasa views youtube
トラックバック:Bagaimana perhitungan view di youtube
トラックバック:royal toto88
トラックバック:beli viewers youtube murah
トラックバック:toto 88 casino
トラックバック:https://twicsy.com/nl/instagram-likes-kopen
トラックバック:Apakah Jasaview Aman
トラックバック:kriper.net/user/cicadacup2/
トラックバック:मुझे पकड़ो
トラックバック:spbo asia
トラックバック:agen slot pragmatic play
トラックバック:mattress
トラックバック:heated mattress pad
トラックバック:mattress pad
トラックバック:Jasa Backlink Profile
トラックバック:seuraa näitä tietoja
トラックバック:https://gothammag.com/buy-tiktok-followers
トラックバック:Quick Fix New Orleans
トラックバック:jasa marketing judi
トラックバック:атрымаць больш інфармацыі
トラックバック:получите повече информация
トラックバック:читать подробнее
トラックバック:toto 88 togel
トラックバック:toto88slot login
トラックバック:toto88 rtp
トラックバック:знайсці гэта ў Інтэрнэце
トラックバック:wismaplay
トラックバック:toto88 live
トラックバック:apk toto88
トラックバック:rogslot link alternatif
トラックバック:詳細を取得する
トラックバック:rtp gtc
トラックバック:toto88 dana
トラックバック:hoc legere online
トラックバック:get more detail
トラックバック:получить более подробную информацию
トラックバック:виберіть цей матеріал онлайн
トラックバック:над шиг
トラックバック:在網上找到這個東西 在线获取这些东西
トラックバック:このようなものをオンラインにする
トラックバック:lue tämä netistä
トラックバック:kratom
トラックバック:homepage
トラックバック:fish
トラックバック:fish care
トラックバック:免费阅读
トラックバック:これをオンラインで読む
トラックバック:このようなものをオンラインで見つける
トラックバック:더 많은 정보를 읽으십시오
トラックバック:تجد هذه الأشياء على الإنترنت
トラックバック:ücretsiz çevrimiçi şeyler
トラックバック:công cụ miễn phí trực tuyến
トラックバック:Saudi Arabien VM 2022 Landsholdstrøje
トラックバック:postupujte podle těchto informací
トラックバック:Fuente de información
トラックバック:ойын ұясы
トラックバック:finde disse ting på nettet
トラックバック:ottenere maggiori informazioni
トラックバック:kies dit spul online
トラックバック:pg slot
トラックバック:jam gacor slot
トラックバック:sigue estas cosas en línea
トラックバック:dewa89 slot
トラックバック:slot 4d deposit pulsa tanpa potongan
トラックバック:situs judi slot gacor
トラックバック:үүнийг үнэгүй унш
トラックバック:coisas grátis online
トラックバック:leggi maggiori informazioni
トラックバック:Lieb mich
トラックバック:seuraa minua
トラックバック:w3 jitu toto login
トラックバック:Login Ahha4d
トラックバック:jitukita slot
トラックバック:vegas jitutoto
トラックバック:jitu toto login
トラックバック:akun toto jitu
トラックバック:jituangka toto login wap
トラックバック:bocoran ahha4d
トラックバック:legenda buaya apk tembak ikan
トラックバック:cholemellowlunchroom.e
トラックバック:rtp live
トラックバック:bocoran slot gacor hari ini
トラックバック:slot gacor deposit pulsa tanpa potongan
トラックバック:game slot deposit pulsa 10rb tanpa potongan
トラックバック:pročitajte više detalja
トラックバック:přečtěte si tyto věci online
トラックバック:gacor slot
トラックバック:situs judi slot terbaik dan terpercaya no 1
トラックバック:segui questo in linea
トラックバック:situs slot deposit pulsa tanpa potongan
トラックバック:få flere oplysninger
トラックバック:bursa judi bola
トラックバック:dunia slot 77
トラックバック:togel hari ini hongkong
トラックバック:leggi questo in linea
トラックバック:احصل على مزيد من التفاصيل
トラックバック:dunia 777 slot gacor
トラックバック:slot gacor malam ini
トラックバック:judi bola resmi
トラックバック:soundcloud downloader chrome extension
トラックバック:Ahha4d Login
トラックバック:slot pulsa tanpa potongan
トラックバック:Ahha4d
トラックバック:{Link Login Alternatif Ahha4d}
トラックバック:Ahha4d Link Login Alternatif
トラックバック:demo slot anti lag
トラックバック:info slot gacor hari ini
トラックバック:Ahha4d Link Alternatif
トラックバック:Ahha4d Login Link Alternatif
トラックバック:to buy instagram followers
トラックバック:buy tiktok followers scotland
トラックバック:безплатни неща онлайн
トラックバック:twicsy review
トラックバック:slot demo pragmatic play
トラックバック:безплатно за присъединяване
トラックバック:situs judi bola resmi di indonesia
トラックバック:accutane 5mg
トラックバック:slot rtp tertinggi hari ini
トラックバック:slot demo gratis pragmatic play no deposit
トラックバック:informatiebron
トラックバック:buy monthly instagram followers
トラックバック:jasa seo judi online
トラックバック:buy instagram real followers cheap
トラックバック:beli viewer youtube
トラックバック:{Link Alternatif Ahha4d}
トラックバック:instagram likes 25
トラックバック:jasa profile backlink
トラックバック:giúp tôi
トラックバック:{Link Ahha4d}
トラックバック:jasa seo website judi
トラックバック:jasa backlink premium
トラックバック:jasa backlink natural
トラックバック:http://bbs.1001860.com/home.php?mod=space&uid=1102226
トラックバック:http://www.aipeople.com.cn/home.php?mod=space&uid=2429409
トラックバック:jasa backlink gsa
トラックバック:jasa pbn judi
トラックバック:plaquenil 200mg price
トラックバック:how to buy tiktok followers reddit
トラックバック:seo backlink profile
トラックバック:pbn judi
トラックバック:beli view youtube
トラックバック:lexoni këto gjëra në internet
トラックバック:nepřetržité čtení
トラックバック:jasa like youtube
トラックバック:Google-Trends weltweit
トラックバック:buy instagram followers uk
トラックバック:Інданезійскія трэндавыя тэмы сёння
トラックバック:trending topic instagram hoje
トラックバック:толығырақ мәліметтер алыңыз
トラックバック:Die Teilnahme ist kostenlos
トラックバック:gratis spullen online
トラックバック:slot gacor 338
トラックバック:kilat 138
トラックバック:omnirank
トラックバック:jasa seo jakarta
トラックバック:slot gacor pola zeus maxwin
トラックバック:Wisma bet login judi slot
トラックバック:belajar seo
トラックバック:depo 10 bonus 15k slot mpo
トラックバック:kelas4d
トラックバック:atrodiet šīs lietas tiešsaistē
トラックバック:ਇੰਟਰਨੈੱਟ ‘ਤੇ ਪ੍ਰਚਲਿਤ ਖ਼ਬਰਾਂ
トラックバック:موضوع شائع instagram اليوم
トラックバック:برترین جستجوهای گوگل امروز
トラックバック:wismabet slot
トラックバック:Gila 4D
トラックバック:olympus zeus slot
トラックバック:petir zeus slot
トラックバック:keluaran semua togel hari ini
トラックバック:slot bola 338
トラックバック:kebunslot
トラックバック:pusat4d
トラックバック:jackpot 338slot
トラックバック:buyspin123
トラックバック:alfabet slot freebet
トラックバック:KebunToto
トラックバック:slot zeus gacor
トラックバック:slot zeus olympus
トラックバック:trouver ce truc en ligne
トラックバック:slot demo zeus
トラックバック:jackpot slot zeus
トラックバック:{link slot zeus}
トラックバック:raja zeus slot
トラックバック:бесперапыннае чытанне
トラックバック:επιλέξτε αυτό το υλικό στο διαδίκτυο
トラックバック:slot zeus
トラックバック:Која е темата во тренд на социјалните мрежи?
トラックバック:pročitajte ovo na mreži
トラックバック:zeus 8m
トラックバック:গুগল ট্রেন্ডস ইউটিউব
トラックバック:trending ngayon
トラックバック:přečtěte si další podrobnosti
トラックバック:sada u trendu
トラックバック:nabavite ove stvari na mreži
トラックバック:在線關注這個東西
トラックバック:Өнөөдөр Индонезийн тренд болсон твиттер
トラックバック:jaunākās ziņas šodien
トラックバック:horúce google trendy
トラックバック:प्रचलित विषयहरू पढ्नुहोस्
トラックバック:urutan game god of war
トラックバック:388hero link alternatif
トラックバック:citeste mai multe informatii
トラックバック:slot kakek zeus
トラックバック:bästa Google-sökningarna idag
トラックバック:горячие тренды гугла
トラックバック:pw togel
トラックバック:најдете го ова на интернет
トラックバック:ahha4d slot login
トラックバック:thehopegg.blogspot.com
トラックバック:zeus slot
トラックバック:zeus slot online
トラックバック:zeus8m
トラックバック:bandarxl
トラックバック:dewa zeus slot
トラックバック:zeus olympus slot
トラックバック:erigo4d
トラックバック:citeste asta online
トラックバック:top 10 Google-zoekopdrachten
トラックバック:verdens nyheder
トラックバック:これをオンラインで読んでください
トラックバック:световни новини
トラックバック:এই সপ্তাহের প্রবণতা বিষয়
トラックバック:Што ў трэндзе ў Інданезіі?
トラックバック:апошнія навіны сёння
トラックバック:He aha nā kumuhana o kēia manawa?
トラックバック:загалоўкі апошніх навін сёння
トラックバック:accutane pill 39 mg
トラックバック:इस सामग्री को ऑनलाइन पढ़ें
トラックバック:nā poʻomanaʻo nūhou
トラックバック:Aké sú aktuálne trendy?
トラックバック:lexoni tema në trend
トラックバック:10 principais pesquisas do Google
トラックバック:عمليات البحث الشائعة اليوم
トラックバック:follow this information
トラックバック:trendovske vijesti u svijetu
トラックバック:titulares de noticias de última hora hoy
トラックバック:dernières nouvelles près de chez moi
トラックバック:brydende nyhedsoverskrifter
トラックバック:ਅੱਜ ਦੀ ਤਾਜ਼ਾ ਖਬਰ
トラックバック:blog link
トラックバック:lettura continua
トラックバック:nā kumuhana i kēia manawa
トラックバック:bbc světové zprávy
トラックバック:Какво е тенденцията в Индонезия?
トラックバック:nouvelles tendances
トラックバック:нийтлэлийн эх сурвалж
トラックバック:kövesse ezt online
トラックバック:হট গুগল প্রবণতা
トラックバック:Was sind die aktuellen Trendthemen?
トラックバック:google trending nieuws
トラックバック:togel malaysia siang
トラックバック:tendances google 2023
トラックバック:situs slot freebet tanpa deposit
トラックバック:heluhelu i kēia ma ka pūnaewele
トラックバック:cara download gates of olympus di android
トラックバック:Google Trends 2023
トラックバック:finden Sie dies online
トラックバック:google-дегі ең жақсы 10 іздеу
トラックバック:freebet 50rb tanpa deposit tanpa syarat
トラックバック:cialis vs sildenafil
トラックバック:google trendy novinky
トラックバック:388hero bonus
トラックバック:Aktuelle Trendthemen auf Twitter
トラックバック:Hvad er et populært emne på sociale medier?
トラックバック:bbc wereldnieuws
トラックバック:인도네시아에서 유행하는 것은 무엇입니까?
トラックバック:look at more info
トラックバック:таких
トラックバック:把這些東西帶到網上
トラックバック:ما هو موضوع شائع على وسائل التواصل الاجتماعي؟
トラックバック:такого типа
トラックバック:najnovije vijesti za danas
トラックバック:Indonesiske trendemner i dag
トラックバック:здесь
トラックバック:папулярныя тэмы на гэтым тыдні
トラックバック:актуална тема в Instagram днес
トラックバック:le 10 migliori ricerche su google
トラックバック:Интернеттегі тамаша заттар
トラックバック:gratis om mee te doen
トラックバック:Wisma bet login app
トラックバック:slot freebet tanpa depo
トラックバック:қосылу тегін
トラックバック:kakak slot
トラックバック:judi slot online jackpot terbesar
トラックバック:slot olympus zeus
トラックバック:slot server thailand super gacor
トラックバック:Holen Sie sich dieses Zeug online
トラックバック:tendencat e google youtube
トラックバック:الأخبار العاجلة اليوم
トラックバック:u trendu danas
トラックバック:skaffa mer information
トラックバック:Kas ir aktuāls temats sociālajos medijos?
トラックバック:Indonesisches Trend-Twitter heute
トラックバック:prenesite ove stvari na internet
トラックバック:zeus slot pragmatic
トラックバック:tiêu đề tin tức bbc hôm nay
トラックバック:요즘 유튜브에서 핫한 주제
トラックバック:wisma 338
トラックバック:få disse ting online
トラックバック:выбрать этот материал онлайн
トラックバック:mayorqq
トラックバック:έκτακτες ειδήσεις σήμερα
トラックバック:актуальна тема instagram сьогодні
トラックバック:heluhelu mau
トラックバック:buyspin
トラックバック:소셜 미디어에서 유행하는 주제는 무엇입니까?
トラックバック:mpo depo 10 bonus 15k slot
トラックバック:garuda138
トラックバック:さらに詳しい情報を得る
トラックバック:tin thịnh hành trên mạng
トラックバック:388hero login
トラックバック:Прочети ме
トラックバック:지금 추세
トラックバック:заголовки последних новостей
トラックバック:BBC világhírek
トラックバック:عناوین اخبار فوری امروز
トラックバック:オンラインでこれを選ぶ
トラックバック:usong balita sa internet
トラックバック:slot gacor hari ini
トラックバック:aktuální témata na youtube dnes
トラックバック:přečtěte si další informace
トラックバック:nouvelles tendances dans le monde
トラックバック:agen toto play
トラックバック:lexim i vazhdueshëm
トラックバック:ਗੂਗਲ ਟ੍ਰੈਂਡਿੰਗ ਖਬਰਾਂ
トラックバック:популярные новости
トラックバック:следвайте това онлайн
トラックバック:Was ist ein Trendthema in den sozialen Medien?
トラックバック:trova questo in rete
トラックバック:order meclizine online cheap
トラックバック:agen togel play
トラックバック:chủ đề thịnh hành instagram hôm nay
トラックバック:Một chủ đề xu hướng trên phương tiện truyền thông xã hội là gì?
トラックバック:энэ зүйлийг онлайнаар сонго
トラックバック:slot deposit qris 5000
トラックバック:rtp bisnis4d
トラックバック:Baik777
トラックバック:기사 출처
トラックバック:bonus88
トラックバック:wwd.com
トラックバック:Mga headline ng bbc news ngayon
トラックバック:актуални новини в интернет
トラックバック:Was ist in Indonesien im Trend?
トラックバック:jasa pbn
トラックバック:вземете тези неща онлайн
トラックバック:مصدر المعلومات
トラックバック:Koja je tema u trendu na društvenim mrežama?
トラックバック:διαβάστε αυτό δωρεάν
トラックバック:jasa backlink judi
トラックバック:Jaké je aktuální téma na sociálních sítích?
トラックバック:udarne vijesti u mojoj blizini
トラックバック:tendances google chaudes
トラックバック:google трендтері 2023
トラックバック:porn
トラックバック:グーグルトレンド、ユーチューブ
トラックバック:бұл заттарды желіге әкеліңіз
トラックバック:beli youtube views
トラックバック:чытаць гэты матэрыял у Інтэрнэце
トラックバック:porn
トラックバック:推特上今天的熱門話題
トラックバック:jasa backlink permanen
トラックバック:child porn
トラックバック:jasa promosi youtube
トラックバック:breaking news i nærheden af mig
トラックバック:porn
トラックバック:trending topics deze week
トラックバック:situs slot deposit qris
トラックバック:backlink pbn
トラックバック:крыніцы інфармацыі
トラックバック:beli viewers instagram
トラックバック:қосымша ақпаратты оқу
トラックバック:cara dapat petir merah olympus
トラックバック:beli youtube view
トラックバック:jual backlink
トラックバック:slot gacor gampang menang
トラックバック:인스타그램 오늘 화제 화제
トラックバック:jasa seo judi terpercaya
トラックバック:child porn
トラックバック:jual followers tiktok
トラックバック:szabad csatlakozni
トラックバック:siendo tendencia ahora
トラックバック:jasa backlink pyramid
トラックバック:папулярныя навіны ў інтэрнэце
トラックバック:jual backlink berkualitas
トラックバック:Bugün dünyada öne çıkan haberler
トラックバック:harga jasa seo
トラックバック:porn
トラックバック:child porn
トラックバック:trendikkäissä nyt twitterissä
トラックバック:CBS nouvelles en direct
トラックバック:nuus vandag
トラックバック:child porn
トラックバック:seo judi
トラックバック:jasa backlink judi online
トラックバック:актуални новини в света
トラックバック:Ко је број 1 у тренду на Гоогле-у?
トラックバック:Top 5 Sportnachrichten auf Englisch für die Schulversammlung
トラックバック:beli pbn
トラックバック:jasa seo murah bergaransi
トラックバック:jasa backlink pbn murah
トラックバック:jual jasa seo
トラックバック:jasa pbn murah
トラックバック:Trendnachrichten
トラックバック:папулярныя пошукавыя запыты сёння
トラックバック:sosyal medya etkileri ile ilgili haber makalesi
トラックバック:Trending nuus in die wêreld hierdie week
トラックバック:sosiale media vandag
トラックバック:youtube сёння папулярны ва ўсім свеце
トラックバック:Nangungunang 5 balita sa palakasan sa ingles para sa pagpupulong ng paaralan
トラックバック:popularna pretraživanja danas
トラックバック:trending nuus Indonesië
トラックバック:child porn
トラックバック:ʻO ka nūhou haʻuki ola i kēia lā
トラックバック:Google에서 인기 1위는 누구인가요?
トラックバック:Canlı xəbər axını pulsuz youtube
トラックバック:Wie staat momenteel op nummer 1 op YouTube?
トラックバック:жывыя навіны Фокс
トラックバック:Ким Google’да №1 трендде?
トラックバック:Jetzt im Trend: Google
トラックバック:trendovske vijesti na društvenim mrežama
トラックバック:http://Www.Zjxsnj.cn/comment/html/?27669.html
トラックバック:врвни трендовски вести на социјалните мрежи
トラックバック:tauPI.ORg
トラックバック:https://Rnma.Xyz/boinc/view_profile.php?Userid=1412057
トラックバック:международные спортивные новости сегодня
トラックバック:https://Nebenwelten.net/index.php?title=User:AlyceNona587
トラックバック:Top 5 sportskih vijesti na engleskom za školsku skupštinu
トラックバック:https://biowiki.clinomics.com/index.php/User:KennyEdman7611
トラックバック:http://Classicalmusicmp3freedownload.com/ja/index.php?title=:SusanaBojorquez
トラックバック:Wiki.freeneuropathology.org
トラックバック:Во тренд вести на интернет оваа недела
トラックバック:Bramptoneast.Org
トラックバック:please click the following post
トラックバック:Sky Sports futebol ao vivo
トラックバック:http://www.gedankengut.One/index.php?title=user:Rachelmbx73817
トラックバック:학교 조회를 위한 영어 상위 5개 스포츠 뉴스
トラックバック:Http://Www.Sxlopw.Cn
トラックバック:http://eldoradofus.free.fr/forum/profile.php?id=174374
トラックバック:https://Lnx.Argonband.it/web/modules.php?name=Forums&file=profile&mode=viewprofile&u=84080
トラックバック:wEAkfAntASy.De
トラックバック:https://nebenwelten.net/index.php?title=User:SerenaFolk671
トラックバック:https://wiki.Nerdbird.media/index.php?title=User:RosemarieSolano
トラックバック:forum.Inos.At
トラックバック:Leonblog.Net
トラックバック:https://wiki.sports-5.ch/index.php?title=Utilisateur:RosalinePollack
トラックバック:https://wiki.sports-5.ch/index.php?title=Utilisateur:LeandroGreenwald
トラックバック:trending op internet vandaag
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1422864
トラックバック:https://wiki.Nerdbird.media/index.php?title=Determinacin_Del_Origen_Y_Valoracin_Del_Dao_Corporal
トラックバック:noticias de actualidad en el mundo
トラックバック:just click the up coming page
トラックバック:https://Okniga.org/user/VinceKoertig857/
トラックバック:https://Okniga.org/user/MindaLyke6/
トラックバック:https://wiki.castaways.com/wiki/User:KazukoYagan37
トラックバック:click through the next website page
トラックバック:BgMCd.cO.uK
トラックバック:Www.vANDer-HoRST.nl
トラックバック:Successionwiki.Co.Uk
トラックバック:Wiki.sports-5.ch
トラックバック:https://Yoga.wiki/index.php?title=User:RachelO62157401
トラックバック:visit the following web page
トラックバック:https://wiki.tentere.net/index.php?title=:LolaGrosse806
トラックバック:gewilde nuus op Twitter
トラックバック:https://Wiki.tentere.net/index.php?title=Ecotrap_Fly_Guard:_Control_Ecolgico_De_Moscas_En_M_xico
トラックバック:https://forum.inos.at/profile.php?id=315571
トラックバック:click the following internet page
トラックバック:https://Pipewiki.org/app/index.php/Logistique_Transport_Par_Les_Voitures__Montr_al
トラックバック:live nyhedsræv
トラックバック:Gedankengut.one
トラックバック:maga.wiki
トラックバック:biowiki.ClInoMICS.com
トラックバック:Tin tức hot trên mạng xã hội tuần này
トラックバック:Https://Www.Vander-Horst.Nl/
トラックバック:https://Infodin.Com.br/
トラックバック:Saju.codeway.kr
トラックバック:Página de Internet Altamente recomendada
トラックバック:Pipewiki.org
トラックバック:just click the following website
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=319317
トラックバック:hvad der sker med sociale medier i dag
トラックバック:https://classifieds.ocala-news.com/author/evelynewein
トラックバック:Vacayphilippines.com
トラックバック:https://okniga.org/
トラックバック:https://www.vander-horst.nl/wiki/User:EvelynHardey5
トラックバック:KIng.Az
トラックバック:Yhet.fi
トラックバック:https://Pipewiki.org/app/index.php/User:NCZZoila96656
トラックバック:Classicalmusicmp3Freedownload.com
トラックバック:wwW.KEnpOGuY.COM
トラックバック:rnma.xyz
トラックバック:https://Biowiki.Clinomics.com/index.php/User:Chad11H781989
トラックバック:clique na seguinte página web
トラックバック:https://Rxlrealms.com/XTop/index.php?a=stats&u=katia37600486
トラックバック:英語のトップ 5 スポーツ ニュース
トラックバック:esta
トラックバック:simply click the next website
トラックバック:Outhistory.Wwu.edu
トラックバック:http://Theglobalfederation.org/profile.php?id=1984956
トラックバック:wiki.Hstkb.sch.id
トラックバック:https://Taupi.org/index.Php?title=User:KieraPalmquist7
トラックバック:https://Religiopedia.com/index.php/User:MarcLaster
トラックバック:www.security.sbm.pw
トラックバック:bbc xəbərləri
トラックバック:http://superstitionism.com/forum/profile.php?id=366848
トラックバック:sell
トラックバック:https://xdpascal.com/index.php/user:andreacrider639
トラックバック:https://demo.Centreon.com/wiki/index.php?title=User:CerysSpeed951
トラックバック:https://Demo.Centreon.com/
トラックバック:Https://Bgmcd.Co.Uk/Index.Php?Title=User:JadaLehner4023
トラックバック:https://Okniga.org/user/BebeStreeter5/
トラックバック:https://aproblemsquaredwiki.com/User:RandallMendoza
トラックバック:https://Aproblemsquaredwiki.com/User:BryantMaestas7
トラックバック:xdpascal.com
トラックバック:http://Seattlewomenmag.xyz/blogs/viewstory/26584
トラックバック:https://netcallvoip.com/wiki/index.php/User:EpifaniaCuellar
トラックバック:Https://www.vander-horst.nl
トラックバック:Wiki.gem-flash.com
トラックバック:http://Afcantarelle.org
トラックバック:click through the up coming internet page
トラックバック:https://Maga.wiki/index.php/User:MelissaKavanagh
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1424690
トラックバック:https://okniga.org/user/LeviBartels/
トラックバック:zjxsnj.cn
トラックバック:Ко је тренутно број 1 на ИоуТубе-у?
トラックバック:Live sportnieuws eredivisie
トラックバック:Aħbarijiet trending fuq l-internet din il-ġimgħa
トラックバック:wiki.Nerdbird.media
トラックバック:tin tức về internet hôm nay
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1411932
トラックバック:Afcantarelle.org
トラックバック:https://Zvukiknig.cc/user/Theodore51S/
トラックバック:http://Www.Bjkclh.com/comment/html/?187046.html
トラックバック:Www.Mafiascum.Net
トラックバック:Bjkclh.com
トラックバック:http://Www.die-Seite.com/index.php?a=stats&u=maricruzoms
トラックバック:https://Porscheforsale.org/author/isidrobouci/
トラックバック:topp 5 sportnyheter på engelska
トラックバック:https://taupi.org/index.php?title=User:BeatrizLoera525
トラックバック:provaforumsavoia1234.altervista.org
トラックバック:Click on Demo Centreon
トラックバック:https://Dublinohiousa.gov/
トラックバック:click the next website page
トラックバック:http://Www.Gotanproject.net/node/22354135?—————————4154877377168Content-Disposition:form-data;name=titleLapeinturepoxy:Unersolutionrsistanteetrobuste—————————4154877377168Content-Disposition:form-data;name=bodyLaahref=h
トラックバック:Nebenwelten.net
トラックバック:https://portal.virtueliving.org/profile_info.php?ID=32471
トラックバック:http://Cloud-Dev.Mthmn.com/node/179492
トラックバック:great post to read
トラックバック:http://afcantarelle.org/index.php?title=User:DorethaConnolly
トラックバック:Askreader.co.uk
トラックバック:mBsrE.cOm
トラックバック:YOGA.WIKi
トラックバック:Www.oaSiSKORea.NeT
トラックバック:http://Cloud-dev.mthmn.com/node/181410
トラックバック:Luennemann.org
トラックバック:Informação secreta
トラックバック:my company
トラックバック:http://Cloud-Dev.Mthmn.com/node/179473
トラックバック:http://cloud-dev.mthmn.com/node/181511
トラックバック:Top-Trendnachrichten in den sozialen Medien
トラックバック:http://saju.Codeway.kr/index.php/User:KaliKoerstz021
トラックバック:Dnešní trendy na internetu
トラックバック:http://www.gotanproject.net/node/22356431?—————————960416106151Content-Disposition:form-data;name=titlePrixD’uneToitureEn2022Bardeaux,lastomre,Tpo,EpdmEtPlus—————————960416106151Content-Disposition:form-data;name=bodyN
トラックバック:https://aproblemsquaredwiki.com/User:CliffRentoul730
トラックバック:please click the following website
トラックバック:http://Gijangchurch.org/index.php?mid=board_UvBh53&document_srl=163168
トラックバック:Https://Dimension-Gaming.Nl/Profile.Php?Id=46029
トラックバック:Xn–4Kqz9Dx34Awsd.Copytrade.website
トラックバック:http://cloud-dev.mthmn.com/node/180219
トラックバック:http://cloud-dev.mthmn.com/node/178324
トラックバック:Zvukiknig.cc
トラックバック:eldoradofus.free.fr
トラックバック:https://untoldjekyll.com/60085/joanna-maitre–quebec-paris
トラックバック:https://koloiko.com/wiki/index.php?title=User:RaulGreenwood7
トラックバック:Sanatandharam.in
トラックバック:Cloud-dev.mthmn.com
トラックバック:Dripwiki.com
トラックバック:Apeguebremariam.org
トラックバック:Trendy nyheter i verden i dag
トラックバック:Readukrainianbooks.Com
トラックバック:Www.sxlopw.cn
トラックバック:Incardio.Cuas.at
トラックバック:https://Yhet.fi/wiki/index.php/Nos_v_nementsdu_1_Sur_Le_5_Mai_2018
トラックバック:http://www.Driftpedia.com/wiki/index.php/Soins_De_Pieds__Domicile
トラックバック:Canamkart.Ca
トラックバック:www.offwiki.org
トラックバック:Www.fragrance.ipt.pw
トラックバック:Religiopedia.com
トラックバック:diAlOGOS.wIKi
トラックバック:https://Urduwiki.in
トラックバック:NoBElBOErsE.De
トラックバック:www.rEBeLsCON.COm
トラックバック:https://mmhsmassageme.com/index.php?page=user&action=pub_profile&id=5800623
トラックバック:https://napiri.com
トラックバック:PorscHEFORsALE.oRg
トラックバック:More Support
トラックバック:http://cloud-Dev.Mthmn.com/node/173542
トラックバック:Napiri.com
トラックバック:https://Www.vesti24.eu/user/profile/kluverna88/
トラックバック:Demo.Centreon.com
トラックバック:http://cloud-dev.mthmn.com/node/179476
トラックバック:www.traders.sblinks.net
トラックバック:http://Die-Seite.com/index.php?a=stats&u=dalenephelan6
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=323594
トラックバック:Sustainabilipedia.Org
トラックバック:nbc xəbərləri
トラックバック:WWW.reGister.Ipt.Pw
トラックバック:https://telugusaahityam.com/User:RoscoeLenz7136
トラックバック:Wiki.vie.today
トラックバック:https://dialogos.wiki/index.php/L_inspection_D_une_Vieille_Maison_:_10_Aspects__Surveiller
トラックバック:theglobalfederation.org
トラックバック:https://nebenwelten.net/index.php?title=Lancme_Perfume:_Elegance_And_Innovation_In_Every_Bottle
トラックバック:http://Xiamenyoga.com/comment/html/?235232.html
トラックバック:https://www.oasiskorea.net/Brand/3141874
トラックバック:Orlandowomenmag.xyz
トラックバック:https://apeguebremariam.org/community/?wpfs=&membersite=httpspiedconfort.combloguepied-arque&membersignature=span+stylefont-weight:+800;Les+orthses+plantaires+sont/span+span+stylefont-style:+oblique;une+type+de+aide+pour+les/span+orteils+dont+le+b
トラックバック:http://cloud-dev.mthmn.com/Node/177746
トラックバック:Read Even more
トラックバック:https://qna.lrmer.com/index.php?qa=161705&qa_1=lavandera-poblado-medelln-cuidado-excepcional-prendas
トラックバック:Suggested Resource site
トラックバック:http://Www.zilahy.info/wiki/index.php/User:MauraMontero
トラックバック:http://Www.arts-and-entertainment.ipt.pw/News/crystal-dreams-world-9/
トラックバック:her explanation
トラックバック:see this here
トラックバック:www.dictionary.sblinks.net
トラックバック:http://outsourcing.sbm.pw/News/la-bouticaire-29/
トラックバック:https://Matrice.Btsndrc.ac/forum/profile/lounewcomb78095/
トラックバック:https://King.az/user/ChesterBurne/
トラックバック:Onsale.tawansmile.com
トラックバック:https://www.oasiskorea.net/Brand/2479729
トラックバック:https://Demo.Centreon.com/wiki/index.php?title=User:ThaoYup527735
トラックバック:Qzfczs.com
トラックバック:http://cloud-dev.mthmn.com/node/177978
トラックバック:Portal.Virtueliving.org
トラックバック:https://E-Schoolfaso.com/Forums/Users/kaceysaunders46
トラックバック:https://Maga.wiki/index.php/User:AlexandraButters
トラックバック:trendikkäitä uutisia Internetissä
トラックバック:go source
トラックバック:Xiamenyoga.Com
トラックバック:http://startflag.Rulez.jp/index.php/Installation_Par_Collage
トラックバック:Топ 5 на спортните новини на английски днес
トラックバック:http://www.property.sblinks.net/user/soontjanga/
トラックバック:http://Www.trimmers.Ipt.pw/News/physiobalance-47/
トラックバック:http://www.Zjxsnj.cn/comment/html/?53018.html
トラックバック:Wiki.Team-Glisto.Com
トラックバック:https://www.Oasiskorea.net/Brand/3197278
トラックバック:s741690.ha003.t.justns.ru
トラックバック:https://classifieds.ocala-news.com/author/klara315587
トラックバック:https://Trans.Hiragana.jp/ruby/https://illinoisbay.com/user/profile/6125387
トラックバック:http://www.gotanproject.net/node/22354848?—————————4574525541Content-Disposition:form-data;name=titleCrditsansintrtauCanada:Optionsconsidrer—————————4574525541Content-Disposition:form-data;name=bodyLorsquevousrecherchez
トラックバック:WiKI.MoNaSHicpC.COM
トラックバック:Rowan.wiki
トラックバック:Tendencaj novaĵoj en sociaj amaskomunikiloj ĉi-semajne
トラックバック:dimension-gaming.nl
トラックバック:http://Die-Seite.com/index.php?a=stats&u=brianneeav
トラックバック:just click the up coming article
トラックバック:https://Telearchaeology.org/TAWiki/index.php/User:KirkMcLoud
トラックバック:mouse click the following website page
トラックバック:http://Forum.prolifeclinics.ro/profile.php?id=26909
トラックバック:recent Nxlv.ru blog post
トラックバック:More inspiring ideas
トラックバック:read this blog article from Apeguebremariam.org
トラックバック:https://brilliantcollections.com/tumbled-stones/
トラックバック:Https://telugusaahityam.Com/Small_Enterprise_Loans_Canada
トラックバック:Www.Motline.com
トラックバック:MoTliNE.coM
トラックバック:сацыяльныя сеткі сёння
トラックバック:find out here now
トラックバック:https://www.Vander-horst.nl/wiki/Transporte_No_Pblico_De_Pasajeros_Para_Poder_Turismo:_Comodidad_Y_Flexibilidad_En_Tus_Viajes
トラックバック:http://www.Xjykj.cn/comment/html/?364345.html
トラックバック:www.Die-seite.com
トラックバック:https://Wiki.Castaways.com/wiki/User:VeolaWimberly4
トラックバック:read this post from Guidemagazine
トラックバック:Kaidan136.com
トラックバック:Que signifie la tendance actuelle ?
トラックバック:wiki.rl-transport.org
トラックバック:visit site
トラックバック:http://Cloud-Dev.Mthmn.com/node/64637
トラックバック:https://wiki.bigtata.org/index.php/Utilisateur:DaniloStoneman
トラックバック:https://classifieds.ocala-News.com/
トラックバック:Suits.Bookmarking.site
トラックバック:https://wiki.team-glisto.com/index.php?title=Benutzer:UlyssesDcr
トラックバック:article de presse sur les effets des médias sociaux
トラックバック:http://mastas.co.kr/xe/index.php?mid=Construction_VOD&document_srl=963526
トラックバック:https://online-Learning-initiative.org/wiki/index.php/Free_Canadian_Demand_Loan_Settlement
トラックバック:Www.Ascertain.Ipt.pw
トラックバック:https://Adsclassy.com/index.php?page=user&action=pub_profile&id=851
トラックバック:http://wiki.moebius.com.br
トラックバック:https://zvukiknig.cc
トラックバック:https://Xdpascal.com/index.php/User:ShalandaCannan
トラックバック:https://successionwiki.co.uk/index.php/User:FaustoGroce
トラックバック:https://demo.Centreon.com/wiki/index.php?title=User:MariamMcKinnon
トラックバック:mastas.co.kr
トラックバック:https://Religiopedia.com/index.php/Submarines_Sous
トラックバック:https://Wiki.Vie.today/index.php?title=:TereseCavanaugh
トラックバック:https://Xdpascal.com/index.php/User:NadiaHoran4754
トラックバック:https://Mzlgam.com/index.php?action=profile;u=127950
トラックバック:https://Forum.Inos.at/profile.php?id=220837
トラックバック:click through the following website page
トラックバック:https://Www.Oasiskorea.net/Brand/1594413
トラックバック:http://Cloud-Dev.Mthmn.com/
トラックバック:http://gijangchurch.org/
トラックバック:Read More At this website
トラックバック:Mateenbeat.com
トラックバック:http://gijangchurch.org/index.php?mid=board_UvBh53&document_srl=161768
トラックバック:http://www.somangchurch.org/board_DIJb91/520976
トラックバック:http://Wiki.Quanticsystems.Com.br/index.php/Immediate_On-line_Payday_Mortgage_Canada
トラックバック:Hobbyclues.in
トラックバック:https://telearchaeology.org/TAWiki/index.php/User:MasonBitner894
トラックバック:https://aproblemsquaredwiki.com/User:JadaAlp1156
トラックバック:https://Wiki.Unionoframblers.com/index.php/User:BrigitteGrier
トラックバック:https://Vacayphilippines.com/author/kristinehsu/
トラックバック:https://kaidan136.com/index.php?title=No-Hands_Slip-On_Shoes:_Embrace_Convenience_And_Comfort_In_Canada
トラックバック:Https://mbsre.com/forums/users/candidalandis2
トラックバック:http://zjxsnj.cn/comment/html/?59552.html
トラックバック:https://yoga.wiki/index.php?title=Crystal_Properties_Reference_Guide
トラックバック:Www.Statistics.dofollowlinks.org
トラックバック:http://www.Jeromebaray.com/afm/wiki/index.php/Utilisateur:Agnes2759203907
トラックバック:https://Nxlv.ru/user/CharlineGalgano/
トラックバック:http://Classicalmusicmp3Freedownload.com/ja/index.php?title=Cuisines_Verdun
トラックバック:http://Theglobalfederation.Org/
トラックバック:Wiki.castaways.com
トラックバック:http://www.Onlineschool.bookmarking.site/News/zen-valuations-21/
トラックバック:https://Telearchaeology.org/TAWiki/index.php/User:ElmoHodge3
トラックバック:https://www.volker-rau.de/index.php/Benutzer:Woodrow1790
トラックバック:https://apeguebremariam.org/community/?wpfs=&membersite=httpsPiedconfort.combloguemedecin-des-pieds&membersignature=Lorthse+par+les+orteils+et+la+podiatrie+sont+des+domaines+de+la+bien-tre+qui+sont+typiquement+ngligs+mais+qui+peuvent+avoir+un+effe
トラックバック:https://Sanatandharam.in/index.php/User:LeahRenard0800
トラックバック:https://wiki.Itcoug.com/index.php?title=Usuario:LurleneY45
トラックバック:https://Wiki.nerdbird.media/index.php?title=Pruebas_No_Funcionales:_Asegurando_La_Calidad_Ms_All_De_La_Funcionalidad
トラックバック:https://dptotti.fic.edu.uy/mediawiki/index.php/Enqute_De_Cr_dit_En_Ligne_Sur_Le_Canada_:_Tout_Ce_Que_Vous_Devriez_Comprendre
トラックバック:http://zjxsnj.cn/comment/html/?59483.html
トラックバック:just click the following internet site
トラックバック:wiki.gahlawat.Dynu.Com
トラックバック:telearchaeology.Org
トラックバック:https://luxuriousrentz.com/fubuki-brands-quality-boots-for-unparalleled-performance-in-the-canadian-outdoors/
トラックバック:https://nxlv.ru/user/Neva33805726590/
トラックバック:Virus Win 32 said
トラックバック:WWW.cHIlD-HEAlth.BookmARkINg.Site
トラックバック:Click on Weakfantasy
トラックバック:Gamesfashionarchive.net
トラックバック:https://Apeguebremariam.org/community/?wpfs=&membersite=httpsSelectflex.comblogswork-wellnesstaggednurse-safety&membersignature=I+actually+have+had+these+for++a+hrefhttps://Selectflex.com/blogs/work-wellness/tagged/energyreturntechnology+reldofoll
トラックバック:Highly recommended Online site
トラックバック:https://Religiopedia.com/index.php/Prts_Virtuels_Rapides_Et_Faciles
トラックバック:https://mediawiki.governancaegestao.wiki.br/index.php/User:FranchescaDane5
トラックバック:Www.Consulting.sblinks.net
トラックバック:http://Forum.megi.cz//profile.php?id=2808489
トラックバック:http://Www.Die-Seite.com/index.php?a=stats&u=shayneswan
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1411972
トラックバック:https://Pipewiki.org/app/index.php/The_Golden_Goddess
トラックバック:http://wikivicente.x10Host.com/index.php/Usuario:CarloDoyne7794
トラックバック:Www.Recruiterwiki.de
トラックバック:https://Mzlgam.com/index.php?action=profile;u=128834
トラックバック:https://Kenpoguy.com/phasickombatives/profile.php?id=1332356
トラックバック:Www.seasonal.Ipt.pw
トラックバック:Http://Wiki.Monashicpc.Com/User:Brandybender13
トラックバック:https://Wiki.Rr206.de/index.php?title=Benutzer:Carmon09M9305058
トラックバック:https://Www.Wakewiki.de/index.php?title=Benutzer:MargeryDrennen
トラックバック:wiki.renew-Platforms.dk
トラックバック:https://kaidan136.com/index.php?title=:ZPDBrianne
トラックバック:https://Wiki.Renew-Platforms.dk/index.php?title=User:MindaK282131
トラックバック:http://www.synonyms.sbm.pw/out/roi-recreation-outfitters-91/
トラックバック:online-Learning-initiative.org
トラックバック:https://Incardio.Cuas.at/wiki/index.php/User:SebastianShimizu
トラックバック:https://Wiki.Sports-5.ch/index.php?title=Utilisateur:RudyEmbley
トラックバック:http://cloud-Dev.mthmn.com/node/191601
トラックバック:published on annunci.formazionenautilus.it
トラックバック:jeromebaray.com
トラックバック:https://Wiki.Nerdbird.media/index.php?title=User:ScotLind23484857
トラックバック:Www.vesti24.eu
トラックバック:https://Aproblemsquaredwiki.com/Les_Automobiles_Toyota_Et_Lexus_Ont_La_Cote_Des_Voleurs_De_Voiture_Et_Des_Convertisseurs_Catalytiques_Dans_Le_Royaume
トラックバック:Wiki.prologosconsultoresasociados.cl
トラックバック:Telugusaahityam.com
トラックバック:Http://Internet.Webtv.Dk/User/VancePatel1120
トラックバック:http://bramptoneast.org/index.php/User:ArchieConlan
トラックバック:http://Www.Ruanjiaoyang.com/member.asp?action=view&memName=JulietDaplyn5048922
トラックバック:https://virus.win32.wiki/wiki/Clinique_Podiatrique_Fabreville_In_Laval
トラックバック:gijangchurch.org
トラックバック:Backpacks.sblinks.Net
トラックバック:https://Taupi.org
トラックバック:https://illinoisbay.com/user/profile/6126639
トラックバック:http://Hardware.ipt.pw/out/capital-food-services-206/
トラックバック:http://clothing.Businessadvertising.xyz/blogs/viewstory/5260
トラックバック:Gratisafhalen.be
トラックバック:Https://Wiki.Team-Glisto.Com/Index.Php?Title=Benutzer:Kitty54P78957
トラックバック:click the up coming site
トラックバック:https://Bgmcd.Co.uk/index.php?title=User:Marcella6170
トラックバック:https://Biowiki.clinomics.com
トラックバック:click the next internet page
トラックバック:omen-13.De
トラックバック:https://Zvukiknig.cc/user/DPRBrigida/
トラックバック:WWw.UPdATes.sbM.Pw
トラックバック:WwW.wATerBorEFIJi.COm
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=325888
トラックバック:Beautyconceptasia.com
トラックバック:WwW.goTaNpROJeCt.Net
トラックバック:https://Outhistory.Wwu.edu/wiki/User:GusR7041824496
トラックバック:visit my homepage
トラックバック:okNiGA.OrG
トラックバック:https://Wiki.bigtata.org/
トラックバック:https://Wiki.Lafabriquedelalogistique.fr/Utilisateur:LuellaDimarco90
トラックバック:urbino.fh-joanneum.at
トラックバック:http://bjkclh.com/comment/html/?186324.html
トラックバック:Forum.prolifeclinics.ro
トラックバック:https://maga.wiki/index.php/User:SaraMcBrien8
トラックバック:Illinoisbay.com
トラックバック:http://Www.Ruanjiaoyang.com/member.asp?action=view&memName=JonahSlocum82159
トラックバック:Sl860.com
トラックバック:wwW.sl860.COM
トラックバック:http://www.healthcare-industry.Ipt.pw/News/la-bouticaire-3/
トラックバック:Wiki.Psychedelic-Lab.Com
トラックバック:https://98e.fun/home.php?mod=space&uid=6471395&do=profile&from=space
トラックバック:mouse click the following web site
トラックバック:www.Agriculture-And-Forestry.Sblinks.net
トラックバック:Miapedia.Cz
トラックバック:simply click the following webpage
トラックバック:http://Direcar.Co.kr/board_rxWR73/657242
トラックバック:http://www.fantasyroleplay.co/wiki/index.php/Le_Note_Des_300_Suppl_mentaire_Importantes_Pme_Du_Qu_bec_En_2019
トラックバック:http://www.Suits.Bookmarking.site/News/la-bouticaire-97/
トラックバック:wwW.DIgITAL-MArkEtINg.ipt.PW
トラックバック:http://Forum.Prolifeclinics.Ro/
トラックバック:urduwiki.in
トラックバック:http://www.drsbook.co.kr/board/8234250
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=273642
トラックバック:https://yhet.fi/wiki/index.php/User:NinaPenrod46831
トラックバック:http://Www.Attitude.Bookmarking.site/News/la-bouticaire-11/
トラックバック:http://Www.exotic.bookmarking.site/out/capital-food-services-22/
トラックバック:Read Much more
トラックバック:click through the up coming web site
トラックバック:Thedatabite.Com
トラックバック:Check This Out
トラックバック:http://Gijangchurch.org/index.php?mid=board_UvBh53&document_srl=260516
トラックバック:https://Okniga.org/user/WillieWhitworth/
トラックバック:recent Utahsyardsale.com blog post
トラックバック:wWW.S-miLES.cOm
トラックバック:http://Www.zjxsnj.cn/comment/html/?47435.html
トラックバック:Fridayad.in
トラックバック:https://nobelboerse.de/mitglied/karinastein/
トラックバック:Www.Healthcare-Industry.Sblinks.Net
トラックバック:https://vacayphilippines.com/author/mckinleyn56/
トラックバック:www.calsouthchurch.Org
トラックバック:www.zilahy.info
トラックバック:https://okniga.org/user/Ramona66I416477/
トラックバック:http://Www.Die-Seite.com/index.php?a=stats&u=anitraieu8300466
トラックバック:https://wiki.Unionoframblers.com/index.php/User:CyrusHamrick9
トラックバック:visite site
トラックバック:https://Nebenwelten.net/index.php?title=User:JustinaK42
トラックバック:http://Vulteevaliant.com/index.php/User:Leta94Q4500
トラックバック:VolKEr-rau.de
トラックバック:Chadwiki.Org
トラックバック:Www.visualchemy.gallery
トラックバック:onE.neW-Tkf.XyZ
トラックバック:click here for info
トラックバック:Www.Wfkun.com
トラックバック:http://wiki.psychedelic-lab.com/index.php?title=meuble_boucherville
トラックバック:https://Taupi.org/index.php?title=User:ImogeneEap
トラックバック:Recommended Resource site
トラックバック:Https://Www.Wikinawa.Fr/
トラックバック:calsouthchurch.org
トラックバック:Www.Capital.Bookmarking.Site
トラックバック:Https://Illinoisbay.com/
トラックバック:Koloiko.com
トラックバック:please click the up coming post
トラックバック:you can look here
トラックバック:Aproblemsquaredwiki.com
トラックバック:www.Bjkclh.Com
トラックバック:http://cloud-dev.mthmn.com/node/212633
トラックバック:http://Gotanproject.net/node/22375372?—————————9460384556561Content-Disposition:form-data;name=titleActivitsSportives&RvleSoyezL—————————9460384556561Content-Disposition:form-data;name=bodyemLeGalaLesOlivier,enle/em
トラックバック:similar site
トラックバック:https://www.Oasiskorea.net/Brand/1596832
トラックバック:http://Forum.prolifeclinics.ro/profile.php?id=45159
トラックバック:https://www.Dzliprojects.wiki/index.php/User:Noelia0155
トラックバック:http://Mateenbeat.com/index.php/User:RandalTyq38627
トラックバック:Ndd.vc
トラックバック:http://www.Hotels.Sblinks.net/News/la-bouticaire-120/
トラックバック:WIKi.TEntErE.NeT
トラックバック:http://S741690.Ha003.T.Justns.ru/index.php?subaction=userinfo&user=RowenaMacfarlan
トラックバック:writes in the official Sanatandharam.in blog
トラックバック:https://Weakfantasy.de/index.php/Benutzer:ZandraHoyt21471
トラックバック:wiki.Gigaro.Com.br
トラックバック:http://Www.Gotanproject.Net
トラックバック:wonplay888 daftar
トラックバック:Www.christmas.Ipt.pw
トラックバック:http://Cloud-dev.Mthmn.com/node/174308
トラックバック:http://Www.diywiki.org/index.php/User:Maximo25R4
トラックバック:Read Full Report
トラックバック:https://Aproblemsquaredwiki.com/User:TodBorn310
トラックバック:http://xiamenyoga.com/comment/html/?248664.html
トラックバック:http://qzfczs.com/comment/html/?282184.html
トラックバック:https://zvukiknig.cc/user/JensCoffman828/
トラックバック:Www.Jeromebaray.Com
トラックバック:relevant website
トラックバック:https://Dialogos.wiki/index.php/User:Alicia6059
トラックバック:http://Www.Fantasyroleplay.co/wiki/index.php/User:JanessaCraig
トラックバック:c674576n.beget.tech
トラックバック:http://s741690.ha003.T.justns.ru/index.php?subaction=userinfo&user=JuliusVillanueva
トラックバック:https://onsale.Tawansmile.com/index.php?action=profile;u=8810
トラックバック:http://www.Rebelscon.com/profile.php?id=1596868
トラックバック:https://rebelbase.Customwebarchitect.com/groups/poignees-celui-dehors-exterieures-et-accessoires/info/
トラックバック:https://www.Offwiki.org/wiki/User:TerraWilkins48
トラックバック:https://nebenwelten.net/index.php?title=User:LorenEklund
トラックバック:click through the up coming post
トラックバック:raleighwomenmag.xyz
トラックバック:pOpoFfmuSIC.CoM
トラックバック:https://wiki.bigtata.org/index.php/5_Id_Es_Pour_Une_Salle_De_Bain_Tendance
トラックバック:www.Morphonic-records.com
トラックバック:http://Wikivicente.X10Host.com/index.php/Usuario:HermineMcKinley
トラックバック:Modernbookmarks.com
トラックバック:https://listingpanda.ca/author/julianapti/
トラックバック:https://Topsearch24H.com/search/Peintre+Professionnel+Rsidentiel+Industriel+A+Laval+Rive
トラックバック:http://Www.gedankengut.one/index.php?title=User:Thorsten64E
トラックバック:https://www.Mafiascum.net/social-games/game-20190906/index.php?action=profile;u=309464
トラックバック:https://Dripwiki.com/index.php/User:IsidroBeardsley
トラックバック:https://wiki.rr206.de/index.php?title=Benutzer:MatthiasCoffey6
トラックバック:http://wiki.monashicpc.com/User:BarryStuder796
トラックバック:https://wiki.nerdbird.media/index.php?title=User:TillyMackinolty
トラックバック:recommended site
トラックバック:https://wiki.sports-5.ch/index.php?title=Utilisateur:Merry16U867
トラックバック:https://readukrainianbooks.com/user/HamishWaid/
トラックバック:https://omnias.wiki/index.php/User:KareemDarker2
トラックバック:https://iamelf.com/wiki/index.php/User:HaroldBartlett
トラックバック:Utahsyardsale.com
トラックバック:Https://Dialogos.Wiki/Index.Php/User:Kina21J7319884
トラックバック:click through the up coming page
トラックバック:https://Outhistory.wwu.edu/wiki/Drafting_Rate_Of_Interest_Calculation_Provisions_In_Company_Finance_Transactions
トラックバック:http://www.zilahy.info/wiki/index.php/Understanding_The_Risks_Of_A_Personal_Loan
トラックバック:https://plaza.konchangfuns.com/index.php?action=profile;u=10496
トラックバック:Recommended Internet site
トラックバック:https://deadreckoninggame.com/index.php/User:OpheliaEpstein4
トラックバック:please click the next web page
トラックバック:http://www.real-estate.Dofollowlinks.org/News/lave-toutou-8/
トラックバック:Www.Indopariwara.com
トラックバック:http://Cloud-Dev.Mthmn.com/node/187888
トラックバック:https://Wiki.Freeneuropathology.org/index.php?title=Bote_D_entreposage_Par_Garde
トラックバック:https://zvukiknig.cc/user/IraBrinkley1/
トラックバック:https://moravian.bucknell.edu/transcriptions/index.php?title=User:SoniaRitchey62
トラックバック:https://trabalhadoresindependentes.com/author/rolandoheck/
トラックバック:https://taupi.org/index.php?title=User:GuadalupeCruce4
トラックバック:click the following web page
トラックバック:https://onsale.tawansmile.com/index.php?action=profile;u=8323
トラックバック:https://Weakfantasy.de/index.php/Benutzer:MaximoNesbitt2
トラックバック:click the following article
トラックバック:98E.fun
トラックバック:https://wiki.gigaro.com.br/index.php/User:DKNDerick374
トラックバック:https://napiri.com/design_works/281291
トラックバック:E-SchoOlFAso.coM
トラックバック:http://Wiki.quanticsystems.com.br/index.php/User:Emile512714662
トラックバック:perguntaspoderosas.blog.Br
トラックバック:https://Onsale.Tawansmile.com/index.php?action=profile;u=8819
トラックバック:http://www.somangchurch.org/board_DIJb91/517622
トラックバック:https://maga.wiki/index.php/Dr_David_S_Mulder
トラックバック:http://www.agriculture-and-Forestry.sblinks.net
トラックバック:https://Apeguebremariam.org/community/?wpfs=&membersite=httpsWww.hesmangarage.compostl-alignement-des-roues&membersignature=img+srchttps://picography.co/page/1/600+width450+stylemax-width:450px;max-width:420px;float:right;padding:10px+0px+10px+10p
トラックバック:http://forum.Prolifeclinics.ro/profile.php?id=83011
トラックバック:http://capital.bookmarking.site/News/freaky-socks-30/
トラックバック:Https://Listingpanda.Ca/Author/Cortneystan
トラックバック:Http://Luennemann.Org/
トラックバック:Www.zjxsnj.cn
トラックバック:https://Www.vesti24.eu/user/profile/clarkwhitf/
トラックバック:Dptotti.Fic.Edu.Uy
トラックバック:https://Calsouthchurch.org/board_Txxk18/1514334
トラックバック:https://Kaidan136.com/index.php?title=:MarvinLenihan
トラックバック:https://chadwiki.org/index.php/R_novation_Des_Toilettes_Sherbrooke_Magog
トラックバック:Wikivicente.X10Host.com
トラックバック:https://www.recruiterwiki.de/Benutzer:Rene603241767746
トラックバック:Aaahe.com
トラックバック:https://yoga.wiki/index.php?title=User:HeribertoYin
トラックバック:https://readukrainianbooks.com
トラックバック:http://Wiki.rl-transport.org/index.php/User:JoanneDoolette
トラックバック:cONNEctNGrOw.oRG
トラックバック:https://Trans.Hiragana.jp/ruby/http://cloud-dev.mthmn.com/node/198854
トラックバック:https://zvukiknig.cc/user/JoycelynVonwille/
トラックバック:www.mtmoa02.Net
トラックバック:jasa backlink terbaik
トラックバック:visit my home page
トラックバック:This Internet site
トラックバック:https://luxuriousrentz.com/650-salles-de-bain-ideas-in-2022/
トラックバック:https://Dptotti.fic.edu.uy/mediawiki/index.php/usuario:shanabrophy4
トラックバック:https://Luxuriousrentz.com/avoir-une-soumission-par-fabrication-darmoires/
トラックバック:Https://Wiki.Castaways.Com/Wiki/User:XavierGoward87
トラックバック:Trimmers.ipt.pw
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1221118
トラックバック:http://canamkart.ca/index.php?page=user&action=pub_profile&id=1519706
トラックバック:about his
トラックバック:http://www.child-Health.sblinks.net/News/freaky-socks-12/
トラックバック:superstitionism.Com
トラックバック:Obengdarko.Com.Gh
トラックバック:https://apeguebremariam.org/community/?wpfs=&membersite=httpsEtrema.caendust-masks&membersignature=Le+port+du+masques+de+procdure+est+obligatoire+en+tout+a+temps+par+toutes+les+gens+de+10+ans+et+supplmentaire.pnbsp;/ppnbsp;/p+span+stylefont-style:
トラックバック:www.Legal-information.Sblinks.net
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1214786
トラックバック:https://biconsultingpro.com/baignoire-spa-et-massage-therapeutique-durant-la-etre-enceinte/
トラックバック:Virus.Win32.wiki
トラックバック:http://Cloud-dev.mthmn.com/node/186910
トラックバック:https://luxuriousrentz.com/vinateria-en-queretaro-descubre-una-seleccion-exquisita-de-vinos/
トラックバック:https://www.wakewiki.de/index.php?title=benutzer:lawrencemeudell
トラックバック:http://Www.Bjkclh.com/comment/html/?118099.html
トラックバック:www.loAfeRs.SBLINks.Net
トラックバック:Www.Photography.Ipt.Pw
トラックバック:http://caulove.Com/?document_Srl=569557
トラックバック:https://King.az/user/Ted82R123910519/
トラックバック:https://okniga.org/user/TamikaDang5/
トラックバック:Trans.hiragana.jp
トラックバック:https://mbsre.com/forums/users/monagij791773/
トラックバック:https://urduwiki.in/index.php/User:JessieShirk75
トラックバック:http://www.gedankengut.one/index.php?title=User:OlenNoble55340
トラックバック:click here to find out more
トラックバック:Nxlv.Ru
トラックバック:https://ladder2leader.com/el-sol-azul-de-l-a-laguna-de-san-ignacio-un-fenomeno-natural-asombroso/
トラックバック:http://Www.Rainbow.Bookmarking.site/News/clinica-maxi-dental-27/
トラックバック:Www.Drsbook.co.kr
トラックバック:http://www.e-tracking-system.bookmarking.site/News/armo-design-36/
トラックバック:https://isotrope.cloud/index.php/User:YvetteMonaco
トラックバック:digital-marketing.ipt.Pw
トラックバック:KiRKESIMportS.cOm
トラックバック:http://rebelscon.com/profile.php?id=1601805
トラックバック:http://Beautyconceptasia.com/faq/1240849
トラックバック:http://www.rebelscon.com/profile.php?id=1603937
トラックバック:http://canamkart.ca/Index.php?page=user&action=pub_profile&id=1483361
トラックバック:Isotrope.cloud
トラックバック:mouse click the up coming website page
トラックバック:wwW.OUTsoURciNg.SbM.pw
トラックバック:Http://Www.Drsbook.Co.Kr/Board/8617695
トラックバック:http://eldoradofus.Free.fr/forum/profile.php?id=190852
トラックバック:Https://Virus.Win32.Wiki/
トラックバック:https://online-learning-initiative.org/wiki/index.php/User:TommieDozier
トラックバック:https://www.Checkmygigs.com/community/?wpfs=&membersite=httpsGreensqa.comcontinuous-business-monitoring&membersignature=img+srchttps://yewtu.be/-kFzyn7-SEs+width450+stylemax-width:450px;max-width:400px;float:right;padding:10px+0px+10px+10px;border
トラックバック:http://Direcar.Co.kr/?document_srl=769122
トラックバック:http://Www.capital.Bookmarking.site/user/byronmarks/
トラックバック:http://gotanproject.net/node/22379768?—————————48482186876414Content-Disposition:form-data;name=titleDomaineDeGeorgeSandWikipdia—————————48482186876414Content-Disposition:form-data;name=bodyEtquecelesdeuxounondormirsans
トラックバック:Highly recommended Site
トラックバック:http://cloud-dev.mthmn.com/node/193581
トラックバック:https://wiki.Fukuoka-denshi-kousaku.club/index.php?title=:LavadaLeary9618
トラックバック:http://Www.customer-service.sblinks.Net
トラックバック:http://Www.weather.Sbm.pw/News/la-bouticaire-13/
トラックバック:Magnumgam.Co.kr
トラックバック:visit these guys
トラックバック:http://Www.sxlopw.cn/
トラックバック:https://mbsre.com/forums/users/charlamontenegro/
トラックバック:Wiki.moebius.com.br
トラックバック:https://Wiki.Team-Glisto.com/index.php?title=Benutzer:EricRays77466
トラックバック:http://Www.bjkclh.com/comment/html/?185732.html
トラックバック:http://Zavalen.megi.cz//profile.php?id=1894890
トラックバック:http://www.Gedankengut.one/index.php?title=User:LaceyTroedel8
トラックバック:Die-Seite.com
トラックバック:internet site
トラックバック:http://Www.jeromebaray.com/afm/wiki/index.php/Utilisateur:SidneyHornsby39
トラックバック:visit the up coming webpage
トラックバック:https://trans.Hiragana.jp/ruby/https://illinoisbay.com/user/profile/6120759
トラックバック:https://Telugusaahityam.com/User:NewtonColson1
トラックバック:http://invoices.dofollowlinks.org/user/yqrkarla89/
トラックバック:Direcar.Co.kr
トラックバック:http://Cloud-Dev.Mthmn.com
トラックバック:click here now
トラックバック:Testforum.K9Lady.Com
トラックバック:https://nxlv.ru/user/RemonaScammell8/
トラックバック:Https://Weakfantasy.De/Index.Php/Benutzer:Abe09R558864
トラックバック:https://Www.Waterborefiji.com/index.php?title=User:KPTCathryn
トラックバック:https://Sustainabilipedia.org/index.php/User:WillieRennie477
トラックバック:Classifieds.Ocala-News.com
トラックバック:simply click the up coming website
トラックバック:via vulteevaliant.com
トラックバック:http://cloud-dev.mthmn.com/node/188241
トラックバック:https://www.vander-horst.nl/wiki/User:RobbyYount529
トラックバック:https://dripwiki.com/index.php/User:NealCiotti
トラックバック:Readukrainianbooks link for more info
トラックバック:https://biowiki.clinomics.com/index.php/User:KieranShaffer72
トラックバック:https://Dimension-Gaming.nl/profile.php?id=37033
トラックバック:https://readukrainianbooks.com/user/GeneFerris/
トラックバック:https://Porscheforsale.org/author/mirandaghol/
トラックバック:http://Www.Calsouthchurch.Org/board_txxk18/484876
トラックバック:https://Www.Oasiskorea.net/Brand/3285099
トラックバック:http://www.season.dofollowlinks.org/news/clinica-maxi-dental-5/
トラックバック:https://Mbsre.Com/forums/users/lamont10b967/
トラックバック:http://Www.Driftpedia.com/wiki/index.php/User:LashayGcm3104
トラックバック:https://formazione.Geqmedia.it/blog/index.php?entryid=17126
トラックバック:look at this web-site
トラックバック:https://Classifieds.ocala-news.com/author/ervinwilhoi
トラックバック:https://Weakfantasy.de/index.php/Balcon_Patio_Polybois_Decking_100_Pour_Cent_Plasti
トラックバック:recent Nxlv blog post
トラックバック:https://Offroadjunk.com/Questions/index.php?qa=1205331&qa_1=Prt-sans-refus
トラックバック:https://luxuriousrentz.com/tout-ce-quvous-devriez-comprendre-sur-linstallation-de-pave-uni-a-montreal/
トラックバック:https://Nebenwelten.net/index.php?title=User:Silke380436
トラックバック:Matrice.Btsndrc.ac
トラックバック:https://unitedindia.info/forums/topic/idees-damenagement-par-la-facade-de-votre-maison-2/
トラックバック:Faq.warexo.de
トラックバック:http://canamkart.ca/index.php?page=user&action=pub_profile&id=1505626
トラックバック:http://Www.die-seite.com/
トラックバック:wWW.voLkeR-rAu.DE
トラックバック:http://Cloud-Dev.mthmn.com/node/176680
トラックバック:Https://omnias.Wiki/index.php/User:MyrnaGuzman2175
トラックバック:Https://Wiki.Gigaro.Com.Br/
トラックバック:discover here
トラックバック:http://gijangchurch.org/index.php?mid=board_UvBh53&document_srl=272614
トラックバック:http://mastas.co.kr/xe/index.php?mid=Construction_VOD&document_srl=960227
トラックバック:http://zavalen.megi.cz//profile.php?id=1920917
トラックバック:My Page
トラックバック:please click for source
トラックバック:https://King.az/user/ZNZMilla08/
トラックバック:http://www.pinnaclebattleship.com/wiki/index.php/User:LuigiOreilly40
トラックバック:Www.synonyms.bookmarking.site
トラックバック:https://readukrainianbooks.com/user/AliciaOrmond1/
トラックバック:https://Wiki.Team-Glisto.com/Index.php?title=Benutzer:AlanaBecker271
トラックバック:https://biowiki.clinomics.com/index.php/User:ArdenToussaint
トラックバック:http://Gijangchurch.org/index.php?mid=board_UvBh53&document_srl=273116
トラックバック:http://Www.Rebelscon.com/profile.php?id=1597685
トラックバック:השכרת רכב בבוקרשט
トラックバック:your input here
トラックバック:https://zvukiknig.cc/user/NanniePan74685/
トラックバック:Weakfantasy.de’s website
トラックバック:http://Aaahe.com/index.php?page=user&action=pub_profile&id=72083
トラックバック:https://www.oasiskorea.net/Brand/3071232
トラックバック:Suggested Online site
トラックバック:Edddriihm.tp.crea.pro
トラックバック:https://mountainrootsonline.com/index.php/User:AnibalBischof
トラックバック:https://forum.inos.at/profile.php?id=334259
トラックバック:here.
トラックバック:https://onsale.tawansmile.com/Index.php?action=Profile;u=6960
トラックバック:simply click for source
トラックバック:http://luennemann.org/index.php?mod=users&action=view&id=324313
トラックバック:https://Infodin.Com.br/index.php/User:GarnetSymon379
トラックバック:www.gedankengut.one
トラックバック:Www.Hotels.Sblinks.net
トラックバック:https://Aproblemsquaredwiki.com/User:DannielleLuisini
トラックバック:http://Leonblog.net/member.asp?action=view&memName=MaddisonMerryman361
トラックバック:https://Readukrainianbooks.com/user/CarolSkalski985/
トラックバック:http://direcar.Co.kr/board_rxWR73/698486
トラックバック:https://www.morphonic-Records.com/community/profile/elvaingram00172/
トラックバック:https://portal.virtueliving.org/profile_info.php?ID=36590
トラックバック:https://Demo.Centreon.com/wiki/index.php?title=User:ForestHirschfeld
トラックバック:http://Gijangchurch.org/index.php?mid=board_UvBh53&document_srl=161037
トラックバック:this post
トラックバック:wikI.FUKUOka-DEnsHi-kOUsAkU.cLUb
トラックバック:https://taupi.org/index.php?title=User:GeraldoOMay6
トラックバック:http://www.bjkclh.com/comment/html/?192389.html
トラックバック:https://wiki.nerdbird.media/index.php?title=User:LeonoreOuo
トラックバック:Http://Saju.Codeway.Kr/Index.Php/Base_De_Lit_Matelot__Six_Tiroirs_Pour_TrS_G_Ant_Matelas_King_S_Mate_De_Prepac_Gris_Dbk
トラックバック:https://Readukrainianbooks.com/user/Angelita70O/
トラックバック:Www.online-teaching.sblinks.net
トラックバック:Wiki.Nativeland.info
トラックバック:http://cloud-dev.mthmn.com/node/219356
トラックバック:http://demos.Gamer-Templates.de/specialtemps/clansphere20114Sdemo01/Index.php?mod=users&action=View&id=5846727
トラックバック:Brilliantcollections.com
トラックバック:https://portal.virtueliving.org/profile_info.php?ID=33135
トラックバック:simply click the next web page
トラックバック:Cloud Dev Mthmn said in a blog post
トラックバック:https://Nxlv.ru/user/GlenRountree124/
トラックバック:https://Wiki.Tentere.net/index.php?title=Bijoux_Par_Femme
トラックバック:http://Beautyconceptasia.com/faq/1143237
トラックバック:https://mzlgam.com/index.php?action=profile;u=205098
トラックバック:http://Www.superstitionism.com/forum/profile.php?id=385058
トラックバック:http://Loafers.ipt.pw/News/la-bouticaire-12/
トラックバック:https://Www.Oasiskorea.net/Brand/3493150
トラックバック:https://Plamosoku.com/enjyo/index.php?title=:SabrinaTaul2
トラックバック:http://wsdjcd.cn/comment/html/?80411.html
トラックバック:https://Dublinohiousa.gov/?p=
トラックバック:Www.recruiting-and-retention.bookmarking.site
トラックバック:https://Zvukiknig.cc/user/ValenciaX02/
トラックバック:https://www.morphonic-records.com/Community/profile/brittferrara49/
トラックバック:Коя е актуална тема в социалните медии?
トラックバック:notícias de tendência no mundo
トラックバック:https://ladder2Leader.com/laguna-san-ignacio-una-joya-natural-en-baja-california-sur/
トラックバック:http://Www.gotanproject.net/node/22364157?—————————732408056302Content-Disposition:form-data;name=titleSummaryOfGuidanceForMinimizingTheImpactOfCovid-19OnIndividualPersons,Communities,AndHealthCareSystemsUnitedStates,August2022Mmwr——
トラックバック:https://mmhsmassageme.com/index.php?page=user&action=pub_profile&id=5822786
トラックバック:mouse click the up coming post
トラックバック:Www.Photography.Sblinks.net
トラックバック:Www.Lunchbox.Sblinks.net
トラックバック:спортни новини на живо
トラックバック:just click the up coming website
トラックバック:https://www.oasiskorea.net/Brand/3449836
トラックバック:http://Gotanproject.net/node/22387625?—————————123727724Content-Disposition:form-data;name=titlePanneauxSolairesAuSol:Rglementation,Cot,Aides—————————123727724Content-Disposition:form-data;name=bodyiAujourd’hui,unparco
トラックバック:https://dripwiki.com/index.php/User:TaniaBartley
トラックバック:https://Unitedindia.info/forums/topic/elagage-vs-emondage-quelle-est-la-distinction-2/
トラックバック:http://Gotanproject.net/node/22385075?—————————58061928985819Content-Disposition:form-data;name=titleLebtondesign,unpenchantdcorativedurable—————————58061928985819Content-Disposition:form-data;name=bodyiSous-titres:/ibr
トラックバック:https://unitedindia.info/forums/topic/comment-consolider-vos-argent-du-conseils-budgetaires-et-planification-3/
トラックバック:www.financial-services.Bookmarking.Site
トラックバック:Girl.Sblinks.net
トラックバック:http://www.Bjkclh.com/comment/html/?189512.html
トラックバック:http://www.gedankengut.one/index.php?title=User:ManieBerman32
トラックバック:Mediawiki.governancaegestao.Wiki.br
トラックバック:titujt e lajmeve sportive të ditës së sotme
トラックバック:https://ciutatgranturia.es/2023/09/26/vinedo-en-queretaro-descubriendo-la-riqueza-vinicola-la-region/
トラックバック:http://Www.Zilahy.info/wiki/index.php/User:VickieSpalding0
トラックバック:Www.Airline.Bookmarking.site
トラックバック:Http://Www.zjxsnj.cn
トラックバック:http://Rainbow.bookmarking.site/News/armo-design-30/
トラックバック:https://Aproblemsquaredwiki.com/User:Cole280757325
トラックバック:tin tức trực tiếp của cbs
トラックバック:click the following webpage
トラックバック:flusso di notizie in diretta gratuito
トラックバック:Https://Wiki.Castaways.Com/Wiki/La_Importancia_Del_Ecoturismo:_ConservaciN_Desarrollo_Y_Conciencia_Ambiental
トラックバック:https://weakfantasy.de/index.php/Benutzer:LeonardDickerson
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=329628
トラックバック:https://www.recruiterwiki.de/Benutzer:TessaK0664
トラックバック:have a peek at this website
トラックバック:Безплатен поток от новини на живо в youtube
トラックバック:Omnias.Wiki
トラックバック:Gotanproject.net
トラックバック:tiempos de noticias deportivas de la india hoy
トラックバック:www.superstitionism.com
トラックバック:item550758107
トラックバック:https://aproblemsquaredwiki.com/User:Boris59Y5089
トラックバック:http://qzfczs.com/comment/html/?289176.html
トラックバック:you can try Illinoisbay.com
トラックバック:click through the up coming webpage
トラックバック:https://Procesal.cl/index.php/User:FreemanLansford
トラックバック:https://runsexme.Ru/
トラックバック:Https://Wiki.Sports-5.Ch/Index.Php?Title=Utilisateur:Elliotlowin0461
トラックバック:최신 뉴스 인도네시아
トラックバック:https://Trans.Hiragana.jp/ruby/http://cloud-dev.mthmn.com/node/199807
トラックバック:https://Matrice.Btsndrc.ac/forum/profile/shaynavoyles20/
トラックバック:https://Dripwiki.com/index.php/User:DaisyBiermann9
トラックバック:https://Vipsbay.net/index.php/blog/55882/pruebas-uat-en-colombia-garantizando-la-excelencia-del-software/
トラックバック:https://Pipewiki.org/app/index.php/User:Cristina3303
トラックバック:http://wiki.Quanticsystems.com.br/index.php/User:QHUErik56051
トラックバック:https://yoga.wiki/index.php/v_nements_Par_C_libataires__Montr_al_:_Rencontre_Et_Connexion_Authentique
トラックバック:http://www.rebelscon.com/profile.php?id=1594645
トラックバック:http://www.gotanproject.net/
トラックバック:Sudancancer-Clinic.com
トラックバック:https://www.motline.com/index.php?mid=rent_counseling&document_srl=2235952
トラックバック:http://www.customer-Service.sblinks.net/News/tres-amigos-outfitters-10/
トラックバック:https://www.kenpoguy.com/phasickombatives/profile.php?id=1378714
トラックバック:Wiki.Unionoframblers.Com
トラックバック:www.commit.ipt.Pw
トラックバック:https://apeguebremariam.org/community/?wpfs=&membersite=httpsFlorilegejardinerie.comboutiquecouronne-funeraire&membersignature=span+stylefont-style:+oblique;La+prparation+peut+avoir/span+lieu++la+fin+du+mois+de+mai+dans+plusieurs+arrondissements+d
トラックバック:http://Www.Register.Sblinks.net/out/neuro-performa/
トラックバック:https://maga.wiki/index.php/User:GarryZercho
トラックバック:https://porscheforsale.org
トラックバック:agreement.bookmarking.site
トラックバック:Www.Terrarium-Reptile.com
トラックバック:visit the up coming site
トラックバック:Www.Loafers.ipt.pw
トラックバック:https://Matrice.btsndrc.ac/forum/profile/elisebna5675035/
トラックバック:https://infodin.com.br/index.php/User:MeiHandcock174
トラックバック:http://wiki.quanticsystems.Com.br/index.php/User:ShaniHartnett
トラックバック:https://Aproblemsquaredwiki.com/User:AidanWilliford
トラックバック:Related Site
トラックバック:https://www.globasnet.com/members/taylamauriello/profile/
トラックバック:http://www.Digital-marketing.Ipt.pw/News/armo-design-68/
トラックバック:Suggested Looking at
トラックバック:http://www.Gedankengut.one/index.php?title=User:MichealHillary
トラックバック:http://Www.diywiki.Org/
トラックバック:https://infodin.com.br/index.php/User:JanellColmenero
トラックバック:http://Qzfczs.com/comment/html/?291423.html
トラックバック:http://www.s-miles.com/xe/board_gBNS02/808904
トラックバック:http://afcantarelle.org/index.Php?title=User:WRFBrandi022438
トラックバック:https://king.az/user/SheenaHogan
トラックバック:https://wiki.nerdbird.media/index.php?title=User:GregSyx69999
トラックバック:https://biowiki.clinomics.com/index.php/User:BenedictCagle
トラックバック:https://yhet.fi/wiki/index.php/User:AngelaKoonce03
トラックバック:трендовски вести во Индонезија
トラックバック:http://Sl860.com/comment/html/?241116.html
トラックバック:https://utahsyardsale.com/author/jesusgay67/
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=327553
トラックバック:https://www.oasiskorea.net/Brand/3191087
トラックバック:information from Www.Kenpoguy.com
トラックバック:https://Nxlv.ru/user/CharlotteSturgil/
トラックバック:https://Pipewiki.org/app/index.php/Satisfaccin_Al_Cliente:_Ejemplos_En_Colombia_Que_Impulsan_El_xito_Empresarial
トラックバック:http://gijangchurch.org/index.php?mid=board_UvBh53&document_srl=310027
トラックバック:simply click the up coming web site
トラックバック:https://Www.Oasiskorea.net/Brand/3221717
トラックバック:http://afcantarelle.org/index.php?title=Article_Title
トラックバック:more about Ladder 2leader
トラックバック:Https://Illinoisbay.com/user/Profile/6147897
トラックバック:https://Forum.Inos.at/profile.php?id=276853
トラックバック:актуални новини в Twitter
トラックバック:https://Www.Vander-Horst.nl/wiki/User:Brittany53K
トラックバック:https://Classifieds.ocala-news.com/author/alicabliss6
トラックバック:http://www.gotanproject.net/node/22390780?—————————42044346194642Content-Disposition:form-data;name=titleAryaRugsAccessoriesHighQualityCarpets&Rugs—————————42044346194642Content-Disposition:form-data;name=bodyimgsrc
トラックバック:Актуални новини в интернет тази седмица
トラックバック:Suggested Reading
トラックバック:http://Gotanproject.net/node/22392003?—————————3101004761Content-Disposition:form-data;name=titleEmprisonnonsLaChaleurSection5:LesToitsEtLesEntretoits—————————3101004761Content-Disposition:form-data;name=bodyimgsrc=http
トラックバック:Https://illinoisbay.com/user/profile/6151406
トラックバック:http://forum.megi.cz//profile.php?id=2822177
トラックバック:Https://Www.Oasiskorea.Net
トラックバック:https://Www.oasiskorea.net/Brand/3580058
トラックバック:Infodin.Com.br
トラックバック:http://Cloud-dev.Mthmn.com/Node/237962
トラックバック:https://nobelboerse.de/mitglied/warnerblank/
トラックバック:https://illinoisbay.com/user/profile/6149153
トラックバック:https://Www.Drclydewilson.com/community/?wpfs=&membersite=httpsvanspremium.com.coservicios&membersignature=Bogot+la+capital+de+Colombia+es+una+ciudad+rica+en+tradicin++a+hrefhttps://vanspremium.com.co/+reldofollowServicios+de+Transporte+terrestre+
トラックバック:https://hobbyclues.in/user/profile/30636
トラックバック:https://Okniga.org/user/EddyGlaspie/
トラックバック:http://luennemann.org/index.php?mod=users&action=view&id=328007
トラックバック:http://Canamkart.ca/index.php?page=user&action=pub_profile&id=1528824
トラックバック:Http://Qzfczs.com
トラックバック:https://king.az/user/JaquelineStrangw/
トラックバック:https://Antislave.com/groups/service-de-reparation-gps-garmin-laval-canada/
トラックバック:http://Sl860.com/comment/html/?268547.html
トラックバック:pede togel login alternatif
トラックバック:https://www.offwiki.org/wiki/User:LavadaSouza59
トラックバック:simply click the up coming internet page
トラックバック:https://portal.virtueliving.org/profile_info.php?ID=31668
トラックバック:http://Forum.Prolifeclinics.ro/profile.php?id=84061
トラックバック:Preuniversitarioperu.com
トラックバック:Http://Gijangchurch.Org
トラックバック:Highly recommended Website
トラックバック:Cosmeascopes.com
トラックバック:https://Readukrainianbooks.com/user/ArielMackersey8/
トラックバック:http://cloud-dev.mthmn.com/node/181619
トラックバック:Https://Matrice.btsndrc.ac/
トラックバック:http://Www.zilahy.info/wiki/index.php/User:ZVSTamela9
トラックバック:Https://www.motline.com
トラックバック:https://taupi.org/index.php?title=User:NQMFlora18
トラックバック:https://Okniga.org/user/BlytheGoins880/
トラックバック:financial-services.bookmarking.site
トラックバック:https://Okniga.org/user/LucaMcGahan315/
トラックバック:Full Piece of writing
トラックバック:https://demo.centreon.com/wiki/index.php?title=User:WhitneyOMeara03
トラックバック:https://Theglobalfederation.org/profile.php?id=1995223
トラックバック:https://mmhsmassageme.com/index.php?page=user&action=pub_profile&id=5838024
トラックバック:Азыр тренд деген эмнени билдирет?
トラックバック:https://Portal.Virtueliving.org/profile_info.php?ID=38236
トラックバック:https://hobbyclues.in/user/profile/36298
トラックバック:https://zvukiknig.cc/user/SherleneCard510/
トラックバック:http://Qzfczs.com/comment/html/?293979.html
トラックバック:mzlgam.Com
トラックバック:https://Nobelboerse.de/mitglied/changmathes/
トラックバック:blog post from cloud-dev.mthmn.com
トラックバック:Customer-service.Sblinks.net
トラックバック:https://King.az
トラックバック:http://www.suits.ipt.pw/News/designer-dinterieur-a-montrea-31/
トラックバック:http://Sl860.com/comment/html/?243456.html
トラックバック:https://checkmygigs.com/community/?wpfs=&membersite=httpscouvreurpaquette.comrefection-de-toiture-a-sainte-scholastique&membersignature=il+assure+une+pose+dans+les+normes+de+quelque+manire+que+ce+soit+au+degr+de+qualit+mais+en+plus+bas+sur+les+rgl
トラックバック:https://Biowiki.Clinomics.com/index.php/Armoire_De_Cuisine
トラックバック:http://C674576N.Beget.tech/author/felipe14c7/
トラックバック:Oasiskorea.net
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=329534
トラックバック:http://Www.Weather.Sbm.pw
トラックバック:just click for source
トラックバック:https://Xdpascal.com/index.php/User:OrvilleDacomb1
トラックバック:http://My-Broholmer.de/community/profile/angiedownie6605
トラックバック:https://classifieds.exponentialhealth.coop/community/?email=&membersite=httpsmoney911.caenquick-loans&membersignature=lorsque+vous+recherchez+un+prt+personnel+au+qubec+aider++faire+appel++1+revendeur+en+prt+pourrait+tre+une+choix+judicieuse+qui+pe
トラックバック:http://www.Gaming.sblinks.net/News/tres-amigos-outfitters-6/
トラックバック:Luxuriousrentz.Com
トラックバック:http://Www.Superstitionism.com/forum/profile.php?id=378453
トラックバック:click the next site
トラックバック:http://direcar.Co.kr/board_rxWR73/901931
トラックバック:Www.change-management.dofollowlinks.org
トラックバック:Mmhsmassageme.com
トラックバック:https://wiki.freeneuropathology.org/index.php?title=Bureau_D_Architecture__Montr_al_:_Cr_ativit_Et_Excellence_Sur_Le_Service_De_Vos_Projets
トラックバック:http://www.s-miles.com/xe/board_gBNS02/253851
トラックバック:http://www.Die-seite.com/index.php?a=stats&u=reynaldogreenfie
トラックバック:https://Okniga.org/user/CyrusMccallister/
トラックバック:visit Seasonal.Ipt.pw now >>>
トラックバック:https://Isotrope.cloud/index.php/Conseils_Sur_Comment_Faire_Face__Une_D_pense_Inattendue
トラックバック:click the following page
トラックバック:https://Illinoisbay.com/user/profile/6147051
トラックバック:http://Theglobalfederation.org/profile.php?id=2000565
トラックバック:Http://canamkart.ca/index.php?page=user&action=pub_profile&id=1350975
トラックバック:Related Web Page
トラックバック:Https://Forum.veriagi.com
トラックバック:bu gün sosial media ilə nə baş verir
トラックバック:https://Napiri.com/design_works/334014
トラックバック:vacayphilippines.com`s blog
トラックバック:Startflag.Rulez.jp wrote in a blog post
トラックバック:Forum.giperplasma.ru
トラックバック:https://Www.Checkmygigs.com/community/?wpfs=&membersite=httpsWww.Ciminvestigacion.comel-mercado-en-la-actualidad&membersignature=span+styletext-decoration:+underline;El+benchmarking+interno+es+una/span+estrategia+empresarial+que+puede+enfoca+en+co
トラックバック:https://king.az/user/JimCastleton49/
トラックバック:https://Wiki.Unionoframblers.com/index.php/User:RaymondFewings
トラックバック:https://forum.veriagi.com/profile.php?id=4248886
トラックバック:https://Virus.Win32.wiki/wiki/Podiatre_Fermer_De_Laval
トラックバック:http://Xiamenyoga.com/Comment/html/?253152.html
トラックバック:http://Www.Video.Dofollowlinks.org/News/tres-amigos-outfitters-28/
トラックバック:http://Gotanproject.net/node/22397337?—————————68082558Content-Disposition:form-data;name=titleUnTuteurDeMousseSimpleFabriquerJardinierParesseuxMonsteraDeliciosa,SwissCheesePlant,CheesePlant—————————68082558Content-Disp
トラックバック:https://Pipewiki.org/app/index.php/User:MillieSundberg
トラックバック:https://www.Vander-horst.nl/wiki/User:SonjaIev804186
トラックバック:https://Thedatabite.com/community/?wpfs=&membersite=httpsmaisondermasens.com&membersignature=Avant+dutiliser+un+produit+par+la+pores+et+peau+il+est+prfrable+de+demander+lavis+de+un+mdecin+ou+un+pharmacien++a+hrefhttps://Maisondermasens.com/+reldof
トラックバック:http://Soccer-Manager.eu/forum/profile.php?id=1093716
トラックバック:Wisetrubador.com
トラックバック:vander-Horst.nl
トラックバック:My Home Page
トラックバック:https://Successionwiki.co.uk/index.php/User:GretchenGilberts
トラックバック:https://pipewiki.org/app/index.php/User:CecilaThao39988
トラックバック:EtoWnjUNGLIsts.coM
トラックバック:http://Die-Seite.com/index.php?a=stats&u=maxlayh1125264
トラックバック:Www.soccer-Manager.eu
トラックバック:http://Www.Bjkclh.com/comment/html/?119247.html
トラックバック:like this
トラックバック:http://afcantarelle.org/index.php?title=User:TobiasBirtles
トラックバック:http://qzfczs.com/comment/html/?275604.html
トラックバック:Unitedindia.info
トラックバック:http://zavalen.megi.cz//profile.php?id=1921174
トラックバック:اخبار پرطرفدار در رسانه های اجتماعی
トラックバック:https://zvukiknig.cc/user/ChesterLegge1/
トラックバック:Risingsun.co.kr
トラックバック:www.business-to-business.ipt.pw
トラックバック:WwW.MiRAgeARb.COM
トラックバック:click through the next article
トラックバック:https://www.vander-horst.nl/wiki/User:NorrisPgx96765
トラックバック:pop over to this site
トラックバック:Tko je broj 1 u trendu na Googleu?
トラックバック:https://king.az/user/BobbyeBrough971/
トラックバック:http://eldoradofus.free.fr/forum/profile.php?id=191377
トラックバック:co se dnes děje se sociálními sítěmi
トラックバック:https://Dripwiki.com/index.php/User:SelinaYxy58
トラックバック:https://mediawiki.Governancaegestao.wiki.br/index.php/Stihl_Pole_Saw_Canada:_Features_And_Benefits
トラックバック:https://Pipewiki.org/app/index.php/User:LizziePringle6
トラックバック:https://Enableelearn.com/?s=&post_type=courses&membersite=httpsPoupartsyndic.caconsolidation-de-dettes-a-dorval&membersignature=span+stylefont-style:+italic;Sous-titres+:+/spanpnbsp;/ppnbsp;/p+1.+Comprendre+les+prts+hypothcairespnbsp;/ppnbsp;/
トラックバック:https://Able.Extralifestudios.com/wiki/index.php/User:AltonBrownbill6
トラックバック:https://avfoch.com/author/warnerhillm/
トラックバック:forum.Veriagi.com
トラックバック:https://Nxlv.ru/user/CharityWpx/
トラックバック:https://classifieds.ocala-news.com/author/klaussherma
トラックバック:https://King.az/user/PBJWilson1784319/
トラックバック:Legalidad.net
トラックバック:Zilahy.Info
トラックバック:https://www.Waterborefiji.com/index.php?title=User:LonnyHenschke
トラックバック:http://Cloud-Dev.Mthmn.com/node/245194
トラックバック:Aviamili.com
トラックバック:http://Www.Legal-Information.sblinks.net/News/denta-especialidades-32/
トラックバック:http://Cloud-dev.mthmn.com/node/244677
トラックバック:https://Omnias.wiki/index.php/User:OdessaPutman0
トラックバック:www.sigmachiiu.Com
トラックバック:https://Cbnxt.com
トラックバック:Zwitsch.io
トラックバック:шуурхай мэдээ гарчиг
トラックバック:killer deal
トラックバック:Procesal.cl
トラックバック:Https://Infodin.Com.Br/Index.Php/User:ColetteSommerlad
トラックバック:http://www.register.Bookmarking.site/News/freaky-socks-29/
トラックバック:Trabalhadoresindependentes.com
トラックバック:https://www.Motline.com/index.php?mid=rent_counseling&document_srl=2463061
トラックバック:http://cloud-dev.Mthmn.com/node/246783
トラックバック:https://pipewiki.org/app/index.php/User:NganWeisz6
トラックバック:visit this website
トラックバック:https://thedatabite.com/community/?wpfs=&membersite=httpsEnergiaysistemas.comups-online&membersignature=span+stylefont-style:+oblique;Bogot+la+vibrante+capital/span+de+Colombia+es+un+centro+de+actividad+negocio+y+empresarial.+En+un+entorno+donde+l
トラックバック:http://Www.zilahy.info/wiki/index.php/User:MoniqueWinters
トラックバック:https://barretocell.com/2023/10/11/ecoturismo-en-la-region-de-san-ignacio-una-estadia-inolvidable/
トラックバック:Minibookmarks.Com
トラックバック:Forum.Megi.cz
トラックバック:Www.weather.sbm.pw
トラックバック:Zavalen.megi.cz
トラックバック:http://market-Research.sblinks.Net
トラックバック:http://Www.Die-Seite.com/index.php?a=stats&u=russellcreighton
トラックバック:http://Www.Rebelscon.com/profile.php?id=1611202
トラックバック:Https://Maga.wiki/
トラックバック:okniga.org said
トラックバック:ʻO nā nūhou kaulana ma ka pūnaewele i kēia lā
トラックバック:https://wiki.freeneuropathology.org/index.php?title=user:jettaperkin04
トラックバック:i was reading this
トラックバック:Http://www.gedankengut.One
トラックバック:https://infodin.com.br/index.php/User:HeidiThorp3
トラックバック:https://Trans.Hiragana.jp/ruby/http://cloud-dev.mthmn.com/node/245990
トラックバック:Get Source
トラックバック:Moodjhomedia.com
トラックバック:lnX.ARgOnBAnD.iT
トラックバック:http://Wiki.Rl-Transport.org/index.php/User:AraSutcliffe126
トラックバック:http://Qzfczs.com/comment/html/?300445.html
トラックバック:https://Kaidan136.com/index.php?title=:KAGDoug3884027
トラックバック:find more information
トラックバック:https://sustainabilipedia.org/index.php/User:LoisDehaven951
トラックバック:https://okniga.org/user/EugeneRooney8/
トラックバック:http://Www.Sports.Sblinks.net/out/performance-saw-17/
トラックバック:라이브 스포츠 뉴스 프리미어 리그
トラックバック:http://Www.Sxlopw.cn/comment/html/?225758.html
トラックバック:Https://lnx.Argonband.It
トラックバック:Besplatni prijenos vijesti uživo na youtube
トラックバック:http://Wiki.quanticsystems.com.Br/
トラックバック:https://Gratisafhalen.be/author/amparo03i61/
トラックバック:https://kaidan136.com/index.php?title=:BlytheLemay990
トラックバック:http://afcantarelle.org/index.php?title=User:PaulettePrescott
トラックバック:http://www.Die-seite.com/index.php?a=stats&u=leomau42125
トラックバック:http://www.soccer-Manager.eu/forum/profile.php?id=1165628
トラックバック:http://sl860.com/comment/html/?244010.html
トラックバック:just click the up coming web site
トラックバック:http://Qzfczs.com/comment/html/?298682.html
トラックバック:Vivaj sportaj novaĵoj hodiaŭ
トラックバック:www.healthcare-industry.Ipt.pw
トラックバック:http://www.Gedankengut.one/index.php?title=User:ChristalI89
トラックバック:https://Readukrainianbooks.com/user/IeshaMccrary7/
トラックバック:https://avfoch.com/author/wfxmellisa1/
トラックバック:https://oasiskorea.net/Brand/1762904
トラックバック:http://c674576n.beget.tech/author/solomongene/
トラックバック:My Web Site
トラックバック:http://www.Zilahy.info/Wiki/index.php/User:VitoMcCarthy
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1062688
トラックバック:https://Wiki.Gem-Flash.com/index.php?title=User:EulaCollazo184
トラックバック:http://Zilahy.info/wiki/index.php/Comment_Nettoyer_Un_Climatiseur_Mural_:_tapes__Suivre
トラックバック:avtpoligraf.ru
トラックバック:https://Taupi.org/index.php?title=User:CarsonTreacy06
トラックバック:https://pipewiki.org/app/index.php/User:RyanBrandow
トラックバック:wwwbj.com.cn
トラックバック:https://okniga.org/user/MarleneHooton6/
トラックバック:www.events.sblinks.net
トラックバック:you could try here
トラックバック:Afcantarelle`s recent blog post
トラックバック:Www.agchem.co.kr
トラックバック:Wiki Psychedelic Lab said in a blog post
トラックバック:Wiki.Quanticsystems.Com.br
トラックバック:https://Mzlgam.Com/index.php?action=profile;u=209808
トラックバック:https://qa.laodongzu.com/?qa=569791/cadenas-eficientes-camino-empresas-invencibles-colombia
トラックバック:https://Wiki.Freeneuropathology.org/index.php?title=User:FrankMcAlister1
トラックバック:simply click the up coming webpage
トラックバック:шууд мэдээ үнэг
トラックバック:Sxlopw.cn
トラックバック:https://dptotti.fic.edu.uy/mediawiki/index.php/Usuario:WadeClibborn2
トラックバック:Suggested Web site
トラックバック:https://mediawiki.governancaegestao.wiki.br/index.php/User:MurrayKoerstz84
トラックバック:https://aumcgogrzo.cloudimg.io/v7/https://www.akilia.net/contact?message=Very+nice+post.+I+just+stumbled+upon+your+blog+and+wanted+to+say+that+I+have+truly+loved+browsing+your+blog+posts.+In+any+case+I+will+be+subscribing+in+your+feed+and+Im+hoping+you+wr
トラックバック:http://leonblog.net/member.asp?action=view&MemName=MadonnaBullock13341
トラックバック:Live lajme sportive të ligës së parë
トラックバック:Classifieds.Exponentialhealth.coop
トラックバック:http://www.Digital-marketing.ipt.pw/out/tres-amigos-outfitters-21/
トラックバック:https://wiki.castaways.com/wiki/User:GregorioDadswell
トラックバック:http://wiki.moebius.com.br/index.php/Cursos_DC-3_En_Lnea_En_M_xico:_Tu_Opcin_Para_Poder_La_Capacitacin_Laboral
トラックバック:https://Forum.inos.at/
トラックバック:Cloud-Dev.mthmn.com
トラックバック:https://Avtpoligraf.ru/content/forfait-massage-therapeutique-suedois-ou-californien-90-minutes-et-soin-visage-le-classique
トラックバック:relevant resource site
トラックバック:https://Telearchaeology.org/TAWiki/index.php/User:TobySuh75415548
トラックバック:http://www.security.sbm.pw/News/couvreur-paquette-28/
トラックバック:https://Mzlgam.com/index.php?action=profile;u=178757
トラックバック:https://dptotti.fic.edu.uy/mediawiki/index.php/MS_880_Stihl:_A_High-Performance_Chainsaw_For_Heavy-Duty_Jobs
トラックバック:Cbnxt.com
トラックバック:gewilde nuus op sosiale media
トラックバック:http://Wiki.monashicpc.com/User:Major8643378995
トラックバック:https://Upscadvisor.Co.in/groups/refrigeracion-industrial-en-medellin-enfriamiento-eficiente-para-la-industria-local/
トラックバック:https://socialbraintech.com/story1054033/cim-investigacin
トラックバック:trendi hírek ma
トラックバック:http://commission.sbm.pw/News/mon-genie-en-batiment-22/
トラックバック:https://www.checkmygigs.com/community/?wpfs=&membersite=httpswww.solutions-g00.com&membersignature=Learn+in+regards+to+the+work+the+training+youll+need+what+youll+earn+and+extra.+Provided+youve+the+suitable+conditions+the+programs+in+this+program+
トラックバック:http://Customer-Service.Sblinks.net/News/tres-amigos-outfitters-14/
トラックバック:http://Child-Health.Bookmarking.site/News/tres-amigos-outfitters-18/
トラックバック:http://Www.Die-Seite.com/index.php?a=stats&u=kari39m21625
トラックバック:click for more
トラックバック:http://Direcar.co.kr/board_rxWR73/653857
トラックバック:https://www.guidemagazine.org/participant/cathrynstorm94/profile/?claim_code=&submit_2=&membersite=httpsrdttaq.com&membersignature=vous+pouvez+vous+faire+rembourser+des+frais+mme+si+vous+navez+pas+eu++vous+absenter+du+travail.+le+service+de+ss
トラックバック:http://www.die-seite.com/index.php?a=stats&u=rayfordzaleski1
トラックバック:http://Canamkart.ca/index.php?page=user&action=pub_profile&id=1593646
トラックバック:Rocket League sensation Joyo
トラックバック:http://www.weather.sbm.pw/out/ott-official-25/
トラックバック:Https://Yuniverse.wiki
トラックバック:Directmysocial.com
トラックバック:https://Utahsyardsale.com/author/tuyetzalesk/
トラックバック:Sparxsocial.com
トラックバック:https://Aproblemsquaredwiki.com/User:KerrieLindgren1
トラックバック:seolisTLINKs.Com
トラックバック:advicebookmarks.com
トラックバック:NBC News in diretta streaming gratuito
トラックバック:see this
トラックバック:http://Www.traders.Sblinks.net/News/gaia-total-30/
トラックバック:Gaming.Sblinks.net
トラックバック:http://Www.Outsourcing.Sbm.pw/out/clinica-maxi-dental-21/
トラックバック:Https://Nimmansocial.Com/Story5237458/Energa-Y-Sistemas
トラックバック:click for info
トラックバック:Những chủ đề nào đang là xu hướng hiện nay?
トラックバック:https://Readukrainianbooks.com/user/MarisolWgq/
トラックバック:Mysitesname.com
トラックバック:https://www.oasiskorea.net/Brand/3756591
トラックバック:http://classicalmusicmp3freedownload.com/ja/index.php?title=M_dical_Podiatrique_De_L_estrie
トラックバック:http://www.superstitionism.com/forum/profile.php?id=389912
トラックバック:https://enableelearn.com/?s=&post_type=courses&membersite=httpsFlorilegejardinerie.compaysager&membersignature=Aucun+curiosit+ne+bref+pendant+la+intervalle+du+programme.pnbsp;/ppnbsp;/p+Les+programmes+de+modalits+spciales+de+cot+ne+ralit+pas+c
トラックバック:Socialbraintech.com
トラックバック:LiNGEriEbOoKmArK.CoM
トラックバック:https://Weakfantasy.de/index.php/Benutzer:LavondaSlate84
トラックバック:Linkingbookmark.com
トラックバック:https://wavesocialmedia.com/story1165326/emprunts-d-argent-rapide-sans-enqute-de-crdit-money911
トラックバック:qna.lrmer.com
トラックバック:Актуелне вести на друштвеним мрежама данас
トラックバック:http://Callcenters.Sblinks.net/News/ott-official-22/
トラックバック:http://gijangchurch.org/index.php?mid=board_UvBh53&document_srl=527393
トラックバック:http://www.seasonal.ipt.pw/out/intermezzo-montreal-93/
トラックバック:DialOGoS.wikI
トラックバック:https://Luxuriousrentz.com/top-gear-outfitters-your-one-stop-shop-for-outdoor-Gear-in-canada-4/
トラックバック:Siambookmark.Com
トラックバック:Dzliprojects.wiki
トラックバック:https://Bookmarktiger.com/story15835099/intermezzo
トラックバック:https://livingbooksaboutlife.org/books/User:SantoGreaves17
トラックバック:https://Pipewiki.org/app/index.php/Symptmes_Du_Traumatisme_Crnien_:_Reconnatre_Les_Signaux_D_Alerte
トラックバック:http://luennemann.org/index.php?mod=users&action=view&id=307638
トラックバック:https://Mysitesname.com/story5340018/intermezzo
トラックバック:https://wiki.bigtata.org/index.php/Utilisateur:DanielleDegree
トラックバック:https://Mediawiki.Governancaegestao.Wiki.br/index.php/User:BlythePena1732
トラックバック:brIghTbookmARKs.coM
トラックバック:just click the up coming internet site
トラックバック:https://wiki.castaways.com/wiki/User:BrentK54908189
トラックバック:http://saju.codeway.kr
トラックバック:WASTewiki.Com
トラックバック:Bookmarkinglive.com
トラックバック:https://social-Galaxy.com/story1157475/hesman-garage
トラックバック:http://www.bjkclh.com/Comment/html/?125423.html
トラックバック:http://Www.healthcare-Industry.ipt.pw/out/intermezzo-montreal-71/
トラックバック:www.shirts.bookmarking.site
トラックバック:https://Illinoisbay.com/user/profile/6033379
トラックバック:youtube bugün dünya çapında trend
トラックバック:https://www.volker-rau.de/
トラックバック:https://Zvukiknig.cc/user/AshlyBoisvert43/
トラックバック:http://www.s-miles.com/xe/board_gBNS02/1004784
トラックバック:Sugeriu Olhando
トラックバック:please click the up coming document
トラックバック:http://Www.Flowers.Bookmarking.site/News/vicky-girouard-5/
トラックバック:https://Readukrainianbooks.com/user/UWHDane973210146/
トラックバック:https://okniga.org/user/GabrielleEastham/
トラックバック:my review here
トラックバック:Τάσεις ειδήσεων στο διαδίκτυο σήμερα
トラックバック:ツイッターで話題のニュース
トラックバック:https://trans.hiragana.jp/ruby/http://cloud-dev.mthmn.com/node/250008
トラックバック:Trending nieuws in de wereld van vandaag
トラックバック:http://forum.megi.cz//profile.php?id=2814663
トラックバック:view
トラックバック:read this blog post from keromaissaude.com
トラックバック:https://www.Oasiskorea.net/Brand/3715917
トラックバック:https://Bookmarkswing.com/story16909868/Hesman-Garage
トラックバック:https://sanatandharam.in/index.php/User:LilyStoddard74
トラックバック:Kush është numër 1 në trend në Google?
トラックバック:God-999.com
トラックバック:Alphabookmarking.com
トラックバック:http://cloud-dev.mthmn.com/node/249178
トラックバック:http://Qzfczs.com/comment/html/?301699.html
トラックバック:https://okniga.org/user/Dominic6290/
トラックバック:{link Alternatif Rajabandot}
トラックバック:bOokmArkLoVeS.cOm
トラックバック:Link Alternatif Ahha4d
トラックバック:Suggested Webpage
トラックバック:straight from the source
トラックバック:Full Content
トラックバック:pede toto
トラックバック:BOokmaRKwOrM.COM
トラックバック:Rajabandot login
トラックバック:https://Bookmarkswing.com/story16910087/couvreur-paquette
トラックバック:rajabandot
トラックバック:http://Zjxsnj.cn/comment/html/?112236.html
トラックバック:Pukkabookmarks.com
トラックバック:http://www.S-miles.com/xe/board_gBNS02/1156805
トラックバック:Americaswomenmagazine.xyz
トラックバック:Www.scullycap.com
トラックバック:Dolmie.com
トラックバック:http://Www.Website-Development.Dofollowlinks.org/News/atl-demenagement-3/
トラックバック:pede togel alternatif
トラックバック:for beginners
トラックバック:http://www.hardware.ipt.pw/News/amenagement-denis-42/
トラックバック:http://Gijangchurch.org/index.php?mid=board_UvBh53&document_srl=634974
トラックバック:Www.diywiki.org
トラックバック:Sap.Ient.ai
トラックバック:pede togel
トラックバック:redirect to Mzlgam
トラックバック:Rajabandot link Alternatif
トラックバック:Read Alot more
トラックバック:Socialrus.com
トラックバック:https://forum.Giperplasma.ru/index.php?action=profile;u=562942
トラックバック:wonplay 888
トラックバック:GEtidEALIst.cOm
トラックバック:daftar wonplay 888
トラックバック:Highly recommended Web-site
トラックバック:Checkbookmarks.com
トラックバック:https://Nxlv.ru/user/TiffanyBurgos29/
トラックバック:http://nswiki.svenskasuperserier.se/w/index.php?title=Anvndare:DannChandler379
トラックバック:wonplay 888 Slot
トラックバック:Www.process.dofollowlinks.org
トラックバック:https://classifieds.Exponentialhealth.coop/community/profile/blythemccubbin0/?email=&membersite=httpsPiedconfort.combloguepied-arque&membersignature=span+stylefont-weight:+800;La+fasciite+plantaire+est+un/span+dysfonctionnement+douloureux+du+pied+
トラックバック:http://www.glamstones.Co.kr/sub_06_01/59292
トラックバック:https://www.homecareshoppe.com/a-louer-natif-commercial-et-industriel-de-tous-genres-site-professionnel/
トラックバック:visualizá-lo agora
トラックバック:Kenpoguy.com
トラックバック:http://zjxsnj.cn/comment/html/?115564.html
トラックバック:https://45listing.com
トラックバック:antislave.com
トラックバック:Mais sugestões
トラックバック:https://heechunkim.Co.kr/board_qKHj18/287297
トラックバック:http://Gijangchurch.org/index.php?mid=board_UvBh53&document_srl=725855
トラックバック:Runsexme.ru
トラックバック:http://Rebelscon.com/profile.php?id=1612333
トラックバック:Www.beach.sbm.pw
トラックバック:Https://Kmicc.Com
トラックバック:Www.Somangchurch.org
トラックバック:https://Unitedindia.info/forums/topic/outils-de-securite-masques-chirurgical-jetable-a01400-50-unites/
トラックバック:Mediasocially.com
トラックバック:https://tvsocialnews.com/story1146180/cim-investigacin
トラックバック:https://Apeguebremariam.org/community/?wpfs=&membersite=httpsAvantisleep.comproductslivone&membersignature=76++78+pouces+de+extensif+par+quatre-vingt+pouces+de+long+pour+un+matelas++King+.+Une+chambre+principale+den+tout+a+cas+10+x+10+ft+carrs+ser
トラックバック:similar website
トラックバック:moved here
トラックバック:Www.Matthew-Morris.com
トラックバック:Bookmark-TemplaTe.COm
トラックバック:http://luennemann.org/index.php?mod=users&action=view&id=335491
トラックバック:http://Virusclan.de/index.php?mod=users&action=view&id=5145
トラックバック:wonplay 888 Login
トラックバック:Bn.trEndI.toP
トラックバック:http://Www.Die-Seite.com/index.php?a=stats&u=sharylwillilams
トラックバック:this
トラックバック:http://www.Rebelscon.com/profile.php?id=1619973
トラックバック:{Link Rajabandot}
トラックバック:https://one.new-tkf.xyz/user/MurrayOiz392052/
トラックバック:head to 7prbookmarks
トラックバック:BOUCHESOcIAl.cOm
トラックバック:http://cloud-Dev.mthmn.com/node/249941
トラックバック:http://www.photography.ipt.pw
トラックバック:https://Getidealist.com
トラックバック:https://Www.Oasiskorea.net/Brand/3818295
トラックバック:http://Theglobalfederation.org/profile.php?id=2014039
トラックバック:https://Kbookmarking.com/story15856295/hesman-garage
トラックバック:Vipsbay.Net
トラックバック:http://wikivicente.X10Host.com/index.php/Article_Title
トラックバック:http://website-development.dofollowlinks.org/News/dominique-patrice/
トラックバック:https://Ezmarkbookmarks.com/story15894521/soljit-salesforce-partner-of-your-Transformation
トラックバック:visit my web page
トラックバック:https://Bookmarkplaces.com/story15803669/couvreur-paquette
トラックバック:WwW.JEromEBarAY.Com
トラックバック:https://lingeriebookmark.com/story5370694/energa-y-sistemas
トラックバック:Allyourbookmarks.com
トラックバック:Www.radio.dofollowlinks.org
トラックバック:página da Internet
トラックバック:Baidubookmark.com
トラックバック:https://Bookmarkedblog.com/story16206641/servicios-de-transporte-terrestre-en-bogot-vanspremium
トラックバック:Our Site
トラックバック:Bookmarkmoz.com
トラックバック:http://Cloud-Dev.Mthmn.com/node/246037
トラックバック:http://Www.Zilahy.info/wiki/index.php/Pizza_Plat_D_or_Joliette_Eaterie_Opening_Several_Hours_And_Critical_Reviews
トラックバック:https://resetlifestyleproductsuk.com/communiquer-avec-le-repertoire-toxicologique-cnesst/
トラックバック:https://biowiki.clinomics.com/index.php/User:VictorinaBack
トラックバック:go to this web-site
トラックバック:onsale.Tawansmile.com
トラックバック:Avfoch.com
トラックバック:https://Bookmarklethq.com/story15874652/emprunts-d-argent-rapide-sans-enqute-de-crdit-money911
トラックバック:WwW.mISSIOnCA.OrG
トラックバック:http://Avtpoligraf.ru/content/lentrepot-du-cadre-decorations-murales
トラックバック:http://leonblog.net/member.asp?action=view&memName=Joeann91W644834395420
トラックバック:https://Bookmarkshq.com/story16930024/amnagement-denis-paysagiste–montral-laval
トラックバック:Read the Full Document
トラックバック:check over here
トラックバック:bIGMasteRLiFeStYle.Com
トラックバック:jual pbn murah
トラックバック:http://classicalmusicmp3Freedownload.com/ja/index.php?title=:Sienna2881
トラックバック:http://Cloud-Dev.Mthmn.com/node/28300
トラックバック:Http://Www.die-seite.com/index.Php?a=Stats&u=niamhsaenz383
トラックバック:jasa seo specialist
トラックバック:http://www.ruanjiaoyang.com/member.asp?action=view&memName=JerrellRomo090199101
トラックバック:Telugusaahityam.com
トラックバック:click this over here now
トラックバック:https://Bookmarkboom.com/story15774164/emprunts-d-argent-rapide-sans-enqute-de-crdit-money911
トラックバック:https://Avfoch.com/author/hanscurley4/
トラックバック:Www.geNeRATe.SBM.pw
トラックバック:http://Www.Superstitionism.com/forum/profile.php?id=230657
トラックバック:https://Hindibookmark.com/story17032998/cim-investigacin
トラックバック:https://Kmicc.com/index.php?mid=certi&document_srl=692198
トラックバック:beli backlink berkualitas
トラックバック:Login wonplay 888
トラックバック:siNGnalSocial.com
トラックバック:https://www.allclanbattles.com/
トラックバック:https://mmhsmassageme.com/index.php?page=user&action=pub_profile&id=5869306
トラックバック:https://Ztndz.com/story17526869/entrepreneur-spcialis-en-finition-de-bton-la-truelle-d-or
トラックバック:Socialbuzzmaster.com
トラックバック:https://Resetlifestyleproductsuk.com/entreposage-jcs/
トラックバック:https://Www.oasiskorea.net/Brand/3945867
トラックバック:http://calsouthchurch.org/board_Txxk18/703125
トラックバック:Cbz.Minzdravao.ru
トラックバック:rajabandot togel
トラックバック:http://Www.zilahy.Info
トラックバック:https://wiki.unionoframblers.com/index.php/Top_Machine__Glaons
トラックバック:Virusclan.de
トラックバック:Pillowcovers.sblinks.net
トラックバック:http://Www.Reform.Bookmarking.site/News/dermka-clinik-23/
トラックバック:Https://Fellowfavorite.Com/Story16570555/Hesman-Garage
トラックバック:https://wiki.vie.today/index.php?title=:MargaretaMoonlig
トラックバック:http://www.Die-seite.com/index.php?a=stats&u=wilbertnickle83
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=303864
トラックバック:https://topsearch24H.com/search/Titre+Tout+Ce+Que+Vous+Devez+Savoir+Sur+Le+Pointage+De+Crdit+Dimpt+Par+Dmnagement+De+Revenu+Qubec
トラックバック:Guideyoursocial.com
トラックバック:http://Shinyangm.com/bbs/board.php?bo_table=free&wr_id=135747
トラックバック:http://Www.Helpdesk.Ipt.pw/News/couvreur-paquette-6/
トラックバック:https://classifieds.Exponentialhealth.coop/community/?email=&membersite=httpsbeautybomb.cofrcreme-lissante-pour-cheveux&membersignature=the+fractionated+coconut+oil+absorbs+deeply+and++a+hrefhttps://beautybomb.co/fr/creme-lissante-pour-cheveux/+re
トラックバック:why not try here
トラックバック:jasa traffic organic
トラックバック:Sites2000.com
トラックバック:https://theglobalfederation.org/profile.php?id=1951441
トラックバック:http://www.website-development.dofollowlinks.Org/
トラックバック:http://theglobalfederation.org
トラックバック:website
トラックバック:http://avtpoligraf.ru/content/sen-aller-de-19-99-pour-un-protege
トラックバック:https://Kmicc.com/index.php?mid=certi&document_srl=692651
トラックバック:http://Gijangchurch.org/index.php?mid=board_UvBh53&document_srl=770164
トラックバック:Mysterybookmarks.com
トラックバック:simply click nebenwelten.net
トラックバック:https://Mediajx.com/story17161337/entrepreneur-spcialis-en-finition-de-bton-la-truelle-d-or
トラックバック:Https://Nybookmark.Com/Story17008386/AmNagement-Denis-Paysagiste–MontrAl-Laval
トラックバック:http://Die-Seite.com
トラックバック:https://infodin.Com.br/index.php/Couvreur_R_sidentiel
トラックバック:http://www.computer-science.sbm.pw/News/vicky-girouard-14/
トラックバック:http://www.consulting.bookmarking.site/News/mon-inspection-5/
トラックバック:Naturalbookmarks.com
トラックバック:http://czxawb.cn/comment/html/?70398.html
トラックバック:http://www.drsbook.co.kr/board/7253700
トラックバック:Fantasyroleplay.co
トラックバック:Www.framefounder.Com
トラックバック:pinnaclebattleship.com
トラックバック:http://S741690.Ha003.T.Justns.ru/index.php?subaction=userinfo&user=CandidaZla
トラックバック:http://Avtpoligraf.ru/content/masque-jetable-0
トラックバック:https://Breitband-Wiki.de/index.php?title=Moulin__Lame_Par_Grains_De_Caf_pices_Et_Fines_Herbes_Noir_Salton
トラックバック:http://Www.Diywiki.org/index.php/clairage
トラックバック:Www.information-Brokers.sblinks.net
トラックバック:http://Sl860.com/comment/html/?209169.html
トラックバック:https://avtpoligraf.ru/content/avis-sur-Institut-pure-excellence-1
トラックバック:pedetogel
トラックバック:https://askreader.co.uk/43084/prpar-employs-dans-mauvaise-cote-de-crdit-au-canada
トラックバック:his comment is here
トラックバック:wWw.homeCaRESHOpPe.cOM
トラックバック:http://information-Brokers.sblinks.net/News/atl-demenagement-11/
トラックバック:www.loans.ipt.pw
トラックバック:jasa seo website judi online
トラックバック:Biconsultingpro.com
トラックバック:Www.child-health.ipt.pw
トラックバック:https://pipewiki.org/app/index.php/User:CherylFultz
トラックバック:http://Jeromebaray.com/afm/wiki/index.php/Utilisateur:CristineElz
トラックバック:Forum.vkmoravia.cz
トラックバック:click the up coming website
トラックバック:Daftar Ahha4d
トラックバック:clique com o seguinte post
トラックバック:Wiki.Bigtata.Org
トラックバック:pede togel link alternatif
トラックバック:http://Afcantarelle.org/index.php?title=User:KandisRae5239
トラックバック:http://Sh.Ri.L.Lw.Q.Zu@nkuk21.co.uk/?document_srl=7542851
トラックバック:clique para investigar
トラックバック:jasa seo backlink
トラックバック:http://www.Die-Seite.com/index.php?a=stats&u=harlanbirnie
トラックバック:onlinEsChooL.BOOkmArkiNg.SItE
トラックバック:http://Fridayad.in/user/profile/1969771
トラックバック:Www.sports.bookmarking.site
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1542942
トラックバック:https://Okniga.org/user/FannieLandry/
トラックバック:http://theglobalfederation.org/profile.php?id=2033074
トラックバック:jasa backlink bergaransi
トラックバック:you could check here
トラックバック:https://Bookmarketmaven.com/story15993250/entrepreneur-spcialis-en-finition-de-bton-la-truelle-d-or
トラックバック:Modernizacion.Archivonacional.cl
トラックバック:https://Www.Vander-horst.nl/wiki/User:KrystalNies
トラックバック:Wisma bet login judi
トラックバック:https://Www.kenpoguy.com/phasickombatives/profile.php?id=1435381
トラックバック:http://sl860.com/comment/html/?291502.html
トラックバック:Https://Rnma.Xyz/
トラックバック:http://www.Zjxsnj.cn/comment/html/?167669.html
トラックバック:https://Dzliprojects.wiki/index.php/User:Eugenio48A
トラックバック:https://apeguebremariam.org/community/?wpfs=&membersite=httpsamenagementdenis.comexpert-en-toit-terrasse-a-vimont&membersignature=Lamnagement+paysager+fait+partie+importante+de+lentretien+hors+de+votre+possession+que+vous+soyez+propritaire+dune+ma
トラックバック:https://Throbsocial.com/story17291968/cim-investigacin
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1548051
トラックバック:https://enableelearn.com/?s=&post_type=courses&membersite=httpsFlorilegejardinerie.comboutiquepilea-peperomioides-2-5po&membersignature=uEn+plus+dapporter+dune/u+fracheur+et+du+saveur++vos+plats+ou+vos+boissons+ces+cultures+embaument+la+Maison
トラックバック:http://www.agchem.co.kr/freeboard/1754551
トラックバック:http://www.engineering.dofollowlinks.org/news/couvreur-paquette-7/
トラックバック:Offwiki.Org
トラックバック:agen cuan
トラックバック:jual jasa backlink murah
トラックバック:http://diywiki.org/index.php/User:LaverneBeverly
トラックバック:https://Weakfantasy.de/index.php/Photographie_Rajeunissement_Et_Boutons_Thermage_Lvres_Pulpeuses_Ulthera_Et_Thermocoagulation
トラックバック:Worldlistpro.Com
トラックバック:https://Drclydewilson.com/community/?wpfs=&membersite=httpsUnick.ca&membersignature=span+stylefont-style:+italic;Nos+routines+de+nettoyage+et/span+nos+cours+de+qualit+nous+donnent+une+socit+parfaite+et+efficacement+huile.+Le+contrle+qualit+de+notr
トラックバック:http://Forum.Prolifeclinics.ro/profile.php?id=10934
トラックバック:https://Okniga.org/user/SusanneNewell1/
トラックバック:Www.guidemagazine.org
トラックバック:jasa backlink pbn judi
トラックバック:https://Wiki.freeneuropathology.org/index.php?title=Article_Title
トラックバック:https://manu-Auare.ru/estelacambag
トラックバック:http://Www.Zjxsnj.cn/comment/html/?170885.html
トラックバック:https://Wiki.rr206.de/index.php?title=Benutzer:Maureen24Q
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1550340
トラックバック:Going On this site
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1542814
トラックバック:Http://Luennemann.Org/Index.Php?Mod=Users&Action=View&Id=346897
トラックバック:Read This method
トラックバック:jasa backlink website
トラックバック:their website
トラックバック:Getsocialpr.Com
トラックバック:simply click the up coming post
トラックバック:https://Binary.Copy-Trade.fun/?qa=319685/boucle-doreille-enfant
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1548766
トラックバック:https://bookmarkwuzz.com/story15901391/gelka-soluciones
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1556102
トラックバック:http://Www.Online-Teaching.Sblinks.net/out/dominique-patrice-15/
トラックバック:jasa halaman 1 google
トラックバック:https://King.az/user/AlbertoRagland8/
トラックバック:cuan slot 88
トラックバック:over here
トラックバック:https://trabalhadoresindependentes.com/author/peggy52690/
トラックバック:Www.fantasyroleplay.co
トラックバック:Www.Driftpedia.Com
トラックバック:https://moravian.Bucknell.edu/transcriptions/index.php?title=Entretien_M_nager_R_sidentiel_Et_Industriel__Montr_al
トラックバック:Https://Okniga.Org
トラックバック:backlink judi
トラックバック:http://luennemann.org/index.php?mod=users&action=view&id=347520
トラックバック:https://Bookmarkpressure.com/story15826866/cim-investigacin
トラックバック:http://die-Seite.com/index.php?a=stats&u=lavadalin4373
トラックバック:http://www.hospitality.Dofollowlinks.org/News/couvreur-paquette-11/
トラックバック:https://Zvukiknig.cc/user/Alexandra5186/
トラックバック:http://luennemann.org/index.php?mod=users&action=view&id=347745
トラックバック:Www.trimmers.Ipt.pw
トラックバック:https://Bookmarkja.com/story17138271/soljit-salesforce-partner-of-your-transformation
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1545791
トラックバック:beli backlink murah
トラックバック:Live4Christnetworks.Com
トラックバック:http://Cloud-Dev.Mthmn.com/node/284519
トラックバック:https://Sites2000.com/story5260724/emprunts-d-argent-rapide-sans-enqute-de-crdit-money911
トラックバック:sneak a peek at this website
トラックバック:jasa page one google
トラックバック:new content from socialbookmarkgs.com
トラックバック:https://Okniga.org/user/DeneseRamsbotham/
トラックバック:Throbsocial.com
トラックバック:Hubwebsites.com
トラックバック:https://Connectngrow.org/myforum/profile.php?id=66916
トラックバック:Todaybookmarks.com
トラックバック:https://Outhistory.wwu.edu/wiki/User:VirginiaCoombe
トラックバック:jasa backlink berkualitas
トラックバック:visit Mnobookmarks`s official website
トラックバック:http://qzfczs.com/comment/html/?316403.html
トラックバック:Https://maga.Wiki
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1550757
トラックバック:https://wiki.hstkb.sch.id/index.php?qa=30366&qa_1=obtenir-un-prt-dargent-pas-de-enqute-de-pointage-de-crdit
トラックバック:content
トラックバック:https://wiki.vie.today/index.php?title=Delicacies_Moderne_Review_Choisir_L_Ensemble_Des_Meubles_Tout_Autant_Que_Armoires_Sobre_Cuisine
トラックバック:http://luennemann.org/index.php?mod=users&action=view&id=346926
トラックバック:http://Www.zjxsnj.cn/comment/html/?169661.html
トラックバック:https://Maga.wiki/index.php/User:JasperKrier6
トラックバック:http://www.Die-seite.com
トラックバック:http://Xiamenyoga.com/comment/html/?185890.html
トラックバック:Continued
トラックバック:Classifieds.Exponentialhealth.coop
トラックバック:http://Qzfczs.com/comment/html/?321592.html
トラックバック:http://Www.gotanproject.net/node/22461012?—————————98926205Content-Disposition:form-data;name=titleOreillerPourUnAideDansToutesLesPositionsDeSommeil—————————98926205Content-Disposition:form-data;name=bodyspanstyle=font-
トラックバック:https://brilliantcollections.com/pneu-et-jante/
トラックバック:https://Domainnamesseo.com/listing/emprunts-dargent-rapide-sans-enquete-de-credit-money911-532917
トラックバック:Bookmarknap.com
トラックバック:http://die-seite.com/index.php?a=stats&u=dwight5585
トラックバック:http://drsbook.Co.kr/board/6413491
トラックバック:Portal.Virtueliving.org
トラックバック:http://www.die-Seite.com/index.php?a=stats&u=dhedino8989347
トラックバック:http://Register.Ipt.pw/News/ott-official-25/
トラックバック:look at this now
トラックバック:http://Cloud-Dev.Mthmn.com/node/297332
トラックバック:http://Cloud-Dev.mthmn.com/node/300067
トラックバック:http://www.die-seite.com/index.php?a=stats&u=shayna51l8244175
トラックバック:Madbookmarks.com
トラックバック:moravian.Bucknell.Edu
トラックバック:Growthbookmarks.com
トラックバック:Wiishlist.com
トラックバック:http://gijangchurch.org/index.php?mid=board_UvBh53&document_srl=1087243
トラックバック:http://forum.prolifeclinics.ro/profile.php?id=155999
トラックバック:https://onsale.tawansmile.com/index.php?action=profile;u=12212
トラックバック:http://luennemann.org/index.php?mod=users&action=view&id=353152
トラックバック:Learn More Here
トラックバック:https://Www.imdipet-Project.eu/groupes/embracing-canadian-culture-a-guide-to-canadian-cultural-events/
トラックバック:http://Www.Sxlopw.cn/comment/html/?237096.html
トラックバック:http://cloud-Dev.mthmn.com/node/304394
トラックバック:http://virusclan.de/index.php?mod=users&action=view&id=21901
トラックバック:https://Nxlv.ru/user/LawannaStell/
トラックバック:https://blog.Isoc.sn/?option=com_k2&view=itemlist&task=user&id=3353813
トラックバック:Http://Www.Drsbook.Co.Kr/Board/7288946
トラックバック:UK IMMIGRATION LAWYER IN US
トラックバック:https://mzlgam.com/index.php?action=profile;u=124061
トラックバック:jual jasa backlink
トラックバック:thebookmarkid.com
トラックバック:https://Resetlifestyleproductsuk.com/emplois-par-entretien-menager/
トラックバック:Www.kmicc.com
トラックバック:Http://God-999.com/board_ysKC49/713098
トラックバック:Megashop.work
トラックバック:https://apeguebremariam.org/community/?wpfs=&membersite=httpspoupartsyndic.caconsolidation-dettesqcsainte-therese&membersignature=Sous-titres+:pnbsp;/ppnbsp;/p+1.+Pourquoi+votre+cote+de+crdit+est+importante+par+payer+de+fric+pour+une+hypothquepnbs
トラックバック:Sigmachiiu.com
トラックバック:Mariskamast.net
トラックバック:Http://Detroitwomenmag.Xyz/Blogs/Viewstory/152296
トラックバック:https://Illinoisbay.com/user/profile/6244207
トラックバック:Http://www.Rebelscon.com
トラックバック:http://Gijangchurch.org/index.php?mid=board_UvBh53&document_srl=1096901
トラックバック:Https://www.Kmicc.com
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1548437
トラックバック:https://Isotrope.cloud/index.php/User:DeeGye746334484
トラックバック:Thekiwisocial.com
トラックバック:Fastwitchfitness.com
トラックバック:http://www.shavers.sblinks.net/News/ott-official-12/
トラックバック:click the up coming web site
トラックバック:Bookmarkingalpha.com
トラックバック:http://www.die-seite.com/index.php?a=stats&u=darcyelmore27
トラックバック:http://Cloud-Dev.Mthmn.com/node/326167
トラックバック:https://Okniga.org/user/CierraWoodfull4/
トラックバック:Https://Techonpage.Com/Story1182799/Cuisines-Denis-Couture
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1597380
トラックバック:Bookmarkbirth.com
トラックバック:http://Canamkart.ca/index.php?page=user&action=pub_profile&id=1732914
トラックバック:http://cloud-dev.mthmn.com/node/282833
トラックバック:http://www.zjxsnj.cn/comment/html/?189956.html
トラックバック:please click the following internet site
トラックバック:please click the following article
トラックバック:https://Classifieds.Exponentialhealth.coop/community/?email=&membersite=httpspaisi.caencollectionspillows&membersignature=lanalyse+de+ltude+a+t+ralise+dans+le+monde+entier+et+prsente+actuelles+et+traditionnelles+de+lexpansion+de+lanalyse+analyse+d
トラックバック:look at these guys
トラックバック:https://heechunkim.co.kr/board_qKHj18/244243
トラックバック:Highly recommended Internet site
トラックバック:Https://Socialmphl.Com
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1551578
トラックバック:https://Dailybookmarkhit.com/story15939423/hesman-garage-boucherville
トラックバック:http://www.Die-seite.com/index.php?a=stats&u=stephanywillard
トラックバック:22446688.Cn
トラックバック:https://motline.com/index.php?mid=rent_counseling&document_srl=2667719
トラックバック:https://virus.Win32.wiki/wiki/Btisse_Commerciale
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1547414
トラックバック:https://Manu-auare.ru/madeleinerup
トラックバック:http://Virusclan.de/index.php?mod=users&action=view&id=22964
トラックバック:http://Www.customer-service.sblinks.net/News/amenagement-denis-80/
トラックバック:Kcwomenmag.xyz
トラックバック:Atozbookmarkc.com
トラックバック:Listingpanda.ca
トラックバック:Thefairlist.com
トラックバック:http://www.gotanproject.net/node/22488259?—————————716503764792556Content-Disposition:form-data;name=titleSpcialistesDeLaAmliorationDeL’habitatAmliorationDeL’habitatAceh—————————716503764792556Content-Disposition:form
トラックバック:http://www.hardware.sbm.pw/out/ott-official-19/
トラックバック:Socialclubfm.com
トラックバック:recent post by Cloud-Dev.Mthmn.com
トラックバック:http://Hospitality.dofollowlinks.org/user/carleycuni/
トラックバック:Bookmarkspedia.com
トラックバック:http://Virusclan.de/index.php?mod=users&action=view&id=22082
トラックバック:bookmarkmiracle.com
トラックバック:http://www.Jeromebaray.com/afm/wiki/index.php/Prt_Futur_Entrepreneur
トラックバック:http://Ruanjiaoyang.com/member.asp?action=view&memName=LarryKauffmann02
トラックバック:https://luxuriousrentz.Com/Create-an-exquisite-backyard-Terrace-a-perfect-outdoor-retreat
トラックバック:https://centrofreire.com/blog/index.php?entryid=24999
トラックバック:Suggested Web page
トラックバック:http://oxm.tw/xoops/modules/profile/userinfo.php?uid=795695
トラックバック:https://Www.Imdipet-Project.eu/groupes/finding-your-dream-home-a-guide-to-the-best-homes-magazines-in-canada/
トラックバック:Worldsocialindex.com
トラックバック:https://oneability.ca/forums/topic/developing-an-effective-engagement-plan-with-salesforce/
トラックバック:wwW.GLaMsTOneS.Co.KR
トラックバック:Mountainrootsonline.com
トラックバック:Enableelearn.com
トラックバック:http://www.Zjxsnj.cn/comment/html/?195358.html
トラックバック:Bookmarksknot.com
トラックバック:http://Zjxsnj.cn/comment/html/?187613.html
トラックバック:click the up coming website page
トラックバック:http://Demos.gamer-Templates.de/specialtemps/clansphere20114Sdemo01/index.php?mod=users&action=view&id=5890326
トラックバック:https://fellowfavorite.com/story16643671/servicios-de-transporte-terrestre-en-bogot-vanspremium
トラックバック:go directly to cloud-dev.mthmn.com
トラックバック:click the up coming webpage
トラックバック:http://cloud-dev.mthmn.com/node/321807
トラックバック:please click the next document
トラックバック:https://Wiki.nerdbird.media/index.php?title=User:JennyAddis084
トラックバック:http://wiki.quanticsystems.com.br/index.php/User:Edison9263
トラックバック:Www.islandcrowd.com
トラックバック:http://latenitetip.com/index.php?page=user&action=pub_profile&id=44456
トラックバック:read more
トラックバック:http://ruanjiaoyang.com/member.asp?action=view&memName=CamillaLevering
トラックバック:http://Www.Rebelscon.com/profile.php?id=1633698
トラックバック:https://Zvukiknig.cc/user/WilfredoUther/
トラックバック:more tips here
トラックバック:http://Gedankengut.one/
トラックバック:https://Www.Kenpoguy.com/phasickombatives/profile.php?id=1450844
トラックバック:https://Morphonic-Records.com/community/profile/arnulfoolivarez/
トラックバック:https://Lingeriebookmark.com/story5425063/soljit-salesforce-partner-of-your-transformation
トラックバック:Http://dallaswomenmag.Xyz/
トラックバック:http://Demos.Gamer-Templates.de/specialtemps/clansphere20114Sdemo01/index.php?mod=users&action=view&id=5891615
トラックバック:jasa backlink murah berkualitas
トラックバック:https://telearchaeology.org/TAWiki/index.php/User:Louise82Q15208
トラックバック:http://Www.Gotanproject.net/node/22489394?—————————40225344335Content-Disposition:form-data;name=titleMdecinsDeMnageLaval—————————40225344335Content-Disposition:form-data;name=bodyEtquecesoitounontoutefoisunerfrencepour
トラックバック:http://Virusclan.de/index.php?mod=users&action=view&id=23080
トラックバック:bookmarkbooth.com
トラックバック:http://Die-Seite.com/index.php?a=stats&u=florene08m
トラックバック:getsoCialSoUrCe.COm
トラックバック:Demos.Gamer-Templates.De
トラックバック:http://Www.Die-Seite.com/index.php?a=stats&u=antwanmorisset5
トラックバック:Dftsocial.com
トラックバック:http://Saju.codeway.kr/index.php/Enseignes_Commerciales_Auvent_Afficheurs_Del_Et_Lettre_Channel
トラックバック:http://Forum.Prolifeclinics.ro/profile.php?id=163534
トラックバック:helpful hints
トラックバック:sneak a peek at this web-site.
トラックバック:click for more info
トラックバック:https://Www.Oasiskorea.net/Brand/4962765
トラックバック:https://Xdpascal.com/index.php/User:Sang46Z63123577
トラックバック:https://Www.Homecareshoppe.com/kidicomfort-matelas-matelas-facile-coton-naturel/
トラックバック:www.Xjykj.Cn
トラックバック:http://Virusclan.de/index.php?mod=users&action=view&id=23730
トラックバック:ELEARNing.hCBEAuTy.CoM
トラックバック:https://pr7bookmark.com/story15994599/vanspremium
トラックバック:https://Brilliantcollections.com/fifty-three-meilleures-idees-sur-revetement-mur/
トラックバック:https://apeguebremariam.org/community/?wpfs=&membersite=httpsGoodlifeloan.compret-sans-enquete&membersignature=2+to+3+repayments+can+be+found+primarily+based+on+your+pay+frequency+at+no+further+price+or+charges+up+to+62+days.+When+you+apply+for+ca
トラックバック:https://Www.imdipet-project.eu
トラックバック:https://Nimmansocial.com/story5300028/papeterie-gilbert-jeux-a-g
トラックバック:http://Wiki.Moebius.Com.br/index.php/Pourquoi_Mis_Sur_Des_Images_Sur_Mon_Site_Web
トラックバック:http://Qzfczs.com/comment/html/?331646.html
トラックバック:https://Www.Oasiskorea.net/Brand/5037330
トラックバック:http://Www.Zjxsnj.cn/comment/html/?191612.html
トラックバック:https://Classifieds.Exponentialhealth.coop/community/profile/wbfiris11069659/?email=&membersite=httpspoupartsyndic.caproposition-de-consommateur-a-plan-bouchard&membersignature=img+srchttps://p.turbosquid.com/ts-thumb/tj/uUQi5U/ZILMjHWa/a1720002/j
トラックバック:what is it worth
トラックバック:https://Socialbookmarkgs.com/story15923640/emondage-prestige
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=347758
トラックバック:on the main page
トラックバック:Continue Reading
トラックバック:jasa seo slot
トラックバック:https://bookmarkbirth.com/story15274954/naturothrapie–laval-mackandal
トラックバック:simply click the following page
トラックバック:https://Socialmediainuk.com/story15804313/entrepreneur-en-construction
トラックバック:https://aproblemsquaredwiki.com/User:NPIBerry2386
トラックバック:https://Okniga.org/user/ClemmieCheyne/
トラックバック:http://gijangchurch.org/index.php?mid=board_UvBh53&document_srl=1182127
トラックバック:https://bookmark-vip.com/story15904413/Dermka-clinik
トラックバック:Https://Classifieds.Exponentialhealth.Coop
トラックバック:https://Thefairlist.com/story5610961/bpc
トラックバック:Finopsfirst.org
トラックバック:https://onlybookmarkings.com/story15903081/cuisines-denis-couture
トラックバック:https://Socialrator.com/story5736502/roi-recreation-outfitters
トラックバック:http://Cloud-dev.mthmn.com/node/285577
トラックバック:http://Raleighwomenmag.xyz
トラックバック:http://cloud-dev.Mthmn.com/node/340072
トラックバック:https://infodin.com.br/index.php/User:CaraStevenson0
トラックバック:Bookmarkshut.Com
トラックバック:http://www.xjykj.cn/comment/html/?435350.html
トラックバック:http://Gotanproject.net/node/22494420?—————————326766121Content-Disposition:form-data;name=titleRenouvellementdePrtHypothcaire:CommentMettreJourVotrePrt—————————326766121Content-Disposition:form-data;name=bodyimgsrc=htt
トラックバック:https://Yoga.wiki/index.php/User:JaiPagan25494
トラックバック:http://Forum.Prolifeclinics.ro/profile.php?id=163837
トラックバック:https://Sparxsocial.com/story5690253/naturothrapie–laval-mackandal
トラックバック:https://Sustainabilipedia.org/index.php/User:AbbyFerretti
トラックバック:http://Gotanproject.net/node/22491036?—————————1746084100809Content-Disposition:form-data;name=titleTitre:Conseilspourunbondmnagementetunebonneinstallation—————————1746084100809Content-Disposition:form-data;name=bodyUnd
トラックバック:https://Okniga.org/user/AmyS421089246438/
トラックバック:mouse click the following article
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=354927
トラックバック:http://Gijangchurch.org/index.php?mid=board_UvBh53&document_srl=1236618
トラックバック:Johsocial.com
トラックバック:just click the following post
トラックバック:Telebookmarks.com
トラックバック:https://king.az/user/OlenStobie40/
トラックバック:https://Bookmarksurl.com/story1194483/spcialistes-du-dmnagement-atl
トラックバック:click the up coming web page
トラックバック:http://www.khaan.net/process/526387
トラックバック:click through the next webpage
トラックバック:https://Wiki.sports-5.ch/index.php?title=Anick_Snyder_Micropigmentation_Lashes__Heyspa_Ca
トラックバック:https://www.kmicc.com/index.php?mid=certi&document_srl=1368105
トラックバック:https://socialbuzzfeed.com/story1213811/hesman-garage-boucherville
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1544934
トラックバック:https://Bookmark-dofollow.com/story17390529/reinco
トラックバック:SociAlmPhL.Com
トラックバック:internet
トラックバック:http://theglobalfederation.org/profile.php?id=2045226
トラックバック:here are the findings
トラックバック:https://get-social-now.com/story1136254/naturothrapie–laval-mackandal
トラックバック:Exactlybookmarks.com
トラックバック:Www.science.sblinks.net
トラックバック:Topsearch24H.com
トラックバック:https://thekiwisocial.com/story1285656/soljit-salesforce-partner-of-your-transformation
トラックバック:https://Pipewiki.org/app/index.php/User:LemuelMesa37
トラックバック:http://www.die-seite.com/index.php?a=stats&u=hxrthalia8
トラックバック:redirect to Www.die-Seite.com
トラックバック:http://www.Sxlopw.cn/comment/html/?243279.html
トラックバック:https://Bookmarketmaven.com/story16018763/tres-amigos-outfitters
トラックバック:Letusbookmark.com
トラックバック:http://Www.Gotanproject.net/node/22496604?—————————9065305965Content-Disposition:form-data;name=titleLaFormationenNaturopathieLaval:UnParcoursVersuneApprocheNaturelled’uneSant—————————9065305965Content-Disposition:form
トラックバック:http://cloud-Dev.mthmn.com/node/311426
トラックバック:https://social-Medialink.com/story1204261/naturothrapie–laval-mackandal
トラックバック:http://www.Images.bookmarking.site/News/emondage-prestige-23/
トラックバック:https://letusbookmark.com/story17051609/plus-pour-les-planchers-more-4-floors
トラックバック:Learn Alot more
トラックバック:http://God-999.com/board_ysKC49/863513
トラックバック:https://Isotrope.cloud/index.php/User:BarbraLove57
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1600894
トラックバック:mouse click the up coming web site
トラックバック:http://Saju.codeway.kr/index.php/User:WinnieMarina813
トラックバック:Bookmark-share.com
トラックバック:https://Socialskates.com/story16572875/magik-loans
トラックバック:http://qzfczs.com/comment/html/?322504.html
トラックバック:https://classifieds.exponentialhealth.coop/community/profile/eloycrombie3602/?email=&membersite=httpsMichelbergeronrenovations.comvilleboucherville&membersignature=Des+serrures+et+poignes+par+tous+les+budgets+mettant+ainsi+la+touche+finale++votre+
トラックバック:www.Khaan.net
トラックバック:click the next internet site
トラックバック:http://Cloud-dev.Mthmn.com/node/352596
トラックバック:https://Mbsre.com/forums/users/torstensanderson/
トラックバック:https://Sparxsocial.com/story5706136/transactions-immobilires–gatineau-dominique-patrice
トラックバック:https://throbsocial.com/story17319751/construction-labrie
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1594526
トラックバック:https://www.Offwiki.org/wiki/User:LilaPagan27247
トラックバック:https://procesal.cl/index.php/User:RoseannaHenderso
トラックバック:https://Bookmarkboom.com/story15832071/xnon-enseignes-clairage
トラックバック:visit the next web site
トラックバック:Https://Sustainabilipedia.Org
トラックバック:https://Taupi.org/index.php?title=User:Nannie11T7
トラックバック:https://Checkbookmarks.Com
トラックバック:Www.23ebook.com
トラックバック:www.imdipet-project.Eu
トラックバック:http://demos.gamer-templates.de/specialtemps/clansphere20114Sdemo01/index.php?mod=users&action=view&id=5893705
トラックバック:https://Travialist.com/story5694597/mackandal
トラックバック:http://Gotanproject.net/node/22500465?—————————92559051679405696Content-Disposition:form-data;name=titleSanctionparl’abattaged’boissansautorisationlgale—————————92559051679405696Content-Disposition:form-data;name=body
トラックバック:Www.Ruanjiaoyang.com
トラックバック:https://rnma.Xyz
トラックバック:http://sdswrj.cn/comment/html/?32468.html
トラックバック:check here
トラックバック:https://my-social-Box.com/story1187766/tailored-suit-paris
トラックバック:simply click the following internet page
トラックバック:jasa backlink murah dan berkualitas
トラックバック:https://Bookmarkstumble.com/story17100008/oregon-lemon-law
トラックバック:Tripsbookmarks.com
トラックバック:http://www.records-research.sblinks.net/News/atl-demenagement-9/
トラックバック:https://Classifieds.Exponentialhealth.coop/community/?email=&membersite=httpsapplicationmp.compre-traitement-au-phosphate-de-fer-a-sainte-therese&membersignature=img+srchttps://img-new.cgtrader.com/items/4189082/e94ff5edb8/large/eagle-of-saint-joh
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1642019
トラックバック:socialmediastore.net
トラックバック:http://forum.prolifeclinics.ro/profile.php?id=170379
トラックバック:Jasa Followers Threads
トラックバック:http://www.register.sbm.pw/News/la-bouticaire-32/
トラックバック:http://www.gedankengut.one/index.php?title=User:ReggiePlate587
トラックバック:http://Theglobalfederation.org/profile.php?id=2039574
トラックバック:https://Bookmarkport.com/story17376288/entrepreneur-en-construction
トラックバック:http://Www.Dictionary.Sblinks.net/News/montreal-outdoor-living-30/
トラックバック:livEBackPaGe.COM
トラックバック:http://Gotanproject.net/node/22502005?—————————888846604Content-Disposition:form-data;name=titleLespnalitspsychologiquesd’undmnagement:commentlesanticiperetlesrcuprerde—————————888846604Content-Disposition:form-data;na
トラックバック:https://www.oasiskorea.net/Brand/5260418
トラックバック:Kingslists.com
トラックバック:http://www.Bestsermonoutlines.com/recherche-de-personnes-dentreprises-et-recherche-par-numero-de-telephone/
トラックバック:https://bookmarkshq.com/story17025906/crystal-dreams-world
トラックバック:Read the Full Post
トラックバック:http://cloud-dev.mthmn.com/node/305598
トラックバック:http://Cloud-Dev.Mthmn.Com/node/363047
トラックバック:http://Www.Records-Research.Sblinks.net/News/denta-especialidades-4/
トラックバック:https://bgmcd.co.uk/index.php?title=User:CorazonPresley9
トラックバック:http://www.rebelscon.com/profile.php?id=1648096
トラックバック:http://Cloud-dev.mthmn.com/node/366868
トラックバック:https://Www.imdipet-Project.eu/groupes/getting-older-and-seniors-care/
トラックバック:https://Sigmachiiu.com/forums/users/alyciaeisenhauer/
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1647217
トラックバック:http://cloud-dev.mthmn.com/node/366012
トラックバック:Sdswrj.cn
トラックバック:http://www.Die-seite.com/index.php?a=stats&u=geraldinearce10
トラックバック:https://Marketqna.com/community/?wpfs=&membersite=httpsclinicamaxidental.comimplantes-dentales&membersignature=span+styletext-decoration:+underline;Los+implantes+dentales+ofrecen/span+span+stylefont-style:+italic;una+resolucin+duradera+y/span+span
トラックバック:http://Qzfczs.com/comment/html/?334288.html
トラックバック:click through the up coming website
トラックバック:Dirstop.com
トラックバック:Read Zilahy
トラックバック:Recommended Internet page
トラックバック:learn more about Gotanproject
トラックバック:click here to investigate
トラックバック:https://Bookmarkingdelta.com/story15892956/cim-investigacin
トラックバック:https://Zvukiknig.cc/user/KandiceMosman/
トラックバック:tHeJIllisT.coM
トラックバック:relevant internet site
トラックバック:https://Apeguebremariam.org/community/?wpfs=&membersite=httpsAtldemenagement.comdeplacement-lourd-a-saint-hyacinthe&membersignature=Le+dmnagement+pourrait+tre+une+exprience+coteuse+surtout+si+vous+ne+savez+pas+exactement+ce+que+vous+devez+payer+et
トラックバック:https://bgmcd.co.uk/index.php?title=User:FaustoDHage336
トラックバック:bookmarkforce.com
トラックバック:Http://Pittsburghwomenmag.Xyz/blogs/viewstory/101313
トラックバック:Johsocial`s blog
トラックバック:https://Bookmarkingace.com/story15880131/hesman-garage-boucherville
トラックバック:http://www.Trimmers.Ipt.pw
トラックバック:http://cloud-Dev.mthmn.com/node/372811
トラックバック:https://Bookmarksknot.com/story17175385/magik-loans
トラックバック:Click That Link
トラックバック:missionca.Org
トラックバック:https://Www.mtmoa02.Net/mtreport/566628
トラックバック:view website
トラックバック:http://Www.gotanproject.net/node/22503259?—————————49201682Content-Disposition:form-data;name=titleTerreauPourCactusEtCulturesGrasses—————————49201682Content-Disposition:form-data;name=bodyFirementconuparSimplisticsToro
トラックバック:Http://Www.Gedankengut.One/Index.Php?Title=User:OllieRanieri325
トラックバック:http://Www.Superstitionism.com/forum/profile.php?id=437170
トラックバック:Thebookmarkage.com
トラックバック:https://Gamesfashionarchive.net/wiki/User:JonnaMeyer3
トラックバック:Going to God 999
トラックバック:https://Portal.virtueliving.Org
トラックバック:a cool way to improve
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1601051
トラックバック:http://siremifasol.chez.com/modules/profile/userinfo.php?uid=3923163
トラックバック:https://www.kenpoguy.Com
トラックバック:http://cloud-dev.mthmn.com/node/17790
トラックバック:https://Rnma.xyz/boinc/view_profile.php?userid=1641133
トラックバック:Bookmarkja.com
トラックバック:https://Onsale.Tawansmile.com/index.php?action=profile;u=8861
トラックバック:http://Www.gotanproject.net/node/22503031?—————————363006506862162Content-Disposition:form-data;name=titlePorteCabanonAchetezOuVendezDesBiens,BilletsOuGadgetsTechnosDansQubecPetitesAnnoncesDeKijiji—————————3630065068621
トラックバック:http://cloud-dev.Mthmn.com/node/15858
トラックバック:Www.Register.Sblinks.net
トラックバック:https://zvukiknig.cc/user/HULJennie4692001/
トラックバック:http://zjxsnj.cn/comment/html/?210035.html
トラックバック:Mysocialquiz.com
トラックバック:Https://portal.Virtueliving.org/profile_info.php?ID=64165
トラックバック:https://1usaclassifieds.com/author/dominicofly/
トラックバック:https://Bookmarkbells.com/story15976597/americanos
トラックバック:http://Www.Dqyjs.cn/comment/html/?5973.html
トラックバック:Www.customer-service.sblinks.net
トラックバック:http://wiki.start2study.ru/index.php?title=Supports_D__crans
トラックバック:http://gotanproject.net/node/22506553?—————————49350973content-disposition:form-data;name=titlepanneauxmurauxenbois,prfinietplusrno-dpt—————————49350973content-disposition:form-data;name=bodylesrevtementsmurauxsontdispo
トラックバック:http://Www.fantasyroleplay.co/wiki/index.php/User:Connor4683
トラックバック:http://www.weather.Sbm.pw/out/kitchen-cabinets-3/
トラックバック:Https://Classifieds.Exponentialhealth.Coop/Community/Profile/Andreaswhitlock/?Email=&Membersite=Httpsmackandalnaturotherapie.Comcontactnaturotherapie-A-Champfleury&Membersignature=La+ThRapie+De+DSintoxication+Au+QuBec+Offre+Un+Soutien+CompTent+Ess
トラックバック:http://www.gotanproject.net/node/22505061?—————————507976181384566Content-Disposition:form-data;name=titleTerreauPremiumParVertsEtFinesHerbesPro-mix2Pi18,1KgPromix7042476—————————507976181384566Content-Disposition:form-
トラックバック:https://Bgmcd.Co.uk/index.php?title=Les_Armoires
トラックバック:hop over to this site
トラックバック:visit the following webpage
トラックバック:HINdIbOOKMarK.COM
トラックバック:go to the website
トラックバック:had me going
トラックバック:Http://888.Lililian.Com/Comment/Html/?157781.Html
トラックバック:https://checkbookmarks.com/story1242671/cim-investigacin
トラックバック:https://biowiki.clinomics.com/index.php/User:MonroeKay459
トラックバック:Http://Www.Zjxsnj.Cn/Comment/Html/?186244.Html
トラックバック:http://www.Science.Sblinks.net/News/la-bouticaire-32/
トラックバック:http://Www.Superstitionism.com/forum/profile.php?id=440347
トラックバック:http://www.management.bookmarking.site/News/la-bouticaire-23/
トラックバック:https://rnma.xyz/boinc/view_profile.php?userid=1641519
トラックバック:Www.1Usaclassifieds.com
トラックバック:https://Bookmark-Nation.com/story15814526/transactions-immobilires–gatineau-dominique-patrice
トラックバック:http://www.Dqyjs.cn/comment/Html/?7813.html
トラックバック:https://classifieds.ocala-news.com/author/karenstiltn
トラックバック:Socialskates.com
トラックバック:http://afcantarelle.org/index.php?title=Volkswagen_Diesel_Settlements_Environmental_Mitigation
トラックバック:mouse click the up coming internet site
トラックバック:https://infodin.com.br/index.php/User:EarthaConley23
トラックバック:https://taupi.org/index.php?title=User:GuadalupeCutlack
トラックバック:Full Document
トラックバック:Hylistings.com
トラックバック:simply click the following post
トラックバック:https://enableelearn.com/?s=&post_type=courses&membersite=httpsDermkaclinik.comenhow-to-get-rid-of-cellulite&membersignature=Lux+bar++ongles+et+esthtique+offre+un+service+ultra+professionnel+et+chaleureux.+Vous+pourrez+y+recevoir+une+manucure+
トラックバック:https://Trabalhadoresindependentes.com/author/angie64v684/
トラックバック:http://Wiki.Rl-transport.org/index.php/User:RashadZof9033432
トラックバック:Www.real-estate.dofollowlinks.org
トラックバック:cinnamon roll icing recipe
トラックバック:http://Www.property.sblinks.net/News/amenagement-denis-178/
トラックバック:https://Mediajx.com/story17225624/bpc
トラックバック:https://mysocialport.com/story1235761/hesman-garage
トラックバック:https://www.Imdipet-Project.eu/groupes/comment-trouver-un-demenageur-a-petit-prix/
トラックバック:i thought about this
トラックバック:Bbsocialclub.com
トラックバック:https://Kirkesimports.com/?s=&post_type=product&membersite=httpsWww.Solutions-G00.comserviceslusinage-cnc&membersignature=Darrell+researched+what+was+needed+and+obtained+again+to+us+rapidly+with+several+superb+options.+Once+we+selected+which+c
トラックバック:pr7bookmark.com
トラックバック:https://Mysitesname.com/story5428500/la-bouticaire
トラックバック:http://Cloud-Dev.Mthmn.com/node/387321
トラックバック:https://Procesal.cl/index.php/User:RomaineShepherds
トラックバック:Top100Bookmark.com
トラックバック:https://kaidan136.com/index.php?title=:PVEMyrtle2
トラックバック:http://www.die-seite.com/index.php?a=stats&u=danutae396
トラックバック:Social-Lyft.com
トラックバック:www.smart-PriCe.sblinks.NeT
トラックバック:http://luennemann.org/index.php?mod=users&action=view&id=364617
トラックバック:Https://Wiki.Team-Glisto.Com
トラックバック:https://Wiki.sports-5.ch/index.php?title=utilisateur:effieguess
トラックバック:www.arts-and-entertainment.ipt.pw
トラックバック:http://superstitionism.com/forum/profile.php?id=439182
トラックバック:special info
トラックバック:https://Bookmarkity.com/story15927596/oregon-lemon-law
トラックバック:https://Infodin.Com.br/index.php/User:SeymourBacote
トラックバック:webcastlist.com
トラックバック:https://Elearning.Hcbeauty.com/blog/index.php?entryid=62126
トラックバック:https://wiki.gem-flash.com/index.php?title=Article_Title
トラックバック:Https://Www.1Usaclassifieds.Com
トラックバック:https://Dirstop.com/story17602033/entrepreneur-spcialis-en-finition-de-bton-la-truelle-d-or
トラックバック:http://provaforumsavoia1234.Altervista.org/community/?wpfs=&membersite=httpsLatruelledor.carevetements-specialises-a-saint-ferreol-les-neiges&membersignature=Introduction+:pnbsp;/ppnbsp;/p+emLe+bton+estamp+est+une/em+mthode+de+revtement+de+sol+ext
トラックバック:https://Okniga.org/user/EzraMoffat00371/
トラックバック:http://Canamkart.ca/index.php?page=user&action=pub_profile&id=1078431
トラックバック:investigate this site
トラックバック:https://Hylistings.com/story16659356/kitchen-cabinets
トラックバック:https://mysocialport.com/story1224318/americanos
トラックバック:WWw.SUIts.Ipt.PW
トラックバック:Bookmarkswing.com
トラックバック:sitesrow.com
トラックバック:https://king.az/user/JeffHinton32/
トラックバック:check out here
トラックバック:Www.wakewiki.de
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=271141
トラックバック:freebookmarkpost.com
トラックバック:Https://Onrafrica.Com/Query-Pour-Les-Couvreurs-Residentiel
トラックバック:click the following document
トラックバック:https://www.homecareshoppe.com/Points-de-vente-de-ameublement-in-saint/
トラックバック:https://Thefairlist.com/story5629137/magik-loans
トラックバック:gUeStpOSTsALE.coM
トラックバック:https://cruxbookmarks.com/story15977907/cim-investigacin
トラックバック:http://Www.sxlopw.cn/comment/html/?241041.html
トラックバック:https://Dimension-gaming.nl/profile.php?id=75329
トラックバック:http://forum.prolifeclinics.ro/profile.php?id=181498
トラックバック:Unitedindia.info
トラックバック:http://Forum.Prolifeclinics.ro/profile.php?id=160764
トラックバック:http://Www.Die-Seite.com/index.php?a=stats&u=dewey37n7041
トラックバック:bleezlabs.Com
トラックバック:http://cloud-dev.mthmn.com/node/373061
トラックバック:https://wiki.team-glisto.com/index.php?title=Cr_ation_De_Site_Web__Montr_al_:_Conseils_Par_Une_Pr_sence_Num_rique_R_ussie
トラックバック:https://wise-social.com/story1217997/servicios-de-transporte-terrestre-en-bogot-vanspremium
トラックバック:https://Demo.Qkseo.In/profile.php?id=364402
トラックバック:https://Infodin.Com.br/index.php/User:ArianneStallcup
トラックバック:Sissipedia.wiki
トラックバック:http://Luennemann.org/index.php?mod=users&action=view&id=354745
トラックバック:https://Socialskates.com/story16600059/gouttires-aluminium-jb
トラックバック:https://Advicebookmarks.com/story15995662/grandbox
トラックバック:Health-Lists.com
トラックバック:https://Nxlv.ru/user/ErnestoTuttle/
トラックバック:http://die-seite.com/index.php?a=stats&u=gabrielledelance
トラックバック:Https://Zvukiknig.cc/
トラックバック:geNeraTe.sbM.pw
トラックバック:http://www.gotanproject.net/node/22522822?—————————337379244Content-Disposition:form-data;name=titleBornelectriqueSubvention:Commentbnficierd’aidespourvotreinstallation—————————337379244Content-Disposition:form-data;na
トラックバック:echobookmarks.Com
トラックバック:https://trans.Hiragana.jp/ruby/http://cloud-dev.mthmn.com/node/381253
トラックバック:http://www.Gotanproject.net/node/22521032?—————————7272374402327827Content-Disposition:form-data;name=titleCommentimpermabiliserdesDallesdeBton—————————7272374402327827Content-Disposition:form-data;name=bodySous-titre1:
トラックバック:Imdipet-project.eu
トラックバック:https://Obengdarko.com.gh/forums/users/sibylfosdick687/
トラックバック:change-Management.dofollowlinks.org
トラックバック:http://Www.Gotanproject.net/node/22497442?—————————37843884Content-Disposition:form-data;name=titleRenovatingStartLookingAtEquipmentPackagesNow—————————37843884Content-Disposition:form-data;name=bodyThesedayseverydishwa
トラックバック:http://www.xjykj.cn/comment/html/?445278.html
トラックバック:jasa seo web
トラックバック:WIN368
トラックバック:jasa seo harga
トラックバック:beli followers ig murah
トラックバック:backlink pbn gratis
トラックバック:accutane attorney | Buy Accutane online
トラックバック:toto sgp
トラックバック:auto followers pinterest
トラックバック:trending news on social media 2023
トラックバック:toto macau
トラックバック:link alternatif pedetogel
トラックバック:xyz 338 slot
トラックバック:Miataki Mushrooms Share
トラックバック:kebuntoto link alternatif login
トラックバック:kebuntoto login
トラックバック:jasa view dan like youtube
トラックバック:FitBites BHB Gummies
トラックバック:Fit Bites Gummies
トラックバック:Fit Today Keto Gummies
トラックバック:Circulaxil
トラックバック:beli followers instagram aktif indonesia murah
トラックバック:Greenhouse CBD Gummies
トラックバック:Stimula Blood Sugar Support
トラックバック:Lights Out CBD Gummies
トラックバック:ABForce Stimulator & Recovery
トラックバック:sex
トラックバック:jual followers instagram 10k
トラックバック:beli followers instagram
トラックバック:apakah beli view youtube aman
トラックバック:Nuubu Detox Patch
トラックバック:Apex Pencil
トラックバック:tambah view youtube
トラックバック:cara menambah view instagram tanpa aplikasi
トラックバック:suntik like youtube
トラックバック:check it out
トラックバック:jasa like instagram murah
トラックバック:toto sdy
トラックバック:beli subscriber youtube aman
トラックバック:Vision Nutri Complex
トラックバック:best gold ira companies
トラックバック:beli view story instagram
トラックバック:toto hk
トラックバック:donkey Milk soap organic
トラックバック:donkey Milk Soap skin benefits
トラックバック:tototogel
トラックバック:http://latenitetip.com/index.php?page=user&action=pub_profile&id=75726
トラックバック:beli followers ig permanen indonesia
トラックバック:Medioxil 24
トラックバック:TV Share Max
トラックバック:https://oracleepm.guide/
トラックバック:biaya seo website
トラックバック:jual views youtube
トラックバック:jual followers spotify
トラックバック:Jasa Backlink
トラックバック:harga seo website
トラックバック:jasa backlink artikel
トラックバック:apa itu pinterest
トラックバック:Vitamin Dee Male Enhancement Gummies
トラックバック:Ezpostings
トラックバック:modern kitchen decor
トラックバック:urine test tips
トラックバック:jasa backlink seo
トラックバック:backlink murah
トラックバック:beli subscriber youtube permanen
トラックバック:trendi hírek a világon
トラックバック:Trending na balita sa social media ngayon
トラックバック:server thailand
トラックバック:adorable animals
トラックバック:Актуальныя навіны свету гэтага тыдня
トラックバック:psykholog
トラックバック:golden energy
トラックバック:print 3d models
トラックバック:nyheder om internet i dag
トラックバック:2023-жылдагы социалдык медиадагы жаңылыктар
トラックバック:актуални новини в Индонезия
トラックバック:batmanapollo.ru
トラックバック:nā manawa o ka nūhou haʻuki India i kēia lā
トラックバック:социалдык тармактарда эң популярдуу жаңылыктар
トラックバック:今日のトレンドニュース
トラックバック:www.pinterest.com
トラックバック:Banci Toto
トラックバック:BanciToto
トラックバック:golden Teacher
トラックバック:right foods
トラックバック:astra 338 link login
トラックバック:hotels check-in 18
トラックバック:hotel 18+
トラックバック:hotel check-in 18
トラックバック:Banci togel 2d
トラックバック:Banci dalam togel
トラックバック:growkit Golden teacher
トラックバック:Astra338 login
トラックバック:Update Site Error ¹ 654
トラックバック:Update Site Error ¹ 655
トラックバック:Chang’s Beach: Maui’s Hidden Gem Featured in Maui Now Guide
トラックバック:zillow
トラックバック:viagra
トラックバック:354
トラックバック:wismabet link alternatif
トラックバック:porn
トラックバック:pembesar payudara
トラックバック:jasa seo bergaransi
トラックバック:ads508
トラックバック:ceria777
トラックバック:read this blog article from buybatsknifemm2online.wordpress.com
トラックバック:harga backlink berkualitas
トラックバック:Link
トラックバック:Beli Follower Threads IG
トラックバック:aurora2019valuetrade.wordpress.com
トラックバック:Apocalypse MM2 Value
トラックバック:Charcoal briquettes Indonesia
トラックバック:Coconut charcoal from Indonesia
トラックバック:slot online
トラックバック:hotels
トラックバック:hotel
トラックバック:hotels 18+
トラックバック:世界で話題のニュース
トラックバック:transfert de nouvelles sur les sports aériens
トラックバック:DafaToto slot
トラックバック:psy
トラックバック:internetdə trend xəbərlər
トラックバック:што сёння адбываецца з сацыяльнымі сеткамі
トラックバック:sportsnyhedscricket
トラックバック:ما هو الاتجاه الشائع الآن؟
トラックバック:kiino4k.ru
トラックバック:jasa seo togel
トラックバック:jasa pbn berkualitas
トラックバック:depresiya
トラックバック:film
トラックバック:“https://x.com/rayanwebb/status/1740571631867830311?s=20
トラックバック:“https://cameradb.review/wiki/Sverhi.net
トラックバック:new 2024
トラックバック:jual backlink murah
トラックバック:seo situs judi online
トラックバック:backlink judi online
トラックバック:batman apollo
トラックバック:film2024
トラックバック:slot
トラックバック:123 Movies
トラックバック:laloxeziya-chto-eto-prostymi-slovami.ru
トラックバック:Crap
トラックバック:child porn
トラックバック:Из замкнутого круга сериал 2023 смотреть онлайн бесплатно в хорошем качестве
トラックバック:Алекс Лютый. Дело Шульца смотреть онлайн бесплатно в хорошем качестве
トラックバック:Candle MM2
トラックバック:Buy Candied Knife MM2
トラックバック:Camo MM2 Value
トラックバック:Candycorn 2020mm 2rarity Wordpress wrote
トラックバック:سكاي سبورتس لايف لكرة القدم
トラックバック:Бесплатен пренос на вести во живо на YouTube
トラックバック:000
トラックバック:samorazvitiepsi
トラックバック:zegelring dames
トラックバック:hentai game
トラックバック:ceria ceria777 slot
トラックバック:web ca cuoc truc tuyen
トラックバック:Што з’яўляецца моднай тэмай у сацыяльных сетках?
トラックバック:сублимация на футболках технология
トラックバック:jongste sportnuus vandag in Engels
トラックバック:medali303
トラックバック:Online Visa Application Form
トラックバック:lajmet në trend indonezi
トラックバック:Топ 5 спортски вести на англиски денес
トラックバック:macauslot88 deposit pulsa im3
トラックバック:İngilis dilində ən yaxşı 5 idman xəbəri
トラックバック:litteraction.fr
トラックバック:situs dadu online
トラックバック:bocoran rtp slot
トラックバック:slot gacor
トラックバック:situs gacor
トラックバック:situs slot
トラックバック:Golden teacher sklep
トラックバック:nbc xəbərləri indi aparıcıdır
トラックバック:Live-urheiluuutiset Intiassa
トラックバック:reduslim inhaltsstoffe
トラックバック:Каква е популярната тенденция в момента?
トラックバック:Donkey Milk Soap Ingredients
トラックバック:bolacasino88
トラックバック:tider med indiske sportsnyheder i dag
トラックバック:udin777
トラックバック:kardash69.ru
トラックバック:Tucker Carlson – Vladimir Putin – 2024-02-09 Putin interview summary, full interview.
トラックバック:Tucker Carlson – Vladimir Putin
トラックバック:ppf bandung
トラックバック:nano ceramic
トラックバック:“https://remotebillpay.com/tarantasik/
トラックバック:“http://www.malang.info.ooo:80/index.php/Pengguna:DannEaston65
トラックバック:спорт жаңылыктары бүгүн баш макалалар
トラックバック:Sexleben
トラックバック:адвокат по вопросам недвижимости
トラックバック:CookiecaneKnifeMM2ChromaValue.wordpress.com
トラックバック:instagram reset followers
トラックバック:james charles lost followers on tiktok
トラックバック:помощь юриста при разводе через суд
トラックバック:Chroma Boneblade MM2
トラックバック:beli subscriber youtube
トラックバック:pvp777
トラックバック:услуги медицинского педикюра
トラックバック:beli subscriber
トラックバック:http://genomicdata.hacettepe.edu.tr
トラックバック:адвокат для бизнеса в москве
トラックバック:юридическая помощь при дтп автоюристы
トラックバック:www.sexmoon.de
トラックバック:ChromafangValueKnife.wordpress.com
トラックバック:Buy Cherry Knife MM2
トラックバック:CocukK PornosuS
トラックバック:Click at Mm 2knifedeathshardchromavalue Wordpress
トラックバック:terradesic.org
トラックバック:адвокаты г москвы
トラックバック:юрист по строительным вопросам
トラックバック:coba777
トラックバック:chroma Cookiecane mm2
トラックバック:“https://wiki.roboco.co/index.php/Enhancing_Accuracy_And_Innovation_With_Jasa_Laser_Cutting_Solutions
トラックバック:“http://bondpedia.altervista.org/index.php?title=Enhancing_Precision_And_Innovation_With_Jasa_Laser_Cutting_Services
トラックバック:“https://massagemobilityau.com/elevating-precision-and-creativity-with-jasa-laser-cutting-services/
トラックバック:“https://redvice.eu/2024/03/01/enhancing-precision-and-innovation-with-jasa-laser-cutting-services-2/
トラックバック:“https://parentingliteracy.com/wiki/index.php/User:DamianManley89
トラックバック:“http://www.freddypilar.com/enhancing-precision-and-innovation-with-jasa-laser-cutting-services/
トラックバック:“https://wiki.conspiracycraft.net/index.php?title=Zamok
トラックバック:“https://hikvisiondb.webcam/wiki/User:JudeRintel
トラックバック:“http://wiki.myamens.com/index.php/User:TyroneSoutherlan
トラックバック:https://www.cucumber7.com/
トラックバック:uck74.ru
トラックバック:slot gampang jackpot
トラックバック:юрист по банковским вопросам бесплатная консультация
トラックバック:look at these guys
トラックバック:128.199.127.24
トラックバック:kasino rolet terpercaya
トラックバック:google bola
トラックバック:cara menaikkan website judi
トラックバック:superman68
トラックバック:taruhan dadu online
トラックバック:macauslot88 daftar
トラックバック:Buy Chromatic Knife MM2
トラックバック:jtayl.me
トラックバック:telegolf.org
トラックバック:kchurchofchrist.com
トラックバック:jasa seo pbn
トラックバック:https://shorl.com
トラックバック:http://jtayl.me/daftarslotonlinegacor978977
トラックバック:Cookie MM2
トラックバック:Donkey Milk Cosmetics Cyprus
トラックバック:sarangsbobet
トラックバック:https://v.gd/
トラックバック:sarangsbobet link
トラックバック:sga508
トラックバック:r
トラックバック:coursework
トラックバック:https://ValueKnifeMM2Clown.wordpress.com
トラックバック:en.wikipedia.org
トラックバック:https://canvas.ubc.ca/eportfolios/49464/blogs/NCAA_Drug_Testing_What_Happens_If_You_Fail
トラックバック:ips77
トラックバック:xgslot88 link alternatif
トラックバック:Nooro Knee Massager
トラックバック:สาระน่ารู้
トラックバック:mawartoto link terbaru
トラックバック:natural donkey milk soap ingredients
トラックバック:otoslot login alternatif
トラックバック:เกร็ดความรู้
トラックバック:สาระน่ารู้ทั่วไป
トラックバック:v.gd
トラックバック:slot gampang maxwin
トラックバック:rsjakarta.co.id
トラックバック:เว็บความรู้
トラックバック:xgslot88
トラックバック:otoslot link
トラックバック:Arena333
トラックバック:slot gacor hari ini pragmatic
トラックバック:grandpashabet
トラックバック:magic amanita mushroom gummy
トラックバック:Qunix Nisqa
トラックバック:wisma bet login
トラックバック:artis777
トラックバック:Polototo sgp
トラックバック:xgslot88 login alternatif
トラックバック:child porn
トラックバック:macauslot88 2024
トラックバック:พนันออนไลน์
トラックバック:เว็บพนันออนไลน์
トラックバック:เว็บพนันออนไลน์เว็บตรง
トラックバック:tgslot
トラックバック:เว็บพนัน
トラックバック:cuancash88
トラックバック:RecehBet Login
トラックバック:ips77 login
トラックバック:original site
トラックバック:test gsa
トラックバック:https://hentaihaven.su/
トラックバック:юрист по алиментам онлайн консультация бесплатно
トラックバック:Gopek178 Link Alternatif
トラックバック:bu gün trend axtarışları
トラックバック:أفضل 5 أخبار رياضية باللغة الإنجليزية
トラックバック:папулярныя навіны ў сацыяльных сетках 2023
トラックバック:otoslot4d
トラックバック:Slot Pulsa
トラックバック:otoslot link login
トラックバック:أخبار الثعلب
トラックバック:youtube danas u trendu širom svijeta
トラックバック:https://-51.
トラックバック:intlawcompany.ru
トラックバック:mitä sosiaalisessa mediassa tapahtuu tänään
トラックバック:Məktəb yığıncağı üçün ingilis dilində ən yaxşı 5 idman xəbəri
トラックバック:youtube je dnes celosvětovým trendem
トラックバック:desa333
トラックバック:otoslot
トラックバック:Прамыя спартыўныя навіны прэм’ер-лігі
トラックバック:child porn
トラックバック:otoslot rtp
トラックバック:youtube në trend sot në mbarë botën
トラックバック:Sosial mediada trend olan mövzu nədir?
トラックバック:finviz
トラックバック:oto slot link alternatif
トラックバック:当今世界的热门新闻
トラックバック:трэндавая тэма dunia hari ini
トラックバック:https://hanime.su/
トラックバック:post503000728
トラックバック:โปรแกรมทัวร์ไต้หวัน
トラックバック:โปรแกรมทัวร์จีน
トラックバック:เที่ยวเกาหลีใต้
トラックバック:адвокат по заливам цена
トラックバック:bersama138
トラックバック:https://valuettddjspeakerman1.wordpress.com
トラックバック:Hero Keto ACV Gummies
トラックバック:пинап. казино
トラックバック:Purchase Dancing Speakerwoman TTD
トラックバック:ทัวร์จีน 5 ดาว
トラックバック:ทัวร์พม่า
トラックバック:“https://www.yoonjobooks.co.kr/yoonjo/bbs/board.php?bo_table=free&wr_id=274560”
トラックバック:TTD Large Cameraman Value
トラックバック:먹튀검증
トラックバック:Dancing Speakerwoman TTD
トラックバック:KKSLOT777
トラックバック:Ninja Cameraman TTD
トラックバック:SlimPulse
トラックバック:notizie di tendenza oggi
トラックバック:kio okazas kun sociaj amaskomunikiloj hodiaŭ
トラックバック:animeporn su
トラックバック:Restore CBD Gummies
トラックバック:Што азначае экстранныя навіны?
トラックバック:click through the following web page
トラックバック:trending på internettet i dag
トラックバック:hotels check-in 18 new york
トラックバック:hotel check-in 18 nyc
トラックバック:hotels 18+ new york
トラックバック:What is benefits slimysol
トラックバック:เว็บบทความ
トラックバック:Going At this website
トラックバック:How long should I take Nexaslim pills?
トラックバック:Purchase Camera Repair Drone TTD
トラックバック:TTD Corrupted Cameraman
トラックバック:Glitch Cameraman TTD
トラックバック:Camera Spider TTD Camera Spider TTD Value TTD Camera Spider Value TTD Camera Spider Buy Camera Spider TTD Purchase Camera Spider TTD
トラックバック:Camera Helicopter TTD
トラックバック:TTD Engineer Cameraman
トラックバック:TTD Large Firework Cameraman Value
トラックバック:Purchase Jetpack Cameraman TTD
トラックバック:Buy Hunter Cameraman TTD
トラックバック:Ttd Glitch Cameraman
トラックバック:Hunter Cameraman TTD
トラックバック:our source
トラックバック:Glitch Cameraman TTD Value
トラックバック:Purchase Hunter Cameraman TTD
トラックバック:Buy Large Cameraman TTD
トラックバック:ValueHunterCameramanUnitTTD.wordpress.com
トラックバック:Hunter Cameraman TTD Value
トラックバック:TTD Glitch Cameraman Value
トラックバック:her comment is here
トラックバック:https://TTDHunterCameramanTrade.wordpress.com
トラックバック:Camera Repair Drone TTD
トラックバック:HunterCameramanTTD.wordpress.com
トラックバック:Ttdunitlargecameramanshop.Wordpress.Com
トラックバック:ttdlargecameramanunitstore.wordpress.Com
トラックバック:https://LargeCameramanUnitTTDStore.wordpress.com/
トラックバック:Purchase Glitch Cameraman Ttd
トラックバック:ValueLargeCameramanTTD.wordpress.com
トラックバック:ValueTTDUnitLargeCameraman.wordpress.com
トラックバック:https://TTDHunterCameraman.wordpress.com
トラックバック:information from ValueGlitchCameramanTTDUnit.wordpress.com
トラックバック:Ttdunitglitchcameramanvalue.Wordpress.Com
トラックバック:Large Cameraman TTD Value
トラックバック:https://HunterCameramanUnitTTDStore.wordpress.com/
トラックバック:https://glitchcameramanunitttdstore.wordpress.com/
トラックバック:Buy Glitch Cameraman TTD
トラックバック:valueglitchcameramanunitttd.wordpress.Com
トラックバック:https://LargeCameramanUnitValueTTD.wordpress.com
トラックバック:Corrupted Cameraman TTD Value
トラックバック:Large Cameraman TTD
トラックバック:Https://TTDLargeCameramanShop.Wordpress.Com/
トラックバック:go!!
トラックバック:Large Firework Cameraman TTD
トラックバック:https://TTDUnitCameraSpiderMarket.wordpress.com
トラックバック:https://CameraSpiderTTDUnitShop.wordpress.com/
トラックバック:Corrupted Cameraman TTD
トラックバック:Buy Corrupted Cameraman TTD
トラックバック:CorruptedCameramanUnitTTDMarket.wordpress.com
トラックバック:just click TTDUnitCorruptedCameramanMarket.wordpress.com
トラックバック:TTD Corrupted Cameraman Value
トラックバック:the original source
トラックバック:CorruptedCameramanValueTTD.wordpress.com
トラックバック:Corruptedcameramanttdtrade Wordpress`s statement on its official blog
トラックバック:use Glitchcameramanunitttdvalue Wordpress here
トラックバック:ValueGlitchCameramanTTD.wordpress.com
トラックバック:published on Ttdcorruptedcameramanmarket Wordpress
トラックバック:https://TTDCorruptedCameramanUnit.wordpress.com/
トラックバック:CorruptedCameramanTTDUnitMarket.wordpress.com
トラックバック:https://GlitchCameramanUnitTTDTrade.wordpress.com
トラックバック:CorruptedCameramanUnitTTD.wordpress.com
トラックバック:visit this site
トラックバック:https://TTDCameraSpiderUnitMarket.wordpress.com
トラックバック:click through the up coming web page
トラックバック:https://ValueCorruptedCameramanTTD.wordpress.com/
トラックバック:https://CorruptedCameramanTTD.wordpress.com
トラックバック:CameraHelicopterTTDlevel.wordpress.com
トラックバック:https://TTDUnitLargeCameraman.wordpress.com
トラックバック:Camera Helicopter TTD Value
トラックバック:Link Website
トラックバック:Purchase Camera Helicopter TTD
トラックバック:click through the following article
トラックバック:TTDCameraHelicopterUnitValue.wordpress.com
トラックバック:visit the following website
トラックバック:Buy Camera Repair Drone TTD
トラックバック:Buy Engineer Cameraman TTD
トラックバック:dog food recipes for allergies
トラックバック:Purchase Engineer Cameraman Ttd
トラックバック:More Material
トラックバック:HunterCameramanUnitValueTTD.wordpress.com
トラックバック:TTD Hunter Cameraman Value
トラックバック:relevant site
トラックバック:engineer cameraman ttd value
トラックバック:official ValueEngineerCameramanUnitTTD.wordpress.com blog
トラックバック:TTDEngineerCameramanTrade.wordpress.com
トラックバック:TTDUnitEngineerCameraman.wordpress.com
トラックバック:EngineerCameramanTTDStore.wordpress.com
トラックバック:Camera Repair Drone TTD Value
トラックバック:EngineerCameramanTTD.wordpress.com
トラックバック:mouse click the following webpage
トラックバック:ValueCameraSpiderUnitTTD.wordpress.com
トラックバック:https://TTDCorruptedCameramanUnitStore.wordpress.com
トラックバック:TTDHunterCameramanupgrade.wordpress.com
トラックバック:CorruptedCameramanTTDMarket.wordpress.com
トラックバック:https://TTDCameraRepairDroneUnitMarket.wordpress.com
トラックバック:EngineerCameramanUnitTTDMarket.wordpress.com
トラックバック:TTD Camera Repair Drone
トラックバック:read this blog post from ValueCameraSpiderTTD.wordpress.com
トラックバック:https://CameraSpiderTTDUnitValue.wordpress.com/
トラックバック:TTDCameraSpiderShop.wordpress.com
トラックバック:visit the next page
トラックバック:Buy Large Firework Cameraman TTD
トラックバック:TTDCameraSpiderTrade.wordpress.com website
トラックバック:TTD Large Cameraman
トラックバック:mouse click the next article
トラックバック:Large Firework Cameraman TTD Value
トラックバック:Full Article
トラックバック:Https://LargeCameramanTTDUnitStore.wordpress.com
トラックバック:Check Out Valuettdcameraspider Wordpress
トラックバック:click through the following web site
トラックバック:Purchase Large Firework Cameraman TTD
トラックバック:ProFlexen Result
トラックバック:https://ValueCameraRepairDroneUnitTTD.wordpress.com
トラックバック:https://CameraRepairDroneUnitTTDShop.wordpress.com
トラックバック:https://ValueTTDUnitGlitchCameraman.wordpress.com
トラックバック:ProPlayers Wellness Keto Gummies Reviews
トラックバック:visit the next site
トラックバック:https://TTDEngineerCameramanMarket.wordpress.com/
トラックバック:Engineer Cameraman TTD
トラックバック:TTD Engineer Cameraman Value
トラックバック:TTDUnitValueLargeFireworkCameraman.wordpress.com
トラックバック:LargeFireworkCameramanUnitTTDValue.wordpress.com
トラックバック:TTD Large Firework Cameraman
トラックバック:valuettdlargefireworkcameramanunit.wordpress.com
トラックバック:wb403 alternatif
トラックバック:TTD Camera Repair Drone Value
トラックバック:this guy
トラックバック:TTDCameraRepairDroneUnitValue.wordpress.com
トラックバック:TTDCameraRepairDroneMarket.wordpress.com wrote in a blog post
トラックバック:Results Transformation Center https://socialstrategie.com/story2074664/sparks-workout-sessions
トラックバック:visit Ttdlargefireworkcameramantrade Wordpress here >>
トラックバック:please click the next page
トラックバック:ttdunitlargefireworkcameramantrade.wordpress.com
トラックバック:https://LargeFireworkCameramanUnitTTD.wordpress.com/
トラックバック:scatter hitam
トラックバック:https://bukansitus.com/2024/05/08/home-faucet-repair-construction-plumbing/
トラックバック:easy homeowner lighting
トラックバック:Arena333 Link Alternatif
トラックバック:{link gacor slot}
トラックバック:go directly to TTDUnitLargeSpeakermanMarket.wordpress.com
トラックバック:Gopek178 Hoki
トラックバック:Arena333 pro
トラックバック:MechCameramanTTDGG.wordpress.com
トラックバック:Arena333 Slot
トラックバック:Laser Gun Cameraman TTD
トラックバック:Medic Cameraman TTD
トラックバック:Buy Scary Speakerman TTD
トラックバック:SandiBet Alternatif
トラックバック:situs judi slot
トラックバック:porno izle
トラックバック:SandiBet
トラックバック:Arena333 Slot Login
トラックバック:Arena333 Slot Login Link Alternatif
トラックバック:{link slot terbaru}
トラックバック:simply click the up coming document
トラックバック:TTD Mech Cameraman Value
トラックバック:santatvmanttdstore.wordpress.com
トラックバック:Arena333 vip
トラックバック:Buy Large TV Man TTD
トラックバック:TTD Laser Gun Cameraman Value
トラックバック:to TTDUnitChefTVManShop.wordpress.com
トラックバック:Purchase Mech Cameraman TTD
トラックバック:TTD Large Speakerman
トラックバック:Gopek178 Login
トラックバック:Purchase Large Speakerman TTD
トラックバック:Laser Gun Cameraman TTD Value
トラックバック:SandiBet Login
トラックバック:Buy Santa TV Man TTD
トラックバック:CBD Care Gummies
トラックバック:https://LargeLaserCameramanTTDStore.wordpress.com
トラックバック:Read Significantly more
トラックバック:{link slot gacor terpercaya}
トラックバック:Gopek178 Alternatif
トラックバック:simply click the up coming article
トラックバック:situs judi slot online terpercaya
トラックバック:situs judi slot online resmi
トラックバック:{link slot gacor hari ini}
トラックバック:M494
トラックバック:Gopek178 Legal
トラックバック:TTD Large Laser Cameraman
トラックバック:MedicCameramanUnitTTDMarket.wordpress.com
トラックバック:Medic Cameraman TTD Value
トラックバック:situs judi slot online gampang menang
トラックバック:click here
トラックバック:TTD Dual Blade Bunnyman Value
トラックバック:https://www.mysoter.net/quiz-will-online-book-marketing-help-sales/
トラックバック:https://mjwildlife.ca/community/profile/jesusbanda61958/
トラックバック:Wild Stallion Pro
トラックバック:SandiBet Link
トラックバック:Gopek178 Petir
トラックバック:Gopek178 Slot
トラックバック:visit this website link
トラックバック:TTD Elf Camerawoman
トラックバック:Elf Camerawoman TTD
トラックバック:Buy Cupid Camerawoman TTD
トラックバック:TTD Cupid Camerawoman Value
トラックバック:Elf camerawoman ttd Value
トラックバック:Nuubu Detox Foot Patches
トラックバック:Going On this page
トラックバック:relevant webpage
トラックバック:https://CupidCamerawomanUnitTTDStore.wordpress.com
トラックバック:TTD Cupid Camerawoman
トラックバック:Wordpress blog post
トラックバック:Elf Camerawoman TTD Value
トラックバック:Elf Camerawoman TTD
トラックバック:https://TTDElfCamerawomanStore.wordpress.com
トラックバック:Wild Stallion Pro Reviews
トラックバック:wd808
トラックバック:Tupi Tea ME
トラックバック:Uqalo Yuvalift
トラックバック:related resource site
トラックバック:link gacor slot
トラックバック:Awitogel Login Link Alternatif
トラックバック:NexaSlim Ketosis
トラックバック:Glucoslim Reviews
トラックバック:GLOTER
トラックバック:Slimysol
トラックバック:NuviaLab Keto
トラックバック:look here
トラックバック:Awitoto Link Alternatif
トラックバック:otoslot login
トラックバック:freebet gratis
トラックバック:web slot gacor
トラックバック:AkarToto 777
トラックバック:AkarToto Alternatif
トラックバック:slot online gacor
トラックバック:AkarToto Login
トラックバック:slot paling gacor
トラックバック:AkarToto
トラックバック:okta388
トラックバック:New games for Android
トラックバック:otoslot link alternatif
トラックバック:slot yang lagi gacor
トラックバック:slot terbaru
トラックバック:AkarToto Slot Login
トラックバック:slot yang lagi gacor sekarang
トラックバック:Best games for Android
トラックバック:slot online paling gacor
トラックバック:situs slot gacor hari ini
トラックバック:bonus new member 100 slot game
トラックバック:Smart Hemp Gummies
トラックバック:bit.ly/kto-takoy-opsuimolog
トラックバック:super cuan 88
トラックバック:slot online gacor hari ini
トラックバック:Popular games for Android
トラックバック:Urgent Visa Online
トラックバック:Slot Deposit 5k
トラックバック:Surveillance Camerawoman TTD
トラックバック:{link slot gacor}
トラックバック:Toy
トラックバック:oto slot gacor
トラックバック:free porn
トラックバック:site
トラックバック:link slot gacor hari ini
トラックバック:sims 4 goth decor cc
トラックバック:cuancash
トラックバック:TTD Scary Speakerman Value
トラックバック:TTD Healer TV Woman Value
トラックバック:ttd images
トラックバック:เว็บวาไรตี้
トラックバック:about
トラックバック:TTD Scary Speakerman
トラックバック:BloxCart MM2
トラックバック:Candleflame MM2
トラックバック:Purchase Huge Anime Unicorn PS99
トラックバック:PS99 Huge Angel Cat
トラックバック:PS99 Huge Abyssal Axolotl Value
トラックバック:Huge Alien Arachnid PS99
トラックバック:PS99 Huge Anime Agony Value
トラックバック:koko303
トラックバック:JUDI ONLINE
トラックバック:먹튀검증업체 순위
トラックバック:when to use lose and loss?
トラックバック:성남 출장
トラックバック:bath and body works candles toxic
トラックバック:수유출장마사지
トラックバック:scameter app for android free
トラックバック:mfa bypass roblox
トラックバック:japan travel in december
トラックバック:купить аттестат 11 классов
トラックバック:singapore vaccinated travel lane japan
トラックバック:Buy Orange Seer Knife MM2
トラックバック:Buy Old Glory Knife MM2
トラックバック:Buy Pixel Knife MM2
トラックバック:shorts
トラックバック:index
トラックバック:seerr
トラックバック:see
トラックバック:seo